Best Practices for Cost Management on Databricks - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
このブログ記事は、Databricks環境を管理・維持する人にとって重要なトピックにフォーカスした管理者向け基本シリーズの一部です。更なるトピックに関する追加の記事を楽しみにしていてください。そして、以前のワークスペースや管理者に関する記事をご覧ください!
クラウドプラットフォームを活用することによる主要なメリットの一つには、柔軟性が挙げられます。Databricksのレイクハウスプラットフォームはユーザーにほぼ即時に水平にスケールする計算資源へのアクセスを提供します。しかし、容易に計算資源を作成できるということは、管理不在やガードレールが存在しない場合にはクラウドのコストが増大するというリスクを伴います。管理者として、ユーザーに不要な摩擦を引き起こすことなしに作業してもらいつつも、とてつもないインフラコストを回避することとのバランスを常に取り続ける必要があります。この記事では、このバランスを見出し、ユーザーの生産性を抑制することなしにコストをコントロールするためのDatabricks管理者向けツールを議論します。
コントロールと使いやすさのスペクトル
DBUとは?
Databricksプラットフォームで活用できるコストコントロールに踏み込む前に、初めにワークロードを実行するコストの基礎を理解することが重要となります。Databricksユニット(DBU)はプラットフォームにおけるコンサンプションの内部単位です。SQLウェアハウスを除き(SQLウェアハウスは基本的にクラスターのグループであり、DBUのレートはウェアハウスを構成するクラスターのDBUレートの合計となります)、消費されるDBUの量は、それぞれのクラスターのノードの数と内部のVMのインスタンスタイプの計算能力に基づくものとなります。ハイレベルにおいては、類似のクラスターに対してそれぞれのクラウドでは若干異なるDBUレートを持ち値ますが、Databricksのウェブサイトでは、サポートするそれぞれのクラウドプロバイダー向けのDBUカリキュレーターを提供しています(AWS | Azure | GCP)。
DBUの使用量をドルに換算するには、クラスターのDBUレートとそれぞれのDBUを生成するワークロードタイプ(例: 自動ジョブ、All-purposeコンピュート、Delta Live Tables、SQLコンピュート、サーバレスコンピュート)、サブスクリプションプラン(AzureやGCPではスタンダードやプレミアム、AWSではスタンダード、プレミアム、エンタープライズ)が必要となります。例えば、AWSのエンタープライズDatabricksワークスペースにおいては、JobsのDBUは20セント/DBUと一覧されています。3 DBU/時で動作するインスタンスタイプからなる4ノードのジョブクラスターは、1時間あたり2.40ドル課金されます($0.2 * 3 * 4)。課金の合計を計算し、SKUとティア(AWS | Azure | GCP)を含むクラウド固有のマトリクスで価格一覧を要約するためにDBUカリキュレーターを活用することができます。
計算資源の利用、特にクラスターの利用によってコストが計算されるので、クラスターポリシーを通じてDatabricksワークスペースを管理することが重要となります。次のセクションでは、さまざまなクラスターポリシーがどのようにDBU消費を制限し、プラットフォームのコストを効率的に管理するのかを議論します。また、以降のセクションでは、検討すべき背後のクラウドコストのいくつかをレビューし、Databricksの使用量と課金をどの様に監視するのかを説明します。
クラスターポリシーによるコストの管理
クラスターポリシーとは?
