この投稿は 「自然言語処理 Advent Calendar 2019 - Qiita」 の25日目の記事です。
sinyです。
この記事では、2019年時点の自然言語処理において大きな役割を果たしているBERTを使ったネガポジ分類機の作成についてまとめました。
はじめに
書籍、ブログやQiitaなどでBERTに関するナレッジはだいぶ出回って来たと思います。
しかし、自然言語処理に活用できるデータセットの多くが英語をベースとしており、日本語のデータセットがあまりない状況のため、なかなか日本語のテキストを使ってBERTを活用するという事例、情報が少ないと感じました。
現状、無料で使える日本語データセットとしては以下がメジャーかと思います。
「ある程度のデータ数があり、日本語のテキストデータでしかも無料で使えるデータセットはないものか?」と探していたところ、chABSA-datasetという日本語のデータセット(約2800データ)を見つけました。
chABSA-datasetは上場企業の有価証券報告書をベースに作成された日本語データセットです。
各文に対してネガティブ・ポジティブの感情分類だけでなく、「何が」ネガティブ・ポジティブなのかという観点を表す情報が含まれています。
以下はchABSA-datasetのサンプルデータです。
{
"header": {
"document_id": "E00008",
"document_name": "ホクト株式会社",
"doc_text": "有価証券報告書",
"edi_id": "E00008",
"security_code": "13790",
"category33": "水産・農林業",
"category17": "食品",
"scale": "6"
},
"sentences": [
{
"sentence_id": 0,
"sentence": "当連結会計年度におけるわが国経済は、政府の経済政策や日銀の金融緩和策により、企業業績、雇用・所得環境は改善し...",
"opinions": [
{
"target": "わが国経済",
"category": "NULL#general",
"polarity": "neutral",
"from": 11,
"to": 16
},
{
"target": "企業業績",
"category": "NULL#general",
"polarity": "positive",
"from": 38,
"to": 42
},...
],
},
{
"sentence_id": 1,
"sentence": "当社グループを取り巻く環境は、実質賃金が伸び悩むなか、消費者の皆様の...",
"opinions": [
{
"target": "実質賃金",
"category": "NULL#general",
"polarity": "negative",
"from": 15,
"to": 19
},...
]
},...
]
}
「chABSA-datasetであれば、データ数も数千件あり、感情を表す値もあるのでネガポジ分類に使えるかも?」ということで、このデータセットでBERTのネガポジ分類機を作成してみました。
なお、本記事で説明している実装コードはすべて以下githubにありますので適宜Cloneしてお使いください。
また、各処理についてはgithubのBERTモデル作成~学習~推論.ipynbに記載されていますので適宜参照ください。
「chABSA-dataset」(https://github.com/sinjorjob/chABSA-dataset)
目次
- 前提
- 環境構築
- ネガポジ分類のBERTモデル概要図
- ネガポジ学習用データセットの作成
- BERT用Tokenizerの実装
- DataLoaderを作成
- BERTによるネガポジ分類モデル実装
- BERTファインチューニングの設定
- BERTの学習・推論
- 学習結果
- テスト文章をインプットして予測値とAttentionを可視化する
- 大量のテストデータで推論結果と混合行列を表示
- まとめ
1.前提
この記事では、以下の前提でネガポジ分類機を作成していきます。
| 項目 | 意味|
|:--|:--|:--|
| OS | Ubuntu |
| BERTモデル | 京都大学が公開しているpytorch-pretrained-BERTモデルをベースにファインチューニングを行う。|
| 形態素解析| Juman++ (v2.0.0-rc2) or (v2.0.0-rc3) |
|ライブラリ | Pytorch|
2.環境構築
PyTorchでBERT日本語Pretrainedモデルを利用できる環境を構築します。
ライブラリのインストール
conda create -n pytorch python=3.6
conda activate pytorch
conda install pytorch=0.4 torchvision -c pytorch
conda install pytorch=0.4 torchvision cudatoolkit -c pytorch
conda install pandas jupyter matplotlib scipy scikit-learn pillow tqdm cython
pip install torchtext
pip install mojimoji
pip install attrdict
pip install pyknp
※condaでうまく入らないものはpipでインストールしました。
Juman++のインストール
今回利用するBERT日本語Pretrainedモデルは、入力テキストにJuman++ (v2.0.0-rc2)で形態素解析を行っていますので、本記事でも形態素解析ツールを**Juman++**に合わせます。
