概要
ツイートをもとに地図上にマーカーを表示する。
- 任意のキーワードでツイッター上を検索しツイートを取得する
- 取得したツイートから地名を抽出する(形態素解析)
- 地名から位置座標を取得する(ジオコーディング)
- 地図上に表示する
余談
ある夜、ぐっすり眠っていたところを緊急地震速報に叩き起こされ、眠れず手持ち無沙汰でTwitterを開いたとき「此方は停電があって照明が付きません」だのなんだの停電被害の書き込みがわらわらと出てくるのを見た。そこで「停電」を含む書き込みの地図上の分布を知りたくなった。
プロフィールやツイート本文から地名を抽出してジオコーディングすることにした。
目次
手順
環境
- Windows 10 Home 64bit
- python 3.8.8
- Visual Studio Code 1.55.2
TwitterAPI各種キー・トークン取得
TwitterAPIって何?
- Twitterにある情報をできるだけ広く共有するために
- API **(アプリケーション・プログラミング・インタフェイス)**を通して
- 企業、開発者、利用者に提供します。
TwitterAPIでは以下のキーが必要である。Twitter開発者アカウントを申請し取得する。
- Consumer key
- Consumer secret
- Access token
- Access token secret
参考記事様
Twitter API 登録 (アカウント申請方法) から承認されるまでの手順まとめ ※2019年8月時点の情報 - Qiita
各種キーはconfig.pyとして保存しておく。
CONSUMER_KEY = "*****"
CONSUMER_SECRET = "*****"
ACCESS_TOKEN = "*****"
ACCESS_TOKEN_SECRET = "*****"
ツイートを取得してjsonを保存する
- 「停電」で検索し、結果をjsonファイルとして保存する
- 日付時刻を名前としてフォルダを作成し、そこに保存する
- TwitterAPIは一度に100件しかくれない。100回繰り返して10000件もらうことにする
- 取得するツイートが被っては困るので、ツイートidの最大値を指定して「それ以前」のツイートに限定する
import json
import datetime
import config # さっき保存したキー
import os
import time
from requests_oauthlib import OAuth1Session
# 各キーの読み込み
CK = config.CONSUMER_KEY
CS = config.CONSUMER_SECRET
AT = config.ACCESS_TOKEN
ATS = config.ACCESS_TOKEN_SECRET
# 認証情報
twitter = OAuth1Session(CK, CS, AT, ATS)
# 保存フォルダ作成
now = datetime.datetime.now()
strNow = now.strftime('%Y%m%d_%H%M%S')
saving_directory_path = f'tweets_{strNow}'
os.mkdir(saving_directory_path)
# クエリを作成
url = 'https://api.twitter.com/1.1/search/tweets.json'
keyword = ['停電']
params = {
'q': keyword,
'lang': 'ja',
'locale': 'ja',
'result_type': 'recent',
'count': 100,
'tweet_mode': 'extended', # full text
'exclude': 'retweets'
}
for i in range(100):
# API制限回避のため
time.sleep(5)
# リクエストを行う
req = twitter.get(url, params=params)
# 応答が正常ならば
if req.status_code == 200:
print('fin write a response')
# json
res = json.loads(req.text)
# idの最小値をクエリに追加
idList = []
for index, tweet in enumerate(res["statuses"]):
idList.append(tweet[u'id'])
params['max_id'] = min(idList) - 1
# ファイル保存
now = datetime.datetime.now()
strNow = now.strftime('%Y%m%d_%H%M%S')
with open(f'{saving_directory_path}\{strNow}.json', mode='wt', encoding='utf-8') as file:
json.dump(res, file, ensure_ascii=False, indent=2)
print(f'get : {i+1}')
else: # 応答が正常でなければ
print('Failed your requests, status_code: {}'.format(req.status_code))
break
jsonファイルを読み込む
- 参照するディレクトリ(さっき保存したやつ)を選ぶ
import os
# 参照jsonの設定
# カレントディレクトリ下に存在するディレクトリのリストを作る
path = "./"
files = os.listdir(path)
files_dir = [f for f in files if os.path.isdir(os.path.join(path, f))]
# ディレクトリのリストを出力
print('switch directory')
for i,item in enumerate(files_dir):
print(i,item)
# 入力
dirNum = input("item number?")
