本日我々は、ML(機械学習)のデプロイの加速するために、Delta Lake、MLflowと協調設計した史上初となるフィーチャーストア Databricks Feature Storeを発表しました。Delta Lakeの全ての利点、データはオープンフォーマットで保存され、ビルトインのバージョン管理、フィーチャーの発見を容易にする自動リネージュ追跡機能を継承しています。特徴量情報をMLflowのモデルフォーマットにパッケージングすることで、特徴量からモデルへのリネージュ情報を提供し、データが変更された際のモデルの再トレーニングとエンドツーエンドのガバナンスを容易にします。モデルのデプロイメントにおいては、モデルは直接フィーチャーストアから特徴量を検索するので、新たなモデルとフィーチャーをデプロイする際のプロセスを劇的にシンプルなものにします。
AIにおけるデータの問題
生のデータ(トランザクションログ、クリック履歴、画像、テキストなど)をそのまま機械学習(ML)に使用することはできません。データエンジニア、データサイエンティスト、MLエンジニアは、生のデータからMLモデルで使用できる最終的な「特徴量」に変換するためにとてつもない時間を費やしています。このプロセスは「特徴量エンジニアリング」とも呼ばれ、データの集計(例:特定の時間ウィンドウにおけるユーザーの購入件数)からMLアルゴリズムの複雑な結果(例:word embeddings)まであらゆるものが含まれます。
このようなデータ変換とMLアルゴリズムの相互依存性は、MLモデルの開発、デプロイに大きな課題を引き起こします。
- オンライン/オフラインの偏り: 多くの意味のあるMLユースケースのいくつかにおいては、モデルは低いレイテンシーのオンラインでデプロイされる必要があります(ウェブページが読み込まれた際に数十msで実行されるレコメンデーションモデルを考えてみてください)。トレーニング(オフライン)における特徴量計算に使用される変換処理は、モデルのデプロイメントの際(オンライン)には、低いレイテンシーで処理される必要があります。このため、チームは特徴量計算を何度も実装しなくてはならず、モデルの品質に重大な影響をもたらす些細な違い(オンライン/オフラインの偏り)を持ち込んでしまいます。
- 再利用性と発見可能性: 多くの場合、特徴量を探し出すのが容易ではないため、何度も再実装しなくてはならず、仮に発見できたとしても再利用しやすい形で管理されていません。この問題に対する素朴な解決策は、特徴量の名前に基づく検索機能の提供ですが、この場合、データサイエンティストは他の人が特徴量にどのような名前をつけたのかを推測しなくてはなりません。さらには、どの特徴量がどこで使われたのかを知る術がなく、特徴量テーブルの更新・削除を決断するのが困難になります。
Databricks Feature StoreはAIにおけるデータ問題をユニークなアプローチで解決
Databricks Feature Storeは、データとMLOpsプラットフォームと協調設計された史上初のフィーチャーストアです。人気のあるオープンソースフレームワークDelta LakeとMLflowとの密接な連携により、フィーチャーストアに格納されているデータはオープンであり、MLフレームワークによってトレーニングされたモデルは、MLflowモデルフォーマットでフィーチャーストアと連携することで様々なメリットを享受することができます。結果として、このフィーチャーストアは、データチームがMLに関わる作業を高速化できるいくつかのユニークな競合優位性を提供します。
