How to Architect MLOps on the Databricks Lakehouse - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
堅牢なMLOpsプラクティスを構築するための新たなデータ中心アプローチ
Databricksにおいて、我々は数多くのお客様が機械学習(ML)をプロダクションに移行するお手伝いをし続けています。Shellは160ものアクティブなAIプロジェクトを進めており、数百万ドルを節約しています。ComcastはMLflowを用いて容易に数百もの機械学習モデルを管理しています。そして、その他多くの企業がMLによって強化されたソリューションの構築に成功しています。
我々とコラボレーションするまで、多くのお客様はMLをプロダクションに移行することに奮闘していました。これには正当な理由があります。Machine Learning Operations (MLOps)は困難なものです。MLOpsには、プロダクションに向けた道のりにおいてコード(DevOps)、データ(DataOps)、モデル(ModelOps)をともに管理することが含まれます。これまで見てきた最も一般的で苦痛な課題は、データ、MLの間のギャップであり、多くの場合、ツールとチームが分断あるいは疎結合となっていました。
この課題を解決するために、レイクハウスアーキテクチャの上に構築されるDatabricks Machine LearningはMLOpsに対して、自身のキーとなる利点、シンプルさとオープン性を拡張します。
我々のプラットフォームは、DevOps、DataOps、ModelOpsのベストプラクティスを統合するデータ中心のワークフローを定義することでMLをシンプルなものにします。最終的に機械学習パイプラインはデータがさまざまなペルソナの手に渡るデータパイプラインとなります。データエンジニアがデータを取り込み準備をします。データサイエンティストがデータからモデルを構築します。MLエンジニアがモデルのメトリクスを監視します。そして、ビジネスアナリストが予測結果を検証します。Databricksは、これらのデータチームを支援することでプロダクションレベルの機械学習をシンプルなものにし、単一のプラットフォーム上でこの膨大なデータを管理できるようにします。例えば、我々の提供するFeature Storeを用いることで、モデルと特徴量をともにプロダクションに移行することができます。よりシンプルなプロセスでMLエンジニアがモデルをデプロイできるように、データサイエンティストは必要とする特徴量を「考慮する」モデルを作成します。
MLOpsに対するDatabricksのアプローチはオープンかつ業界の標準に立脚しています。DevOpsにおいては、GitやCI/CDとインテグレーションします。DataOpsにおいては、オープンかつ高性能なデータ処理のデファクトのアーキテクチャであるレイクハウスとDelta Lakeを用いて構築します。ModelOpsにおいては、モデル管理で最も人気のあるオープンソースツールであるMLflowを活用します。オープンなフォーマット、APIによる基盤によって、お客さまは自身のさまざまな要件に我々のプラットフォームを適合させることができます。例えば、我々のMLflowオファリングをベースにモデルを集中管理しているお客様は、自身の要件に基づいてビルトインのモデルサービングあるいは他のソリューションを活用することができます。
この記事を通じて我々のMLOpsアーキテクチャを共有できることを嬉しく思っています。ここでは、DevOps + DataOps + ModelOpsの組み合わせにおける課題、我々のソリューションの概要、我々のリファレンスアーキテクチャに関して議論します。ディープダイブする際には、The Big Book of MLOpsをダンロードいただき、間も無く開催されるData+AI Summit 2022のMLOps talksに参加してください。
