スタバTwitterシリーズの第4回目です。
今回は、tweetデータに含まれる位置情報を処理してみたいと思います!
その1:Twitter REST APIsでデータを取り込みmongoDBにインポート
http://qiita.com/kenmatsu4/items/23768cbe32fe381d54a2
その2:取得したTwitterデータからスパムの分離
http://qiita.com/kenmatsu4/items/8d88e0992ca6e443f446
その3:ある日を境にツイート数が増えたわけは?
http://qiita.com/kenmatsu4/items/02034e5688cc186f224b
その4:Twitterにひそむ位置情報の視覚化(今回)
http://qiita.com/kenmatsu4/items/114f3cff815aa5037535
<<< 分析対象データ >>>
- データ件数
- 600,777件 ・・・ だいぶ増えてきました
- 取得データの期間
- 2015-03-11 04:43:42 から 2015-04-03 02:09:30
- 1秒あたりツイート数
- 3.292 tweet/sec
今回の内容の概略図
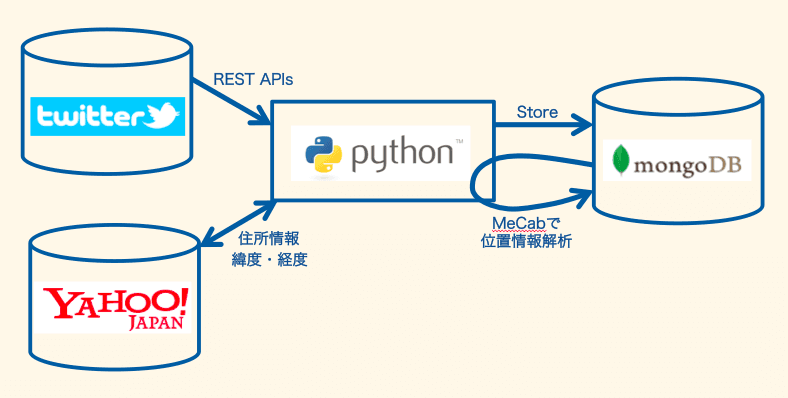
今回も本文に「スタバ」が含まれたツイートを分析対象にします。また、ツイート自体に付加されている緯度経度情報に加え、MeCabをつかってツイート本文から地名を抽出し、それをYahoo!ジオコーダAPIをつかって緯度経度情報に変換して、この内容も見て行く、ということを行います。
前半はデータの処理をどうコーディングするかの話、後半はそれを視覚化、ビジュアライゼーションした結果を見ていく、という構成になっていますので、絵的にどうなっているかを見たい人はこのページの下半分くらいを見ていただければと思います。
1.ツイート本文からの位置情報推測
###1-1. 準備 ###
まず最初に使用するライブラリ群のインポートとmongoDBへの接続を確立します。
%matplotlib inline
import numpy as np
import json, requests, pymongo, re
from pymongo import Connection
from collections import defaultdict
import matplotlib.pyplot as plt
from mpl_toolkits.basemap import Basemap
connect = Connection('localhost', 27017)
db = connect.starbucks
tweetdata = db.tweetdata
location_dict = db.location
ツイート情報自体に"coordinates"というフィールドが含まれており、GPSなどの位置情報付きでつぶやいた場合はここに緯度経度が含まれます。まず、どのくらいの人が位置情報付きでツイートしているかを見てみたいと思います。
num_not_geo = tweetdata.find({'coordinates':None,'spam':None,'retweeted_status': None},{'_id':1, 'coordinates':1}).count()
num_geo = tweetdata.find({'coordinates':{"$ne":None},'spam':None,'retweeted_status': None},{'_id':1, 'coordinates':1}).count()
print "num_not_geo",num_not_geo
print "num_geo", num_geo
print "%.3f"%(num_geo / float(num_geo+num_not_geo) * 100),"%"
<<< 結果 >>>
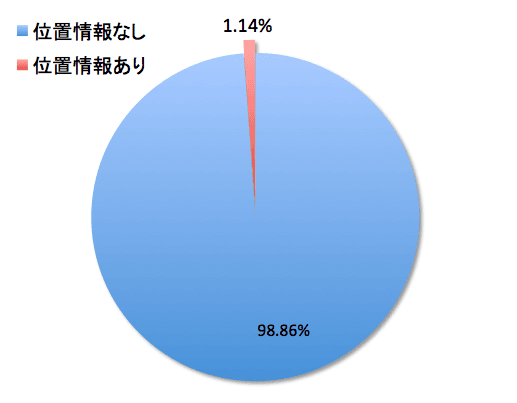
- 位置情報なしツイート数
- 444,188件
- 位置情報ありツイート数
- 5,122件
- 位置情報つぶやき率
- 1.140 %
@arieee0さんの「テキストからのSNSユーザ位置推定手法と活用事例紹介」 p24の場合は位置情報付きTweetの割合は0.3%だったそうなので、スタバ愛好家は若干を主張する傾向にあるかもしれませんw(正確には差が有意かの検定をして見ないとわかりませんが)
1-2. 地名を示す単語の抽出
ツイート本文から地理情報を何か推測できないかと色々探していたのですが、そもそもMeCabで地名が抜き出せることがわかり、これを使っていきます。なんて便利なんだ!
