はじめに
シリーズ第4回です。
これまで、与えたランダムな数値データから平均値と標準偏差を出力するNN(第2回)、与えた正規分布波形データから、正規分布波形データを作成するのに使用した3つのパラメーターを出力するNN(第3回)を、作成してきました。
今回は、円を描いた二次元の画像データから、円を描くのに使用した4つのパラメーター(円の中心のx座標、y座標、半径、ペンの線の太さ)を出力する畳み込みNN(CNN)を作成します。
画像データは、Objective-Cで作成しました。
画像データの作成
まずは画像データの作成です。50ピクセルx50ピクセルの円を描いた画像を作成し、ここからピクセルデータを取得し、円を描くのに使用した4つのパラメーターと併せてファイルに書き出します。1件のデータは、カンマ区切りの2504個のデータよりなります。最初の2500個は、0から1までの数値、残り4個は、円の中心のx座標、y座標、半径、円の線の太さです。データの間は改行(\n)で区切ります。
データの作成はObjective-CでNSImageクラスを使用しました。
// 画像サイズは 50ピクセル x 50ピクセル
// 中心座標、半径、線の太さを乱数で決める。
// 半径は5から25
// 中心座標は、円が画像内に含まれるようにする。
// 線の太さは、0.2から5
# import <Cocoa/Cocoa.h>
-(uint8_t *)pixelDataFromImage(NSImage *image);//main()内で使う関数のプロトタイプ宣言
int main(int argc, const char * argv[]) {
srand((unsigned int)time(NULL));//乱数の初期化
//書き出し先のファイルを開く
char *fileName = "~/imageLearningData.txt";
FILE *fp = fopen(fileName, "w");
//50000枚作成
for(int mmm = 0; mmm < 50000;mmm++){
double radius = (double)rand()/RAND_MAX*20 + 5;
double x = (double)rand()/RAND_MAX*(50 - radius * 2) + radius;
double y = (double)rand()/RAND_MAX*(50 - radius * 2) + radius;
double lineWidth = (double)rand()/RAND_MAX*4.8 + 0.2;
[NSBezierPath setDefaultLineWidth:lineWidth];
NSImage *image = [[NSImage alloc] initWithSize:NSMakeSize(50, 50)];
NSBezierPath *bezierPath = [NSBezierPath bezierPath];
//イメージの描画
[image lockFocus];
[bezierPath appendBezierPathWithOvalInRect:NSMakeRect(x - radius, y - radius, radius * 2, radius * 2)];
[bezierPath stroke];
[image unlockFocus];
uint8_t *pixels = pixelDataFromImage(image);
//ピクセルデータを出力
NSSize size = [image size];
uint32_t width = (uint32_t) size.width;
uint32_t height = (uint32_t) size.height;
int components = 4;
for(int iii = 0; iii < height ;iii ++){
for(int kkk = 0; kkk < width ; kkk++){
double value = 0;
value += pixels[( width * iii + kkk )*4 ]/255.0;
value += pixels[( width * iii + kkk )*4 + 1 ]/255.0;
value += pixels[( width * iii + kkk )*4 + 2 ]/255.0;
//以下は出力ファイルサイズを抑えるための工夫。「1.0000000」の代わりに「1」を出力する。
value /= 3;
if(value == 1){
fprintf(fp,"%d,",1);
}else{
fprintf(fp,"%f,",value);
}
}
}
fprintf(fp,"%f,%f,%f,%f\n",x,y,radius,lineWidth);
free(pixels);
}
fclose(fp);
}
上のコードにある メソッドpixelDataFromImage についてはしまぴょんさん@shimacpyon のコード をすこしだけ改変して以下のように作成しました。しまぴょんさん、ありがとうございます。
-(uint8_t *)pixelDataFromImage(NSImage *image){
/* NSBitmapImageRepのインスタンスを作成します */
NSBitmapImageRep*bitmapRep = [NSBitmapImageRep imageRepWithData:[image TIFFRepresentation]];
/* JPEGで保存する場合は、アルファチャンネルを削除します */
[bitmapRep setAlpha:NO];
/* 保存のための品質を取得します */
float quality = 1.0;
/* プロパティを作成します */
NSDictionary* properties = [NSDictionary dictionaryWithObject:[NSNumber numberWithFloat:quality] forKey:NSImageCompressionFactor];
/* JPEGデータを作成します */
NSData *data = [bitmapRep representationUsingType:NSJPEGFileType properties:properties];
//NSDataからNSImageを改めて作成
NSImage *newImage = [[NSImage alloc] initWithData:data];
if (newImage != nil) {
NSSize size = [newImage size];
uint32_t width = (uint32_t) size.width, height = (uint32_t) size.height, components = 4;
