概要
Raft は安全な ステートマシンレプリケーション (SMR; State Machine Replication) を実装するための分散合意アルゴリズム。分散システムにおいて一貫性 (分散トランザクション) と可用性 (障害耐性) を実装するための基本的な部品として使用することができる。
分散システムにおける合意 (Consensus) とは、参加しているすべてのノードが最終的に同じ値を採用すること (≒ 同じ状態になること) を意味します。このため、合意アルゴリズムは一貫性のあるレプリケーションを実現するために利用されます。
TL;DR
- Raft は強い一貫性のレプリケーションや分散実行を行うことができる。
- 合意に達したデータが破壊されるシナリオが存在しない。
- 長期間の停止や大幅に遅延したノードが Raft クラスタに復帰しても問題ない。
- ノード故障によるリーダー交代が発生しても問題ない。
- 役割分担もアルゴリズムも構成も簡単 (simplicity) で簡単 (easiness)。
- ノードの役割はリーダー、フォロワー、候補者の 3 つだけ。
- メッセージの流れはリーダー → フォロワー方向だけ。
- SMR の機構を理解するための最小限の範囲はリーダー選挙とログ複製の 2 点のみ。
- この記事ではその 2 つとメンバーシップ変更を説明。より実用的な実装にはさらに以下の考慮が必要だが分散合意とはあまり関係ないのでこの記事では省略。
- スナップショット (ログコンパクション)
- この記事ではその 2 つとメンバーシップ変更を説明。より実用的な実装にはさらに以下の考慮が必要だが分散合意とはあまり関係ないのでこの記事では省略。
前書き
「Raft の名前を知っている、仕組みに興味がある」から「英語の論文を読み解くのは時間コストが…」までの間で悶々としている人向けの記事です。パワー系プログラマであれば少し論文から補足すれば「俺が想像する Raft」を実装できると思います。
この記事は私が Raft の論文 In Search of an Understandable Consensus Algorithm (Extended Version)1 を読み、自分の言葉で説明することで理解を進めることを目的としています。また論文にかかれていない考察なども散文的に記述しています。The Raft Consensus Algorithm や Raft - Understandable Distributed Consensus のアニメーション説明と併せて読むと理解の助けになると思います。
(追記) 論文の著者による学位論文 Consensus: Bridging theory and practice2 は、元の論文1の内容を完全に内包しつつ、(研究誌に掲載するには冗長な) より詳細な意図や実験結果、実践的な洞察、追加の要件などについても書かれています。少し大きいですが、すでに論文を読んで理解した人や、Raft が現実世界で普及してきた今から読むのであればこちらがおすすめです (CC BY ライセンスなので日本語に翻訳しています)。
元々、Hyperledger Fabric というプライベートブロックチェーンが Raft で合意形成するという話を聞いて「Raft って Byzantine 障害耐性はないよね?」と論文を読み始めたことがきっかけなのでブロックチェーンの視点を交えています 。

State Machine Replication
可用性 (Availability) のある分散システムでは複数のノードがデータのコピーを持ち合うことで、あるノードが故障したとしても残ったノードでサービスを継続できるように設計します。State Machine Replication (SMR) はそのようなアイディアで複数のマシンにデータの複製を作るレプリケーション手法の一つです。可用性ありきの分散システム設計ではまず SMR のようなレプリケーション機構があり、一貫性 (Consistency) に振るのであればトランザクション (強い一貫性) を導入し、分断耐性 (Partition Tolerance) に振るのであれば結果整合性を導入します。
Raft は強い一貫性を持つ SMR に基づくアーキテクチャです。強い一貫性の SMR は、同じ初期状態から開始した複数の有限状態機械 (FSM) に同じコマンドを同じ順序で適用することで全てのマシンを同じ状態で遷移させます。Raft ではこのマルチキャストされるコマンドのことをログと読んでいます。
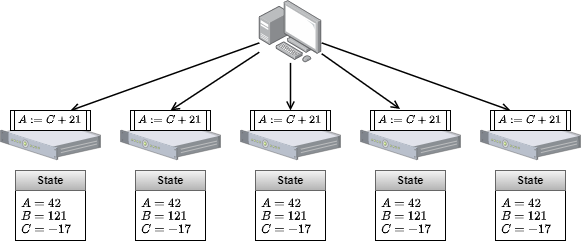
ここで問題が「どのようにしてログの適用順序を正しく決めるか?」です。非同期ネットワークでは、複数のマシンが同時にログを送信したとき、ネットワーク上でのログの伝播速度によって各 FSM への到着順序は容易に入れ替わります。そしてログの適用順序が FSM ごとに異なると、それらの FSM は互いに異なる状態を持ってしまうため強い一貫性が達成できなくなります。
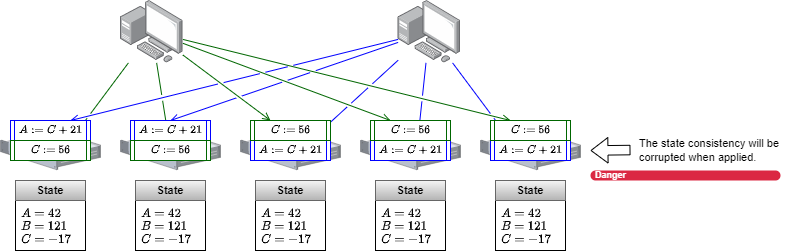
Raft (および多くの強い一貫性の設計) ではすべてのログは リーダー と呼ばれる 1 つの FSM に送信され、そのリーダーがログの順序を決定します。
