目的
本記事はハンズオンを通してApache Kafkaに触れ、少しでも多くの方にKafkaの良さを理解していただくことを目的としています。細かいKafkaの実装や仕組みについては割愛し、実際にKafkaを用いることでどのような処理が可能になるのか、既存の問題に対して解決策となるのかなどイメージを膨らませられる機会となれば幸いです。
Kafka入門
Kafkaについて一通りの基礎を理解されている方は読み飛ばして頂いて問題ありません。
Kafkaとは2011年LinkedInにより「分散メッセージングキュー」として発表されました。現在Kafkaの公式ページには「分散ストリーミングプラットフォーム」と記載されておりますが、基本的にはメッセージングキューとして認識して頂いて問題ないかと思います。
以下のような特徴を持ち、柔軟でスケーラブルかつ耐障害性を兼ね備えたメッセージングプラットフォームとして様々な大規模システムで採用されています。
- Pub/Subモデル => 同じメッセージを複数のアプリが受信可能(柔軟・スケーラブル)
- マルチブローカーによるクラスタ構成 => メッセージ量によりサーバーを増やし高スループットを実現
- メッセージデータのディスク保存による永続化 => 同じメッセージを再度読み込むことでメッセージの再処理が可能
また成熟したコミュニティから様々な言語でのAPIやKafka Connectと呼ばれる豊富なプラグインが提供されており、開発者にとっても優しい環境が揃っています。
Kafkaの用語と簡単な仕組み
Kafkaにはそれぞれ役割に応じた用語が使われており、大まかに以下のような構成となっています。
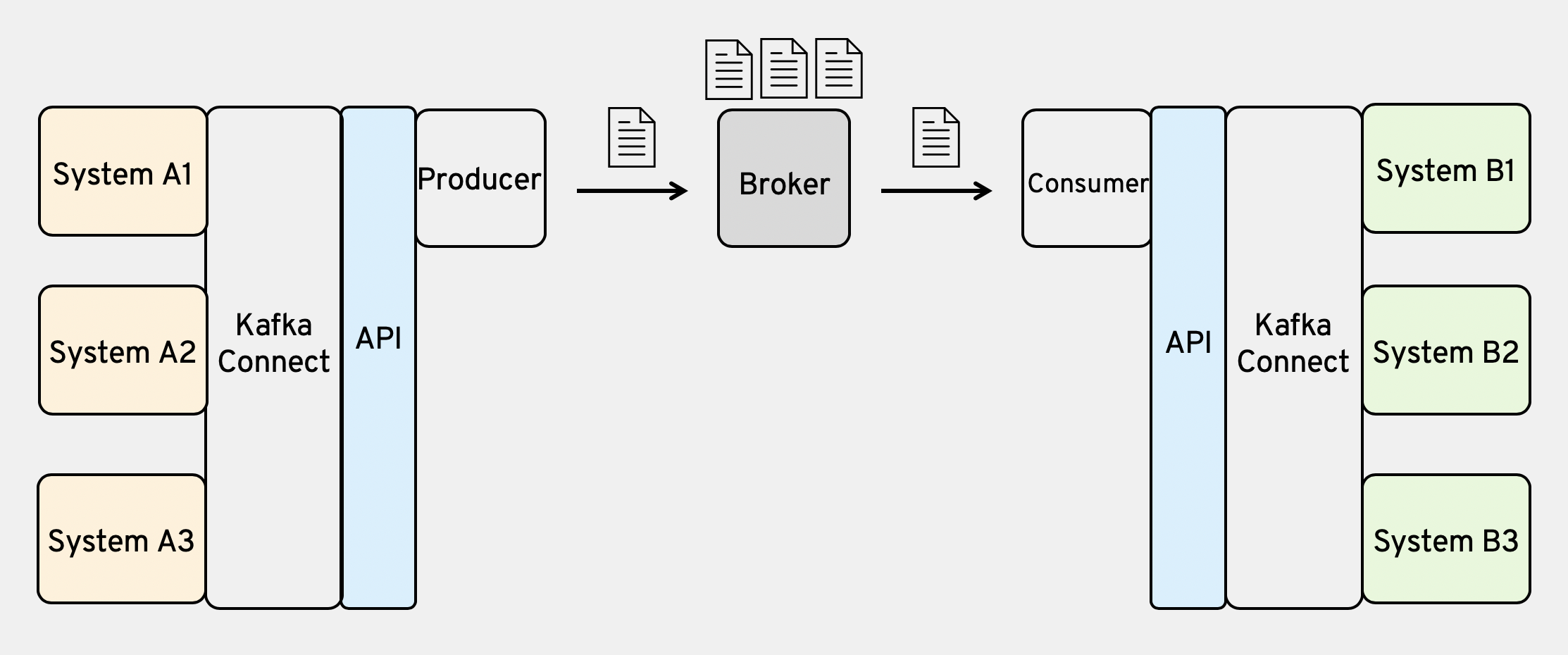
メッセージ送信側:Producer
メッセージ受信側:Consumer
メッセージ仲介役:Broker
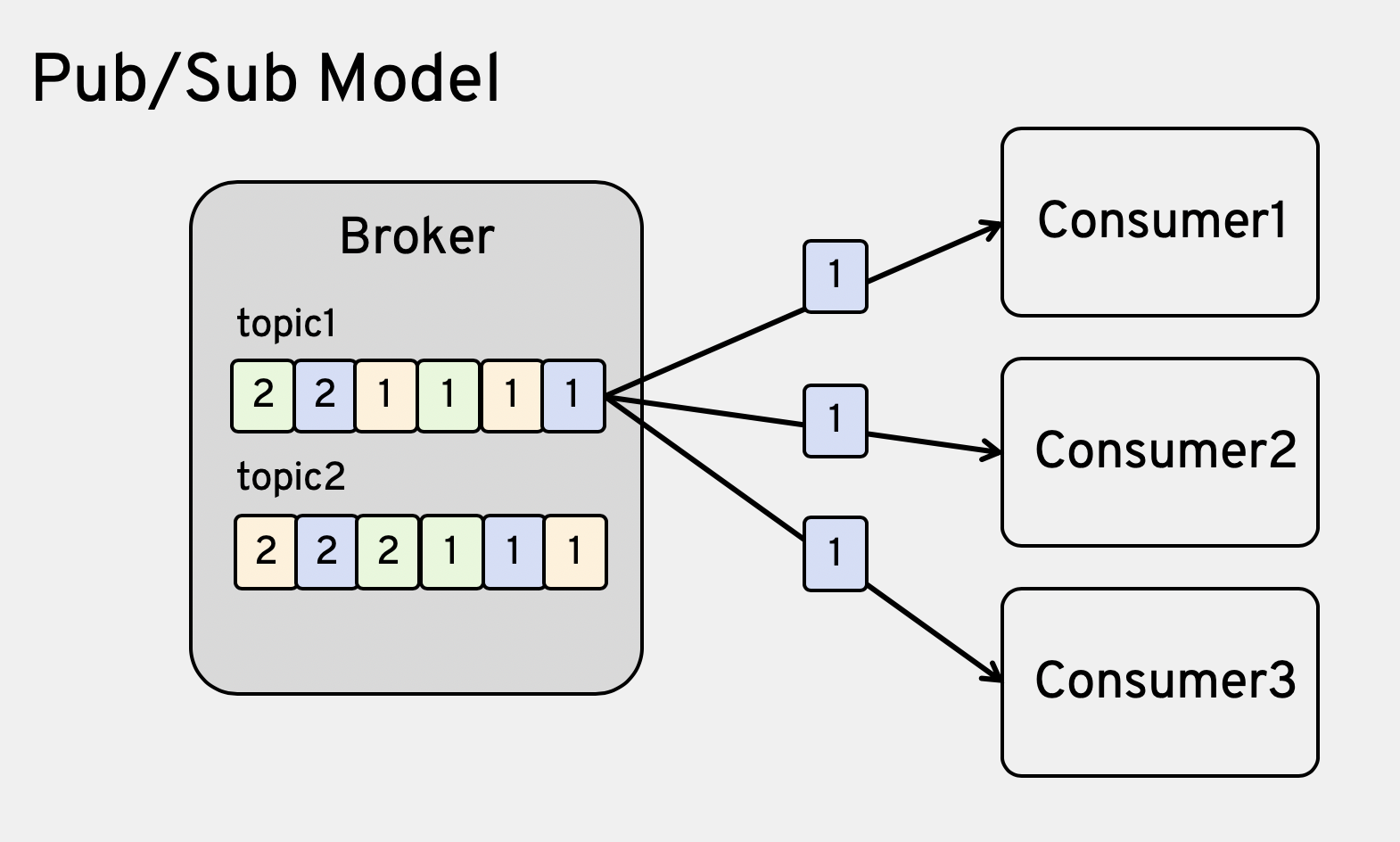
各メッセージキューイング:Topic
Topicのキューをシャーディングしたキューイング:Partition
 さらにKafkaのクラスタ管理にはZookeeperの起動が必要です。
さらにKafkaのクラスタ管理にはZookeeperの起動が必要です。
ハンズオン
概要はここまでにして、実際に手を動かしてみましょう。
今回は以下の環境でハンズオンを進めていきます。
macOS: 10.14
python: 3.7.4
docker: 2.1.0.5
kafka-docker: https://github.com/wurstmeister/kafka-docker
KSQL: https://github.com/confluentinc/ksql
#1 Kafkaをdocker上で起動
#1.1 準備
まずはkafka-dockerをローカルにクローンしてきましょう。
適当にローカル環境にディレクトリを作成し、githubよりクローンします。
mkdir ~/kafka && cd ~/kafka
git clone https://github.com/wurstmeister/kafka-docker.git
cd kafka-docker
kafka-dockerよりdocker-compose.ymlが提供されているので、そのままdocker-compose up -dを実施したいところですが、こちらのファイルに少し修正が必要です。
ref) https://github.com/wurstmeister/kafka-docker#advertised-hostname
に記載されているようにadvertised ipを設定する必要があります。
KAFKA_ADVERTISED_HOST_NAME: 192.168.99.100と直書きされているIPアドレスを環境変数DOCKER_HOST_IPに変更しておきます。
