How Data-Centric Platforms Solve the Biggest Challenges for MLOps - The Databricks Blogの翻訳です。
モデル中心のアプローチからデータ中心のアプローチに切り替えることで、なぜMLOps最大の課題を解決できるのか
このブログ記事はMLOpsとモデルガバナンスに関するシリーズの第一話です。次の記事では、どのようにデータサイエンスと機械学習において適切な技術を選択するのかを、Joseph Bradleyが自身が顧客と協働した経験に基づき議論します。
イントロダクション
機械学習プロジェクトの失敗率が、いまだに驚くほど高いものであることを最近になって知りました。調査では、プロジェクトの85-96%が本格運用に到達しないと出ています。過去5年間における機械学習(ML)とデータサイエンスの成長を見ると、この数字は特筆すべきものと言えます。一体何がこの失敗率に寄与しているのでしょうか?
MLのイニシアチブによってビジネスを成功させるためには、機械学習におけるリスク、および対策に関する包括的な理解が必要となります。この記事では、MLシステムのモデル中心の考え方からデータ中心の考え方に移行することで、どのようにしてゴールに到達すべきかに関して光を当てることを試みます。また、MLOpsとモデルガバナンス、そして、Databricksのようなデータ中心のMLプラットフォームの活用方法に関して深掘りします。
MLアプリケーションのデータ
もちろん、MLにおいてデータが最も重要なコンポーネントであることは、誰でも知っています。ほぼ全てのデータサイエンティストは、右のような言葉を聞いたことがあるはずです:「ガーベージイン、ガーベージアウト」、「データサイエンティストは時間の80%をデータのクレンジングに費やしている」。これらの格言は、モデルトレーニングを成功させるという文脈において純粋にデータに言及しているものであり、5年前同様、今でも真実と言えます。入力となるトレーニングデータがゴミであれば、モデルの出力結果もゴミとなるので、我々は時間の80%を、データがクリーンであること、モデルが有用な予測を行えるようにすることに費やしているのです。しかし、モデルのトレーニングもまた、MLシステムのコンポーネントの一つに過ぎません。
Rules of Machine Learningにおいて、リサーチサイエンティストのMartin Zinkevichは、最初のモデルをトレーニングする前に、すべてのビジネスメトリクスやテレメトリに対する信頼性のあるデータパイプラインとインフラストラクチャを実装することの重要性を強調しています。彼はまた、シンプルなモデルを用いたパイプラインのテスト、あらゆるプロダクション(本格運用)のデプロイメントの前に、データが期待された通りに流れているかを確実にするための経験則を提唱しています。Zinkevichによると、成功しているMLアプリケーションのデザインにおいては、システムに求められる幅広い要件を最初に検討し、トレーニングデータ、推定データに過度にフォーカスしないとのことです。
Zinkevichだけが、世界をこのように見ている訳ではありません。GoogleにおけるTensorflow Extended (TFX)チームは、Zinkevichを引用し、リアルワールドのMLアプリケーションは、「いくつかのメンタルモデルのシフト(あるいは拡張)を必要とする」と声を上げています。
卓越したAIリサーチャーのAndrew Ngも最近、機械学習システムに対する従来型のモデル中心アプローチではなく、データ中心のアプローチを採用すべきだと述べています。Ngは、より良いトレーニングデータによるモデルの改善の文脈で、このことを述べていますが、さらに深い何かに関して言及しているのだと私は思います。これら両方のリーダーからのメッセージは、MLアプリケーションのデプロイを成功させるためには、フォーカスのシフトが必要であるということです。*「有用なモデルをトレーニングするにはどのようなデータが必要ですか?」と尋ねるのではなく、「私のMLアプリケーションの成功を計測、維持するために必要なデータはどのようなものですか?」*と質問すべきです。