もう一つの重要なことは、すべてのログの適用結果が決定的でなければならないという点です。ノードごとに異なるローカル時刻や OS またはライブラリ依存の動作などはノード間の状態矛盾を引き起こすため使用することはできません。またディスク不足のような実行環境固有の失敗が起きたノードは状態矛盾が発生している可能性があるため意図的にクラスタから離脱させる必要があるかもしれません。
可用性と分断耐性にノードの自立性を加えた設計は非構造型 P2P ネットワークの基盤として利用されています。Bitcoin を始めとするブロックチェーンの実装はトランザクションと呼ばれる不可分取引情報を改ざん不能な鎖状に連結して P2P ネットワークで共有し、それをすべてのノードで同じ順序で適用することで同じ状態を共有できるようにしています。これは SMR と同じ考え方に基づいています。ただし、そのための Proof of Work のような初期の機構はリーダー選出が確定的ではなく、そのため有限時間内に 100% の一貫性を保証することができないという (結果整合性よりさらに緩い確率的整合性とも言うべき) 結果をもたらしています。
障害モデル
Raft の設計は Crash-Recovery 耐性を持ちます。Crash-Recovery とは長時間の停止または大幅に遅延していたノードがクラスタに復帰する状況です。非同期の分散システムでは故障と遅延の区別がつかないことから、Crash-Recovery 耐性は Performance/Timing 耐性、Omission 耐性、Crash-Stop 耐性があることも意味します。
| Failure | Raft |
|---|---|
|
Crash-Stop 突然ネットワーク上から消失し二度と復帰しない。 |
✔ |
|
Omission 偶発的なメッセージのロスト。 |
✔ |
|
Performance, Timing 許容時間 $t$ 内での応答の遅れ。 |
✔ |
|
Crash-Recovery 状態遷移シーケンス上の過去の任意の位置からの復帰。 |
✔ |
|
Byzantine, Arbitrary 状態遷移シーケンスから逸脱。任意のタイミングで任意のメッセージ。悪意的行動。 |
Raft は Byzantine 障害に対する耐性がなく、論文を一見して恒久的なリーダーの乗っ取りからのログの改ざん、リーダー選挙の妨害などが可能であるところを見ても、P2P ではなく完全に管理されたネットワーク向けの合意アルゴリズム (CFT; Crash Fault-Tolerance) です。Byzantine 障害耐性が必要であれば Raft ではなくパフォーマンスを犠牲にして pBFT などを使う必要があるでしょう。
論文では Crash-Recovery より深刻な障害耐性には言及していないが (論説の範囲を外れるため当然だが)、もし実際に Raft を実装するなら現実的に想定される障害に対して工夫できる余地もいくつか存在します。例えば「テスト環境で使用していたノードの 1 つが事故で本番クラスタに『も』参加してしまった」といったような運用事故で起きうる障害は (大抵そのようなケースは任意障害の一ケースに分類される挙動を起こす) クラスタ識別子の導入などで回避できるでしょう。
基本的な構成
Raft は定足数 (quorum; Raft では過半数と同義) に基づくアルゴリズムのため実動想定のノード数は奇数構成が推奨されています。これは偶数にしても故障個所と定足数が増えるだけで障害許容ノード数は変わらず障害耐性が下がるためです。一般的に一貫性を提供する分散システムはノード間の通信頻度が非常に高く、特にリーダーが強い役割を持つ Raft ではノード数が増えればリーダーの負荷も大きくなります。このような強い一貫性型の分散システムでは、単独の合意クラスタとして 3、5、多くても 7 ノードが一般的と思います (論文では 5 ノードが最適としている)。それ以上の規模では、例えば非同期レプリケーションなど、一貫性を緩和して複数のクラスタ間で協調するような設計が必要となるでしょう。
Raft の合意クラスタは選挙によって選ばれた 1 つのリーダーとリーダー以外のフォロワーによって構成されています。これにリーダー選挙時の候補者を加えて、すべてのサーバはこれら 3 つの役割のうちの 1 つの役割が必ず割り当てられています。なお Raft の合意クラスタの初期状態は全てのサーバがフォロワーであり「リーダー選挙待ち」から開始します。
Raft の主要な動作はリーダー選挙とログ複製の 2 つだけです。それぞれに対応する、実装者が用意すべき API は RequestVote RPC と AppendEntries RPC の 2 つです。また論文では Joint Consensus なる方法で新しいノードの追加や離脱 (メンバーシップ変更) のアルゴリズムを紹介しています。
また論文では全てのログをそのまま保持するのではなく、ログを適用した状態のスナップショットを作成することでデータ容量を削減する「ログコンパクション」も提案していますが、トピックとしては分散合意とは性質が異なるためこの記事では扱っていません。
ログ複製
まずすべてのノードが正常に動作していると仮定し、Raft がどのようにして「一度クライアントに成功応答したら定足数以上のノードが機能している限り決してそのログが消えない」仕組みを達成しているかを見てみます。
