Disclaimer
当記事はNewSQL開発ベンダの技術ブログや各種論文、その他ニュースサイト等の内容を個人的にまとめたものです。
そのため、理解不足等に起因する誤解・誤認を含む可能性があります。更なる理解が必要な方はリファレンスに挙げた各種文献を直接参照下さい。技術的な指摘は可能であれば取り込み修正しますが、迅速な対応はお約束できません。
NewSQLの解説は二部構成
当記事は前編でNewSQLの概要編となる。
全体の目次は下記である。
- NewSQLとは何か
- NewSQLのアーキテクチャ
- NewSQLとこれまでのデータベースの比較
- NewSQLのコンポーネント詳解
1章から3章までの内容を当記事で解説する。
4章はさらに詳細な技術的解説となり、後編の「NewSQLのコンポーネント詳解」で記述している。
こちらも合わせて一読いただきたい。
1. NewSQLとは何か
NewSQLとは、海外メディアを中心に言及されることの多い、新しい形のSQLデータベースで、スケーラブル・分散アーキテクチャなど、過去のRDBMSにはない特徴を持つ。
その名前は過去にトレンドとなったNoSQL(Not Only SQL)を連想させるもので、アーキテクチャやトランザクションの考え方などはモノリシックなRDBMSとNoSQLの良い所どりを目標として設計されている。
2011/4のINFOQの記事 "NoSQL, NewSQL and Beyond"には、下図のように当時のDBMSが分類されている。
【DBMSの分類】
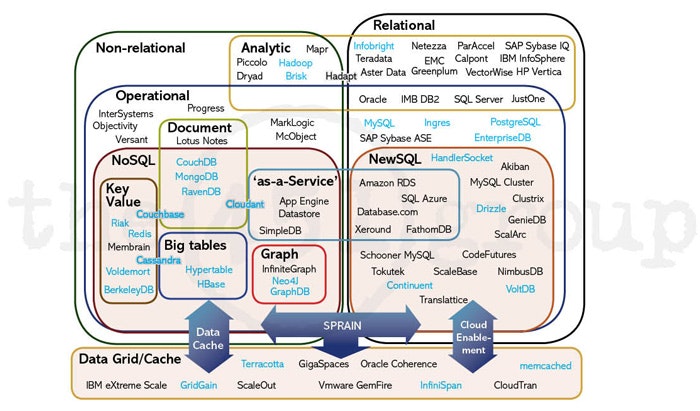
出典: <[NoSQL, NewSQL and Beyond](https://www.infoq.com/news/2011/04/newsql/)>
この図には大きく左半分にNon-releationalなDBが描かれ、その大部分はNoSQLと呼ばれるソフトウェアであることが分かる。RedisやMongoDB、Cassandraなど今でも生き残っているものはあるものの、当時の盛り上りは一段落した感がある。
そして、図の右半分にはRelationalなDBが描かれているが、この中にNewSQLが含まれている。ただし、これは2020年現在の状況とは大きく異なり、今は殆ど姿を見ないNewSQLの走り(ClustrixやVoltDBなど)や単なるManaged Service型のもの(Amazon RDSやSQL Azure)が混在している。
1.1. Google Cloud Spannerに見るNewSQLの一つの完成形
では、2020年の現在でNewSQLの代表的なサービスを一つあげるとすれば何か。
それはGoogle Cloud Spannerである。
2012年に**"Spanner: Google’s Globally Distributed Database"**として論文が発表され、Google内部で利用されていたが、2017年からはGoogle Cloud Spannerとして一般ユーザも利用可能となっている。
当記事はSpannerの解説ではないため、詳細はこちらの記事等を参照頂きたいが、その特徴は主に以下の3つがあげられる。
- SQLインターフェース
- 強い整合性
- トランザクションサポート
上記を特徴としながら、データセンターやリージョンを跨ったデータ複製を行って可用性を高めるとともに、グローバルなビジネスもサポートする。
Google Cloud Spannerのサービス紹介には、
「グローバルおよびリージョナル アプリケーション データ向けのスケーラブルなフルマネージド リレーショナル データベース サービス」