sed -i -e 's/KAFKA_ADVERTISED_HOST_NAME:.*/KAFKA_ADVERTISED_HOST_NAME: ${DOCKER_HOST_IP}/g' docker-compose.yml
次に起動したKafkaに事前にTopicを生成しておきたい場合、次の値を設定すると便利です。
ref) https://github.com/wurstmeister/kafka-docker#automatically-create-topics
先ほど変更したKAFKA_ADVERTISED_HOST_NAMEの次の行に以下の一文を挿入してください。
KAFKA_CREATE_TOPICS: "topic1:3:2,topic2:3:2
以上で準備完了です。
それではKafkaを起動してみましょう。
#1.2 Kafkaの起動
# .bashrcなどshell起動時に設定されるようにしておくといいでしょう
export DOCKER_HOST_IP=$(ipconfig getifaddr en0)
docker-compose up -d --build
docker-compose ps
# ポート番号は異なる場合もあります。
# Name Command State Ports
# ----------------------------------------------------------------------------------------------------------------------
# kafka-docker_kafka_1 start-kafka.sh Up 0.0.0.0:32771->9092/tcp
# kafka-docker_zookeeper_1 /bin/sh -c /usr/sbin/sshd ... Up 0.0.0.0:2181->2181/tcp, 22/tcp, 2888/tcp, 3888/tcp
Brokerの数を3つに増やします。
docker-compose scale kafka=3
docker-compose ps
# Name Command State Ports
# ----------------------------------------------------------------------------------------------------------------------
# kafka-docker_kafka_1 start-kafka.sh Up 0.0.0.0:32771->9092/tcp
# kafka-docker_kafka_2 start-kafka.sh Up 0.0.0.0:32772->9092/tcp
# kafka-docker_kafka_3 start-kafka.sh Up 0.0.0.0:32773->9092/tcp
# kafka-docker_zookeeper_1 /bin/sh -c /usr/sbin/sshd ... Up 0.0.0.0:2181->2181/tcp, 22/tcp, 2888/tcp, 3888/tcp
#1.3 Kafka動作確認
それでは、実際にKafkaをCLIで操作してみましょう。
# dockerコンテナ内にアクセス
./start-kafka-shell.sh $DOCKER_HOST_IP
# Broker情報が出力
bash-4.4# broker-list.sh
# 10.XXX.XXX.XXX:32772,10.XXX.XXX.XXX:32773
# 10.XXX.XXX.XXX:32771
# docker-compose.ymlのKAFKA_CREATE_TOPICSに指定したTopicが生成されていることを確認
bash-4.4# $KAFKA_HOME/bin/kafka-topics.sh --list --bootstrap-server `broker-list.sh`