- ネイティブモデルパッケージングによるオンライン/オフラインの偏りの除去: MLflowとの連携によって、Feature Storeによるモデルのアーティファクトと特徴量検索ロジックのパッケージングを可能にします。Feature Storeのデータを用いてトレーニングされたMLflowモデルがデプロイされる際、モデル自身が適切なオンラインストアから特徴量を検索します。これは最初からFeature Storeが存在するかどうかを気にせずに、クライアントがモデルを呼び出せるということを意味します。結果として、クライアントの複雑性は低下し、モデルを呼び出すクライアントを変更することなしに、特徴量を更新できることになります。
-
自動化されたリネージュ追跡による再利用性、発見可能性の実現: データネイティブな環境における特徴量計算によって、Databricks Feature Storeが特徴量計算に用いられたデータソース、使用されたコードバージョンを自動で追跡できるようになります。これにより、リネージュベースでの検索が可能となります。データサイエンティストは生データを用いることで、同じデータから計算された全ての特徴量を見つけることができます。加えて、MLflowのモデルフォーマットとの連携により、特徴量からモデルに至る下流のリネージュを提供します。Feature Storeは正確にどのモデルと特定の特徴量を使用したエンドポイントを理解しているので、エンドツーエンドのリネージュを実現し、特徴量テーブルに対する更新、削除を安全に意思決定することができます。
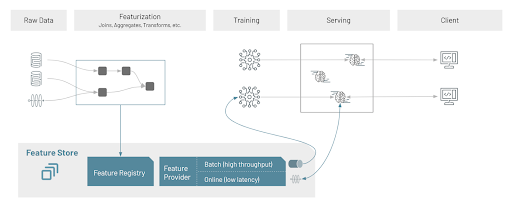
ディスカバリー、コラボレーション、ガバナンスのための中央リポジトリとしてのFeature Store UI
Feature Storeは企業における全ての特徴量の中央管理リポジトリとなります。全ての特徴量に対して検索可能なレコード、定義・計算ロジック、データソース、作成者、特徴量の利用者を参照できます。UIを用いることで、データサイエンティストは以下のことが可能となります。
- 特徴量テーブル名、特徴量、データソースによる特徴量の検索
- 特徴量テーブルから特徴量、接続されたオンラインストアへのナビゲーション
- 特徴量テーブル作成に用いられたデータソースの特定
- 特定の特徴量を使用する利用者(モデル、エンドポイント、ノートブック、ジョブ)の特定
- 特徴量テーブルのメタデータに対するアクセス権管理
Databricks Feature Storeは、他のDatabricksのコンポーネントと完全に統合されています。このネイティブな統合によって、特徴量計算に用いられたデータ、特徴量をリクエストした全ての利用者、Feature Storeの特徴量を利用してトレーニングされたDatabricksモデルレジストリ上のモデルのすべてのリネージュを可能にします。
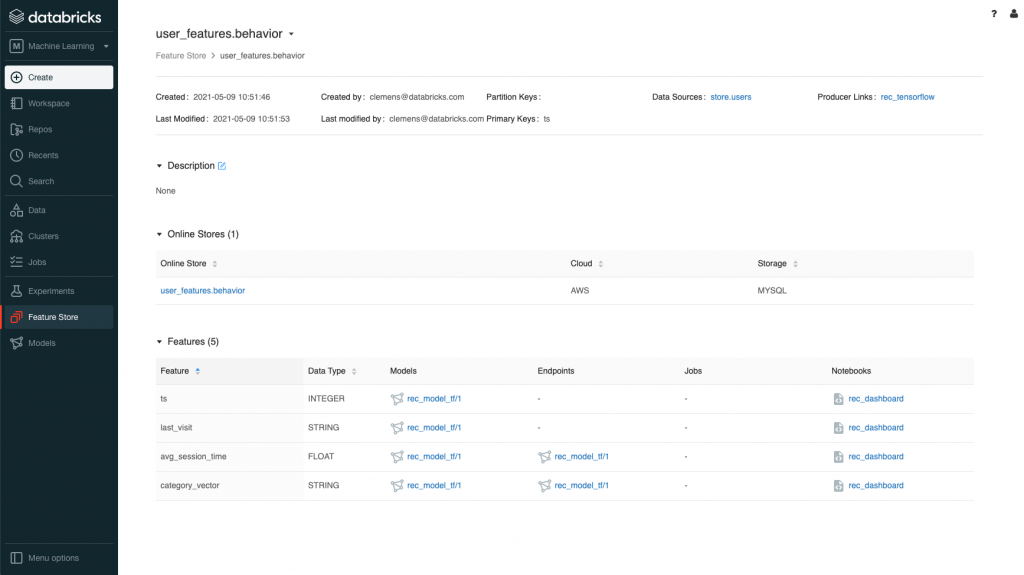
特徴量テーブルuser_features.behaviorのデータソース、作成元のノートブック、モデル、利用側のモデル、エンドポイント、ノートブックを表示
高スループットでのオフラインアクセス、低レーテンシーでのオンラインアクセス
Feature Storeは特徴量にアクセスするアプリケーションに対する様々なオフライン、オンラインの特徴量プロバイダーをサポートしています。特徴量は二つのモードで提供されます。バッチレイヤーは、MLモデルのトレーニングとバッチ推論において特徴量を高いスループットで提供します。オンラインプロバイダーはオンラインでのモデルサービングで同じ特徴量を低いレイテンシーで提供します。オンラインプロバイダーはプラグイン可能な共通的な抽象化で定義され、様々なオンラインストアをサポートし、オフラインからオンラインに特徴量を公開し、特徴量を検索するためのAPIをサポートします。
