How to Execute Pandas Workloads in a Distributed Manner With Apache Spark - The Databricks Blogの翻訳です。
来たるApache Spark™ 3.2リリースの一部としてpandas APIを発表できることを嬉しく思います。pandasはパワフルかつ柔軟性のあるライブラリであり、データサイエンスライブラリの標準として急速に成長しました。今では、pandasのユーザーは既存Sparkクラスターでpandas APIを活用することができます。
数年前、我々はSpark上でpandas DataFrame APIを実装するオープンソースプロジェクトKoalasを立ち上げ、これはデータサイエンティストの皆様に広く受け入れられました。最近、Project Zen(Data + AI Summit 2021のProject Zen: Making Data Science Easier in PySparkもご覧ください)の一環としてSPIP: Support pandas API layer on PySparkによって、Koalasは正式にPySparkに統合されました。
pandasのユーザーは来たるSpark 3.2リリースでは、1行の変更のみで今のワークロードをスケールさせることができるようになります。

この記事では、Spark 3.2におけるpandas APIサポートを要約し、特筆すべき機能、変更、ロードマップをハイライトします。
シングルマシンの向こうのスケーラビリティ
pandasにおける既知の制限の一つは、シングルマシンの処理であるために、データボリュームに対して線形にスケールしないというものです。例えば、pandasにおいて、シングルマシンで利用できるメモリーよりも大きいデータセットを読み込もうとすると、アウトオブメモリーで処理が失敗します。
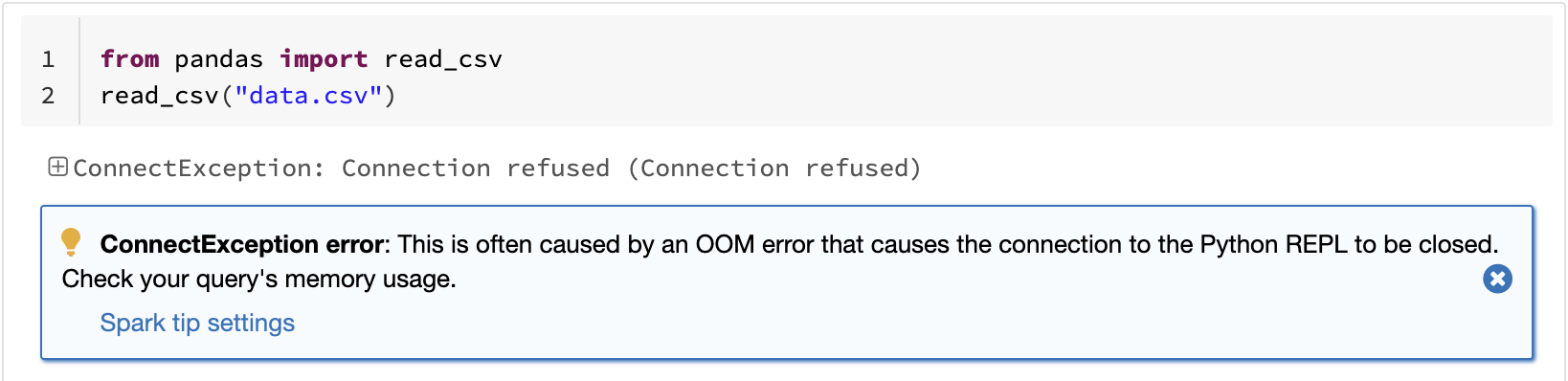
pandas: 大規模CSVの読み込みによるアウトオブメモリー
Sparkにおけるpandas APIはこの制限を乗り越え、Sparkを活用することでユーザーは大規模データセットを取り扱えるようになります。

Sparkにおけるpandas APIは大規模クラスターノードにおいても適切にスケールします。以下のグラフでは、異なるサイズのクラスターにおいて15TBのParquetデータセットを分析した際の性能を示しています。クラスターのそれぞれのマシンは8個のvCPU、61GBメモリーを搭載しています。
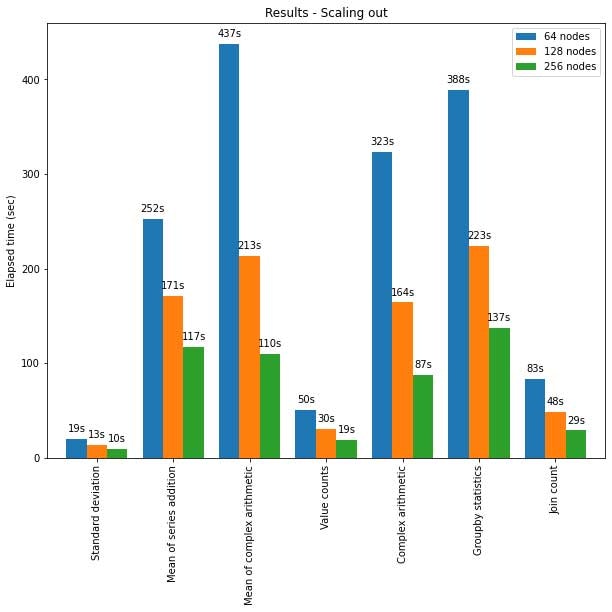
Sparkにおけるpandas APIのスケールアウト
