これまで多くのトランザクションの要素技術を説明してきた。
Googleの公開している論文Spanner: Google's Globally-Distributed Database は公開当初、要求される専門技術の多さからよくわからないと言っている人が多かったが、これまでに説明した要素技術をベースにすると理解しやすい。
Spannerとは
複数のデータセンターに跨ってデータベースの内容を複製し続ける事で高い可用性を実現するという構想は数多くあった。
しかしそれらの分散データベースは実用的な速度を実現しようとすると、データモデルがただのRDBより単純化して使いにくかったりトランザクションをサポートしなかったりと、アプリケーションの一貫性を実現するのが難しい。
現にGoogleの社内でもBigtableなどを用いたアプリケーションは複数あるものの、それぞれでそのデータモデルの上で無理やりトランザクションを再実装するためにあれこれ頑張った事例が多くそこでエンバグする事態が多発していたとSpannerの論文には書いてある。
そこで、一貫性とデータセンター間複製と性能とを鼎立する為に新たに設計されたのがSpannerである。
データモデル
いわゆるリレーショナル・データベースであり、SQL-Likeなクエリ言語をサポートする。(厳密にはキーバリューストアであるがクエリ言語がSQL-Likeなので)
個々のテーブルは複数のTabletという単位に自動的にshardingされたShared-Nothing構成となり。それぞれのTabletは複数のマシンでPaxosを用いて内容を全複製したShared-Everything構成からできている。JOIN対象のデータがインターリーブされていたりなどクエリを高速化するための工夫が複数入っているが、トランザクションと直接の関係は無いので省略する。
個々の行は値の他にタイムスタンプ付きのバージョン情報と過去のデータを保持する。つまり追記型のストレージであり、バージョンを指定することで任意の過去のデータを読みに行く事ができる。
トランザクションサポート
1つのトランザクション操作が複数のTabletに跨るか、1つのTabletに完結するかで使われる機能が違うが、複数のTabletに跨る操作の時はそれぞれのTabletの中のPaxosリーダーの間でTwo Phase Commit(2PC)を行って合意する。2PCは参加者が途中で音信不通になるとそこで停止するプロトコルだが、個々の参加者がPaxosで冗長化されているので停止の心配はない(ということになっている)。2PC及びPaxosの詳細に関しては並行制御とはやや遠い話なのでこの記事では扱わない。
読み書きをするトランザクションを実現するための並行制御にはStrict 2 Phase Lockを用いる。
すべてのトランザクションがStrict 2 Phase Lockを用いるならそこで並行性の問題は解決するのだが、Spannerでは読み込みオンリートランザクションか、読み書きトランザクションかで動作が異なる。「読み書きトランザクションの中でたまたま書き込みをしないもの」と「読み込みオンリートランザクション」はそもそも別物で、トランザクション開始時にユーザが明示的に宣言する必要がある。
トランザクションが読み込みオンリーの場合には、開始時にそのトランザクションは読み込みオンリートランザクションとしての実行パスを通るのだが、これを高速化するためにLockを用いずにデータをNon-Blockingに読み出す。Lockを用いずにデータを読み出すトランザクションであればOCCで説明したように、ValidationのステップでRead-Setを再度読んでバージョン番号の一致を確認すれば良い。が、Spannerはそれを選ばず、MVCCによる隔離を行う事で、Read-Setのvalidation不一致によるリトライすら不要にしてReadを高速化した。MVCCには複数の実装があるがSpannerが採用しているのはROMV(Read-Only Multi-Version)と呼ばれるものである。
さて、MVCCによってReadをNon-Blockingにすると、Writeとの調停が問題になる。
具体的には以下のようなケースの場合