下記がMeCabで形態素解析した例ですが、六本木、渋谷と文中にありますが、これらに「固有名詞,地域」というタグが付くので簡単に抜き出せます![]()
今日 名詞,副詞可能,*,*,*,*,今日,キョウ,キョー
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
六本木 名詞,固有名詞,地域,一般,*,*,六本木,ロッポンギ,ロッポンギ
に 助詞,格助詞,一般,*,*,*,に,ニ,ニ
行く 動詞,自立,*,*,五段・カ行促音便,基本形,行く,イク,イク
けど 助詞,接続助詞,*,*,*,*,けど,ケド,ケド
、 記号,読点,*,*,*,*,、,、,、
その 連体詞,*,*,*,*,*,その,ソノ,ソノ
前 名詞,副詞可能,*,*,*,*,前,マエ,マエ
に 助詞,格助詞,一般,*,*,*,に,ニ,ニ
渋谷 名詞,固有名詞,地域,一般,*,*,渋谷,シブヤ,シブヤ
に 助詞,格助詞,一般,*,*,*,に,ニ,ニ
行き 動詞,自立,*,*,五段・カ行促音便,連用形,行く,イキ,イキ
たい 助動詞,*,*,*,特殊・タイ,基本形,たい,タイ,タイ
。 記号,句点,*,*,*,*,。,。,。
既に名詞をMeCabで抜き出してDBにいれてあったので、ここから地名を抽出して別フィールドに入れ込みます。
# Mecabで本文から地域名称を抽出してfield: location_nameとして設定する
def location_name_mecab(sentence):
t = mc.Tagger('-Ochasen -d /usr/local/Cellar/mecab/0.996/lib/mecab/dic/mecab-ipadic-neologd/')
sentence = sentence.replace('\n', ' ')
text = sentence.encode('utf-8')
node = t.parseToNode(text)
result_dict = defaultdict(list)
for i in range(140):
if node.surface != "": # ヘッダとフッタを除外
# 固有名詞かつ、地域の単語を選択
if (node.feature.split(",")[1] == "固有名詞") and (node.feature.split(",")[2] == "地域"):
plain_word = node.feature.split(",")[6]
if plain_word !="*":
result_dict[u'地域名称'].append(plain_word.decode('utf-8'))
node = node.next
if node is None:
break
return result_dict
for d in tweetdata.find({'spam':None},{'_id':1, 'text':1}):
ret = location_name_mecab(d['text'])
tweetdata.update({'_id' : d['_id']},{'$push': {'location_name':{'$each':ret[u'地域名称']}}})
###1-3. 地名から緯度経度に変換する ###
地名が抜き出せたので、それを元に緯度経度情報を取得します。Yahoo!ジオコーダAPIを使うのですが、毎回アクセスに行くと回数を消費し切ってしまいアクセス回数制限に引っかかってしまうので、先に変換対象の地名をピックアップして地名と緯度経度のセットを持つテーブルをmongoDB上に持ってしまいます。
まず、緯度経度情報が欲しい地名リストを作成します。
# Tweetのlocation_nameをユニークにして辞書オブジェクト"loc_name_dict"に集約する
loc_name_dict = defaultdict(int)
for d in tweetdata.find({'spam':None},{'_id':1, 'location_name':1}):
for name in d['location_name']:
loc_name_dict[name] += 1
集約した地名一式をYahoo!ジオコーダAPIに投げて、緯度経度情報を取得します。
ジオコーダAPIを使うためにはappidが必要なので、Yahoo!デベロッパーネットワークでアカウント作成、appid取得して設定します。
# ツイートから抽出した地名に緯度経度を付与してmongoDBにインポート
def get_coordinate_from_location(location_name):
payload = {'appid': '<Yahooのappidをセット>', 'output':'json'} # appidは自分のアカウントのものを設定してください!
