Disclaimer
当記事はNewSQL開発ベンダの技術ブログや各種論文、その他ニュースサイト等の内容を個人的にまとめたものです。
そのため、理解不足等に起因する誤解・誤認を含む可能性があります。更なる理解が必要な方はリファレンスに挙げた各種文献を直接参照下さい。技術的な指摘は可能であれば取り込み修正しますが、迅速な対応はお約束できません。
NewSQLの解説は二部構成
今回記事は「2020年現在のNewSQLについて」の続編であり、後編となる。NewSQLって何?という方は前回記事からお読みになることをお勧めする。
全体の目次は下記である。
- NewSQLとは何か
- NewSQLのアーキテクチャ
- NewSQLとこれまでのデータベースの比較
- NewSQLのコンポーネント詳解 (当記事)
前編のまとめ
1章から3章までは前編として、NewSQLとしてGoogle Cloud Spannerおよびそのクローンと言われる製品を3つほど紹介した。
いずれも「強い整合性を持ち、ACIDトランザクションをサポートする、(地球規模の)分散型のSQLデータベース」を目標として設計されており、これまでのRDBやNoSQLが妥協してきたものを現在の技術を用いて補うべく開発が進められている。
中でもNewSQLのアーキテクチャとして、下記3つの要素を紹介している。
- SQLクエリエンジン
- 分散トランザクションマネージャ
- ストレージエンジン(分散ストレージ)
SQLクエリエンジンはPostgreSQLまたはMySQLと互換性を持ち、NewSQLとクライアントのインターフェースとなる部分である。
分散トランザクションマネージャは、NewSQLで必要となる分散トランザクションの管理を行う重要な要素であり、ストレージエンジンは最終的なデータの永続化と整合性の確保を担う。
これら3つをどのようにクラスタ内のノードに配置するかは製品ごとに異なっていた。
4. NewSQLのコンポーネント詳解
さて今回は、NewSQLの中で実際に使われている技術要素を一つ一つ取り上げ、詳解を試みる。
具体的には以下4つのコンポーネントを説明していく。
【今回解説する4つのコンポーネント】
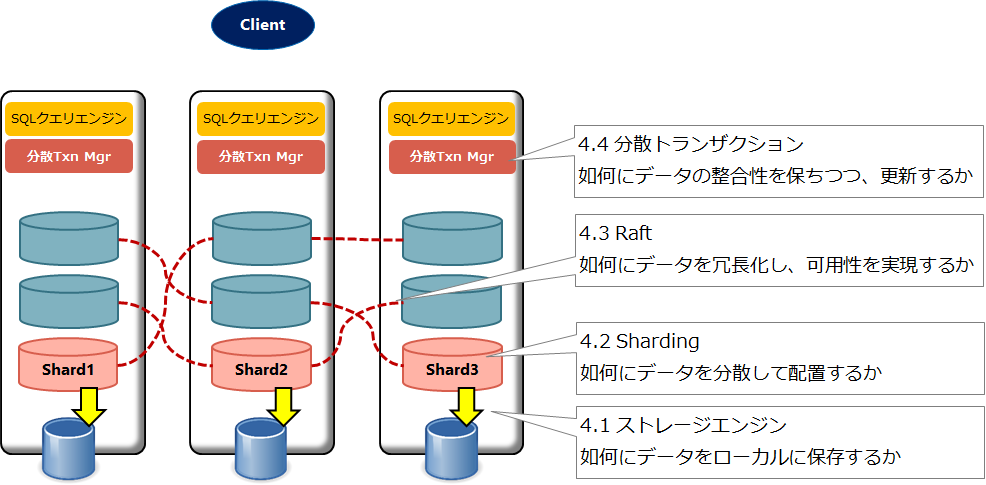
それぞれ関連しあうコンポーネントを下層から順に紹介していく。ご存じの部分があれば、もちろん飛ばして進んで頂いて構わない。
4.1 ストレージエンジン
NewSQLは分散型のSQLデータベースであるが、どれほど分散していたとしても最終的にデータはクラスタ内ノードのローカルディスクに保存されることになる。その意味ではNewSQLのストレージエンジンも、従前のRDBに組み込まれていたそれと役割が大きく変わるわけではない。
ただ、長らくRDBの(正確にはそれらのストレージエンジンの)ベースとなっていたデータ構造であるB Treeに代わり、後発のLSM Tree(log-structured merge-tree) が勢力を拡大している。(こちらのブログではそうした状況とRocksDBを採用したプロジェクトが解説されている) 。
こうした傾向には、B+ Tree(B Treeの派生)がHDDのように読み書きが遅いメディアでの利用に最適化されており、近年では欠点が多く指摘されているという背景がある。
例えば、B+ Treeは高スループットで低レイテンシな読取りが可能な反面、書込みのオーバーヘッドが大きい。一部のレコードを書き換えるにも固定長ブロック全体を上書きする仕組みのため、いわゆるWrite Amplificationを招く。
この辺りのアカデミックな議論は2019年に発売されたDatabase Internalsに詳しい。ストレージエンジンについて深く学びたい読者は是非お読み頂きたい。
4.1.1 LSM Treeの長所と短所
一般的な対比では、読取り性能重視のB Tree、書込み性能重視のLSM Treeとされる。
下図はLSM Treeの書込みを表している。
元記事には、メモリへの書込みからマージが複数回行われてストレージに保存される様子が記述されているので興味がある方は一読をお勧めする。
【LSM Treeの書込みイメージ】
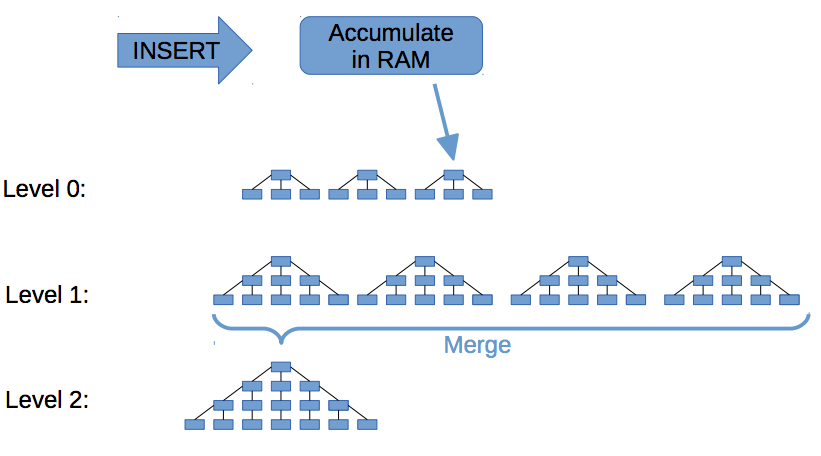
出典: <[SQLite4の開発物語](https://enterprisezine.jp/dbonline/detail/9928)>
【LSM Treeの長所】
上図にあるように、LSM TreeではメモリへのランダムWrireをLevel 0へのシーケンシャルWriteに変換し、効率的に書込みを行う。その処理は追記(バージョニングされたもの) であり、B Treeのようなページ上書きではないため、Write Amplificationを抑えられる。
蓄積されたデータはバックグラウンドでマージして階層化していくのだが、この過程で不要データを削除し、ディスク利用効率を高めることが出来る。
【LSM Treeの短所】
B Treeのデータ構造においては、特定のキーに紐づく値は物理的に一つしか存在しない。値の更新時には同一箇所が上書きされるためである。
LSM Treeでは追記のため、上図のLevel 0とLevel 1に同じキーの異なる値(バージョン違い) が存在するケースがある。そのため、Read時に複数レベルのSSTable(上図の各ツリーにあたるもの) を走査する必要が出てきてしまう。
Write時も、重要なLevel 0への書込み(Flush) とバックグラウンドのマージが競合する場合があり、双方の性能を劣化させる。その上、マージが長時間行えない場合は読込み対象となるSSTableが増加する可能性があり、Read性能をさらに劣化させてしまう。
概して言えば、LSM Treeは理想の状態では高速に動くものの、B Treeに比べて予測不可能性が各所に含まれており、それらを改善する仕組みが実装に要求されている。
4.1.2 RocksDB: NewSQLでの利用
RockSDBはLSM Tree実装であるLevelDBのフォークとして、Facebookにより開発された。
今回紹介しているSpannerクローンの全てで使われており(一部はベースとしてだが) 、その特色として下記がある。
【RocksDBの特色】
- Key-Value型で永続的なデータストアを組込み可能な形式で提供。
- SSDなど低レイテンシなデバイスに読取り/書込みが最適化されている。
- マージ、圧縮、SCANなど分散DBに必要な高度な機能セットを提供。
まず、前節で述べたようにLSM Tree実装のRocksDBは追記処理で複数バージョンを保持できるため、分散SQLデータベースで必要となるMVCCをストレージエンジンレイヤからサポートできる。