# topic1
# topic2
# Topicの作成
bash-4.4# $KAFKA_HOME/bin/kafka-topics.sh --create --topic topic-from-cli --partitions 3 --replication-factor 2 --bootstrap-server `broker-list.sh`
bash-4.4# $KAFKA_HOME/bin/kafka-topics.sh --list --bootstrap-server `broker-list.sh`
# topic-from-cli
# topic1
# topic2
以上で、簡単なKafkaの動作確認は終了です。
クローンしたリポジトリにはProducerやConsumerもCLIで試せるshファイルが用意されていますので、そちらも試してみると良いでしょう。
実際のシステムではCLI経由でProducer/Consumerを実装することはほとんどないと思いますので、次はPython3を使ったProducerを作成し、アプリ経由でTopicにメッセージを送信できるようにしましょう。
#2 Kafkaへメッセージを送信 - Producerの実装
#2.1 準備
Python3のKafkaライブラリをインストールしましょう。各々足りないモジュールは適宜インストールしてください。
cd ~/kafka
pip install kafka-python
続けて以下のファイルを作成します。私自身Python自体普段書きません。
あくまで動作確認レベルのコードです。
from kafka import KafkaProducer
from datetime import datetime
import subprocess
import json
import random
cwd_name = subprocess.check_output("pwd").decode('utf-8').rstrip('\n') + "/kafka-docker"
host_ip = subprocess.check_output("ipconfig getifaddr en0", shell=True).decode('utf-8').rstrip('\n')
netstat_result = subprocess.check_output("DOCKER_HOST_IP=${host_ip} && docker-compose exec kafka netstat |awk '{ print $5 }' |grep '^1.*:32.*'", cwd=cwd_name, shell=True).decode('utf-8').rstrip('\n')
kafka_ips = list(set(netstat_result.split('\n')))
# print(kafka_ips)
date = datetime.now().strftime("%Y/%m/%d")
messageId = datetime.now().strftime("%Y/%m/%d-%H:%M:%S:%f")
user_id = random.choice([1000, 2000, 3000])
word_id = random.randint(1,5)
word_pattern = {1: 'hello', 2: 'world', 3: 'hoge', 4: 'fuga', 5: 'hello world'}
word_count = random.randint(1,3)