コード、データ、モデルの共同管理をシンプルにする支援をするレイクハウスプラットフォーム上のMLOpsの構築
コード、データ、モデルを一緒に管理する
MLOpsは、主な二つのゴール、安定したパフォーマンスとMLシステムにおける長期的な効率性を達成するために、コード、データ、モデルを管理するための一連のプロセスとオートメーションです。簡単に言えば、 MLOps = DevOps + DataOps + ModelOpsとなります。
開発、ステージング、プロダクション
ビジネス、あるいは顧客に公開するアプリケーションに向けた道のりにおいては、ML資産(コード、データ、モデル)が一連のステージを移動していきます。これらは開発(「開発」ステージ)、テスト(「ステージング」ステージ)、デプロイ(「プロダクション」ステージ)される必要があります。この作業は、Databricksワークスペースのような実行環境で行われます。
実行環境、コード、データ、モデルのすべては、dev、staging、prodに分割されます。これらの分割によって、品質保証やアクセスコントロールの観点から理解できるものです。開発段階の資産はより広くアクセスできるものですが、品質保証はされません。プロダクションの資産は一般的にはビジネスクリティカルであり、テストや品質に対する最高の保証がされますが、誰が変更できるのかに関しては厳密な制御が行われます。
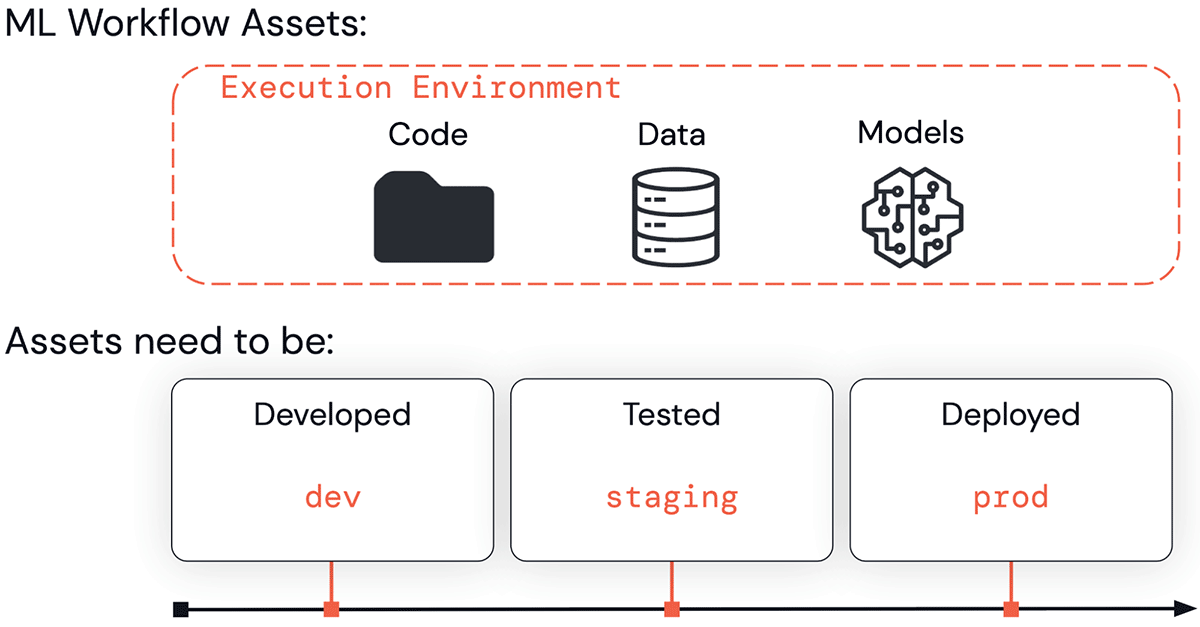
MLOpsでは、実行環境、コード、データ、モデルをともに管理します。これら4つはdev、staging、prodステージに分割されます。
主な課題
上述した一連の要件によって複雑性は容易に爆発します。複数のチームにおいて、開発、テスト、プロダクションにまたがって、アクセスコントロールや複数のテクノロジーによる複雑性に対応しつつ、どのようにコード、データ、モデルを管理するのでしょうか?我々はこれまでにいくつかの主要な課題につながる複雑性を見てきました。
オペレーションのプロセス
DevOpsの考え方を直接MLOpsに翻訳することができません。DevOpsでは、実行環境、コード、データの間に密接な対応が存在します。例えば、プロダクション環境はプロダクションレベルのコードのみを実行し、プロダクションレベルのデータのみを生成します。モデルとコードのライフサイクルのフェーズが多くの場合非同期に実行されるため、MLモデルが話を複雑なものにします。コードの変更をプッシュする前に新たなモデルバージョンをプッシュしようとしたい、あるいは逆の順序でプッシュしたいと考えるかもしれません。以下のシナリオを考えてみましょう。
- 不正なトランザクションを検知するために、週次でモデルを再トレーニングするMLパイプラインを構築します。4半期ごとにコードをアップデートしますが、毎週新たなモデルが自動でトレーニング、テストされ、プロダクションに移行します。このシナリオではモデルのライフサイクルはコードのライフサイクルよりも速いものとなります。
- 大規模なニューラルネットワークを用いて文書を分類するために、モデルのトレーニングとデプロイはコストの都合上多くの場合一度限りのプロセスとなります。しかし、後段のシステムは定期的に変更されるので、対応するためにサービング、モニタリングのコードを更新します。このシナリオでは、コードのライフサイクはモデルのライフサイクルよりも速いものとなります。
コラボレーションとマネジメント
MLOpsでは、データサイエンティストがモデルを開発し維持していくための柔軟性とか姿勢を持てるニーズと、それと競合するMLエンジニアによるプロダクションシステムに対するコントロールを持てるニーズのバランスを取る必要があります。データサイエンティストは自身のコードをプロダクションのデータに対して実行し、プロダクションシステムにおけるログやモデル、他の結果を参照する必要があります。MLエンジニアは安定性を維持し、時にはデータのプライバシーを保護するためにプロダクションシステムへのアクセスを制限する必要があります。単一のアクセスコントロールモデルを共有しない断絶された複数のテクノロジーのつぎはぎでプラットフォームが構成されれいる場合には、この課題の解決はさらに困難なものとなります。
