はじめに
July Tech Festa 2020において、「マイクロサービスの今だからこそ!理解して拡げる 分散システムの基礎知識」のタイトルで登壇をしてきました。スライドはこちらにありますが、資料内や当日のトークで話せていない部分を含めて、こちらでblogとして解説をしておきたいと思います。
1. セッションの導入 - 新たなムチャブリ -
今回は昨年の#JTF2019で私が話した、「Cloud Native開発者のためのDatabase with Kubernetes」からの続編という形にしてみました。
昨年は、
「せっかくKubernetesを使うのにアプリケーションだけじゃもったいない。
DB、そしてステートフルなワークロードにも適用していきましょう」
という話をしましたが、Kubernetes-native Testbedなど、そうした取り組みが増えつつある傾向にはとても興味を持っています。
今年はCloud Nativeな開発という観点から一歩踏み出して、マイクロサービス化というテーマに取り組んでみました。ただ、導入部分のおふざけが過ぎたという感じがあって、一番反応があったのがこのスライドという事態が発生してしまいました。
ネタスライド(?)がそこそこ受けてそうだったので良かった。 pic.twitter.com/8pMm4hGBC1
— こば(右)- Koba as a DB engineer (@tzkb) July 25, 2020
導入で言いたかったこと
本当は皆さんの記憶に残したかったのは、以下のことでした。
- マイクロサービス化により、アーキテクチャはモノリスの頃から大きく変わることになる。
- 一つの共有データベースから、サービス単位のデータベースに分割される。
- その時から長く苦しい分散トランザクションとの闘いが始まる。
- もちろん、データベースのスケーラビリティという古き長き闘いも続いていく。
そう今回のメインテーマは後半の2つ、「分散トランザクション」と「データベースのスケーラビリティ」なのです。
2. 分散トランザクションに取り組む - モノリスからマイクロサービスへ -
マイクロサービス化の目的を整理する
ここは先日のデブサミ2020夏で聞くことが出来た、グーグル・クラウド・ジャパン中井さんのセッションを参考にさせて頂きました。
私は「マイクロサービスを適切に設計できるアーキテクトです」とは、とても名乗れる立場にありませんが、DevOpsという観点と合わせてマイクロサービス化の目的を以下のように整理してみました。
- Devから見ると「コードベースに、適切なコントロールとアジリティを導入したい」
- Opsから見ると「アーキテクチャに、適切な拡張性と可用性を導入したい」
私はOpsに近い立場となりますので、今回のセッションでは**拡張性(スケーラビリティ)と可用性(アベイラビリティ)**を中心に、ここから先の説明を展開しています。
マイクロサービス≒分散システム
目的を整理したところで、このスライドで「マイクロサービスとはすなわち分散システムである」と主張しました。

これはSander Hoogendoornという方のセッションメモを参考にしていますが、私自身もこの意見に深く同意しています。
マイクロサービス≒分散システムという前提があって初めて、タネンバウム先生の「Distributed Systems」の内容と今回のセッションの内容が重なってきます。そうした意味で実は重要なスライドになっていました。
モノリスか?マイクロサービスか?
これはセッション中にも話しましたが、実は現場で「このシステムはモノリスです」と明言するのは簡単なことではありません。
「マイクロサービス=良い、モノリス=悪い」というイメージが先行しており、歴史あるレガシーな現場であっても、新しめのCloud Nativeな現場であっても、モノリスだと言われることを喜ぶ人は殆どいません。
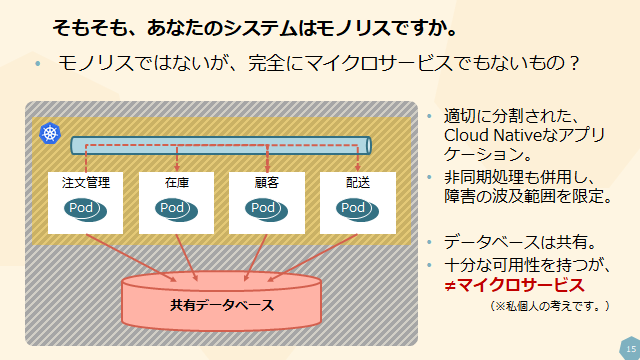