input_dir = f'./{files_dir[int(dirNum)]}'
fileList = os.listdir(input_dir)
print(f'\n{input_dir}\n------------ file list ------------')
for i,item in enumerate(fileList):
print(f'{i} \t {item}')
- 選んだディレクトリ下のjsonファイルを読んで、リストに格納する
- とりあえず テキスト、日付時刻、所在地を拾うことにする
import json
textList = []
createdAtList = []
locationList = []
idList = []
# jsonファイルを検討する
for json_file in fileList:
json_path = f'{input_dir}/{json_file}'
json_open = open(json_path, 'r',encoding="utf-8") # jsonを読み込む
res = json.load(json_open)
# jsonを読んでいく
for tweet in res["statuses"]:
textList.append(tweet[u'full_text'])
createdAtList.append(tweet[u'created_at'])
locationList.append(tweet[u'user'][u'location'])
print(min(createdAtList),' -> ',max(createdAtList))
print('Done.')
形態素解析して地名を抽出する
MeCabをインストールする。
MeCabは 京都大学情報学研究科−日本電信電話株式会社コミュニケーション科学基礎研究所 共同研究ユニットプロジェクト を通じて開発されたオープンソース 形態素解析エンジンです。
MeCab: Yet Another Part-of-Speech and Morphological Analyzer (taku910.github.io)
インストールできたらパスを通しておく。
Path C:\Program Files (x86)\MeCab\bin
MECABRC C:\Program Files (x86)\MeCab\etc\mecabrc
python側のパッケージはmecab-pythonを使用する。
- 地名を抽出し辞書配列にキーとして格納していく
- カタカナや広すぎる単語は除外する
- 複数同じものが存在するときは個数を、キー
countに格納する - 都道府県であるか、キー
prefecturesに真偽を格納する
import MeCab, unidic_lite, re
# 除外ワードの設定
def WordVerification(text):
# 正規表現でカタカナを除外する
regex = u'^[\u30a1-\u30fa\u30fc]+$'
match = re.match(regex, text)
if match:
return False
# リストに一致するワードを除外する
elif text in [u'新開発', u'日本',u'関東',u'関西',u'東北',u'東',u'西',u'南',u'北']:
return False
else:
return True
# 地名だけ抽出する
def PlaceExtracting(text):
# 形態素解析
mecab = MeCab.Tagger()
node = mecab.parseToNode(text)
locList = []
while node:
pos = node.feature.split(",")
# 除外ワードに引っかからなくてかつ地名であるとき
if WordVerification(node.surface) and pos[2] == "地名":
locList.append(node.surface)
node = node.next
return locList
# 都道府県リスト
prefecturesList = [u'愛知',u'青森',u'秋田',u'秋田',u'石川',u'茨城',u'岩手',u'愛媛',u'大分',u'大阪',u'岡山',u'沖縄',u'香川',u'鹿児島',u'神奈川',u'岐阜',u'京都',u'熊本',u'群馬',u'高知',u'埼玉',u'佐賀',u'滋賀',u'静岡',u'島根',u'千葉',u'東京',u'徳島',u'栃木',u'鳥取',u'富山',u'長崎',u'長野',u'奈良',u'新潟',u'兵庫',u'広島',u'福井',u'福岡',u'福島',u'北海道',u'三重',u'宮城',u'宮崎',u'山形',u'山口',u'山梨',u'和歌山']
# ツイート本文と所在地を連結して扱う
combiList = textList + locationList
# 辞書配列を作成
locations_found_dic = {}
for i, loc in enumerate(combiList):
# 地名をリストに抽出する
location = PlaceExtracting(loc)
# 地名について検討する
for loc in location:
# 地名の登場回数を計測
try:
locations_found_dic[loc]['count'] += 1
print(f'{loc}\tcount:{locations_found_dic[loc]["count"]}')
# 既存の辞書配列キーに無いとき、新しくキーを追加する
except KeyError:
locations_found_dic[loc] = {'count':1}
if loc in prefecturesList:
locations_found_dic[loc]['prefectures'] = True
else:
locations_found_dic[loc]['prefectures'] = False
print(f'{loc}\tnew!')
print('\nDone.')