とあり、(横文字だらけだが) Googleが作った最強のRDBサービスであることは伝わってくる。
Spannerは国内でも決済サービスなどシビアなユースケースでの利用実績があり、今後も利用する企業・サービスは増えてくるものと思われる。
1.1.1 なぜSpannerが必要とされるか
詳細は後述するが、
- 従来のRDBはスケーラビリティが限界に来ており、
- NoSQLの上に複雑なアプリケーションを組むことは想像以上に難しかった
というのが主な理由だろう。
例えば、RDBMSでもリードレプリカとRedisのようなメモリKVSを使うことでRead/Writeの性能をスケールすることはこれまでも行われてきた。しかし、それでもレプリケーションラグや書込み遅延などでデータの整合性が保たれないタイミングは存在し、構成を複雑化した苦労が報われたかというと疑問は残る。
そのため、更にスケーラビリティを必要とする(特にWriteヘビーな) ユースケースでCassandraなどのNoSQLを使うこともあった。しかしこの場合、整合性に関してはDBの責務ではなく、アプリケーション側で最大限の考慮をする必要が出てくる。
こうしたRead/Writeともにスケーラブルでありながら、かつデータの整合性が何時如何なる時も保たれるデータベースが求められ、それに現状で最も近いものがSpannerであるということになる。
1.2 Spannerクローンの勃興
冒頭の2011年のINFOQ記事にもあるように、当時からNewSQLという分野は存在し、様々な製品が開発されてきた。現在でもMySQL NDB Clusterはアーキテクチャ的に完全にNewSQLに見えるし、その他にもVoltDBやFoundationDB、NuoDBなど当時から生き残っているものもいくつか存在する。
しかし、Spannerの発表後、それまでとは異なる形でNewSQLを実現する製品がいくつか現れている。
当記事ではそうしたデータベース(Spannerクローンと呼んでよいだろう) を3つほど紹介する。
- CockroachDB
- TiDB
- YugaByteDB
これらはSpannerをベースに少しずつ異なる設計思想と技術要素を以て、
強い整合性を持ち、ACIDトランザクションをサポートする、(地球規模の)分散型のSQLデータベース
を提供する。
これらの製品を利用することで、Google CloudユーザでなくてもSpannerに近いデータベース基盤を構築し、より効率的で柔軟なアプリケーション開発が可能であると各ベンダは主張している。
これらのNewSQLに共通する、または部分的に異なるアーキテクチャは2章以降で詳述する。
1.3 Spannerの欠点とそれを改善するもの
現状で利用可能なNewSQLとして一つの理想形であるSpannerだが、もちろん何の欠点もないわけではない。
そもそも地理的に分散された環境下で、強い整合性を持ち、トランザクションをサポートすること自体が簡単なことではない。
アカデミックな視点では、Spannerと頻繁に比較されるのがCalvinである。
こちらも2012年に**"Calvin: Fast Distributed Transactions for Partitioned Database Systems"**として論文が発表されている。
詳細は別稿のトランザクションの説明において触れたいと思うが、Spannerやそのクローンで弱点となるPaxosやRaftによる通信のオーバヘッドを削減し、整合性担保と性能を両立することを目的としている。
Calvinとその亜種の研究は継続されており、分散データベースの一つの流れとなっているとも言える。
また、CalvinをベースとしたデータベースサービスとしてFaunaDBが提供されている。こちらはSQLベースではないため、今回のNewSQLの範疇では扱わないが興味深いサービスとなっている。
