PythonからApache Sparkを操作する際に使用するAPIであるPySparkの基本的な使い方を説明します。
こちらの記事で説明しているノートブックはこちらとなります。
Apache Sparkとは
Apache Sparkとは、ビッグデータと機械学習のための非常に高速な分散処理フレームワークです。SparkはDatabricksの創業者たちによって開発されました。Databricksにおける分散処理はSparkによって行われます。
参考資料
PySparkとは
PySparkとは、Sparkを実行するためのPython APIです。Apache SparkとPythonのコラボレーションをサポートするためにリリースされました。開発者はPySparkを用いることで、Pythonからデータフレームを操作する形でSparkを活用することができます。
参考資料
- PySpark – Databricks
- Databricks Apache Sparkクイックスタート - Qiita
- Databricks Apache Sparkデータフレームチュートリアル - Qiita
- PySpark Documentation — PySpark 3.2.1 documentation
- Beginner’s Guide on Databricks: Spark Using Python & PySpark | by Christopher Lewis | Analytics Vidhya | Medium
- 【PySpark入門】第1弾 PySparkとは? - サーバーワークスエンジニアブログ
PySparkの基本的な使い方
データのロード
PySparkでデータをロードする際にはspark.readを使用します。formatの引数に読み込むデータのフォーマットを指定します。json、parquet、deltaなどが指定できます。読み込んだデータはSparkデータフレームとなります。
その前に、読み込むデータを以下のコマンドで確認します。こちらのデータは、アメリカの都市ごとの人口と売上のデータとなります。
%fs
ls dbfs:/databricks-datasets/samples/population-vs-price/

# データフレームにサンプルデータをロードします
df = spark.read.format("csv").option("header", True).load("/databricks-datasets/samples/population-vs-price/data_geo.csv")
データフレームを表示します。