uint8_t *pixels = (uint8_t *) malloc(size.width * size.height * components);//0から255
if (pixels) {
CGColorSpaceRef colorSpace = CGColorSpaceCreateDeviceRGB();
CGContextRef bitmapContext = CGBitmapContextCreate(pixels, width, height, 8, components * width, colorSpace, kCGImageAlphaPremultipliedLast);
NSRect rect = NSMakeRect(0, 0, width, height);
NSGraphicsContext *graphicsContext = (NSGraphicsContext *) [[NSGraphicsContext currentContext] graphicsPort];
CGImageRef cgImage = [newImage CGImageForProposedRect:&rect context:graphicsContext hints:nil];
CGContextDrawImage(bitmapContext, NSRectToCGRect(rect), cgImage);
CGContextRelease(bitmapContext);
CGColorSpaceRelease(colorSpace);
return pixels;
}
}
return nil;
}
NSImageから直接ピクセルデータを取り出すことはできず、NSImageからJPEG形式のデータ(NSData)を取得し、これをもとにあらためてNSImageを作成してそこからピクセルデータを取り出しました。もう少しスマートな方法があるのかもしれませんが、先に進めたいと思います。
学習データの分割
作成した学習データ(2504データ x 50000行)を4つ、すなわち、
- 訓練用の入力データ(2500データx40000行)、
- 訓練用の正解データ(4データ x 40000行)、
- 評価用の入力データ(2500データx10000行)、
- 評価用の正解データ(4データx10000行)、
に分割します。
import numpy as np
d = np.loadtxt('./imageLearningData.txt', delimiter=',')
# -4:は後ろから4つ目から最後まで。
d_training_x = d[:40000,:-4]
d_training_y = d[:40000,-4:]
d_test_x = d[40000:,:-4]
d_test_y = d[40000:,-4:]
# データの形の変更
d_training_x = d_training_x.reshape(40000,50,50,1)
d_test_x = d_test_x.reshape(10000,50,50,1)
CNNのデザイン
CNNをデザインします。二次元画像を学習させるので畳み込みニューラルネットワークを使用します。CNNのデザインは勘に基づいて、適当にデザインしました。考慮したのは以下の点です。
- 畳み込み層をいくつかおく。
- Maxプーリング層でデータ数を減らす。
- 全結合層をいくつか結合して徐々にデータ数を減らして4にする。
- 損失関数は、2乗和誤差を使用。
- 最初の層の入力shapeは(50,50,1)。
- 最後の層の出力数は4。
import keras
from keras.models import Sequential
from keras.layers.convolutional import Conv2D
from keras.layers.pooling import MaxPool2D
from keras.optimizers import Adam
from keras.layers.core import Dense, Activation, Dropout, Flatten
# モデルの定義
model = Sequential()
model.add(Conv2D(32,5,input_shape=(50,50,1)))
model.add(Activation('tanh'))
model.add(Conv2D(32,3))
model.add(Activation('relu'))
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Conv2D(64,3))
model.add(Activation('relu'))
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(1024))
model.add(Activation('relu'))
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dense(4, activation='linear'))
adam = Adam(lr=1e-4)
model.compile(optimizer=adam, loss='mean_squared_error', metrics=["accuracy"])
model.summary()
学習の開始
パラメータの数は6,722,916個です。結構時間がかかりそうですね.....。学習を開始します。
batch_size = 128 # 128データをまとめて放りこむ
epochs = 20
history = model.fit(d_training_x, d_training_y,
batch_size=batch_size,
epochs=20,
verbose=1,
validation_data=(d_test_x, d_test_y))
1エポックあたり107秒かかりました。
学習が進行する様子をグラフにします。lossは訓練データから計算された損失値、val_lossは評価用データから計算された損失値です。
# グラフの描画
import matplotlib.pyplot as plt
plt.plot(history.history['loss'],label="loss")
plt.plot(history.history['val_loss'],label="val_loss")
plt.legend() # 凡例を表示
plt.title("Can CNN learn to predict 4 parameters used to draw a circle?")
