やりたいこと
患者の訴えから診断することってAIでできるのかなと、薬剤師の経験からふと思ったので試してみた。
Twitter APIで取得したデータを加工し、BERTモデルで学習させ、症状を診断するAIを作成する。
当初6クラスに分類する予定だったのが、うまく精度がでなかったため2値分類も行った。
学習データの収集
Twitter APIで学習用のデータを取得
取得したデータはエクセルに出力して、エクセルでデータ加工。
その後CSVへ変換しpandasでモデルに読み込ませる。
import tweepy
import pandas as pd
import datetime
# TweepyAPI KEY
CONSUMER_KEY = "取得したCONSUMER_KEY "
CONSUMER_SECRET = "取得したCONSUMER_SECRET "
ACCESS_TOKEN = "取得したACCESS_TOKEN"
ACCESS_TOKEN_SECRET = "取得したACCESS_TOKEN_SECRET"
#tweepyの設定
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)
auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET)
api = tweepy.API(auth)
columns_name=["TW_NO","TW_TIME","TW_TEXT","FAV","RT","X"]
#検索キーワードを設定する。
searchWord = ["咳","鼻水","頭痛","喉痛"]
count = 100
#ツイート取得
def get_tweets(searchWord):
tweet_data = []
for q in searchWord:
# api.searchで検索する。(戻り値はSearchResultオブジェクト => Statusオブジェクトのリスト)
for tweet in api.search(q=q, lang='ja', result_type='recent', count=count): #qに検索したいワードを指定する。
tweet_data.append([tweet.id,tweet.created_at+datetime.timedelta(hours=9),tweet.text.replace('\n',''),tweet.favorite_count,tweet.retweet_count])
# pandasでテーブルを作成
df = pd.DataFrame(tweet_data,columns=columns_name)
# Excelで出力する
df.to_excel('tw_%s.xlsx'%searchWord, sheet_name='Sheet1')
# 終了報告
print("end")
get_tweets(searchWord)
1回に検索ワード4種類を各100件(全400件)取得するので、何回か繰り返し取得する。
データの整形。
ツイートごとにラベルを設定
0: 症状なし(None)
1: 咳(Cough)
2: 鼻水(Runny Nose)
3: 咽頭痛(Sore Throat)
4: 頭痛(Headache)
5: 受診(Doctor)
同じツイートを取得した場合は削除。
BERTでデータを扱えるように、RTなどの宛先や絵文字、顔文字などは削除。
また、風邪の症状とは違う内容である場合は削除。
BERTモデル
こちらのモデルをお借りしました。
ところどころ修正しています。
※ torchtext0.9.0以上では、torchtext.dataはtorch.legacy.dataへ変更する
ディレクトリ構造
├─Clinical_reasoning.ipynb
├─data # 学習用のデータ
│ ├─test.tsv
│ ├─train.tsv
│ ├─test_dumy.tsv
│ └─train_dumy.tsv
│
├─utils
│ ├─bert.py #BERTモデルの定義
│ ├─dataloader.py #dataloader生成用
│ ├─predict.py #推論用
│ ├─tokenizer.py #形態素解析用
│ └─train.py #学習用
│
├─predicted # 予想データを格納
├─vocab # bert語録辞書vocab.txt
├─images # 学習のグラフを格納
└─weights # モデルの重みを格納
vocab.txtを変更
vocab.txtにない言葉は[UNK]となるため、症状を示すような必須ワードを追加する。
=> vocab.txtの行数(辞書の単語数)が指定されているみたい?なので、新規に追加するとエラーになった。
=> 行数をどこで定義しているかわからなかったので、不要なワードを削除して対応。
出力数を変更
当初6クラスで実行したため、各ファイルの出力数を変更。
また、最終的に6クラスと2クラスで行ったので、クラス数で処理を分けるように引数を設定。
分類器を変更
最終的に分類される分類器を変更。
学習結果をグラフで出力できるように追加
matplotlibでepochごとのaccuracyとlossをグラフとして出力するように設定。
Colaboratoryで実行
from google.colab import drive
drive.mount('/content/drive')
形態素解析にJuamn++を使用
# インストール
!wget https://github.com/ku-nlp/jumanpp/releases/download/v2.0.0-rc2/jumanpp-2.0.0-rc2.tar.xz
!tar xfv jumanpp-2.0.0-rc2.tar.xz
%cd jumanpp-2.0.0-rc2
!mkdir bld
%cd bld
!cmake .. -DCMAKE_BUILD_TYPE=Release -DCMAKE_INSTALL_PREFIX=/usr/local
!make install -j2