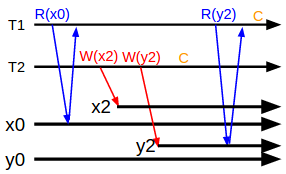
トランザクションT1はxとyの値が読みたいだけなのだが、途中でトランザクションT2が挟まって2つの値の最新版を作成してしまう。T1はT2の更新する2つの値の内片方だけを読んでしまうのでこれはSerialな実行結果にならない。いわゆるRead Skew Anomalyである。
T1は本来であれば(x0, y0)もしくは(x2, y2)の値を読んで欲しい、それを実現できそうな方法を列挙してみると
- x0を読んだ段階でT1がx0の値をロックすれば良いかというと、そもそも読み込みオンリートランザクションは読み書きトランザクション側をブロッキングしたくないのでロックするわけには行かない
- 例えばxとyの論理バージョンクロックを更新のたびにインクリメントさせるとしても、xとyが常に同時に更新されるとも限らないのでどのバージョンを読むべきかの手がかりとしては使えない
- WriteされたデータにすべてそのWriteが依存するデータの情報を保存すると(この場合、y2の書き込みの中にx2も更新したよというメタデータを埋め込む)トランザクションが増える程にメタデータが膨れ上がる
- 実時間のタイムスタンプをつけるとすると
xとyが別のマシンに置かれているとして、yの載ったマシンの時刻が⊿t秒遅れていたら、T1側が特定のタイムスタンプt1を指定してそれぞれをReadした時に、t1の時刻のx0と、t1+⊿tの時刻のy2を読みだしてしまって結局(x0, y2)を読みだしてしまう事になる。(⊿tが充分小さければいいのだが)
Spannerの実装
Spannerが最終的に提供する一貫性モデルであるExternal Consistencyに付いて説明し、それをナイーブな方法では実現できない事を示し、Spannerがそれをどう解決したかを説明する。
External Consistency
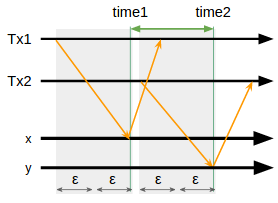
あるトランザクションが終わった後に始まったトランザクションは、前に終わったトランザクションより必ず大きいタイムスタンプを得る、という言葉に直すと何を当然の事をと言いたくなるような一貫性保証の事をExternal Consistencyと呼ぶ。トランザクションの開始・完了という論理的な概念に対して実時間の関係を定義している点が新しい。図で表すと
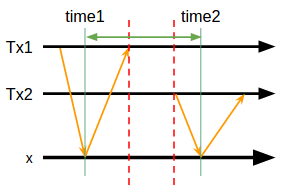
この図中で「Tx1が完全に終わった後にTx2が始まった」なら「_time2_は_time1_より大きい」という条件が常に満たされるのがExternal Consistencyである。
なぜExternal Consistencyは破られるか
値が1つしか無ければ、S2PLでロックしている以上、タイムスタンプとしてサーバ側の時刻を使用していればいくつのトランザクションが同時に書き換えに来ても、ロック中の時刻がタイムスタンプに採用されるのでロックによってタイムスタンプの順序はトランザクションの完了順へと直列化される。
しかし値が複数あり、それぞれが別のサーバ内で動いていたりしたら
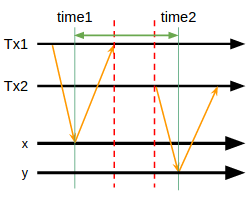
図中では_time1_の後に_time2_が来ているが、yを持っているサーバやクライアントのタイムスタンプのズレ⊿tが_time2 - time1_より大きかったら、yに記録されるタイムスタンプはxに記録されたタイムスタンプより過去の値となってしまいExternal Consistencyは破られる。
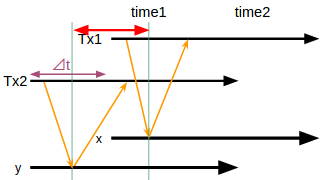
値が2つ程度ならその都度ネゴってタイムスタンプを決定しても良いがSpannerが相手にしているのは合計で億オーダーの行数を持つ数千マシンに跨るデータなのでその中でネゴるなど正気の沙汰ではない。
なので、昔から「分散システムでタイムスタンプを使うのは現実的ではない」というのが通説となっていた。
Spannerはどう解決したか
論文には小難しい式が書いてあるが、実際の所大した事はない。
Spannerが導入したのはCommit Waitという手法で、一言で表すなら「⊿tが_time2 - time1_より小さくなるよう余計な時間ロックを握りしめれば良い」というだけのものである。