Geocoder/OSMでジオコーディングする
- Geocorderライブラリを通じてOSMさんに問い合わせ、緯度と経度を取得する
- 取得した内容を辞書配列の
coordキーに格納しておく - 内容が無いようであれば、地名キーごと削除する
- 辞書配列をjsonファイルに保存する
import geocoder
keys = []
print(len(locations_found_dic))
# 辞書配列キーのリストを作成する
for loc in locations_found_dic.keys():
keys.append(loc)
# キーを検討していく
for i,place in enumerate(keys):
# geocoderでOSMにジオコーディングしてもらう
ret = geocoder.osm(place,timeout=5.0)
coords = ret.latlng
# 座標はあったか
if not coords is None:
# 辞書に座標を格納しておく
locations_found_dic[place]['coord'] = coords
print(i, place, coords)
# なかったらキーごと消す
else:
locations_found_dic.pop(place)
continue
# 日付を名前にして保存
now = datetime.datetime.now()
strNow = now.strftime('%Y%m%d_%H%M%S')
with open(f'{strNow}_dic.json', 'w') as f:
json.dump(locations_found_dic, f, indent=2, ensure_ascii=False)
print(f'\nsaved as "{strNow}_dic.json"')
print('Done.')
ビジュアライゼーション
- これは以前に保存した地名を読み込むときに使うプログラム
- 必須ではない
import os
import glob
import json
# 参照jsonの設定
# jsonファイルのリストを作成する
filesList = glob.glob('./*.json')
print('switch directory')