インテグレーションとカスタマイゼーション
多くのMLツールはオープンであるように設計されていません。例えば、いくつかのMLツールはJARファイルのようにブラックボックスフォーマットでのみモデルをエクスポートします。多くのデータツールはML向けに設計されていません。例えば、データウェアハウスでは、MLツールにデータをエクスポートする必要があり、ストレージのコストを引き上げ、ガバナンスに関する頭痛を引き起こします。これらのコンポーネントツールがオープンなフォーマットやAPIに準拠していない場合、統合されたプラットフォームにこれらをインテグレーションすることは不可能です。
レイクハウスでMLOpsをシンプルにする
MLOpsに対する要件を満たすために、Databricksはレイクハウスアーキテクチャにおけるアプローチを構築しました。レイクハウスは単一のプラットフォームでデータレイクとデータウェアハウスの機能を統合し、両方のタイプのデータワークロードを強化するオープンなフォーマットとAPIを用いて、この簡素化を実現することができます。同様に我々はオープンなデータ標準に立脚してMLOpsを構築するので、MLOpsに対してもよりシンプルなアーキテクチャを提供します。
我々のアーキテクチャ上のアプローチの詳細に踏み込む前に、主なメリットをハイレベルで説明します。
オペレーションのプロセス
我々のアプローチではDevOpsの考え方をMLに拡張し、コード、データ、モデルにおいて「プロダクションに移行する」ことが何を意味するのか明確なセマンティクス(意味論)を定義します。MLパイプラインのコードを管理するために、既存のDevOps、CI/CDプロセスを再利用することができます。特徴量の計算、推論、他のデータパイプラインは、モデルトレーニングコードと同じ開発プロセスに従うので、オペレーションをシンプルなものにします。MLflowのモデルレジストリを用いることで、コードとモデルを独立して更新することができ、DevOpsの方法論をMLに適応させる際の主要な課題を解決します。
コラボレーションとマネジメント
我々のアプローチは、データエンジニアリング、探索的なデータサイエンス、プロダクションML、ビジネスアナリティクスが全て共有レイクハウスのデータレイヤーによって支持される統合プラットフォームをベースにしています。MLデータは他のデータパイプラインでも使用される同じレイクハウスアーキテクチャの下で管理されるので、引き継ぎをシンプルなものにします。実行環境、コード、データモデルに対するアクセスコントローによって、適切なチームが適切なレベルのアクセスを持つことができ、管理をシンプルにします。
インテグレーションとカスタマイゼーション
我々のアプローチは、Gitと関連CI/CDツール、Delta Lakeとレイクハウスアーキテクチャ、MLflowのようにオープンなフォーマットとAPIに準拠しています。コード、データ、モデルはお使いのクラウドアカウントにオープンフォーマットで保存され、オープンなAPIを用いたサービスによってサポートされます。以下で説明するリファレンスアーキテクチャは全てをDatabricksで実装することができますが、それぞれのモジュールは皆様の既存のインフラストラクチャとインテグレーションすることができ、カスタマイズ可能です。例えば、モデルの再トレーニングを完全に自動化、あるいは部分的に自動化、手動にすることが可能です。
MLOpsのリファレンスアーキテクチャ