Juman++の導入手順は別記事でまとめていますので、以下を参照ください。
[JUMAN++の導入手順まとめ]https://sinyblog.com/deaplearning/juman/
BERT日本語Pretrainedモデルの準備
BERT日本語Pretrainedモデルは以下のURLからダウンロードできます。
[BERT日本語Pretrainedモデル]http://nlp.ist.i.kyoto-u.ac.jp/index.php?BERT%E6%97%A5%E6%9C%AC%E8%AA%9EPretrained%E3%83%A2%E3%83%87%E3%83%AB
上記HPの「Japanese_L-12_H-768_A-12_E-30_BPE.zip (1.6G)****」からJapanese_L-12_H-768_A-12_E-30_BPE .zip**をダウンロードします。
zipファイルを解凍するといくつかファイルが入っていますが、今回必要なものは以下の3つです。
| 項目 | 意味|
|:--|:--|:--|
|bert_config.json | BERTモデル用のConfigファイル |
|pytorch_model.bin | pytorch版BERT (pytorch-pretrained-BERT)用に変換したモデル|
|vocab.txt| BERT用語録辞書データ|
全体のディレクトリ構成は以下の通りです。
├─data
│ └─chABSA #chABSAのjsonファイル
│ └─test.tsv #テスト用データ
│ └─train.tsv #訓練用データ
│ └─test_dumy.tsv #ダミーデータ
│ └─train_dumy.tsv #ダミーデータ
├─utils
│ └─bert.py #BERTモデルの定義
│ └─config.py #各種パスの定義
│ └─dataloader.py #dataloader生成用
│ └─predict.py #推論用
│ └─predict.py #推論用
│ └─tokenizer.py #形態素解析用
│ └─train.py #学習用
├─vocab # bert語録辞書vocab.txt
└─weights # bert_config.json、pytorch_model.bin
└─Create_data_from_chABSA.ipynb #tsvデータ作成
└─BERTモデル作成~学習~推論.ipynb #データローダ作成~学習~推論
※以下のファイルは容量が大きいためgitリポジトリには格納されていませんので、前者については京大HPからダウンロード、後者はNotebookに従って学習を行いモデルパラメータを各自保存してご利用ください。
pytorch_model.bin(pytorch-pretrained-BERT)
bert_fine_tuning_chABSA_22epoch.pth(ネガポジ学習済みパラメータファイル)
3.ネガポジ分類のBERTモデル概要図
今回実装するネガポジ分類のBERTモデルの概要図です。

上記BERTモデルは、書籍「つくりながら学ぶ! PyTorchによる発展ディープラーニング」のソースコードを元に作成しています。
本記事ではBERTモデルの詳細については解説しませんので、興味がある方は書籍の方を参考にしてみてください。
※ソースコード自体は上記リンク先で公開されています。
ポイントだけ解説すると、BERTのソースコード自体はhuggingface/transformersをベースに作られており、BERTモデルの末尾にネガポジ分類のための全結合層(Linear)を追加し、出力として2クラス分類**[ネガティブ(0)or ポジティブ(1)]を出力するモデルにしています。
クラス分類には入力した文章データの1単語目[CLS]**の特徴量を利用します。
4.ネガポジ学習用データセットの作成
chABSA-datasetデータセットにはjson形式のデータファイルが230個存在していますが、このままでBERTを用いたネガポジ分類機の学習データとして利用することができません。
1つのjsonファイルには複数の文章データが格納されており、以下のような情報が含まれています。
| 項目 | 意味|
|:--|:--|:--|
| sentence_id | データを一意に特定するID |
| sentence| 文章データ|
| opinions | オプションの中には{target,category,porarity,from,to}のセットが複数含まれている。 |
| target |targetにはsentenceの中でキーとなる単語が指定されている|
| category |業種の情報|
| polarity |targetのキーワードがポジティブか、ネガティブか?|
|from, to |targetのキーワードがsentenceの何文字目から何文字目に存在しているか?|
これらのjsonファイルから以下のように学習に利用できる形のtsvデータセットを作成します。
各行は「入力文章 0(ネガティブ) or 1(ポジティブ)」という形式になっています。
その一方で、中国経済の景気減速や米国新政権の政策運営、英国のEU離脱等のリスクにより、先行きは依然として不透明な状況にあります 0
化粧品・雑貨事業は、大型店による店舗展開を強化し、デジタル販促による集客やイベント開催による顧客の増大に取組み、売上高は32億62百万円(前年同期比15.5%減)となりました 0
加えて、保守契約が堅調に増加し、売上高は6,952百万円(前年同期比1.2%増)となりました 1
利益につきましては、取替工事の増加及び保守契約による安定的な利益の確保により、セグメント利益(営業利益)は1,687百万円(前年同期比2.4%増)となりました 1
その他のセグメントでは駐輪システムが堅調に推移し、売上高は721百万円(前年同期比0.8%増)となりました 1
