想定読者
- Treasure Dataは触ったことある(触れる環境がある)
- SQLはある程度書ける(サブクエリもできる)
- 機械学習はあんまりやったことない(これからやりたい)
3行で言うと
- Treasure Dataの機械学習についてまとまった日本語ドキュメントがなかったのでまとめてみた
- 主要な5つの機械学習機能を、とりあえずTreasure Data上で実装できるようになることを目指す
- 一部の機械学習については詳細なSQLや実行結果まで載せるが、一部は外部リンクや公式ドキュメントの紹介のみ
注意事項
-
この記事は、「とりあえずTreasure Dataで機械学習を動かすこと」を目的とします。精度・パフォーマンスの観点ではベストな実装でない可能性が多分にありますがご了承ください。(良い実装方法があれば是非コメントでお知らせ下さい)
-
以降、特段の記載のあるもの以外は、Hivemallユーザーガイドを参考にしています。不明な点など、適宜原文をご参照ください。
Treasure Dataで機械学習?
Treasure DataにはHivemallという機械学習ライブラリが組み込まれており、以下画像のクエリ画面で、Hiveに切り替えるだけで利用可能です。
SQLベースで実行できるため、Pythonを書かなくても(書けなくても)機械学習ができることが最大のメリットだと感じています。
とはいえ、Hivemallを使うには、種々の関数を覚え、使いこなす必要がありますので、この記事ではそれら機械学習関連の機能をご紹介します。
この記事で取り上げる機械学習機能
Hivemallユーザーガイドにリストアップされてるものから、個人的に利用頻度が高いと想定する以下の5つをご紹介します。
- 回帰(Regression)
- 2値分類(Binary classification)
- ランダムフォレスト(RandomForest)
- リコメンド(Recommendation)
- 異常検知(Anomaly detection)
データの準備
回帰や分類の機械学習を行う時は、ユーザーガイドにてインプットフォーマットが定められています。
インプットとして準備が必要な必要なデータは
-
features(説明変数) -
label(目的変数)
の2つです。
Treasure Dataではテーブルの形で用意するので、上記2カラムのテーブルを準備することとなります。
繰り返しですが、上記は回帰や分類のタスクで必要なデータフォーマットであり、それ以外(リコメンドや異常検知)のタスクでは異なるデータを準備する必要があります。
featuresの準備
features(説明変数)については、配列の形で準備する必要があります。
通常、説明変数には複数の変数(場合によっては100を超える)を使うと思いますが、すべて配列化して1カラムに投入します。
さらに配列の中身は、インデックス:値というフォーマットである必要があります。
インデックスは数値でも文字列でもOKのようです。
- インデックスが数値の例)
["1:3.4", "2:0.5", "3:0.231"] - インデックスが文字列の例)
["height:1.5", "length:2.0"]
上記のインデックスフォーマットを準備するための関数featureがあるので、これを利用しましょう。
この部分は、下記サイトを参考にさせて頂きました。
Treasure Dataのhivemallで類似ユーザレコメンドを試す
select
user_id
, ARRAY(FEATURE(1,変数1),
FEATURE(2,変数2),
FEATURE(3,変数3),
FEATURE(4,変数4),
FEATURE(5,変数5),
FEATURE(6,変数6),
FEATURE(7,変数7)
) as features
, label
from
テーブル名
上記を実行するとこんな感じになります。