pip install mojimoji
pip install attrdict
pip install pyknp
import random
import time
import numpy as np
from tqdm import tqdm
import torch
from torch import nn
import torch.optim as optim
import torchtext
from utils.dataloader import get_chABSA_DataLoaders_and_TEXT
from utils.bert import BertTokenizer
import sys
sys.path.append('/content/drive/MyDrive')
num_class = 6
学習
train_dl, val_dl, TEXT, dataloaders_dict= get_chABSA_DataLoaders_and_TEXT(max_length=256, batch_size=32, num_class=num_class)
>>
['風邪', 'か', '肺炎', 'か', 'を', '痰', 'で', '[UNK]', '黄色', 'より', '濃い', 'か', '薄い', 'か', 'が', 'ポイント', '△', '肺炎', 'だ', 'と', '[UNK]', '痰', 'の', '色', 'が', '濃い', '[UNK]', '黄色', '緑色', '茶色', 'である', 'こと', 'が', '多い', '△', '風邪', 'だ', 'と', '[UNK]', '痰', 'の', '色', 'が', '薄い', '[UNK]', '無色', '白色', '黄色', '濃い', 'もの', 'は', '炎症', '(', '肺炎', ')', 'を', '起こして', 'いる', '可能', '性', 'が', '高い', '医者', 'に', '行こう']
['風邪', 'な', 'の', 'か', 'コロナ', 'な', 'の', 'か', 'ストレス', 'な', 'の', 'か', '疲れ', 'な', 'の', 'か', 'わから', 'ん', 'が', '[UNK]', '[UNK]', 'くれ']
:
:
:
['風邪', 'は', '風邪', '薬', 'が', '[UNK]', 'いる', 'と', 'いう', 'こと']
モデル実装
from utils.bert import get_config, BertModel,BertForchABSA, set_learned_params
# モデル設定のJOSNファイルをオブジェクト変数として読み込みます
config = get_config(file_path="/weights/bert_config.json")
# BERTモデルを作成します
net_bert = BertModel(config)
# BERTモデルに学習済みパラメータセットします
net_bert = set_learned_params(
net_bert, weights_path="/weights/pytorch_model.bin")
# モデル構築
net = BertForchABSA(net_bert, num_class=num_class)
# 訓練モードに設定
net.train()
print('ネットワーク設定完了')
ファインチューニング用の設定
# 勾配計算を最後のBertLayerモジュールと追加した分類アダプターのみ実行
# 1. まず全部を、勾配計算Falseにしてしまう
for name, param in net.named_parameters():
param.requires_grad = False
# 2. 最後のBertLayerモジュールを勾配計算ありに変更
for name, param in net.bert.encoder.layer[-1].named_parameters():
param.requires_grad = True
# 3. 識別器を勾配計算ありに変更
# num_classが2と6で分類器が異なるため、設定も異なる。
if num_class == 2:
for name, param in net.cls1.named_parameters():
param.requires_grad = True
for name, param in net.cls2.named_parameters():
param.requires_grad = True
for name, param in net.cls3.named_parameters():
param.requires_grad = True
elif num_class == 6:
for name, param in net.cls1.named_parameters():
param.requires_grad = True
for name, param in net.cls2.named_parameters():
param.requires_grad = True
# 最適化手法の設定
# BERTの元の部分はファインチューニング
if num_class == 2:
optimizer = optim.Adam([
{'params': net.bert.encoder.layer[-1].parameters(), 'lr': 5e-5},
{'params': net.cls1.parameters(), 'lr': 5e-5},
{'params': net.cls2.parameters(), 'lr': 5e-5},
{'params': net.cls3.parameters(), 'lr': 5e-5}
], betas=(0.9, 0.999))
elif num_class == 6:
optimizer = optim.Adam([
{'params': net.bert.encoder.layer[-1].parameters(), 'lr': 5e-5},