データの作成はJupyternotebookでCreate_data_from_chABSA.ipynbのコードを実行してください。
手順に従うと、1970個の文章を含む学習用データ(train.tsv)と843個のデータを含むテスト用データ(test.tsv)が作成されます。
5. BERT用Tokenizerの実装
utils\bert.py内に入力文章を単語分割するためのBertTokenizerクラスを実装しています。
今回は日本語データセットを利用しますが、BERT日本語Pretrainedモデルの仕様に合わせてJuman++を使って形態素解析するようにします。
また、リンク先記載されている通り、以下の点を日本語用にカスタマイズしています。
bert.py内のBertTokenizerクラスで**--do_lower_case オプションをFalse**にする。
Class BertTokenizer(object):
#BERT用の文章の単語分割クラスを実装
def __init__(self, vocab_file, do_lower_case=False): #Falseに変更(英語モデルと異なる部分)
tokenizer.pyのBasicTokenizerクラス内の以下をコメントアウト
# text = self._tokenize_chinese_chars(text) #漢字が全て一文字単位になってしまうのでコメントアウトする
tokenizer.pyにJuman++で形態素解析するJumanTokenizeクラスを追加しています。
from pyknp import Juman
class JumanTokenize(object):
"""Runs JumanTokenizer."""
def __init__(self):
self.juman = Juman()
def tokenize(self, text):
result = self.juman.analysis(text)
return [mrph.midasi for mrph in result.mrph_list()]
上記JumanTokenizerクラスを利用すると以下のように入力文章をJuman++で形態素解析してくれます。
cd chABSA-dataset
python
>>>from utils.tokenizer import JumanTokenize
>>>from pyknp import Juman
>>>text = "経常収益は、貸出金利息など資金運用収益の減少を主因に、前年度比8億81百万円減少し2,278億11百万円となりました"
>>>juman = JumanTokenize()
>>>print(juman.tokenize(text))
['経常', '収益', 'は', '、', '貸出', '金', '利息', 'など', '資金', '運用', '収益', 'の', '減少', 'を', '主因', 'に', ' 、', '前', '年度', '比', '8億81百万', '円', '減少', 'し', '2,278億11百万', '円', 'と', 'なり', 'ました']
>>>
6. DataLoaderを作成
学習及びテスト用のデータを生成するためにtorchtextでDataLoaderを作成します。
今回はDataLoder作成用関数「get_chABSA_DataLoaders_and_TEXT」をdataloder.py内に作成していますのでこれを利用します。
※BERTを用いる場合は細かい前処理をしないほうが良いという意見もあるようですが、今回は前処理として以下を追加しています。
- 「半角→全角」
- 「改行、半角スペース、全角スペースを削除」
- 「数字文字をすべて0に統一」
- 「カンマ、ピリオド以外の記号をスペースに置換」
get_chABSA_DataLoaders_and_TEXT関数の戻り値は以下の通りです。
| 項目 | 意味|
|:--|:--|:--|
|train_dl | 訓練用データセット |
|val_dl | 検証用データセット|
|TEXT| torchtext.data.field.Fieldオブジェクト|
|dataloaders_dict| 学習用と検証用データのiterator辞書データ**※1**|
※1 dataloaders_dictは学習、検証時に利用する。
torchtextの利用方法がよくわからない方は以下の記事も参考にしてみてください。
pytorchテキスト前処理(torchtext)【入門者向け】
以下がDataloaderを生成するコードです。
from utils.dataloader import get_chABSA_DataLoaders_and_TEXT
from utils.bert import BertTokenizer
train_dl, val_dl, TEXT, dataloaders_dict= get_chABSA_DataLoaders_and_TEXT(max_length=256, batch_size=32)
生成した学習用データ(train_dl)からデータを取り出して中身を確認してみます。
# 動作確認 検証データのデータセットで確認
batch = next(iter(train_dl))
print("Textの形状=", batch.Text[0].shape)
print("Labelの形状=", batch.Label.shape)
print(batch.Text)
print(batch.Label)
以下の通り、Text(入力データ)にはバッチサイズ(32個)分の文章データ(長さのMaxは256)が生成されています。
入力データは単語リストをIDに変換して数値のリストデータになっています。