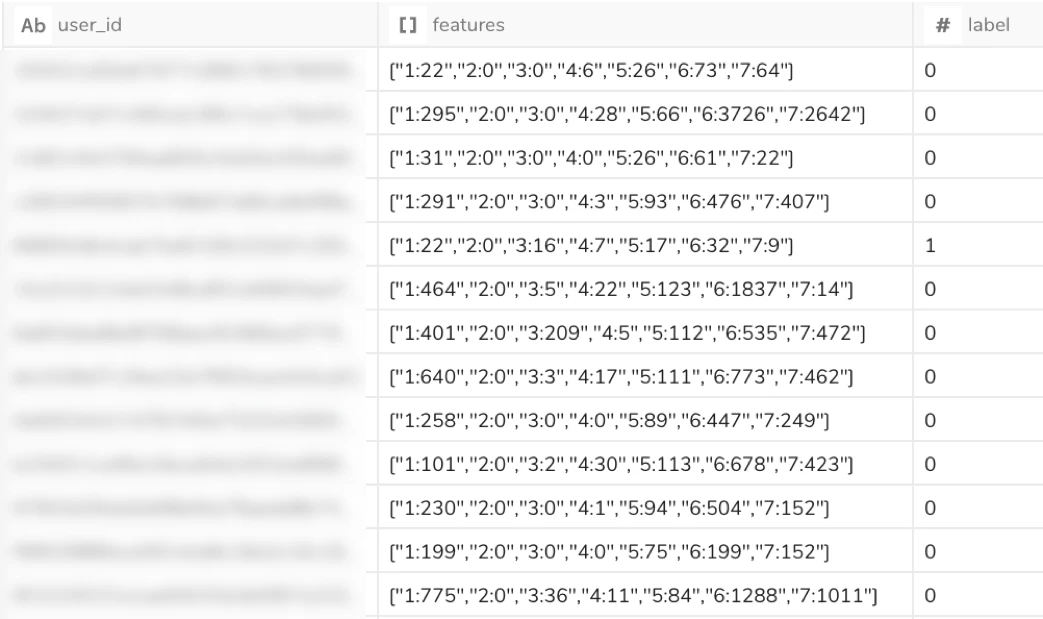
さて、これで機械学習を実行する準備ができました。
ここからは、個別の分析手法について見ていきます。
*本来は、さらにデータの前処理をする必要がありますが、まずは機械学習を回してみましょう。
(例えばデータの正規化とか ⇒Feature Scalingはなぜ必要?)
Treasure Dataで実行できる主要な機械学習
回帰(Regression)
train_arow_regrという関数が用意されています
SELECT
feature,
argmin_kld(weight, covar) as weight
FROM (
SELECT
train_arow_regr(features,label) as (feature,weight,covar)
FROM
training_data
) t
GROUP BY feature
上記を、最初に準備したデータセットに対して実行するとこんな感じです。
各変数の重み(回帰係数)が算出されました。
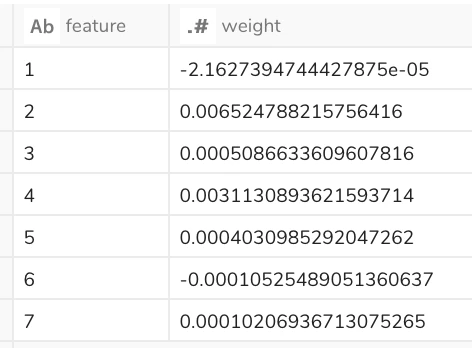
(回帰の決定係数や残差も出せるかな?と思ったのですが、算出する方法がわからなかったので、ご存知の方がいらっしゃったらご教示頂ければ幸いです。)
ちなみに、単回帰分析であれば、わざわざHivemallを使わなくとも、Prestoで実現可能なようです。
⇒Prestoで単回帰分析を行う
2値分類(Binary classification)
train_classifier関数が用意されています。
訓練
--WITH classification_model as ( ←予測のときに使います
select
feature,
avg(weight) as weight
from (
select
train_classifier(
add_bias(features), label,
"-loss logistic -iter 30"
) as (feature,weight)
from
a9a_train
) t
group by feature;
--)
↓こちらが実行結果です。変数6を特に重く評価するモデルができあがりました。
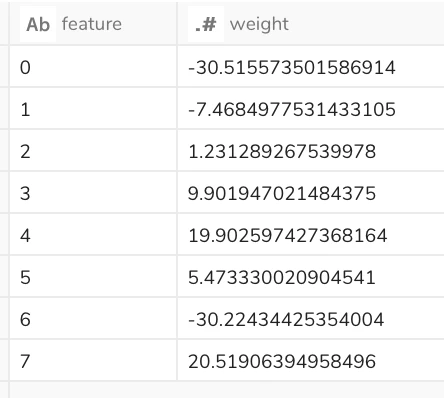
続いて、上記のモデルをテストデータに適用して、labelを予測してみます。
予測
WITH test_exploded as (
select
rowid,
label,
extract_feature(feature) as feature,
extract_weight(feature) as value
from
a9a_test LATERAL VIEW explode(add_bias(features)) t AS feature
),
--predict as ( ←評価の時に使います
select
t.rowid,
sigmoid(sum(m.weight * t.value)) as prob,
(case when sigmoid(sum(m.weight * t.value)) >= 0.5 then 1.0 else 0.0 end)as label
from
test_exploded t
LEFT OUTER JOIN classification_model m
ON (t.feature = m.feature)
group by
t.rowid
--)
↓実行結果はこちらです。probが「その人がどの程度label=1でありそうか?」を示すスコアです。(1に近いほど、label=1である可能性が強いと予測されている)
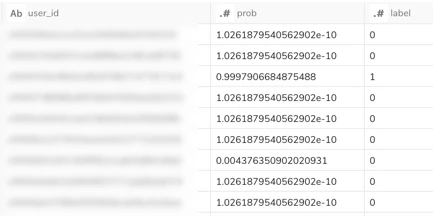
さて、予測はできましたが、このモデルは実際正確に予測できているのでしょうか?
