今回はデータを準備する回となります。
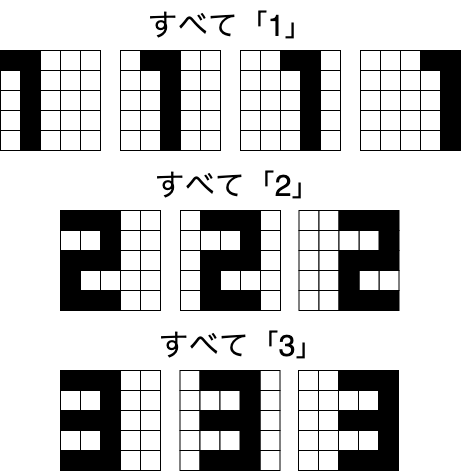
ニューラルネットワークに識別させるための数字のデータを用意します。「1」「2」「3」の3種類の数字を用意します。
5×5のピクセルで,次のものを「1」「2」「3」の基本的な形とします。
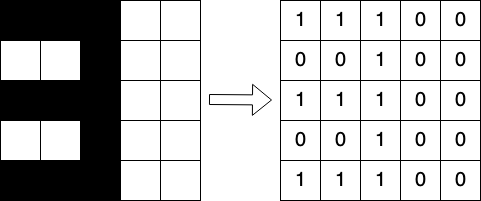
それぞれの画像について,下の図のように黒いピクセルを1で,白いピクセルを0で置き換えます。
これを,txtファイルで準備します(1-1.txt〜1-4.txt,2-1.txt〜2-3.txt,3-1.txt〜3-3.txt)。
11100
00100
11100
00100
11100
この,「 (数字の種類)-(ID).txt 」を読み込んでデータセットを作成していきます(make_dataset.c)。
今準備したデータをもとに,次の図のような濃淡のあるデータを作成していきます。
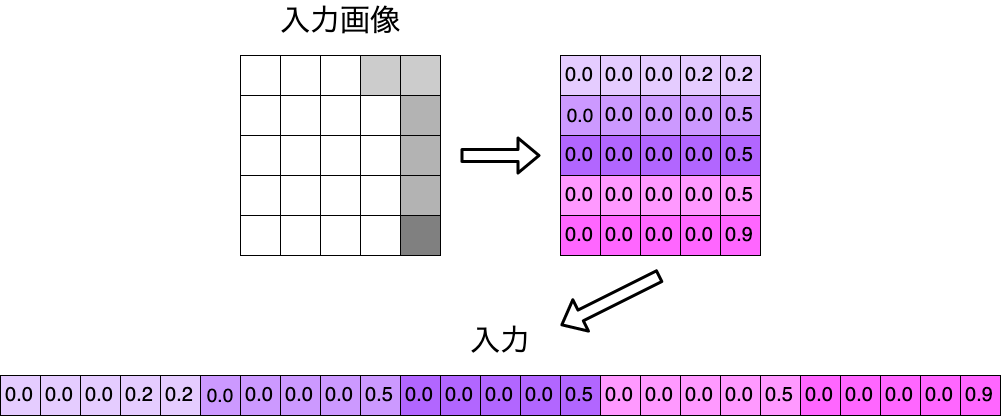
1000 // データの個数
1 // 1個目のデータの数字の種類(正解のラベル)
0.0 // この行からピクセルの値
0.0
0.0
0.2
0.2
0.0
0.0
0.0
0.0
0.5
0.0
0.0
0.0
0.0
0.5
0.0
0.0
0.0
0.0
0.5
0.0
0.0
0.0
0.0
0.9 // 1文字目終了
3 // 2個目のデータの数字の種類(正解のラベル)
...
ニューラルネットワークに上のtrain_data.txtの1個目のデータが入力される場合, $\boldsymbol{x} = (0.0, 0.0, 0.0, 0.2, 0.2, 0.0, \cdots, 0.0, 0.9)^{\top}$ となります。
1-1.txt〜3-3.txtまでを読み込んで,訓練用データ(train_data.txt),検証用データ(validation_data.txt),テスト用データ(test_data.txt)を作成するようなシェルスクリプト(make_dataset.sh)を書いたので,深く考えずともこれを実行するだけでデータが準備されます。
準備するデータの個数を変更したい場合は,make_dataset.c中の N_train , N_validation , N_test の値を変更してください。
また,文字の濃淡は,正規分布に従う乱数をもとに決めています。平均や分散を変えることで,識別問題の難易度を変えることができます。ただし,値が0を下回ったり1を超えたりする場合は,範囲内に収める必要があります。
続き
C言語でニューラルネットワークの実装(1)〜多層パーセプトロンの構造と活性化関数〜
C言語でニューラルネットワークの実装(2)〜順伝播と損失関数〜
C言語でニューラルネットワークの実装(3)〜誤差逆伝播法〜
C言語でニューラルネットワークの実装(4)〜データの準備〜 ←現在の記事
C言語でニューラルネットワークの実装(5)〜モデルの構造と順伝播の実装〜
C言語でニューラルネットワークの実装(6)〜逆伝播の実装〜
C言語でニューラルネットワークの実装(7)〜オンライン学習と重みの初期値〜
C言語でニューラルネットワークの実装(8)〜ミニバッチ学習〜