自信を持って成功を計測し維持するためには、ビジネス、エンジニアリング要件を満足するために様々なデータを収集する必要があります。例えば、どうすればプロジェクトにおけるビジネスKPIを達成したのかどうかを知ることができるのでしょうか?あるいは、我々のモデルとデータに関するドキュメントはどこにあるのでしょうか?このモデルに責任を持っているのは誰で、リネージュ(系統情報)をどのように追跡できますか?MLアプリケーションにおけるデータフローに目を向けることで、これらのデータポイントのいくつかをどこで発見できるのかが見えてきます。
以下の図では、それぞれのステージのペルソナに植物を提案する架空のWebアプリケーションにおけるデータフローを示しています。
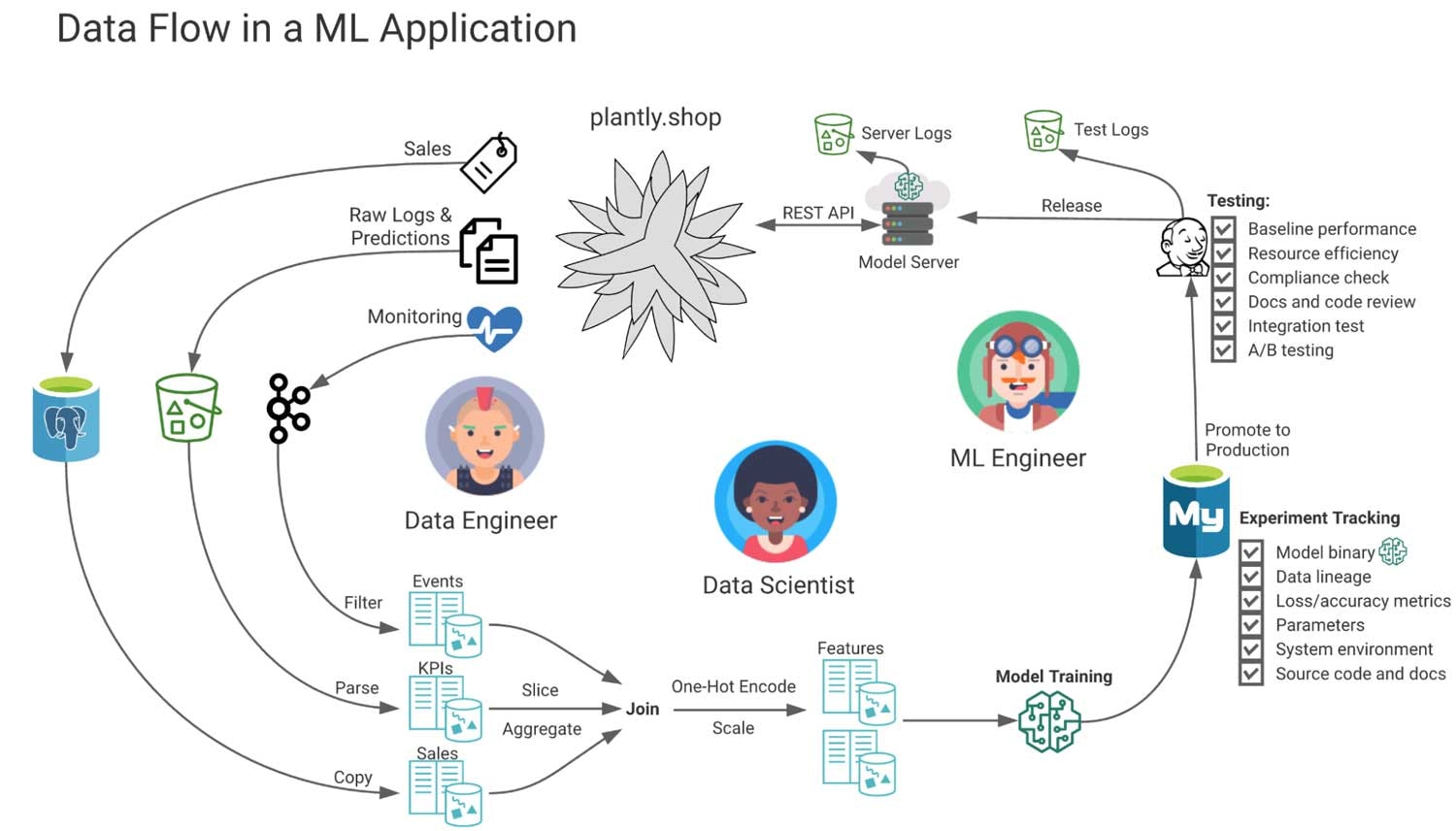
この図では、Webアプリケーションのソースデータから、中間ストレージ、そして、派生テーブルにデータが流れています。これらは、モニタリング、レポート、特徴量エンジニアリング、そして、モデルのトレーニングに使用されます。モデルに関する追加のメタデータが抽出され、コンプライアンスおよび監査目的で、テスト、サービングに関するログが記録されます。特定のタスクに対してMLモデルがうまく動作しているかどうかに関係なく、このプロジェクトで見逃している、あるいは管理できていないのは、モデルのパフォーマンスが発揮されていない、あるいは全く動作していないというリスクです。
MLエンジニアリング、MLOps、モデルガバナンス
DevOpsとデータガバナンスがリスクを低減し、ある種の原則になったのと同様に、オペレーションをハンドリングする際の原則(MLOps)として、MLアプリケーションに対するガバナンスとしてMLエンジニアリングが誕生しました。本文脈においては、主に2種類のリスクを管理する必要があります:MLアプリケーションシステム固有のリスクと、外部システムによるコンプライアンス違反のリスクです。もし、データパイプラインのインフラストラクチャ、KPI、モデルのモニタリング、ドキュメンテーションが欠如していたら、お使いのシステムの安定性、効果が損なわれるリスクが増加します。一方で、きちんと設計されていても、企業、規制、倫理的要件に準拠できていないアプリケーションは、ファンディングの機会を失い、罰金を受け、悪い評判が立つリスクを冒していると言えます。
どうすれば企業はこのリスクを管理できるのでしょうか?MLOpsとモデルガバナンスはいまだ黎明期であり、正式な標準や定義は存在していません。このため、顧客との協働を通じて得られた我々の経験から、これらを考えるための有用な定義を提案します。
MLOps(機械学習オペレーション)は、本格運用モデルとタスクに対するアクティブなマネジメントであり、これには安定性と効果が含まれます。言い換えると、MLOpsは、より良いデータ、モデル、開発者のオペレーションを通じた、MLアプリケーションの機能の維持に関するものだと言えます。つまり、MLOps = ModelOps + DataOps + DevOpsと言えます
一方、モデルガバナンスは、周辺システム上でのモデル、タスク、そして、効果に対するコントロールおよび規制と言えます。リアルワールドでMLアプリケーションが機能することで、どのような影響が起きるのかに焦点を当てたものとなります。
この違いを説明するために、誰かがあなたのデバイス上でBitcoinを隠れてマイニングするために使用される、高機能MLアプリケーションを構築したという極端なケースを考えてみます。これは非常に効果的ですが、ガバナンスの欠如は社会に対してネガティブな結果をもたらします。同じように、政府の規制に対応するために、クレジットリスクモデルに関して400ページものコンプライアンス、監査レポートを書くことができるかもしれませんが、アプリケーションが安定しておらず、成果も出していない場合には、オペレーション観点が欠落していることになります。
機能的であり、人間に敬意を払うシステムを構築するためには両方が必要となります。少なくとも、稼働時間と安定性を維持するためにオペレーションされるべきであり、それぞれの企業は、作成するMLアプリケーションに対して、法的、経済的な責任を持つ必要があります。今時点では、AIに対する法規制が未成熟であるため、この責任は比較的限定的です。しかし、この業界の先進的な企業や学術機関は、未来を形作るために動き始めています。GDPRがデータ管理の世界に大きな波を引き起こしたのと同じように、MLにおいても同様の規制が施行されることは不可避のように見えます。