クラスターポリシーを用いることで、管理者は新規クラスターを作成する際に利用できる設定をコントロールすることができ、これらのポリシーを個別のユーザーやユーザーグループに割り当てることができます。デフォルトでは、すべてのユーザーにはワークスペースにおける「制限なしのクラスター作成」権限が付与されています。これは、割り当てられたポリシーの範囲外で制限なしにクラスターを作成できてしまい、管理されないままコストを垂れ流すことになるので滅多なことで使うべきではありません。
ポリシー内では、管理者は変更不可の固定値、より制限を緩和した値のレンジや正規表現、完全にオープンなデフォルト値を用いてそれぞれの設定値をコントロールすることができます。ポリシーを用いることで、VMのインスタンスタイプの様なきめ細かい設定から、時間あたり最大許容DBUやワークロードタイプのようなよりハイレベルの「合成」属性にいたるすべてに対して、単一のクラスターによる消費を制限することができ、効率的にDBUの総量の制限をかけることができます。
一見すると、より厳格な制限がされたクラスターによってコストの引き下げができる様に見えるかもしれませんが、これは常に真とは限りません。非常の厳格なポリシーは、クラスターがタイムリーな方法でタスクを完了できず、ジョブを長時間実行することでコストを引き上げることになります。このため、チームが彼らのワークロードを実行するために適切な計算パワーを与えるクラスターポリシーを設計する際には、ユースケースドリブンのアプローチを取ることが不可避となります。これをサポートするために、Databricksではより高速な処理時間を通じてコスト削減に繋げる、最適化されたApache Spark™ランタイムや、特筆すべきPhotonエンジンのようなパフォーマンスのための機能を提供しています。以降のセクションではランタイムのポリシーを議論しますが、最初に水平スケーリングを管理するポリシーからスタートしましょう。
ノード数の制限、オートスケーリング、自動停止
計算コストに関してよく直面する懸念事項は、使い切られていなかったり、アイドル状態であり続けるクラスターです。Databricksでは、これらの懸念を人手を介することなしに動的に軽減するためのオートスケーリングや自動停止機能を提供しています。これらの機能はポリシーを通じて、ユーザーが利用できる計算資源を妨げることなしに強制することができます。
ノード数の制限とオートスケーリング
ポリシーによって、ワーカーノードの最小数が設定された状態でオートスケーリング機能が有効化されるクラスターを強制することができます。例えば、以下の様なポリシーは、オートスケーリングが有効化され、ユーザーは必要な際には最大10ワーカーノードのクラスターを使用することができます。
"autoscale.max_workers": { "type": "range", "value": 10, "defaultValue": 5 },
"autoscale.min_workers": { "type": "fixed", "value": 1 }
ワーカーの最大数に対する強制のタイプは「range」なので、作成時に値が10より小さくなることはあり得ます。しかし、ワーカー数の最小値は「fixed」の1によって設定されていますので、使用されていない場合にクラスターは1台のみのワーカーにまでスケールダウンし、計算資源のコストを節約する様にします。ここでもう一つのフィールドは「defaultValue」であり、名前が示す通り、クラスター設定ページでワーカーの最大数にデフォルトとして設定される値となります。これによって、デフォルトでクラスターの最大数を少ない値に設定することで、作成者は必要があれば意図的に10ノードまでスケールアップすることができ、ワーカー数の削減に役立ちます。
ノード数の制限やオートスケーリングを有効化するかどうかに関しては、ポリシーを作成、割り当てる際にユースケースを理解することが重要となります。例えば、以下の様なケースではオートスケーリングの強制は有効です。
- 共有all-puposeコンピュートクラスター: チームはアドホック分析や実験的ジョブ、機械学習ワークロードのために一つのクラスターを共有することができます。
- 複雑性に違いがある長時間実行のバッチジョブ: ジョブは必要となるリソースの度合いに応じてスケールできる様にオートスケーリングを活用できます。
オートスケーリングを使用するジョブは、クラスターのスケールアップに伴うノードの起動時間によって処理完了に遅れが起こる場合があるので、厳格な時間要件がないものであることに注意してください。これを軽減するには、可能な場合にはインスタンスプールを使ってください。