for i,item in enumerate(filesList):
print(i,item)
# 入力を促す
dirNum = input("item number?")
input_path = filesList[int(dirNum)]
print(f'input "{input_path}"')
# 辞書として読み込み
with open(input_path) as f:
locations_found_dic = json.load(f)
#内容の確認
createdAtList = []
for loc in locations_found_dic.keys():
print(f'{loc}\tcount:{locations_found_dic[loc]["count"]}')
print(f'total:{len(locations_found_dic.keys())}\nDone.')
地図を描写するためにbasemapを導入する。
どうやらサポートが終了してしまったらしいので、windows用の非公式whlを利用する。
basemap‑1.2.2‑cp38‑cp38‑win_amd64.whl
注意書きがあるので読んでおく。
The files are unofficial (meaning: informal, unrecognized, personal, unsupported, no warranty, no liability, provided "as is") and made available for testing and evaluation purposes.
これらのファイルは非公式( ここでの意味 : 非公式であり認証はなく個人的で、いかなるサポートも保証も責任もなく、「あるがまま」提供される)であり、テストおよび評価の目的で利用可能になる。
Python Extension Packages for Windows - Christoph Gohlke (uci.edu)
県境を描写したいのでjapan_border2ライブラリを利用する。
こちらからコピーできる。
使い方
(略)Pythonパスの通ったフォルダに保存するか、地図のプログラムと同じフォルダに保存します。
- matplotlibとbasemapで地図をプロット