全てのログは AppendEntries RPC を使ってリーダーからフォロワー方向にのみ伝達されます。リーダーは自分を含めて定足数のサーバがログを保存できたことを確認するとログの複製を達成したとみなしてローカルの状態にログを適用し(commit) クライアントに成功応答します。少し遅れて、フォロワーが次の Heartbeat もしくは AppendEntried RPC を受信したときにリーダーがどこまで commit したかが分かるため、その時点までのログをローカルの状態に適用します。
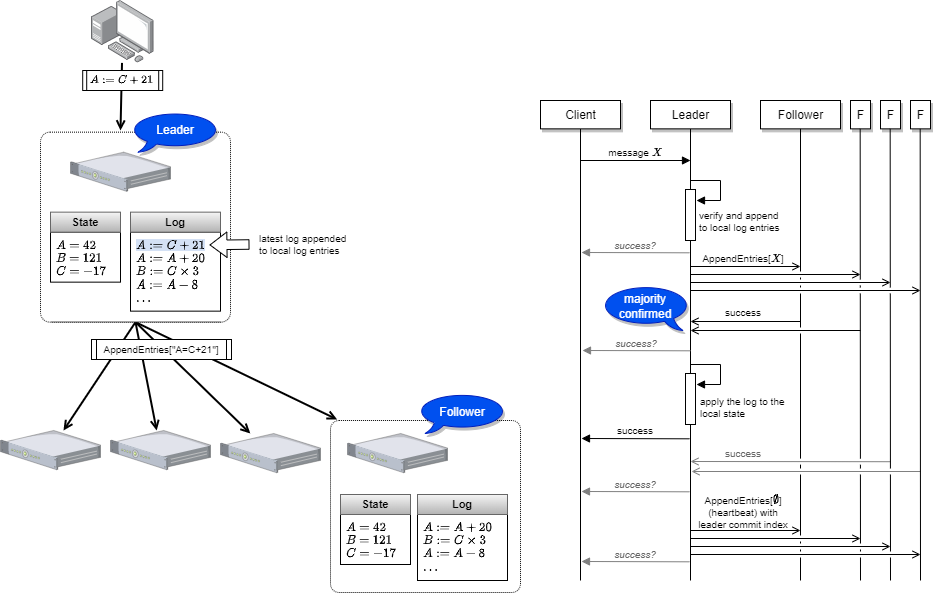
クライアントは (参照であれ更新であれ) 常に合意クラスタのリーダーと対話します。したがって、成功応答を受けたクライアントがすぐに問い合わせ返しても直前の命令を実行した状態を参照することができます。
一貫性レベル
上記のシーケンス図が示すように、リーダーがどの時点を完了とみなしてクライアントに応答するかには少し設計に余地があります。いくつかの分散データベースではこれらを一貫性レベルとしてパラメータ化しクライアント要求ごとに指定できるようになっています。
- リーダーがローカルのエントリにログを保存できた時点で
- クラスタ内の定足数以上がログの複製できた時点で (クラスタとして確定)
- クラスタ内のすべてがログを複製できた時点で
- リーダーが定足数のログ複製を確認しローカルの状態を更新した時点で (論文はここを示している)
- クラスタ内の定足数以上が状態を更新できた時点で
- クラスタ内のすべてが状態を更新できた時点で
上記の 1. は故障によるログ喪失の可能性がありますが重要なデータでなく高速な応答が求められるときに有用かもしれません。Raft の設計では 2. 以上であれば成功応答後すぐにリーダーが故障しても合意クラスタからログが消えることはありませんが、2. では成功応答直後のリクエストでまだログの適用結果が見えない可能性があります。成功応答=適用結果の参照可能を保証するのであれば 4. が必要だし (一般に一貫性と言えばここを意味する)、負荷分散のためにフォロワーを Read Only ノードとして利用しているのであれば 6. が必要な場面もあるかもしれません (通常は READ 処理もリーダーが担当する)。
他にも地理分散を想定して「1つのデータセンターが喪失しても残ったデータセンターで定足数を確保できるようになった時点で」といった方針も考えられます (強い一貫性の分散システムがデータセンターで分離されるケースはあまり見ないですが 最近は NewSQL と呼ばれるスケーラブルな SQL データベースの登場によってデータセンター間で Raft のような強い一貫性が利用されるようになってきています)。
死活監視
死活監視はリーダー役が機能していることを確認する動作です。合意クラスタ内のフォロワーはリーダーが機能していないことを検知すると速やかにリーダー選挙を開始します。
Raft ではリーダーから全てのフォロワーに対して定期的に Heartbeat を送信することでリーダーが故障していないことを知らせています。
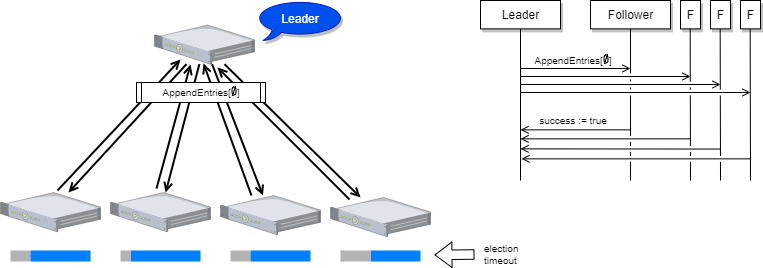
Heartbeat の実体は、リーダーからフォロワーに向けてログ複製のための AppendEntries RPC を複製ログ 0 件で呼び出しているだけです。AppendEntries RPC には選挙やログの世代がどこまで進んでいるかの情報も含まれていることから、長期間停止していたフォロワーが突然復帰したとしても、AppendEntries RPC のやりとりがあった時点で自分の状態が古くなっていることを認識することができます。
フォロワーはリーダーから一定時間 Heartbeat や通常のログ複製が到達しなければリーダーが故障したものとして新しい選挙を開始してリーダーに立候補します (この間隔を選挙タイムアウトと呼びます)。ここで、複数のフォロワーが同時に立候補してしまうと選挙を失敗させる split vote (後述) が発生しやすくなるため、Raft ではフォロワーごとの乱数で選挙タイムアウトを調整してます。例えば Heartbeat 間隔が 1 秒、Heartbeat 到達の最大許容遅延を 0.5 秒として選挙タイムアウトを 1 + 0.5 + 1.5 × rand() とすれば、同時の立候補者が出る確率を減らしつつ最悪でも 3 秒以内にリーダーの故障を検知できます。
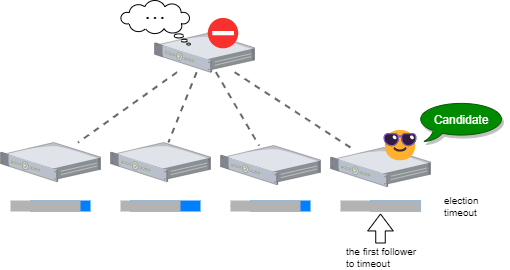
論文では選挙タイムアウトは Heartbeat 間隔より一桁大きい程度の見積もりを推奨しています。最短の選挙タイムアウトは、Heartbeat の現実的な平均ブロードキャスト応答時間 (RTT) を $t_b$ = 0.5~20ms と想定すると $t_e$ = 10~500ms 程度となり、これにサーバごとの乱数調整分が加算したあたりとなるでしょう。
ところで、乱数調整分をサーバごとの優先順位値 × $t_b$ のように設計すれば split vote も発生しづらく (確定的ではないが) リーダーの順序を方針づけることもできます。分散環境でのサーバの順位付けには起動タイムスタンプの古さなどいくつかの方法があります。
さて、リーダーの故障を検知したら次はリーダー選挙です。
リーダー選挙
Raft には選挙が行われるたびに単純増加するタームと呼ばれる数値があります。ある時点のタームを担当するリーダーは 1 つないしは 0 (選挙失敗時) であり、2 つ以上のリーダーが同一のタームに発生することはありません。