基本的な機能
オペレーションとはガバナンスの区別をしたことで、次の質問ができるようになりました:これらをサポートするために必要な機能は何でしょうか?これに対する答えは、大きく6つのカテゴリーに分類されます。
データの処理および管理
MLにおける数多くのイノベーションはオープンソースの世界で起きているため、オープンなフォーマット、APIによる構造化データ、そして非構造化データのサポートは前提条件となります。そして、システムはKPI、モデルのトレーニング、推論、ターゲットのドリフト、テスト、ロギングに対するパイプラインを処理、管理できる必要があります。すべてのパイプラインが同じようにデータを処理し、同じSLAを必要とする訳ではないことに注意してください。ユースケースに応じて、トレーニングパイプラインがGPUを必要とする場合がありますし、モニタリングパイプラインはストリーミング、推論パイプラインは低レーテンシーのオンラインサービングを必要とする場合があります。特徴量はトレーニング(オフライン)、サービング(オンライン)の間で一貫性が保持されるべきであり、多くの場合でソリューションとしての特徴量ストアが必要となります。どうすれば、データエンジニアによる特徴量の管理、失敗したジョブの再実行、データリネージュの理解、GDPRのような規制への準拠が容易に行えるようになるのでしょうか?これらの機能を提供する際の選択がROIに大きく跳ね返ってきます。
セキュアなコラボレーション
リアルワールドのMLエンジニアリングは部門横断の取り組みであり、成功のためには全体的なプロジェクト管理、ビジネス上のステークホルダーとデータチーム間の継続的コラボレーションが重要となります。ヒューマンエラー、ミスコンダクトのリスクを低減しつつも、一つの場所にあるデータ、コード、モデルを対象として、適切なグループが協働できるようにするためには、アクセスコントロールが重要な役割を担います。この概念は、開発環境と運用環境の分離にも拡張されます。
テスト
期待している品質をシステムが達成していることを確実にするために、コード、データ、モデルに対してテストを行うべきです。これには、特徴量エンジニアリング、トレーニング、サービング、メトリクスをカバーするパイプラインコートに対するユニットテストと、エンドツーエンドの統合テストが含まれます。モデルに対しては、デモグラフィック、地理セグメントに対するベースラインの精度、特徴量の重要度、バイアス、入力スキーマの競合、計算処理の効率に関してテストされるべきです。データに対しては、センシティブな個人情報・医療情報の有無、トレーニング・サービングの偏り、特徴量ドリフト、ターゲットドリフトに対するテストが行われるべきです。理想的に自動化されたテストはヒューマンエラーのリスクを低減し、コンプライアンスに対して対応できるようになります。
モニタリング
システムに対する定期監視は、安定性と効果に関するリスクを増加させるようなイベントの識別、対応をサポートします。キーとなるパイプラインの失敗、モデルの鮮度の損失、運用中の新規モデルがメモリーリークを引き起こした際、どの程度早い段階で発見すべきでしょうか?全ての特徴量テーブルが最後に更新された、制限されているデータに誰かがアクセスを試みたのはいつでしょうか?これらの疑問に答えるためには、ライブ(ストリーミング)、定期的(バッチ)、イベントドリブンの更新の組み合わせが必要となります。
再現性の確保
これは、モデルの定義(コード)、入力(データ)、システム環境(依存関係)を再作成して、モデルの出力結果を検証するための機能に関するものです。新規のモデルが予期せずプアなパフォーマンス、人口セグメントに対するバイアスを検知した場合には、コード、特徴量エンジニアリング、トレーニングに用いられたデータに対して監査を行い、別のバージョンを再作成し、再デプロイできるようになっている必要があります。また、運用時のモデルが期待しない動作をした際、再現をせずにデバッグすることができるでしょうか?
