概要
Kafkaに魅せられて、とりあえず手元のマシンで動かしてみましょうか、、、と、インフラしか知らないSEがMacBookProを新たに購入し、Qiita等にアップされている諸先輩方の記事を参考にさせていただき、動作確認したまでの手順を数回に分け記載しています。
なお、Kafkaの概要につきましたは、こちらの記事 を参照ください。
第6回は、第5回でConsumer上のPythonプログラムでtopic-11のデータをターミナル出力するものでしたが、今回はそのプログラムを拡張することにより、そのデータをS3に書き出すことを確認します。
なお、S3への書き出しには Kafka S3 Connector(sink) を使用せず、Pythonプログラム上 で boto3 を使用することにより確認します。
簡単に絵を描くとこんな感じになります。
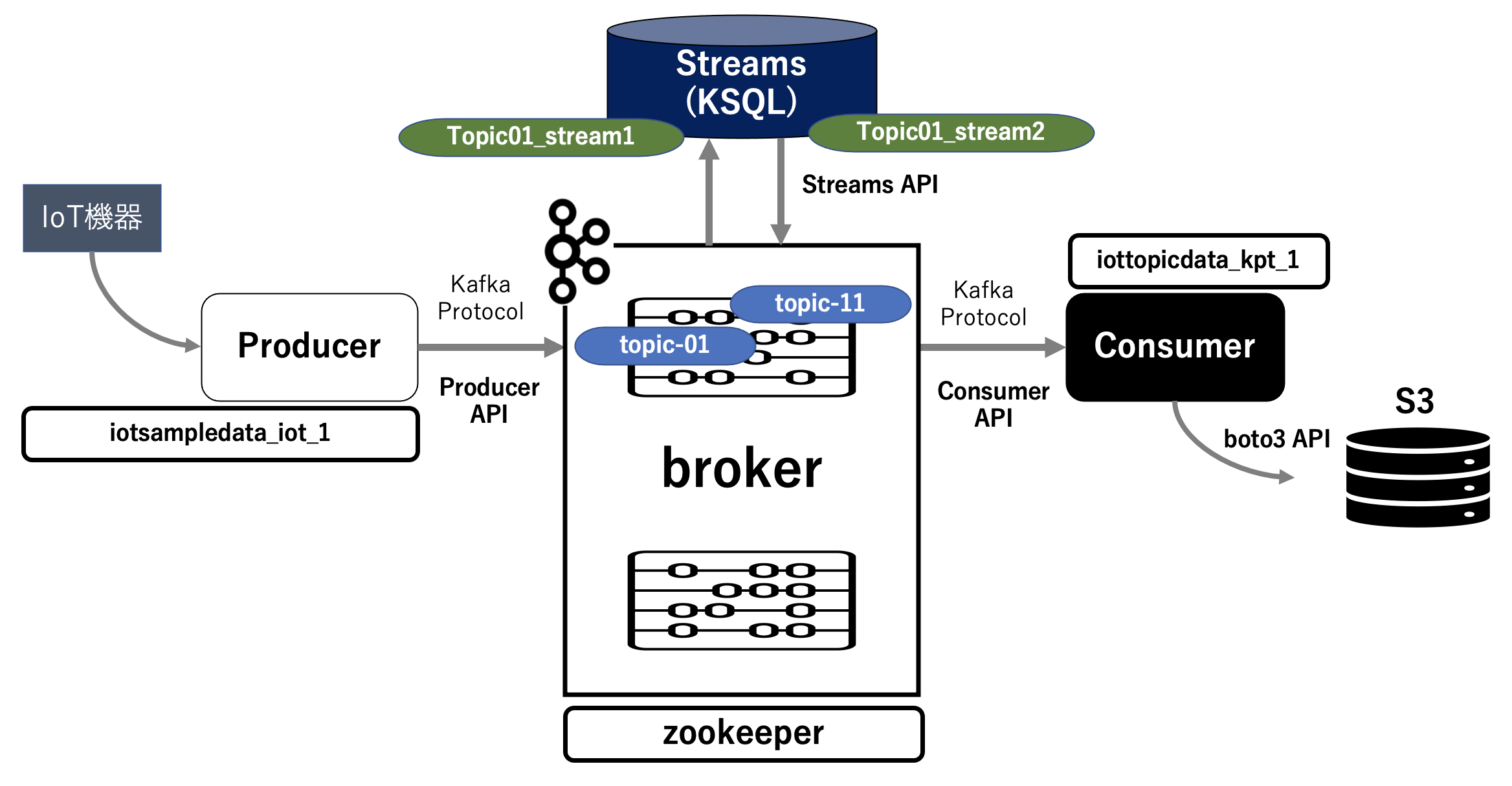
実行環境
macOS Big Sur 11.1
Docker version 20.10.2, build 2291f61
Python 3.8.3
Consumerコンテナの作成
S3のクレデンシャル情報を「.env」に定義します。
KEY_ID=xxxxxxxxxxxxxxxxxx
KEY_VALUE=zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz
REGION=ap-northeast-1
Pythonプログラムが稼働するコンテナ作成のためのディレクトリ構成は以下となります。
$ tree
.