さて、合意クラスタ内のリーダー不在を検知したフォロワーはリーダーに立候補し候補者となります。候補者は自分の認識しているタームを一つ進め、自分に投票し、クラスタ内の他のサーバの RequestVote RPC (投票要求) を呼び出します。
RequestVote RPC を呼び出されたサーバは、自分がまだそのタームに投票しておらず、候補者の持つログが自分と同じかそれより新しければ投票を行います。さもなくば投票を拒否します。候補者がクラスタ内のサーバの定足数票を獲得すると新しいリーダーとなり Heartbeat をブロードキャストして自分が新しいタームのリーダーとなったことをクラスタの全サーバに通達します。
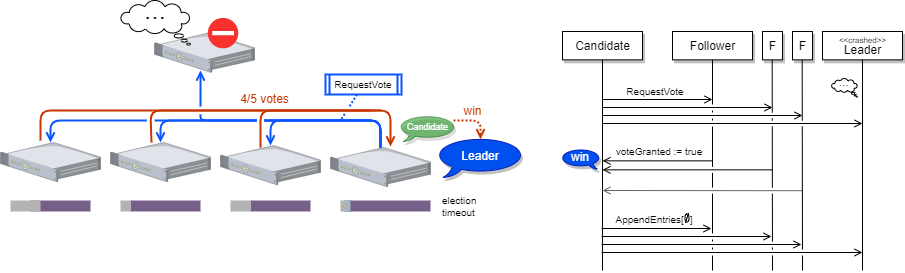
全てのフォロワーは、受信した Heartbeat (AppendEntries RPC) のタームが自分の認識しているタームより進んでいた場合、自分がそのタームの投票にどう関与したかにかかわらずその送信元のサーバを最新のリーダーと認識します (従ってもしクラスタ内に Byzantine ノードが存在した場合は選挙を行わずに容易にリーダーとなることができます)。
反対に、受信した Heartbeat が自分の認識しているタームより小さい場合、長期間故障停止していた古いリーダーが復帰して何も知らずに送信したものと推測できます。この時フォロワーは自分の認識している最新のターム付きで失敗応答を返すため、旧リーダーは自分がすでにリーダーではない事を知ることができます。
選挙の失敗
リーダー選挙はいくつかの理由で失敗することがあります。一つの例は合意クラスタ内の応答可能なサーバが定足数を下回っているケースです。このような状況ではどの候補者もリーダーになることはできません (これは Raft で Split Brain が発生した時に片方のクラスタがサービスを継続できない = 分断耐性がないことも意味しています)。
もう一つの例は Split Vote です。これは複数の候補者がほぼ同時に RequestVote RPC をブロードキャストし、クラスタ内のサーバの票が割れてどの候補者も定足数票を獲得できないケースです。
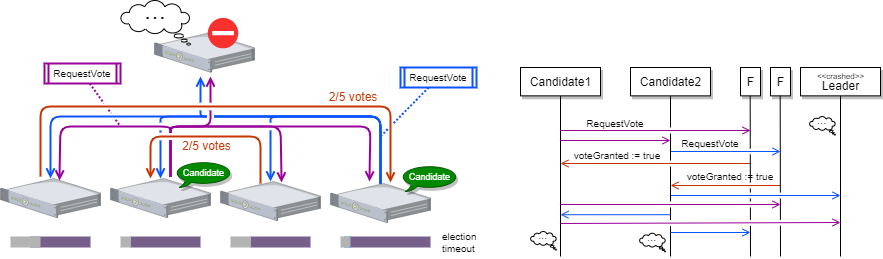
Split Vote に対処するため Raft は Heartbeat と全く同じタイムアウト機構を選挙時にも機能させています。つまり、RequestVote RPC で投票してから選挙タイムアウトの時間が経過しても新しいリーダーからの Heartbeat が到達しなかったサーバ (定足数を獲得できていない候補者も含む) は、そのタームの選挙が失敗したものとみなして、自分のタームを一つ進め、新しい選挙を開始して自分が立候補します。
機能回復時間
リーダーが故障してからクラスタが機能を回復するまでの時間を考えてみよう。Heartbeat の平均ブロードキャスト応答時間 (RTT) を $t_b$、選挙タイムアウトを $t_e$ とすると、リーダー故障からクラスタ機能回復までの各ステップに要する時間は以下のようになります。
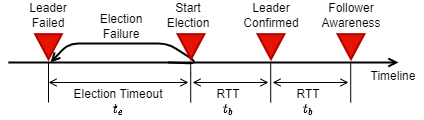
例えば $t_b$ = 20ms、$t_e$ = 500ms の環境では (リーダー以外の故障や split vote が発生しなければ) 最大 540ms 程度でクラスタ機能を回復することができるだろう。split vote が発生するケースでは選挙に失敗した回数だけ $t_e$ を繰り返します。つまり split vote のような選挙失敗の発生回数を $n_f$ とした場合 $t_e + n_f \times t_e + 2 t_b$ 程度で回復します。
ただし Raft では一度リーダーが故障して選挙が発生すると機能回復が有限時間内に終わることを保証することはできません。実際、合意クラスタ内にフォロワーが 20 ノードも存在すれば複数の立候補者が同時に立候補する確率も高くなり選挙失敗が連続する頻度は現実的に非常に高くなります。
これは安全性/障害耐性 (≒一貫性/可用性) を実装している非同期システムは有限時間内に処理を終了することを保証できないという FLP Impossibility が意味するところです。分散システムでのリーダー選挙という手法は split vote のような失敗状況が連続して発生することを完全に阻止することはできないことがよく知られています。しかし一方で、まさに Raft が行っているように (1) ランダムさと (2) クロックおよびタイムアウト機構の 2 つを導入することで現実的な問題とならないように設計することが可能ということもよく知られています。
クライアント
クライアントはどのようにして最新のリーダーを知ればよいでしょうか? すべてのフォロワーは現在のリーダーを知っています。合意クラスタ内のいずれかのサーバと接続し、もしそのサーバがリーダーでなければリーダーのアドレス付きで失敗応答するのは一つの方法となります (HTTP の 302 Found リダイレクト相当の動き)。あるいはそのサーバが代理となってリーダーにリクエストを転送することもできます。
整合性の回復
あるリーダーが継続して機能している間は、同一タームのログがリーダーからフォロワーに順に送られるだけであるため、フォロワー間で多少のログ受信のズレがあったとしてもそのうち回復するだろう。コミット済みのログが覆されることはない。では、一部のフォロワーのみが持っている未コミットのログはリーダー交代によってどう扱われるのだろうか?