- japan_border2で都道府県境を描写
- 辞書配列を読んでリストを作成
- リスト内容を散布図としてプロット
-
countはサイズで表現する - 都道府県は黄色、ほか市区町村などは赤で表示
-
import matplotlib.pyplot as plt
import numpy as np
from mpl_toolkits.basemap import Basemap
import japan_border2 as jb2
import time
import datetime
# 表示する範囲を緯度経度で指定
top=50
bottom=25
right=151
left=125
# 表示するサイズ
fig=plt.figure(figsize=(10,10))
# 地図を描く
map = Basemap(projection='merc',llcrnrlat = bottom,urcrnrlat = top,llcrnrlon = left,urcrnrlon = right,resolution = "i")
map.drawcoastlines(linewidth=1,color='#6f6f6f')
map.fillcontinents(color = '#444444',lake_color='#353d7e')
map.drawmapboundary(fill_color='#1b1b1b')
jb2.prefectural_bound(map = map,linewidth=0.5,color='#6f6f6f',linestyle = '-')
# 辞書配列を読んでリストを作る
x = []
y = []
p_x=[]
p_y=[]
s=[]
p_s=[]
for place in locations_found_dic:
dic = locations_found_dic[place]
try:
coords = dic['coord']
if dic['prefectures']:
p_x.append(coords[1])
p_y.append(coords[0])
p_s.append(dic['count'])
else:
x.append(coords[1])
y.append(coords[0])
s.append(dic['count'])