特徴量は、Databricksにおけるバッチ処理やストリーミングパイプラインで計算され、Deltaテーブルとして格納されます。これらの特徴量は、Databricksのジョブやストリーミングパイプラインを用いて公開することが可能です。これにより、トレーニングとサービングで用いられる特徴量にズレがないことを保証し、バッチトレーニングで用いられる特徴量と、バッチ・オンラインでのモデル推論で用いられる特徴量の一貫性を保つことができます。
モデルのパッケージング
MLflowモデルフォーマットとの連携により、特徴量の情報はMLflowのモデルと一緒にパッケージングされます。フィーチャーレジストリと適切なプロバイダーから特徴量を検索できるように、Feature Store APIはモデルのトレーニングの際、自動的にモデルのアーティファクト、全ての特徴量、実行時に用いられたコードをパッケージングします。
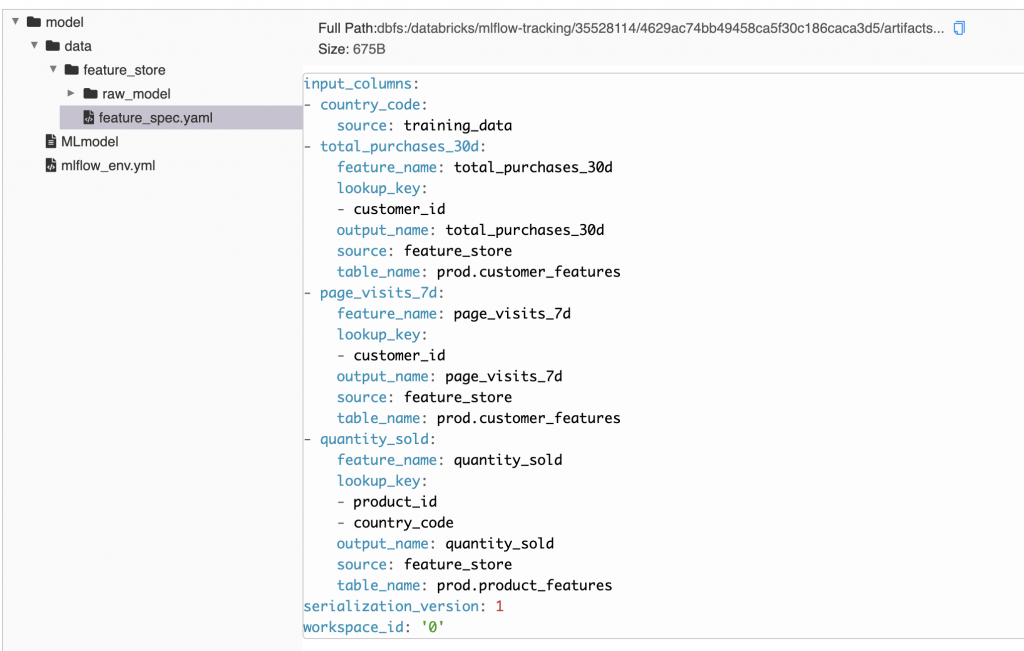
フィーチャーストア情報を含むfeature_spec.yamlはMLflowモデルアーティファクトと一緒にパッケージングされます
モデルアーティファクトと一緒にパッケージングされた特徴量情報によって、Feature StoreのスコアリングAPIが入力データをスコアリングするために、格納されたキーを用いて自動的に特徴量を取得して結合します。このことは、モデルのデプロイメントの際にモデルを呼び出すクライアントはFeature Storeとやり取りする必要がないことを意味します。結果として、クライアントを変更することなしに特徴量を更新できることになります。
Feature Store APIワークフロー
FeatureStoreClient Pythonライブラリは、特徴量の計算・格納方法の定義、モデルトレーニングにおける既存特徴量の利用、バッチスコアリングにおける自動検索、オンラインストアへの特徴量の公開を行うために、Feature StoreのコンポーネントのとやりとりするためのAPIを提供します。このライブラリはDatabricks MLランタイム(バージョン8.3以降)に同梱されています。
新規特徴量の作成
低レベルAPIは、カスタムの特徴量計算コードを記述するのに便利な機構を提供します。データサインティストは、ソーステーブルやファイルを用いて特徴量を計算するためのPythonの関数を記述します。
Python
def compute_customer_features(data):
'''Custom function to compute features and return a Spark DataFrame'''
pass
customer_features_df = compute_customer_features(input_df)
新たな特徴量を作成してFeature Registryに登録するためには、create_feature_table APIを呼び出します。特徴量を格納するための特定のデータベースやテーブルを指定することもできます。それぞれの特徴量テーブルは、エンティティの特徴量の値を識別するための主キーを持つ必要があります。
Python
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
customer_feature_table = fs.create_feature_table(
name='recommender.customer_features',
keys='customer_id',
features_df=customer_features_df,
description='Customer features. Uses data from app interactions.'