これまでは、標準的なストリーミングワークロードは、オートスケーリングのメリットを享受することができませんでした。この様なケースでは、シンプルに最大ノード数までスケールし、ジョブの実行中はずっとそのままでした。この様なタイプのワークロードに取り組んでいるチームにとって、よりプロダクションレディな選択肢は、Delta Live Tablesや強化オートスケーリングを活用するというものです(この記事の後半で説明する「cluster_type」ポリシーでDLTのワークロードを強制することができます)。DLTはストリーミングワークロードを想定して開発されたものですが、ターゲットテーブルに対するインクリメンタルなアップデートを可能にするTrigger.AvailableNowオプションを用いることで、バッチパイプラインに適用することができます。
クラスターサイジングのポリシーに対する別の一般的な設定は、シングルノードのポリシーです。シングルノードのクラスターは、新たなユーザーがプラットフォームを探索したり、非分散処理のMLライブラリを活用しているデータサイエンスチーム、軽量な探索的なデータ分析を必要としているユーザーにとっては有用なものとなります。シングルノードクラスターポリシーのサンプルにあるように、ポリシーによって特定のインスタンスプールを使用する様に限定することができます。この結果、このポリシーが割り当てられたチームは、プールの最大キャパシティの設定に基づいて、作成できるシングルノードクラスターの総量に制限を持つことになります。
自動停止
Databricksプラットフォームでクラスターを作成する際に設定できる別の属性が、自動停止の時間であり、この時間アイドル状態が続くとクラスターはシャットダウンされます。アイドル期間はSparkジョブや構造化ストリーミング、JDBCの呼び出し等いかなるタイプのアクティビティが存在しない時間として定義されます。クラスター上のアクティビティと見做されないものには、クラスターへのSSH接続、bashコマンドの実行が挙げられます。
最も一般的な自動停止の期間は1時間です。例として、固定の1時間ウィンドウに設定されたポリシーを示します。
"autotermination_minutes": { "type": "fixed", "value": 60, "hidden": true}
この例では、ユーザーのクラスター設定ページからウィジェットを非表示にする様に制御する「hidden」属性も追加されています。ジョブクラスター、DLTクラスターは割り当てられたすべてのタスクが完了すると自動でシャットダウンするので、この属性はall purposeクラスターにのみ適用されます。
クラスターランタイムとPhoton
Databricksランタイムは、Databricksにおけるパフォーマンス最適化において重要な役割を担います。お客さまは多くのケースにおいて、設定を変更することなしに新しいランタイムが稼働するクラスターにスイッチするだけでメリットを得ています。クラスターポリシーを作成する管理者には、コスト削減においてはクラスターを作成する際に新しいランタイムの実行を教育することが重要となります。ユーザーが新しいランタイムに移行するにつれて、古いランタイムはフェーズアウトさせ、ポリシーを通じて制限を行います。クイックな例として、DBランタイムのバージョン11.0あるいは11.1に制限する「spark_version」の属性を示します。
"spark_version": {
"type": "allowlist", "values": [ "11.1.x-scala2.12", "11.0.x-scala2.12" ]
}
しかし、正規表現や許可リストを拡張することで、他のバージョン、MLランタイム、Photonランタイム、GPUランタイムを許可することで、このポリシーをより柔軟にすることも可能です。
コストを削減するためにパフォーマンスを最適化する際に検討すべき他のランタイム機能は、我々のベクトル化Photonエンジンです。Photonはベクトル化されたSparkエンジンを通じてワークロードの一部をインテリジェントに高速化し、お客さまにおいては3倍から8倍の性能改善を体験されています。パフォーマンスの劇的な向上によって、より高速なジョブを実現し、結果としてトータルコストを引き下げることになります。
クラウドのインスタンスタイプとスポットインスタンス