ドキュメンテーション
MLアプリケーションのドキュメント化は、オペレーションに関する知識をスケールさせ、技術的負債のリスクを低減し、コンプライアンス違反に対する防波堤として動作します。これには、スキーマ、パラメーター、特徴量の依存関係、モデル、メトリクスなどシステムアーキテクチャの説明可能性、可視化が含まれます。また、運用中の全モデル、ガバナンス要件をレポートします。
データを中心とした機械学習プラットフォームに対するニーズ
最近のウェビナーでMatei Zahariaが、望まれるMLプラットフォームの機能として、データチームによる導入容易性、データインフラストラクチャとのインテグレーション、コラボレーション機能を列挙しました。
この点に関して、モデル中心のアプローチから生まれたデータサイエンスツールは限定的なものとなっています。これらのツールはソフトウェアにおいて高度なモデル管理機能を提供しますが、運用環境や重要なデータパイプラインからは分離されています。この分断されたアーキテクチャは、インフラストラクチャの最も重要なコンポーネントであるデータを管理するために他のサービスに依存しています。
このため、全体的なデータフローに対するアクセスコントロール、テスト、ドキュメンテーションは、複数のプラットフォームに分散することになります。この時点での分離は任意のものに見えますが、基盤が確立されるに従い、あらゆるMLアプリケーションの失敗のリスクと複雑性を増加させることになります。
データ中心のMLプラットフォームは、モデルと特徴量に、ビジネスメトリクス、モニタリング、コンプライアンスに関するデータをもたらします。これらを統合することで、根本的にシンプルなものとなります。レイクハウスアーキテクチャにようこそ。
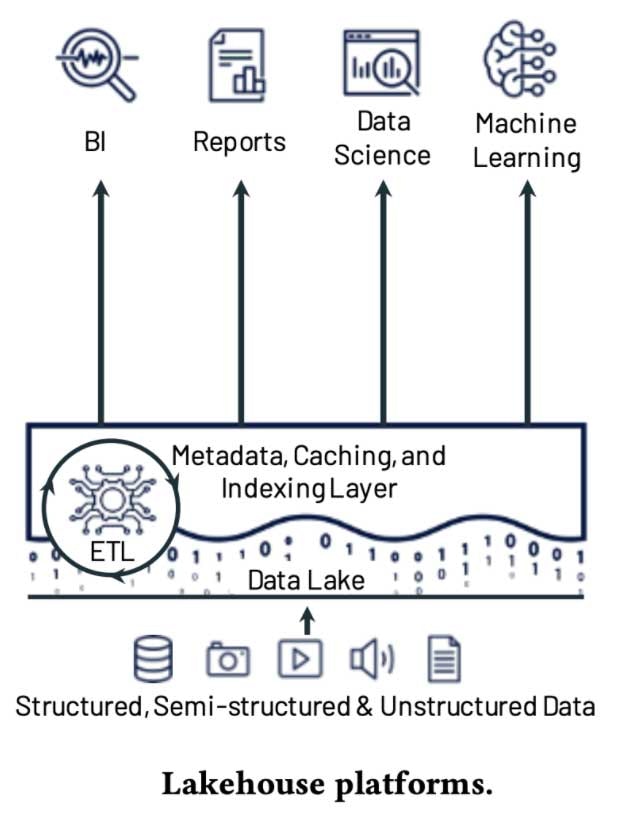
レイクハウスは定義上、データ中心のものであり、データレイクの柔軟性とスケーラビリティとデータウェアハウスのパフォーマンスとデータマネジメントを兼ね備えています。オープンソースベースの基盤は、MLとデータの格納場所との統合を容易にします。Tensorflow、PyTorch、scikit-learnのようなMLフレームワークを使うために、プロプライエタリのシステムからデータをエクスポートする必要はありません。これによって、導入が非常に容易なものになります。
Databricksの機械学習は、レイクハウスアーキテクチャ上に構築されており、セキュアなコラボレーションやモデル管理、テスト、ドキュメンテーションなど重要なMLOps、ガバナンスの要件に対応しています。
データの処理および管理
MLアプリケーションが必要とする様々なタイプ、規模のデータソースを管理、処理する際、DatabricksはApache SparkとDelta Lakeを活用して高いパフォーマンスを発揮します。これらはバッチ処理とストリーミング処理を統合し、GPUの有無に関係なく、ペタバイト規模で構築されたモニタリング、メトリクス、ロギング、トレーニング・推論パイプラインに対するオペレーションが可能となります。Delta Lakeのデータ管理機能によって、規制への準拠が容易となります。トレーニングと推論ジョブにおける、特徴量の検索とサービングを容易にするために、Feature StoreはDelta、Spark、MLlflowと密連携しています。マルチステップのパイプラインはスケジュールされたジョブ、あるいはAPI経由で実行できます。ジョブにおいてはリトライ、メールによる通知が可能です。低レーテンシーでのモデルサービングを行うためには、DatabricksがホスティングするMLflowモデルサービングの機能をテスト、オンラインストアへの特徴量の公開の目的で利用することができます。また、これは実運用の際にAzure MLやSagemakerのようなクラウドサービスの提供している環境やKubernetes環境と連携することも可能です。