更にLSM Treeを補完するRocksDBの高度な機能があり、それらをカスタムで開発することを避けた経緯などがCockroachDBのブログでも語られている。
一例として、LSM Treeの短所であげたRead性能の改善のために、RocksDBではBloom Filter/Prefix Bloom Filterという機能でReadの高速化を図っている。詳細は先述のCockroachDBブログや、TiKVのドキュメントを参照のこと。
また、NewSQLはRow構造、RocksDBはKey-Value構造である。
そのため、Row構造で頻繁に行われる処理を、RocksDBでも効率的に捌くことが求められる。CockroachDBやTiKVでは、範囲検索や範囲削除(つまりDELETE FROM) をサポートするためにRocksDBの機能が用いられている。
4.1.3 RocksDBの最適化: DocDB
CockroachDBやTiKVと異なり、YugaByteDBではRocksDBをエンハンスした独自のDocDBをストレージエンジンとして利用している。NewSQL用途でのエンハンスの必要性、ポイントについてはYugaByteDBのこちらのブログに詳しい解説がある。
要点をまとめると下記のとおりである。
- Scanに耐性を持つキャッシュの実装(mid-point insertion strategy)
- Bloom Filter及びインデックスのマルチレベルのブロック分割対応
- RocksDBのマルチインスタンス対応
- 機能が重複するジャーナリングやMVCCに用いられていたシーケンスの利用回避
中でも3つ目のマルチインスタンス対応には大きく手が入れられているように見える。後述するようにYugaByteDBではデータをTabletという単位に分割するが、障害時に必要となるデータ可搬性などから考えると、1Tablet=1RocksDBインスタンスを理想としており、前述ブログではその構造のメリットが取り上げられている。
一方で1ノードに多数のRocksDBのインスタンスが稼働すると、リソース利用に無駄が生じる可能性が高まる。それを最適化するために、ノードグローバルに使えるキャッシュの開発などもDocDBでは行われている。
4.1.4 ここまでのまとめ
NewSQLのストレージエンジンとして、LSM Tree実装であるRocksDBやその派生が用いられている。
LSM Treeは一般的に書込み量の大きいワークロードで高い性能を誇るが、RocksDBではRead性能を高めるためにBloom Filterなど高度な機能が提供されている。
また、Key-Value構造であるRocksDBにデータを格納するためにRDBのRow型からデータ変換が発生するが、それらをどのようにマッピングし、クラスタグローバルな一貫性も担保するかは各製品での工夫のしどころであり、DocDBのように独自改善を行うアプローチも存在している。
ストレージエンジンのおまけ
組込みのストレージエンジンと聞くと、SQLiteを頭に浮かべるDBエンジニアも多いかも知れない。
そんな方には「go-sqlite3を使ってCloud Spannerエミュレーターを作ってみた」というスライドを紹介しておく。つまり、SQLiteをベースにしたSpannerクローンであり、非常に興味深い内容となっている。
また、短時間でストレージエンジンのサマリを抑えたいという方にはYugaByteDBの技術ブログからこちらの記事もお勧めする。
4.2 Sharding
分散DBにおいては、レコードをどのように多数のノードに配置するかの考慮が必要となる。一般的にレコード単位では管理効率が悪いため、固定長に区切られたレコードの集合でデータを分散し、同時にレプリカを作成する(レプリカについては4.3 Raftの節で解説する) 。
もともとRDBではデータブロック(Oracle) やPage(PostgreSQL) と言った単位でレコードをまとめて扱っており、その管理がストレージエンジンの責務であった。
そして、前回紹介したSharding を用いた分散DBではデータブロックとは別の単位で、レコードのキーに基づく一定のルールでノード間にデータを分散配置する。この単位を(Shard) という。
NewSQLにおいても同様にShardingが行われるが、Shardの名称やサイズ、分割手法は製品それぞれで異なる。前回紹介したSpannerとそのクローン3つのShardingについて下表に示す。
【表1: NewSQLごとのSharding方式】
| NewSQL名 | Shardを指す名称 | Shardの最大サイズ | Sharding手法 | 参考URL |
|---|---|---|---|---|
| Spanner | Split | 4GB | range | スキーマとデータモデル |
| CockroachDB | Range | 64MB | range | Range Splits |
| TiKV(TIDB) | Region | 100MB | range | region-max-sizeで指定 FAQ |
| YugaByteDB | Tablet | 制限なし | hash/range | 100GB未満を推奨とのこと |
4.2.1 Shardingの手法
先ほどの表1を理解するにはSharding手法の列にあげられた各用語の理解が必要となる。
YugaByteDBのブログ「Four Data Sharding Strategies We Analyzed in Building a Distributed SQL Database」には、非常に詳しくShardingの手法が紹介されている。この記事では、大きく以下4つの分類があるという。
- Algorithmic Sharding (例: Memcached/Redis)
- Linear Hash Sharding (例: 過去のCassandra)
- Consistent Hash Sharding (例: DynamoDB、Cassandra)
- Range Sharding (例: Spanner、HBase)
詳細は割愛するが、1つ目のアルゴリズム・シャーディングと2つ目のリニア・ハッシュ・シャーディングには大規模運用時やHotspotの回避などに問題があり、NewSQLでは利用されていない。
Consistent Hash Sharding(ここでは表1のhashとほぼ同義に扱う) はいわゆるハッシュ関数によるデータ分散であるが、長所としては上記記事にもあるように、ノードへの均等な分散が可能となるためにHotspotを出来づらく、スケーラビリティを高めることが出来る。また、Key-Valueストアで一般的なキー指定の値取得(get) に強い。一方で短所として、RDBで頻繁に発生する範囲検索(0>key>100などのRange Scan) で効率が劣化する。
