本投稿の内容
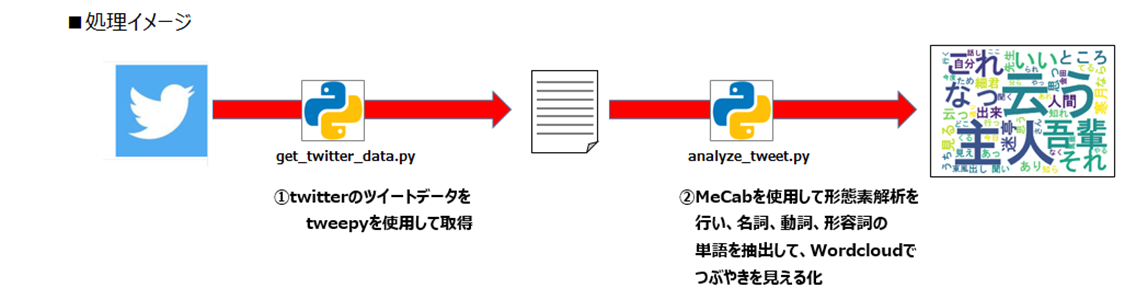
pythonでtwitterのつぶやきを取得してその内容を見える化します。
- Twitterのツイートデータをtweepyを使用して取得してテキストに出力
- MeCabを使用して形態素解析を行い、名詞、動詞、形容詞の単語を抽出してデータ分析(Wordcloudで見える化)
Twitterの検索キーワードは
7月27日に開催された「Oracle Innovation Summit Tokyo 2018」のつぶやき
ハッシュタグ「#oracleinnovation」を検索しました。
(7月27日にtwitterのデータは取得していたのですが、トラブル対応等で忙しかったので投稿がおくれました。。)
事前準備
準備は以下の4つを実施
1.Twitter APIを使用するためのアカウント申請と「Consumer API keys」、「アクセストークン」の取得
2.tweepyのインストール
3.Mecabのインストール
4.WordCloudのインストール
Twitter APIを使用するためのアカウント申請と「Consumer API keys」、「アクセストークン」の取得
7月はじめにTwitter APIを申請した際の画面キャプチャをとってましたけど
アカウント登録方法は、7月と変わっている。。
Twitter、API使用条件を厳格化 「厳しすぎる」開発者から悲鳴も
新しくなった Twitter API 登録について別投稿で纏めましたので
こちらを参考ください。
Twitter API 登録 (アカウント申請方法) から承認されるまでの手順まとめ ※2018年9月時点の情報
tweepyのインストール
Anaconda Promptを起動して tweepy をインストール
Anaconda Promptで
tweepy を 「 pip install tweepy 」 でインストール
(base) C:\Users\kngsym>pip install tweepy
Collecting tweepy
Downloading https://files.pythonhosted.org/packages/05/f1/2e8c7b202dd04117a378
ac0c55cc7dafa80280ebd7f692f1fa8f27fd6288/tweepy-3.6.0-py2.py3-none-any.whl
Requirement already satisfied: six>=1.10.0 in c:\users\kngsym\anaconda3\lib\si
te-packages (from tweepy) (1.11.0)
Requirement already satisfied: requests>=2.11.1 in c:\users\kngsym\anaconda3\l
ib\site-packages (from tweepy) (2.18.4)
Requirement already satisfied: PySocks>=1.5.7 in c:\users\kngsym\anaconda3\lib
\site-packages (from tweepy) (1.6.7)
Collecting requests-oauthlib>=0.7.0 (from tweepy)
Downloading https://files.pythonhosted.org/packages/94/e7/c250d122992e1561690d
9c0f7856dadb79d61fd4bdd0e598087dce607f6c/requests_oauthlib-1.0.0-py2.py3-none-an
y.whl
Requirement already satisfied: chardet<3.1.0,>=3.0.2 in c:\users\kngsym\anacon
da3\lib\site-packages (from requests>=2.11.1->tweepy) (3.0.4)
Requirement already satisfied: idna<2.7,>=2.5 in c:\users\kngsym\anaconda3\lib
\site-packages (from requests>=2.11.1->tweepy) (2.6)
Requirement already satisfied: urllib3<1.23,>=1.21.1 in c:\users\kngsym\anacon
da3\lib\site-packages (from requests>=2.11.1->tweepy) (1.22)
Requirement already satisfied: certifi>=2017.4.17 in c:\users\kngsym\anaconda3
\lib\site-packages (from requests>=2.11.1->tweepy) (2018.1.18)
Collecting oauthlib>=0.6.2 (from requests-oauthlib>=0.7.0->tweepy)
Downloading https://files.pythonhosted.org/packages/e6/d1/ddd9cfea3e736399b97d
ed5c2dd62d1322adef4a72d816f1ed1049d6a179/oauthlib-2.1.0-py2.py3-none-any.whl (12
1kB)
100% |████████████████████████████████| 122kB 86kB/s
notebook 5.4.0 requires ipykernel, which is not installed.
jupyter 1.0.0 requires ipykernel, which is not installed.
jupyter-console 5.2.0 requires ipykernel, which is not installed.
ipywidgets 7.1.1 requires ipykernel>=4.5.1, which is not installed.