セキュアなコラボレーション
テーブルに対するアクセス権の定義に加えて、Databricksは、モデル、コード、計算資源、認証情報に対して、クラウドリソース、ユーザーIDレベルでのアクセスコントロールをサポートしています。これによって、セキュリティポリシーを遵守しながらも、ワークスペース上でのノートブックの同時参照、同時編集が可能となります。運用環境へのアクセスを制限するための管理機能は、世界中の金融機関、医療機関、政府機関で活用されています。
テスト
DatabricksのReposを用いることで、プロジェクトとバージョン管理システムとの連携が可能となり、JenkinsやAzure DevOpsのような、自動化されたビルドアンドテストサーバーと連携できるようになります。これは、コードがコミットされた際に、ユニットテスト、統合テストを実行する際に使用できます。また、Databricksは、例えばステージングからプロダクションにモデルが昇格するなど、モデルのライフサイクルに変化があった際に実行されるMLflow webhooksをサポートしています。これらのイベントによって、モデルのベースライン精度、特徴量の重要度、バイアス、計算効率の検証を強制することが可能になり、検証を通過しなかった候補を棄却するか、コードレビューを招聘したり、それぞれのモデルにタグづけが行えます。MLflowモデルの入力スキーマのシグネチャは、ロギングの際に提供され、運用環境のデータに対する互換性チェックに用いられます。
モニタリング
継続的監視のために、リアルタイムのダッシュボード上にシステムのテレメトリ、KPI、特徴量の分布を可視化し、ステークホルダーに提示するために、構造化ストリーミングとDelta Lakeは、Databricks SQLと組み合わせて活用されます。後ほど分析が行えるように、定期的なバッチジョブが静的な履歴、監査ログテーブルを最新の状態に保ちます。重要なイベントに追従できるように、ジョブが失敗した際にメールあるいはSlackに通知を送ることができます。入力される特徴量の妥当性を維持するために、定期的に特徴量の分布に対する統計検定を実施し、結果をMLflowに記録すべきです。特徴量の形状およびターゲットの分布が変化しているかどうかを容易に確認するためにMLflowのrunを比較することができます。分布やアプリケーションのレーテンシーが閾値を上まった場合に、Databricks SQLのアラートがwebhook経由でモデルのトレーニングジョブを実行し、自動で新規バージョンをデプロイすることができます。MLflowモデルレジストリ上のモデルのステータスの変化は、テストで述べたものと同じwebhookを用いてモニタリングすることができます。これらのアラートは、運用中のモデルの効力を維持するためには重要なものとなります。
再現性の確保
MLflowは実験段階から実運用に至るまでのモデルを管理、追跡するための一般的なフレームワークです。トレーニング時に、ソースコード、データソース、ライブラリの依存関係、インフラストラクチャ、モデル、そしてSHAP explainersや、pandas-profilingのような任意のアーティファクトが記録(あるいはオートロギング)されます。これによって、クリック一つでトレーニングを再現することができます。このデータは、モデルが集中管理されるモデルレジストリに昇格された際に保存され、デザイン、データリネージュ、作成者に関する監査履歴として活用できます。レジストリでモデルのバージョンを管理することで、問題が発生した際にエンジニアがデバッグ、調査を行うために原因を追跡するのと並行して、容易にロールバックできるようになります。