そのため、今回はモジュールがある程度分割されていて一部では非同期連携のような仕組みを導入していたとしても、共有データベースでかつそこが拡張性のネックとなってしまっている構成は、マイクロサービスではありませんと主張しています。
データベースの分割、そして分散トランザクションとの闘い
先述したようなモノリス(つまりマイクロサービスではないもの)を、共有データベースではなく、Database per Serviceにして、同時にKafkaを導入してサービス間の疎結合を実現した構成をこのスライドでは示しました。
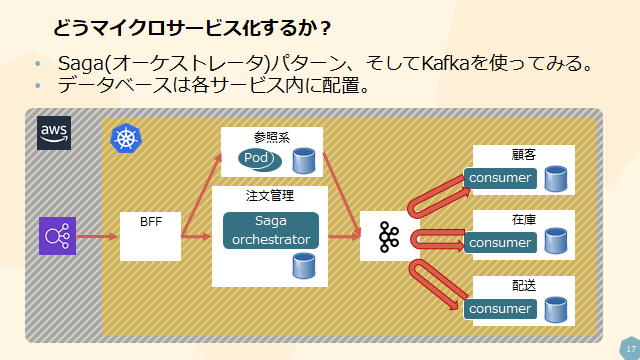
そして、分散トランザクションはSagaパターンにより実現しています。
このスライドについては、社内でマイクロサービスの優秀なアーキテクトにヒアリングした後に作成しており、実は私自身が語るべきことは多くありません。
もしSagaに関して詳細に知りたいという方は、「ACID Is So Yesterday: Maintaining Data Consistency with Sagas」という素晴らしい資料がありますので、こちらをご覧ください。また、Microsoftで公開している分散データに関するドキュメントも大変参考になりました。
CQRS、そしてAtomic Visibility
分散トランザクションの補足として、SagaトランザクションではACIDのうち、ACDは担保できるもののI(Isolation)は実現できないということを述べました。この考えも先ほどのSagaの解説資料2つで触れられています。
各サービスでローカルなトランザクションを、Sagaトランザクションの単位で如何にAtomicに見せるかという方法を2つ、セッション中では示しました。CQRS自体は最近良く聞く概念ですが、もう一方のAtomic Visibilityについては、こちらに論文著者による解説スライドがあります。
なお、289枚という超大作ですので読む際には時間と気合を忘れずに。
3. Size & Geographical Scalability - それでも残る課題 -
前節で述べたSaga等を使って適切なマイクロサービスが設計できたとしても、システムに残る課題として、スケーラビリティを考えていきます。つまり、極論すれば、
「あなたのマイクロサービスは、本当にスケーラブルですか?」
ということです。
マイクロサービスは自明にスケーラブルではない
ここでの主張はシンプルです。
たしかにサービスを小さく分割することで、各サービス自体の処理量は減少するかもしれません。また、ステートレスなアプリケーションはコンテナなどを利用して水平スケールさせることが可能でしょう。
ただ、データベースはそうは行きません。
システム全体への流量が増え、特定のサービスに負荷が集中した際にそれを支えるローカルなデータベースのスケールは簡単ではないのです。
データベース拡張手法の整理
ここではタネンバウム先生のいう2つの軸、SizeとGeographicalという観点で既存のデータベース拡張手法を整理しています。
Size、つまり量的な拡張の方法については以前blogにまとめています。
「2020年のNewSQL -3.1.1 RDBMSはスケーラビリティがない?」で述べたように、以下の手法が比較的容易に利用できます。
- レプリケーション (=Single Leader Replication)
- Sharding (e.g. Vitess、Citus)
- マルチマスター (e.g. Oracle Real Application Cluster)
もう一軸のGeographical、つまり地理的な拡張については、これまで私がお話することはなかった部分です。一言でいえば、DRサイトの考え方になります。
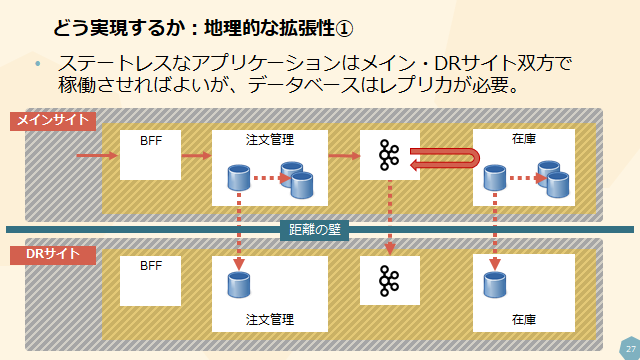
マイクロサービス化されたシステムをDRサイトでもう一面立ち上げ、災害発生時には切り替えられるように、と言われた際のことを想定した構成が上図となります。