まず Raft でコミットについて正確に理解しよう。ログエントリは、そのエントリを作成したリーダーから過半数のサーバに複製されるとコミットされる。これは、そのリーダーが作成していないログエントリ、つまりリーダー交代によって自分より前のリーダーから引き継がれた未コミットのログエントリについては、過半数に複製してもまだコミットされたとは見なされないという意味です。その後、そのリーダーが作成したログエントリがコミットされると、以前のログエントリもまとめてコミットされたことになります。
リーダーはログ内のどのエントリまでがコミットされたかを知っているため、AppendEntries RPC を使って各フォロワーに伝達します。コミットされたログエントリはステートマシンに安全に適用することができます。
リーダーが交代したとき、リーダーとフォロワーのログが完全に一致していなかったら何が起きるだろうか? まずリーダーは、自身の持っているログの末尾の位置を付けて AppendEntries RPC を送信します。フォロワーはこの位置が自身のログと矛盾していると否定で応答します。このときリーダーは、ログの位置を一つ戻して AppendEntries RPC を再送信します。この動作を繰り返すことで、リーダーとフォロワーでログが一致している末尾の位置を見つけることができます。引き続きリーダーは AppendEntries RPC を実行して、この位置から自身のログで上書きすることで、リーダーとフォロワーのログは同じ状態になります。
論文では、リーダーが一部にログを複製してすぐに交代するようなより複雑なケースについても、この方法で正しく回復できることを説明しています。
障害発生時の復旧動作
停止したフォロワーの復帰
リーダーは AppendEntries RPC に応答しないフォロワーを検出すると、比較的短時間で復帰することを期待して定期的に同じ RPC を実行します。ただしこれは単なる投機的行動です。
リーダー交代前にフォロワーが復帰した場合、リトライしていたログから順に再送信されフォロワーの状態は復元します。停止中にリーダー交代があった場合は、新しいリーダーも停止を検知して同じように送信を繰り返しますが、新しいリーダーが送っているログは復旧に必要なログの正しいインデックスではない可能性があります。この場合、フォロワーが復帰してもログ複製は拒否され、応答で正しいログのインデックスを返します。リーダーはその正しいインデックスから再送信します。
Heartbeat がログ複製と同じ AppendEntiries RPC であることを考えれば、この再送信処理はなくても Heartbeat が到達した時点で再送信処理が開始します。
リーダー停止からの復旧
フォロワーがリーダーの停止を検出すると新しい選挙が始まり次のリーダーが選出されます。ではこのとき処理中のログはどうなるだろうか?
Raft では、投票要求を行った候補者の確定済みログの位置が自分より送れていると投票を拒否します。ログの確定は合意クラスタの定足数の受理によって進むため、つまり定足数に複製されている最新ログを持っていない候補者は定足数票を取り得ない仕組みになっています。さらに言い換えると、定足数票を得た新リーダーは、少なくとも最新の確定済みログの複製を持っていることが保証されます (Leader Completeness Property)。
リーダーがクライアントに応答する前にクラッシュしたとき、要求した処理はどうなるだろうか? ログ複製の進行状況によっていくつかのシナリオが考えられます。
- ログが定足数のサーバに複製されていれば、ログは確定しており新リーダーもそのログを持っている。
- ログが定足数のサーバに複製されなければ:
- 新リーダーが(たまたま)そのログを持っていれば:
- 新リーダーがそのログを複製/確定した時点でログは確定する (旧リーダーの処理を引き継ぐ挙動)。このとき、すでに旧リーダーから複製したログを持っているフォローワーは同じ内容のログで上書きする動作になる。
- 新リーダーがそのログを複製/確定する前に停止すれば、新しいリーダー選挙後に 2. へ戻る。
- 新リーダーがそのログを持っていなければ:
- 新リーダーが別の新しいログを受信/複製した時点で、一部のフォロワーに残っていたそのログは上書き/無効化される。
- 新リーダーが別の新しいログを受信/複製する前に停止すれば、新しいリーダー選挙後に 2. へ戻る。
- 新リーダーが(たまたま)そのログを持っていれば:
- 旧リーダーのローカルエントリに保存される前であれば、クラスタ内には物理的に存在せず無効。
結局のところ、適用されるケースも破棄されるケースもあり合意クラスタが復旧してみないと分からないという結論になります。また 2.2.1 で新しいログを受信しないケースや、2.1.2 や 2.2.2 を繰り返すケースがあるため、有限時間内にどちらかに定まる保証もありません。論文では、クライアントがログにユニークな番号をつけ、サーバ側でそのログが確定済みかを検査することで、失敗時にクライアントがリトライしても安全な設計を提案しています。
ネットワーク障害とリーダーリース
Raft 論文1は基本的なコンセンサスアルゴリズムの枠組みを示していますが、現実の分散環境ではネットワークの断絶や遅延などによってリーダーの認識が不安定になることがあります。このような状況で一貫性と可用性を両立するには、単純な読み取りリクエストを含むすべてのリクエストに応答するとき、現在のリーダーが自分であることを Raft クラスタ内で確認する必要があります。しかしこれは大きな非効率性を招きます。
etcd や KRaft は学位論文2で説明している Pre-Vote を導入しています。またクロックドリフトを検出したり修正する追加の機構が必要ですが、CockroachDB や TiDB、YugabyteDB などの実用的な Raft ベースの分散データベースでは、リーダーリース (Leader Lease) を導入することで非効率性を回避しながらネットワーク障害時にもクラスタの安定性を向上させることができます。
ネットワーク分断と Stale Read
Raft は「同じターム で複数のリーダーが選ばれることはない」ことを保証しますが、現実のネットワーク障害では ある時点で 複数のノードがリーダーとして動作する可能性があります。以下のシナリオを考えてみましょう。
ノード A, B, C が存在し、ターム $t$ においてリーダー A がフォロワー B, C に対してレプリケーションを行っています。クライアントはすべてリーダー A に接続してリクエストを送信しています。