1.4 ここまでのまとめ
2012年のSpanner発表以降、NewSQLの潮流に変化が現れた。
2020年現在、NewSQLの定義は以下のようになる。
強い整合性を持ち、ACIDトランザクションをサポートする、(地球規模の)分散型のSQLデータベース
2. NewSQLのアーキテクチャ
NewSQLでは、従来のRDBMSに内包されていた各種コンポーネントを分割し、それぞれにスケール可能な構成を取る。
また、大きな特徴としてマルチマスター構成であることがあげられる。どれかのサーバがプライマリ、他はセカンダリまたはRead-Onlyということではなく、クラスタ内の全てのサーバがMasterとして稼働する(厳密にいうと少し違うのだが、それは3章以降で詳述する)。
大まかにいうと、以下の3つのコンポーネントを持ち、これらをどのようにサーバにDeployするかは各製品ごとに設計思想が少しづつ異なっている。
- SQLクエリエンジン
- 分散トランザクションマネージャ
- ストレージエンジン(分散ストレージ)
2.1 Spannerのアーキテクチャ
Spannerのアーキテクチャはこちらのブログが詳しい。
【Google Cloud Spannerのアーキテクチャ】
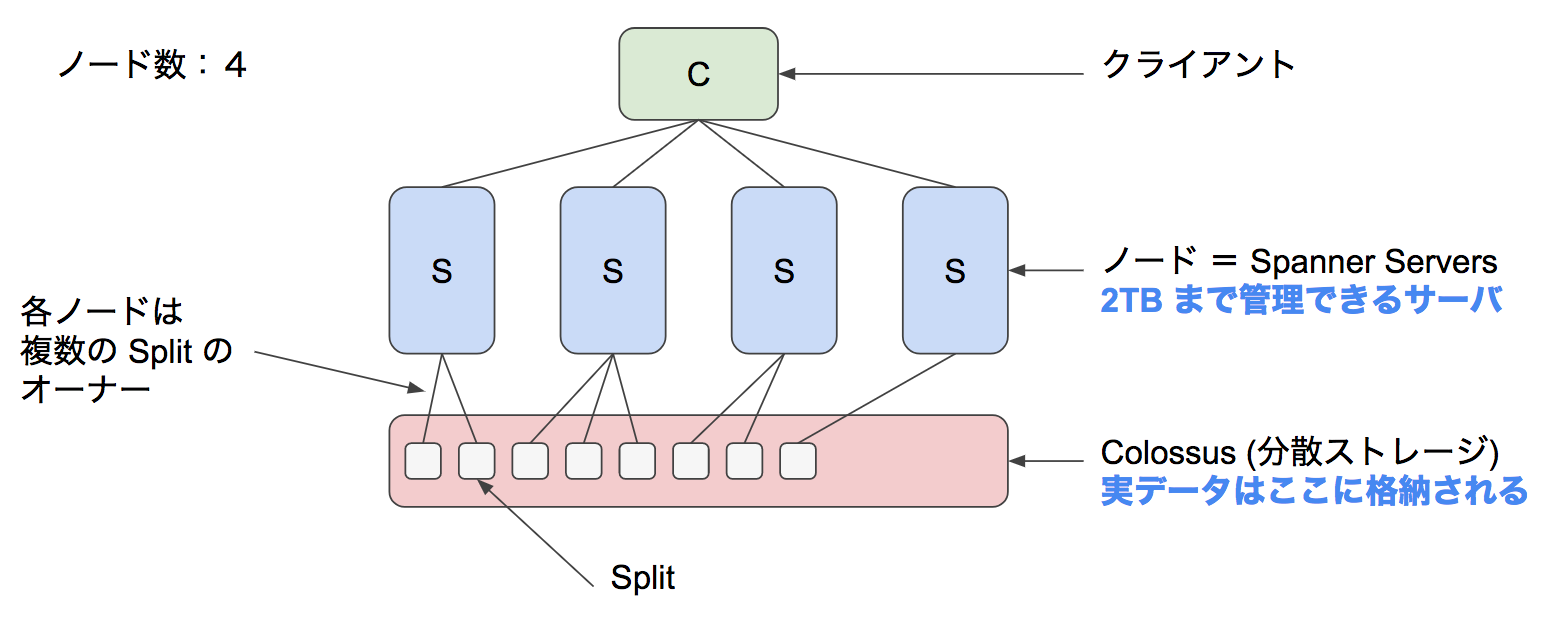
出典: <[Cloud Spanner のハイレベルアーキテクチャ解説](https://medium.com/google-cloud-jp/cloud-spanner-%E3%81%AE%E3%83%8F%E3%82%A4%E3%83%AC%E3%83%99%E3%83%AB%E3%82%A2%E3%83%BC%E3%82%AD%E3%83%86%E3%82%AF%E3%83%81%E3%83%A3%E8%A7%A3%E8%AA%AC-fee62c17f7ed)>
Spannerは2TBまでのデータを管理するノード(Spanner Server) と、分散ストレージであるColossusに分かれる。
クライアントはgRPCまたはREST APIでノードへ接続し、各ノードはデータ実体を持たないため、ネットワーク経由で分散ストレージへアクセスしてデータを取得する。
論文を見ると、Spanner Serverにはクエリエンジンとトランザクションマネージャが含まれ、Colossusは当然分散ストレージレイヤを担当する(なお、論文中ではSplitではなくTabletという記述になっている) 。
1ノードごとに3つのレプリカが構成され、ノード間のレプリケーションはPaxosを用いて行われている。このブログが書かれた当時はRW可能なのはUSリージョンのみだったようで、AsiaリージョンなどではROのみであったことが伺える(現状は未調査)。
RDBでいうところのテーブルは、Split(Shardingで言うところのshard) という単位に分割される。このSplitはいずれかのノードから管理される。
このSplitの分散状況がSpannerの性能に大きく関与するため、それを定義するPKの設定は重要な設計ポイントとなっている。
(2020/3/2追記)
SpannerはもちろんSQLで操作でき、ANSI2011規格の拡張SQLに対応しているとドキュメントに記載がある。
2.2 Spannerクローンのアーキテクチャ: YugabyteDB
YugaByteDBはSpannerの設計思想を踏襲しながらも、コンポーネントの配置はオリジナルと異なっている。
下図はYugaByteDBのアーキテクチャであるが、SQLクエリエンジン・分散トランザクションマネージャ・ストレージエンジンはレイヤとしては分かれているものの、クラスタ内のノードに一様に配置されている。