これで、Databricksレイクハウスプラットフォーム上でMLOpsを実装するためのリファレンスアーキテクチャをレビューする準備ができました。このアーキテクチャとDatabricksは通常クラウドを限定せず、一つあるいは複数のクラウドで使用することができます。このため、これが皆様の特定の要件に適応させることを目的としたリファレンスアーキテクチャとなります。このアーキテクチャに関する更なる議論や可能なカスタマイゼーションに関しては、The Big Book of MLOpsを参照ください。
概要
このアーキテクチャは、ハイレベルで我々のMLOpsプロセスを説明します。以下で、このアーキテクチャのキーとなるコンポーネントと、MLパイプラインをプロダクションに移行するステップバイステップのワークフローを説明します。
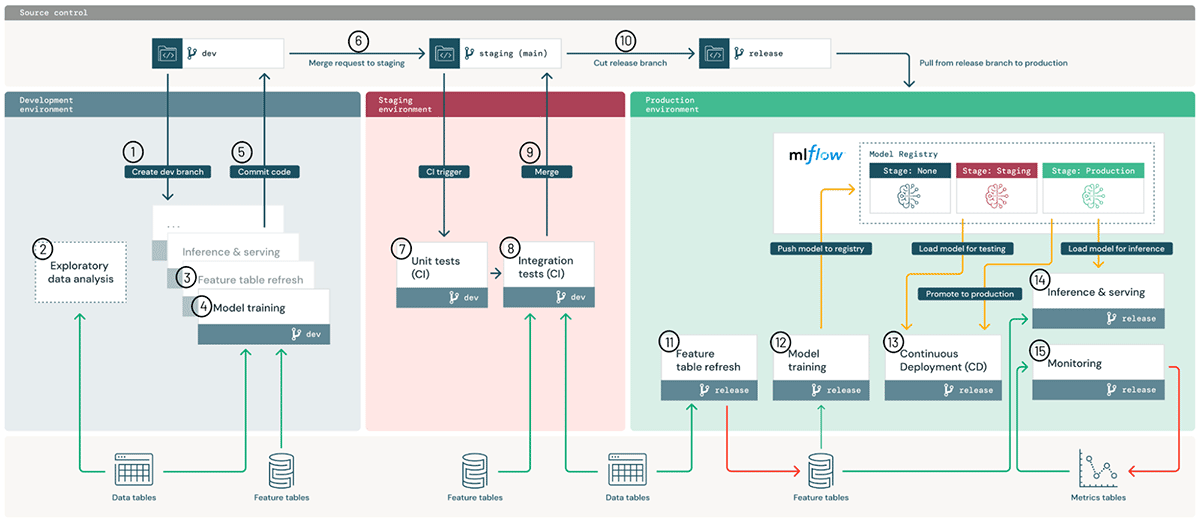
この図はdev、staging、prod環境にまたがるハイレベルのMLOpsアーキテクチャを説明しています。
コンポーネント
いくつかのキーの資産である実行環境、コード、データ、モデルを管理するという観点でアプローチを定義しています。
実行環境はモデルやデータが作成され、コードによって利用される場所となります。環境は、開発、ステージング、プロダクション向けにロールの分離を矯正するワークスペースアクセスコントロールを伴うDatabricksワークスペース(AWS, Azure, GCP)として定義されます。このアーキテクチャ図では、青、赤、緑の領域が3つの環境を表しています。
環境内で、それぞれのMLパイプライン(図の小さい箱)が我々のクラスターサービス(AWS, Azure, GCP)によって管理される計算インスタンス上で実行されます。これらのステップは手動あるいはワークフローやジョブ(AWS, Azure, GCP)を通じて自動実行することができます。それぞれのステップはデフォルトでは、ライブラリが事前インストールされているDatabricks機械学習ランタイム(AWS, Azure, GCP)を使用しますが、カスタムライブラリ(AWS, Azure, GCP)を使用することも可能です。
MLパイプラインを定義するコードはバージョン管理のためにGitに格納されます。MLパイプラインには、特徴量計算、モデルトレーニング、チューニング、推論、モニタリングを含めることができます。ハイレベルで「MLをプロダクションに移行する」ということは、コードを開発ブランチからステージングブランチ(通常はmain)を通じて、プロダクション用途でリリースブランチにプロモートすることを意味します。このDevOpsとのアライメントによって、ユーザーは既存のCI/CDツールとインテグレーションすることができます。上のアーキテクチャ図においては、このコードのプロモーションのプロセスは上部に示されています。
MLパイプラインを構築する際に、データサイエンティストはノートブックからスタートし、必要に応じてDatabricksあるいはIDE上のモジュール化されたコードに移行することができます。お使いのgitプロバイダーとDatabricksワークスペースでノートブックやソースコードを同期するために、Databricks Reposとgitプロバイダーが連携されます(AWS, Azure, GCP)。
データは全て皆様のクラウドアカウント上のレイクハウスアーキテクチャに格納されます。特徴量計算、推論、モニタリングのためのパイプラインは全てデータパイプラインとして扱うことができます。例えば、モデルモニタリングは生のクエリーイベントからダッシュボード向けの集計テーブルに順次データを洗練するメダリオンアーキテクチャに従うべきです。上のアーキテクチャ図では、データは「レイクハウス」データとして一般化して下部に表現されており、開発、ステージング、プロダクションレベルのデータとしては示していません。
デフォルトでは、生データ、特徴量テーブルの両方はパフォーマンスと一貫性保証の観点からDeltaテーブルとして保存されます。Delta Lakeは構造化データ、非構造化データに対するオープンかつ効率的なストレージレイヤー、そして、Databricksで最適化されたDeltaエンジンを提供します(AWS, Azure, GCP)。Feature Storeのテーブルはリネージュのような追加メタデータを持つDeltaテーブルです。生のファイルとテーブルはアクセス管理されており、必要に応じてアクセスを許可、制限することができます。
