使い始めて3年くらい経ちますが、改めて振り返ってみます。
こちらの記事を書いたりしていますが復習も大事なわけで。
2025/9にもくもく会を開催します。
Sparkの体験型学習アプリを作成しました。
翔泳社よりApache Spark徹底入門が絶賛発売中です!

その他のDatabricksコアコンポーネントの記事はこちらです。
Apache Sparkプロジェクトの歴史
![]()
SparkはDatabricksの創始者たちがUC Berkeleyにいるときに誕生しました。Sparkプロジェクトは2009年にスタートし、2010年にオープンソース化され、2013年にApacheにコードが寄贈されApache Sparkになりました。Apache Sparkのコードの75%以上がDatabricksの従業員の手によって書かれており、他の企業に比べて10倍以上の貢献をし続けています。Apache Sparkは、多数のマシンにまたがって並列でコードを実行するための、洗練された分散処理フレームワークです。概要とインタフェースはシンプルですが、クラスターの管理とプロダクションレベルの安定性を確実にすることはそれほどシンプルではありません。Databricksにおいては、Apache Sparkをホストするソリューションとして提供することで、ビッグデータをシンプルなものにします。
Apache Sparkとは
Apache Sparkは、オンプレミスのデータセンターやクラウドで利用できる大規模分散データ処理のために設計された統合エンジンです。

Sparkは中間結果をメモリーで保持するのでHadoop MapReduceよりもはるかに高速になります。機械学習(MLlib)、インタラクティブなクエリーのためのSQL(Spark SQL)、リアルタイムデータを操作するためのストリーム処理(構造化ストリーミング)、グラフ処理(GraphX)で利用可能なAPIを持つライブラリと連携します。
Sparkの設計哲学は4つのキーとなる特性を中心としています:
- スピード: Sparkではさまざまな方法でスピードを追求しています。大量の安価なハードウェアを活用することで、効率的なマルチスレッド、並列処理を実現しています。すべての中間結果がメモリーに保持され、ディスクのI/Oを削減することで高いパフォーマンスを実現しています。
- 使いやすさ: データフレームやデータセットのような高レベルのデータ構造がベースとしているRDD(Resilient Distributed Dataset)を用いて、シンプルな論理的データ構造を提供することでシンプルさを実現しています。一連のトランスフォーメーションとアクションを提供することで、慣れ親しんだ言語でビッグデータアプリケーションの構築で活用できるシンプルなプログラミングモデルの恩恵を受けることができます。
- モジュール性: Sparkのオペレーションは、さまざまなワークロードに適用することができ、サポートされるプログラミング言語で表現することができます。Scala、Java、SQL、Rがサポートされています。また、SparkはSpark SQL、構造化ストリーミング、機械学習のためのMLlib、グラフ解析のためのGraphXのようなコアコンポーネントのAPIを持つライブラリと統合されています。
-
拡張可能性: Sparkはストレージよりも自身の高速な並列処理エンジンにフォーカスしています。ストレージと計算資源を持つApache Hadoopと異なり、Sparkではそれらを分離しています。これは、Apache Hadoop、Apache Cassandra、Apache HBase、MongoDB、Apache Hive、RDBMSなどのさまざまなソースに格納されているデータを読み込み、すべてをメモリーで処理するためにSparkを活用できることを意味します。また、SparkのDataFrameReaderやDataFrameWriterは、Apache Kafka、Kinesis、Azure Storage、Amazon S3などのソースからデータを読み込み、それらを操作できるように論理的なデータ抽象化レイヤーに読み込むように拡張することができます。