【Consistent Hash Shardingのイメージ】

出典: <[Four Data Sharding Strategies We Analyzed in Building a Distributed SQL Database](https://blog.yugabyte.com/four-data-sharding-strategies-we-analyzed-in-building-a-distributed-sql-database/)>
そして、Range Sharding(表1のrangeと同義) はhashと対極の特徴を持つ。
つまり、長所として範囲検索に強くなるが、短所としてキーの設計次第でHotspotの問題が避けられない。
【Range Shardingのイメージ】

出典: <[Four Data Sharding Strategies We Analyzed in Building a Distributed SQL Database](https://blog.yugabyte.com/four-data-sharding-strategies-we-analyzed-in-building-a-distributed-sql-database/)>
(おまけ) Partitioning
ここまでShardingにおけるデータ分割手法を説明してきたが、これもNewSQLに固有の話ではない。
例えば、Oracle DatabaseのPartitioning機能では以下の分割手法がサポートされている。
- レンジ・パーティション (rangeとして説明したもの)
- リスト・パーティション (NewSQLでは存在しない)
- ハッシュ・パーティション (hashとして説明したもの)
- コンポジットパーティション (上記の組み合わせ)
これらの前提知識がある場合、理解の一助となるだろう。
4.2.2 Shardingの違いがもたらすもの
基本的な用語を解説したところで、改めて表1が示す意味を考察していこう。
ドキュメントを見る限り、SpannerではrangeによるShardingを行うように見え、キー値にハッシュ関数を咬ませる等Hotspotの回避はアプリケーション設計者に委ねられている。そのため、こうしたベストプラクティス が紹介されているなど、プライマリキーの設計に注意を払う必要がある。
また、SpannerではShardのサイズが上限を超えた際以外にも、Shardへのアクセスが高まったタイミングで分割を行う仕組みが用意されている。詳細はこちらなどを参照のこと。
Spanner同様にCockroachDBとTiKV(TiDB) でもrangeによるShardingが行われている。これはそれぞれの製品ブログにRDBとしての範囲検索をサポートするためと理由が示されている。
YugaByteDBではhashによるShardingを基本的として採用し、Hotspotの回避を強く意識している。一方でRDBとしての検索性能を高めるためにCreate Table時にrangeによるShardingを指定できるようになっており、ここもSpanner同様にアプリケーション設計の大きなポイントとなる。
このような各製品の状況は、分散DBのスケーラビリティを高める観点ではhashが妥当だが、SQLをサポートするNewSQLとしては何らかの形でrangeのサポートが必要、という実情を示している。
4.2.3 Geo-Partitioning
今回の記事では、地理分散(特に地球規模など広域のケース) について深く解説するつもりはないが、Shardingによるデータ分割は地理分散とも単位を同じくする。
そのため、Geo-Partitioningの観点ではShardをどのリージョンに配置するかという戦略で、CockroachDBやYugaByteDBではそうした配置設計やサポート機能を紹介しており、この観点でもSpannerを追随している。
例えば、CockroachDBのドキュメントでは「Geo-Partitioned Replicas Topology」としてTopologyベースのShardとレプリカ管理の方法が紹介されている。
また、YugaByteDBでは「9 Techniques to Build Cloud-Native, Geo-Distributed SQL Apps with Low Latency」として、Geo-Partitioningのサポートなど広範な機能が紹介されている。
なお、こうした地理分散への対応はGoogleにおいても簡単ではなく、Spannerにおいても構成に制約があるように見える。(Spannerのマルチリージョン構成)
後述のRaftでもLeader/Followerの配置が地理分散の影響を受ける部分があるため、その点については後述する。
4.2.3 ここまでのまとめ
データの分割に用いられる方法として、Hotspotを作りづらく書込みに強いが範囲検索に弱いhashと、Hotspotが発生しやすいが範囲検索に強いrangeの2つの手法がある。
NewSQLでもhash/rangeのどちらかまたは両方をサポートするなど製品によって状況が異なるため、特性を理解してキー設計に反映する必要がある。
4.3 Raft
ここからはNewSQLにおけるRaft活用の解説に入る。
前回記事では深入りを避けたが、分散SQLデータベースでは前述したShard単位でデータを分散するだけでなく、ノード障害時にもデータロストを回避し、クエリに応答するためにShardのレプリカを持つ必要がある。
このデータレプリカをNewSQLではRaftを用いて作成している。
4.3.1 そもそもRaftとは
Raftは2014年に「In Search of an Understandable Consensus Algorithm」として論文が発表された、合意アルゴリズムである。(論文の邦訳はこちら)
大まかに言うと、Raftには下記2つの機能がある。
- リーダー選出
- ログ複製
この2つを使って、何が出来るかはこちらのブログが非常に分かりやすい。冒頭のまとめが簡潔にRaftの機能を説明してくれているため、そちらを引用する。
- 一貫性のあるレプリケーションや分散実行を行うことができる。
- 長期間の停止や大幅に遅延したノードが復帰したり、ノード故障によるリーダー交代が発生しても、合意したデータが破壊されるシナリオが存在しない。
- 役割もアルゴリズムも構成も簡単 (simplicity) & 簡単 (easiness)。