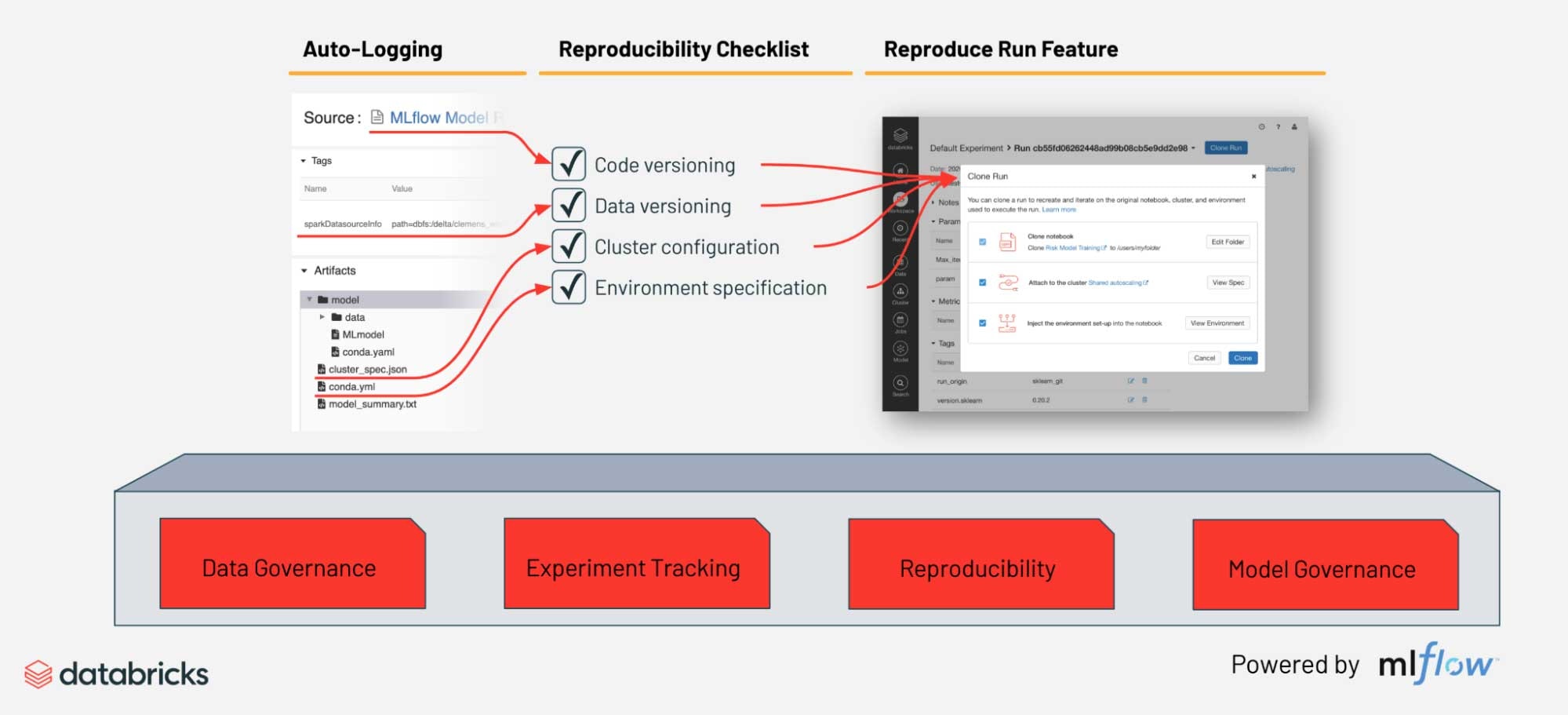
ドキュメンテーション
ドキュメンテーションは検索しやすいものであるべきと言う意見に従い、Databricksのノートブックはプラットフォームで実行されるパイプラインとシステムアーキテクチャのドキュメントを作成する際にフィットしています。上で述べたように、ノートブックに加えて、関連するアーティファクトをMLflowトラッキングサーバーに記録することで、モデルもきちんと説明できるようになります。トラッキングサーバー、レジストリは、モデルに対するアノテーションや、UI、API経由でライフサイクル上のステージに関する記述をサポートしています。これらは、AIシステムに対して、人間による判断とフィードバックをもたらす重要な機能です。
全てを統合
Databricksのようなデータ中心MLプラットフォームにおける、MLアプリケーションの開発がどのようなものかを説明するために、以下のようなシナリオを考えてみます。
オンラインストアplantly.shopにおける売り上げを改善する推薦エンジンを構築するタスクを担った三人からなるチーム(データエンジニア、サイエンティスト、機械学習エンジニア)
最初に、チームはビジネスステークホルダーと会って、KPIおよびモデル、アプリケーション、対応するデータパイプラインに対する要件を明らかにし、データアクセスの方法や直近対応すべき規制などを明確にします。
データエンジニアは、ソースコードをDatabricksのRepoに同期させて、バージョンコントロールをするところからプロジェクトをスタートします。そして、Apache Sparkを使ってApache KafkaやOLTPデータベースからDelta Lakeにセールスデータとアプリケーションログデータを取り込む作業に取り掛かります。すべてのパイプラインは、将来に渡ってターンキーのストリーミングを提供できるように、Sparkの構造化ストリーミングとTriggerOnceを用いて構築されます。テーブルに対する品質を確保するために、データに対するエクスペクテーションが定義され、IDEからローカルモードのSparkを用いてユニットテストと統合テストが記述されます。Databricksの共有ノートブック上で、マークダウンを用いてテーブル定義のドキュメントが作成され、社内のwikiにコピーされます。
データサイエンティストはSQLを用いたテーブルへのアクセスを許可されており、Databricks AutoML、koalasとノートブックを用いて、提示された植物をユーザーが購入するかどうかを予測するベースラインモデルを開発します。ベースラインのシステム環境、コード、モデルのバイナリー、データリネージュ、特徴量の重要度がMLflowトラッキングサーバーに自動的に記録され、監査、再現性の確保をシンプルなものにします。
実運用されているパイプラインでテストを行いたいと考え、データサイエンティストはMLflowモデルレジストリでモデルを昇格させます。これによってwebhookが起動され、MLエンジニアによって記述された一連の検証テストが実行されます。予測精度、運用環境との互換性、計算性能、トレーニングデータ、予測結果に関するコンプライアンス上の懸念(侵入生物を提案できませんよね?)に対するチェックを通過したのち、MLエンジニアがモデルの本格運用への遷移を承認します。MLflowのモデルサービングを用いることで、REST API経由でモデルをアプリケーションに公開することができます。