Installing collected packages: oauthlib, requests-oauthlib, tweepy
Successfully installed oauthlib-2.1.0 requests-oauthlib-1.0.0 tweepy-3.6.0
Successfully installed oauthlib-2.1.0 requests-oauthlib-1.0.0 tweepy-3.6.0 とでれば
インストール成功!
Mecabのインストール
こちらのURLを参考にさせていただきました。
(HN:あれこれ さん、ありがとうございました)
https://toolmania.info/post-9815/
※こちらのURLの手順のみでMecabは動作しました
Windows10 となってましたが、私の環境はWindows7 でも同じ手順で実施しました
WordCloudのインストール
Anaconda Promptで
wordcloudを 「 pip install wordcloud 」 でインストール
(base) D:\> pip install wordcloud
Collecting wordcloud
Using cached https://files.pythonhosted.org/packages/bc/e8/cab8479b25297b3847c
fb55e85a5014e8c53b80e513eaf1ba58c7b3a6acd/wordcloud-1.4.1.tar.gz
Requirement already satisfied: matplotlib in c:\users\kngsym\anaconda3\lib\sit
e-packages (from wordcloud) (2.1.2)
Requirement already satisfied: numpy>=1.6.1 in c:\users\kngsym\anaconda3\lib\s
ite-packages (from wordcloud) (1.14.0)
Requirement already satisfied: pillow in c:\users\kngsym\anaconda3\lib\site-pa
ckages (from wordcloud) (5.0.0)
Requirement already satisfied: six>=1.10 in c:\users\kngsym\anaconda3\lib\site
-packages (from matplotlib->wordcloud) (1.11.0)
Requirement already satisfied: python-dateutil>=2.1 in c:\users\kngsym\anacond
a3\lib\site-packages (from matplotlib->wordcloud) (2.6.1)
Requirement already satisfied: pytz in c:\users\kngsym\anaconda3\lib\site-pack
ages (from matplotlib->wordcloud) (2017.3)
Requirement already satisfied: cycler>=0.10 in c:\users\kngsym\anaconda3\lib\s
ite-packages (from matplotlib->wordcloud) (0.10.0)
Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in c:\us
ers\kngsym\anaconda3\lib\site-packages (from matplotlib->wordcloud) (2.2.0)
Building wheels for collected packages: wordcloud
Running setup.py bdist_wheel for wordcloud ... error
Complete output from command c:\users\kngsym\anaconda3\python.exe -u -c "imp
ort setuptools, tokenize;__file__='C:\\Users\\kngsym\\AppData\\Local\\Temp\\pi
p-install-xd__zvx8\\wordcloud\\setup.py';f=getattr(tokenize, 'open', open)(__fil
e__);code=f.read().replace('\r\n', '\n');f.close();exec(compile(code, __file__,
'exec'))" bdist_wheel -d C:\Users\kngsym\AppData\Local\Temp\pip-wheel-v1rh7ipx
--python-tag cp36:
<省略>
running build_ext
building 'wordcloud.query_integral_image' extension
error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual
C++ Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools
error: Microsoft Visual C++ 14.0 is required. というエラーが出て、
イントールは失敗。
メッセージをみるに、
「Microsoft Visual C++ 14.0 がないので、http://landinghub.visualstudio.com/visual-cpp-build-tools
からインストールせよ」とある。
早速、アクセス
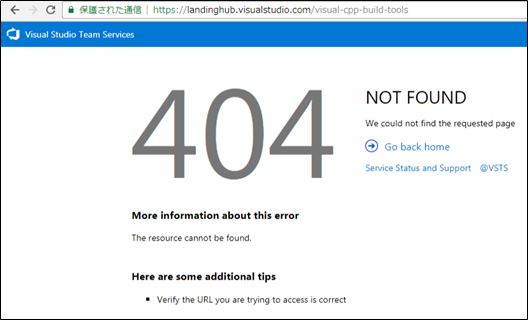
NOT FOUND。。
いろいろ調査すると
以下のURLからMicrosoft Visual C++ Build Tools をインストールできることがわかった。
※一応wordcloud はインストールできましたが、これが正しいかは断言できない。。
Microsoft Visual C++ Build Tools をインストール後、
再度、Anaconda Promptで
wordcloudを 「 pip install wordcloud 」 でインストール
(base) D:\> pip install wordcloud
Collecting wordcloud