payload['query'] = location_name # eg.g u'六本木'
url = "http://geo.search.olp.yahooapis.jp/OpenLocalPlatform/V1/geoCoder"
r = requests.get(url, params=payload)
if r.status_code == 200:
jdata = json.loads(r.content)
# クエリで取得してた位置情報のリストから平均を算出してそれをその地名の緯度経度とする。
try:
ret = np.array([map(float,j['Geometry']['Coordinates'].split(',')) for j in jdata['Feature']])
except KeyError, e:
"KeyError(%s)" % str(e)
return []
return np.average(ret,axis=0)
else:
print "%d: error." % r.status_code
return []
# 地名 - 緯度経度 のリンクを保持するテーブル"location"に入れ込む
for name in loc_name_dict.keys():
loc = get_coordinate_from_location(name)
if len(loc) > 0:
location_dict.insert({"word":name,"latitude":loc[1],"longitude":loc[0]})
###1-4. 緯度経度情報をTweetデータに付加する###
地名と緯度経度の紐付けが出来ましたので、これをTweetデータに適用していきます。
カタカナ地名は国名等を表現する場合が多く、自分の所在と表すケースが少なかったのでカタカナのみの地名は除外しました。また、富山県射水市に新開発(しんかいほつ)という地域があるのですが、これ、別な意味で使われているケースが非常に多かったので例外としてこれも除外しました。(珍しい地名ですね)あと、「日本」も非常に漠然としているので除外しています。
# Tweetデータにテキスト位置情報を付加
# DBより地名、緯度経度を取り出し辞書オブジェクトで保持
loc_dict = {loc['word']:[loc['longitude'],loc['latitude']] for loc in location_dict.find({})}
def get_coord(loc_name):
# カタカナだけの地名は除外(国名が多く、所在地を表している可能性が低い為)
regex = u'^[ァ-ン]*$'
match = re.search(regex, loc_name, re.U)
if match:
return 0
# 除外ワード(新開発がなぜか地名となっているのと、日本は漠然としすぎる割に高頻度のため)
if loc_name in [u'新開発', u'日本']:
return 0
if loc_name in loc_dict:
# あれば位置情報を返す
return (loc_dict[loc_name][0],loc_dict[loc_name][1])
else:
# なければゼロを返す
return 0
def exist_check(word):
return True if word in loc_dict else False
for d in tweetdata.find({'coordinates':None,'spam':None},{'_id':1, 'location_name':1}):
