本記事はPostgreSQL on Kubernetes Advent Calendar 2018の17日目です。
昨日は「PostgreSQL on K8sの運用を考える(2) バックアップ・リストア」ということで、PostgreSQL on Kubernetesの計画停止とバックアップ・リストアの検証を行いました。
今日はちょっと趣向を変えて、PostgreSQL on Kubernetesの構成でDeploymentを使うとどうなるのかを見ていきます。
TL;DR
- Deploymentのspec.Strategyにtype:Recreateを設定するとStatefulSetに近い動きに。
- しかし、ノード障害時の動きなどは微妙に異なった。
- 同じPVがマウントされることが仕様なのか等も確認が必要。
DeploymentでつくるActive-Standby構成
第4回でご覧頂いたとおり、ここまで検証しているPostgreSQL on Kubernetesの構成はStatefulSetでPostgreSQLインスタンスを管理しています。その際にはレプリカ数を1とすることで、起動されるインスタンスは一つだけ、かつポッドの停止と起動をシーケンシャルに行うというStatefulSetの特徴を活かして、常に同じブロックデバイス(Cephが提供するRBD)をマウントしています。
これをDeploymentで構築するとどうなるでしょうか。
通常はDeploymentのポッド生成は並列で行われ、ポッドの停止・起動も同時に走ってしまうため、今回のようにReadWriteOnceのブロックデバイスをマウントする構成には向いていません。
しかし、Deploymentではspec.StrategyとしてRecreateを選べます。
これを設定した場合、全てのポッドを停止後に再作成するので、結果としてStatefulSetに近い動きになるのでは?と期待されます。
Deployment版PostgreSQL on k8sの構成
では、以下のような構成で障害時の動きを検証していきます。
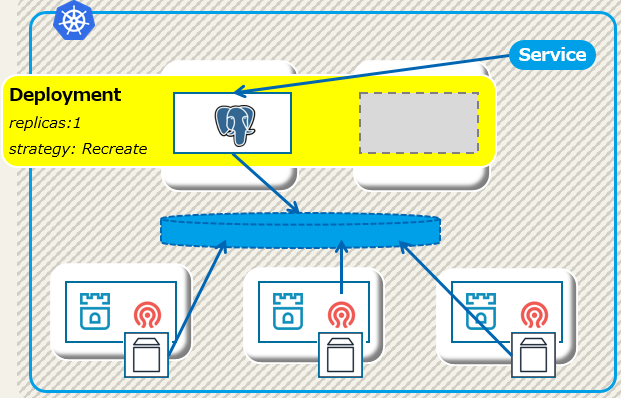
具体的にstrategyやreplicasは以下のように指定しています。
apiVersion: apps/v1
kind: Deployment
metadata:
name: pg-rook-ds
spec:
strategy:
type: Recreate
replicas: 1
※YAML全文はこちら。
検証ポイント
こちらの記事でも書いた検証ポイントから、DBノードとPostgreSQLポッドに関連するものだけ抜き出した下表が検証対象となります。
| 障害分類 | 障害部位 | 想定する動き |
|---|---|---|
| ノード | DBノード | サービス継続、PostgreSQLフェイルオーバ |
| ポッド | PostgreSQL | サービス停止、PostgreSQLポッド再起動 |
DBノード障害のケース
Deployment版の構成でもレプリカ数は1となるため、DBノードが停止した場合は待機系ノードでPostgreSQLインスタンスを再起動してほしいところですが、StatefulSetでは上手くいきませんでした。
今回もStatefulSetと同じ手順でテストをしていきます。
- pgbenchで3分程度のベンチマークを流す。※但し2.の時点で止まる。そこでサービス停止時間を計測。
- pg-rook-dsのポッドが稼動しているノードを停止。
- pg-rook-dsのポッドが別ノードでRunningとなることを確認。
- PostgreSQLのログから起動時間を確認。1.との差分でサービス停止時間を計測。
結論からいうと、StatefulSetの際と同じようにフェイルオーバの動きにはなりませんでしたが、中身は異なっていました。
何が起きたか
まず、ノードを停止した状態を確認します。
$ kubectl get node
NAME STATUS ROLES AGE VERSION
ip-172-31-15-58 NotReady worker 9d v1.10.5
ip-172-31-7-35 Ready worker 9d v1.10.5
この状態がしばらく続いた後にポッドの状態を確認したところ、以下のようにポッド再作成を試みていることが分かりました。
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
pg-rook-ds-d7b5c44cf-ghrmx 0/1 ContainerCreating 0 15s <none> ip-172-31-7-35
pg-rook-ds-d7b5c44cf-rwx7m 1/1 Unknown 2 53m 10.42.1.12 ip-172-31-15-58
上記でNotReadyとなっていたポッドはUnknownになっていますが、もう一つのノードでデプロイメントがポッドを作成している様子が見えます。しかし、このポッド生成は完了しません。
その理由はdescribe podのEventsを見てみると分かりました。
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 1m default-scheduler Successfully assigned pg-rook-ds-d7b5c44cf-ghrmx to ip-172-31-7-35
Normal SuccessfulMountVolume 1m kubelet, ip-172-31-7-35 MountVolume.SetUp succeeded for volume "default-token-kkgp2"
Warning FailedMount 1s (x8 over 1m) kubelet, ip-172-31-7-35 MountVolume.SetUp failed for volume "pvc-db25d0af-013d-11e9-83f0-02786407b9a8" : mount command failed, status: Failure, reason: Rook: Mount volume failed: failed to attach volume pvc-db25d0af-013d-11e9-83f0-02786407b9a8 for pod default/pg-rook-ds-d7b5c44cf-ghrmx. Volume is already attached by pod default/pg-rook-ds-d7b5c44cf-rwx7m. Status Running
CephのRBDマウントに失敗しています。理由も出力されており、既に別のポッド(Unknownになっているもの)にマウントされているからだ、となっています。
ポッドの強制削除をしてみると
状態はStatefulSetのDBノード障害時と異なるのですが、対応は同じように手動でのポッド強制削除になります。
$ kubectl delete pod pg-rook-ds-d7b5c44cf-rwx7m --force --grace-period=0
warning: Immediate deletion does not wait for confirmation that the running resource has been terminated. The resource may continue to run on the cluster indefinitely.
pod "pg-rook-ds-d7b5c44cf-rwx7m" force deleted
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
pg-rook-ds-d7b5c44cf-ghrmx 1/1 Running 0 4m 10.42.2.12 ip-172-31-7-35
これにより、必要なボリュームをマウントしていたポッドが消えたため、ContainerCreatingで止まってしまっていたポッドの起動に成功します。
当然ですが、同じボリュームがマウントされているため、データも保全されていてリカバリ処理も走っています。
まとめ
今回はPostgreSQL on KubernetesのDeployment版構成を検証してみました。ノード障害時の動きは基本的にStatefulSetと同じように見えましたが、細かい動きは異なっています。
ただ、気になるのはこれがDeploymentの仕様通りの動きなのか、です。
StatefulSetと異なり、同じPVをマウントするのが仕様ではない場合、この構成で使うのは適切ではありません。このあたりは後ほど調べてみたいと思います。
よろしくお願いします。