モデルは、MLflowによって管理され、Databricks内外、任意のデプロイメント手法、任意のMLライブラリによるモデルの統合管理を可能にします。Databricksでは、アクセスコントロール、数百万のモデルに対するスケーラビリティ、オープンソースのMLflow APIのスーパーセットを持つマネージド版のMLflowを提供します。
開発においては、MLflowのトラッキングサーバーがコードのスナップショット、パラメーター、メトリクスや他のメタデータとともにプロトタイプのモデルを追跡します(AWS, Azure, GCP)。プロダクションにおいては、再現性確保やガバナンスの目的で、同じプロセスが記録を行います。
継続的デプロイメント(CD)においては、MLflowのモデルレジストリがモデルのデプロイメントのステータスを追跡し、webhook(AWS, Azure, How to Architect MLOps on the Databricks Lakehouse - The Databricks Blog)あるいはAPI(AWS, Azure, GCP)経由でCDシステムと連携します。モデルレジストリサービスは、コードのライフサイクルとは別にモデルのライフサイクルを追跡します。このモデルとコードの緩やかな結合によって、コードを変更することなしにプロダクションモデルを更新したり、逆のケースも行える柔軟性を提供します。例えば、自動化された再トレーニングパイプラインは、全てプロダクション環境内で、更新されたモデル(「開発」モデル)をトレーニングし、テストし(「ステージング」モデル)、デプロイ(「プロダクション」モデル)することができます。
以下のテーブルでは、コード、データ、モデルに対する「開発」、「ステージング」、「プロダクション」のセマンティクスをまとめています。
| 資産 | dev/staging/prodのセマンティクス | 管理 | 実行環境との関係 |
|---|---|---|---|
| コード | Dev: テストされていないパイプライン Staging: パイプラインのテスト Prod: デプロイできるパイプライン |
MLパイプラインのコードはGitに格納され、dev、staging、releaseブランチに分離されます。 | Prod環境はprodレベルのコードのみを実行すべきです。Dev環境では任意のレベルのコードを実行できます。 |
| データ | Dev: 「Dev」データはdev環境で生成されたデータであることを意味します。Staging/Prodに関しても同様です。 | データはレイクハウスに存在しているので、必要に応じてテーブルアクセスコントロールやクラウドストレージのアクセス権を通じて環境を横断して共有することができます。 | Prodデータはdevやstaging環境から読み込み可能にすることもできますし、ガバナンス要件を満たすために制限することもできます。 |
| モデル | Dev: 新規モデル Staging: 現行のprodモデルとの比較テスト Prod: デプロイできるモデル |
モデルはアクセスコントロールを提供するMLflowモデルレジストリに格納されます。 | それぞれの環境の中でモデルは自身のdev->stagin->prodに遷移することができます。 |
ワークフロー
上述したアーキテクチャのメインコンポーネントを用いることで、MLパイプラインを開発段階からプロダクションに移行するワークフローをウォークスルーすることができます。
開発環境: 主にデータサイエンティストが開発環境でオペレーションを行い、特徴量計算、モデルトレーニング、推論、モニタリングなどを行うMLパイプラインのコードを構築します。