word_keys = random.sample(word_pattern.keys(), word_count)
producer = KafkaProducer(bootstrap_servers=kafka_ips, value_serializer=lambda m: json.dumps(m).encode('utf-8'))
for word_type in word_keys:
kafka_msg = {'userId': user_id, 'messageId': messageId, 'message': {'wordId': word_type, 'word': word_pattern[word_type]}}
producer.send('topic1', key=date.encode('utf-8'), value=kafka_msg).get(timeout=1)
#2.2 Kafkaにメッセージを送信
2つのターミナルタブを使います。
1つはトピック内のメッセージ確認用、もう1つはメッセージ送信用です。
# tab1
# Kafka CLI起動
./start-kafka-shell.sh $DOCKER_HOST_IP
# Consumer起動
# --from-beginningオプションをつけると既にTopicに届いているメッセージを表示することが可能
bash-4.4# $KAFKA_HOME/bin/kafka-console-consumer.sh --topic=topic1 --from-beginning --bootstrap-server `broker-list.sh`
---
# tab2
python topic1-producer.py
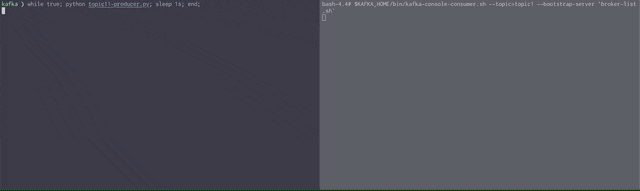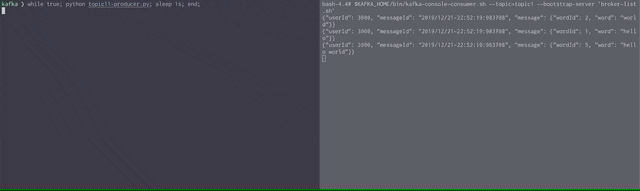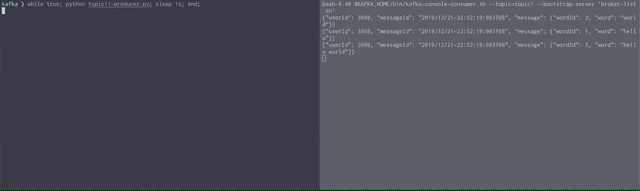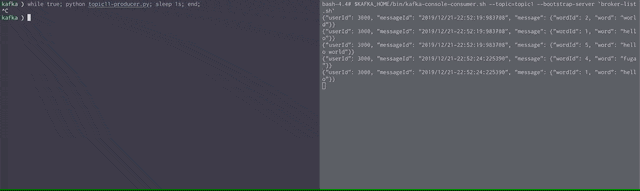
tab2のPythonスクリプトを実行するとtab1側に
{"userId": 1000, "messageId": "2019/12/21-22:46:03:131468", "message": {"wordId": 2, "word": "world"}}
のようにメッセージが流れてくることが確認できるはずです。
以下のようにスクリプトを実行すると3秒ごとにメッセージが到達することがわかるでしょう。
# bash
while true; do python topic1-producer.py; sleep 3s; done;
# fish
while true; python topic1-producer.py; sleep 3s; end;
#2.3 メッセージ到着の様子
#3 KSQLを使ったStreaming処理の実装
続いてストリーミング処理を行ってみましょう。ストリーミングといっても、特殊なことはなく延々とTopicに流れるメッセージ(イベント)全体を「ストリーミング」と呼んでいるにすぎません。KSQLはそれらの流れているイベントに対してSQLライクにクエリを投げてフィルタや集計を行うことができるAPIです。Topicに流れてくるメッセージの連続データを別の連続データ(Stream)や集計データ(Table)に変化させ、そのデータを新たなトピックとし別のアプリケーションで処理を行うことができるというものです。詳細は下記のリンクを参照してみてください。
ref) https://kafka.apache.org/documentation/streams/
ref) https://www.youtube.com/watch?v=DPGn-j7yD68