【YugaByteDBのアーキテクチャ】

出典: <[What is Distributed SQL?](https://blog.yugabyte.com/what-is-distributed-sql/)>
つまり、分散ストレージに対してComputeノードがネットワークアクセスを行う構造ではなく、各ノードローカルのストレージエンジン(RocksDBをベースにしたDocDBといわれるもの) に上位レイヤがアクセスする形となる。
データの複製はノード間で行われるため、全体としてみれば分散ストレージの構造を果たすが、この密結合度合いがSpannerとの最大の違いとなる。
Google Cloudのように大規模に分散ストレージを用意できない通常のユーザにとっては、これは適した手法にも見えるが、Computeとストレージを個別にスケール出来ないという点が問題になる場面も存在するだろう。
(2020/3/2追記)
YugaByteDBはSQLクエリエンジンだけでなく、Key-Valueのクエリエンジンも持っている。SQL APIはYSQLと呼ばれ、2020年2月現在でPostgreSQL11.2との互換性を持つ。Key-Value型のAPIはYCQLと呼ばれ、Cassandra Query Language(CQL)をベースに開発されている。
2.2.1 CockroachDB
CockroachDBもYugaByteDBと同じく、3つのコンポーネントを密結合した形で多数のノードに配置するクラスタ構成を取る。
YugaByteDBとの違いはCockroachDBでは、更に3つのコンポーネントが1バイナリに納まっていることである。1バイナリ(プロセス) か、複数バイナリかは設計思想の違いに拠るものであるが、両ベンダとも自身のアーキテクチャに利があると主張している。
(2020/3/2追記)
CockroachDBもYugaByteDBと同様にPostgreSQLと互換性がある。こちらのドキュメントによると、2020年2月時点でPostgreSQL9.6と互換性がある旨の記載がある。
2.3 Spannerクローンのアーキテクチャ: TiKV/TiDB
TiDBについては、これまで紹介したCockroachDB・YugaByteDBとは構成がかなり異なる。
というのも、前述の2つのSpannerクローンがSQLクエリエンジンとストレージエンジンを密結合してクラスタ内のノードに配置していたのに対して、TiDBではSpanner同様にComputeノードと分散ストレージが分離された構成を取る。
下図はTiDBのアーキテクチャとして示されているものであるが、この図から分かるのはTiDBはあくまで分散KVSであるTiKVのエコシステムの一部である、ということだ。
【TiKVを中心としたTiDB等のアーキテクチャ】
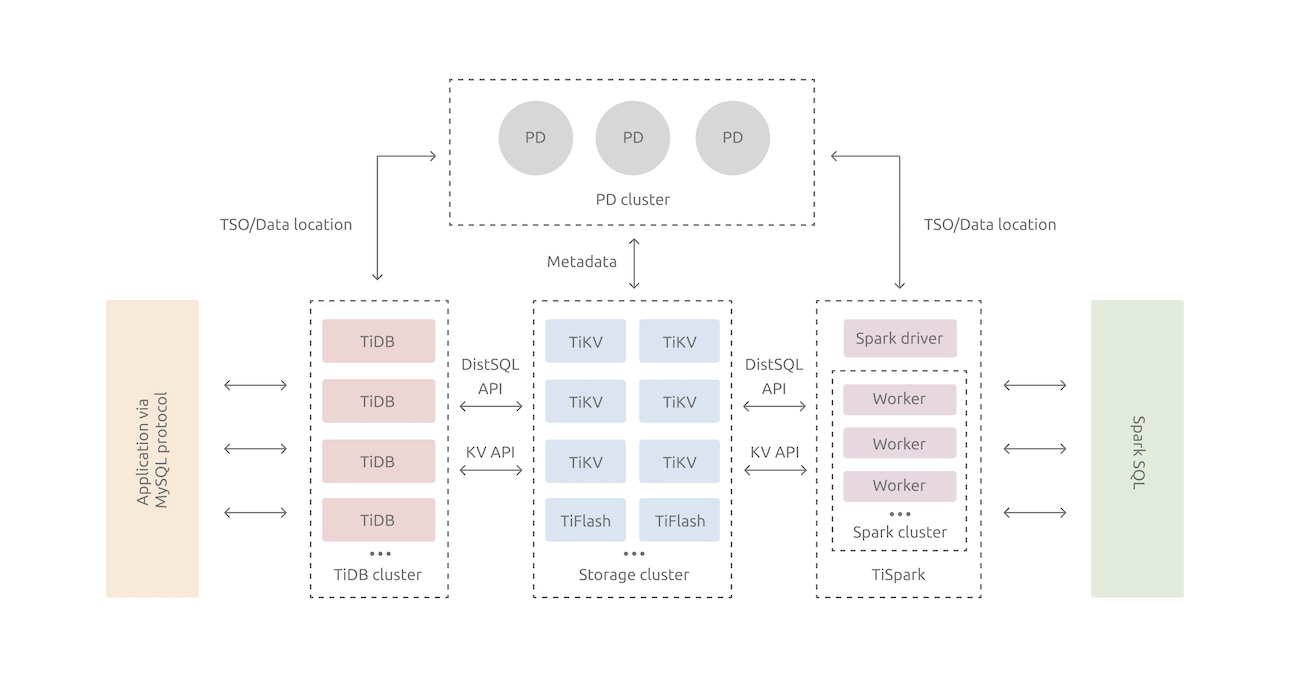
出典: <[TiDB Architecuture](https://pingcap.com/docs/stable/architecture/)>
分散データベースとしての機能は殆どTiKV上に実装されており、TiDBはMySQLインターフェースを提供し、裏側にある分散ストレージエンジン(=TiKV) へのアクセスを提供しているに過ぎない。
(2020/3/2追記)
SQLクエリエンジンについても、TiDBは前述のSpannerクローン2つと異なりMySQL互換である。
ドキュメントによれば、2020年現在でMySQL5.7互換となっている。
2.3.1 TiKV
では、TiDBの実体であるTiKVについてもう少し詳しく見ていこう。