if len(d['location_name']) > 0:
name_list = np.array(d['location_name'])
# 位置情報があるものはTrue, ないものはFalseの配列生成
ind = np.array(map(exist_check, name_list))
# Trueの数カウント
T_num = len(ind[ind==True])
# 地名をもつTweetのみ処理する
if T_num > 0:
coordRet = map(get_coord, name_list[ind]) # key_list[ind]は位置情報存在するものだけ
[coordRet.remove(0) for i in range(coordRet.count(0))] # 0を除去
if len(coordRet) == 0:
continue
# 最初の地名を採用する(複数の地名がTweet内にあるケースがあるが、最初の方が重要、ということにする)
lon, lat = coordRet[0]
# DBに反映
tweetdata.update({'_id' : d['_id']},
{'$set' : {'text_coord' : {'longitude':lon, 'latitude': lat}}})
##2. 位置情報の可視化##
###2-1. プロットする###
データが一通り揃いましたので可視化をやっていきたいと思います。
まずは何も考えずにえいやっとプロットします。
# ツイートに含まれる緯度経度情報の取り出し
loc_data = np.array([[d['coordinates']['coordinates'][1],d['coordinates']['coordinates'][0]]\
for d in tweetdata.find({'coordinates':{"$ne":None},'spam':None},{'_id':1, 'coordinates':1})])
# DBよりツイート抽出位置情報リストを取り出し
text_coord = np.array([[d['text_coord']['latitude'],d['text_coord']['longitude']] for d in tweetdata.find({'text_coord':{'$ne':None}},{'_id':1, 'text_coord':1})])
lat1 = loc_data[:,0] # 緯度(latitude)
lon1 = loc_data[:,1] # 経度(longitude)
lat2 = text_coord[:,0] # 緯度(latitude)
lon2 = text_coord[:,1] # 経度(longitude)
xlim_min = [np.min(lon)*.9,120,139]
xlim_max = [np.max(lon)*1.1,150,140.5]
ylim_min = [np.min(lat)*.9,20,35.1]
ylim_max = [np.max(lat)*1.1,50,36.1]
for x1,x2,y1,y2 in zip(xlim_min,xlim_max,ylim_min,ylim_max):
plt.figure(figsize=(10,10))
plt.xlim(x1,x2)
plt.ylim(y1,y2)
plt.scatter(lon1, lat1, s=20, alpha=0.4, c='b')
for x1,x2,y1,y2 in zip(xlim_min,xlim_max,ylim_min,ylim_max):