クラスター作成時には、ドライバーノードとワーカーノードのそれぞれのVMインスタンスタイプを選択することができます。利用できるインスタンスタイプには、それぞれ異なるDBUレートがあり、それぞれのクラウドのDatabricks価格見積もりページで確認することができます(AWS、Azure、GCP)。例えば、AWSにおいて2コア、メモリー8GBのm4.largeインスタンスタープはall-purposeコンピュートモードでは、1時間あたり0.4DBUを消費しますが、64コア、メモリー256GBのm4.16xlargeインスタンスタイプは1時間あたり12DBUを消費します。計算リソースにおいてDBU利用量には大きな開きがあるので、ポリシーを通じてこの属性に対して制限をかけることが重要となります。
クラウドインスタンスタイプは、「allowlist」タイプ、あるいは1つのタイプのインスタンスのみの利用を許可する「fixed」タイプで簡単にコントロールすることができます。以下の例では、ユーザーが利用できるワーカーノードタイプを設定する「node_type_id」属性と、ドライバーノードタイプに対してポリシーを設定する「driver_node_type_id」を示しています。
"node_type_id": {
"type": "allowlist",
"values": ["i3.xlarge", "i3.2xlarge", "i3.4xlarge"],
"defaultValue": "i3.2xlarge"
},
"driver_node_type_id": {
"type": "fixed",
"value": "i3.2xlarge"
}
管理者がこれらのポリシーを作成するので、それぞれのチームがどの様なタイプのワークロードを実行しているのかを理解し、適切なポリシーを割り当てることが重要となります。小規模なデータを取り扱うワークロードでは、メモリーの少ないインスタンスタイプで十分ですが、ディープラーニングのモデルのトレーニングにおいてはGPUクラスターを活用するメリットが大きくなりますが、通常より多くのDBUを消費します。インスタンスタイプの制限は詰まるところバランスを取る取り組みとなります。チームがポリシー制限よりも上回るリソースを必要とするワークロードを実行する必要がある場合、ジョブが完了するまでには長い時間を必要とし、結果としてコストを引き上げることになります。特定のワークロードに対するクラスターを設定する際に従うベストプラクティスがいくつか存在します。例えば、データのシャッフルを必要とする大量の幅広な変換処理から構成される複雑なワークロードにおいては、水平のスケーリング(ノードを追加)よりも垂直なスケーリング(より強力なインスタンスタイプを使用)が推奨されます。とは言っても、経験の少ないチームにおいては、あまり複雑でないワークロードにパワフルなVMを提供するメリットは少ないため、小規模なインスタンスタイプに限定するポリシーを割り当てるべきです。
Databricksプラットフォームにおける比較的新しいコスト節約のための機能は、Arm64命令セットアーキテクチャ上に構築されたAWS Graviton有効化VMです。AWSによる検証結果とPhotonを用いたDatabricksによるベンチマークによると、これらのGraviton有効化インスタンスには、AWSのEC2インスタンスタイプセットにおいて、ベストなコストパフォーマンスを示しています。
スポットインスタンス
Databricksでは、スポットインスタンスを用いて特に内部VMの計算コストを削減する別の設定を提供しています(GCPのDatabricksにおいて利用できるオプションでは、スポットインスタンスと同様のプリエンプティブインスタンスを使用しています)。スポットインスタンスは、背後のクラウドプロバイダーによって提供されるスペアのVMであり、ライブなマーケットでビッディングすることになります。これらのインスタンスによって、急勾配なディスカウントを実現し、時にはインスタンスコストにおいて90%の削減が可能となります。スポットインスタンスのトレードオフは、短時間の事前通知(AWSでは2分、AzureやGCPでは30秒)によっていかなる時にも背後のクラウドプロバイダーによってインスタンスが取り上げられるということです。
AWSを使っている場合、スポットインスタンスの利用を含むクラスターポリシーは以下の様になります。
"aws_attributes.first_on_demand": { "type": "fixed", "value": 1 },
"aws_attributes.availability": { "type": "fixed", "value": "SPOT_WITH_FALLBACK" }
Azureでは以下のようになります。
"azure_attributes.first_on_demand": { "type": "fixed", "value": 1},