StreamやTableは基本的に(24/7)常時稼働しているもので、Topicと同じ扱いと認識しておくとスッと入りやすいかと思います。
#3.1 準備
まずはconfluent社の開発したKSQLを準備します。
cd ~/kafka
git clone https://github.com/confluentinc/ksql.git
cd ksql
#3.2 KSQL server / KSQL CLIの起動
# kafka-dockerディレクトリに戻る
cd ../kafka-docker
# kafkaの起動中IPアドレス+Port番号取得
export KSQL_BOOTSTRAP_SERVERS=(docker-compose exec kafka netstat |awk '{ print $5 }' |grep '^1.*:32.*' |sort |uniq |tr '\n' ',')
# ksqlディレクトリへ移動
cd ../ksql
# ksql server起動
docker run -d -p $DOCKER_HOST_IP:8088:8088 \
-e KSQL_BOOTSTRAP_SERVERS=$KSQL_BOOTSTRAP_SERVERS \
-e KSQL_OPTS="-Dksql.service.id=ksql_service_3_ -Dlisteners=http://0.0.0.0:8088/" \
confluentinc/cp-ksql-server:5.3.1
# dockerプロセス確認
docker ps
# confluentinc/cp-ksql-server:5.3.1のコンテナが起動していること
# KSQL CLI起動
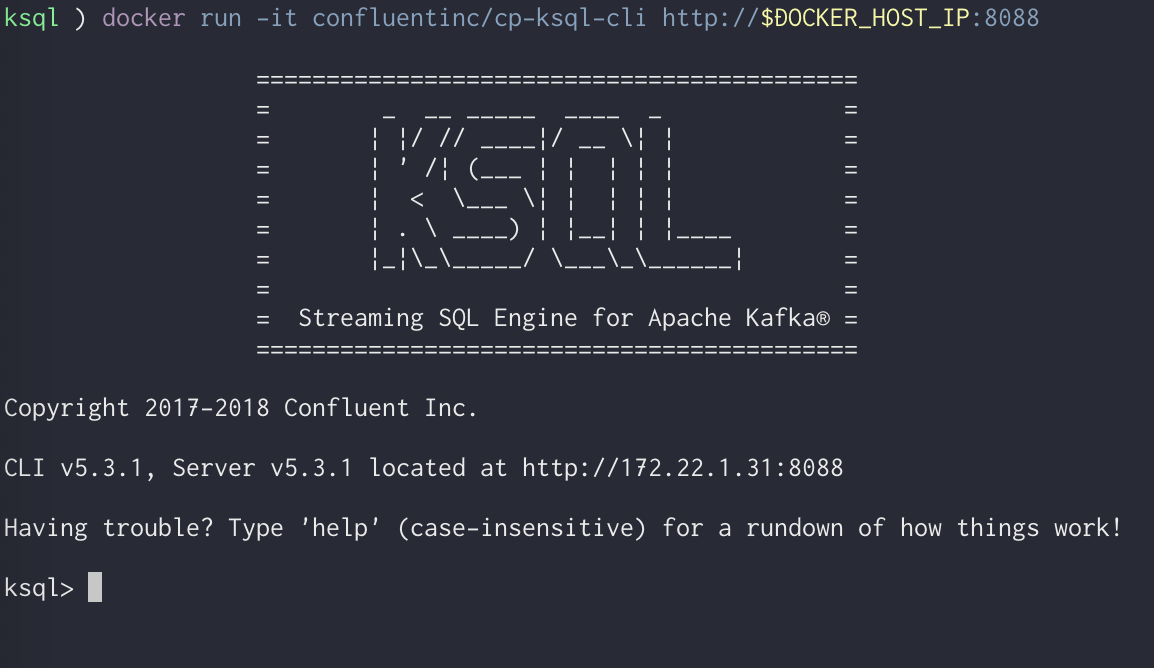
docker run -it confluentinc/cp-ksql-cli http://$DOCKER_HOST_IP:8088
KSQLのCLI起動が成功すると下のようなCLIが立ち上がります。
#3.3 Streamの作成
ここでは、topic1,2からstreaming処理用のstream, tableを作成してみます。
ksql> show streams;
# Stream Name | Kafka Topic | Format
# ------------------------------------
# ------------------------------------
ksql> CREATE STREAM topic1_stream1 (userId INT, messageId VARCHAR, message STRUCT<word VARCHAR, wordId INT>) WITH (KAFKA_TOPIC = 'topic1', VALUE_FORMAT='JSON', KEY='userId');
ksql> show streams;
# Stream Name | Kafka Topic | Format
# ---------------------------------------
# TOPIC1_STREAM1 | topic1 | JSON
# ---------------------------------------
ksql> CREATE TABLE topic1_table1 (userId INT, wordCount INT, message STRUCT<word VARCHAR, wordId INT>) WITH (KAFKA_TOPIC = 'topic1', VALUE_FORMAT='JSON', KEY='userId');
ksql> show tables;