plt.figure(figsize=(10,10))
plt.xlim(x1,x2)
plt.ylim(y1,y2)
plt.scatter(lon2, lat2, s=20, alpha=0.4, c='g')
まずは、Tweetデータにもともと緯度経度を含んでいるものから見ていきます。
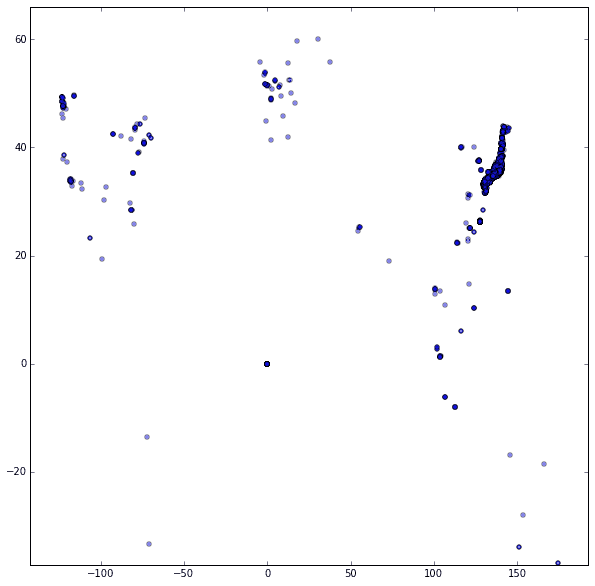
さてどうでしょう。
よくわからないですね。
でもお気づきの方もいるかもしれませんが、右上の方に点が集まっているところがあります。
ちょっと拡大してみてみたいと思います。
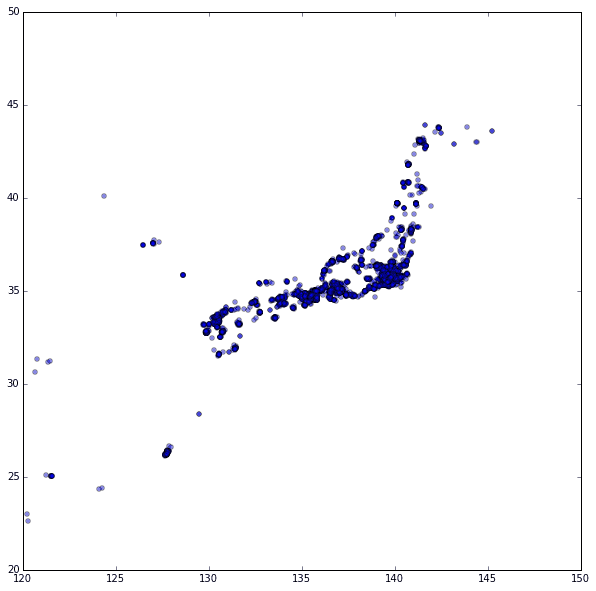
日本ですね! ![]()
検索ワードが「スタバ」なので当たり前っちゃ当たり前なのですが、1%, 5千件程度のツイートで日本列島が判別できるということは、「スタバ」でツイートしている人が割と均等に散らばっていると言えるのではないでしょうか。
###2-2. 地図の上にプロットする###
では、今度はこのデータを地図の上に乗せてもっとはっきり見てみたいと思います
Matplotlib basemapというライブラリを使用しますので、このリンクを参照にライブラリをインストールしておきます。
# 地図の上にプロットする
from mpl_toolkits.basemap import Basemap
import matplotlib.pyplot as plt
#ite = 20
ar = np.arange
enlarge = [1,2,4,8,16,32]
w_list = [15000000./(i) for i in enlarge]
h_list = [9000000./(i) for i in enlarge]
xlim_min = [-142, 80, 120, 135, 139]#[3:5]
xlim_max = [ 192, 160, 150, 142, 141]#[3:5]
ylim_min = [ -55, 0, 20, 33, 35]#[3:5]
ylim_max = [ 75, 50, 50, 37, 36.2]#[3:5]
ss = [ 0.7, 0.3, 0.1, 0.03, 0.005]#[3:5]
for lon, lat in zip([lon1,lon2],[lat1,lat2]):
for i, s in zip(ar(len(xlim_min)),ss):
m = Basemap(projection='merc',llcrnrlat=ylim_min[i] ,urcrnrlat=ylim_max[i] ,\
llcrnrlon=xlim_min[i],urcrnrlon=xlim_max[i] ,lat_ts=20, resolution='c')
plt.figure(figsize=(13,13))
m.bluemarble()
if i > 2:
m.drawcoastlines(linewidth=0.25)
for x, y in zip(lon,lat):
m.tissot(x, y, s,100,facecolor='red',zorder=100,alpha=0.4)
plt.show()
plt.savefig('plot_map_%s.png'%(str(i)))
さて、これが結果です。
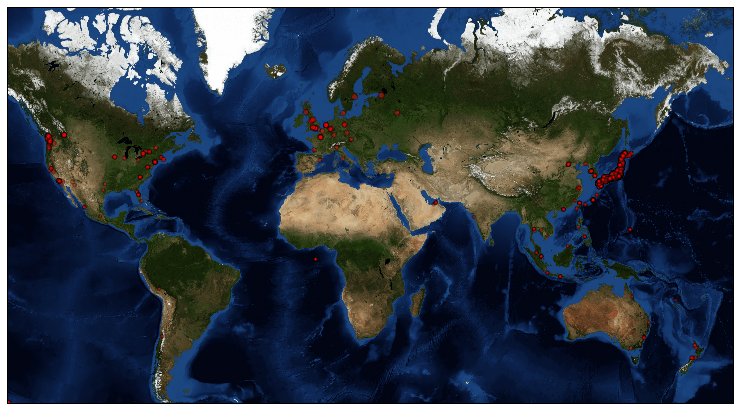
地図の上に乗せてみるとどの地域からTweetされているか一目瞭然です。
「スタバ」で検索しているのでやはり日本が多いですが、意外とヨーロッパ、アメリカ、東南アジア等、様々な地域からも「スタバ」ツイートがされているんですね!