df.show(20)
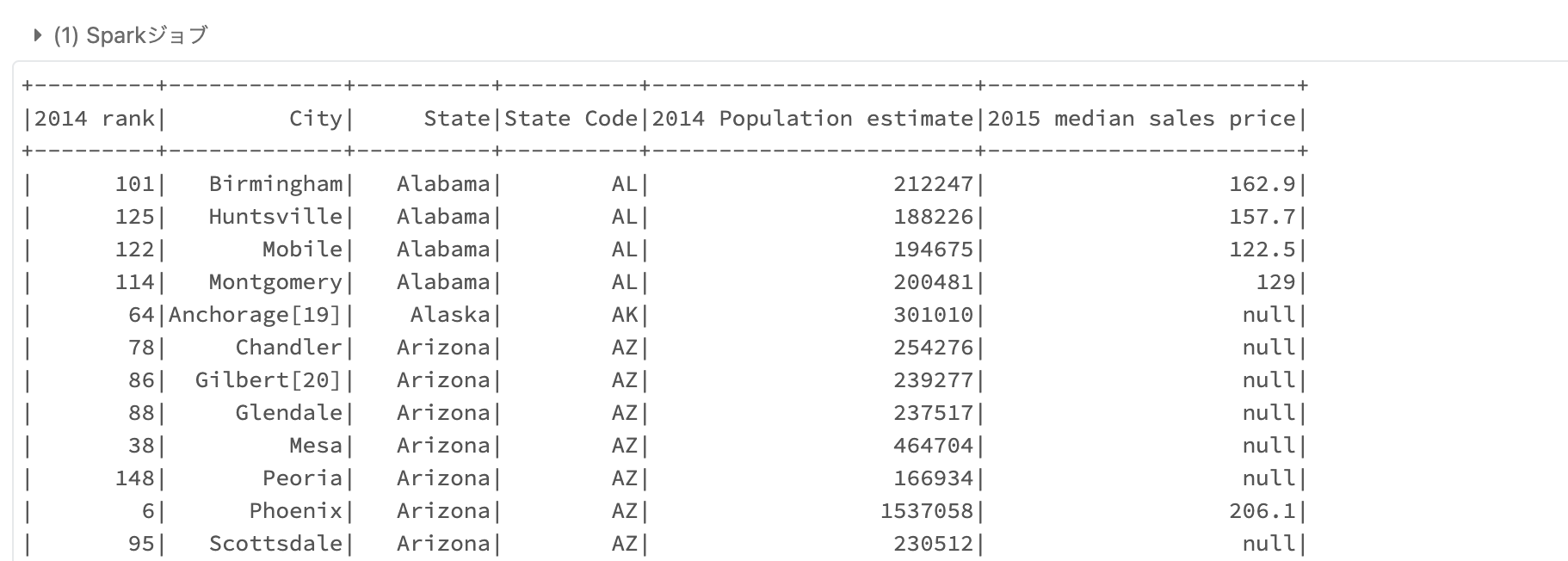
display関数を用いることで、よりグラフィカルに結果を表示、操作することができます。簡単にグラフを表示することもできます。
# Databricksでデータフレームを表示するにはdisplay関数を使うと便利です
display(df)
カラムの確認
df.columns

スキーマの確認
# データフレームのスキーマを表示
df.printSchema()

カラム名の変更
withColumnRenamedを使ってカラム名を変更します。
df2 = df.withColumnRenamed('2014 rank', '2014_rank')\
.withColumnRenamed('State Code', 'state_code')\
.withColumnRenamed('2014 Population estimate', '2014_pop_estimate')\
.withColumnRenamed('2015 median sales price', '2015_median_sales_price')
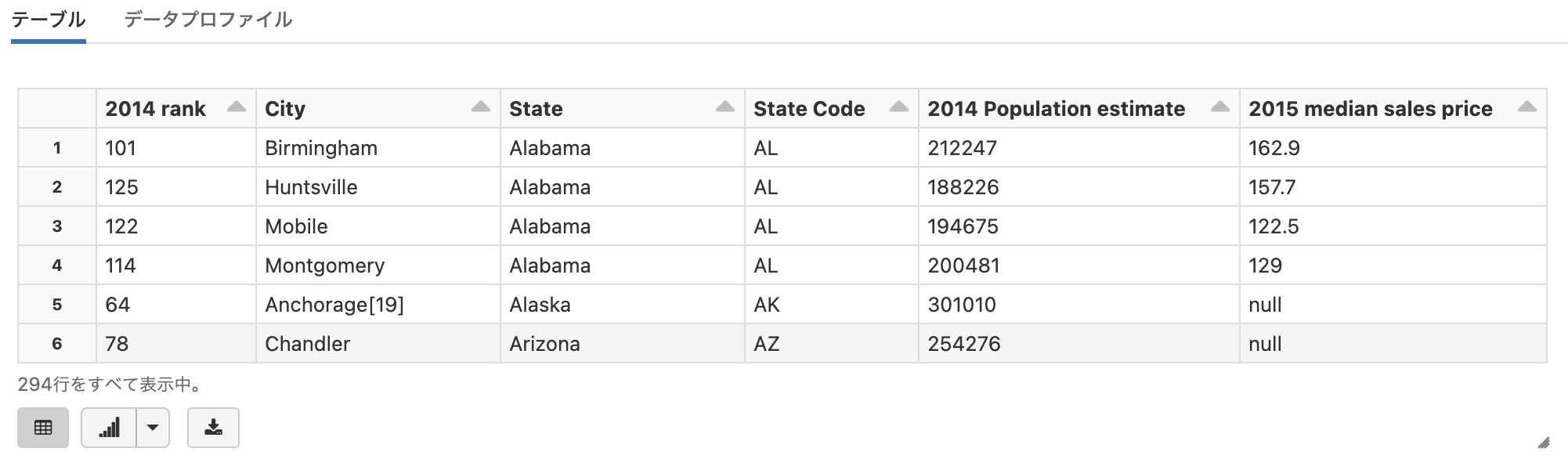
display(df2)

データ型の変換
- 既に存在しているデータフレームのカラムを指定するには、
col関数の引数にカラム名を指定します。 -
castにデータ型を指定してキャストします。 -
withColumnを用いて、キャストした後の値を持つカラムで更新します。
参考資料
df3 = df2.withColumn("2014_rank", col("2014_rank").cast(IntegerType()))\
.withColumn("2014_pop_estimate", col("2014_pop_estimate").cast(IntegerType()))\
.withColumn("2015_median_sales_price", col("2015_median_sales_price").cast(FloatType()))
display(df3)

データの操作
フィルタリング、ソート
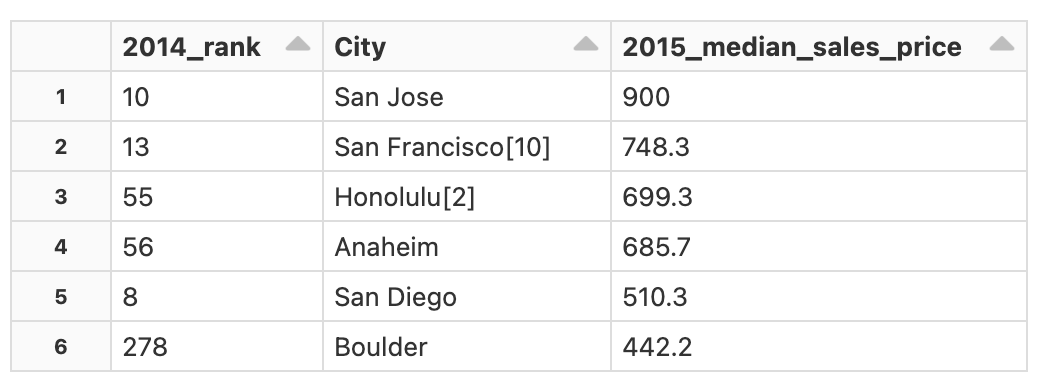
以下の例では、df3で2015_median_sales_priceが100より大きいレコードを2015_median_sales_priceの降順でソートし、カラム2014_rank, City, 2015_median_sales_priceを取得しています。
