本記事は、Spark, SQL on Hadoop etc. Advent Calendar 2014の8日目の記事だったはずの原稿です。
Movielensデータセットを使って、HivemallにおけるMatrix Factorizationの実行方法を解説します。
はじめに
以前、Hadoop Conference 2014で発表させて頂いたときに聴衆の方にアンケートをとったところレコメンデーションの需要が(クラス分類か回帰分析と比べて)非常に高いという傾向がありました。Hivemallのv0.3以前もminhashやk近傍法を用いたレコメンデーション機能をサポートしておりましたが、v0.3からはMatrix Factorizationもサポート致しました。
本記事では、HivemallにおけるMatrix Factorizationを用いた評価値の予測方法を紹介します。
Matrix Factorizationとは
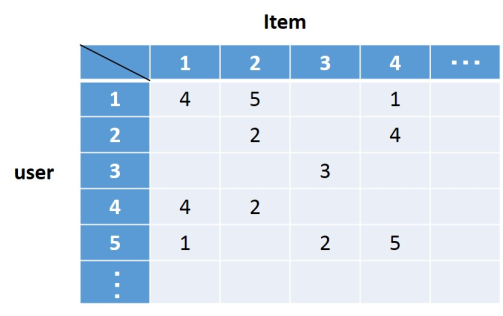
$n_{u}$人のユーザの$n_{i}$個の各商品に対する$n_{u}\times n_{i}$の評価値行列$R$を想定下さい。
Matrix Factorizationでは評価値行列$R$を$n_{u} \times k$のユーザ行列$P$と$k \times n_{i}$の商品行列$Q$を用いて以下のように近似します。
R \approx P^{T}Q
図で示すと次のような形です。
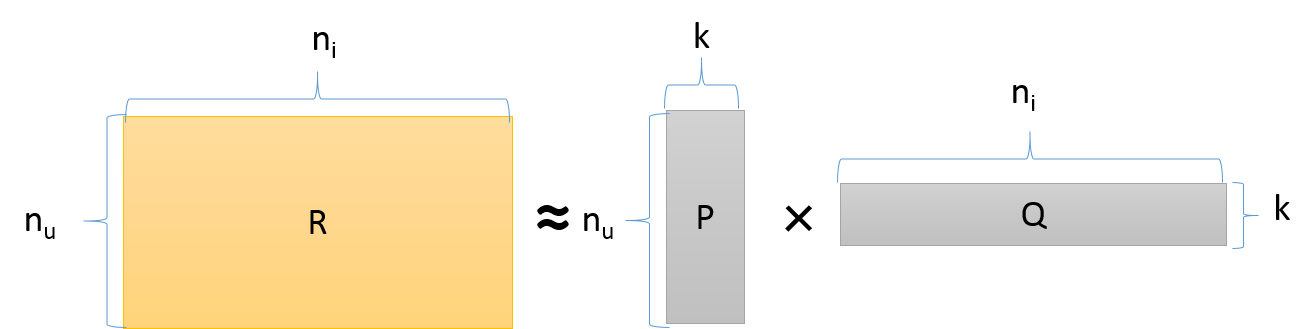
つまり、$k$個の潜在因子によって各ユーザ$P_{u}$および各商品$Q_{i}$が特徴付けされます。
ここで、ユーザ$u$に対する商品$i$の予測評価値$R_{ui}$は、$\overrightarrow{P_{u}}^{T}\overrightarrow{Q_{i}}$を介して求めることができます。
より詳しいMatrix Factorizationの解説は、他の方の記事12を参照下さい。
バイアスを考慮した Matrix Factorization
Matrix Factorizationのアルゴリズムにも様々ありますが、HivemallではKorenらによるバイアスを考慮したMatrix Factorization手法(以下,BiasedMF)3の確率的勾配降下法(およびAdaGrad)による実装をサポートしております。
BisedMFの予測モデルでは、評価の平均$\mu$、ユーザごとの評価バイアス$B_{u}$、商品ごとの評価バイアス$B_{i}$を考慮した上で評価値$R^{'}_{ui}$を予測します。
R^{'}_{ui} = \mu + B_{u} + B_{i} + \overrightarrow{P_{u}}^{T}\overrightarrow{Q_{i}}
学習では、以下の式を満たす$P$, $Q$および$B$を訓練データから導きます。
min_{P,Q,B} \sum_{(u,i) \in R}{(R_{ui}-R^{'}_{ui})^{2} + \lambda ({||B_{u}||}^{2} + {||B_{i}||}^{2} + {||\overrightarrow{P_{u}}||}^{2} + {||\overrightarrow{Q_{i}}||}^{2}})
第2項の$\lambda$は、教師データへの過剰適合(過学習)を防ぐための正則化係数です。誤差最小化の目的関数に正則化項を取り入れることで汎化性能(未知のデータへの識別性能)のあるモデルが学習されます。
なお、$\mu$にあてずっぽうな値を指定した場合や設定しない($\mu=0$)でも学習自体は可能です。
Movielens 1M Datasetの準備
今回はこちら2のSpark MLlibでの検証と比較しやすいように、MovieLens 1Mを使用します。
6,040人のユーザがそれぞれの映画を1~5の5段階評価しているデータセットで評価数は約100万(1,000,209)件です。
まず、次のようにHiveの外部テーブルを定義しましょう。
create database movielens;
use movielens;
CREATE EXTERNAL TABLE ratings (
userid INT,
movieid INT,
rating INT,
tstamp STRING
) ROW FORMAT DELIMITED
FIELDS TERMINATED BY '#'
STORED AS TEXTFILE
LOCATION '/dataset/movielens/ratings';
テーブルにデータを投入します。sedで加工してからHDFSの指定のパスにデータを投入します。
sed 's/::/#/g' ratings.dat | hadoop fs -put - /dataset/movielens/ratings/ratings.t
訓練データ/テストデータの作成
ここでは、ランダムに選択した8割を訓練データ、残りの2割をテストデータとして利用します。
training/testingテーブルをそれぞれ次のように作成します。
SET hivevar:seed=31;
CREATE TABLE ratings2
as
select
rand(${seed}) as rnd,
userid,
movieid,
rating
from
ratings;
CREATE TABLE training
as
select * from ratings2
order by rnd DESC
limit 800000;