もちろんこれが唯一解ではないでしょう。上図ではデータの複製がメインサイトからDRサイトへの一方通行になっていますが、これを双方向にして、メインとDR双方がActive-Activeになる構成も可能なはずです。
但し、その場合にはデータベースに求められる要件は一方通行よりも更に複雑となります。両サイトでの完全なマルチマスター、そしてデータ更新の衝突を回避・解決する手段が必要になってきます。
プロプライエタリなDBを用いた地理的拡張性の実現
セッション中ではこうした地理的拡張性を満たすための方法として、OracleのActive Data Guardを紹介しました。
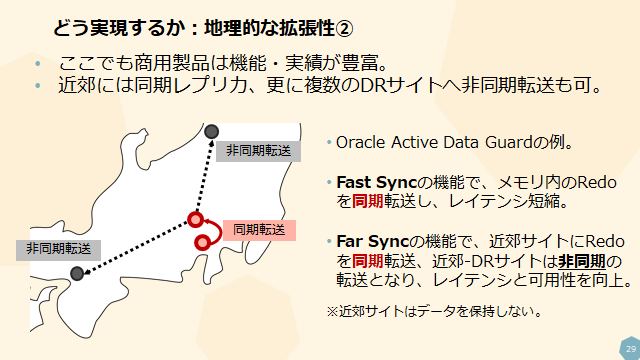
このオプションは高機能で信頼性が高く、エンタープライズの大規模システムで豊富な実績があります。
そして、このスライドで紹介しているFar Syncの考え方は、遠距離へのデータ複製時の同期転送と非同期転送のバランスを上手くとったやり方として、参考になる部分が多いです。
おそらく、他のプロプライエタリな製品でも似た機能はあると思うのですが、私自身がOracleの経験が多いことから今回は上記1製品のみの説明としています。
4. 真にスケーラブルなDBを求めて
今回のセッションでは、2章でマイクロサービスにおける分散トランザクションの解決方法を、3章でマイクロサービスにおけるローカルDBの拡張手法を、それぞれ整理してきました。ただ、それだけではこのセッションの価値、特に新規性の部分が欠落しています。
最終章となる4章では、私が最近関心をもって追い続けているデータベースのイノベーション、いわゆるNewSQLを用いて、これまで提示した課題をより効果的に解決する方法を提案しています。
※なお、当セッション自体ではあえて「NewSQL」の単語は用いていません。そこが主題ではないためです。
Google Cloud Spannerを拡張性観点で捉える
タネンバウム先生が言及した、SizeとGeographical両方の観点で真の拡張性を満たすデータベースがGoogle Cloud Spannerです、という話をしました。
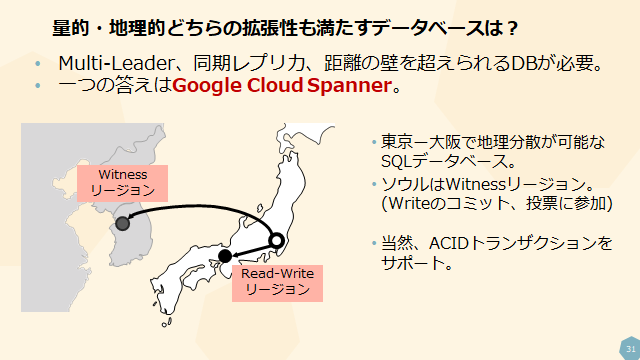
Spannerを用いることでMulti-Leader、同期レプリカに近い可用性、そして十分な距離での地理分散が可能となります。上図では東京―大阪―ソウル(Witness)を用いた国内でも使えるDR構成を示しています。
この辺りの詳細が知りたい方は、Spannerのマルチリージョンに関するドキュメントをお読みください。
分散SQLデータベースの仕組み
Spannerやそれに類似したNewSQLのデータベースで用いられる、合意ベースのレプリケーションについても解説しています。
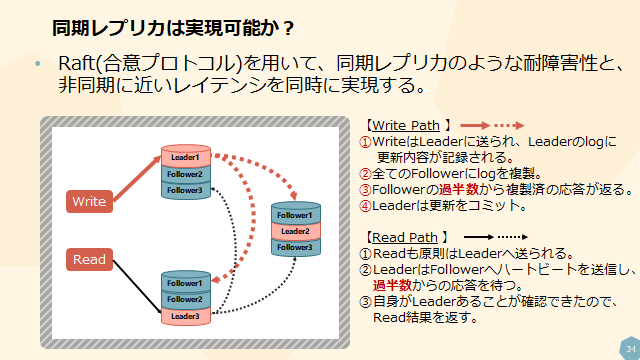
上図よりも以前書いた「NewSQLのコンポーネント詳解 - 4.3 Raft」の方が詳しく解説をしておりますので、興味がある方は是非そちらをご覧ください。
当日質問があった、Readに関する最適化についても上のblogで解説しています。
こんな質問が来てました。
— こば(右)- Koba as a DB engineer (@tzkb) July 25, 2020
「Raft における Read Path のハートビート処理は Read 処理毎に毎回行われるのでしょうか?(毎回過半数からの応答が無いとクライアントに結果を返せないのでしょうか?)」
せっかくなので、ここで回答しますね。
これまで合意ベースの分散DBで述べていなかった点
今回のセッション中では、Single Leader Replicationなどの仕組みと比較した、合意ベースの分散DBの重要な特徴をいくつか説明しています。
Single Leader Replication(PostgreSQLのStreaming Replicationなど)では、データの複製方法として同期と非同期が選択可能ですが、どちらにもメリット・デメリットがあります。