Apache Sparkの基本アーキテクチャ
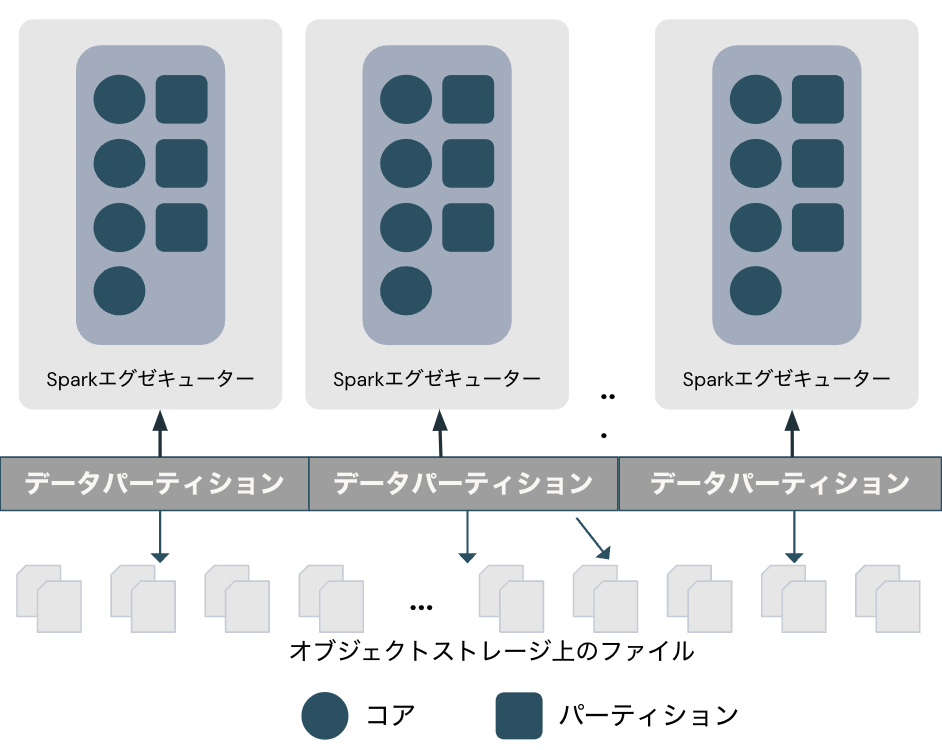
アーキテクチャを理解するには、ドライバーとエグゼキューター(ワーカー)から構成されるSparkクラスターを理解することが重要です。ドライバーが司令塔、エグゼキューターが実際の処理を担います。これによって、並列処理を実現します。
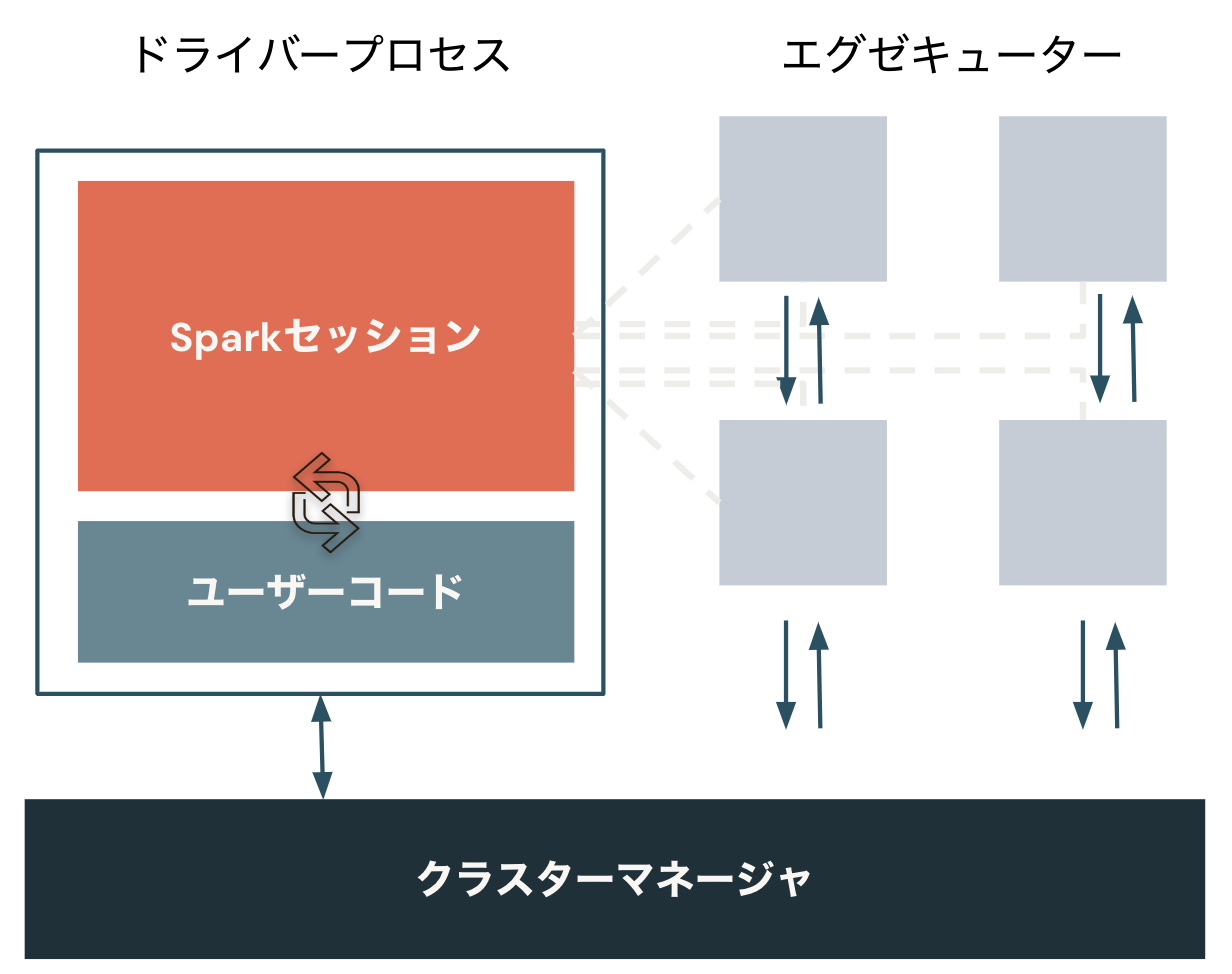
- クラスターマネージャが物理マシンを管理し、Sparkアプリケーションにリソースを割り当てます。
- ドライバープロセスは、タスクを完了するためにエグゼキューターでドライバープログラムを実行することに責任を持ちます。
- エグゼキューターはSparkコードを実行します。
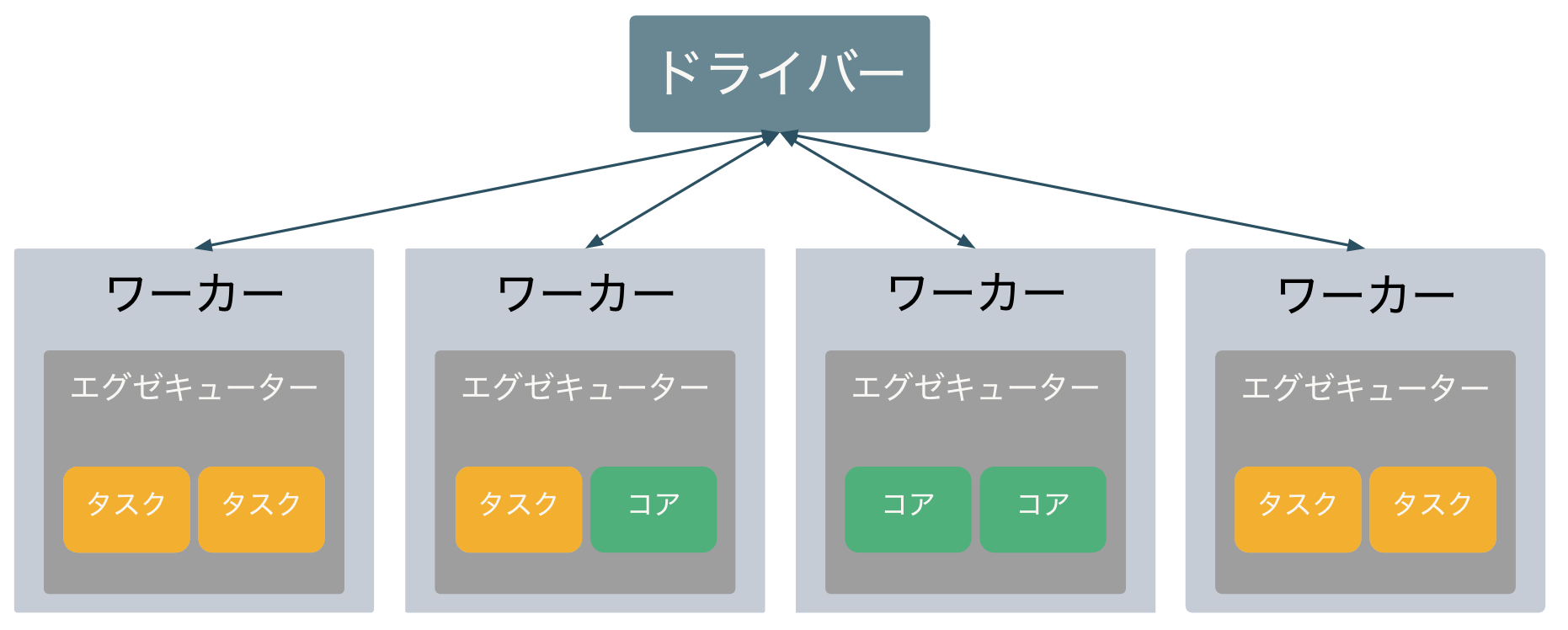
Sparkクラスター
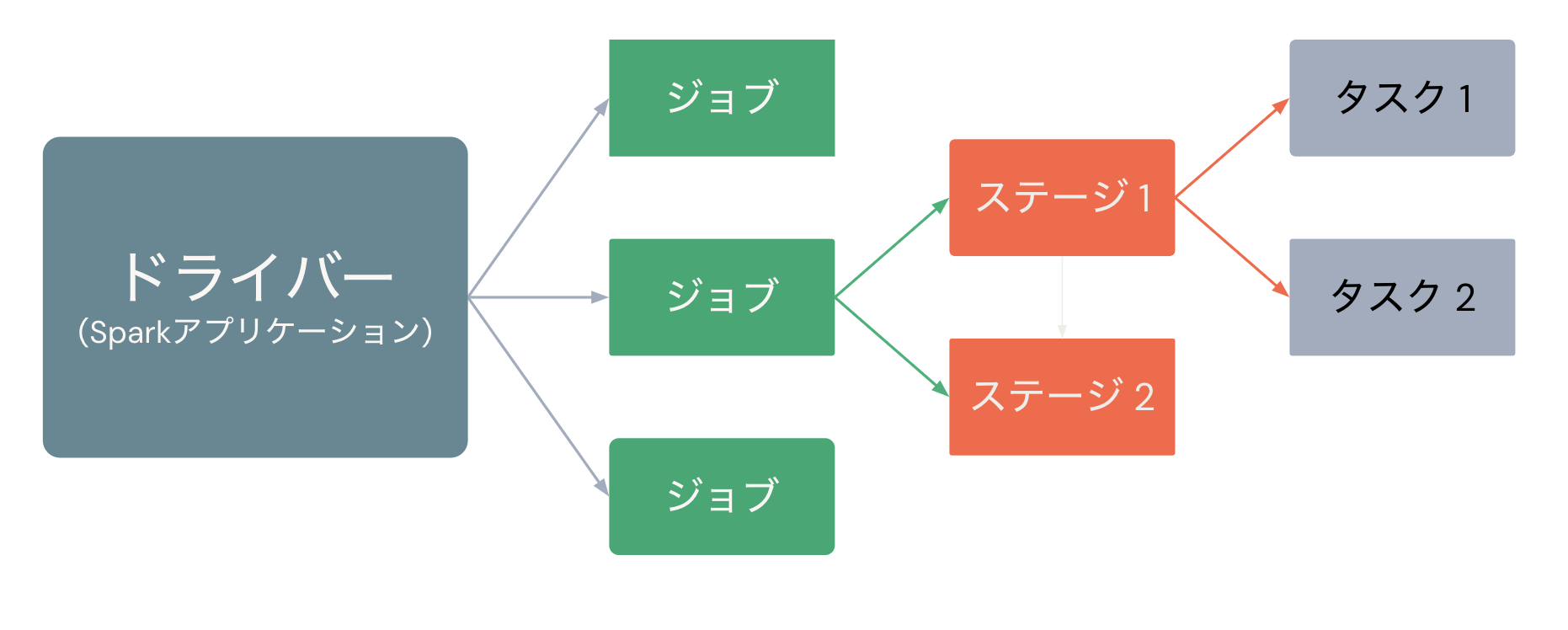
Sparkにおける処理
処理の流れを動画にしました。以下の用語の理解の助けになるかと。
- シェアリソース (Shared resources)
- 並列化 (Parallelization)
- パーティション (Partitions)
- ジョブ、ステージ、タスク (Jobs、 Stages、 Tasks)
- ドライバー (Drivers)
- エグゼキューター (Executors)
- クラスター、ノード (Clusters、 Nodes)
- スロット、コア、スレッド (Slots、 Cores、 Threads)
こちらの記事も参考になります。
Sparkアプリケーション(ユーザーのコード)が実行されると、処理対象のデータを分担できるようにデータを分割することでパーティションが作成され、ドライバーはSparkジョブを生成します。さらにジョブをステージに分割し、最終的にはタスクに分割します。このタスクとパーティションをエグゼキューターに割り当て、エグゼキューターは割り当てられたパーティションに対してタスクを実行(execute)します。これがエグゼキューターの名前の由来です。なお、パーティションのサイズを明示的に指定することも可能です。パフォーマンスの最適化を行う際には、このパーティションサイズが鍵となることが多いです。