CREATE TABLE testing
as
select * from ratings2
order by rnd ASC
limit 200209;
確率的勾配降下法を用いたオンライン学習では、学習データをランダムにシャッフルしておくことが重要です。
シャッフルにはHiveのCLUSTER BY構文を利用したCLUSTER BY rand()も有用です。
学習のパラメタの設定
ここでは、学習に利用するパラメタを3つ設定します。
これらのパラメタはオプションに指定しなくてもデフォルト値が利用されて動きますが、設定することをおすすめしています。
-- 1) mean rating
set hivevar:mu=3.593565;
-- 2) number of factors
set hivevar:factor=10;
-- 3) maximum number of training iterations
set hivevar:iters=50;
- 一つ目の$muは、トレーニングデータの評価値の平均値です。
select avg(rating) from training;
で平均値を求めた上で設定下さい(この例では、$mu=3.593565)。
-
$factorには潜在因子の数を指定します。ここでは、$factor=10とします。
-
$itersにはそれぞれの(map)タスクにおける学習の最大イテレーション回数を指定します。
ここでは、最大50イテレーションを指定します。経験ロスの変化の割合から学習が収束したと判断された場合は学習を終了します。
Matrix Factorizationの学習
train_mf_sgdユーザ定義テーブル生成関数を用いて、次のようにモデルを構築します。
train_mf_sgdの第4引数で学習に利用するパラメタを指定します。
create table sgd_model
as
select
idx,
array_avg(u_rank) as Pu,
array_avg(m_rank) as Qi,
avg(u_bias) as Bu,
avg(m_bias) as Bi
from (
select
train_mf_sgd(userid, movieid, rating, "-factor ${factor} -mu ${mu} -iter ${iters}") as (idx, u_rank, m_rank, u_bias, m_bias)
from
training
) t
group by idx;
作成される予測モデルテーブルの形式は次のとおりです。
hive> desc sgd_model;
idx int
pu array<float>
qi array<float>
bu double
bi double
関係モデルとの親和性を考慮して、予測モデルはベクトルのidxごとにタプルとして表現しています。
ここで、$P_{u}$および$Q_{i}$は$factorで指定した要素数を持ちます。
評価値の予測
テストデータに対して、$P_{u}, B_{u}$および$Q_{i}, B_{i}$をLEFT JOINによって結合します。
その上で、mf_predict関数を利用して予測評価値を得ます。
select
t2.actual,
mf_predict(t2.Pu, p2.Qi, t2.Bu, p2.Bi, ${mu}) as predicted
from (
select
t1.userid,
t1.movieid,
t1.rating as actual,
p1.Pu,
p1.Bu
from
testing t1 LEFT OUTER JOIN sgd_model p1
ON (t1.userid = p1.idx)
) t2
LEFT OUTER JOIN sgd_model p2
ON (t2.movieid = p2.idx);
アイテムの推薦(レコメンド)
userid=1のユーザに、ユーザがまだ評価していない$topk個の映画を推薦する場合は次のようなクエリを用います。
set hivevar:userid=1;
set hivevar:topk=5;
select
t1.movieid,
mf_predict(t2.Pu, t1.Qi, t2.Bu, t1.Bi, ${mu}) as predicted
from (
select
idx as movieid,
Qi,
Bi
from
sgd_model p
where
p.idx NOT IN
(select movieid from training where userid=${userid})
) t1 CROSS JOIN (
select
Pu,
Bu
from
sgd_model
where
idx = ${userid}
) t2
order by
predicted DESC
limit ${topk};
ここでは、t1で求める未評価の映画の特徴量とt2で求めるユーザの特徴量から映画の評価値を予測しています。
| movieid | predicted |
|---|---|
| 318 | 4.8051853 |
| 2503 | 4.788541 |
| 53 | 4.7518783 |
| 904 | 4.7463417 |
| 953 | 4.732769 |
なお、SQLのNOT IN句はHive v0.13以降からサポートされた機能であることにご注意下さい。NOT INはJOINとIS NULLで表現することが可能ですので、古いバージョンのHiveではJOINとIS NULLを使ったクエリを代用下さい。
アイテムではなく、ユーザの推薦も上記のクエリを読み替えることで可能です。