Labelには該当文章が0(ネガティブ)か1(ポジティブ)の正解ラベルが格納されています。
Textの形状= torch.Size([32, 256])
Labelの形状= torch.Size([32])
(tensor([[ 2, 3718, 534, ..., 0, 0, 0],
[ 2, 17249, 442, ..., 0, 0, 0],
[ 2, 719, 3700, ..., 0, 0, 0],
...,
[ 2, 719, 3700, ..., 0, 0, 0],
[ 2, 64, 6, ..., 0, 0, 0],
[ 2, 1, 3962, ..., 0, 0, 0]]), tensor([68, 48, 31, 30, 33, 89, 55, 49, 53, 29, 61, 44, 21, 69, 51, 48, 30, 32,
54, 31, 39, 28, 27, 24, 24, 48, 21, 86, 39, 51, 71, 42]))
tensor([0, 1, 0, 1, 1, 1, 1, 0, 0, 1, 0, 0, 1, 0, 0, 1, 1, 1, 0, 1, 1, 0, 1, 0,
1, 1, 0, 1, 0, 1, 0, 0])
念のため、ミニバッチから1文章取り出し、数値化されているリストデータをtokenizer_bertのids_to_tokensメソッドに渡して元の文章(単語)に復元してみます。
# ミニバッチの1文目を確認してみる
tokenizer_bert = BertTokenizer(vocab_file="./vocab/vocab.txt", do_lower_case=False)
text_minibatch_1 = (batch.Text[0][1]).numpy()
# IDを単語に戻す
text = tokenizer_bert.convert_ids_to_tokens(text_minibatch_1)
print(text)
['[CLS]', '営業', '利益', 'は', '、', '完成', '工事', '総', '利益', '率', 'が', '向上', 'した', 'こと', 'から', '、', '前', '連結', '会計', '年度', '比', '[UNK]', '.', '[UNK]', '%', '増', 'の', '[UNK]', '円', '(', '前', '連結', '会計', '年度', 'は', '[UNK]', '円', ')', 'と', 'なった', '[SEP]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]']
文章の開始は**[CLS]、末尾が[SEP]、未知語は[UNK]、256文字に満たない部分は[PAD]**でpaddingされます。
以上、データセットの作成と実際に生成されるミニバッチを確認しました。
7.BERTによるネガポジ分類モデル実装
続いてBERTによるネガポジ分類モデルを実装していきます。
今回実装する以下のBERTモデルはutils\bert.py内にBertModelクラスとして定義しているのでこのクラスを使ってモデルを生成します。

モデル構築にあたっては、以下のファイルを利用します。
| 項目 | 説明|
|:--|:--|:--|
|bert_config.json | BERTモデルのパラメータファイル |
|pytorch_model.bin | 学習済みBERTモデル|
まず、BertModelクラスにconfig設定ファイルを引数に指定してベースのBERTモデルを作ったあと、bert.py内に定義されているset_learned_paramsメソッドを使って学習済みのBERTモデル(pytorch_model.bin)のパラメータをセットします。
その後、BertForchABSAクラスを使ってネガポジ分類モデルを生成したあと、**net.train()**で学習モードにしておきます。
モデルを生成するコードは以下の通りです。
from utils.bert import get_config, BertModel,BertForchABSA, set_learned_params
# モデル設定のJOSNファイルをオブジェクト変数として読み込む
config = get_config(file_path="./weights/bert_config.json")
# ベースのBERTモデルを生成
net_bert = BertModel(config)
# BERTモデルに学習済みパラメータセット
net_bert = set_learned_params(
net_bert, weights_path="./weights/pytorch_model.bin")
# BERTネガポジ分類モデルを生成(モデルの末尾にネガポジ分類のための全結合層(Linear)を追加)
net = BertForchABSA(net_bert)
# 訓練モードに設定
net.train()
8.BERTファインチューニングの設定
BERTの元論文では12段のBertLayer(Self-Attention)層すべてをファインチューニングしていますが、今回は最後の1層+ネガポジ分類機のみを学習対象としています。
# 勾配計算を最後のBertLayerモジュールと追加した分類アダプターのみ実行
# 1. 全体の勾配計算Falseにセット
for name, param in net.named_parameters():
param.requires_grad = False
# 2. 最後のBertLayerモジュールだけ勾配計算ありに変更
for name, param in net.bert.encoder.layer[-1].named_parameters():
param.requires_grad = True