テストにおいて、Sparkにおけるpandas APIの分散実行はほぼ線形にスケールしました。クラスターのマシンの数が倍になると、処理時間は半分に減少します。シンブルマシンと比較してスピードアップの度合いは劇的なものになります。例えば、*標準偏差(Standard deviation)*のベンチマークにおいては、256台のマシンのクラスターは、シングルマシンのほぼ250倍のデータを同じ時間で処理することができています(それぞれのマシンは8個のvCPU、61GBメモリーを搭載しています)。
| シングルマシン | 256台のクラスター | |
|---|---|---|
| Parquetデータセット | 60GB | 60GB x 250(15TB) |
| 標準偏差の処理時間(秒) | 12s | 10s |
最適化されたシングルマシンのパフォーマンス
Sparkにおけるpandas APIは、Sparkエンジンの最適化によって、シングルマシンにおいても多くのケースでpandasの性能を上回ります。以下のグラフはシングルマシンで130GBのCSVデータセットに対して処理を行った際のpandasの性能とSparkのpandas APIの性能を比較したものです。
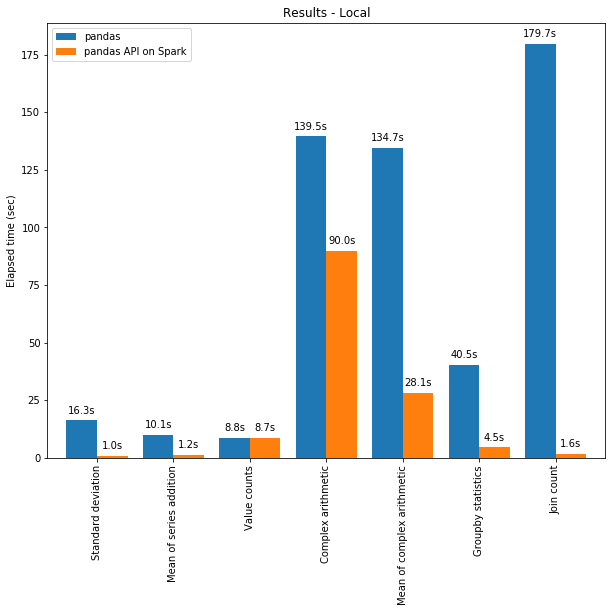
pandas vs. Sparkのpandas API
マルチスレッド処理とSpark SQLのCatalyst Optimizerの両方が性能の最適化に貢献しています。例えば、Join countオペレーションはwhole-stageコード生成によって、4倍程度高速になります。コード生成なしで5.9秒、コード生成ありで1.6秒になります。
Sparkは特に処理を連鎖させる際に優位となります。pandasにおいては、ステップごとに全てのデータをメモリにロードする傾向がある一方、Catalystクエリーオプティマイザは、賢くデータをスキップするために、フィルタリング処理を認識し、ディスクベースのJOINを適用することができます。
フィルタリングされた二つのデータフレームをJOINし、JOINされたデータフレームの平均を計算するクエリーを考えてみます。Sparkのpandas APIは4.5秒で処理を完了しますが、以下のようにpandasにおいてはアウトオブメモリー(OOM)エラーで失敗します。
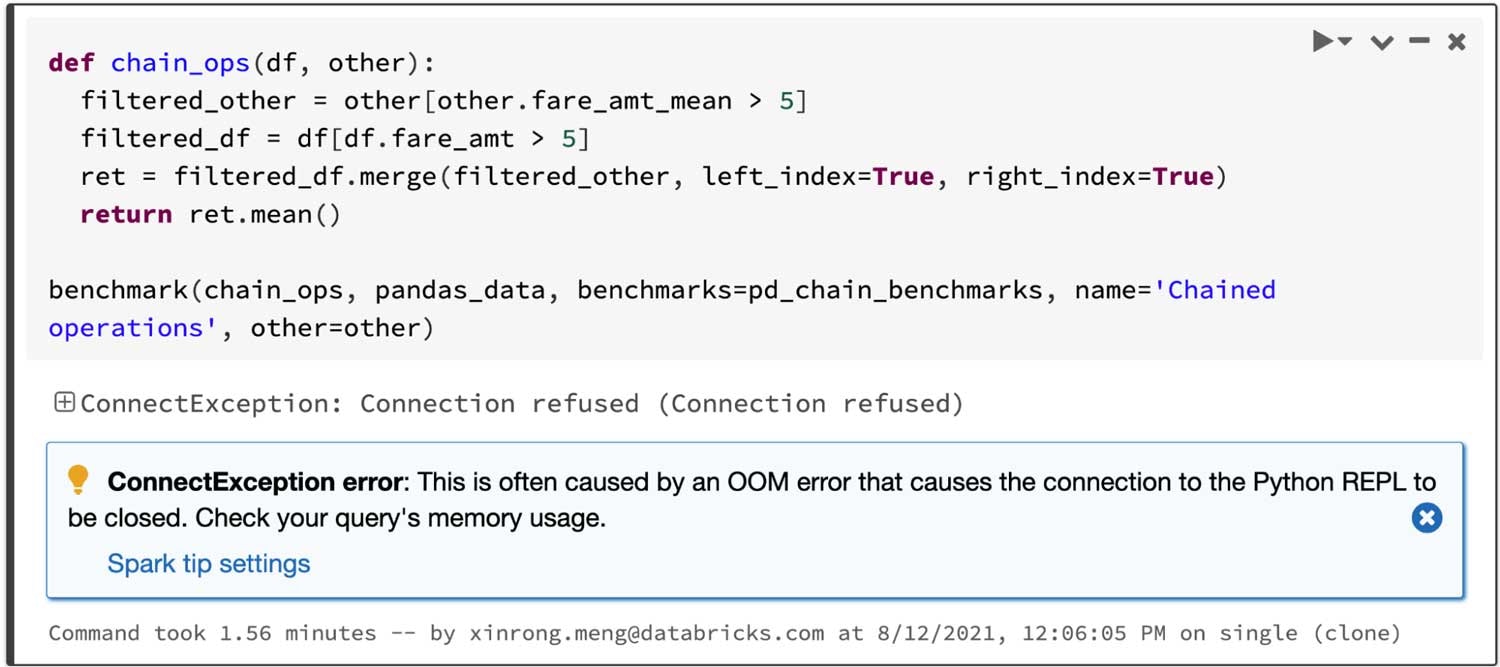
pandas: オペレーションの連鎖でアウトオブメモリーに
インタラクティブなデータの可視化
pandasは、静的なプロットチャートを提供するmatplotlibをデフォルトで使用します。例えば、以下のコードは静的なチャートを生成します。
# Area
pandas.DataFrame(