# Table Name | Kafka Topic | Format | Windowed
# -------------------------------------------------
# TOPIC1_TABLE1 | topic1 | JSON | false
# -------------------------------------------------
※重要
Stream、Tableを作る際にはいくつか制限があります。私自身このルールを覚えるまで色々試行錯誤が必要でした。
ref) https://docs.confluent.io/current/ksql/docs/developer-guide/join-streams-and-tables.html
| from Topic | from stream | from stream-stream | from table-table | from stream-table | |
|---|---|---|---|---|---|
| CREATE Stream | o | o | o | x | o |
| CREATE Table | o | o | x | o | x |
SQL同様、2つのリソースから新しいStream, Tableを作成するためにはJOIN構文を用います。ここで注意が必要なのは各リソースのKEYに設定された値でのみJOINが可能であるという点です。つまり、上の例ではtopic1から作成したStreamと別のtopicから作成されたStreamにおいて2つのカラムでJOINすることはできないということです。(例:userId=2000 and wordCount=5のイベントを新Streamとすることはできない。)
複数のカラムでJOINしたい場合は、Topicのメッセージにそれらを組み合わせたカラムを用意しKEYとすることで対応可能です。(例:KEY => ${userId}-${wordCount})
また、TableへのクエリでGROUP BYをするためにも対象がKEYである必要があります。
#3.4 Streamへのクエリ
Streamへのクエリは常に更新分のメッセージに対して行われます。つまり、クエリを投げた時点よりも前にTopicへ詰められたメッセージはStreamへのクエリ結果として出力されません。この章の冒頭で述べたようにStreamやTableは常時稼働しておくものでTopicと同じように事前に作成するものです。KSQLを触りたての時期はその認識が抜けているため、「結局何に使うの?いつ使うの?」という疑問が残ってしまうかもしれません。実際のシステムではCLI経由でStream処理を行うことはほとんどないと思いますが、ハンズオンのためデバッグの意味も込めて下記のように既にTopicに入っているメッセージに対してもクエリ結果が確認できるように以下の値をKSQLのCLIで設定しましょう。
ksql> SET 'auto.offset.reset'='earliest';
# Stream内全てのeventを取得
ksql> select * from topic1_stream1;
# 1576936834754 | 2019/12/21 | 3000 | 2019/12/21-23:00:34:614230 | {WORD=fuga, WORDID=4}
# 1576936837399 | 2019/12/21 | 1000 | 2019/12/21-23:00:37:275858 | {WORD=hello world, WORDID=5}
# 1576936837512 | 2019/12/21 | 1000 | 2019/12/21-23:00:37:275858 | {WORD=hoge, WORDID=3}
---
