YAD2U C#編
Yet Another Deepmimic to Unity !
Other References
-
Environmental Setting
https://qiita.com/tanakataiki/items/40f54b3851c2ed3e09ec -
Tensorflow Search
https://qiita.com/tanakataiki/items/8655c76b68933905f3ea -
Unity&C Sharp
https://qiita.com/tanakataiki/items/fbb3a4782add01d73428
対象
- Unity(Mocapデータ,Kinematic tree,Animation)
- C#(物理エンジン,幾何学計算)
- mlagent(強化学習SDK)
以上の3つに慣れ親しんでいる人の参考に少しでもなればいいなぁと思った.
略語
- Additional Task Objective
- Immitation Objective
概要
YAD2U yet another deepmimic to unity deepmimicの理論を用いた
非公認プロジェクトです.
Unity Editor側
Scene内のParentから順に説明していきます.
Deepmimicにある観測するStateを以下を参考にmlagentにおけるvector observationの変数として設定.
https://qiita.com/tanakataiki/items/94c7778341a40438cc99#state
アーム版のAgentでは両手首は両前腕に固定しているため,Observationは冗長なので,はじきました.
Actionは各関節のTargetRotationとしました.
EarlierTermination(ET)の実装
OnCollisionEnterの時にAgentをDoneして終了します.(mlagentのC#の変数として定義されています)
その場合Penaltyとして,SetRewardを0にします.
ETは歩く場合足以外のCollisionに対して,行います.歩行,走る,バク転など
復帰できない動作に対して有効です.
ArmerAgentを動かす際はいりません.
Mimic Pairについて
AgentとReference Record,Goal(AditionalTaskObjectiveの時今回はStrike)のセットになるように作成します.
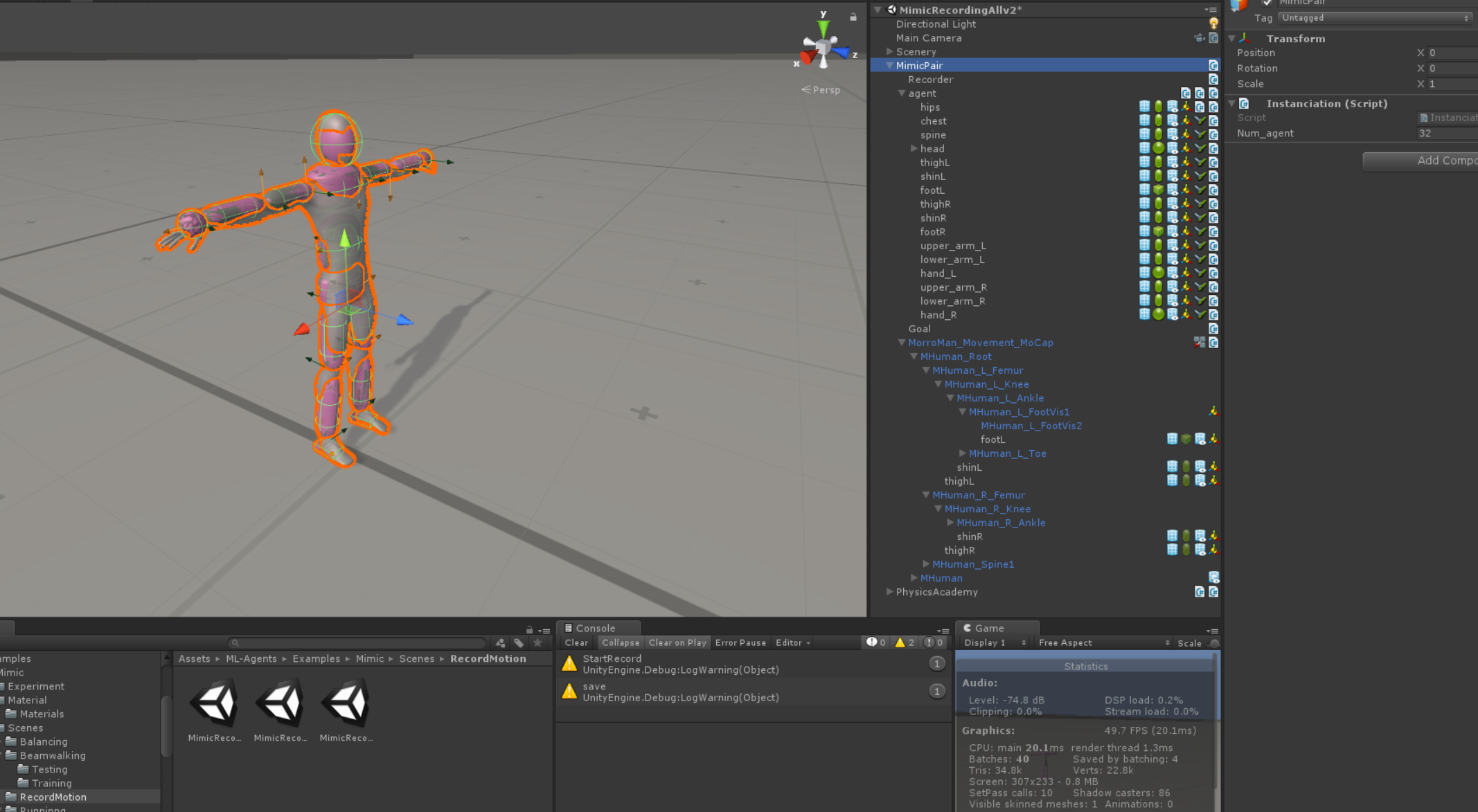
これをInitialize Academy時に複数Instanciateすると並列分散学習ができるはず!