システム内のサーバには可能な限り正確な時刻を獲得させる為にTrueTimeAPIという物を用いる。そのためにデータセンタに小型の原子時計をもたせるとかそんな話がインターネット界隈をどよめかせたが
- 参考: グーグル「Spanner」:地球大のリアルタイム・データベース
- 参考: Spanner再論 — Cyber-Physical Systemsとしての大規模分散データベース ←こっちは僕の理解と大きく異なるのでおすすめしない
実際のところ時刻の正確さはアルゴリズムの正しさとは何の関係もなく、NTPを使っても実現可能であるしもっと言うとNTPすら無くても良い。現にSpannerのオープンソースクローンの立ち位置にあるCockroachDBは公式のドキュメントに「原子時計なんて普通ないからNTPでいいよ」と書いている。
TrueTime API
Spannerの論文を読むとGPSやデータセンタから正確な時刻を獲得するAPIの事をTrueTimeAPIと呼ぶかのように早とちりしそうになるが、正確にはSpanner内の時刻のズレをε以下に抑えるように時刻を頻繁に再同期したり、どうしても時刻がズレすぎるマシンを故障としてSpannerからキックしたりする。
さて、システム内の時刻のズレがε以下に抑えられたということは、システム内で一番早い時刻を見ているマシンの時間はシステム内で一番遅い時刻を見ているマシンと比べて2εの時差を持つことになる。
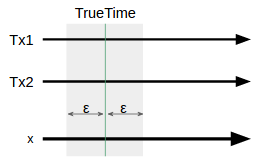
つまり、タイムスタンプのズレ⊿tの最大値が2εであるという事が保証できるようになる。
後は先ほどのケースでの_time2_ - time1 が⊿tより常に小さくなる方法を考えるだけである。
Commit Wait
読み書きを行うトランザクションはS2PLで走り、読み書きするデータのロックを獲得する。
そのトランザクションでロックを獲得した後でTrueTimeAPIで獲得した時刻を時刻_t1_とおき、そこに2εを足した値が「自分の時刻がシステム内で一番遅かったと仮定した場合の、システム内で一番速いシステムが取りうるタイムスタンプ」である。それをそのトランザクションの使用するのタイムスタンプとする。
このようにトランザクションに与えるタイムスタンプを決定することで時刻がブレても
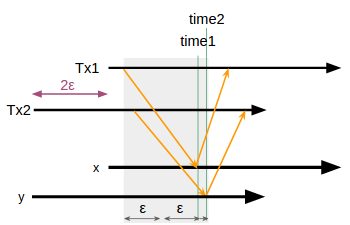
Tx1より後にTx2が始まったならその2つの間の時刻が許容限界ギリギリまでブレていてもその2つに振られるタイムスタンプは順序関係を守る。
そして、トランザクションが読み書きを終えて、ログを書き込んで永続化して、ロックを手放すタイミングで t1 + 2ε が必ず経過したと言える時間までわざとロック期間を引き伸ばすという待機時間を導入する。これがCommit Waitである。これによってタイムスタンプ値が書き込まれる時刻はシステム内のどのマシンから見ても必ずロックが取られているという状態を保っているので一貫性が保証される。
Read-Only Muliti-version Portocol
Spannerの最大の特徴は、分散環境でMVCCを実現した事である。MVCCと言っても複雑なものではなく、読み書きトランザクションがS2PLを使っている点では理解しやすい。読み込みトランザクションはタイムスタンプのみを用いる事で一切ロックに触れる事なくデータを読み出せる。
具体的には読み出しを行おうとした瞬間にTrueTimeAPIで獲得した値に2εを足す事で、「自分の時刻がシステム内で一番遅かったと仮定した場合の、システム内で一番速いシステムが取りうるタイムスタンプ」を獲得できる。そのタイムスタンプより小さい値を持つ最新の過去データを各サーバに問い合わせて獲得すれば良い。
原子時計は必要だったの?
Commit-Waitの際の時刻が短い方がロック期間が短くできるので並列度が上がる。つまり時刻が正確なら正確なほど、書き込みレイテンシが短くなり、書き込みスループットが増える。
まとめ
Spannerは割とシンプルなアルゴリズムなので大仰に構えなくて良いし原子時計が無くても実現は一応できる。