注意
ここで述べているタスクは集計やフィルタリングなどのデータ処理に限定されません。Pythonの関数で記述できるものであれば基本何でも大丈夫です。このため、機械学習モデルのトレーニングや推論、自然言語処理なども分散処理することが可能です。
Sparkのパーティションに関してはこちらも参照ください。
Sparkセッション
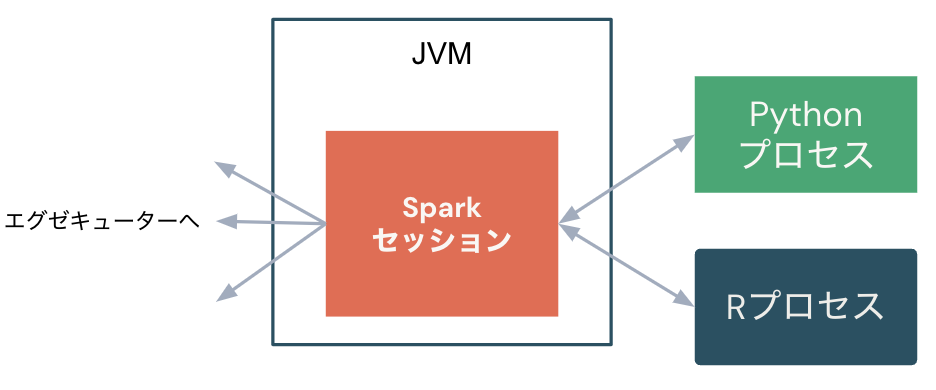
- SparkSessionはすべてのデータフレームAPIの機能に対する単一のエントリーポイントです。
- Databricksノートブックでは自動的に変数
sparkが作成されます。spark...という形で各種メソッドを呼び出して処理を行います。
以下のようなメソッドがあります。
| メソッド | 説明 |
|---|---|
| sql | 指定されたクエリーの結果を表現するデータフレームを返却。 |
| table | 指定されたテーブルをデータフレームとして返却。 |
| read | データフレームとしてデータを読み込む際に使用できるDataFrameReaderを返却。 |
| range | startからend(含まない)の範囲とステップ値、パーティション数を持つ要素を含むカラムを持つデータフレームを生成。 |
| createDataFrame | タプルのリストからデータフレームを作成、主にテストで使用。 |
Sparkデータフレーム
Sparkでのデータ操作においても、pandasやRと同様にデータフレームを用いることが一般的です。Sparkデータフレームは、名前付きカラムでグルーピングされる分散データコレクションです。
- データはストレージの(データ)パーティションに分散されています。このパーティションはSparkパーティションとは別物です。日付のフォルダなどに格納されている状態のことを指しています。