"azure_attributes.availability": { "type": "fixed", "value":
"SPOT_WITH_FALLBACK_AZURE" }
これらの例においては、クラスター作成時に1台のノードのみ(特にドライバーノード)がオンデマンドインスタンスで、クラスターの他のすべてのノードはスポットインスタンスとなります。ここではフォールバックオプションが有効化されているので、クラウドプロバイダーによって取り上げられたスポットインスタンスを置き換えるためにオンデマンドインスタンスがリクエストされます。GCPにおけるポリシーは現状「first_on_demand」を強制しませんが、プリエンプティブノードを強制することは可能です。
gcp_attributes.availability: { "type" :"fixed", "value":
"PREEMPTIBLE_WITH_FALLBACK_GCP" }
デフォルトでは、プリエンプティブインスタンスが有効化されている場合、クラスターセットアップ時にドライバーノードのみがオンデマンドインスタンスを使用します。
信頼性やワークロードの処理時間が重要ではない、実験的ワークロードやアドホッククエリーの様な耐障害性のあるプロセスを実行する際、インスタンスコストを引き下げるためにはスポットインスタンスが簡単な手段を提供します。このため、開発やステージング環境ではスポットインスタンスは適しています。
スポットインスタンスの排除率や価格はTシャツサイズやクラウドのリージョンによって変動します。このため、クラスター設定の最適計画においては、AWS Spot Instance Advisor、AzureアカウントポータルのAzure Spot Pricing and History、Google Cloud Pricing Calculatorのようあそれぞれのクラウドプロバイダーが提供するツールを活用することをお勧めします。
Azureにはこの他にコストをコントロールするレバーがあることに注意してください。Databricksではリザーブドインスタンスを用いることができ、不安定性を引き上げることなしに更なる(おそらく急激な)ディスカウントを得ることができます。
クラスターのタグ
チームによって使用されているリソースを観測する能力は、クラスターをタグ付けすることで得ることができます。これらのタグは、Databricksプラットフォームと背後のクラウドコストの両方から参照できる様に、使用量とコストはクラウドプロバイダーレベルまで伝播します。しかし、クラスターポリシーがないと、クラスターを作成するユーザーはタグをつけることは強制されません。このため、Databricksにアクセスしようとしているチームに対してポリシーを作成する管理者は、ポリシーに割り当てられるチーム固有のクラスタータグの強制を含めることが重要となります。
カスタムのコストセンターのタグを強制するポリシーのサンプルは以下の様になります。
{"custom_tags.cost_center": {"type":"allowlist", "values":["9999", "9921", "9531" ]}}
クラスタ0を使用しているチームを特定するタグが割り当てられると、管理者はDBUを紐付け、クラスターを活用しているチームにコストを割り当てるために利用量ログを分析することができる様になります。また、これらのタグはクラウドプロバイダーのインスタンスコストもチームやコストセンターに還元できるように、VM利用のレベルまで伝播されます。利用ログのモニタリングにおける一般的なオプションについてはこの後議論します。
クラスタープールを用いる際のクラスタータグの重要な違いは、クラスタープールのタグのみが背後のVMインスタンスに伝播するということです。クラスタープールの作成はクラスターポリシーでは制限できないため、管理者はチームに利用権限を割り当てる前に適切なタグを用いてクラスタープールを作成すべきです。すると、チームはポリシーを通じてクラスターを作成する際にそれぞれのプールにアタッチできるようになります。これによって、プールを使用しているチームにタグが付与され、課金のためにVMインスタンスレベルまで伝播されるようになります。
ポリシーの仮想属性
クラスター設定ページに表示される設定以外に、ポリシーによって制限できる「仮想」属性も存在亜します。特に、このカテゴリーで利用できる2つの属性が「dbus_per_hour」と「cluster_type」です。