# Stream内で各ユーザーが同じタイミングでいくつのメッセージを送信したのか
ksql> select userId, count(messageId) from topic1_stream1 group by userId, messageId;
# 1000 | 3
# 3000 | 2
# 3000 | 1
集計関数はKSQLでデフォルトで用意されているものに加えて、開発者が定義したものを使うことも可能です。
ref) https://docs.confluent.io/current/ksql/docs/developer-guide/syntax-reference.html#aggregate-functions
また、集計に関しては下記のドキュメントが非常に参考になります。特定の時間にイベントを区切って集計ができたりするなど非常に幅広いクエリが可能になっています。
ref) https://docs.confluent.io/current/ksql/docs/developer-guide/aggregate-streaming-data.html#aggregate-streaming-data-with-ksql
この状態で#2.2の手順によりtopic1へメッセージを送信してみてください。

#3.4 Stream + Stream => Stream => Table
最後に応用編として2つのStreamから新たなStreamを作成し、そこに対してクエリをかけTableを作成してみましょう。
例としてくじ引きでランダムにユーザーが選出され、そのユーザーが過去60分間に発言していたキーワードを抽出するシーンを想定しましょう。
(良い例が浮かばなかったのでご容赦ください;;)
まずはtopic1-producer.pyをコピーしtopic2-producer.pyを作成しましょう。
cp topic{1,2}-producer.py
from kafka import KafkaProducer
from datetime import datetime
import subprocess
import json
import random
cwd_name = subprocess.check_output("pwd").decode('utf-8').rstrip('\n') + "/kafka-docker"
host_ip = subprocess.check_output("ipconfig getifaddr en0", shell=True).decode('utf-8').rstrip('\n')
netstat_result = subprocess.check_output("DOCKER_HOST_IP=${host_ip} && docker-compose exec kafka netstat |awk '{ print $5 }' |grep '^1.*:32.*'", cwd=cwd_name, shell=True).decode('utf-8').rstrip('\n')
kafka_ips = list(set(netstat_result.split('\n')))
# print(kafka_ips)
date = datetime.now().strftime("%Y/%m/%d")
user_id = random.choice([1000, 2000, 3000])
producer = KafkaProducer(bootstrap_servers=kafka_ips, value_serializer=lambda m: json.dumps(m).encode('utf-8'))
kafka_msg = {'userId': user_id}
producer.send('topic2', key=date.encode('utf-8'), value=kafka_msg).get(timeout=1)