引用: <[分散合意アルゴリズム Raft を理解する](https://qiita.com/torao@github/items/5e2c0b7b0ea59b475cce)>
NewSQLではレコードをキー値に基づいてShardに分割し、そのShardのレプリカ作成にRaftのログ複製を用いる。
また、複数存在するレプリカのうち、Read/Writeを主に担当するLeaderを決める際にもRaft(リーダー選出の機能) を用いる。これは耐障害性のカギでもあり、Leaderの障害時には再びリーダー選出が行われる。
4.3.1.1 ログ複製
ログ複製の説明のために、下図のような分散データベースを想定する。
- 左側の緑の丸はクライアント。
- 右側の3つの青い丸が分散データベースの各ノード。
- 太線で囲われている青丸、Node aが現在のLeader。残り2ノードはFollower。
【ログ複製のイメージ: ログ(コマンド)送信前】
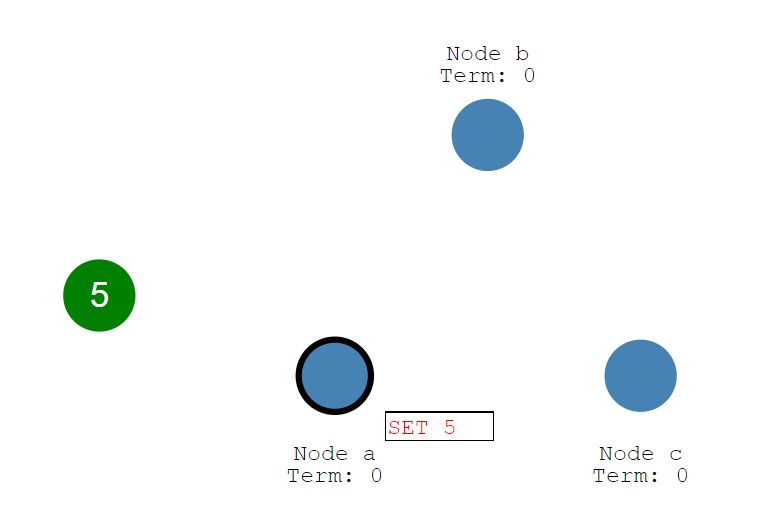
引用:<[The Secret Lives of Data](http://thesecretlivesofdata.com/raft/)>
実際の動きは、Raftの動きを説明するサイトにアニメーションが置かれている。一つ一つ追っていくと、それほど難しいことをしていないのが分かるだろう。
簡単に概要を説明すると、上図でクライアントは分散データベースに値: 5をセットしたいので、それを送信する。その後、以下のシーケンスで処理が行われる。
1. Leaderが更新内容を受信 (Followerが受信したらLeaderへリダイレクト) 2. Leaderのログに更新内容が書き込まれる。この時点では未コミット。 3. コミットのために、Followerへログを複製する。 4. LeaderはFollowerのログ書込みを待機する。 5. ノード過半数の書込みを確認後、Leaderは更新内容を**コミット**し、クライアントへ応答。 6. Leaderは今回のログがコミット済であることをFollowerへ通知する(合意に成功)。このような同期方法はState Machine Replicationと呼ばれ、複数台のノードがあっても同じコマンドを同じ順番で実行したら同じ状態になる、という考えに基づいている。
Raftではこのコマンド(命令) をログと呼んでいる。
またRaftの優れた特性として、LeaderやFollowerに一定数以内の障害が発生しても、またネットワーク分断が起きても、一度合意した値が覆らないという点がある。
分散データベースで良く使われている2PC(2Phase Commit) はトランザクションの調整を行うコーディネータの障害や、参加ノードが停止と復活を繰り返すことで容易にこの整合性が崩れ得る。このあたりの詳細はこちらの資料に詳しい。
4.3.1.2 リーダー選出
正常時には先ほどのログ複製で問題ないが、障害時の動きとしてLeaderやFollowerがダウンした場合にどうなるかを考えておかなければならない。
基本的にLeaderを他ノードが引き継ぎクラスタの整合性を保つが、Leaderは必ず1台だけ存在しなければならない。Raftではリーダー選出のアルゴリズムを用いてこれを実現する。
こちらもログ複製と同じサイトでアニメーションが見れるので、そちらを確認しておこう。
この場合も3つのノードからなる分散データベースを想定する。そして、Leader/Followerの他にもう一つのノードの状態としてCandidateが登場する。
【リーダー選出のイメージ: 選出開始時】
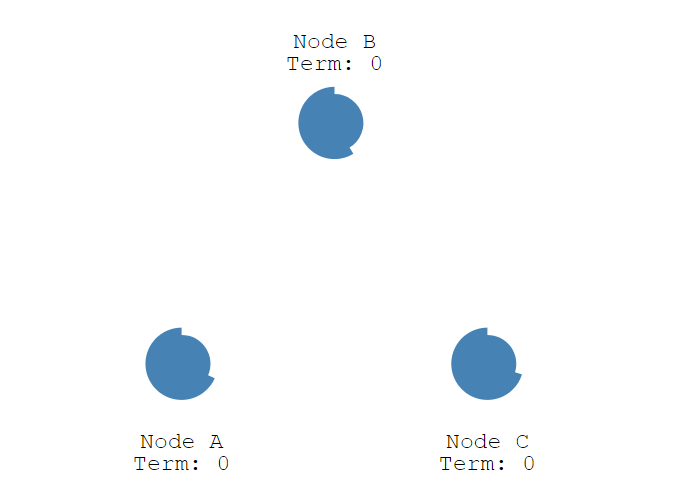
引用:<[The Secret Lives of Data](http://thesecretlivesofdata.com/raft/)>
上図は3つのFollowerが存在し、election timeoutという期限(青丸の周囲にある切り欠け部分) を待っている状態である。ここから次のシーケンスでリーダー選出が行われる。
1. *election timeout*を待機し、自身が**Candidate**になる。 2. 自身に投票し、他ノードへ投票リクエストを送る。 3. 他ノードは問題なければ、Candidateに投票する。この際、*election timeout*をリセットする。 4. 過半数の投票が得られれば、CandidateはLeaderになる。 5. Leaderは一定間隔でFollowerへ**Append Entries**(いわゆるハートビート) を送信する。 6. FollowerはAppend Entriesへ応答し、その都度*election timeout*をリセットする。 7. *election timeout*内にAppend Entriesが送信されてこない場合、1.に戻る。上記サイトのアニメーションにはネットワーク分断時のリーダー選出についても解説があるので、そちらもご覧頂きたい。
ここまで見たように、Raftではリーダー選出を用いて選ばれたLeader(クラスタ内に一つ) とFollowerがログ複製を行うことで、データのレプリカを行う。障害時には新たなLeaderが選ばれるため、一定数以下のノード障害には耐えることができ、高可用性を実現している。
4.3.2 シングルRaftとマルチRaft
前回投稿で「NewSQLはマルチマスターなのか」という疑問を提示し、Raft Groupという概念を示した。こちらについても改めて解説しておこう。
まず、Raftの解説で述べたように「NewSQLではレコードをキー値に基づいてShardに分割し、そのShardのレプリカ作成にRaftのログ複製を用いる」。
つまり、分散SQLデータベースのクラスタとしては、1つ以上の(通常は膨大な数の) Shardを管理し、それらが4.3.1.1で述べたようにRaftで複製されている。
この複製されたShardがRaft Groupにあたる。Raft(またはPaxos) でデータ複製を行うデータベースは今回解説しているNewSQL以外にも存在するが、管理対象が単一Raft Groupなのか(いわゆるシングルRaft)、複数のRaft Groupか(マルチRaft) で特性が大きく異なる。
下図はシングルRaftで構成されたetcdと、マルチRaftのTiKVを比較している。
【etcdとTiKVのRaft Groupに関する比較】
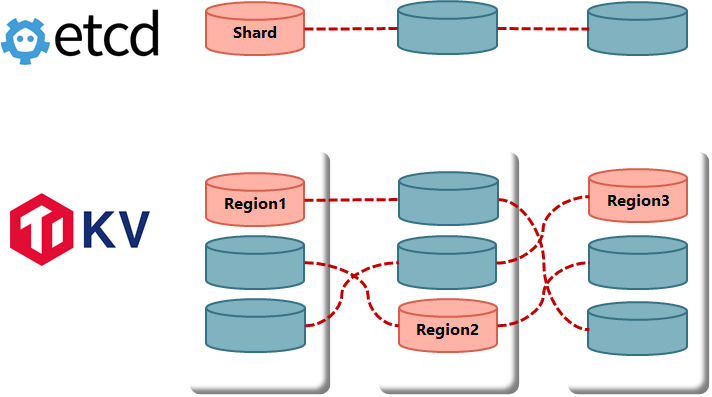
Kubernetesを使っている方はご存じのとおり、etcdは大量のデータが蓄積できるわけではなく、スケーラビリティも限られている。その一因は上記のようにRaft Groupを1つに収めていることにもある。