display(df3.select("2014_rank", "City", "2015_median_sales_price")\
.where("2015_median_sales_price > 100")\
.orderBy(col("2015_median_sales_price").desc()))
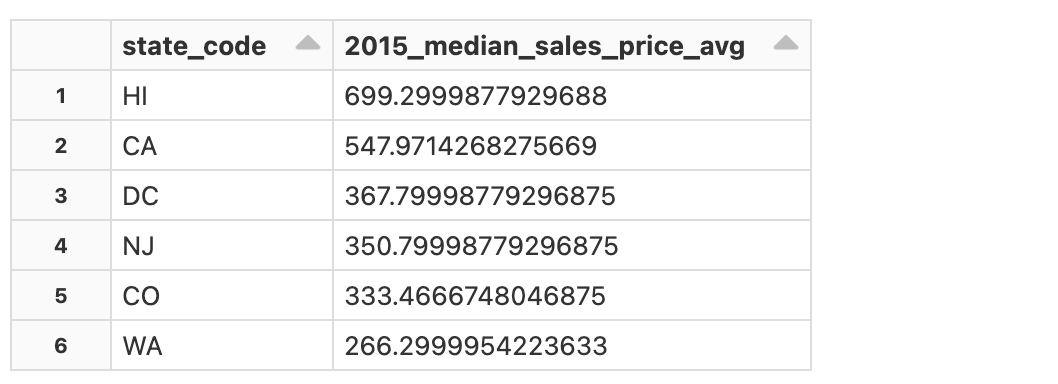
集計
以下の処理を行なっています。
-
state_codeでレコードをグルーピング - グループごとの
2015_median_sales_priceの平均値を計算 - 平均値降順でレコードを取得
display(df3.groupBy("state_code")\
.agg(avg("2015_median_sales_price").alias("2015_median_sales_price_avg"))
.orderBy(col("2015_median_sales_price_avg").desc()))
データの書き込み
ファイルシステムにデータフレームを永続化するには、spark.writeを使用します。
# Databricksユーザー名の取得
username_raw = dbutils.notebook.entry_point.getDbutils().notebook().getContext().tags().apply('user')
print(username)
# データの書き込み先、あとでクリーンアップします
tmp_file_path = f"/tmp/{username}/datacsv"
print(tmp_file_path)
# formatを指定しない場合、デフォルトのDelta形式で保存されます
df3.write.mode("overwrite").save(tmp_file_path)
# データフレームに保存したデータをロードします
df_new = spark.read.format("delta").load(tmp_file_path)
display(df_new)

クリーンアップ
# 上のセルで保存したファイルを削除しておきます
dbutils.fs.rm(tmp_file_path, True)
pandasとのやりとり
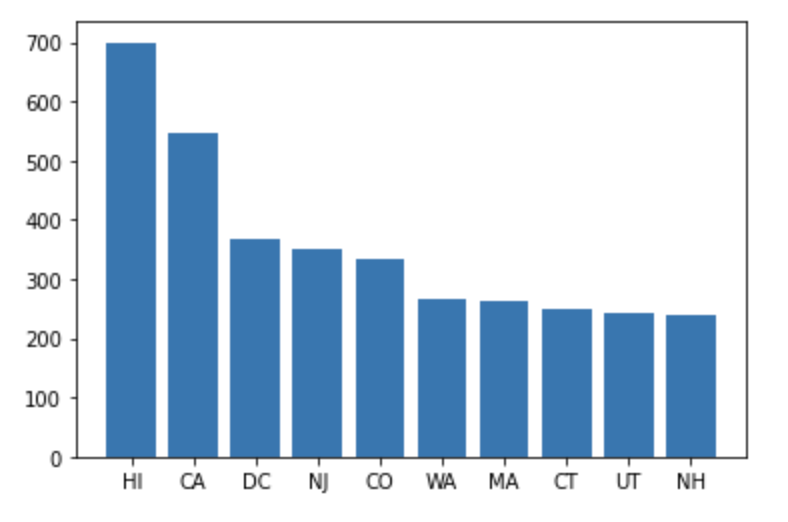
matplotlibで可視化したいなどpandas前提の処理を行う場合には、Sparkデータフレームをpandasデータフレームに変換します。
df4 = df3.groupBy("state_code")\