)
Feature Storeの特徴量を用いたモデルのトレーニング
Feature Storeから特徴量を利用するためには、それぞれの特徴量テーブルが必要とする特徴量を識別するトレーニングセットを作成し、特徴量を検索し特徴量テーブルと結合するためのトレーニングデータセットのキーを記述します。
以下の例では、customer_featuresテーブルから二つの特徴量(total_purchases_30dとpage_visits_7d)を使用し、トレーニングデータセットのcustomer_idをつかって、特徴量テーブルの主キーと突合して結合を行います。さらに、product_featuresテーブルのquantity_soldを使用し、product_idとcountry_codeの複合主キーを用いて特徴量の検索、結合を行います。そして、create_training_set APIを用いてトレーニングセットを構築し、モデルのトレーニングに不要なキーを削除します。
Python
from databricks.feature_store import FeatureLookup
feature_lookups = [
FeatureLookup(
table_name = 'prod.customer_features',
feature_name = 'total_purchases_30d',
lookup_key = 'customer_id'
),
FeatureLookup(
table_name = 'prod.customer_features',
feature_name = 'page_visits_7d',
lookup_key = 'customer_id'
),
FeatureLookup(
table_name = 'prod.product_features',
feature_name = 'quantity_sold',
lookup_key = ['product_id', 'country_code']
)
]
fs = FeatureStoreClient()
training_set = fs.create_training_set(
df,
feature_lookups = feature_lookups,
label = 'rating',
exclude_columns = ['customer_id', 'product_id']
)
モデルをトレーニングするためにあらゆるMLフレームワークを活用できます。log_model APIは特徴量検索情報とMLモデルをパッケージングします。この情報はモデル推論の際に特徴量を検索するために用いられます。
Python
from sklearn import linear_model
# Augment features specified in the training set specification
training_df = training_set.load_df().toPandas()
X_train = training_df.drop(['rating'], axis=1)
y_train = training_df.rating
model = linear_model.LinearRegression().fit(X_train, y_train)
fs.log_model(
model,
"recommendation_model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="recommendation_model"
)
特徴量の検索とパッチスコアリング
特徴量情報がパッケージングされたモデルをスコアリングする際、これらの特徴量はスコアリングの際に自動的に検索されます。ユーザーが指定する必要があるのは、入力データの列を検索するのための主キーです。Feature Storeのscore_batch APIは内部でモデルアーティファクトに格納された特徴量の仕様を用いて、特定のテーブル、特徴量の列、結合キーに関してFeature Registryとやりとりを行います。そして、このAPIは、モデルのスコアリングに必要なスキーマのデータフレームを作成するために、適切な特徴量テーブルと効率的な結合を行います。以下のシンプルなコードでは、上でトレーニングしたモデルに関するオペレーションを説明しています。
Python
# batch_df has columns ‘customer_id’ and ‘product_id’
predictions = fs.score_batch(
model_uri,
batch_df
)
# The returned ‘predictions’ dataframe has these columns:
# inputs from batch_df: ‘customer_id’, ‘product_id’
# features: ‘total_purchases_30d’, ‘page_visits_7d’, ‘quantity_sold’
# model output: ‘prediction’
オンラインストアでの特徴量の公開
オンラインストアに特徴量テーブルを公開するには、まず初めにオンランストアのスペックを指定し、publish_table APIを呼び出します。以降のコードは、バッチプロバイダーのcustomer_featuresテーブルを最新の特徴量で既存のテーブルを上書きします。
Python
online_store = AmazonRdsMySqlSpec(hostname, port, user, password)
fs.publish_table(
name='recommender_system.customer_features',
online_store=online_store,
mode='overwrite'
)
publish_featuresは特定の特徴量の値(日付などのフィルタリング条件)を除外するための様々なオプションをサポートしています。以下の例では、今日時点の特徴量をオンラインストアに流し込み、既存の特徴量とマージします。
Python
fs.publish_table(
name='recommender_system.customer_features',
online_store=online_store,
filter_condition=f"_dt = '{str(datetime.date.today())}'",
mode='merge',
streaming='true'
)
Feature Storeを使い始めてみる
ご自身でトライする準備はできましたか?Databricks Feature Storeの詳細や使い方はそれぞれのドキュメント(AWS、Azure、GCP)で確認することができます。
詳細はData + AIサミットのキーノート(無料)でも確認することができます。