Amazonのログイン情報を保持したい
Q&A
Closed
環境
MAC OS: MAC OS Movajave
言語:python3.8
モジュール一覧
beautifulsoup4 4.9.3
certifi 2020.11.8
chardet 3.0.4
chromedriver-binary 87.0.4280.20.0
click 7.1.2
cssselect 1.1.0
idna 2.10
isodate 0.6.0
lxml 4.6.2
parsel 1.6.0
pip 20.3.1
ppprint 0.1.0
pyparsing 2.4.7
PyYAML 5.3.1
rdflib 5.0.0
requests 2.25.0
selectorlib 0.16.0
selenium 3.141.0
setuptools 49.2.1
six 1.15.0
soupsieve 2.1
SPARQLWrapper 1.8.5
urllib3 1.26.2
w3lib 1.22.0
発生している問題・エラー
クローリングの流れ
1. chromeで「amazon」と検索
2. amazonのURLをクリック
3. amazonにログイン
4. kindle本紹介ページ一覧画面に遷移
5. 一覧ページのhtmlデーターをbeautifulSoupに渡す。
6. ページのスクレピング
手順5のところで詰まっています。
navigateメソッドで該当ページのURLが返されます。
そしてresponseに該当ページのデーターが帰ってくるのですが、ログイン情報が保持されていない状態のページが返されます。
ログイン情報を保持した状態でページが返されてきて欲しいです。
該当するソースコード
import requests
import logging
import time
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
import csv
import pdb
from bs4 import BeautifulSoup
psward = 'パスワード'
search = "amazon"
email = 'メールアドレス'
def main():
options = ChromeOptions()
driver = Chrome(options=options)
actions = ActionChains(driver)
url = navigate(driver, actions)
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
contents = scrape_content_for_login(soup)
# write_to_csv(contents)
def navigate(driver, actions):
logging.info('Navigating...')
driver.get('https://www.google.co.jp/')
# ---pythonを検索
search_window = driver.find_element_by_name('q')
search_window.send_keys(search)
search_window.send_keys(Keys.ENTER)
driver.find_element_by_css_selector('#tads > div > div > div > div.d5oMvf > a > div.cfxYMc.JfZTW.c4Djg.MUxGbd.v0nnCb').click()
#ログイン
flag = login(driver)
# ---メニューをクリック
source = driver.find_element_by_id('nav-hamburger-menu')
source.click()
time.sleep(2)
#---
target =driver.find_element_by_id('hmenu-content')
#--開いたメニューにカーソルを合わせる。
actions.click_and_hold(source)
actions.move_to_element(target)
actions.perform()
time.sleep(2)
#---
i = 0
for _ in range(10):
i += 1
print(i)
#ログインした場合
if flag:
category = driver.find_element_by_css_selector('#hmenu-content > ul.hmenu.hmenu-visible > li:nth-child(14) > a')
else:
#ログインしていない場合
category = driver.find_element_by_css_selector('#hmenu-content > ul.hmenu.hmenu-visible > li:nth-child(13) > a')
print(category.text)
if category.text == 'Kindle 本&電子書籍リーダー':
category.click()
break
else:
time.sleep(3)
actions.click_and_hold(source)
actions.move_to_element(target)
actions.perform()
time.sleep(3)
driver.find_element_by_css_selector('#hmenu-content > ul.hmenu.hmenu-visible.hmenu-translateX > li:nth-child(10) > a').click()
driver.find_element_by_css_selector('#a-page > div.a-container > div.a-row.apb-browse-two-col-center-pad > div.a-column.a-span12.aok-float-right.apb-browse-col-pad-left.apb-browse-two-col-center-margin-right > div:nth-child(4) > div:nth-child(3) > div.a-row.a-spacing-micro.a-spacing-top-mini.dbs-widget-head.a-ws-row > div.a-column.a-span3.a-text-right.a-ws-span4.dbs-widget-head-see-all.a-span-last.a-ws-span-last > a').click()
WebDriverWait(driver, 30).until(EC.visibility_of_element_located)
url = driver.current_url
pdb.set_trace()
return url
def scrape_content_for_login(soup):
logging.info('scraping.....')
contents = []
for book in soup.select('#browse-grid-view > div.browse-clickable-item'):
print(book)
pdb.set_trace()
# title = book.select_one('span > div > span > a > div.p13n-sc-truncate').get_text(strip=True)
# price = book.select_one('span.p13n-sc-price').get_text(strip=True)
# try:
# popular = book.select_one('div.a-icon-row.a-spacing-none > a.a-size-small.a-link-normal').get_text(strip=True)
# except:
# popular = '評価無し'
# contents.append({
#
# 'popular':popular,
# })
# # print(title)
# # print(price)
# # print(popular)
# logging.info(f'scraped {len(contents)} data')
# return contents
def scrape_content_for_unlogin(soup):
logging.info('scraping.....')