また、拡大して見ていきます。
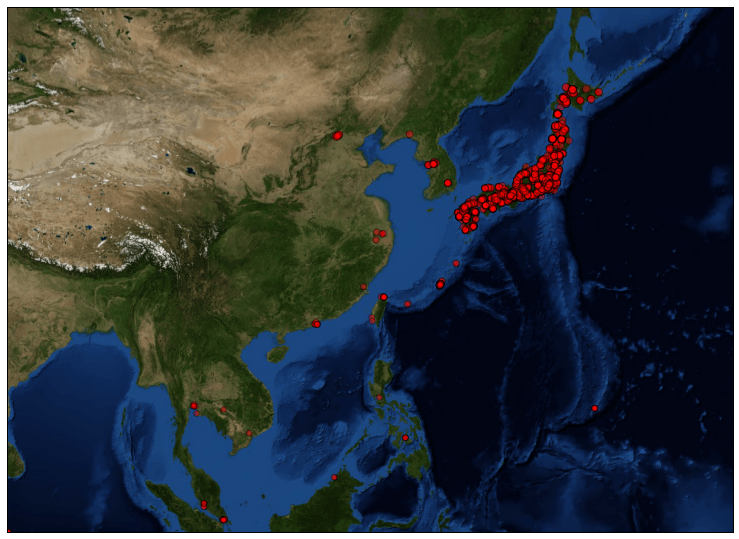
日本を埋め尽くしていますねw
台湾、中国、韓国、東南アジアあたりにもちらほらとツイートの後が見られます。
さらに拡大します。
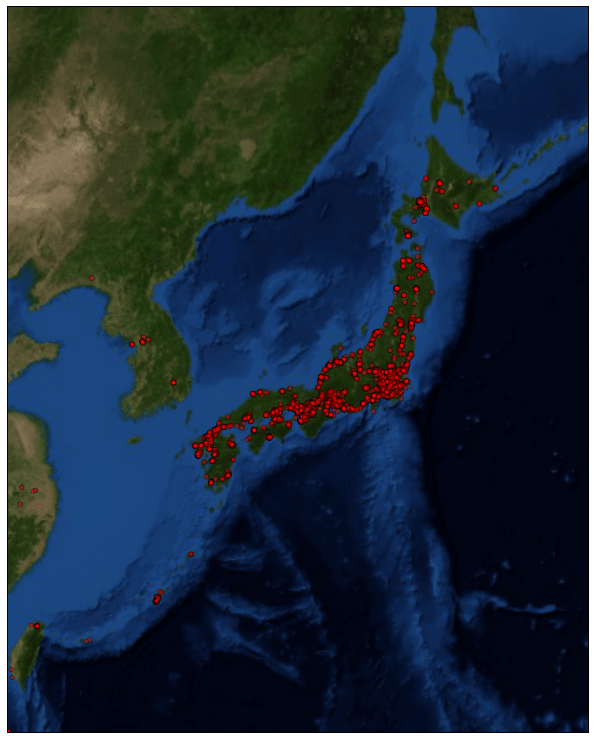
全体に散らばってはいるものの、やはり東名阪は特に密集していますね。
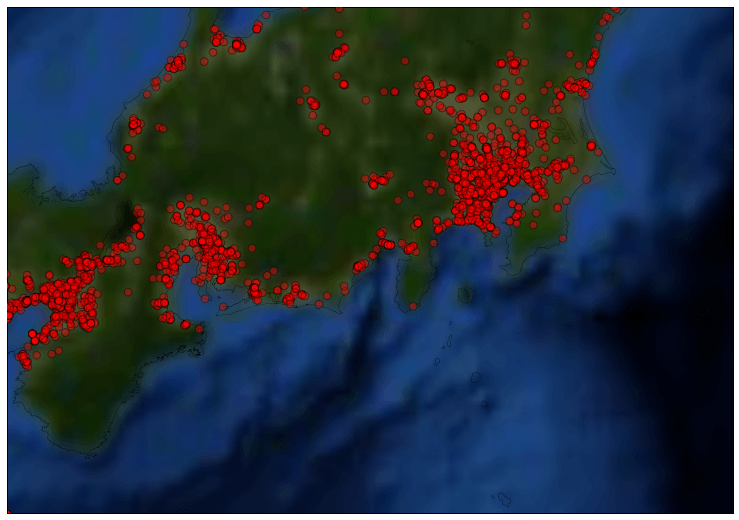
やはり人口が多そうな都市部に多く、山間部にからはツイートされていません。
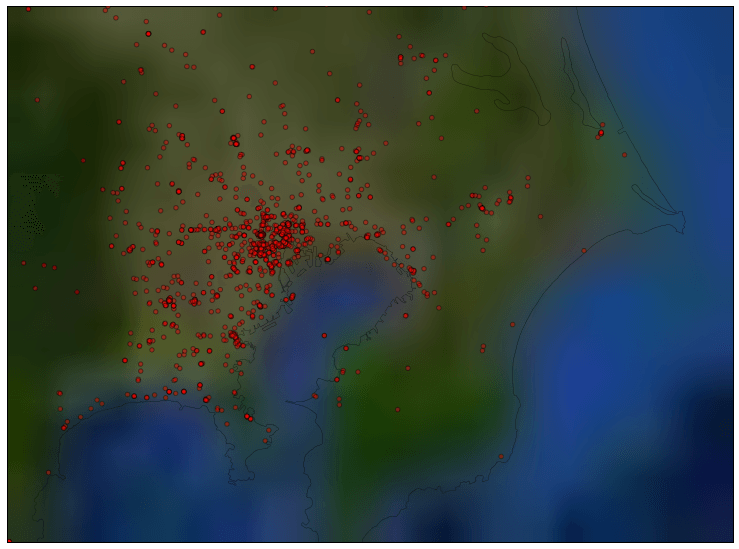
これが一番倍率を上げて首都圏にフォーカスしたものです。
白っぽいところが平野部になりますが、ここからのツイートが多く、緑色の山間部からはツイートされていません。なんとなく直感とあっているのではないでしょうか。
##3. ツイート本文から推測した位置情報も可視化してみる##
本文から推測できた緯度経度情報は50,310件と、GPS情報ベースの先ほどのものより10倍近い数のデータが取れました。