次は予測精度を評価してみましょう。
評価
WITH submit as (
select
t.label as actual,
p.label as predicted,
p.prob as probability
from
a9a_test t
JOIN predict p
on (t.rowid = p.rowid)
)
select
sum(if(actual = predicted, 1, 0)) / count(1) as accuracy
from
submit;
↓実行結果です。予測したラベルと、テストデータの実際のラベルの一致度が算出されます。
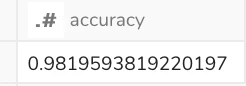
* * *
ちなみに、logress関数も、ほぼ同様の動きをするようです。
logress関数については、以下記事で詳細が解説されていますので、こちらをご参照ください。(当記事よりも遥かに詳細かつわかりやすいです。。。)
ユーザーガイドによると、train_classifierもlogressもさほど精度は変わらないとのこと。
However, at the same time, the options -loss logloss -opt SGD -reg no for train_classifier indicates that Hivemall uses the generic classifier as logress. Hence, the accuracy of prediction based on either logress and train_classifier would be (almost) same under the configuration.
ランダムフォレスト(RandomForest)
train_randomforest_classifier 、train_randomforest_regressorなど複数の関数が用意されています。
ランダムフォレストについては、詳細な別記事がいくつかありますので、そちらをご紹介するにとどめます。
TRAIN_RANDOMFOREST_CLASSIFIER() 関数では-treesで決定木の数、-attrsでは各説明変数が[Q:量的]か[C:質的]かどうかを明示する必要があります。
Hive
SELECT
TRAIN_RANDOMFOREST_CLASSIFIER(features, label, "-trees 500 -attrs C,C,C,Q,Q,Q,C,Q,C,C")
FROM
train
- [Hivemall を利用した機械学習実践入門(Random Forestによるドラッグストアのセールス予測)](
https://tug.red/entry/2016/03/29/hivemall_kaggle_rossmann_1/)
>ここでは、UNION ALL句を用いることで並列で決定木の学習を行っています。“-attr”オプションには変数が質的変数なものにはC、量的変数にはQを指定します
>```sql:
SELECT
-- C: Categorical Variable, Q: Quantitative Variable
train_randomforest_regr(features, label, '-trees 20 -attrs C,C,C,C,C,C,C,C,C,C,C,C,C,C,C,C,Q')
FROM
training3
UNION ALL
SELECT
train_randomforest_regr(features, label, '-trees 20 -attrs C,C,C,C,C,C,C,C,C,C,C,C,C,C,C,C,Q')
FROM
training3
--(以下略)
test2テーブルとmodelテーブルをHivemallで用意された”tree_predict”関数に与えることで、LTVの予測値を取得することができます。複数の決定木で推測された値の平均をLTVの予測値とします
Hive
SELECT
member_id,
EXP(predicted)-1 as predicted,
ltv
FROM(
SELECT
member_id,
avg(predicted) AS predicted,
avg(ltv) AS ltv
FROM(
SELECT
t.member_id,
tree_predict(p.model_id, p.model, t.features, false) as predicted
t.ltv
FROM
model p
LEFT OUTER JOIN test2 t
) t1
group by
member_id
) t2;
## リコメンド(Recommendation)
調べた中では、
- `minhash`
- `train_mf (train_mf_sgd)`
- `train_slim`
- `協調フィルタリング`
の4つが使えそうです。
`minhash`については、こちらのサイトにて詳細解説されています。
[HivemallでMinhash!〜似てる記事を探し出そう。〜](http://yebisupress.dac.co.jp/2015/06/26/hivemall-minhash/)
ただし、上記記事の筆者も仰られていますが、きちんと精度の高いリコメンドをしたい場合は、`train_mf`の方が適しているようです。
>```sql:Hive
select
minhash(id, words, "-n 100") as (clusterId, rowid) –"’-n 100’は100個hash関数を使うためのオプション"
from
news20;
そのtrain_mfについてはこちら。
HivemallでMatrix Factorization(まだ観ていない映画のリコメンド)
Hive