contents = []
for book in soup.select('#zg-ordered-list > li.zg-item-immersion'):
title = book.select_one('span > div > span > a > div.p13n-sc-truncate').get_text(strip=True)
price = book.select_one('span.p13n-sc-price').get_text(strip=True)
try:
popular = book.select_one('div.a-icon-row.a-spacing-none > a.a-size-small.a-link-normal').get_text(strip=True)
except:
popular = '評価無し'
contents.append({
'title':title,
'price':price,
'popular':popular,
})
logging.info(f'scraped {len(contents)} data')
return contents
def login(driver):
element = driver.find_element_by_css_selector('.nav-action-inner')
#JavaScriptを呼びだして無理やりクリック
driver.execute_script('arguments[0].click();', element)
element = driver.find_element_by_id('ap_email')
element.send_keys(email)
driver.find_element_by_id('continue').click()
element = driver.find_element_by_id('ap_password')
element.send_keys(psward)
driver.find_element_by_id('signInSubmit').click()
driver.execute_script('window.alert("この後携帯に送られる認証リンクをクリックしてください。");', element)
time.sleep(10)
return True
def write_to_csv(contents):
header = ['title', 'price', 'popular']
with open('./reommended-books.csv', 'w',newline='', encoding='shift-jis') as f:
writer = csv.DictWriter(f, header)
writer.writeheader()
for content in contents:
writer.writerow(content)
if __name__ == '__main__':
logging.basicConfig(level=logging.INFO)
main()
自分で試したこと
その1
chromeアカウントにログインした状態でamazonのリンクを踏めば、自動的にログインされるのではないかと思いchromeにログインしようとしましたがダメでした。
ソフトウェアによって制御されているブラウザーからはログイン出来ないみたいです。
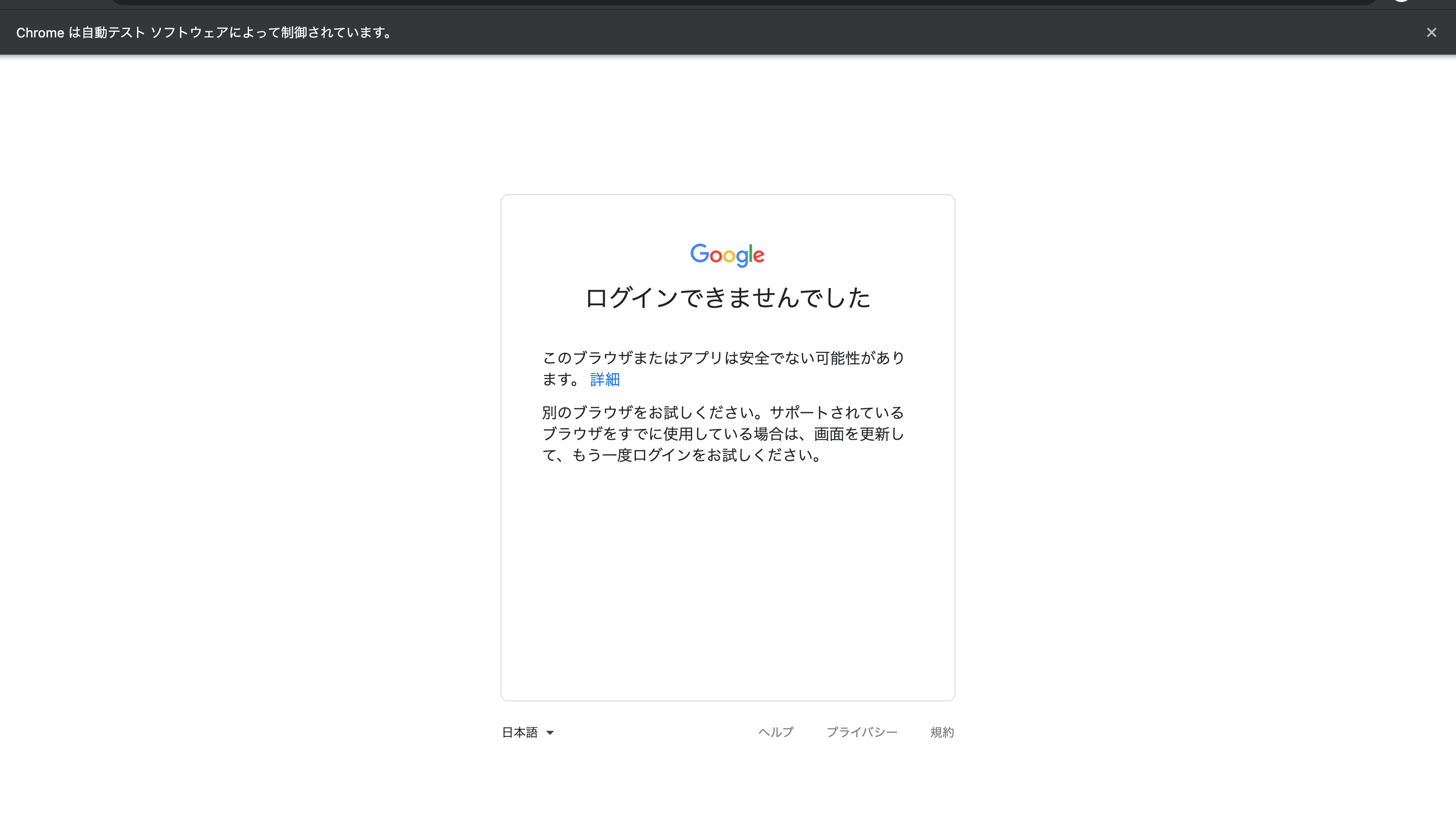
その2
以下のコードを追加してみましたが、ログイン出来ませんでした。
参考にしたページ: Python + Selenium + Chrome で自動ログインいくつか
options = webdriver.ChromeOptions()
options.add_argument('--user-data-dir=Users\\<ユーザ名>\\AppData\\Local\\Google\\Chrome\\User Data')
options.add_argument('--profile-directory=Profile 2') # この行を省略するとDefaultフォルダが指定されます
driver = webdriver.Chrome(options=options)
長文になってしまい申し訳ありません。
何かわかる方、ご教授いただければ幸いです。
0 likes