ここでネットワーク障害が発生し、A が B と C のネットワークから切り離されてしまいました。このときクライアントも、A に接続し続けるものと、接続できなくなったものに分かれます。

Raft の設計では、ハートビートを受け取れなくなった B と C は、選挙タイムアウト後に新たなリーダーを選出します。ここでは B がターム $t+1$ のリーダーになり、新リーダーを認識した C とクライアントは B に接続を切り替えます。
しかし A に視点を移すと、ハートビートが送信できなくなったことは検知できても、他のノードからの投票要求 (RequestVote RPC) が届かないため、「自分はまだリーダーだ」という誤った認識を持ち続け、A と接続できているクライアントからのリクエストを処理しようと試みています。定足数の票を確保できない A が更新リクエストをコミットできないのは明白ですが、同様に参照リクエストにも応答はできません。これは、既に B がコミットした更新が存在している可能性がある ── つまり古い状態を返してしまう Stale Read を引き起こすためです。このため、線形可能性を保証するためには「この参照リクエストに応答する時点で自分が間違いなくリーダーだ」という確証が必要です。
この問題を素直に解決しようとすると、参照リクエストごとにフォロワーへ確認メッセージを送って定足数からの肯定応答を得てから応答する必要があります。この方法は etcd で ReadIndex RPC を追加して行っていますが、この方法ではパフォーマンス低下を招く懸念があります。
この課題は、Raft 論文の第 8 章でもさらっと触れられていますが、リーダーリースを導入することで緩和できます。リースとは、リーダー役が「あと $x$ 秒間だけリーダーでいられることを保証する」という期間をあらかじめ確保する設計です。具体的には、リーダーはハートビート送信時に「あと 10 秒間は私をリーダーとしてください」とフォロワーに依頼します。フォロワーはそれを承認すると、その期間内は他のノードからの投票要求を拒否します。結果として、リーダーはそのリース期間内であれば (例えネットワーク分断が起きていたとしても) リーダー交替が起こっていないことを確信できるため、フォロワーに問い合わせることなく参照リクエストに対してローカル状態だけで安全に応答できるようになります。
ネットワーク部分障害と Leader Flipping
もう一つのネットワーク障害を紹介します。これは Raft 論文1では言及されていませんが学位論文2の方で簡単な説明が見られます。
ノード A, B, C が存在し、ターム $t$ で A がリーダーです。ここで A - B 間のネットワークに障害が発生しました。それにより B はハートビートを受け取れなくなり、選挙タイムアウト後にターム $t+1$ の選挙を開始します。B - C 間のネットワークは機能しているため、C は B に投票し、B は新しいリーダーとして処理を進行します。
一方、B からのハートビートは A に到達しないため、A は B が新しいリーダーになっていることを知りません。しかし C へのハートビートの応答で現在のタームが $t+1$ に進んでいることを知ります。A は新しいリーダーからのハートビートを待ちますが、A - B 間のネットワーク障害でハートビートが到達しないため、選挙タイムアウトして新しい選挙を開始します。A はターム $t+2$ のリーダー選挙を開始すると、C は A に投票して A がターム $t+2$ のリーダーとなります。

この動作が繰り返され、結果として C がキャスティングボート (casting vote) のように振る舞いながら A と B が交互にリーダーを奪い合う Leader Flipping が発生します (リーダーベースのコンセンサス機構で考えられる現象の一つですが、特に名前も無いようなのでここでは Leader Flipping と呼びます)。この頻繁なリーダー切り替えは Raft の Safety や Liveness を破壊するわけではありませんが、コミットの停滞やクラスタ全体の深刻な性能劣化を招くことになります。
ここでもリーダーリースは有効に機能します。リースが設定されていると、ハートビートが到達する限り A が「リーダーでいる権利」を更新し続けるため、C は B の投票要求を受け取ったとしても投票を拒否します。結果的に、このようなネットワーク障害の下でも A がリーダーで居続け、クラスタの安定性を高めます。
余談ですが、このケースではノード B は選挙の開始と失敗を繰り返してタームをどんどん進めます。最終的にネットワークが回復すると、ノード B の開始した選挙が成功し (不必要なリーダー交替)、ログのタームが一気に進むことになります。これは Pre-Vote2 を導入することで回避できます。
実際に 2020 年に起きた Cloudflare の大規模障害では、これをさらに複雑化したネットワーク部分障害が起き、分割投票で誰も etcd のリーダーになれない状況となりました。
リーダーリースの問題
リーダーリースの欠点は、リーダーが「まだリース期間内である」と判断するためにローカルのクロックを使用することです。もしハードウェア障害でクロックが一時的に停止したり、遅れたり、後ろに戻ったりするクロックドリフト (Clock Drift) が発生すると、リースが失効しているにもかかわらずリーダーが応答してしまい、先述のようなネットワーク障害時に Stale Read を引き起こす可能性があります。つまり、単純なリースの使用は単一のハードウェア障害や時刻認識のズレで線形化可能性を崩す余地 (SPoF) が存在することになります。
代表的な Raft 実装の一つである etcd ではリーダーリースはオプションとなっており、デフォルトでは参照リクエストごとに定足数を確保して応答することで Stale Read を防ぐ方法を採用しています。そのためのオプションのコメントからクロックドリフトを意識してそうしていることがうかがえます。
// ReadOnlyLeaseBased ensures linearizability of the read only request by
// relying on the leader lease. It can be affected by clock drift.