TiKV自体はSQLインターフェースを持たない。下図にTiKVのアーキテクチャを示すが、TiDBのバックエンドとして使われる場合は図中のClientがTiDBとなり、そこでは真のクライアントに対してMySQL互換のSQLインターフェースを提供する。
【TiKVのアーキテクチャ】
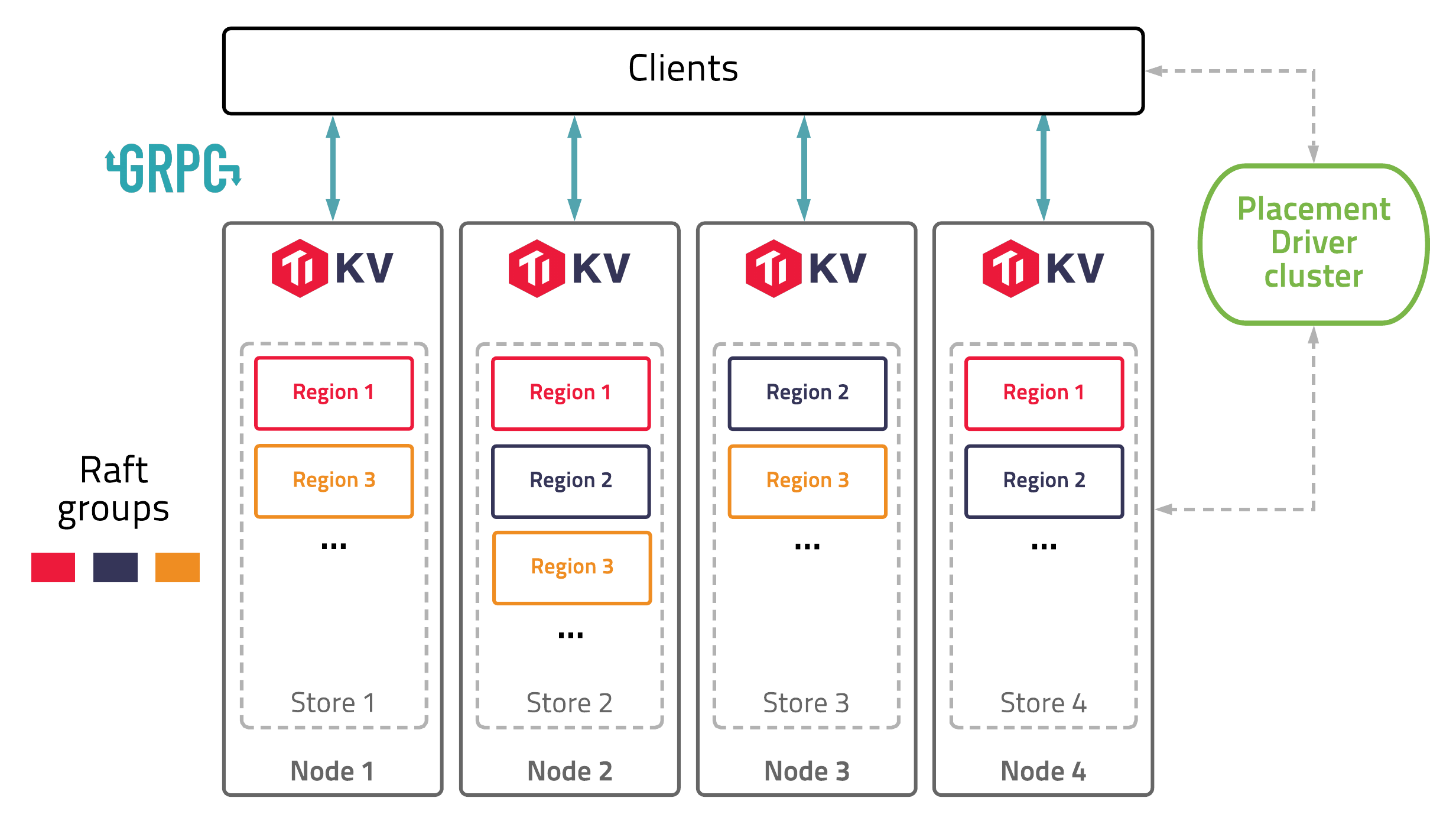
出典: <[TiKV | Architecure](https://tikv.org/docs/3.0/concepts/architecture/)>
上図のTiKV Nodeはトランザクション・マネージャとストレージエンジンを持ち、他ノードに分散したRaft Group内でデータの複製を行う。
ストレージエンジンはCockroachDBと同様にRocksDBを用いる。
そして、上図には他のSpannerクローンにはないPD(Placement Driver) というコンポーネントが存在する。このPDはTiKVのクラスタマネージャであり、データ配置を管理する。また、トランザクション時には重要な役目を果たすTimestamp Oracle(TSO) もここに存在する(TSO自体の説明は後日の別投稿にて) 。
このPDは非常に重要なコンポーネントのため、これ自体もRaftによる冗長化が行われている(前述のTiDBアーキテクチャにその構成が記載されている)。
2.4 ここまでのまとめ
Spannarおよびそのクローン達では、これまでモノリスなDBでは統合されていたコンポーネントを分割し、スケールさせるアーキテクチャを取っている。
SpannerではSQLクエリエンジンとトランザクションマネージャを同居させ、ストレージを分散させてNWアクセスしている。
YugaByteDBとCockroachDBでは3つのコンポーネントをノードに同居させるが、その組み合わせでスケールアウトさせていく。
TiDB/TiKVはどちらとも異なり、ステートレスなSQLクエリエンジンであるTiDBと分散KVSであるTiKVを組み合わせることでSpannerに近い構成を実現している。
3. NewSQLとこれまでのデータベースの比較
ここではNewSQLとそれまでのデータベースの何が違っているのかを比較するために、モノリスなRDBMSとNoSQL(Cassandra) の特徴を整理する。整理の観点にはSpannerの特徴を用いる(前述の3つにスケーラビリティを追加したもの)。
- SQLインターフェース
- 強い整合性
- トランザクションサポート
- 分散可能性、スケーラビリティ
更に(既に陳腐な表現になりつつあるものの) CAP定理のうち、何を満たすことを目標としているのかというのも一つの観点となるだろう。
3.1 モノリスなRDBMSの特徴
ここではOracle Databaseなどのプロプライエタリ、またはPostgreSQLやMySQLのようなOSSのRDBMSを想定する。歴史的な経緯から、モノリスなRDBMSは以下のようなPros/Consを持つ。
【Pros】
- SQL標準を準拠。
- ノードローカルな環境下で"妥当な"整合性(RC、RR) を実現。
【Cons】
- (一般的に性能を優先して)強い整合性を保証せず、アノマリーが発生。
- 限定されたスケーラビリティ。特にWriteヘビーに弱い。
- ネットワーク分断に弱い。低遅延・高信頼なネットワークを前提とする。
モノリスなRDBMSはスケールアウトに弱く、スケールアップによる拡張が採用されることが多い。また、単一DC(あるいは単一ラック) での運用が想定されており、HA構成などを採用したとしても、ノード間のインターコネクトは低遅延・高信頼なものを使うことが前提となる。