- Devブランチの作成: Gitプロジェクトの開発ブランチで新規・更新パイプラインがプロトタイプされ、Reposを通じてDatabricksワークスペースに同期されます。
- 探索的データ分析(EDA): ノートブック、ビジュアライゼーション、Databricks SQLを用いたインタラクティブ、イテレーティブなプロセスを通じて、データサイエンティストがデータを探索、分析します。
- 特徴量テーブルの更新: 特徴量計算ロジックはFeature Storeや他のレイクハウステーブルから読み込みやFeature Storeへの書き込みを行うパイプラインにカプセル化されます。特徴量パイプラインは、特に別のチームによって管理されている場合には、他のMLパイプラインとは別に管理することも可能です。
- モデルトレーニングとその他のパイプライン: データサイエンティストは、読み取り専用のプロダクションデータから、検閲済みあるいは合成データを用いてこれらのパイプラインを開発します。このリファレンスアーキテクチャでは、(モデルではなく)このパイプラインがプロダクションにプロモートされます。必要に応じて、モデルのプロモーションに関する議論に関しては、ホワイトペーパーをご覧ください。
- コードのコミット: ソース管理システムに新規あるいは更新されたコードがコミットされます。アップデートは単一のパイプライン、複数のパイプラインに影響を与えることがあります。
ステージング環境: MLエンジニアが、MLパイプラインがテストされる、ステージング環境のオーナーシップを持ちます。
-
(プル)リクエストのマージ: ステージングブランチ(通常は
mainブランチ)へのマージリクエストが、継続的インテグレーション(CI)プロセスを起動します。 - ユニットテスト(CI): CIプロセスは最初にデータや他のサービスとのやりとりがないユニットテストを実行します。
- インテグレーションテスト(CI): 次にCIプロセスはMLパイプラインを組み合わせてテストを行うインテグレーションテストを実施します。モデルをトレーニングするインテグレーションテストでは、スピードを優先するために小規模のデータ、少ないイテレーションを採用することがあります。
- マージ: テストに通過すると、コードがステージングブランチにマージされます。
- リリースブランチのカット: 用意ができたら、コードリリースをカットし、プロダクションジョブをアップデートするためにCI/CDシステムを起動することでコードをプロダクションにデプロイすることができます。
プロダクション環境: MLパイプラインがデプロイされるプロダクション環境はMLエンジニアがオーナーシップを持ちます。
- 特徴量テーブルの更新: このパイプラインは新たなプロダクションデータを取り込み、プロダクションのFeature Storeテーブルを更新します。これは、バッチあるいはストリーミングジョブ、スケジュールジョブ、トリガージョブ、継続実行されるもののいずれかとなります。
- モデルトレーニング: 完全なプロダクションデータを用いてモデルがトレーニングされ、MLflowモデルレジストリにプッシュされます。コードの変更あるいは自動化された再トレーニングジョブによってトレーニングをトリガーすることができます。
-
継続的デプロイメント(CD): CDのプロセスは新規モデルを取得(モデルレジストリ上は
stage=None)し、テストし(stage=Stagingに移行)、テストに成功したらデプロイ(stage=Productionにプロモーション)するという手順を踏みます。CDはモデルレジストリwebhookあるいは自身のCDシステムを用いて実装することができます。 - 推論 & サービング: モデルレジストリのプロダクションモデルを複数のモード、高スループットのユースケース向けのバッチやストリーミングジョブ、あるいは低レーテンシーユースケース向けのオンラインサービング(REST API)でデプロイすることができます。