├── .env
├── Dockerfile
├── docker-compose.yml
├── opt
│ └── IoTTopicData-v1.py
└── requirements.txt
docker-compose.yml は以下となります。
ローカルのDocker環境なので、Pythonプログラム(IoTTopicData-v1.py)は COPY を使用せず、volumes を使用しました。
version: '3'
services:
iot:
build: .
working_dir: '/app/'
tty: true
volumes:
- ./opt:/app/opt
environment:
AWS_ACCESS_KEY_ID: ${KEY_ID}
AWS_SECRET_ACCESS_KEY: ${KEY_VALUE}
AWS_DEFAULT_REGION: ${REGION}
networks:
default:
external:
name: iot_network
DockerFile は以下となります。
最後の行の「requirements.txt」はPythonプログラムで必要な関数を別途定義します。
FROM python:3.7.5-slim
USER root
RUN apt-get update
RUN apt-get -y install locales && localedef -f UTF-8 -i ja_JP ja_JP.UTF-8
ENV LANG ja_JP.UTF-8
ENV LANGUAGE ja_JP:ja
ENV LC_ALL ja_JP.UTF-8
ENV TZ JST-9
ENV TERM xterm
RUN apt-get install -y vim less
RUN pip install --upgrade pip
RUN pip install --upgrade setuptools
RUN pip install -r requirements.txt
requirements.txt は以下となります。
Pythonプログラムでimportするのに必要な関数を定義しています。
boto3
kafka-python
Consumerコンテナの作成と確認
定義したコンテナをビルドして起動させます。
$ docker-compose up -d
前略
Creating iottopicdata_ktp_1 ... done
起動を確認します。
$ docker-compose ps
Name Command State Ports
--------------------------------------------
iottopicdata_ktp_1 python3 Up
Consumerで稼働させるプログラム
拡張したPythonプログラムは以下となります。受け取るデータの5件単位毎に、S3のバケット「boto3-cloudian」に書き込む内容となります。
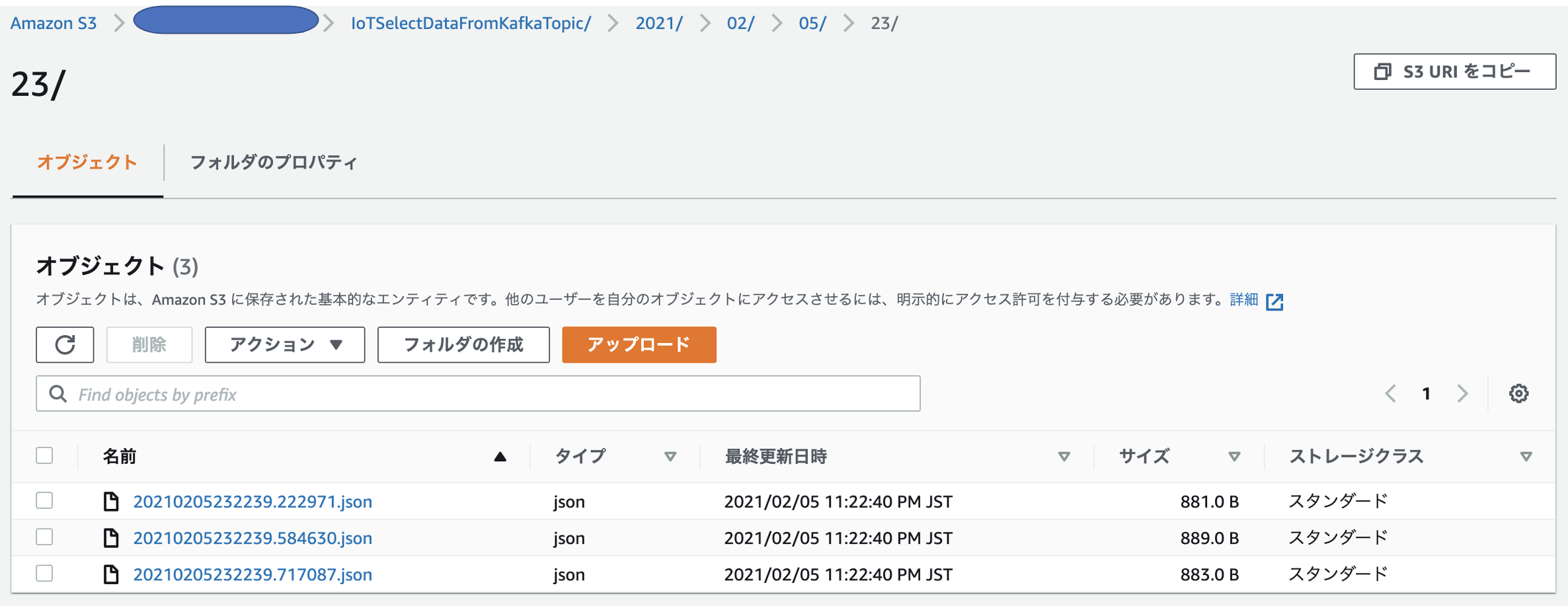
書き込み時のファイル名は、IoTSelectDataFromKafkaTopic/年/月/日/時の階層構造のフォルダ配下に、年月日時分秒.マイクロ秒.json となります。
import json
import time
import argparse
import boto3
import pprint
from datetime import datetime
from kafka import KafkaProducer
from kafka import KafkaConsumer
BUCKET_NAME = 'boto3-cloudian'
# ターミナル出力用
def topic_to_tm(consumer):
print('ターミナル 出力')
# Read data from kafka
try :
for message in consumer:
print ("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition,
message.offset, message.key,
message.value))
except KeyboardInterrupt :
print('\r\n Output to Terminal - interrupted!')
return
# Cloudian/S3 出力用
def topic_to_s3(consumer):
print('Cloudian/S3 出力')
# Read data from kafka
try :
i = 1
buffer = []
for message in consumer:
print ("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition,
message.offset, message.key,
message.value))
buffer.append(message.value)
if i == 5 :
# pprint.pprint (buffer)
write_to_s3(buffer)
buffer.clear()
i = 1
else :
i += 1
except KeyboardInterrupt :
print('\r\n Output to ObjectStorage - interrupted!')
return
# Cloudian/S3のオブジェクトへのデータ書き込み
def write_to_s3(buffer):