つまり、限定されたスケーラビリティに留めることで、その範囲内で整合性と可用性や性能などのバランスを取ることになる。
CAP定理でいえば、モノリスなRDBMSはACと言える。
3.1.1 RDBMSはスケーラビリティがない?
ここまで従来型のRDBMSの欠点について言及してきたが、公平性のために、RDBMSのスケールアウト手法についてもあげておく必要があるだろう。
あくまで複数リージョンや地理的な分散を前提とすると、RDBMSはスケールアウトがしづらいということであり、限定された条件下(過去には一般的であった条件でもある) ではRDBMSをスケールする技術が開発されている。
3.1.1.1 レプリケーション
もっとも多く使われるRDBMSのスケールアウト手法はレプリケーションであろう。多くのDBMSに組み込まれ、利用も容易である。
以下はPostgreSQLのStreaming Replicationの構成を示した図だが、このようにMasterノード(図中M)から複数のSlaveノード(S)にログ(WAL) を転送してデータを同期する。
【PostgreSQLのStreaming Replicationアーキテクチャ】
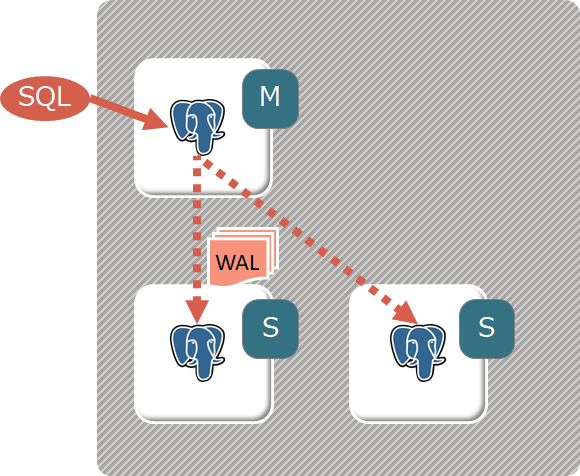
上図のMasterノードはReadもWriteも処理が可能で、SlaveノードはReadのみの処理が可能である。
つまり、この形式のレプリケーションで実現されるのはReadクエリのスケーラビリティのみである。
同期モードによって、Slaveノードへのアクセス時に見えるデータに違いがあり、完全な同期(Master側のCommitがSlaveのデータCommitを待つ) は可用性・性能に問題があるため、準同期(Master側のCommitはSlaveへのログ転送完了を待つ) が採用されることが多い。
物理的なログ(RedoログやWAL) の転送によるレプリケーション以外にも、SQLレベルで同期を実現するロジカルレプリケーションをサポートするDBMSも多いが、これも上記と同じようなデータ同期のラグが生じる。
また、可用性の観点ではMasterノードの障害時にSlaveノードのPromotion(いわゆるFailOver) が発生するが、その際のダウンタイムを問題視する意見もある。その解決策として、後述のマルチマスターが採用されるケースも存在する。
3.1.1.2 Sharding
古くから見られるもう一つのRDBMSスケールアウト手法はShardingである。
これはNewSQLでも採用されている技術で、データを多数のノードに分散配置し、それらを繋ぎ合わせることで一つの論理的な巨大データベースに見せる。近年ではCNCFのGraduated ProjectとなったVitessやAzure HyperScale(Citus)などに採用されており、再度注目されている。
下図はVitessの構成を示したイメージだが、Shardingでは全てのSQLリクエストを受け付けるCoordinatorノード(図中V) が存在する。その配下に通常のデータベースインスタンスが従属し、各インスタンスは自身に割り当てられた範囲のデータのみを保持する。
【Vitessのアーキテクチャ】
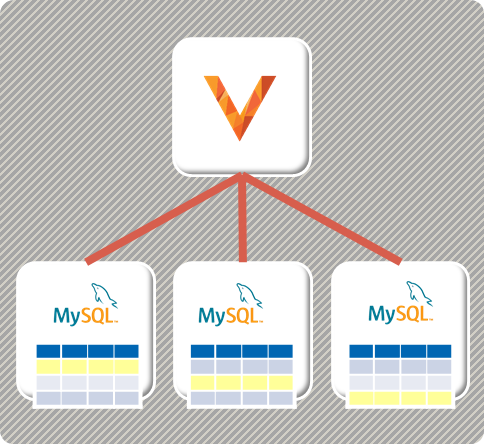
Read/Writeともに関係するインスタンスだけに送信されるため、データ範囲を細かく分割してインスタンスを増加させていくことで、水平方向のスケーラビリティが確保できる。
一方で問題はCoordinator部分の可用性と拡張性である。
図中ではここがSPOFになっているため、実際の運用ではHA構成を取ることが多いが、それでもレプリケーションと同様にFailOverが発生する。
実際のデータ処理は配下のインスタンスが担うものの、複数インスタンスのデータを集約するなどの処理はCoordinatorが担当するため、性能面でもボトルネックになることが想像される。
また、Shardingの最大の問題はデータ設計の難しさだろう。
データをアプリケーションのアクセスパターンに応じて適切に分割配置し、性能を向上させるためには単一インスタンスへのアクセスを理想として、トランザクションもその範囲内に閉じ込める。これは言うは易く、実際に行うのはとても難しい。