// If the clock drift is unbounded, leader might keep the lease longer than it
// should (clock can move backward/pause without any bound). ReadIndex is not safe
// in that case.
ReadOnlyLeaseBased
加えて etcd は「最後のハートビート受信から選挙タイムアウトまでの期間」をリース期間のように扱っています。フォロワーはその期間に受信した投票要求 (etcd では正確には PreVote 要求) を無視するため、Leader Flipping のような事態が起きる可能性を大幅に軽減しています。フォロワーの一つでクロックドリフトが起きても、最悪、投票要求に間違った 1 票を投じられてしまうだけで大きな問題にならないことに注意してください。
etcd はクラスタ構成やサービスディスカバリといったメタデータを扱うことから強い線形可能性が必要です。しかし、その運用特性上、必ずしも同一データセンター内の NTP と同期できるとは限りません。このため物理クロックや NTP 同期に依存しない方針で定足数票方式を採用しています。
一方、TiDB や YugabyteDB では分散トランザクション機構 (TSO, HLC や Safe Time) がクロックドリフトを検出し、クロックスキューが発生しているノードを切り離したりエラーを返したりして、ある程度の許容範囲で時刻が同期していることを保証しています (厳密には監視によるものなので完全な障害耐性ではありませんが、発生リスクを考慮して性能を優先しているように見えます)。
クラスタの構成変更
Raft の合意クラスタに新しいノードが参加したり既存のノードが離脱する場合、Joint Consensus という仕組みで 2 段階の合意で構成を移行します。
例として、現在のクラスタ構成 C1 から新しい構成 C2 に変更することを考えます。ここで双方の和集合を C' = C1 ⋃ C2 とします。例えば C1 = {A,B,C}、C2 = {C,D,E} とすると C' = {A,B,C,D,E} です。
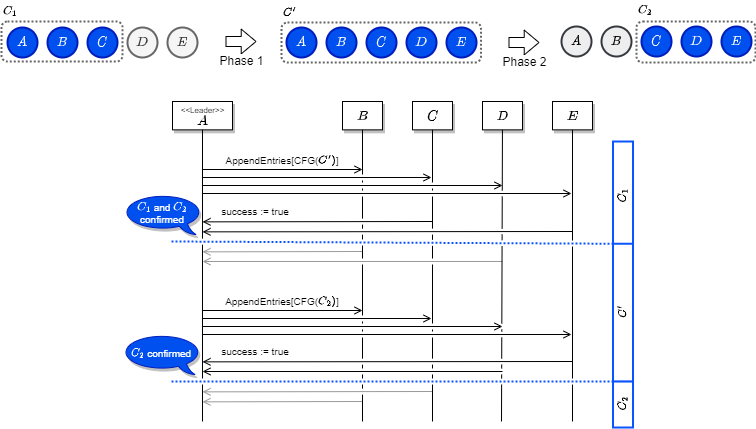
Joint Consensus が開始して完全に新しいクラスタへ移行するまで、Raft のノードは以下のようなルールに従います。
- リーダーは C1 と C2 に含まれるすべてのノードにログエントリを複製する。
- リーダーが故障したとき、C1 と C2 のどちらのノードもリーダーとなり得る。
- 選挙とコミットに関する合意の判断は、C1 と C2 の両方のクラスタで個別に定足数に到達しなければならない。
フェーズ 1: 和集合の構成に移行
リーダーが C2 への構成変更リクエストを受け付けると、まずその和集合である C' の構成に移行します。リーダーは C' への構成変更ログを自身のログエントリに保存し、前述のログ複製を使用して C' に含まれるすべてのノードにこの構成変更ログを送信します。この構成変更ログは特別扱いで、コミット前であってもリーダーとフォロワーは C' の構成を認識します。
C' への構成変更のログ複製で「C1 に含まれる定足数と C2 に含まれる定足数から」複製成功の応答があると、リーダーは C' への構成変更ログがコミットされたと認識します。
フェーズ 2: 新しい構成に移行
リーダーは C' の構成変更がコミットされたと認識すると C2 への構成変更を開始します。リーダーは C2 への構成変更ログを自身のログエントリに保存し、ログ複製を使用して C' に含まれるすべてのノードに C2 へ構成変更するログを送信します。
C2 への構成変更のログ複製では「C2 に含まれる定足数」からの複製成功の応答があると、リーダーは C2 への構成変更ログがコミットされたと認識します。
問題と解決方法
論文では次の 3 つの問題とその解決策について説明しています。ただ論文の記述以外にも考えられる問題はあるかもしれませんし、他にも良いアイディアがあるかもしれません。
- 新しく参加するサーバが初期状態だと、状態が追いつくまでかなりの時間がかかってしまう問題。これは、フォロワーだが合意に参加しない (つまり立候補したり定足数に数えられない) 役割を追加し、現在の状態まで追いついたところでクラスタへの参加を開始する。
- 構成変更で現在のリーダーが新しいクラスタに含まれていない問題。これは、リーダーが新しい構成 C2 がコミットした時点で自分をフォロワーに降格させ、C2 で新しいリーダー選挙を行わせる。C2 に属さないリーダーが C2 を管理している瞬間が発生し、またその間はリーダーは自分を定足数にカウントしないことに注意。
- 離脱させたサーバがまだ C1 または C' の構成だと認識していると、Heartbeat を受け取らないため新しい選挙を開始して C2 のリーダーをフォロワーに降格させてしまう問題。これは、最後の Heartbeat 受信から最小選挙タイムアウトが経過する前に受信した RequestVote RPC を無視するように動けばよいと書かれている (が、そもそも C2 に属さないサーバからの RequestVote RPC は無視すればよいのでは)。
過半数が故障したら?