np.random.rand(100, 4), columns=list("abcd")).plot.area()
一方で、Sparkのpandas APIは、インタラクティブなチャートを提供するplotlyをデフォルトで使用します。例えば、これによってユーザーはインタラクティブにズームイン、ズームアウトが行えます。プロットのタイプに基づき、Sparkのpandas APIはインタラクティブなチャートを生成する際、内部でベストな計算実行方法を自動で決定します。
# Area
pyspark.pandas.DataFrame(
np.random.rand(100, 4), columns=list("abcd")).plot.area()
Sparkにおける統合分析機能の活用
pandasはバッチ処理によるPythonデータサイエンス向けに設計されていますが、SparkはSQL、ストリーミング処理、機械学習を含む統合分析向けに設計されています。これらのギャップを埋めるために、Sparkのpandas APIは以下のように、上級ユーザーがSparkエンジンを活用できるように異なる手段を提供しています。
- 以下のように、Sparkの最適化されたSQLエンジンを用いて、SQLでデータを直接クエリーします。
>>> import pandas as pd
>>> import pyspark.pandas as ps
>>> pdf = pd.DataFrame({"a": [1, 3, 5]}) # pandas DataFrame
>>> sdf = spark.createDataFrame(pdf) # PySpark DataFrame
>>> psdf = sdf.to_pandas_on_spark() # pandas-on-Spark DataFrame
>>> # Query via SQL
... ps.sql("SELECT count(*) as num FROM {psdf}")
- Pythonオブジェクトと自然にやり取りするために、文字列を内挿する文法もサポートしています。
>>> pred = range(4)
>>> # String interpolation with Python instances
... ps.sql("SELECT * from {psdf} WHERE a IN {pred}")
- Sparkのpandas APIはストリーミング処理もサポートしています。
>>> def func(sdf, _):
... # pandas-on-Spark DataFrame
... psdf = sdf.to_pandas_on_spark()
... psdf.describe()
...
>>> spark.readStream.format(