3.1.1.3 マルチマスター
レプリケーションとShardingと比較して構成・運用難度が高いものとして、マルチマスターなデータベースクラスタがある。
個人的な意見として、現在もっとも普及しているマルチマスター・データベースクラスタはOracleのRAC(Real Application Cluster) であろう。※異論は多そうだが。
下図はOracle RACの構成イメージで、一般的に言われるようにRACは「Shared Disk型のデータベースクラスタ」である。
【Oracle RACの構成イメージ】
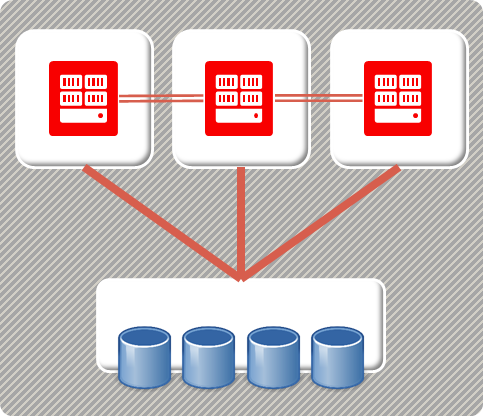
Oracle RACの詳細な技術解説は当記事ではしないが、構成としてデータを永続化するストレージは一つ(論理的には) で、その上位のノード間でデータベース・バッファ(つまりメモリ) を同期する形をとる。これにより、どのノードでもRead/Writeを処理することができ、ノードを増やすことでスケールアウトが可能となる。
但し、バッファ同期のために高速で安定したインターコネクトを必要とし、スケールアウトの限界も10台程度で、100台以上の規模で分散SQLデータベースを実現する技術ではないことに注意が必要である。
また可用性の観点でもノード障害による縮退時にはRAC再構成と言われる処理が走り、短くはない時間がかかる。共有ストレージも現在はASMなどの技術が使われ、単一障害点にはならないが、ここもスケーラビリティは気になる点である。
MySQLにもGroup Replicationと言われる機能でマルチマスターがサポートされているが、こちらはRACよりも更に限定的で性能観点ではなく、FailOver時の可用性低下を避ける技術のようである(MySQLに関しては筆者の知識が乏しいため、詳細割愛) 。
3.2 NoSQLの特徴
NoSQL全般について解説する知識は筆者にないため、ここではCassandraを念頭において、その特性を振り返る。なお、Cassandraの解説も古い知識に基づいている可能性があるので、最新は違うという場合はコメント等でご指摘頂きたい。
3.2.1 Cassandra
【Pros】
- スケーラビリティに優れる。線形スケールアウト可能とも評される。
- ネットワーク分断があっても何らかの形で動き続ける、高い可用性を持つ。
【Cons】
- SQLインターフェースを持たない。
- 整合性はEventual Consistencyと言われるもので、ほぼ何も保証ができないに等しい。
Cassandra自体はマルチマスターの構成を取り、各ノードでRead/Writeを捌くことが可能である。ノード追加によって性能はリニアに向上し、スケーラビリティに優れる。
一方で整合性担保は弱く、トランザクションをサポートしないため、書き込まれた最新のデータが読み出せないケースがある。Quoramを使ったReadにより整合性を上げることもできるが、その場合はレイテンシが犠牲となる。
データはConsistent Hashingと言われる手法でクラスタ内で分散され、さらに複数のレプリカが作られる。
ここまでのCassandraの特性をまとめると、いわゆるCAP定理のうち、Cを妥協したAPの構成と言える。
3.3 NewSQLの位置付け
ここまでの議論を振り返ると、以下のようにまとめることが出来る。
- モノリスなRDBMSはAC 、限定されたスケーラビリティの範囲内で可用性と妥当な整合性を実現している。
- NoSQL(Cassandra)はAP 、整合性を妥協し、可用性とネットワーク分断耐性を高めている。
しかし、ここで議論となってくるのはA(Availability) の意味である。システムに係わるエンジニアならば知る通り、どんなに最新の注意を払ってもAvailabilityが完全に担保されることはない。
クラウド隆盛の時代にあっても、Multi-AZやMulti-Region、さらにMulti-Cloudの構成を組んだとしても避けようのない障害(=Availabilityの低下) は発生する。
そのため、NewSQLでは完璧を求めずに妥協されたAvailabilityの元で、C(Consistency) とP(Partition-tolerance) を追求するという姿勢を取る。