- Sparkはデータをパーティションと呼ばれる塊に分割します。
- Sparkデータフレームによって、物理パーティションにあるデータに対して高レベルの変換処理を適用することができます。
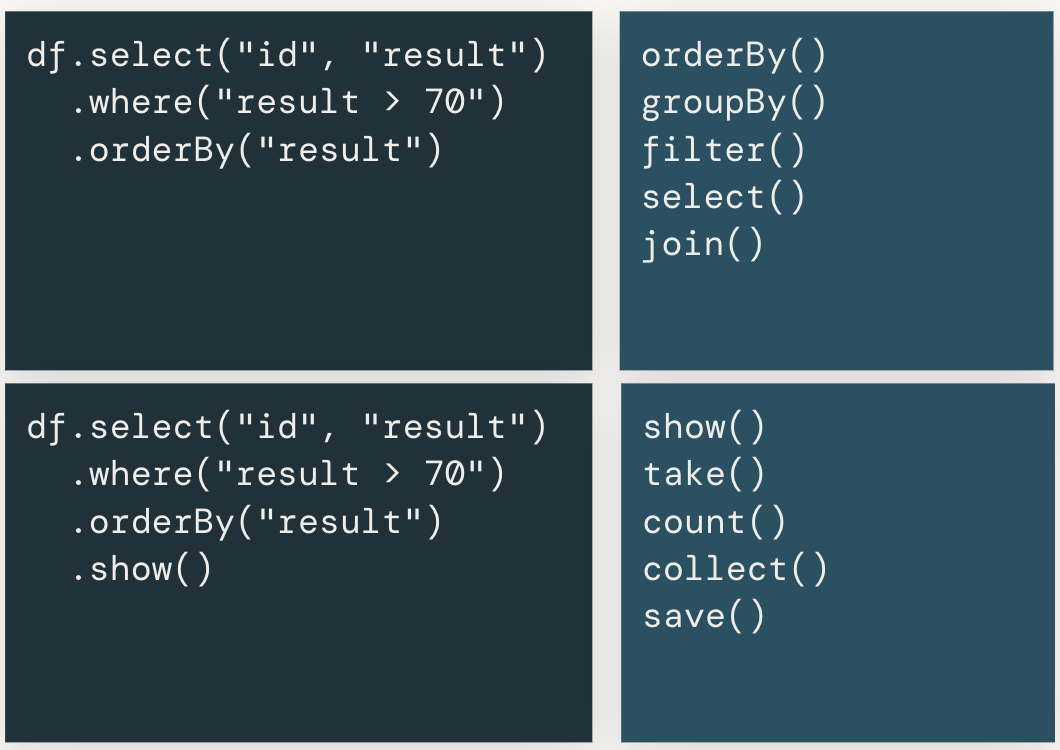
データフレームに対するトランスフォーメーションとアクション
Sparkにおけるデータフレームの操作においては、トランスフォーメーションとアクションを理解することも重要です。Sparkでは大規模データの高速処理を実現するために実行計画を立て、最適化を行うため 遅延評価(lazy evaluation) のアプローチをとっています。逐次実行ではなく、処理のチェーンを組み立てた後に最適化を行うことで、最適なパフォーマンスを実現しています。処理のチェーンを組み立てる際に使用するメソッドがトランスフォーメーションであり、トランスフォーメーションを実行するだけでは実際には処理は行われません。そして、組み立てられた処理のチェーンを最適化して実行を行うメソッドがアクションとなります。
以下の図の右上がトランスフォーメーションのメソッドであり、右下がアクションです。データを取得する、保存するという場合に呼び出すメソッドがアクションとなっています。
サンプル
サンプルノートブックはこちらです。
Databricks上でSparkを実行していきます。
Sparkセッションを確認します。
spark
情報が表示されます。

メソッドrangeを使ってデータフレームを作成し処理を行っていきます。
firstDataFrame = spark.range(1000000)
print(firstDataFrame)
rangeはトランスフォーメーションなのでこの時点では処理実行されません。データフレームのスキーマのみが表示されます。
DataFrame[id: bigint]
さらにトランスフォーメーションを宣言していきます。