- 同期レプリケーションをすれば、データ損失は防げるが、セカンダリ(レプリカ先)がダウンした際にプライマリ(レプリカ元)も停止し得る。また、レイテンシも非同期と比較して遅延する。
- 非同期レプリケーションでは、データ損失を防げないケースがあるが、セカンダリの障害はプライマリに影響しない。
これらの良い所どりを目指しているのが合意ベースの分散DBであり、以下のようなメリットがあります。
- 過半数からの応答でデータをCommitでき、全体としては同期レプリカと見なせる。
- 一部ノードがダウンしていても過半数の投票が満たせれば、障害とはならない。
- 全てのノードからの応答を待つ必要がないので、レイテンシも悪くならないケースがある。
もちろんデメリットもあります。Write/Read双方で複数の通信が発生するため、絶対的なレイテンシは低くなりません。また、多くの処理がタイムアウトに依存したアーキテクチャになっているため、高遅延環境(たとえばグローバルなマルチリージョン構成など)ではその閾値設定が難しく、かつ重要なポイントになってきます。
Spannerなしでも可能な、スケーラブルな分散DBの提案
では、マイクロサービスのバックエンドとしてGoogle Cloud Spannerを使えば、SizeとGeographicalのスケーラビリティを確保できて、万事解決でしょうか。またオンプレの場合は、Oracle RACとActive Data Guardの組み合わせで解決したら良いのでしょうか。
この答えはYesであり、Noでもあります。
SpannerもOracle Databaseも使わず、現状利用可能な分散SQLデータベースと複数のデータセンター(またはAZやRegion)を用いて、真にスケーラブルなDBを構成する案を以下のスライドに示しています。
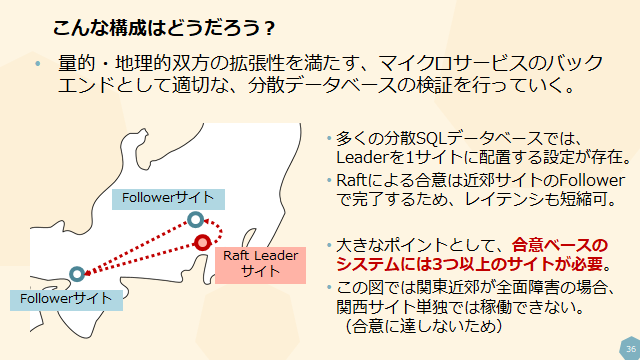
ここでは分散SQLデータベースの以下の2つの特徴に注目しています。
- Shardごとに複数存在するRaft Leaderは1サイトに集めることが出来る。
- Raftでは近いサイトからのレスポンスで過半数が得られれば合意し、Commitができる。
これにActive Data Guard Far Syncのレイテンシに差のあるサイトで同期と非同期を使い分ける考え方を加えて、
「Multi-Leaderで同期レプリカかつ地理分散可能なデータベース」
を実現するのが本提案の骨子です。
上記構成のデメリット
もちろん、上記の構成にも既に課題がいくつか存在します。
3つの地理的に分散されたサイトの準備が前提となること、更に上図のように関東近郊に2サイト用意した構成では、
「関東圏の広域障害時には、DRの関西1サイトしか残らず、合意形成に必要な過半数が確保できない」
という点です。
この辺りは、一部の分散SQLデータベースにあるLeaner(RaftにおいてLeaderでもFollowerでもなく、合意形成には参加しないが、データは非同期で複製されているノード)の仕組みを用いて、DRサイトに短時間でFollowerが構築できるような準備をしておく必要があるでしょう。
なお、LeanerはRaftを用いる有名な分散KVSであるetcdのドキュメントでも触れられています。
まとめ
今回の登壇は今までと雰囲気を変えて、マイクロサービスのバックエンドという文脈を丁寧に設定して、分散データベースにおけるトランザクションとスケーラビリティの課題を整理してみました。
マイクロサービス、そして分散システムという文脈に踏み込むのは私としても大きなチャレンジです。
それらは既に多くのエンジニアが先行して研究・実装を重ねてきた部分であり、そうした方にも何か役に立つことが言えたかというと、残念ながら自信がありません。
それでも、分散データベースの意義や何を解決するものなのかという課題感を共有できていれば、それに勝る喜びはありません。
長文となりましたが、ここまでお読み頂き、ありがとうございました。