評価
MAE(Mean Absolute Error)およびRMSE(Root Mean Squared Error)を利用した評価は次のように行います。
それぞれ予測評価値が実際の評価値からどれくらい離れているかの尺度で、小さい方が予測精度が高いものとなります。
select
mae(predicted, actual) as mae,
rmse(predicted, actual) as rmse
from (
select
t2.actual,
mf_predict(t2.Pu, p2.Qi, t2.Bu, p2.Bi, ${mu}) as predicted
from (
select
t1.userid,
t1.movieid,
t1.rating as actual,
p1.Pu,
p1.Bu
from
testing t1 LEFT OUTER JOIN sgd_model p1
ON (t1.userid = p1.idx)
) t2
LEFT OUTER JOIN sgd_model p2
ON (t2.movieid = p2.idx)
) t;
0.6728969407733578 (MAE)
0.8584162122694449 (RMSE)
なお、平均絶対誤差(MAE)の定義は次のとおりで、(予測値と実際の値の)誤差の絶対値の平均です。
\mathrm{MAE} = \frac{1}{n}\sum_{i=1}^n \left| f_i-y_i\right| =\frac{1}{n}\sum_{i=1}^n \left| e_i \right|
交差検定 (10-fold cross validation)
ここでは、交差検定4により予測性能の評価を行います。
今回は学習データ : 評価データを9 : 1 で分割し、10-foldの交差検定を行った上でMAE/RMSEで評価します。
交差検定用のデータセットの準備
次のようにkfold=10を指定して、元のデータセット(ratingsテーブル)に交差検定用のグループID(gid)を加えたテーブルを作成します。
set hivevar:kfold=10;
set hivevar:seed=31;
-- Adding group id (gid) to each training instance
drop table ratings_groupded;
create table ratings_groupded
as
select
rand_gid2(${kfold}, ${seed}) gid, -- generates group id ranging from 1 to 10
userid,
movieid,
rating
from
ratings
cluster by gid, rand(${seed});
学習用パラメタの設定
-- latent factors
set hivevar:factor=10;
-- maximum number of iterations
set hivevar:iters=50;
-- regularization parameter
set hivevar:lambda=0.05;
-- learning rate
set hivevar:eta=0.005;
-- conversion rate (if changes between iterations became less or equals to ${cv_rate}, the training will stop)
set hivevar:cv_rate=0.001;
$lambdaは正則化のパラメタ、$etaは学習率、$cv_rateは学習の収束を判定するためのTHRESHOLD(イテレーションを重ねても0.1%以下の変化ならば収束したと見なす)になります。
$muには正確でない値でも構いませんが、サンプリングなどを用いて平均的な値を指定してください(例えば5段階で3)。
select avg(rating) from ratings;
3.581564453029317
-- mean rating value (Optional but recommended to set ${mu})
set hivevar:mu=3.581564453029317;
Cross Validation用のクエリの自動生成と実行
generate_cv.shを実行するとgenerate_cv.sqlが生成されます。
generate_cv.sqlを実行するとMAEとRMSEが結果として返ります。
0.6695442192077673 (MAE)
0.8502739040257945 (RMSE)
交差検定用のクエリは多くのmap/reduceタスクを必要としますのでApache Tezを利用した実行をおすすめします。私の32ノードのHadoopクラスタのHive(Tez)環境では、並列にタスクが実行されて約45秒でJOBが終了しました。
実際に何をやっているかはgenerate_cv.sqlを確認ください。
ほかのデータセットに交差検定を適用するときは、generate_cv.shを編集頂くことになります。
さいごに
Movielens 1Mでは、Spark MLlibのALS-WR2とは誤差最小化の目的関数や最適化方法が異なりますが、同等の予測性能となりました。
HivemallのMatrix Factorizationはノード間のパラメタ交換をまだ行っていないので改善余地のある機能です。
ご自身の手で試していただき、フィードバックなりPull requestを頂ければと思います。