select
train_mf_sgd(userid, movieid, rating, "-factor ${factor} -mu ${mu} -iter ${iters}") as (idx, u_rank, m_rank, u_bias, m_bias)
from
training
`train_slim`, `協調フィルタリング`については、日本語の記事が見つからなかったので、ユーザーガイドをご参照下さい。
- [train_slim]((https://hivemall.incubator.apache.org/userguide/recommend/movielens_slim.html))
>```sql:ユーザーガイドより
select
i, nn, avg(w) as w
from (
select
train_slim(i, r_i, knn_i, j, r_j) as (i, nn, w)
from (
select * from slim_training_item
CLUSTER BY i
) t1
) t2
group by i, nn
-
協調フィルタリング
(一発で実現する関数はなく、コサイン類似度とeach_top_kを組み合わせ)
私は、リコメンドといえば協調フィルタリングをまず想起するのですが、Treasure Dataでやろうとすると意外と手間がかかりそうです。
ユーザーガイドより
--実際のクエリはめちゃくちゃ長いので一部を転記
WITH similarity as (
select
o.itemid,
o.other,
cosine_similarity(t1.feature_vector, t2.feature_vector) as similarity
from
cooccurrence o
JOIN item_features t1 ON (o.itemid = t1.itemid)
JOIN item_features t2 ON (o.other = t2.itemid)
),
topk as (
select
each_top_k( -- get top-10 items based on similarity score
10, itemid, similarity,
itemid, other -- output items
) as (rank, similarity, itemid, other)
from (
select * from similarity
where similarity > 0 -- similarity > 0.01
CLUSTER BY itemid
) t
)
## 異常検知(Anomaly detection)
そもそも異常検知には、大きく2つのやり方があるらしいです。
- タイプ1: Outlier(外れ値)
- タイプ2: Change point(変化点)
- (⇒タイプ2のうち、特に時系列の変化に特化したものをタイプ3とする場合もあり)
ちなみにこちらの記事によると⇒[Yahoo!の異常検知フレームワーク"EGADS"](https://takuti.me/ja/note/yahoo-egads/)
>(Change-pointと)Outlierとの違いは、Change-pointはもっと大域的かつ中長期的な変化を発見する点
とのこと。
要は、
- Outlier
- 局所的な異常検知(PVだったら、特定の記事がバズって1日だけスパイクした場合を検知)
- Change Point
- より大局的な変化を検知(Googleの検索アルゴリズムが変わって、PV数のトレンドが変わったポイントを検知)
っていうイメージですかね。
Hivemallにも`Outlier(外れ値)`、`Change Point(変化点)`の両方の関数が用意されています。
### Outlier(外れ値)
以下のようなクエリで、平均からのユークリッド距離が遠いデータを洗い出すようです。
([ユーザーガイドはこちら](https://hivemall.incubator.apache.org/userguide/anomaly/lof.html))
```sql:ユーザーガイドより
select
each_top_k(
-${k}, t1.rowid, euclid_distance(t1.features, t2.features),
t1.rowid,
t2.rowid
) as (rank, distance, target, neighbour)
from
train_normalized t1
LEFT OUTER JOIN train_normalized t2
where
t1.rowid != t2.rowid
Change Point(変化点)
変化点の検知にはsstという関数が用意されています。
(Singular Spectrum Transformationの略)
SELECT
num,
sst(value, "-threshold 0.005") AS result
FROM
timeseries
ORDER BY num ASC
特に時系列のChange Pointを検知したい場合には、changefinderという関数が用意されています。
Changefinderの仕組みについてはこちらを参照
⇒changefinderとはなにかを数式なしで解説
SELECT
num,
changefinder(value, "-outlier_threshold 0.03 -changepoint_threshold 0.0035") AS result
FROM
timeseries
ORDER BY num ASC
;
まとめ
Treasure Dataの機械学習についてまとまった日本語のドキュメントがなかったので、ひとまず主要なものを列記しました。
随時、実際に動かしてみた内容も別記事で追記していきたいと思います。