{'params': net.cls1.parameters(), 'lr': 5e-5},
{'params': net.cls2.parameters(), 'lr': 5e-5}
], betas=(0.9, 0.999))
# 損失関数の設定
criterion = nn.CrossEntropyLoss()
# 学習・検証を実施
from utils.train import train_model
# 学習・検証を実行する。
# lossとaccを取得して、matplotlibでグラフ化するように変更する
if num_class == 2:
num_epochs = 7
elif num_class == 6:
num_epochs = 7
net_trained, epochs_list, train_loss, train_acc, val_loss, val_acc = train_model(net, dataloaders_dict,criterion, optimizer, num_epochs=num_epochs)
import matplotlib.pyplot as plt
%matplotlib inline
# 現在時刻を保存
tokyo_tz = datetime.timezone(datetime.timedelta(hours=9))
time_now = datetime.datetime.now(tokyo_tz)
time_now = time_now.strftime("%Y%m%d%H%M%S")
# グラフにするデータを取得
x = epochs_list
y_tloss = torch.Tensor(train_loss).cpu().numpy()
y_tacc = torch.Tensor(train_acc).cpu().numpy()
y_vloss = torch.Tensor(val_loss).cpu().numpy()
y_vacc = torch.Tensor(val_acc).cpu().numpy()
fig = plt.figure()
# 軸1をtrainに、軸2をtestにする
ax1 = fig.subplots()
ax2 = ax1.twinx()
ax1.plot(x, y_tacc, label="train_acc")
ax1.plot(x, y_vacc, label="val_acc")
ax2.plot(x, y_tloss, label="train_loss", color="g")
ax2.plot(x, y_vloss, label="val_loss", color="m")
# 凡例を表示
h1, l1 = ax1.get_legend_handles_labels()
h2, l2 = ax2.get_legend_handles_labels()
ax1.legend(h1 + h2, l1 + l2, bbox_to_anchor=(1.1, 1), loc='upper left', borderaxespad=0)
# epoch数、クラス数、時間をファイル名を入れてファイルを保存
file_name = f"/images/BERT_fine_tuning_{num_epochs}epochs_{num_class}value_{time_now}.png"
plt.savefig(file_name)
# Colab上でグラフを表示
print(file_name)
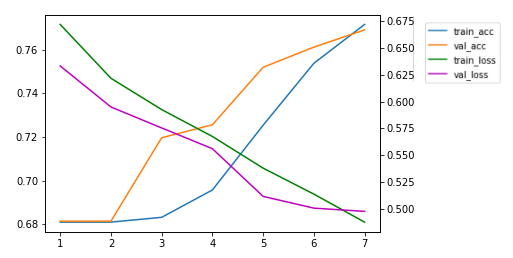
# 学習したネットワークパラメータを保存します
save_weight_path = f"/weights/BERT_fine_tuning_{num_epochs}epochs_{num_class}value_{time_now}.pth"
torch.save(net_trained.state_dict(), save_weight_path)
予測
from utils.config import *
from utils.predict import predict, create_vocab_text, build_bert_model
from IPython.display import HTML, display
#TEXTオブジェクト(torchtext.data.field.Field)をpklファイルにダンプしておく(推論時に利用するため)
# 1度生成すればOK
TEXT = create_vocab_text()
>>
['(', '0', '月', '0', '月', '養育', '支援', '週', '0', ')', '0', '月', 'は', '[UNK]', '[UNK]', '0', '月', 'から', 'やっと', '子供', 'たち', '同じ', '園', 'に', '[UNK]', '[UNK]', '保育', 'コロナ', 'で', '[UNK]', '子供', '達', 'も', '喘息', '持ち', 'だ', 'から', '家庭', '保育', '[UNK]', 'と', '思った', 'けど', '[UNK]', 'ダメ', '(', '子供', 'に', '強く', '[UNK]', 'あたる', '自己', '嫌悪', '起き', 'れ', 'ない', '[UNK]']
['「', '[UNK]', 'いっ', 'か', '」', 'と', '思える', 'こと', 'が', 'ある', '意味', '自分', 'を', '[UNK]', 'ことだ', 'と', '思って', 'ます', '声', 'に', '出して', 'みて', 'ください', '大きく', '息', 'を', '[UNK]', 'その', '息', 'を', '全部', '使って', '「', '[UNK]', 'か', '」', '少し', 'だけ', '気持ち', 'が', '[UNK]', 'なり', 'ませ', 'ん', 'か', '?', '頭痛', '[UNK]', '生理', '痛']