# Create S3 Object key
object_key = get_object_key()
print(object_key)
# client = boto3.client('s3', endpoint_url='http://s3-pic.networld.local') # Cloudianへのアクセス時
client = boto3.client('s3') # S3へのアクセス時
client.put_object(
Bucket=BUCKET_NAME,
Key=object_key,
Body=json.dumps(buffer,ensure_ascii=False).encode('utf-8')
)
# Cloudian/S3のオブジェクトキー(ファイル)名の生成
def get_object_key():
#S3階層可変(日時)値
variable_key = 'IoTSelectDataFromKafkaTopic/' + datetime.now().strftime('%Y/%m/%d/%H/')
# S3に作成するオブジェクト名指定
key_name = datetime.now().strftime('%Y%m%d%H%M%S.%f') + '.json'
object_key = variable_key + key_name
return object_key
# Kafka Topic からのデータ受取
def get_kafka_topic():
# Initialize consumer variable and set property for JSON decode
consumer = KafkaConsumer ('topic-11',
bootstrap_servers = ['broker:29092'],
value_deserializer=lambda m: json.loads(m.decode('utf-8')))
print(consumer)
return consumer
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='KafkaからのIoT機器のなんちゃってStreamデータの取得')
parser.add_argument('--mode', type=str, default='tm', help='tm(ターミナル出力)/ s3(オブジェクトストレージ出力)')
args = parser.parse_args()
start = time.time()
consumer = get_kafka_topic()
if (args.mode == 's3'):
topic_to_s3(consumer)
else :
topic_to_tm(consumer)
making_time = time.time() - start
print("")
print("Streamデータ取得待機時間:{0}".format(making_time) + " [sec]")
print("")
Consumerでのメッセージ受け取り設定
データを受け取るために、Comsumer に接続し、プログラムのあるディレクトリに移動します。
また、AWSのクレデンシャル情報が反映されているかを確認します。
$ docker exec -it iottopicdata_ktp_1 /bin/bash
root@c23123e17068:/app#
root@c23123e17068:/app# cd opt
root@c23123e17068:/app/opt#
root@c23123e17068:/app/opt# env | grep AWS
AWS_DEFAULT_REGION=ap-northeast-1
AWS_SECRET_ACCESS_KEY=zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz
AWS_ACCESS_KEY_ID=xxxxxxxxxxxxxxxxxx
IoTTopicData-v1.py を実行しtopic-11からのデータをS3に書き込む設定をします。
root@c23123e17068:/app/opt# python IoTTopicData-v1.py --mode s3
<kafka.consumer.group.KafkaConsumer object at 0x7f7494085650>
Cloudian/S3 出力
↑ プロンプトが何も表示されない状態ですが、Producerからのメッセージの受け取りを待っています。
Producerからのメッセージ送信
データを送信するために別ターミナルを立ち上げ、Producer に接続し、プログラムのあるディレクトリに移動します。
$ docker exec -it iotsampledata_iot_1 /bin/bash
root@4e4f79c219e1:/app#
root@4e4f79c219e1:/app# cd opt
root@4e4f79c219e1:/app/opt#
IoTSampleData-v2.py を実行し、生成データを送信します(100件)。
root@4e4f79c219e1:/app/opt# python IoTSampleData-v2.py --mode kf --count 100
Kafka 出力
<kafka.producer.future.FutureRecordMetadata object at 0x7fb0125b5e90>