.agg(avg("2015_median_sales_price").alias("2015_median_sales_price_avg"))\
.orderBy(col("2015_median_sales_price_avg").desc()).limit(10)
import matplotlib.pyplot as plt
# pandasデータフレームに変換します
pdf = df4.toPandas()
# 棒グラフを描画します
plt.bar(pdf['state_code'], pdf['2015_median_sales_price_avg'], align="center")
plt.show()
pandasデータフレームをSparkデータフレームに変換することもできます。
# Sparkデータフレームへの変換
sdf = spark.createDataFrame(pdf)
display(sdf)
その他のAPI
PySpark以外のAPIと組み合わせてロジックを組み立てることも可能です。
Spark SQL
データフレームをテーブルあるいは一時ビューに登録することで、SQLを使用してデータを操作することができるようになります。
テーブルやビューは永続化されますが、一時ビューは永続化されず、クラスターが稼働している間のみ一時ビューを作成したセッションでのみ利用することができます。
# データフレームを一時ビューに登録します
df3.createOrReplaceTempView("pop_price")
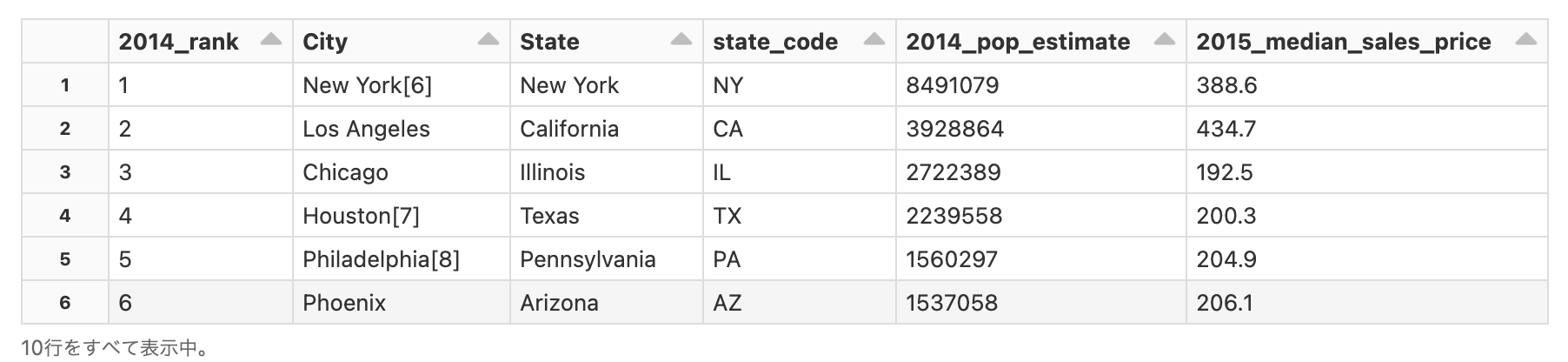
# '2014_rank' カラムに基づいて上位10位の市を参照します
top_10_results = spark.sql("""SELECT * FROM pop_price
WHERE 2014_rank <= 10
SORT BY 2014_rank ASC""")
display(top_10_results)
%sql
SELECT
*
FROM
pop_price
WHERE
2014_rank <= 10 SORT BY 2014_rank ASC
pandas API on Spark
pandas APIに慣れ親しんでいる方は、pandas API on Spark(旧Koalas)を活用することもできます。
参考資料
import pyspark.pandas as ps
psdf = sdf.to_pandas_on_spark() # pandas-on-Sparkデータフレーム
# pandasのお作法でカラムにアクセスします
psdf['state_code']