一方で、分散SQLデータベースはスケーラビリティを重視して複数Raft Groupを管理できるようになっているが、それは構成の複雑さを招き、下記のようなデメリットが生じている。
- 4.3.1.2で触れたようなRaftのハートビート通信量が増大する。
- 1Shardの値はRaftで合意可能だが、複数Shardの整合性を保つには分散トランザクションを要する。
前者の通信量増大については、CockroachDBやTiKVでその削減のための改善をいくつか行っている。詳細はこちらやこちらのブログを参照のこと。
後者の分散トランザクションについては、4.4で解説する。
4.3.3 RaftにおけるRead
さて、ここまではRaftによりデータの書込みが複製され、クラスタとして高い可用性を持つ様子を見てきた。では、Read つまりデータの読取りはどのように処理されるのだろうか。
前回述べたようにRaftでは基本的にLeaderがReadもWriteも処理を行う。では、なぜLeaderがReadリクエストを処理する必要があるかというと、「コミット済みの最新データを返す」という原則を守るためである(線形化可能性にも関わる問題であり、その観点では4.4で解説する) 。
実際、Readリクエストを受け取ったLeaderは「Read中に新しいLeaderが誕生し、そちらでコミットされているデータがある」というケースで、最新データを返せない。
Raftを用いた複製下でReadがどのように行われるか、そしてどんな問題があるかはYugaByteDBのこちらのブログに詳しい。
ブログからReadのシーケンス(これをRaft Log Readと呼ぶ) をまとめると以下のようになる。
1. LeaderがクライアントからReadリクエストを受信する。 2. Leaderはハートビート通信を行い、過半数のレスポンスを待つ。 3. 自身がLeaderなので、ローカルなデータを読み取ってリクエストに応答する。2.のハートビートを省略してLeaderがReadクエリに応答した結果生じる不具合は、YugaByteDBのブログでは下図のように示されている。
【Leaderが誤ったReadを返すケース: ネットワーク分断】
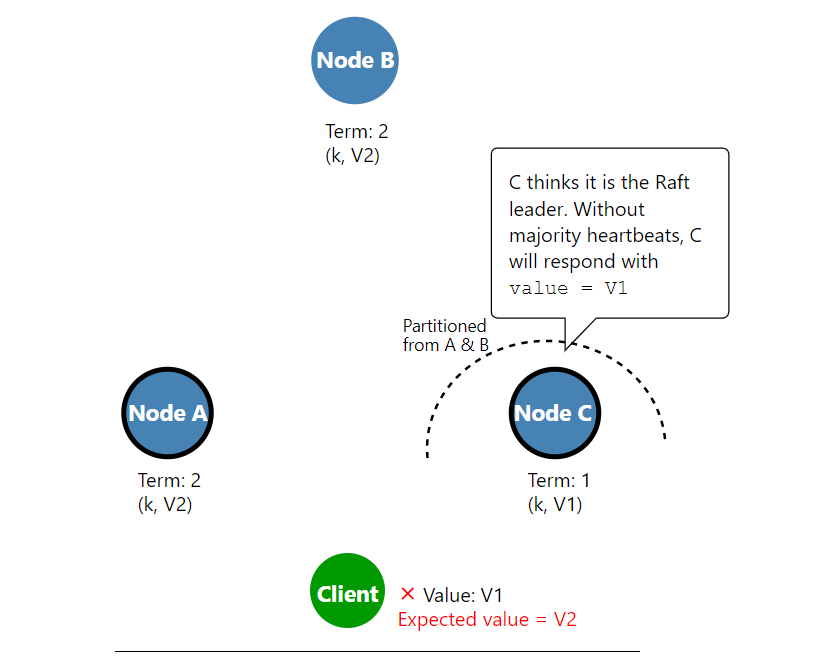
引用: <[Low Latency Reads in Geo-Distributed SQL with Raft Leader Leases](https://blog.yugabyte.com/low-latency-reads-in-geo-distributed-sql-with-raft-leader-leases/)>
しかし一方で、Read応答前にハートビートのレスポンスを待つことで遅延が発生する(地理分散であれば尚更) 。そして、データ読取りにおいては、必ずしも最新のデータが必要ないケースも存在する。
そうした事情から、Spannerや他のNewSQLでは低遅延なReadの仕組みがいくつか実装されている。
4.3.3.1 Lease Read
低遅延なReadの一つとしてLease Readがある。
これは一言でいえば、「Leaderがハートビート通信なしでReadを処理する」ということなのだが、それでもコミット済みの最新データを返すための調整が行われている。
この低遅延Readの前提として、Leaderは読取りなどの処理を行うためにLeader Leaseを必要とする。このLeaseは終了期限をもつもので、DHCPのリース時間を思い出してもらえればイメージしやすいかも知れない。
4.3.1.2で説明したリーダー選出のプロセスで「過半数の投票が得られれば、CandidateはLeaderになる」と書いたが、Leader Leaseを用いる場合、選出後も旧LeaderがLease時間を過ぎて降格し、その後Leader Leaseを得るまで新Leaderは読取り等の処理が出来ない。
先ほど紹介したYugaByteDBのブログに詳しく解説されているが、Leader Leaseを使うことで下図のようにクラスタでReadもWriteも出来ない瞬間が発生する。
【Leader Lease待ちでUPDATEがRejectされるイメージ】
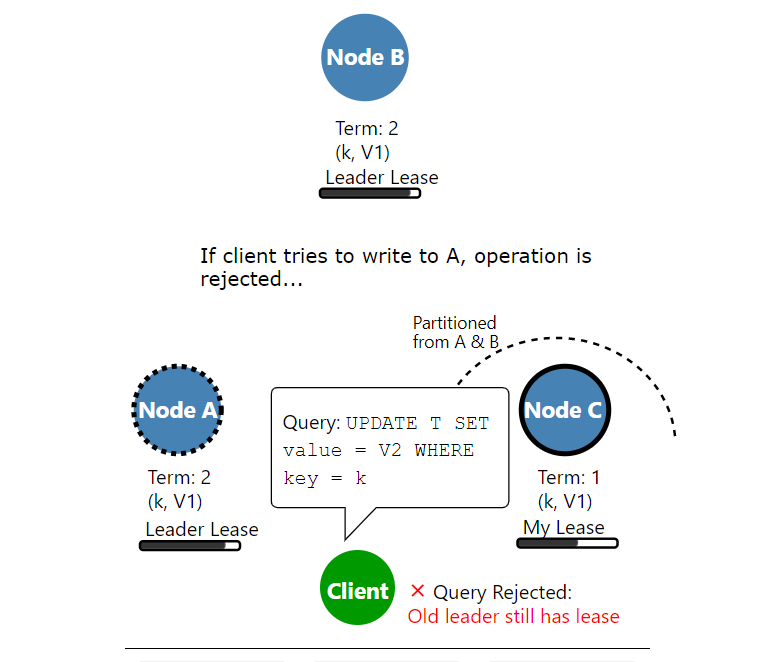
引用: <[Low Latency Reads in Geo-Distributed SQL with Raft Leader Leases](https://blog.yugabyte.com/low-latency-reads-in-geo-distributed-sql-with-raft-leader-leases/)>
一方で、これは「Leaseが切れて現在のLeaderが降格するまでは新たなWriteも行われない」ということであり、これは「現在のLeaderがハートビート不要で最新のデータを読める」ことと同義である。
このように(滅多に起きない) ネットワーク分断の切り替え時に少し待機することで、通常のReadのラウンドトリップを削減するLease ReadはYugaByteDBだけでなく、TiKVでも同様の言及がされている。
4.3.3.2 Follower Read
Lease ReadがあくまでLeaderが「コミット済みの最新データを返す」のに対し、データが最新でなくても良ければ、FollowerがReadリクエストを処理出来るユースケースが存在する。
そのため、いくつかのNewSQLにはFollower Readという機能が提供されている。
例えば、下図はCockroachDBがマルチリージョンな環境下で、クライアントと別リージョンにあるLeader(4.3.3.1で解説したLeader Leaseを保持) からのReadではなく、同一リージョンにあるFollowerからReadする様子を示している。
【マルチリージョンにおけるFollower Readのイメージ】
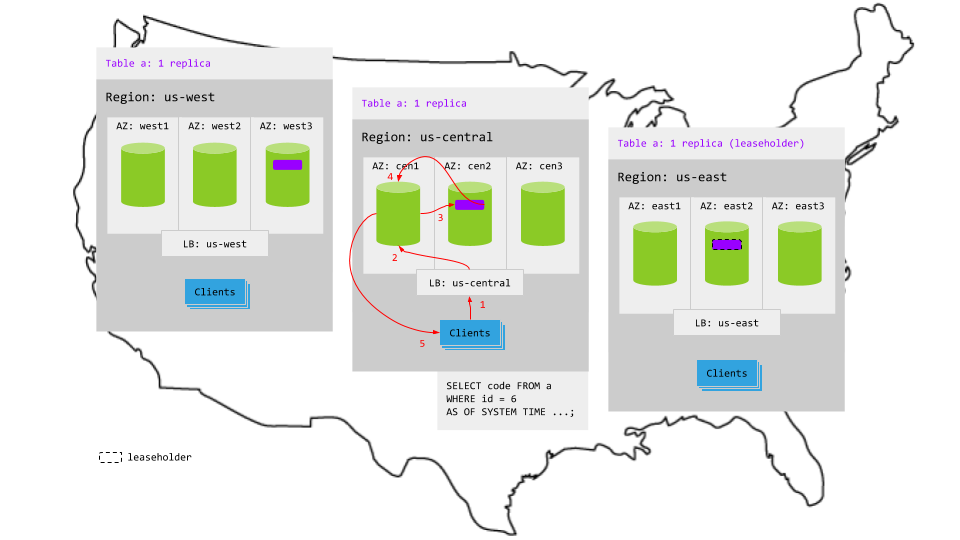
引用: <[Follower Reads Topology](https://www.cockroachlabs.com/docs/stable/topology-follower-reads.html)>
なお、CockroachDBではFollower Readはエンタープライズ向けの機能であり、かつ現在は48秒以上過去のデータしか読み取れないなどの制約が存在する(詳細はこちら) 。
YugaByteDBもFollower Readを提供するが、CockroachDBと同じくTimeline Consistentな読取りしか保証されない。