つまり、**「NewSQLはCP、かつ妥協されたA」**がその設計目標と言える。
3.3.1 NewSQLは巨人の肩の上に
NewSQLでは、これまで上げたモノリスなRDBMSとNoSQLの特徴に加え、更に新たな技術を用いて強い整合性とトランザクションをサポートする。
【Pros】
- SQLインターフェースを用意: モノリスなRDBMSと同様
- Pで問題が発生しても整合性を維持: これは今までにない特徴で、Paxos/Raftで実現
- トランザクション分離レベルでいえばSerializableをサポート: モノリスなRDBMSを強化
- スケーラビリティを高めるためにデータを分散配置: ShardingやNoSQLと同じ考え方
さらに可用性を高めるためにShardingされたデータのレプリカを持ち、マルチマスターやCassandraの説明で見たようなFailOverの影響をなくす構成を取っている。
一方で妥協されたAの意味するものは、過半数以上のノードがダウンした際には更新が停止する(Readは継続できるケースがある) である。こうした状況はDC障害やリージョン全体の障害などめったに起きないケースではあるものの、もちろんゼロではない。
3.3.2 NewSQLはマルチマスターなのか
NewSQLはマルチマスターであるとこれまで述べているが、この点についてもう少し掘り下げて考えてみたい。
下図はYugaByteDBがデータをShardingし、各Shardのレプリカを別ノードに複製する構成を示している。(Shardingに関する詳細は後編4.2を参照)
【YugaByteDBのSharding、Shard冗長化の仕組み】
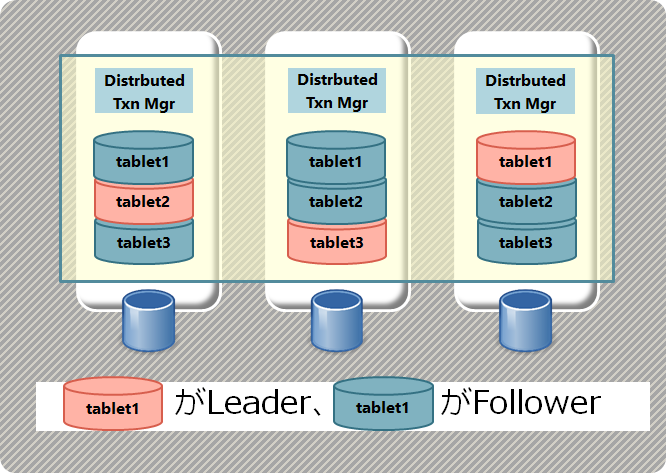
詳細は別稿で説明予定だが、基本的にRaftを用いるNewSQLではRaft Group内(図中でtablet1と書かれた横並びのレプリカがRaft Groupと同義) のLeaderだけがReadもWriteも処理可能である。
つまり、単一Raft Groupの観点ではNewSQLはマルチマスターとは言えない。
しかし、NewSQLではShard=Raft Groupなので一定サイズに分割された複数のRaft Groupが存在し、それらのLeaderは各ノードに分散配置される。つまり、マルチRaft Groupという観点ではマルチマスターなのである。
このRaft Group内のLeaderがReadもWriteも行う、そして一部の限定された条件下でReadをFollowerが行うことが出来るという特徴はNewSQLを理解する上で重要になってくる。
ここまでのまとめ
このエントリではNewSQLの出自と発展経緯、そして現在隆盛しているSpannerとそのクローンについての解説を試みた。
これらのNewSQLは何の問題を解決するものなのかを理解するためには、RDBMSやNoSQLの課題を理解する必要があり、それらに対する個人的見解を後半部でまとめている。
上記により、強い整合性を持ち、ACIDトランザクションをサポートする、(地球規模の)分散型のSQLデータベースという意味が明確化されたと思うが、実際の実装方法については触れていない。
後編「NewSQLのコンポーネント詳解」では下記の内容に触れ、さらに踏み込んだ解説を行なっている。
4. NewSQLのコンポーネント詳解
4.1 ストレージエンジン
4.2 Sharding
4.3 Raft
4.4 分散トランザクション
分散SQLデータベースとして、如何にデータをノードローカルに永続化し(ストレージエンジン)、クラスタ内に分散して配置し(Sharding)、冗長性・可用性を担保し(Raft)、整合性・一貫性を保ちつつ更新していくか(分散トランザクション)、について述べている。
こちらもご一読頂きたい。
(なお、この文脈であれば本来触れるべき、Google BigTableやAWS DynamoDBやAzure CosmosDB、またHBaseやKuduなどについては筆者に知見がなく全く触れていない。この点についてはご容赦頂きたい。)
改訂履歴
- 2020/3/2 2.に各製品のSQLクエリエンジンがどんな既存RDBMSと互換があるのかを追記した。
- 2020/3/15 後編「NewSQLのコンポーネント詳解」へのリンクを追加、まとめの内容も後編の目次に更新。