Using cached https://files.pythonhosted.org/packages/bc/e8/cab8479b25297b3847c
fb55e85a5014e8c53b80e513eaf1ba58c7b3a6acd/wordcloud-1.4.1.tar.gz
Requirement already satisfied: matplotlib in c:\users\kngsym\anaconda3\lib\sit
e-packages (from wordcloud) (2.1.2)
Requirement already satisfied: numpy>=1.6.1 in c:\users\kngsym\anaconda3\lib\s
ite-packages (from wordcloud) (1.14.0)
Requirement already satisfied: pillow in c:\users\kngsym\anaconda3\lib\site-pa
ckages (from wordcloud) (5.0.0)
Requirement already satisfied: six>=1.10 in c:\users\kngsym\anaconda3\lib\site
-packages (from matplotlib->wordcloud) (1.11.0)
Requirement already satisfied: python-dateutil>=2.1 in c:\users\kngsym\anacond
a3\lib\site-packages (from matplotlib->wordcloud) (2.6.1)
Requirement already satisfied: pytz in c:\users\kngsym\anaconda3\lib\site-pack
ages (from matplotlib->wordcloud) (2017.3)
Requirement already satisfied: cycler>=0.10 in c:\users\kngsym\anaconda3\lib\s
ite-packages (from matplotlib->wordcloud) (0.10.0)
Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in c:\us
ers\kngsym\anaconda3\lib\site-packages (from matplotlib->wordcloud) (2.2.0)
Building wheels for collected packages: wordcloud
Running setup.py bdist_wheel for wordcloud ... done
Stored in directory: C:\Users\kngsym\AppData\Local\pip\Cache\wheels\3e\40\7c
\d768cb5022ec6aa5611728339886bc1e9f0b629547f39237fd
Successfully built wordcloud
notebook 5.4.0 requires ipykernel, which is not installed.
jupyter 1.0.0 requires ipykernel, which is not installed.
jupyter-console 5.2.0 requires ipykernel, which is not installed.
ipywidgets 7.1.1 requires ipykernel>=4.5.1, which is not installed.
Installing collected packages: wordcloud
Successfully installed wordcloud-1.4.1
Successfully installed wordcloud-1.4.1 とメッセージがでてインストールできた!
Twitterのつぶやきを取得してその内容を見える化
ここからはpythonスクリプトを作成。
以下の処理のpythonスクリプトを作成
- Twitterのツイートデータをtweepyを使用して取得してテキストに出力
- MeCabを使用して形態素解析を行い、名詞、動詞、形容詞の単語を抽出して、Wordcloudでつぶやきを見える化
Twitterのツイートデータをtweepyを使用して取得してテキストに出力するpythonスクリプト
import tweepy
import datetime
def gettwitterdata(keyword,dfile):
#python で Twitter APIを使用するためのConsumerキー、アクセストークン設定
Consumer_key = '<Twitter API申請して取得したConsumer_key>'
Consumer_secret = '<Twitter API申請して取得したConsumer_secret>'
Access_token = '<Twitter API申請して取得したAccess_token>'
Access_secret = '<Twitter API申請して取得したAccess_secret>'
#認証
auth = tweepy.OAuthHandler(Consumer_key, Consumer_secret)
auth.set_access_token(Access_token, Access_secret)
api = tweepy.API(auth, wait_on_rate_limit = True)
#検索キーワード設定
q = keyword
#つぶやきを格納するリスト
tweets_data =[]
#カーソルを使用してデータ取得
for tweet in tweepy.Cursor(api.search, q=q, count=100,tweet_mode='extended').items():
#つぶやき時間がUTCのため、JSTに変換 ※デバック用のコード
#jsttime = tweet.created_at + datetime.timedelta(hours=9)
#print(jsttime)
#つぶやきテキスト(FULL)を取得
tweets_data.append(tweet.full_text + '\n')
#出力ファイル名
fname = r"'"+ dfile + "'"
fname = fname.replace("'","")
#ファイル出力