データ作成件数:100
データ作成時間:0.13501501083374023 [sec]
上記実行後、topic-11のデータは以下のように Consumerのターミナルに出力され、
root@c23123e17068:/app/opt# python IoTTopicData-v1.py --mode s3
<kafka.consumer.group.KafkaConsumer object at 0x7fee27e25650>
Cloudian/S3 出力
topic-11:0:2: key=b'2021/02/05' value={'SECTION': 'C', 'TIME': '2021-02-05T23:22:38.974127', 'PROC': '111', 'IOT_NUM': '537-7989', 'IOT_STATE': '岡山県', 'VOL_1': 136.47748912214027, 'VOL_2': 89.4598706488899}
topic-11:0:3: key=b'2021/02/05' value={'SECTION': 'W', 'TIME': '2021-02-05T23:22:38.974149', 'PROC': '111', 'IOT_NUM': '424-8856', 'IOT_STATE': '富山県', 'VOL_1': 123.0593268339469, 'VOL_2': 78.46322776492022}
topic-11:0:4: key=b'2021/02/05' value={'SECTION': 'W', 'TIME': '2021-02-05T23:22:38.974710', 'PROC': '111', 'IOT_NUM': '116-0745', 'IOT_STATE': '山梨県', 'VOL_1': 116.11217771503935, 'VOL_2': 74.09635644937616}
topic-11:0:5: key=b'2021/02/05' value={'SECTION': 'C', 'TIME': '2021-02-05T23:22:38.974862', 'PROC': '111', 'IOT_NUM': '843-7881', 'IOT_STATE': '奈良県', 'VOL_1': 108.3586171123569, 'VOL_2': 62.99783651862181}
topic-11:0:6: key=b'2021/02/05' value={'SECTION': 'C', 'TIME': '2021-02-05T23:22:38.974949', 'PROC': '111', 'IOT_NUM': '310-1209', 'IOT_STATE': '熊本県', 'VOL_1': 182.1592585797406, 'VOL_2': 86.23441031130653}
IoTSelectDataFromKafkaTopic/2021/02/05/23/20210205232239.222971.json
中略
IoTSelectDataFromKafkaTopic/2021/02/05/23/20210205232239.584630.json
中略
IoTSelectDataFromKafkaTopic/2021/02/05/23/20210205232239.717087.json
後略
かつ、S3の該当バケット「boto3-cloudian」の階層化フォルダ「IoTSelectDataFromKafkaTopic/年/月/日/時」の配下に、年月日時分秒.マイクロ秒.json として保存されてます。
これで、Producer上のPythonプログラムで生成したデータが topic-01 → Ksql → topic-11 を経由して Consumer 上のPythonプログラムによってS3に書き込めることを確認できました。
次回について
次回(第7回)は、複数台のIoT機器からのデータ取り込みを想定し、Producerのコンテナを複数起動させて同様のことを確認します。
第1回:Kafka基本コンポーネントをローカルのDocker環境で稼働させる
第2回:Kafkaの Producerから送信されたメッセージが Broker を経由して Consumer で受け取れることの確認
第3回:Producer上のPythonプログラムで生成したデータを Broker を経由して Consumer で受け取れることの確認
第4回:Producer上での生成データが topic-01 を経由して KSQL(topic01_stream1 → topic01_stream2) でストリーミング抽出処理されたことの確認
第5回:Producer上での生成データが topic-01 → Ksql → topic-11 を経由して Consumer 上のPythonプログラムで受け取れることの確認
第6回:Producer上での生成データが topic-01 → Ksql → topic-11 を経由して Consumer 上のPythonプログラムによってS3に書き込めることの確認
第7回:2つのProducerコンテナ上で生成したそれぞれのデータが topic-01 → Ksql → topic-11 を経由して Consumer 上のPythonプログラムで受け取れることの確認
参考情報
以下の情報を参考にさせていただきました。感謝申し上げます。
Kafka の Docker のチュートリアル
Kafka からKSQLまで Dockerで簡単環境構築