... "kafka").load().writeStream.foreachBatch(func).start()
- Sparkのスケーラブルな機械学習ライブラリを容易に呼び出すことも可能です。
>>> from pyspark.ml.feature import StringIndexer
>>> sdf = psdf.to_spark() # PySpark DataFrame
>>> indexer = StringIndexer(
... inputCol="category", outputCol="categoryIndex")
>>> indexed = indexer.fit(sdf).transform(sdf)
>>> indexed.show()
PySparkとSparkのpandas APIの相互運用性に関しては、こちらの記事もご覧ください。
次に来るのは?
次のSparkリリースに向けて、ロードマップでは以下にフォーカスしています。
- 更なるタイプヒント Sparkのpandas APIのコードは現状部分的に型付けされており、静的分析とオートコンプリートを可能にしています。将来的には、コード全てが完全に型付けされます。
- パフォーマンス改善 Sparkのpandas APIには性能改善の余地がいくつかあります。これらは、エンジンとSQLオプティマイザをより密連携させることで改善することができます。
- 安定性 NaNやNAのような欠損値において、例外的なケースで異なる振る舞いをする場合があるなど、修正が必要な箇所が存在しています。さらに、Sparkのpandas APIはこれらのケースにおいて最新バージョンの挙動に従うようにする予定です。
- APIカバレッジの強化 Sparkのpandas APIによるpandas APIのカバレッジは83%に到達しており、さらに増加し続けています。現状のターゲットは90%です。
バグや必要とする機能の欠如に直面した場合には、問題をファイルしてください。もちろん、コミュニティへの貢献も歓迎しています。
使い始めてみる
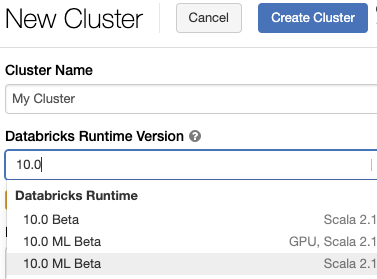
Databricks Runtime 10.0(beta)
Databricks Runtime 10.0はデフォルトでは表示されません(2021/10/10時点)。上のようにDatabricks Runtime Versionで「10.0」と入力してください。
Databricks Runtime 10.0 Beta(Apache Spark 3.2)でSparkのpandas APIを試してみたいのであれば、Databricksコミュニティエディション、あるいは、フリートライアルにサインアップしてください。