# 3. 識別器(ネガティブorポジティブ)を勾配計算ありに変更
for name, param in net.cls.named_parameters():
param.requires_grad = True
次に、学習に使うオプティマイザーと損失関数を指定します。
BertLayer(Self-Attention)の最終層と識別機ともにTorch.optim.Adamクラスを使います。
学習率(lr)は5e-e、betasはデフォルト値の**(0.9, 0.999)**を指定(参考書籍の値をそのまま採用)しています。
そして、今回はネガティブ or ポジティブの2クラス分類なので、criterionにはtorch.nn.CrossEntropyLossを指定しています。
# BERTの元の部分はファインチューニング
optimizer = optim.Adam([
{'params': net.bert.encoder.layer[-1].parameters(), 'lr': 5e-5},
{'params': net.cls.parameters(), 'lr': 5e-5}
], betas=(0.9, 0.999))
# 損失関数の設定
criterion = nn.CrossEntropyLoss()
# nn.LogSoftmax()を計算してからnn.NLLLoss(negative log likelihood loss)を計算
9.BERTの学習・推論
つづいて学習・検証を実施します。
utls.py\train.pyに定義されている学習&検証用の関数train_modelを使って学習と検証を行います。
学習には**train.tsv(1970個)を、検証にはtest.tsv(843個)**のデータを使います。
学習にはCPU環境だと時間がかかるのでGoogle CoraboratoryなどGPU環境の利用をお勧めします。
※Corei7 8コア、16GBメモリのCPU環境で試したところ1epoch30分前後かかりました。
# 学習・検証を実施
from utils.train import train_model
# 学習・検証を実行する。
num_epochs = 1 #適宜エポック数は変更してください。
net_trained = train_model(net, dataloaders_dict,
criterion, optimizer, num_epochs=num_epochs)
# 学習したネットワークパラメータを保存(今回は22epoch回した結果を保存する想定でファイル名を記載)
save_path = './weights/bert_fine_tuning_chABSA_22epoch.pth'
torch.save(net_trained.state_dict(), save_path)
train_modelの引数は以下の通りです。
| 項目 | 説明|
|:--|:--|:--|
|net | BERTネガポジ分類モデル |
|dataloaders_dict | 学習用&検証用のIterator|
|criterion | 損失関数|
|optimizer | オプティマイザー|
|num_epochs | エポック数|
実行すると以下ように10イテレーション毎の正解率とEpoch毎のLosstとAccが表示されます。
使用デバイス: cpu
-----start-------
イテレーション 10 || Loss: 0.6958 || 10iter: 294.9368 sec. || 本イテレーションの正解率:0.46875
イテレーション 20 || Loss: 0.7392 || 10iter: 288.1598 sec. || 本イテレーションの正解率:0.4375
イテレーション 30 || Loss: 0.6995 || 10iter: 232.9404 sec. || 本イテレーションの正解率:0.53125
イテレーション 40 || Loss: 0.5975 || 10iter: 244.0613 sec. || 本イテレーションの正解率:0.6875
イテレーション 50 || Loss: 0.5678 || 10iter: 243.3908 sec. || 本イテレーションの正解率:0.71875
イテレーション 60 || Loss: 0.5512 || 10iter: 269.5538 sec. || 本イテレーションの正解率:0.6875
Epoch 1/1 | train | Loss: 0.6560 Acc: 0.5975
Epoch 1/1 | val | Loss: 0.5591 Acc: 0.7711
10. 学習結果
今回は以下の3パターンでepoch数のMAXを50にして精度比較してみました。
- BertLayer(Self-Attention)の最終層だけファインチューニング
- BertLayer(Self-Attention)の後ろ2層だけファインチューニング
- BertLayer(Self-Attention)の後ろ6層をファインチューニング
結果は以下の通りです。

以下は評価のまとめです。
- 今回のモデルでは、ファインチューニング対象を増やしても精度向上にはほとんど効果がなかった。
- 大体5epochぐらい回すと精度が86%前後に到達しその後epoch数を増やしても大きく精度は上がらない。
- 20epoch超えてくると過学習が顕著になってくる。
結局、BertLayerの最終層だけファインチューニングして22epoch回した時点が正解率MAX(87.76%)となりました。
11.テスト文章をインプットして予測値とAttentionを可視化する
学習したBERTネガポジ分類モデルを使って、サンプルの文章を与えてネガポジ予測値とAttention(どの単語を重視して判定されたか?)を可視化します。