もう一つのSpannerクローン: TiDB/TiKVは異なるアプローチを取る。下図にTiKVのStrong ConsistentなFollower Readのシーケンスを示す。
【TiKV: Follower Readのシーケンス】
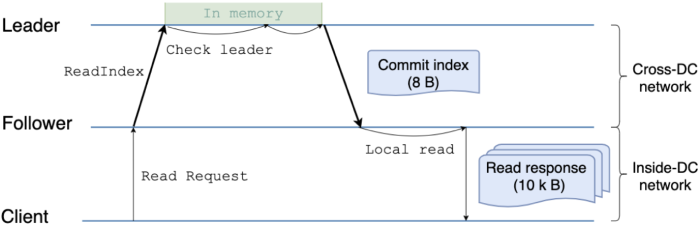
引用: <[How We Reduced Multi-region Read Latency and Network Traffic by 50%](https://download.pingcap.com/images/blog/read-request-processing-with-follower-read-enabled.png)>
ここではFollowerがクライアントからリクエストを受け取った後に、ReadIndexという「Leaderがどこまでコミットしたか?」を確認する通信を行っている。その結果、Followerは最新のデータを判別可能となり、クライアントへコミット済みの最新データを返すことが出来る。
ReadIndexの詳細や通常のRaft Log Readとの比較を詳しく知りたい方は上記のブログに加えて、同じくTiKVのこちらやこちらのブログが参考になる。
ここまで分かるようにLeaderの負荷分散やGeo-Scaleな地理分散でのラウンドトリップタイムを削減するために、一貫性を妥協したり、通信量を削減するFollower Readの機能が実装されている。
4.3.1.1のログ複製のシーケンスを再度見直すとわかるのだが、RaftではFollowerがいつログを反映しCommitするかは決まっていない。つまり、Followerにデータを読取りに行った際にはいつ時点のデータが返されるか分からないという事実がこうした実装の根底にある。
4.3.4 ここまでのまとめ
Raftはリーダー選出とログ複製の機能を持ち、それらを用いてNewSQLではShardの複製と高可用性の担保を実現している。
但し、RaftでもRead/WriteともにLeaderを経由する必要があるなど課題は残るため、それらの解決のためにLease ReadやFollower Readなどの仕組みがNewSQLでは実装されている。
4.4 分散トランザクション
ここまでで分散SQLデータベースが、如何にクラスタ内のノードにデータを分散して配置し、かつ高可用性担保のためにレプリカを管理するかについて学んできた。
この最終節では、分散・レプリカされたデータをどのように整合性を保ちつつ更新するかという観点で、分散トランザクションの解説を試みる。
これはDisclaimerではなく本音としてだが、正直言って分散トランザクションは私が語るには荷が勝ち過ぎている。詳しく知りたい人はデータ指向アプリケーションデザイン(の7章や9章)を読み込む方が有益であるし、以下のブログも非常に参考になる。
以降では、あくまでSpannerクローンのNewSQLを理解するために、分散トランザクションに関する各種ドキュメントを読み解いていく。
4.4.1 NewSQLの同時実行制御
今回紹介しているNewSQLでは「ACIDトランザクションのサポート」を謳っている。
しかし、ACIDの概念は広く、具体的に何ができるかが分かりづらいため、各NewSQLがサポートするトランザクション分離レベルについてまとめてみよう。
【表2: NewSQLがサポートするトランザクション分離レベル】
| NewSQL名 | サポート対象 | 参考URL |
|---|---|---|
| CockroachDB | Serializable | Transactions |
| TiKV(TiDB) | Snapshot Isolation Externally consistent |
transactions |
| YugaByteDB | Snapshot Isolation Serializable |
isolation-levels |
表から分かるようにNewSQLでは、SerializableまたはSnapshot Isolationをサポートしている。OracleやPostgreSQLがデフォルトでRead Committedだったり、MySQLのデフォルトがRepeatable Readであることと比べて、それ以上の厳しい分離レベルを設けているようにも見える。
誤解を恐れずにいえば、NewSQLではSerializableを採用することで、後述する様々なアノマリーをDBレベルで(つまりアプリケーションの特別な考慮不要で) 回避することを目標としている。
4.4.1.1 Snapshot IsolationとSerializable
ここではSerializableについてのおさらいとSnapshot Isolationの概念を確認しておこう。
ANSI SQL標準でトランザクション分離レベルとして定められているのは下記の4つであり、右に行くほど安全性・一貫性が高いが性能が下がる。左に行けばその逆となる。
READ UNCOMMITTED << READ COMMITTED << REPEATABLE READ << SERIALIZABLE
上記にSnapshot Isolation(SI)という概念は含まれないが、それもそのはず、SIはANSI SQLより後に提唱された概念である。1995年に発表された「A Critique of ANSI SQL Isolation Levels」では、ANSI SQLの分離レベルでは不十分として、8つのアノマリーと6つの分離レベルが説明されている。
【8つのアノマリー】
- P0: Dirty Write
- P1: Dirty Read (ANSI SQLと同等)
- P2: Fuzzy Read (ANSI SQLと同等)
- P3: Phantom (ANSI SQLと同等)
- P4: Lost Update
- P4C: Cursor Lost Update
- A5A: Read Skew
- A5B: Write Skew
【6つの分離レベル】
- Read Uncommitted
- Read Committed
- Cursor Stability
- Snapshot Isolation
- Repeatable Read
- Serializable
先述の論文では、Read Committed << Repeatable Read と Read Committed << Snapshot Isolation は成り立つが、Repeatable ReadとSnapshot Isolationは比較できないとしている。(SIはWrite Skewを許容するがRRは許容せず、RRはいくつかのPhantomを許容するがSIは許容しないため。)