「dbus_per_hour」属性を用いることで、クラスターの作成者はポリシーによって定義される制限内にDBU使用量が収まる限り、設定の自由を手に入れることができます。(DBUのレートは多くの場合VMインスタンスのレートと相関しますが)この属性自身は、これまで議論した属性と同じ様に背後のVMインスタンスに起因するコストを直接制限しません。以下に、1時間あたり10DBUに収まるクラスターの作成に制限するポリシー定義を示します。
"dbus_per_hour": { "type": "range", "maxValue": 10}
利用できる別の仮想属性は作成できるクラスタータイプを制限するために使用する「cluster_type」です。この属性で使用できるタイプは「all-purpose」、「job」、「dlt」であり、最後のものはDelta Live Tablesです。このポリシーのサンプルを以下に示します。
"cluster_type": {"type": "fixed", "value": "job"}
クラスタータイプの制限は、開発、デプロイメントのライフサイクルのそれぞれに従事する異なるチームと作業する際には特に重要となります。新規のETLや機械学習パイプラインの開発に取り組むチームにおいては、all-purposeクラスターのみが必要となりますが、デプロイメントを行うエンジニアリングチームではジョブクラスターやDelta Live Tables (DLT)を使用することでしょう。これらのポリシーによって、それぞれ固有の開発、デプロイメントのライフサイクルで適切なクラスタータイプが使用されることを確実にすることでベストプラクティスを強制することができます。
よくあるバッドプラクティスは、all-purposeクラスターを共有して自動化ワークロードの開発を行うというものです。パッと見ると、これは単一のクラスターにコストが紐づけられるので安価なオプションに見えるかもしれません。しかし、この種の設定はクラスターが稼働しなくてはならない時間を引き伸ばすことになるリソースの競合を引き起こし、計算コストを増加させます。代わりに、一度に一つのジョブを実行するために分離されたジョブクラスターを用いることで、一連のジョブを完了するのに必要な計算時間を削減します。これによって、DatabricksのDBU使用量と背後のクラウドインスタンスコストを引き下げます。ジョブクラスターが提供するDBUあたりの安価なコストレートと優れたパフォーマンスによって、劇的にコストを削減することができます。我々は、あるお客様がシンプルにワークロードの10パーセントをall-purposeからジョブクラスターに移行することで、数万ドルの削減をしたのを目撃しています。ジョブクラスターの再利用は、それぞれのタスク間でクラスターの起動時間を排除することで一連のジョブをタイムリーに完了することを保証するために活用することができます。
チームが適切なワークロードのためのクラスターを作成できるようにするポリシーを設計するためには、従うべきベストプラクティスがいくつか存在します。いくつかの典型的な制限ポリシーのパターンは、シングルノードクラスター、ジョブのみのクラスター、チームで共有するオートスケーリングのall-purposeクラスターがあります。完全なポリシーのサンプルに関してはこちらを参照ください。
クラウドプロバイダーのコスト
Databricksのコンサンプションの観点(DBU)から、すべてのコストは使用された計算資源に割り戻すことができます。しかし、背後のクラウドのネットワークやストレージに起因するコストも検討すべきです。
ストレージ
Databricksのようなプラットフォームを活用する利点は、AzureのADLS Gen2、AWSのS3、GCPのGCSのような比較的安価なクラウドストレージとシームレスに動作するというものがあります。これは、通常であればストレージレイヤーの管理やパフォーマンス最適化が困難ですが、Databricksと組み合わせて活用する際にデータガバナンスを提供するDelta Lakeフォーマットを用いる際には特にメリットが顕著なものとなります。
よくあるストレージの設定ミスは、ライフサイクル管理の利用を蔑ろにすることです。最近のケースでは、2.5PBのデータを持ちながらも実際の真のデータは800TBであるお客様のS3バケットを観測しました。残りの1.7PBのデータは価値を提供しないバージョン管理されたものでした。お使いのクラウドストレージから古いオブジェクトを追い出すことは一般的なベストプラクティスですが、お使いのDeltaのVacuumのサイクルとアラインすることが重要です。あなたのストレージライフサイクルによって、Deltaによってバキュームされる前に削除されてしまうとテーブルが破損する可能性があります。より広い範囲で実装する前に、非プロダクションデータでいかなるライフサイクルポリシーをテストしてください。サンプルのポリシーは以下の様になります。