# トランスフォーメーションの例
# IDカラムを選択し、2倍します
secondDataFrame = firstDataFrame.selectExpr("(id * 2) as value")
アクションtakeを呼び出して処理を実行します。
# アクションの例
# firstDataFrameの最初の5行を取得します
print(firstDataFrame.take(5))
# secondDataFrameの最初の5行を取得します
print(secondDataFrame.take(5))
結果が返ってきます。
[Row(id=0), Row(id=1), Row(id=2), Row(id=3), Row(id=4)]
[Row(value=0), Row(value=2), Row(value=4), Row(value=6), Row(value=8)]
なお、この際にはSparkジョブと表示され、Sparkのジョブが実行されたことを確認することができます。

Databricksのdisplay関数もアクションとして動作します。
# display()コマンドでsecondDataFrameを表示します
display(secondDataFrame)
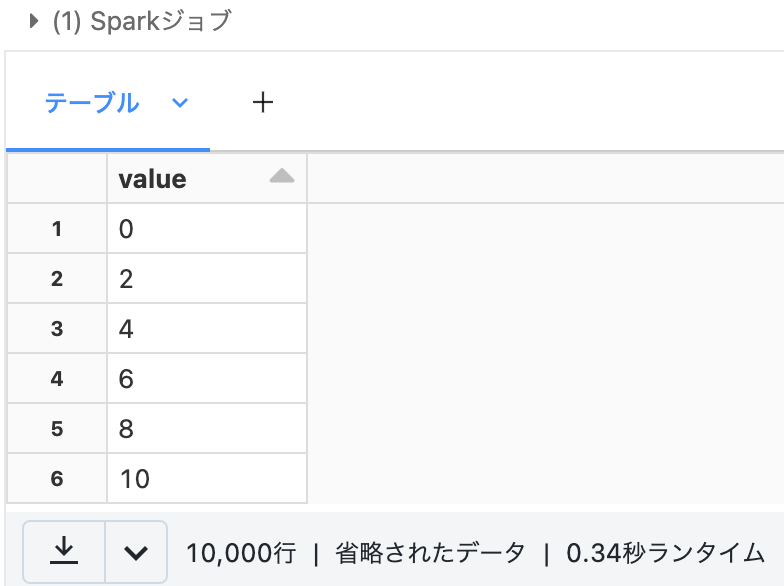
もう少し複雑な処理を行ってみます。ストレージに格納されているcsvファイルを読み込みます。readメソッドとフォーマット、オプションを指定してデータフレームに読み込みます。
dataPath = "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv"
diamonds = spark.read.format("csv")\
.option("header","true")\
.option("inferSchema", "true")\
.load(dataPath)
# inferSchemaはデータを読み込んで自動的にカラムの型を識別するオプションです。データを読み込む分のコストがかかります。
データを確認します。
display(diamonds)
ダイアモンドのデータです。