上記の詳細を知りたい方は論文以外にもこちらの解説ブログをお勧めする。
また、各アノマリーの意味が知りたい方は「Cloud Spanner を使って様々な Anomaly に立ち向かう」が大変分かりやすい。
なお、Snapshot Isolationはトランザクション開始時のデータセット(これがSnapshot) の上でRead/Writeが行われる。そのため、Multi-Vesionなデータ管理が必要となるが、NewSQLでこれを担うのがRocksDB(4.1 ストレージエンジンで解説済み) である。
4.4.1.2 Serializable Snapshot Isolation
SerializableとSnapshot Isolationの概念については説明したが、厳密なSerializableはアノマリーを防ぐが同時実行性(つまり性能) に問題があるため、より高スループットな同時実行制御方法が求められる。
その方法がSerializable Snapshot Isolationと呼ばれるもので、NewSQLでSerializableとして実装されているのはこれである。(例えばCockroachDBのブログにその旨の記載がある)
Serializable Snapshot Isolation(SSI) は、「データ指向アプリケーションデザイン」の7章で説明されているのでそちらを引用しよう。
※邦訳版ではSerializable Snapshot Isolation=直列化可能スナップショット分離、と訳されている。
直列化可能スナップショット分離は楽観的(optimistic)な並行性制御の仕組みです。(中略)...
SSIは、スナップショット分離の上に書き込み間の直列化可能性の衝突を検出するアルゴリズムを加え、中断すべきアルゴリズムを判断します。引用: <[データ指向アプリケーションデザイン](https://www.oreilly.co.jp/books/9784873118703/)> ISBN978-4-87311-870-3
衝突検出のアルゴリズムについては書籍中に詳しく解説されているため、そちらを読んで頂くのが良いだろう。また、こちらのブログにもSSIについての解説がある。
SSIを要約すれば、「分離したスナップショットを用いて、楽観的にトランザクションを並行して進め、書き込み時の衝突を検知したらトランザクションを中断してリトライしよう」ということになるだろうか。また、書き込みでは衝突が発生するものの、Snapshot Isolationを用いて読み取りの同時実行を阻害せず、故に高スループットが期待できるのがSSIの大きな利点である。
もちろん利点だけではなく、トランザクションの競合(衝突) が起きる環境下ではリトライが多発して性能劣化を招き得るという短所も存在する。これはすなわちNewSQLの短所にもなっている。
なお、同時実行制御についてはこちらのスライドが歴史も含めて非常によくまとまっているので、一読をおすすめしたい。
4.4.2 分散トランザクションの具体例
ここまでNewSQLがサポートするトランザクション分離レベルはSerializableであり、その中でも性能上優位なSerializable Snapshot Isolationの実装について説明してきた。
ここからは実際にデータがどのように更新されるかについて、いくつかのケースについて解説していく。
ここまでで何度か述べているように、「NewSQLではレコードをキー値に基づいてShardに分割し、そのShardのレプリカ作成にRaftのログ複製を用いる」。
ということは、トランザクション対象のレコードが単一Shardに属するのか(つまりシングルRaft) 、複数のShardに分散しているのか(マルチRaft) という違いが生まれる。
YugaByteDBのブログでは分散SQLデータベースのトランザクションを下記3つに分類している。
- Single-Row ACID
- Single-Shard ACID
- Distributed ACID
上2つは対象レコードが単一Shardに収まっている場合である。これは対象レコードが1行の場合はもちろん、複数行であっても起こりうる(hashによるShardingではたまたまということなるが) 。
この場合、Shard間の調整が不要でトランザクション管理は非常にシンプルになる。単一Shardのトランザクションはこちらのスライドの後半に解説されている。
3つ目のDistributed ACIDでは複数Shard間で調整が必要で、分散トランザクションマネージャの出番となる。
【Distributed ACIDのライフサイクル】
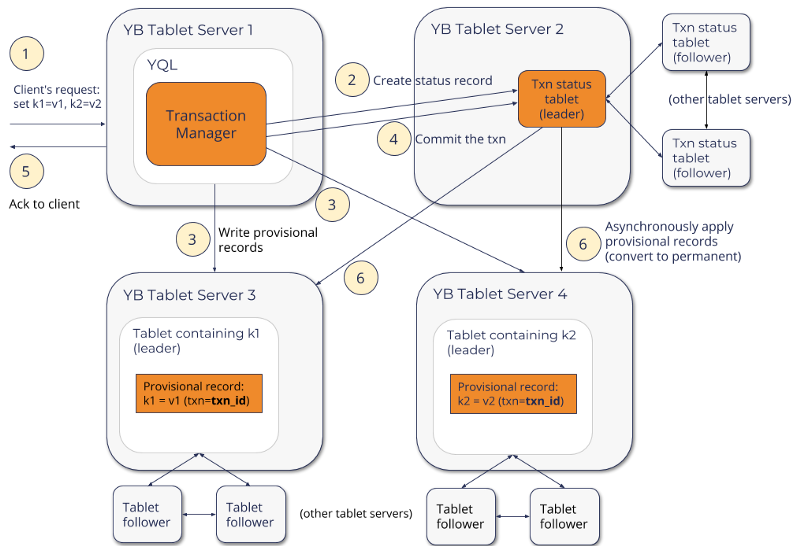
引用: <[Yes We Can! Distributed ACID Transactions with High Performance](https://blog.yugabyte.com/yes-we-can-distributed-acid-transactions-with-high-performance/)>
まず前提として、前回記事でアーキテクチャを紹介したように、YugaByteDBでは各ノードにDistribute Query Executionのレイヤを持つため、上図のようにどのノードでもTransaction Managerの役割を担うことが出来る。
分散トランザクションはTransaction Managerの選択から開始され、以下の流れで処理される。
上記の分散トランザクションはSpannerをベースに設計されているが、Google Cloudが提供するTrueTime APIとGPS・原子時計を備えていない。
そのため、トランザクション間の調整に必要なタイムスタンプ(hyblid Timestamp) は別の考え方で取得し、2.でトランザクションIDなどと共にステータステーブルに挿入される。このタイムスタンプはSnapshot Isolationで説明したMulti-Versionによる同時実行制御(MVCC) でも使用される。
3.で書き込まれた暫定レコードは他の並行トランザクションと競合していないかを検査され、競合が発生した場合は一つのトランザクションが再起動される。これが4.4.1.2で説明したSSIにおける楽観的な同時実行(並行) 制御の動きである。
競合が解決すれば4.でトランザクションはコミットされ、不要になった暫定レコードは6.のクリーンアップフェーズで削除される。
同様の分散トランザクションシーケンスは、CockroachDBのブログにも説明されている。
4.4.2.1 分散トランザクションは回避できるか
ここまでの説明で分かるように、分散トランザクションは複雑である。そのため、過去のShardingでは複数Shardにまたがるトランザクション調整を避ける傾向にある。