net_trained =BertForchABSA(net_bert, num_class=num_class)
# セーブしてあるパラメータを使用
if num_class == 2:
save_path = '/weights/save_params/BERT_fine_tuning_7epochs_2value_20220217191645.pth'
elif num_class == 6:
save_path = '/weights/save_params/BERT_fine_tuning_7epochs_6value_20220222004328.pth'
# 直前にセーブしたパラメータを使用
# save_path = save_weight_path
# 学習したネットワークパラメータをロード
net_trained.load_state_dict(torch.load(save_path, map_location='cpu'))
net_trained.eval()
input_text = "ひどい咳が止まらん"
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net_trained.eval()
net_trained.to(device)
html_output = predict(input_text, net_trained, num_class=num_class)
print("======================推論結果の表示======================")
print(input_text)
display(HTML(html_output))
>>
['ひどい', '咳', 'が', '止まら', 'ん']
[2, 21623, 27740, 11, 25794, 1357, 3]
======================推論結果の表示======================
推論ラベル:Symptom(クラス数2)
推論ラベル:None(クラス数6)
クラス数が2の時は症状ありとして予測されたが、クラス数6の時は症状なしとして予測された。
HTMLで表示してみると重みが違うのがわかる。


from utils.config import *
from utils.predict import predict2, create_vocab_text, build_bert_model
import pandas as pd
import numpy as np
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
if num_class == 6:
read_csv_path = '/data/test_data/test_6value.csv'
elif num_class == 2:
read_csv_path = '/data/test_data/test_2value.csv'
df = pd.read_csv(read_csv_path, engine="python", encoding="utf-8-sig")
df["PREDICT"] = np.nan #予測列を追加
net_trained.eval() #推論モードに。
for index, row in df.iterrows():
df.at[index, "PREDICT"] = predict2(row['INPUT'], net_trained).cpu().numpy()[0] # GPU環境の場合は「.cpu().numpy()」としてください。
print(read_csv_path)
>>
['お', '疲れ', '[UNK]', '頭痛', '大事に', 'して', 'ください']
[2, 273, 22788, 1, 18939, 28464, 19, 13880, 3]
:
:
:
['発症', 'して', '咳', '出', '[UNK]', '説明', 'すら', 'でき', 'ない', 'よ', 'ね', '死ぬ', 'かも', 'わから', 'ん', 'し', 'コロナ', 'かかり', 'たく', '[UNK]']
[2, 7005, 19, 27740, 1047, 1, 1354, 5046, 261, 47, 1291, 2382, 7249, 3766, 9774, 1357, 31, 26834, 9758, 5828, 1, 3]
tokyo_tz = datetime.timezone(datetime.timedelta(hours=9))
time_now = datetime.datetime.now(tokyo_tz)
time_now = time_now.strftime("%Y%m%d%H%M%S")
save_csv_path = f"//data/predicted/predicted_test_{num_epochs}epochs_{num_class}value_{time_now}.csv"
df.to_csv(save_csv_path, encoding="utf-8-sig", index=False)
print(save_csv_path)
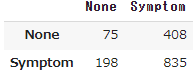
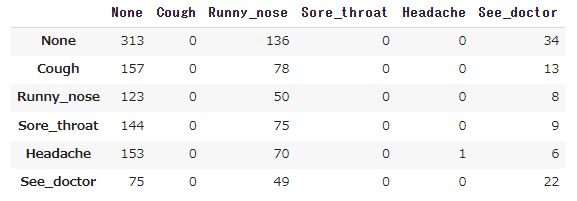
混同行列
y_true =[]
y_pred =[]
# セーブしてあるデータを使用
df = pd.read_csv("/data/predicted/predicted_test_7epochs_2value_20220217192200.csv")
# 直前にセーブしたデータを使用
# df = pd.read_csv(save_csv_path, engine="python", encoding="utf-8-sig")
for index, row in df.iterrows():