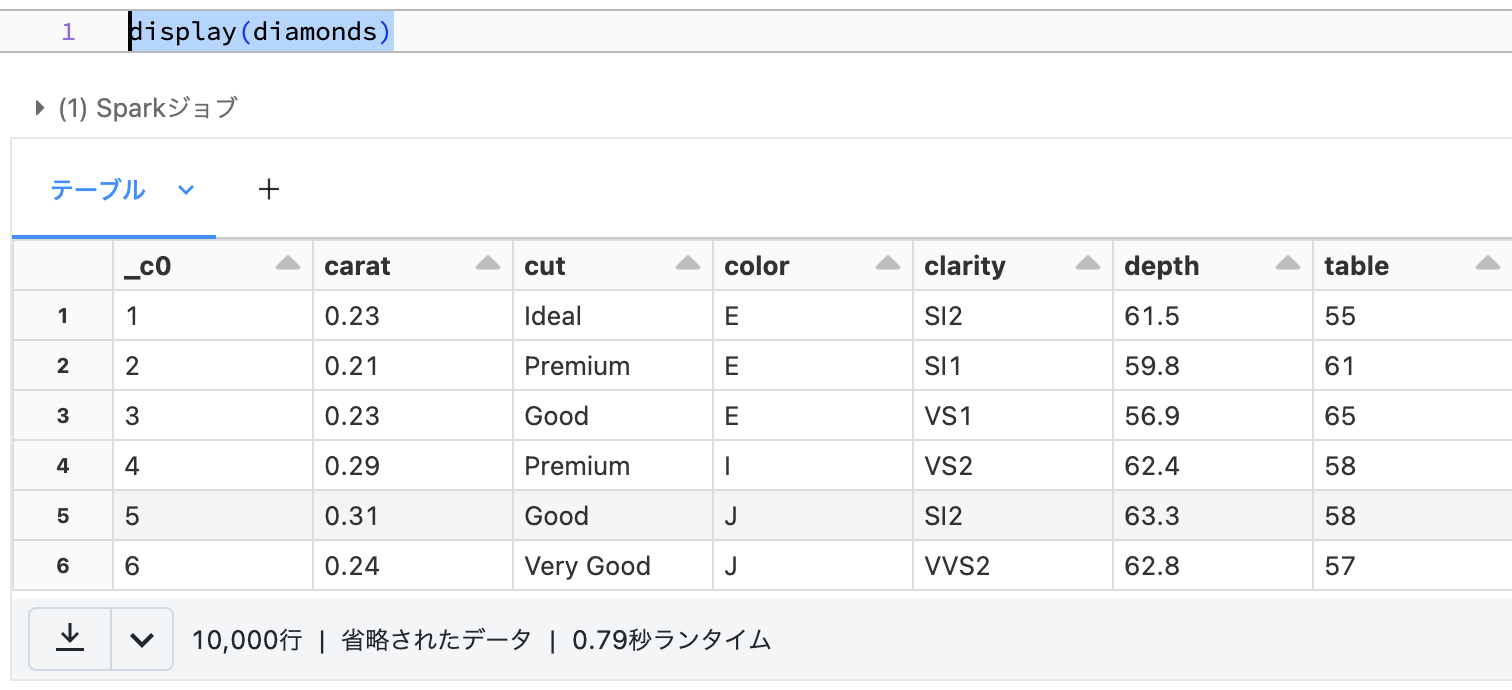
このデータに対して集計、joinを行います。groupByやjoinを使います。個人的にはpandasやRのdplyrと大差ないと思います。これらもトランスフォーメーションなので処理は実行されません。
df1 = diamonds.groupBy("cut", "color").avg("price") # シンプルなグルーピング
df2 = df1\
.join(diamonds, on='color', how='inner')\
.select("`avg(price)`", "carat")
# シンプルなjoin及び列の選択
アクションのcountを実行して処理を行います。
df2.count()
Out[11]: 269700
Pandas API on Spark
ここまではPythonのSpark APIであるpysparkを使ってきていますが、敷居が高いというのは否定できません。その場合には、pandas APIでSparkデータフレームを操作できるPandas API on Spark(旧Koalas)から入るのが良いかもしれません。
import numpy as np
import pandas as pd
import pyspark.pandas as ps
# Pandas API on Sparkのデータフレームの作成
kdf = ps.DataFrame({'A': np.random.rand(5),
'B': np.random.rand(5)})
pandasのAPIを用いながらSparkの並列処理を活用することができます。
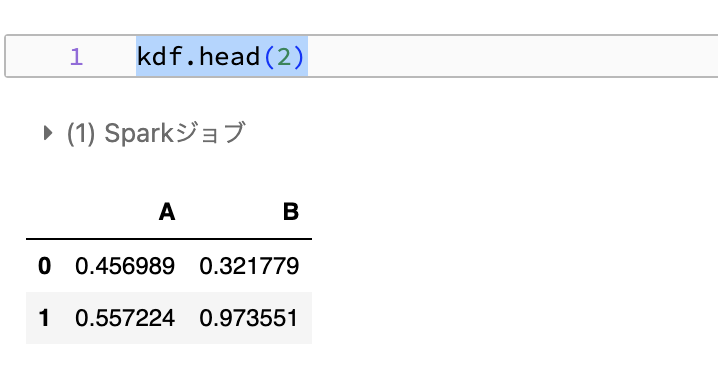
kdf.sort_index()

kdf.head(2)
ただし、注意点もありますのでこちらの記事も一読ください。