例えば、前回紹介したVitessのShardingでは、トランザクションを単一Shardに収めるようなキー設計が推奨されている。
では、複数Shardにまたがトランザクションが発生した場合、Vitessではどうなるか。
こちらのドキュメントにあるように、コミットは**"とても遅くなる"**。その上、4.3.1.1で述べたように2PCが障害時に整合性を崩すという欠点にも陥ることとなる。
では、VitessやAzure HyperScale(Citus) などの従来型のShardingを用いたデータベースで分散トランザクションを回避する(性能劣化を回避する) ことは出来るだろうか。
この点に私は懐疑的である。設計時から完璧なキー設計を行い、運用後もShardをまたがるトランザクションが発生しないという状況は作りがたい。
つまり、Vitessなどでは「多数の単一Shard内トランザクション」と「少数の分散トランザクション」を混合させる結果を招く可能性が高い。
4.4.3 分散トランザクションに必要なTimestampとは?
さて、最後に4.4.2で言及したTimestampについて触れておこう。
(個人的には分散トランザクションを理解する上で、もっともハードルが高くなっているのがここではないかと思っている。)
Spannerが地球規模で分散しつつ、トランザクションを低レイテンシに保つことが出来る理由として、先ほども述べたTrueTime APIと原子時計の組み合わせがあげられる。
4.4.1の表2ではSpannerがサポートするトランザクション分離レベルをあげていないが、ドキュメントによれば、SpannerはSerializableより厳密なExternal Consistencyをサポートしていると記載がある。
SpannerがTrueTime APIとGPS・原子時計を用いて、どのようにExternal Consistencyを実現しているかはこちらのブログを参照頂きたい。また、こちらのスライドも参考になる。
しかし、一方でCockroachDBやYugaByteDBではGPS・原子時計なしで通常のNTPをベースにTimestampを生成し、分散トランザクションの調整を行っている。これがSpannerと比べてどの程度厳密なのか、多くの議論がある。
例えば、前回「1.3 Spannerの欠点とそれを改善するもの」で紹介したCalvinの論文著者はこちらのブログでSpannerクローンが本家同様のConsistency(ここではLinearizability) を保証できない点を指摘している。
また、こちらのブログではTrueTime APIの代わりに用いられるHLC(Hyblid Logical Clock) を、従来のDBMSで用いられてきたLSN(Log Sequence Number) との違いなどにも言及しつつ解説している。
一つここで述べておくべきことは、Spannerクローンとして紹介してきたCockroachDBやYugaByteDBと、TiDB/TiKVの分散トランザクション管理の方式の違いだろう。それぞれが用いるクロックソリューションには以下の違いがある。
- Spanner: TrueTime API
- CockroachDB: HLC (YugaByteDBとは少し異なる可能性がある)
- YugaByteDB: HLC
- TiKV: TSO (Timestamp Oracle)
つまり、SpannerとCockroachDB・YugaByteDBは分散時計(原子時計とHLCで異なるものの)を用いて、Spanner論文で示された方式の分散トランザクション管理を行う。
しかし、TiKVはGoogleが2010年に発表した「Large-scale Incremental Processing Using Distributed Transactions and Notifications」という論文で示されたPercolatorという方式に基づいてトランザクション管理を行う。Percolatorは集中時計(分散していない) を前提としており、TiKVではTSOとして集中時計をPlacement Driver(PD) に設置する構成となっている。ドキュメントはこちらを参照。
※PDについては前回説明したTiKVアーキテクチャにも登場している。
こうしたトランザクション管理方式の違いにより、スループットやコミットのレイテンシに違いが生まれることはこちらのブログにも解説されている。
まとめ
今回の投稿ではSpannerクローンと言われるNewSQLがどのような技術を用いて、「強い整合性を持ち、ACIDトランザクションをサポートする、(地球規模の)分散型のSQLデータベース」を実現しているか、4つの分類でそれぞれ解説を行った。
ただ、LSM TreeベースのストレージエンジンもShardingもRaftも、分散トランザクションもNewSQLで新たに発見された技術要素ではない。いずれも広範な用途の分散システムでの利用を目指して研究された成果だ。
こうした技術の組み合わせでSpannerやその他NewSQLも成り立っていることが理解頂けたとしたら、今回記事を公開した意味がある。
一方で今回記事はNewSQLの技術的要素を理解するのに役立つものの、実際にどのようなユースケースで使うべきかは殆ど述べていない。この点についてはSpannerクローンのPoCを検討したいと思っているので、興味があり一緒にやりたいという方の連絡もお待ちしている。
具体的なユースケースはまだないのだが、Spannerとは少し違う用途での利用も考えている。
例えば、地球規模で分散が必要でWriteヘビーなワークロードにSpannerが使われるケースが多いが、今回整理した特徴からNewSQLはそのためだけのものではないことが分かる。
これまでモノリスなRDBMSが苦手としてきた、低信頼で高遅延な分散システム上で、スケールアウト可能なデータベースを構築する要件にもフィットする可能性がある。
低信頼で高遅延?そんなところでアプリケーションを動かす予定はない??
そんなことはない。それがコンテナであり、現在のKubernetesであるというのが私個人の見解である。
PoCの結果が出れば、その内容はこうしてQiitaに投稿するか、またはカンファレンス等で発表することを目指すつもりだ。
ここまで2回も長文の投稿に付き合って頂いた読者の皆様に感謝する。
(参考情報) 前回、今回投稿の前提となった一連のツイートは[こちら](https://togetter.com/li/1470195)。
改訂履歴
- 2020/3/15 冒頭の「NewSQLの解説は二部構成」と「前編のまとめ」を更新し、前回記事へのリンクを追加した。