次回のリリースにおいては、実運用におけるトラフィックの一部がAPIエンドポイントに送信され、モデルがテストされます。そして、モニタリングシステムが稼働します!ログがDelta Lakeにストリーミングとして流れ込み、パースされたのち、Databricks SQL上のダッシュボード上にコンバージョンレート、計算使用率、予測結果の分布、あらゆる外れ値などが可視化されます。これらによって、ビジネス上のステークホルダーは、プロジェクトがうまくいっているのかどうかを直接状況を確認することができます。
この時、データサイエンティストは、ディープラーニングをを用いたモデルバージョン2の作業で忙しくなっています。MLランタイムが稼働するGPUが有効化されたシングルノードを起動し、MLflowで自動的に追跡されるPyTorchを用いてソリューションを構築します。このモデルはベースラインモデルよりも遥かに優れた性能を示していますが、全く異なる特徴量を使用しています。これらはDelta Lakeに保存され、それぞれの特徴量、ソースとなるテーブル、モデル作成に使用されたソースコードに対するドキュメントを作成します。すべてのテストを通過したのち、バージョン2の植物推薦モデルとして登録されます。
パンデミックは確実に植物の売り上げを急激に向上させ、予想した以上のトラフィックを引き起こしました。チームは、Sparkの構造化ストリーミングを用いて、ニアリアルタイムで新規モデルでの予測を行うためにmlflow.pyfunc.spark_udfを使用します。次回のリリースにおいては、インドゴムの木を提案され、すぐに売り切れました。驚くことはありません!チームは成功を祝いましたが、少しの沈黙ののち、データサイエンティストが「過学習」と言うような何かを呟いているのが聞こえてきました...
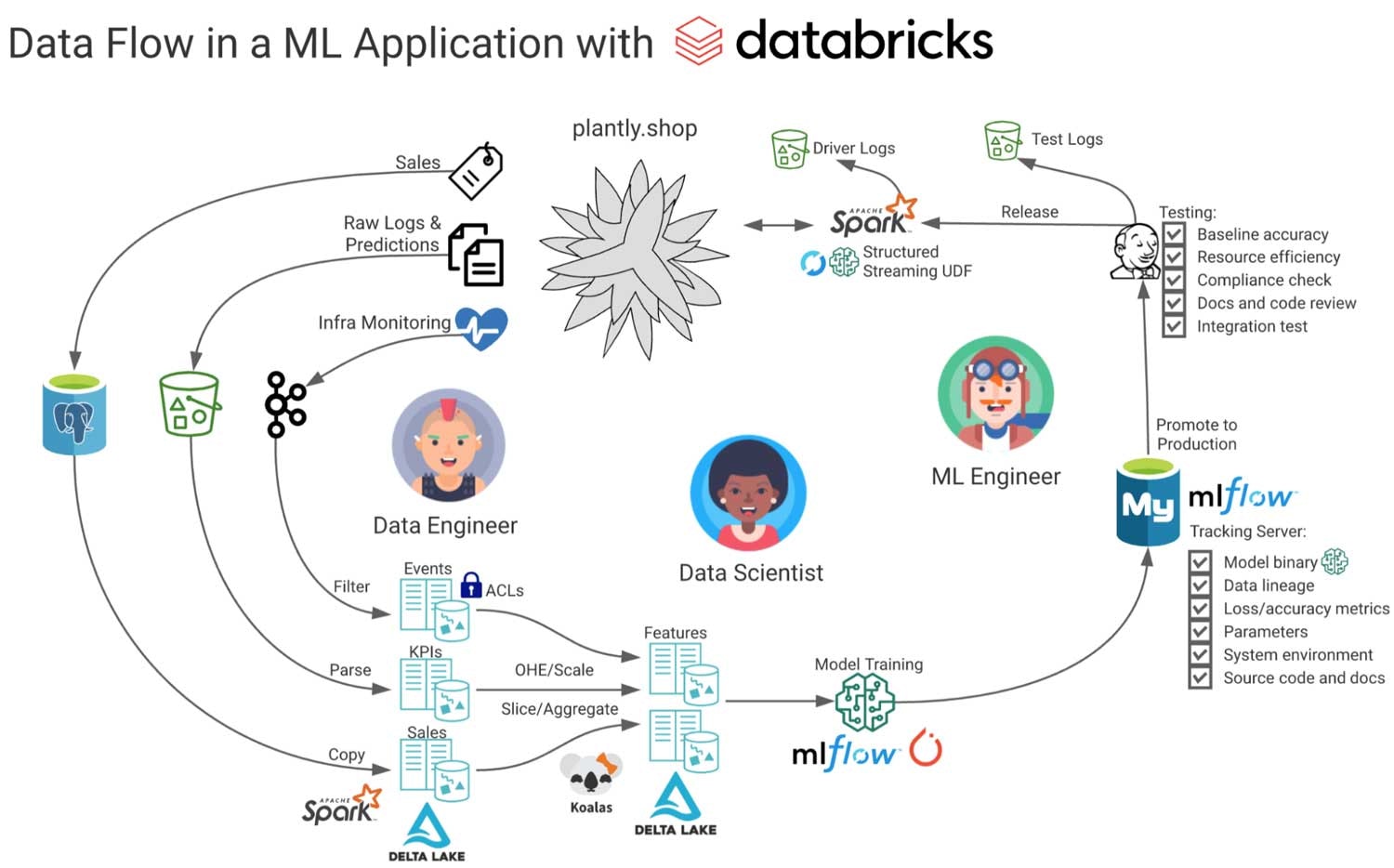
実世界のワークフローをシンプルにしたこの例では、データ中心のMLプラットフォームにおける従来の作業に加えて、MLOpsとガバナンスの部分に焦点を当てました。
まとめ
この記事では、どうしてMLの取り組みが失敗続けるのかを理解する試みを行いました。MLアプリケーションに対するモデル中心のアプローチは、意図せずして膨大なリスクの根源となりうることを発見しました。データ中心のアプローチに切り替えることで、リスクの本質がアプリケーションの機能自体に属するものであるのか、外部システムのコンプライアンスに関するものであるのかを明らかにすることができます。MLOpsとガバナンスは、一連の基本的な機能を通じて実現するMLイニシアチブのリスクを低減するために生まれてきた原理原則です。Databricksのレイクハウスは、オープン性と導入容易性を維持しつつ、これらの機能を提供するデータ中心のMLプラットフォームと言えます。
我々はいまだに機械学習の黎明期にいるのかもしれませんが、それが長く続くとは思えません。AIは経済のあらゆるセクター、そして我々の生活において変化を引き起こし続けるでしょう。強力なMLOpsとガバナンスのプラクティスを伴ったデータ中心のMLプラットフォームを導入した企業は、この変化において重要な役割を担うことになるでしょう。
次のステップ
これらのコンセプトに関するライブデモをご覧になりたい場合には、DAIS 2021セッションLearn to Use Databricks for the Full ML Lifecycleをご覧ください。