Agentの作成
作成したAgent赤いのはMaterialエラーです..なるべくMocapのアセットに近い体形にしました.
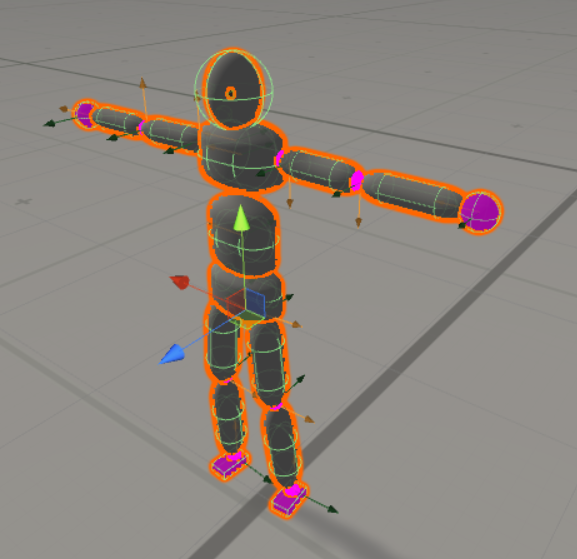
Agentの設定
Massを以下参考に設定
https://qiita.com/tanakataiki/items/94c7778341a40438cc99#body-parts-info
すべてKinematicsはFalse
Referenceの設定
isKinematicはTrue
CollisionもOff
AnimationのKinematicTreeの中にそれぞれのPartsを入れ込む.
Mimicの概要
Recordの実装
ここに実装しておきました.
MocapDataや,自分で作成した,ImmitationしたいMotionをRecordし,学習時に読み込むことで,ReferenceMotionを再現することができます.
RSIの実装
RSIは今回TaskObjectiveも加味して,半分より前の状態すなわちArmerAgentではボールに触りに行く状態から始めています.
Skill Selector UIの実装
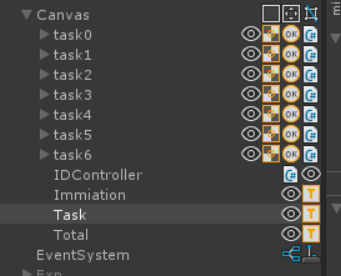
こんな感じでスキルごとのボタンを用意しておきました
つぶやき
うまいなぁと思った点は,Strikeって1度Strikeできたかどうか判定するのに,LSTMやRNNなど,時系列を使うこともできるんだけど,ものすごく複雑になるので,今回はHitしたら,以降Stikeによる報酬は1に設定することで,それ以上無駄なStrikeをしなくなる.(逆にこのようなフラグを設定しないと,いつまでも触り続ける)
微妙だなぁと思った点は,Targetでかいし,芯をとらえていない.
まあ,ただ,芯をとらえるMotivationはImmitationに比べると,あまり大きく無くて,指示通りのこと以上はしてくれない.
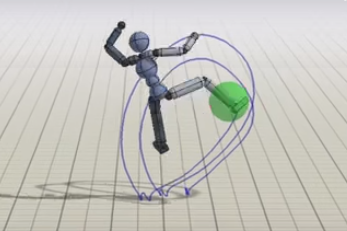
確かに,Targetの距離からEndEffector(ここでは右足)が近づけばRewardはExpに比例して(表現あってる?)大きくなるけど,一定の範囲内に来れば1,になるので,Rewardの7割を占めるImmitationを優先し,残り3割のStrike判定ぎりぎりのところを狙って蹴るのはRewardを最大にするうえで,重要で,まあある意味賢い
TaskのRewardの割合を大きくすると,Immitationしなくなるため,やっぱり暴れる...以下はイメージです...

ここら辺の感覚は実装してみるとわかる.
筆者が頑張って追実装していた去年の9月ごろにはDeepmimicのOpenなRepositoryはなかったので,お,これは作るしか!とか思ってたんだけど,今となってはコードはGithubにあるし,詳細が見放題(HyperParameter論文と違くねとか結構思ったけど,試行錯誤の上なのかなあ.)
https://github.com/xbpeng/DeepMimic
公式のDeepmimic(windows版)は依存環境が多く,環境構築が鬼めんどいので,結局途中であきらめた.誰か環境構築の記事書いて~~