上記のようにファイルを作成したら、Topic1, Topic2からuserIdをKEYとしたStreamを作成しましょう。
ksql> CREATE STREAM topic2_stream1 (userId INTEGER) WITH (KAFKA_TOPIC = 'topic2', VALUE_FORMAT='JSON', KEY='userId');
ksql> show streams;
# Stream Name | Kafka Topic | Format
# ---------------------------------------
# TOPIC2_STREAM1 | topic2 | JSON
# TOPIC1_STREAM1 | topic1 | JSON
# ---------------------------------------
そして、2つのStreamから一致するuserIdから新たなStreamを作成します。Topic2に新しいメッセージ(イベント)が届いたことをトリガーとしているので、Topic2がLEFT側のStreamとなります。
ref) https://docs.confluent.io/current/ksql/docs/developer-guide/join-streams-and-tables.html#semantics-of-stream-stream-joins
# Topic2 Stream + Topic1 Stream => New Stream
ksql> CREATE STREAM topic1_topic2_stream1 AS SELECT t2s1.userId as userId, t1s1.messageId, t1s1.message FROM topic2_stream1 t2s1 INNER JOIN topic1_stream1 t1s1 WITHIN 1 HOURS ON t2s1.userId = t1s1.userId;
# 3.4で SET 'auto.offset.reset'='earliest'; を行った方は下記のコマンドで変更分だけがクエリ結果になるようデフォルトに戻しましょう。
ksql> SET 'auto.offset.reset'='latest';
ksql> select * from topic1_topic2_stream1;
この状態で別タブからtopic2-producer.pyを実行してみてください。
実行すると下記のように過去1時間にtopic1_stream1に届いたメッセージ(イベント)が表示されるでしょう。

それでは最後にtopic1_topic2_stream1のStreamに対するクエリからTableを作成してみましょう。
# StreamへのクエリからTable作成
ksql> CREATE TABLE topic1_topic2_table1 AS SELECT userId, COLLECT_SET(message->word) as word FROM topic1_topic2_stream1 GROUP BY userId;
# Topic2にメッセージを送信しながら下記クエリを実行すると、新しくメッセージ(イベント)が作成される様子が確認可能
ksql> select * from topic1_topic2_table1;
# 1576940945888 | 2019/12/22 | 1000 | [hello, hello world, fuga, hoge, world]
# 1576941043356 | 2019/12/22 | 3000 | [hello, hello world, fuga]
以上でハンズオンの内容は終了です。