個人的には、大規模データを取り扱う際には基本はPySparkで処理を行い、pandasのメソッドが必要な際には、データを絞った上で明示的にセルを分けてpandasデータフレームに変換して処理を行い、Sparkデータフレームに戻すという方法を取っています。どのタイプのデータフレーム(pandas/Pandas API on Spark/Spark)を取り扱っているのかが混乱するので。
なぜ、DatabricksのSparkを使うのか?
Apache Sparkは完全にオープンソースなソフトウェアですが、なぜDatabricks上で使った方が良いのでしょうか?いくつかの理由があります。宣伝めいてすみません。

- Databricksに搭載されているSparkはクラウドやDelta Lakeに最適化されており、非常に高速かつ高いコスト効率を実現します。
- 機械学習や大規模データエンジニアリングを行う際にシームレスにSparkを活用することができ、生産性の向上が見込めます。
- Apache Sparkのオリジナルクリエーターが創業した企業がDatabricksであり、数多くのコミッターを抱えていることに加え、エキスパートのサポートを得ることができます。
大規模言語モデルの勃興など、大規模データを取り扱うケースが増えてきている中、すべてのデータをメモリに載せないと処理できないpandasではすぐに限界に直面することになると思います。Sparkに移行することで、水平スケールによる並列処理やインテリジェントな最適化の恩恵を受けられるようになり、分析や処理の幅も広がるかと思います。是非、ご活用を検討ください。イベントや勉強会なども開催していく予定です!
Sparkに興味がある方はこちらの記事もどうぞ。
- PySparkことはじめ
- Sparkを用いたサンフランシスコ消防署の通報データの分析
- 3つのApache Spark APIの物語:RDD対データフレーム、データセット
- SparkにおけるPandas API
- サンプルを通じたPandasとPySparkデータフレームの比較
- 可視化を通じたApache Sparkアプリケーションの理解
- DatabricksでApache Sparkコードを高速にデバッグする7つのTips