この記事の立ち位置
- アイスタイル Advent Calendar 2016の4日目の記事です
- この記事は時系列データの分析、統計解析の事前知識がない方向けに、「changefinderとは何か?」を解説する記事です。
- 時系列データの基礎、詳細を知りたいという方は、沖本本などで
changefinder
概要
changefiderとは、変化点を検出するのに用いられるアルゴリスムの名前です。
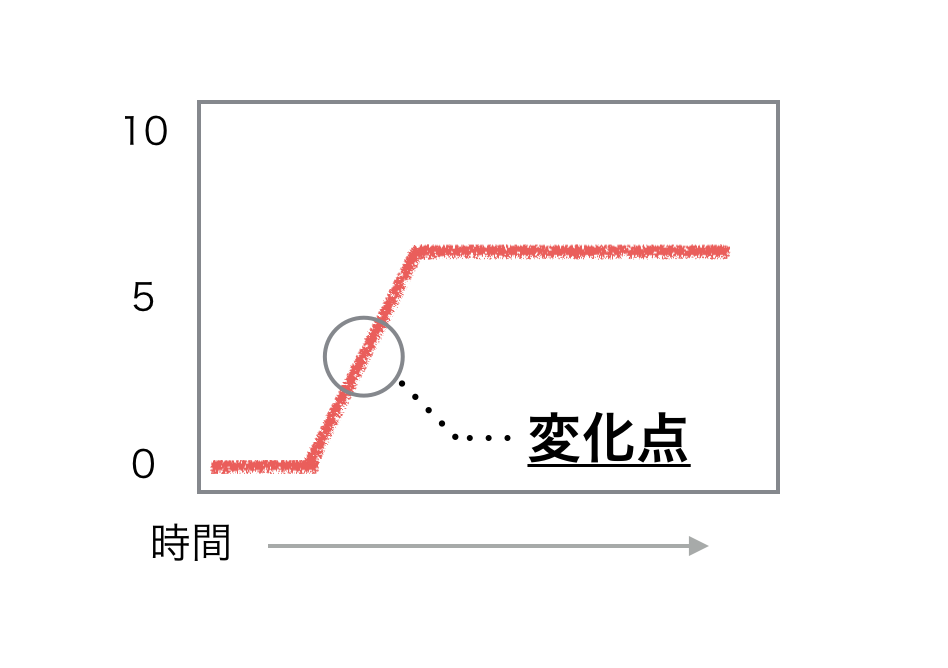
変化点とは、時間とともに変化するデータ(PVや温度など)の性質が変わる点です。
外れ値と何が違うの?となりますが、外れ値は一瞬だけ異常値が出た後は、元の数値に戻ります。
変化点は、その外れ値がデータの変化の点となり、元の数値に戻らずにずっーと続くイメージです。
モデル
スコアを算出するまでの流れは以下のようになります
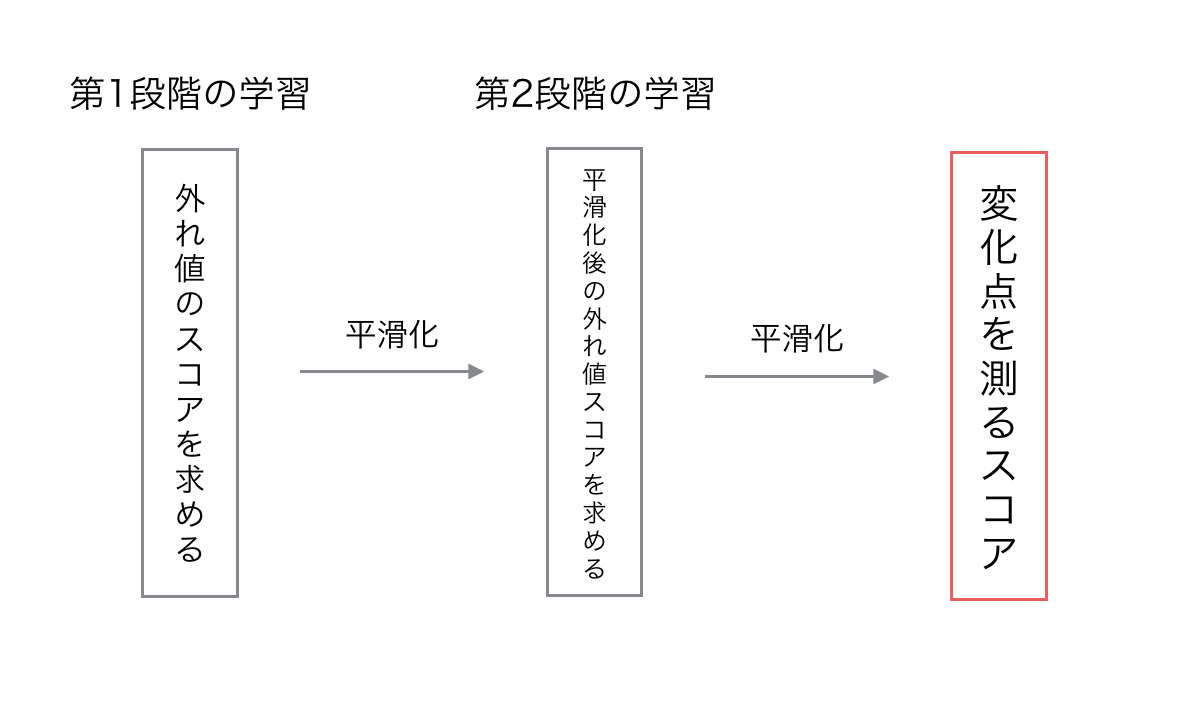
平滑化とは、ざっくり言いますと 「本当に変化にしている部分以外を取り除こうぜ!」 というノリで行われる処理です。スコアを求めるまでの、ざっくりとした流れは理解していただいたと思うので、各学習の部分を説明をします。
第1段階の学習について
(※ARMAモデルを使う選択肢もありますが、今回はARモデルを用いた場合の説明をします)
第1段階の「外れ値スコアを求める」で、使われているARモデルとは、時点Bでの値を算出する式を立てるときに、その前の時点Aの値に、何かをかけたり、足したりすることで、時点Bの値を算出できるようにしたモデルです。
なんでこんなことするかというと、時点Bの値の算出に、時点Aを用いているのだから、**何かしらの相関が出そうでモデル化できそうだよね!**って考えに基づいたモデルだからです。
このモデルで出した値と、実際のスコアがどれくらい異なるかを調べ、外れ値スコアを算出します。
第2段階の学習について
SDARモデルを用いて、第2段階の学習が行われます。このアルゴリズムは、名前にARという名前が入っている通り、先ほどのARモデルの改良版です。また、SDARモデルは忘却型学習アルゴリズムとも呼ばれています。
SDARモデルは、過去の統計量ほど重みを減らす、忘却パラメーターを採用しています。
このため、定常なデータにしか対応できないARモデルとは違い、非定常なデータにも対応できるようになっています。定常とは、過去の平均、自己共分散が、時間を通して、一定の状態であることを言います。
(※ここでいう定常とは、弱定常のことです)
そうして、SDARモデルを用いて算出した外れ値スコアを、また平滑化することで、変化点を測るスコアを算出します。