見ての通り Joint Consensus はオンラインで動作しながら構成変更を行うことを目的としていて、リーダーが正しく機能していることを前提としています。定足数以上のサーバが故障している状況でどのように復旧するかは論文では特に示されていません。
構成変更中にリーダーが故障したら?
Joint Consensus 中にリーダーがクラッシュした場合、あるノードは旧構成と認識し、別のノードは新構成と認識している状態となる可能性があります。それでも Raft では 1 つのタームに 2 つのリーダーが出現しないように設計されています。
例として次のような障害パターンを考えています。

(1) クラスタ C1 = {A, B, C} と C2 = {C, D, E, F, G} があります。現在 C1 が Raft の合意クラスタとなっていて、リーダーは A です。
(2) リーダー A はクライアントから C1 → C2 の構成変更リクエストを受け付けました。ここで A は Joint Consensus が開始した状態になります。
(3) リーダー A は C1 と C2 に属するすべてのノードで Joint Consensus を開始しようとしますが、B と C にメッセージを受信する前に A が故障してしまいました。
(4) Heartbeat がタイムアウトし、B と F が同時にリーダー選挙に立候補しました。現在の構成が C1 と認識している B は {A, C} に RequestVote RPC を実行し、Joint Consensus 状態と認識している F は {A, B, C, D, E, G} に RequestVote RPC を実行します。
(5) B は C から票を獲得しました。B は自分が認識している C1 で定足数に達したので新しいリーダーになったと認識します。一方の F は D, E, G から票を獲得して C2 の定足数には達していますが、C1 からは定足数の票を得ていないため、選挙に勝ったと認識することはありません。「Joint Consensus 中の選挙は C1 と C2 のそれぞれのクラスタで定足数を得ないと勝ったとは言えない」と言うルールを思い出しましょう。
結果的にクライアントの構成変更リクエストは失敗しますが、同一タームで 2 つのリーダーが発生するような Safety を破壊する状態は回避できています。ただ、この状態のクラスタでは B は C1 にしか Heartbeat を行わないことから、C2 のノードの間では「立候補 ⇄ 選挙失敗」が延々と繰り返されることになるでしょう。
論文で挙げられている 3 つの問題の 3 つ目もそうですが、Joint Consensus 中に一部のノードが故障した場合、正当な Raft クラスタの外で「立候補 ⇄ 選挙失敗」を繰り返すノードが発生する可能性があります。
実装イメージ
以下は覚え書き程度に書き起こしただけなので詳細は論文の 5 章あたりを参照。この章はしばらくしたら更新するかもしれない。
ステートマシンの内部状態
Raft ステートマシンは以下のような内部状態で選挙とログ複製を実行するだろう。

Leader State は自分がリーダーの場合に使用する。サーバごとに次に送るべきログインデックスと、そのサーバと自分とで (タームも含めて) 一致している最も大きいログインデックスを保持している。
AppendEntries RPC
以下に AppendEntiries RPC の処理説明を擬似コードで記述する。
def AppendEntries(
term:Long, // リーダーのターム (0,1,2,...)
leaderId:Int, // このタームのリーダー
prevLogIndex:Long, // このリクエストのログエントリの直前のログインデックス (0,1,2,...)
prevLogTerm:Long, // prevLogIndex のターム (0,1,2,...)
entries:Array[Log], // 複製するログ (効率のため複数可; Heartbeat の場合は空)
leaderCommit:Long // リーダーが確定と認識しているログインデックス (0,1,2,...)
):(
term:Long, // フォロワーが認識している現在のターム (0,1,2,...)
success:Boolean // ログを複製した場合 true
) = {
if(term < this.currentTerm || // 旧世代のリーダーが Crash-Recovery した可能性
this.entries.length <= prevLogIndex || // 自分が Crash-Recovery した可能性
this.entries[prevLogIndex].term != prevLogTerm // 自分が Crash-Recovery した可能性
){
return (this.currentTerm, false)
}
// ログを複製する
for(i = 0; i < entries.length; i++){
this.entries[prevLogIndex + i].term = term
this.entries[prevLogIndex + i].log = entries[i]
}
// リーダーが確定と認識しているログの位置を合わせる
if(leaderCommit > this.commitIndex){
this.commitIndex = min(leaderCommit, prevLogIndex + entries.length)
}
this.currentTerm = term
return (this.currentTerm, true)
}
RequestVote RPC
以下に RequestVote RPC の処理説明を擬似コードで記述する。
def RequestVote(
term:Long, // 候補者のターム (0,1,2,...)
candidateId:Int, // 候補者ID
lastLogIndex:Long, // 候補者の持つ最新のログインデックス (0,1,2,...)
lastLogTerm:Long // 候補者の持つ最新のターム (0,1,2,...)
):(
term:Long, // 投票者が認識している現在のターム (0,1,2,...)
voteGranted:Boolean // 候補者に投票した場合 true
) = {
if(
term < this.currentTerm || // 旧世代のリーダー/候補者が Crash-Recovery した可能性
(this.votedFor != null && this.votedFor != candidateId) || // 別の候補者に投票済み
(論文参照) // 候補者の持つログが自分より古い
){
return (this.currentTerm, false)
}
this.votedFor = candidateId
return (this.currentTerm, true)
}
まとめ
この記事では Raft がどのようにして一貫性のある SMR を設計しているかについて説明しました。この記事は元の論文のみならず一部私見も交えています。動作の詳細な条件などは省略しているためプロダクション向けの分散データベースを実装しようとしている人には情報不足だと思いますが、勉強目的で Raft の動きを理解したい人や実装してみたい人、あるいは etcd のような Raft 実装の API の意味や内部動作を理解したい人の参考になればよいと思います。
❏