今後の記事では、どのようにDatabricksがこれらの機能を実現しているのかを詳細に説明するつもりです。また、詳細を学ぶためのリソースを共有します。
- Matei ZahariaをフィーチャーしたOperationalizing Machine Learning at Scale
- Tech Talk: MLOps on Azure Databricks with MLflow
参考資料
- Most Data Science Projects Fail, But Yours Doesn’t Have To, Datanami, Oct. 2020
- Rules of Machine Learning: Best Practices for ML Engineering, Zinkevich, M. 2017
- Towards ML Engineering: A Brief History of Tensorflow Extended (TFX), Katsiapis et al., page 3, 2020.
- See Andrew Ng’s discussion on ML Ops
- For a more comprehensive discussion on mitigating risk in ML applications, see ML Engineering in Action, Wilson, B., 2021
- EU outlines ambitious AI regulations focused on risky uses, Associated Press 2021
- See “Data Dependencies Cost More Than Code Dependencies”, Hidden Technical Debt in Machine Learning Systems, Scully, et al., 2015.
- See “Data Dependencies Cost More Than Code Dependencies”, Hidden Technical Debt in Machine Learning Systems, Scully, et al., 2015.
- See Chapter 3, “Before you model: Planning and Scoping”, ML Engineering in Action, Wilson, B., 2021
- For an excellent treatment of testing, see The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction, Breck, et al., 2017.
- Ibid.
- Keynote: Operationalizing Machine Learning Systems at Scale, 2021
- See Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics, Armbrust, et al., 2021
- Ibid., especially the section ‘Efficient Access for Advanced Analytics’.
- See Running Streaming Jobs Once a Day for 10x Cost Savings, Yavuz, B., Condie, T., 2017
- https://databricks.com/customers