※Attentionはhtml形式で表示するのでJupyterNotebookを利用すると分かりやすいです。
事前準備
推論時にtorchtextで生成したTEXTオブジェクト(torchtext.data.field.Field)を利用するため、一旦TEXTオブジェクトをpklファイルにダンプしておきます。
from utils.predict create_vocab_text
TEXT = create_vocab_text()
上記コードを実行すると\chABSA-dataset\data配下にtext.pklが生成されます。
create_vocab_textメソッドはpredict.py内に定義されています。
\chABSA-dataset\data配下にあるダミーデータ(train_dumy.tsv、test_dumy.tsv)とBERT用語録データ(vocab.txt)を利用してTEXTオブジェクトを生成後にpickleで出力しています。
def create_vocab_text():
TEXT = torchtext.data.Field(sequential=True, tokenize=tokenizer_with_preprocessing, use_vocab=True,
lower=False, include_lengths=True, batch_first=True, fix_length=max_length, init_token="[CLS]", eos_token="[SEP]", pad_token='[PAD]', unk_token='[UNK]')
LABEL = torchtext.data.Field(sequential=False, use_vocab=False)
train_val_ds, test_ds = torchtext.data.TabularDataset.splits(
path=DATA_PATH, train='train_dumy.tsv',
test='test_dumy.tsv', format='tsv',
fields=[('Text', TEXT), ('Label', LABEL)])
vocab_bert, ids_to_tokens_bert = load_vocab(vocab_file=VOCAB_FILE)
TEXT.build_vocab(train_val_ds, min_freq=1)
TEXT.vocab.stoi = vocab_bert
pickle_dump(TEXT, PKL_FILE)
return TEXT
推論とAttention可視化の実行
utils\predict.pyに学習済みモデルのビルド(build_bert_model)と推論(predict)のメソッドを定義してあるので、これを利用してサンプルの文章をインプットして予測値とAttentionを可視化します。
AttentionはIPythonを使ってHTMLを可視化します。
from utils.config import *
from utils.predict import predict, build_bert_model
from IPython.display import HTML, display
input_text = "以上の結果、当連結会計年度における売上高1,785百万円(前年同期比357百万円減、16.7%減)、営業損失117百万円(前年同期比174百万円減、前年同期 営業利益57百万円)、経常損失112百万円(前年同期比183百万円減、前年同期 経常利益71百万円)、親会社株主に帰属する当期純損失58百万円(前年同期比116百万円減、前年同期 親会社株主に帰属する当期純利益57百万円)となりました"
net_trained = build_bert_model()
html_output = predict(input_text, net_trained)
print("======================推論結果の表示======================")
print(input_text)
display(HTML(html_output))
上記コードを実行すると以下のような結果が表示されます。
※未知語の部分は[UNK]として表示

12.大量のテストデータで推論結果と混合行列を表示
大量のテストデータを使って自動で推論を行い、結果を評価するために混合行列の情報を表示させます。
まずは必要なモジュールをインポートします。
from utils.config import *
from utils.predict import predict2, create_vocab_text, build_bert_model
import pandas as pd
import numpy as np
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
混合行列はsklearnを使って表示します。
また、予測値(preds)だけを返するメソッドpredict2をutils\predict.py内に追加しています。
def predict2(input_text, net_trained):
TEXT = pickle_load(PKL_FILE) #vocabデータのロード
input = conver_to_model_format(input_text, TEXT)
input_pad = 1 # 単語のIDにおいて、'<pad>': 1 なので
input_mask = (input != input_pad)
outputs, attention_probs = net_trained(input, token_type_ids=None, attention_mask=None,