plt.xlabel("epoch")
plt.ylabel("Loss")
plt.show()
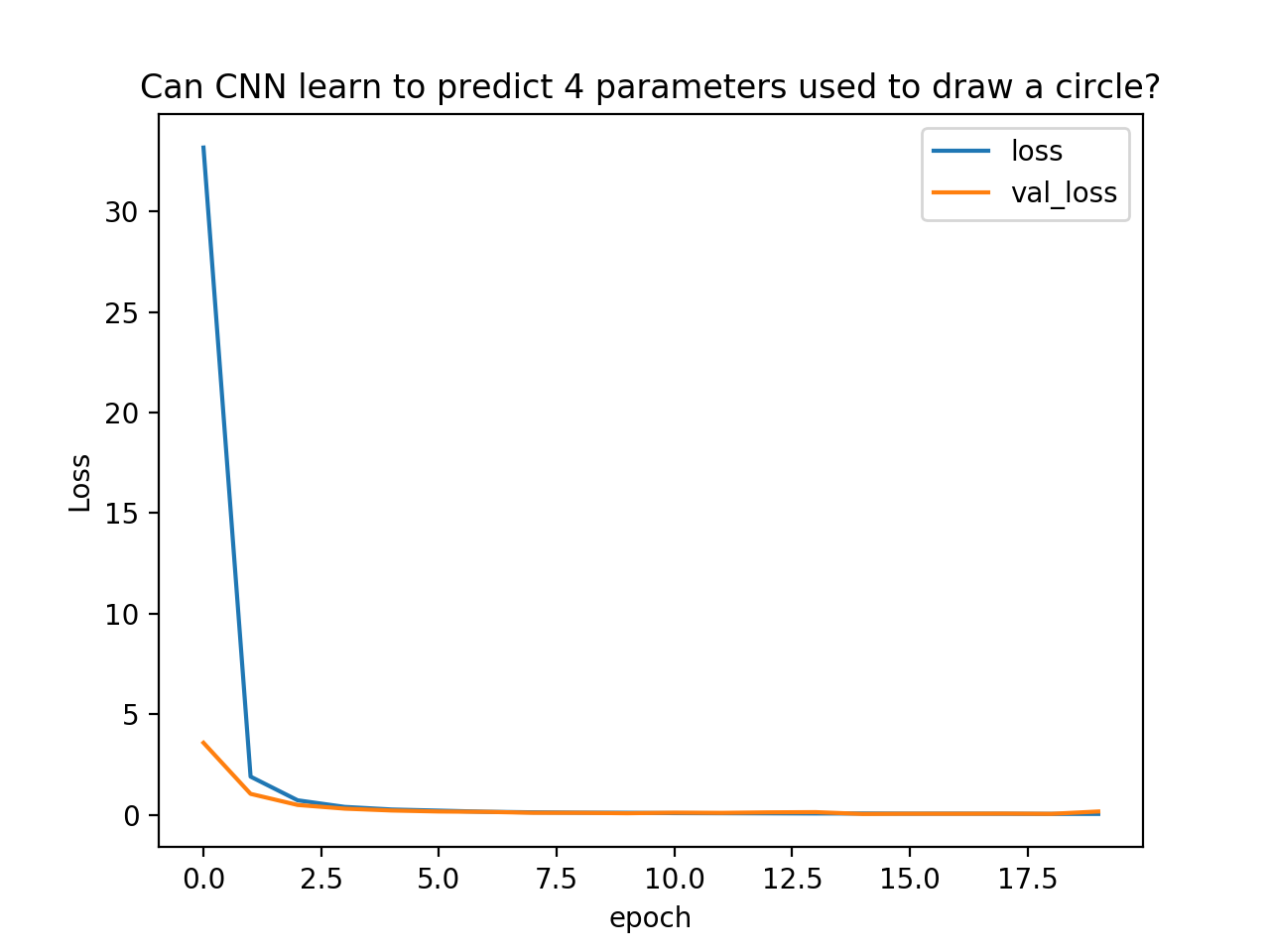
順調に学習できたように見えます。
CNNの評価
どの程度精度良く予測できているでしょうか?評価用データの先頭200データを訓練後のCNNに放り込んでみます。
inp = d_test_x[:200,:]
out = d_test_y[:200,:]
pred = model.predict(inp, batch_size=1)
# グラフにします。
plt.title("Can NN deduce circle parameters?")