先ほどのコードでツイート本文から推測した緯度経度をプロットする処理もすでに入っていますので、地図をまた見ていきます。
ツイート本文の地名からどのようなプロットになるか、楽しみです。
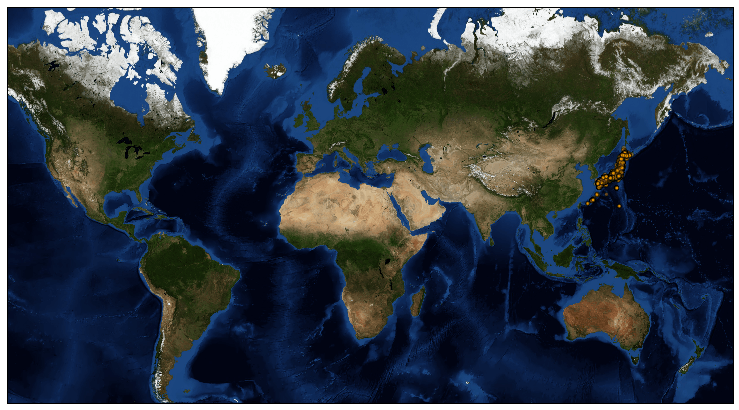
今回は完全に日本に集中しています。というのもMeCabで抽出しているのが日本語の地名であることと、前述の通りカタカナ地名を除外しているので、想定通りの結果と言えるのではと思います。
拡大します。
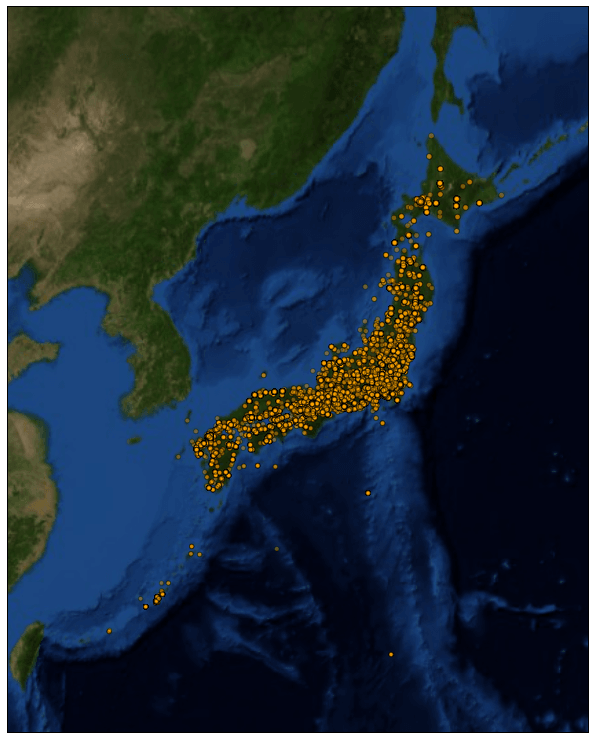
さっきよりびっしりですね!北海道は密度薄めですが、本州、四国、九州の密度はだいぶ高いようです。
地名から緯度経度に変換する際、謎の地名が含まれていたのか、海上真っ只中の点も含まれていることから、やはり精度の面ではGPS情報には勝てないと思います。また、ツイート本文の地名が現在位置を示すとは限らないので、ここは前後の単語から文中での地名の使われ方を推測する手法が取れると精度が上がると思うので、課題としたいと思います。
拡大します。
とは言え、なんかいい感じに散らばっていますよね!