except KeyError:
print('error')
continue
# 散布図の要領で座標の場所に丸を描く
map.scatter(p_x, p_y, alpha = 0.4, s = p_s, c='#f4cd27', edgecolor='y',latlon=True,zorder=3)
map.scatter(x,y,alpha=0.4, s = s, c='#cc1b23', edgecolor='r',latlon=True,zorder=3.1)
# 名前を日付時刻にしてJPG保存
now = datetime.datetime.now()
strNow = now.strftime('%Y%m%d_%H%M%S')
plt.savefig(f'IMG_{strNow}.jpg', dpi=600, bbox_inches='tight')
# 出力
plt.show()
結果
検索ワード : 停電
Sat Mar 20 09:27:43 2021 -> Sat Mar 20 09:33:47 2021 (地震直後)
取得数 : 100件
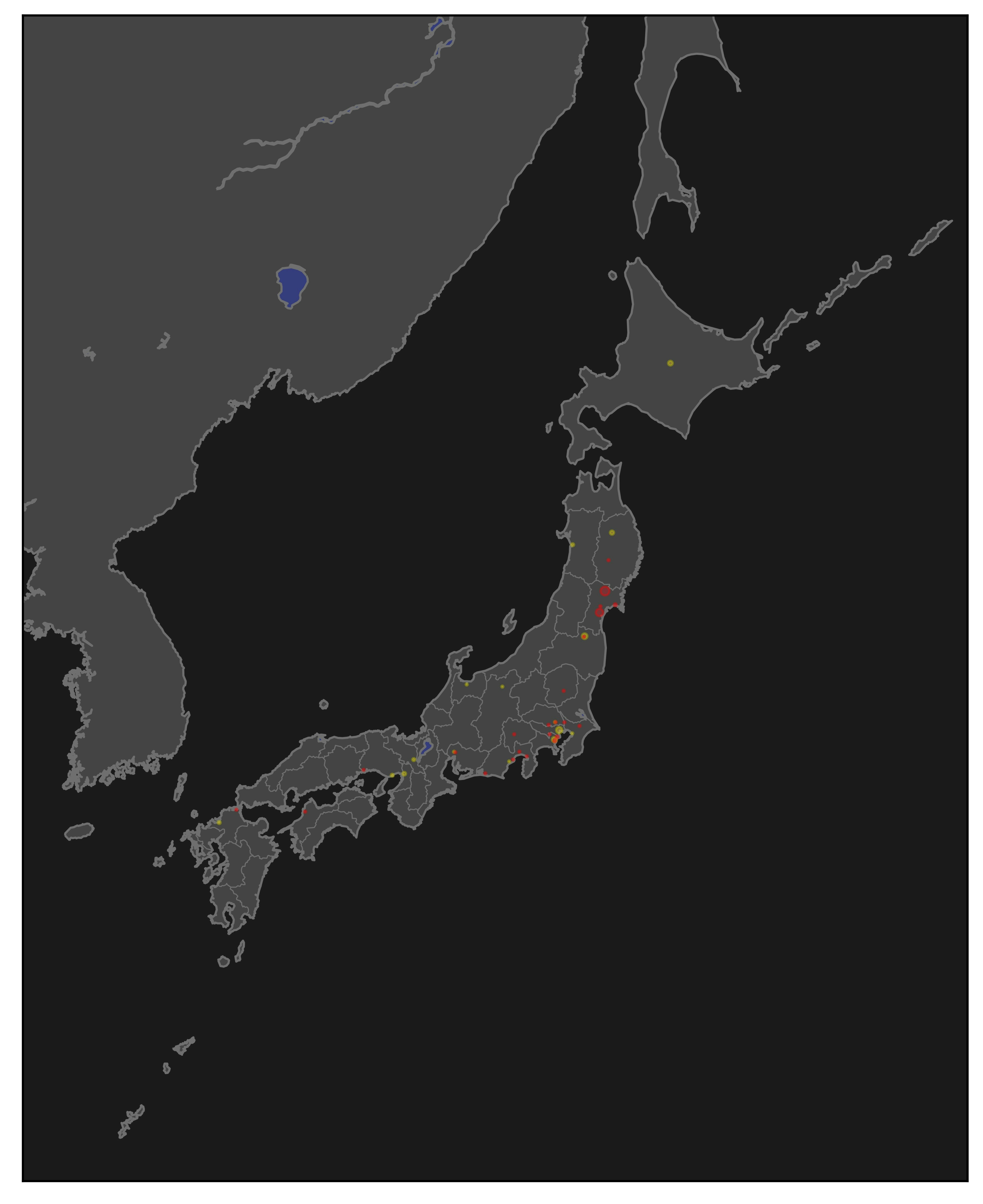
丸が小さくてよくわからない。
countを*100してみる
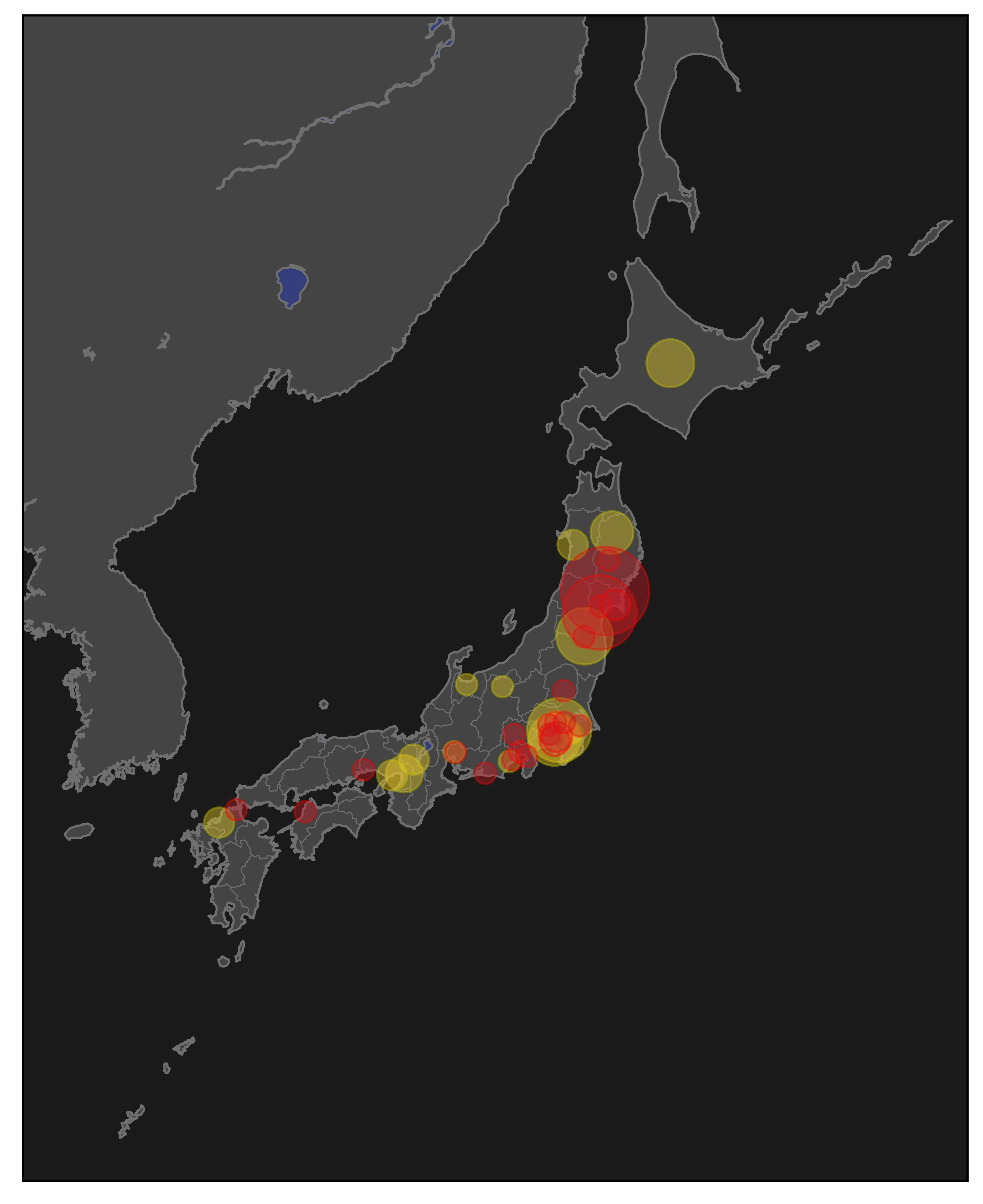
地震情報 2021年03月20日 18時09分頃発生 最大震度:5強 震源地:宮城県沖(牡鹿半島の北東20km付近) - 日本気象協会 tenki.jp
こちらの情報と見比べてみた。
やりたかったことは概ねできているように思える。
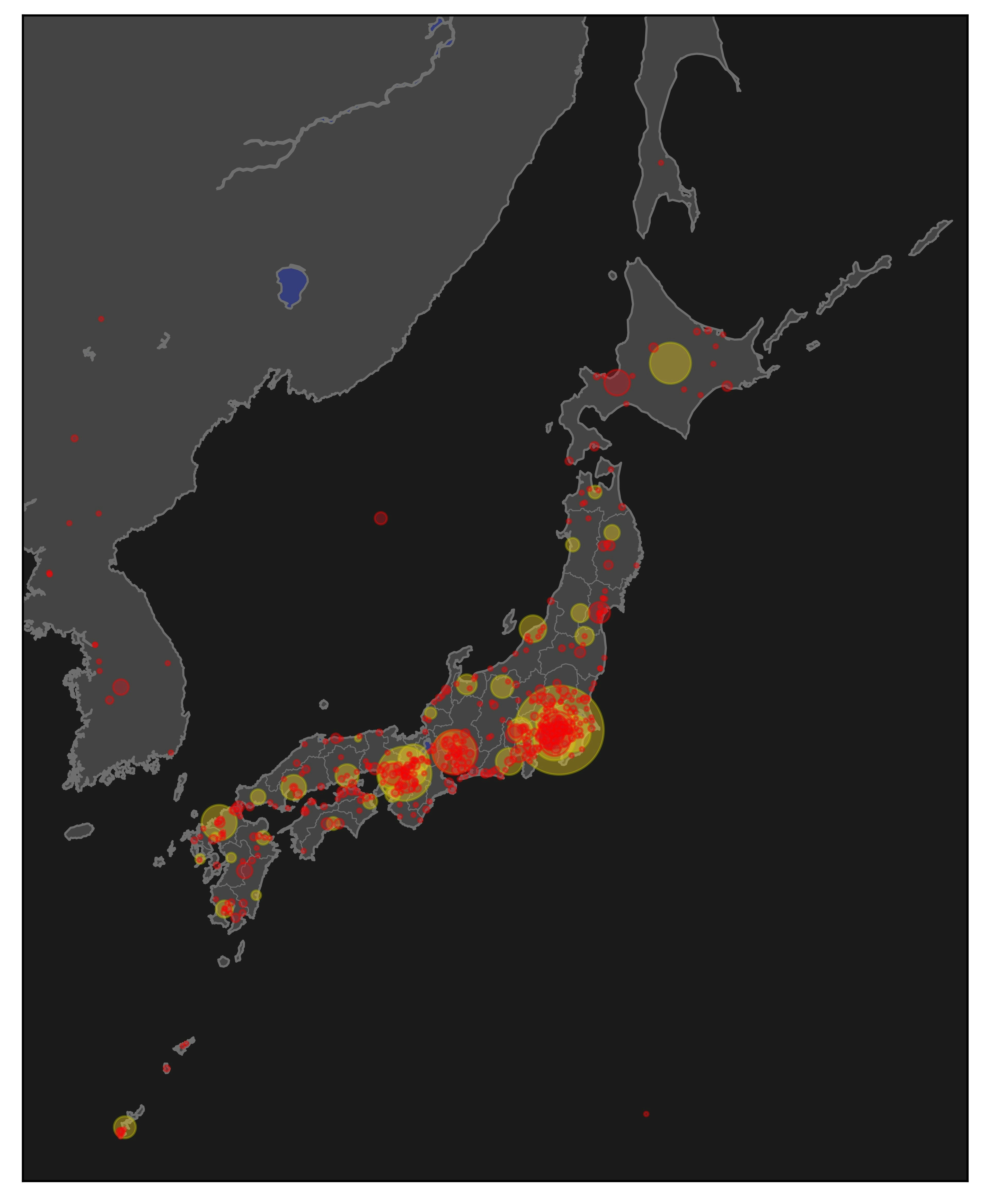
検索ワード : コンビニ
Sun Apr 18 01:21:13 2021 -> Sun Apr 18 07:57:43 2021
取得数 : 1000件
countを*4した
課題
- タイトルや凡例もプロットするべき
- ジオコーディングするときhttpリクエストでは時間がかかる
- ローカルにジオコーダーを構築すればいいのでは
- R&Dが開発したPython用ジオコーディングツールを紹介|公式ブログ|ホットリンク (hottolink.co.jp)
- プログラムが汚い
- ゆるして