with open(fname, "w",encoding="utf-8") as f:
f.writelines(tweets_data)
if __name__ == '__main__':
#検索キーワードを入力 ※リツイートを除外する場合 「キーワード -RT 」と入力
print ('====== Enter Serch KeyWord =====')
keyword = input('> ')
#出力ファイル名を入力(相対パス or 絶対パス)
print ('====== Enter Tweet Data file =====')
dfile = input('> ')
gettwitterdata(keyword,dfile)
pythonスクリプトの実行方法は [Windows環境でPythonスクリプト(.py)の実行方法] (https://qiita.com/kngsym2018/items/21b6efe4547a78661951) を参考ください。
pythonスクリプトを実行すると「検索キーワード」、「出力ファイル名(相対パス or 絶対パス)」を聞かれますので
入力します。
「検索キーワード」:#oracleinnovation -RT
※-RT をつけると リツイートは除外します
「出力ファイル名」: d:\python\Tweet20180727.txt
※Twitter APIの制限として、直近10日のデータしか取得できない。
15分間に取得する回数が限られるなどあります
MeCabを使用して形態素解析を行い、名詞、動詞、形容詞の単語を抽出して、Wordcloudで見える化するpythonスクリプト
import MeCab
import matplotlib.pyplot as plt
import csv
from wordcloud import WordCloud
def analyze_tweet(dfile):
#読込むファイル名を設定
fname = r"'"+ dfile + "'"
fname = fname.replace("'","")
#Mecabを使用して、形態素解析
mecab = MeCab.Tagger("-Ochasen")
#"名詞", "動詞", "形容詞", "副詞"を格納するリスト
words=[]
#ファイルを読込み
with open(fname, 'r',encoding="utf-8") as f:
reader = f.readline()
while reader:
#Mecabで形態素解析を実施
node = mecab.parseToNode(reader)
while node:
word_type = node.feature.split(",")[0]
#取得する単語は、"名詞", "動詞", "形容詞", "副詞"
if word_type in ["名詞", "動詞", "形容詞", "副詞"]:
words.append(node.surface)
node = node.next
reader = f.readline()
#wordcloudで出力するフォントを指定
font_path = r"C:\WINDOWS\Fonts\HGRGE.TTC"
txt = " ".join(words)
# ストップワードの設定 ※これは検索キーワードによって除外したほうがいい単語を設定
stop_words = [ 'https','OracleInnovation' ,'Innovation','Oracle','co','the','of','Summit','Tokyo','Japan','RT',u'説明',u'データ',u'する',u'オラクル',u'日本',u'提供',u'開催',u'お客様']
#解析した単語、ストップワードを設定、背景の色は黒にしてます
wordcloud = WordCloud(background_color="black",font_path=font_path, stopwords=set(stop_words),
width=800,height=600).generate(txt)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
if __name__ == '__main__':
print ('====== Enter Tweet Data file =====')
dfile = input('> ')
analyze_tweet(dfile)
pythonスクリプトの実行方法は [Windows環境でPythonスクリプト(.py)の実行方法] (https://qiita.com/kngsym2018/items/21b6efe4547a78661951) を参考ください。
pythonスクリプト「analyze_tweet.py」を実行すると「読込みファイル名(相対パス or 絶対パス)」を聞かれますので
入力します。
「読込みファイル名」: d:\python\Tweet20180727.txt
※ファイル名の入力はファイルをDOS窓にドラッグでもOKです
WordCloudの結果

文字の大きさは、使用された単語が使用された回数に比例します。
上記結果をみると、「基調講演」、「クラウド」、「Cloud」の順となってます。
データ補正
「クラウド」と「Cloud」と同じ意味ですが、
英語と日本語の違いにより別単語としてなっているとおもったので
先ほど実行したpythonスクリプト「gettwitterdata.py」で取得したデータを補正しました。
「クラウド」⇒「cloud」
で、再度、pythonスクリプト 「analyze_tweet.py」 を実行!

「基調講演」、「Cloud」、「グラフィックレコーディング」の順となりました。
グラフィックレコーディングとは
Twitterで「グラフィックレコーディング」の内容をみましたけど、
話している内容を絵で表現するのはすごいと思いました。
Oracle Innovation Summit Tokyo 2018#OracleInnovation
— しばちょう/TsukasaShibata (@tkssbt) 2018年7月27日
グラフィックレコーディング実演 pic.twitter.com/ZkLGF6AkXs
「グラフィックレコーディング」を行ったのは
BRUSHの活動母体である株式会社グラグリッド さんのようです。
BRUSHメンバー、名古屋・小野・和波が本日「Oracle Innovation Summit 2018」でグラフィックレコーディングを実施しています! https://t.co/4piy1HZcsm
— BRUSH (@brush_go) 2018年7月27日