Databricksクイックスタートガイドのコンテンツです。
DataFrames tutorial | Databricks on AWS [2021/3/30時点]の翻訳です。
Apache SparkのデータフレームAPIは、一般的なデータ分析の課題を効率的に解決するための様々な関数(カラムの選択、フィルタリング、ジョイン、集計など)を提供します。データフレームと、Python/SQL/R/Scalaのカスタムコードをシームレスに組み合わせることも可能です。このチュートリアルモジュールでは以下を学びます。
モジュールで紹介したコードを含むサンプルノートブックを提供していますので、インポートして実行することができます。
要件
Databricks Apache Sparkクイックスタートもご一読ください。
サンプルデータの読み込み
データフレームによる作業をスタートする簡単な方法は、Databricksワークスペースの/databricks-datasetsフォルダーにあるDatabricksのデータセットを活用することです。都市の人口と住宅販売価格の中央値を比較したファイルにアクセスするには、/databricks-datasets/samples/population-vs-price/data_geo.csvファイルを読み込みます。
サンプルノートブックはSQLノートブック(デフォルト言語がSQL)なので、以下のいくかのコマンドでは、%pythonマジックコマンドを使用します。
%python
# Use the Spark CSV datasource with options specifying:
# - First line of file is a header
# - Automatically infer the schema of the data
data = spark.read.csv("/databricks-datasets/samples/population-vs-price/data_geo.csv", header="true", inferSchema="true")
data.cache() # Cache data for faster reuse
data = data.dropna() # drop rows with missing values
データフレームの参照
dataデータフレームを作成したので、take()のような標準的なSparkコマンドを用いて容易にデータにアクセスすることができます。例えば、dataデータフレームの最初の10行を参照したい場合には、data.take(10)コマンドを実行します。
%python
data.take(10)

データをテーブル形式で参照したい場合には、サードパーティのツールにデータをエクスポートするのではなく、Databricksのdisplay()コマンドを使用します。
%python
display(data)

SQLクエリーの実行
SQLクエリーを実行するには、dataデータフレームをテーブルか一時ビューに登録する必要があります。
%python
# Register table so it is accessible via SQL Context
data.createOrReplaceTempView("data_geo")
次に、新たなセルで、2015年の販売価格の中央値を表示するSQLクエリーを実行します。
%sql
select `State Code`, `2015 median sales price` from data_geo

あるいは、ワシントン州の人口推定値を取得します。
%sql
select City, `2014 Population estimate` from data_geo where `State Code` = 'WA';

データフレームの可視化
Databricksのdisplay()コマンドを使う別のメリットとして、様々な可視化手法を用いてデータを簡単に可視化できるという点が挙げられます。 の隣にある下向き矢印をクリックすることで、可視化のタイプの一覧を表示できます。
の隣にある下向き矢印をクリックすることで、可視化のタイプの一覧を表示できます。
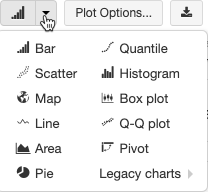
上で実行した販売価格のクエリーの結果を地図で可視化するために、Mapアイコンをクリックします。