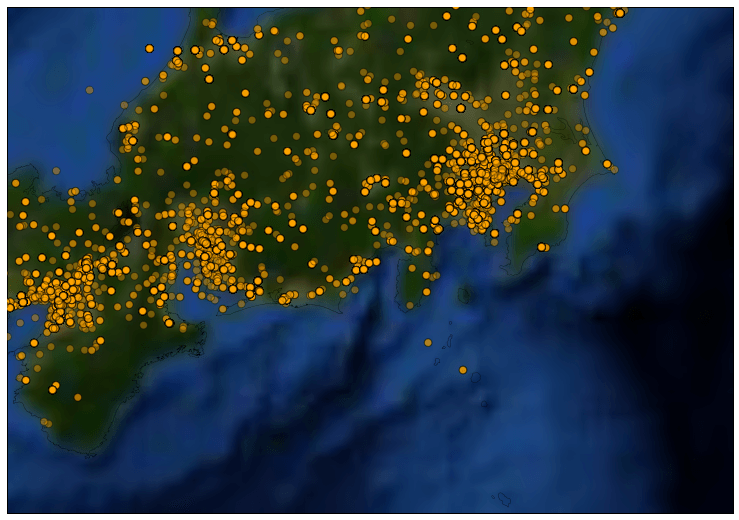
最後にまた首都圏です。
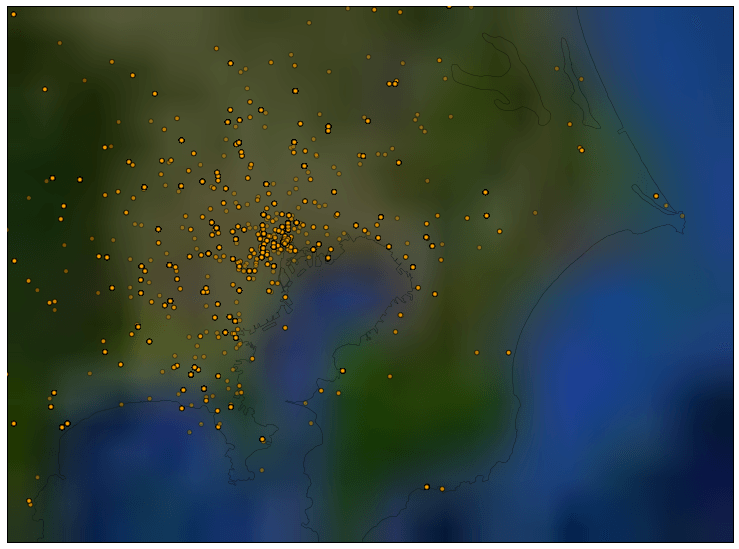
なんだか、GPS情報の時より数が少なく見えるのは、地名から緯度経度を取得しているために同じ地点に集約されてしまうことが理由ですね。色が濃いオレンジの点が見えますが、それは同じ箇所に点がたくさん集まっていることを表しています。
というわけで、Tweetデータから位置情報を取り出して、視覚化するということを今回は行いました。
海外にいて「スタバ」とつぶやく内容はどんなものか?など気になるところがいくつかありますが、だいぶ長くなりましたので、分析結果については以降の回で書いていきたいと思います。
コードの全文はGistにあります。