- モニタリング: いかなるデプロイメントモードにおいても、モデルの入力クエリーと予測結果はDeltaテーブルに記録されます。ここから、ジョブを用いてデータとモデルドリフトをモニタリングすることができ、Databricks SQLのダッシュボードを用いてステータスを表示し、アラートを送信することができます。開発環境においては、データサイエンティストはプロダクションにおける問題を調査するために、ログとメトリクスへのアクセスを許可されます。
- 再トレーニング: シンプルなスケジュール処理、あるいは再トレーニングをトリガーするモニタリングジョブによって、最新のデータを用いてモデルを再トレーニングすることをができます。
あなた自身のMLOpsアーキテクチャを実装する
この記事が、レイクハウスパラダイムに立脚したデータ中心のMLOpsアーキテクチャが、どのようにコード、データ、モデルの管理をシンプルにするのかが皆様に伝われば幸いです。残念ですがこの記事は短いものであり、詳細を省略しています。ご自身のMLOpsアーキテクチャを実装し、改善し始めるには以下をお勧めします。
- ワークフローステップの詳細と選択肢やカスタマイゼーションに関する議論が含まれる完全なeBookを読む。こちらからダウンロードしてください。
- 以下のトピックを含むData+AI Summit 2022のMLOpsセッション(6/27-30) に参加する。
- ハイレベルのセッション
- Day 2 Opening Keynotes: 共同創始者とプロダクトマネージャがDS & ML周りのオープンソース、Databricksプロジェクトにおける最新のビジョンとロードマップを共有します。
- ML on the Lakehouse: Bringing Data and ML Together to Accelerate AI Use Cases: Databricksのプロダクトマネージャとお客様が、レイクハウスアーキテクチャにおける機械学習の概要を説明します。
- DatabricksにおけるMLOpsに関するディープダイブ
- MLOps on Databricks: A How-To Guide: この記事の著者がeBookの詳細を説明し、DatabricksにおけるMLOpsプロセスのデモを行います。
- MLflow Pipelines: Accelerating MLOps from Development to Production: DatabricksのエンジニアがMLflowの最新のイノベーションにディープダイブします。
- MLflow Pipelines: Accelerating MLOps from Development to Production: Databricksのエンジニアが特徴量ストアにディープダイブします。
- 自身のMLプラットフォームに関するお客様のディスカッション
- ハイレベルのセッション
- Databricksアカウントチームと会話する。 アカウントチームは皆様の要件に対するディスカッションをガイドし、このリファレンスアーキテクチャを皆様のプロジェクトに適合させるお手伝いをし、トレーニングや実装に関するリソースを提供します。
MLOpsの背景については、以下を読むことをお勧めします。
- データを中心とした機械学習プラットフォームに対するニーズ → この記事では詳細にMLOpsとデータ中心であることの必要性を説明しており、新たなMLアプリケーションを構築するデータチームの完全な例をウォークスルーしています。
- 機械学習プラットフォームを選択する際の3つの原則 → この記事では、この記事よりも一段ハイレベルなものとなっています。MLプラットフォームにおける技術の選択を議論しており、ハイレベルのガイドラインと関連するお客様のストーリーを説明しています。
- The Comprehensive Guide to Feature Stores → 特徴量ストアはこれらに関連する全体的なトピックです。このガイドではディープダイブを行なっています。