output_all_encoded_layers=False, attention_show_flg=True)
_, preds = torch.max(outputs, 1) # ラベルを予測
#html_output = mk_html(input, preds, attention_probs, TEXT) # HTML作成
return preds
インプットするデータはtest.csvファイルとして以下のようなデータを準備しておくこととします。

続いて、上記test.csvをpandasで読み込み、INPUT列の文章を1つずつ学習済みBERTモデルに与えてネガポジ判定を行い予測結果をPREDICT列に格納していきます。
最後まで処理したらpredicted_test.csvとして保存します。
df = pd.read_csv("test.csv", engine="python", encoding="utf-8-sig")
net_trained.eval() #推論モードに。
for index, row in df.iterrows():
df.at[index, "PREDICT"] = predict(row['INPUT'], net_trained).numpy()[0] # GPU環境の場合は「.cpu().numpy()」としてください。
df.to_csv("predicted_test .csv", encoding="utf-8-sig", index=False)
以下のような予測結果が追記されたpredicted_test.csvが生成されます。

最後にこのcsvファイルの結果から混合行列の情報を表示します。
# 混合行列の表示(評価)
y_true =[]
y_pred =[]
df = pd.read_csv("predicted_test .csv", engine="python", encoding="utf-8-sig")
for index, row in df.iterrows():
if row['LABEL'] == 0:
y_true.append("negative")
if row['LABEL'] ==1:
y_true.append("positive")
if row['PREDICT'] ==0:
y_pred.append("negative")
if row['PREDICT'] ==1:
y_pred.append("positive")
print(len(y_true))
print(len(y_pred))
# 混同行列(confusion matrix)の取得
labels = ["negative", "positive"]
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_true, y_pred, labels=labels)
# データフレームに変換
cm_labeled = pd.DataFrame(cm, columns=labels, index=labels)
# 結果の表示
cm_labeled
以下のような混合行列が表示されます。
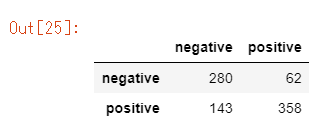
見方は、左側のnegative,positveが実際のデータのラベルで、縦方向のnegative,positveが予測値です。
例えば、「62」という数値はネガティブなデータのうち誤ってpositiveと予測されたデータ数を表しています。
次に以下のコードで正解率、適合率、再現率、F値を表示します。
y_true =[]
y_pred =[]
df = pd.read_csv("predicted_test .csv", engine="python", encoding="utf-8-sig")
for index, row in df.iterrows():
y_true.append(row["LABEL"])
y_pred.append(row["PREDICT"])
print("正解率(すべてのサンプルのうち正解したサンプルの割合)={}%".format((round(accuracy_score(y_true, y_pred),2)) *100 ))
print("適合率(positiveと予測された中で実際にpositiveだった確率)={}%".format((round(precision_score(y_true, y_pred),2)) *100 ))
print("再現率(positiveなデータに対してpositiveと予測された確率)={}%".format((round(recall_score(y_true, y_pred),2)) *100 ))
print("F1(適合率と再現率の調和平均)={}%".format((round(f1_score(y_true, y_pred),2)) *100 ))
# 実行結果
正解率(すべてのサンプルのうち正解したサンプルの割合)=76.0%
適合率(positiveと予測された中で実際にpositiveだった確率)=85.0%
再現率(positiveなデータに対してpositiveと予測された確率)=71.0%
F1(適合率と再現率の調和平均)=78.0%
13.まとめ
今回は、BERTモデルをベースにネガポジを判定する全結合層(Linear)を追加して2値分類としましたが、多値分類であったり、QAへの応用など様々なタスクに応用できるようですので、今後チャレンジしてみたいと思います。
※2019/12/25追記
本記事で作成したBERTネガポジ分類機を用いたDjango REST frameworkの実装について興味がある方は**「Django Advent Calendar 2019 - Qiita 20日目の記事」**をご覧ください。