plt.scatter(out[:,0], pred[:,0],label = "x",marker='.', s=20,alpha=0.7)
plt.scatter(out[:,1], pred[:,1],label = "y",marker='.', s=20,color="green",alpha=0.7)
plt.scatter(out[:,2], pred[:,2],label = "r",marker='.', s=20,color="red",alpha=0.7)
plt.scatter(out[:,3], pred[:,3],label = "line width",marker='.', s=20,color="black",alpha=0.7)
plt.legend(fontsize=14) # 凡例を表示
plt.xlabel("expected value")
plt.ylabel("prediction")
# 見にくいのでx=yのラインは省略
# x = np.arange(-1, 41, 0.01)
# y = x
# plt.plot(x, y,color="black")
plt.show()
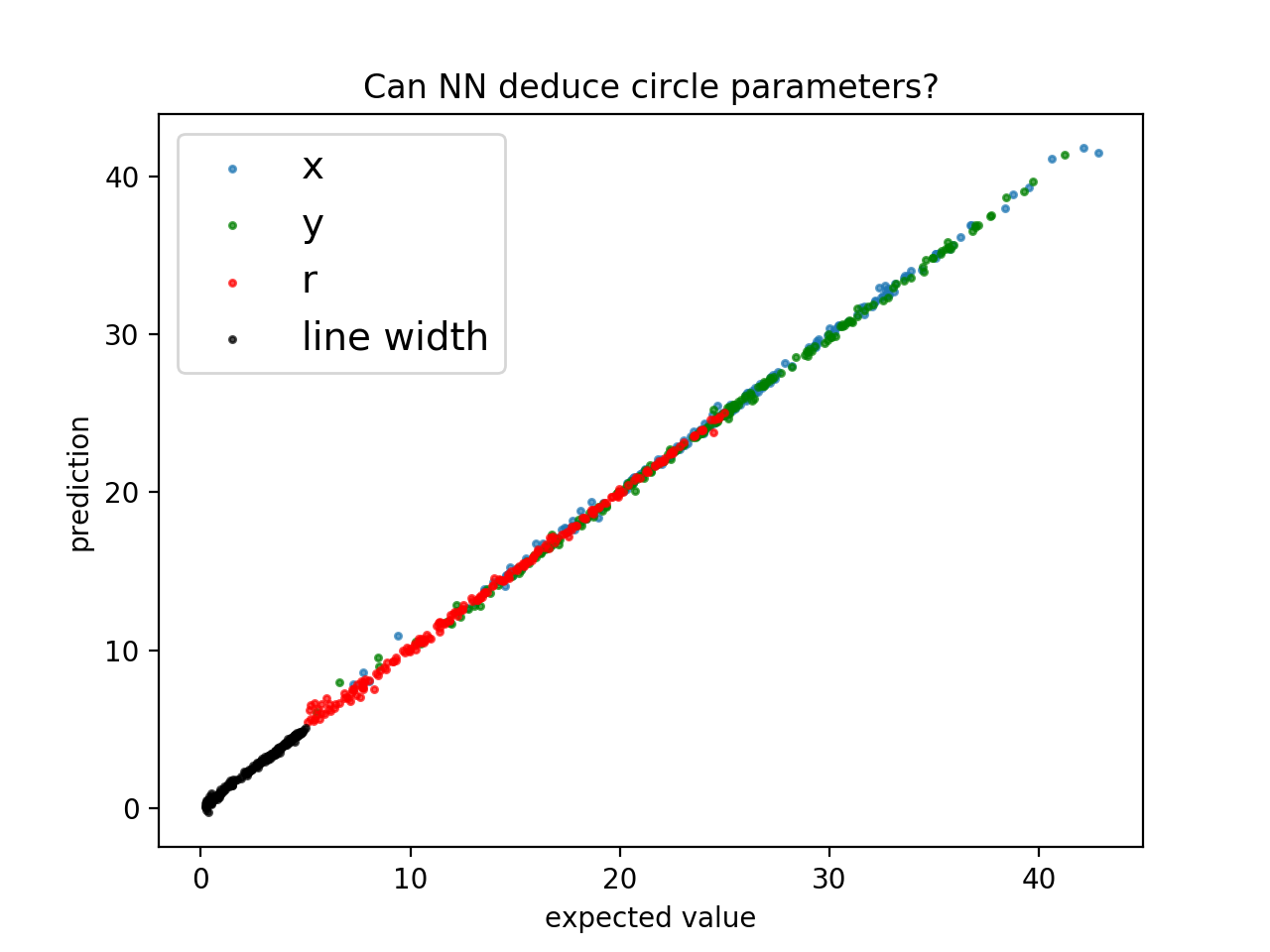
横軸は円データを作成するときに使ったパラメーターの値、縦軸は、画像データをもとにCNNが出力した値です。
左下から右上に引いた$x=y$の線に乗れば、うまく出力できたことになります。
完璧とは言えないものの、概ね良く学習できたようです。ネットワーク構成などを変えたらもう少し良くなるでしょうか?
まとめ
画像の中にどこに、どれくらいの大きさの円があるかを、円を書くためのパラメーターとして出力できるようになりました。
これでシリーズ第4回は終了です!