if row['LABEL'] == 0:
y_true.append("None")
if row['LABEL'] ==1:
y_true.append("Symptom")
if row['PREDICT'] ==0:
y_pred.append("None")
if row['PREDICT'] ==1:
y_pred.append("Symptom")
# 混同行列(confusion matrix)の取得
labels = ["None", "Symptom"]
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_true, y_pred, labels=labels)
# データフレームに変換
cm_labeled = pd.DataFrame(cm, columns=labels, index=labels)
# 結果の表示
cm_labeled
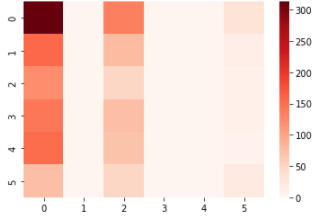
2値分類
6クラス分類
# vocab change
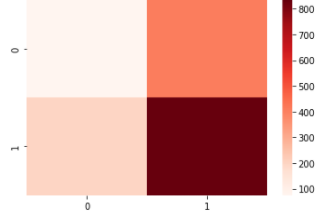
import seaborn as sns
import matplotlib.pyplot as plt
sns.heatmap(cm, cmap='Reds')
2値分類
6クラス分類
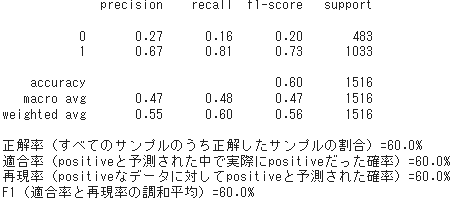
from sklearn.metrics import classification_report
y_true =[]
y_pred =[]
# セーブしてあるデータを使用
df = pd.read_csv("/data/predicted/predicted_test_7epochs_2value_20220217192200.csv")
# 直前にセーブしたデータを使用
# df = pd.read_csv(save_csv_path, engine="python", encoding="utf-8-sig")
for index, row in df.iterrows():
y_true.append(row["LABEL"])
y_pred.append(row["PREDICT"])
print(y_true)
print(classification_report(y_true, y_pred))
print("正解率(すべてのサンプルのうち正解したサンプルの割合)={}%".format((round(accuracy_score(y_true, y_pred),2)) *100 ))
print("適合率(positiveと予測された中で実際にpositiveだった確率)={}%".format((round(precision_score(y_true, y_pred, average="micro"),2)) *100 ))
print("再現率(positiveなデータに対してpositiveと予測された確率)={}%".format((round(recall_score(y_true, y_pred, average="micro"),2)) *100 ))
print("F1(適合率と再現率の調和平均)={}%".format((round(f1_score(y_true, y_pred, average="micro"),2)) *100 ))
2値分類
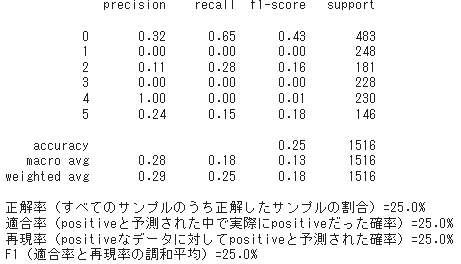
6クラス分類
考察
1か月以上パラメータを変えたりして取り組んでみたけど、全体的に思うほど精度が上がらなかった。
2クラス分類では分類器のパラメータを変えて、何とかF1スコアが0.6に達した感じ。
6クラス分類ではNoneに偏ることが多く、Twitterで取得したデータの前処理にも原因があると思う。
またすべての単語に対応しているわけではないので、Vocab.txtの改善も検討する必要がありそう。
最終的な目標として、症状を判断して薬を提案するところまで改善していきたい。
参考資料
Twitter API
APIリファレンス(公式)
Python Twitterからツイートを取得してテキスト分析(wordcloudで見える化)
【Python】tweepyを使ってツイートを全取得し、エクセルファイルに落とし込む
TwitterAPIを用いたキーワード検索によるデータ収集
PythonでTwitter APIを使って検索できるようにしてみた
Pythonで特定のキーワードが付与されたツイート収集する方法
Pythonメモ: Tweepyのややこしいレスポンスデータの読み方 〜Twitter API活用の最初の難関〜
Tweepyで取得できるStatusの中身(つぶやき)データ一覧
BERTモデル
BERTを用いたネガポジ分類機の作成
【書籍】つくりながら学ぶ! PyTorchによる発展ディープラーニング
Juman++
日本語形態素解析システム JUMAN++(京大院情報学研究科)
ColabでJUMAN++を使う
ライブラリ
ModuleNotFoundError: No module named 'torchtext.data.field'
PyTorchで日本語BERTによる文章分類&Attentionの可視化を実装してみた
matplotlib
Pythonで2軸グラフ表示 Matplotlib 〜Y軸を2本にしてみる:twinx その 1〜
[Python]matplotlibで左右に2つの軸があるグラフを書く方法
matplotlib の legend(凡例) の 位置を調整する
【python】matplotlibでグラフに色を指定する方法【カラーマップ】
予測
混同行列
混同行列・python・sckit-learn・機械学習を理解したい!ための記事
多クラス混同行列とその評価指標〜マクロ平均、マイクロ平均〜
多クラス問題の精度検証!マイクロ平均とマクロ平均の違い!
sklearnで混同行列をヒートマップにして描画するplot_confusion_matrix