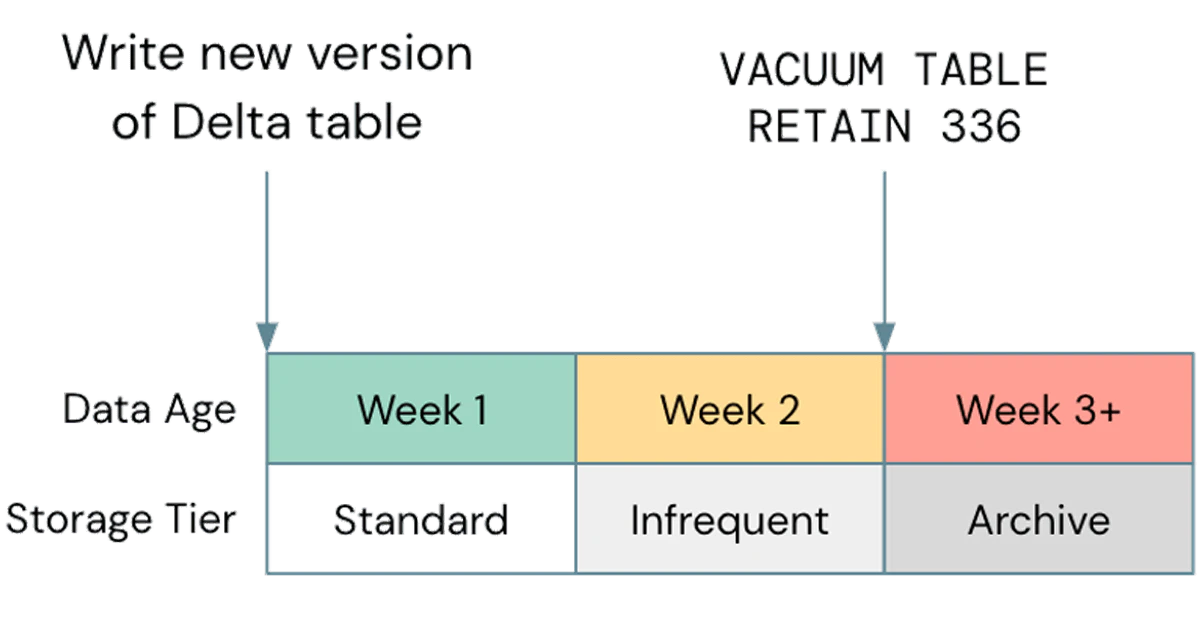
ストレージライフサイクルポリシーのサンプル
S3のGlacierやADLSのArchiveのような非標準のストレージはDatabricksではサポートしていないので、これらのティアが使用される前にVacuumする様にしてください。
ネットワーク
Databricksプラットフォームで使用されるデータは、データウェアハウスやKafkaのようなストリーミングシステムなど、さまざまなソースから到着します。しかし、最も一般的に帯域を使用するのは、S3やADLSのようなストレージレイヤーへの書き込みです。ネットワークのコストを削減するために、Databricksのワークスペースは、リージョンやアベイラビリティーゾーン間のデータ転送量を最小化するという目的のものとでデプロイされるべきです。これには、可能な限りデータの大部分を同じリージョンにデプロイし、必要であればリージョンごとのワークスペースを立ち上げることが含まれます。
AWSのDatabricksで顧客管理のVPCを使用している場合には、インターネットゲートウェイやNATデバイスなしに、VPCとAWSサービス間の接続を可能とするVPCエンドポイントを用いることでネットワークコストを削減することができます。エンドポイントを用いることで、ネットワークトラフィックによって生じるコストを削減し、接続をよりセキュアなものにすることができます。ゲートウェイエンドポイントはS3やDynamoDBに接続する際に使用され、インタフェースエンドポイントは同様にDatabricksのコントロールプレーンに接続するコンピュートインスタンスのコストを削減するために使用されます。ワークスペースでセキュアクラスター接続を使用している限り、これらのエンドポイントを利用することができます。
Azureでも同様に、NATのコストを削減するためにADLSのようなサービスとDatabricksが通信するためにPrivate Linkやサービスエンドポイントを設定することができます。GCPにおいては、Google Cloud Storage(GCS)とGoogle Container Registry(GCR)の間のトラフィックが、公衆のインターネットではなくGoogleの内部ネットワークを使用する様にするためにPrivate Google Access(PGA)を活用することで、NATデバイスの使用をバイパスすることができます。
サーバレスコンピュート
分析のワークロードにおいて検討すべきオプションは、サーバレスオプションが有効化されたSQLウェアハウスを使用することです。サーバレスSQLによって、Databricksプラットフォームは、ユーザーがワークロードを開始した際に常にアサインできるコンピュートインスタンスのプールを管理します。このため、背後のインスタンスは2つの異なる課金(DBUの計算コストと背後のクラウドコンピュートのコスト)ではなく、完全にDatabricksによって管理されます。
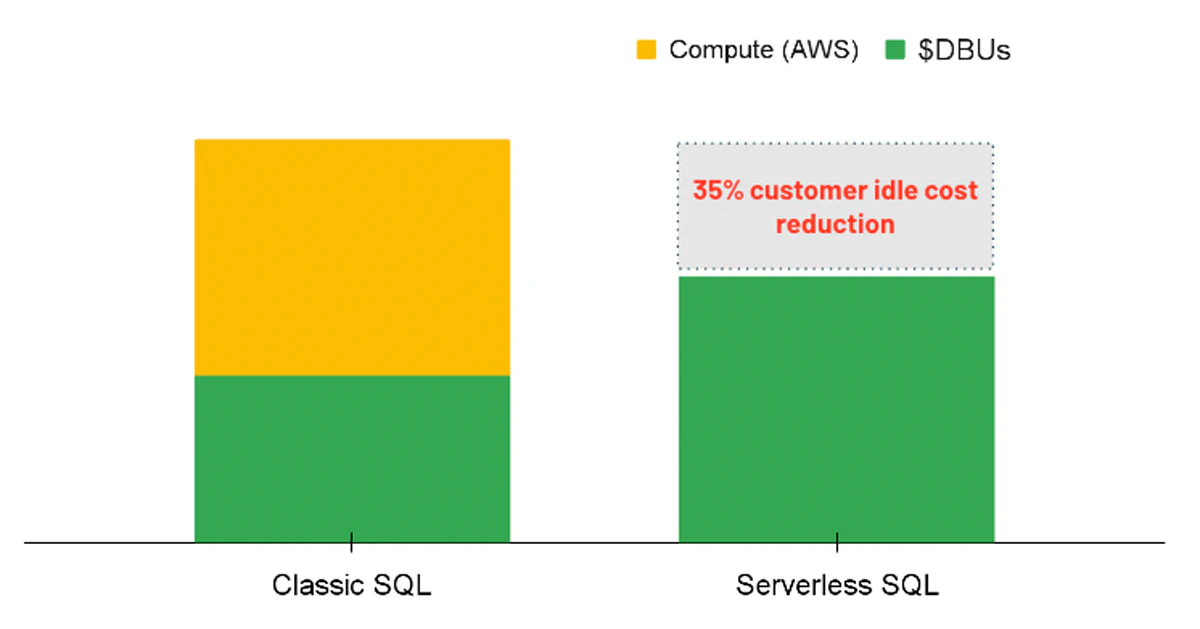
従来のSQLエンドポイントとサーバレスSQLのコストブレークダウンの比較
サーバレスを用いることで、クエリーが実行された際に即座に計算資源を提供することでコスト上のメリットを提供し、利用率の低いクラスターのアイドル状態のコストを削減します。同じ様に、サーバレスを用いることで、ワークロードを効率的に処理し、パフォーマンスを改善することでコストを削減できる様により精度の高いオートスケーリングを可能とします。サーバレスのオプションは現時点ではポリシーで強制することはできませんが、管理者はすべてのユーザーに対してSQLウェアハウスの作成権限を与えるオプションを有効化することができます。
利用量のモニタリング
クラスターポリシーやワークスペースのデプロイメント設定によるコストのコントロールに加え、同様に管理者にとって重要なことは、コストを監視する能力です。Databricksでは、これを行うための通知や利用量分析に基づく警告の自動化に関して、いくつかのオプションを提供しています。特に、管理者はクイックに利用量の概要を把握するためにアカウントコンソールを使用したり、より詳細なビューを得るために利用量ログを解析することができ、予算を超過した際にアクティブな通知を得るために新たなBudgets APIを使用することができます。
アカウントコンソールを活用
DatabricksのEnterprise 2.0アーキテクチャのアカウントコンソールには、管理者にビジュアルでDBUに基づく使用量やドルの総額を確認できるようにするための利用量ページが含まれています。チャートには、ワークスペースやSKUでグルーピングされた集計ビューによるコンサンプションを表示させることができます。SKUでグルーピングした際には、ジョブクラスター、all purposeクラスター、SQLコンピュートごとにコンサンプションが表示されます。ワークスペースごとにチャートが表示された際には、DBU消費の上位9位のワークスペースとその他すべてのワークスペースの合計が結合されて表示されます。個々のワークスペースのより詳細を理解するためには、SKUごとのDBU/ドルの総量がワークスペースごとに表示されているテーブルを参照することができます。このページは管理者がアカウント配下のすべてのワークスペースの利用量とコストに対する完全なビューを得るには適しています。
AzureプラットフォームにおいてはDatabricksはファーストパーティのサービスとなっているので、(他のAzureのサービスと一緒に)Databricksの利用量をモニタリングするためにAzureのコスト管理ツールを活用することができます。AWSやGCPのDatabricksデプロイメントと異なり、Azureのモニタリング能力はタグの詳細レベルまで対応しています。Azureのカスタムタグは、クラスターレベルだけではなくワークスペースレベルでも作成することができます。これらのタグは、利用量データを分析する際にグループやフィルターとして表示されます。これらのレポートにおいては、Databricksの計算処理によって生成された利用量は背後のインスタンスの使用量と共にわかりやすい形で表示されます。また、スケジュールに基づいてストレージコンテナにログをデリバリーし、次のセクションで説明する様により自動化された分析やアラートに活用することができます。
管理者はアカウントコンソールの利用量ページから利用量ログを手動でダウンロードするか、Account APIを活用するというオプションがあります。しかし、これらの利用量ログを解析するより効率的なプロセスは、クラウドストレージに自動でログがデリバリー(AWS、GCP)される様に設定することです。この結果は、日次で出力されるワークスペースごとの利用量の詳細なスキーマに基づくCSVとなります。
3つのクラウドのいずれかでログのデリバリーが設定されると、一般的なベストプラクティスはDatabricks内でこのデータを日次で取り込み、スケジュールされたワークフローを用いてDeltaテーブルに保存するデータパイプラインを作成することとなります。このデータはその後に利用量分析に使用したり、指定された閾値をコンサンプションが超過した際に、利用したコストセンターに責任を持つチームリーダーへの通知をトリガーするために活用することができます。
Budgets API
Databricksにおける計算コストの予算管理をより容易にするために間も無く提供される機能が、Account API内の新たなバジェットエンドポイント(現在はプライベートプレビュー)です。これによって、Databricksワークスペースを利用している誰でもが、ワークスペース、SKU、クラスタータグによってフィルタリングされるカスタムタイムフレームで予算の閾値を超過した際に通知を受け取ることができます。このAPIによって、任意のワークスペース、コストセンター、チームに対して予算を設定することが可能となります。
まとめ
Databricksレイクハウスプラットフォームは多岐にわたるユースケース、ユーザーペルソナに対応するものですが、管理者に対してはコストのコントロールとユーザーのエクスペリエンスのバランスを取るための統合ツールセットを提供することを目指しています。この記事では、このバランスにアプローチするためのいくつかの戦略を列挙しました。
- どのユーザーがクラスターを作成できるのか、クラスターのサイズ、スコープで作成できるのかをコントロールできるクラスターポリシーを活用しましょう。
- ストレージやネットワークのコストの様な、Databricksワークスペースによって生成されるDBU以外のコストを最小化する様に環境を設計しましょう。
- あなたのコストに対する期待値を確実なものにし、効果的なプラクティスを実践できる様にモニタリングツールを活用しましょう。
本書を通じてリンクされている管理者向けブログ記事もチェックし、さらに提供される記事も楽しみにしていてください。また、プライベートリンク(AWS | Azure)やBudgetingのような新機能も試してみてください!