7 Tips to Debug Apache Spark Code Faster with Databricks - The Databricks Blogの翻訳です。
著者であるVida HaはDatabricksのリードソリューションアーキテクトです。彼女は、Google、Square、Databricksにおいてビッグデータアプリケーション構築に対する10年以上の経験を持っています。彼女はApache Sparkの初期ユーザーであり、Databricksのお客様がプロダクションアプリケーションを構築するのを2年以上も支援し続けています。
2016年の記事です。
完璧な世界においては、我々は完璧なApache Sparkコードを記述し、常にすべてがうまく動きます。そうですよね?冗談です。実際には、大規模データセットを取り扱うのはそんなに簡単なことではないことを我々は知っています。あなたのコードに対して、極端なケースを突き付けるデータポイントがまず間違いなく存在します。以下では、あなたのSparkプログラムをデバッグする際のtipsをご紹介します。
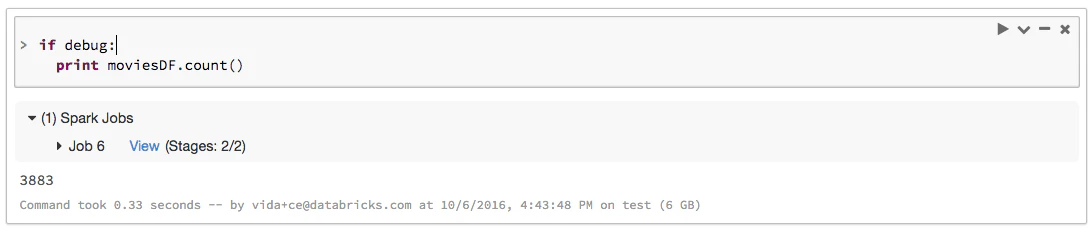
Tip 1: 中間結果のRDD/データフレームに対してアクションを実行するためにcount()を使用する
Sparkが必要があるまでは計算しないようにする遅延計算モデルを活用しているのは素晴らしいことですが、あなたがエラーに直面した際にエラーがあなたのコードのどこに発生したのかが分かりにくいという課題にも繋がります。このため、中間結果のRDD/データフレームを変数として格納するようにコードを構成したくなるでしょう。デバッグを行う際には、どのステージでエラーが起きたのかを確認するために、RDD/データフレームに対してcount()をコールすべきです。これは、エラーに対するtipであるだけではなく、Sparkジョブを最適化する際にも有効です。それぞれのステージの処理時間を計測でき、最適化を行うことができます。
Tip 2: 不適切な入力に対処する
大規模データセットを取り扱っている際、きちんと整形されていない、あるいは期待通りではない不適切な入力データに直面する場合があります。この場合、ユースケース、そして、不適切な入力データを削除するのか、修正・回復を試みるのか、なぜ、入力データが不適切であるのかを調査するのかを、あらかじめ決めておくことをお勧めします。
適切な入力データポイントあるいは(詳細を調査し、デバッグする際には)不適切な入力データポイントのみを取得する際には、filterコマンドが有効です。入力データを修正、あるいは修正できず削除したい場合には、これらを実現するためにflatMap()オペレーションを行うのがお勧めです。

Tip 3: Databricksノートブックのデバッグツールを活用する
Databricksノートブックは、Sparkコードの開発、デバッグにおいて最も効率的なツールです。コードをJARにコンパイルし、Sparkクラスターにsubmitする際、あなたの全体のデータパイプラインはある種のブラックボックスとなり、繰り返し作業が遅くなります。ノートブックを用いることで、データパイプラインにおいて、バグのある、あるいは遅い箇所を分離し、発見できるようになり、クイックに修正が行えるようになります。Databricksにおいては、皆様のデバッグがより容易になるように、様々なビルトインの機能を提供しています。
コメント
会社の他のユーザーがあなたのコードにコメントし、改善を提案することができます。ノートブック上で直接コードレビューを行うことも可能ですし、単にコメントを残すこともできます。

バージョン管理
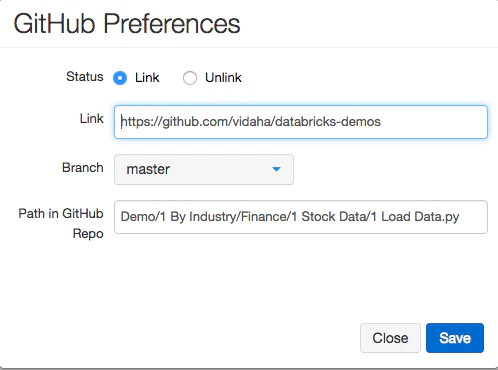
Databricksノートブックには2つの異なるタイプのバージョン管理が存在します。1つ目が、GitHubと直接ノートブックを同期する従来型の方法です。
2つ目の方法はノートブックの以前の状態を参照できる改訂履歴であり、これによりクリック一つで過去のバージョンに巻き戻すことができます。
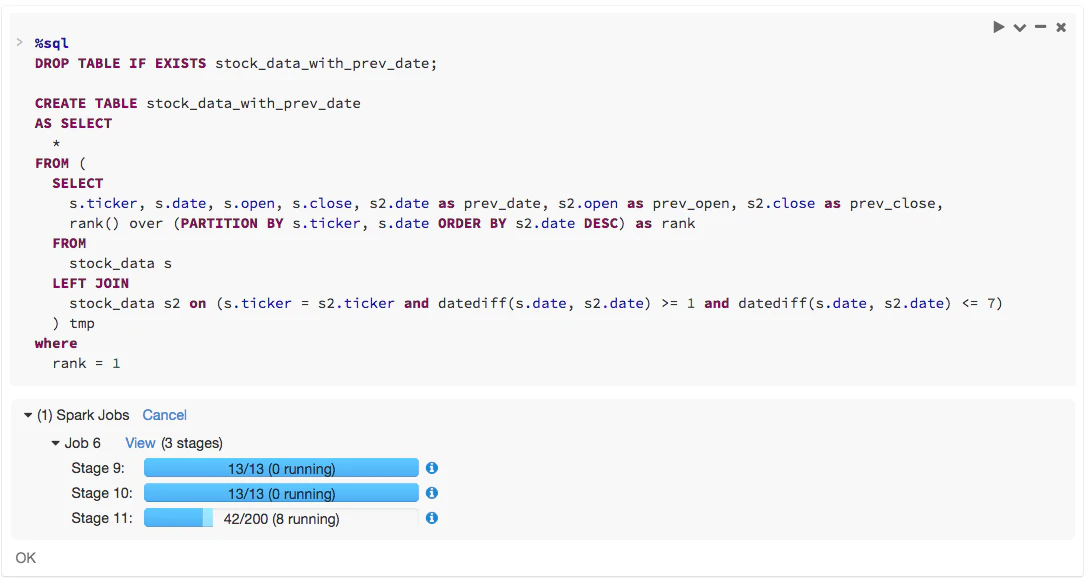
パーティション数の要約ビュー
Sparkジョブを実行する際、ジョブやジョブの実行で必要となるステージ、そしてどこまで進んでいるのかをドリルダウンすることができます。以下のワークロードでは、Stage 11では200パーティションが存在し、42が完了、8が現在実行中であることがわかります。このステージが本当に遅い場合には、より大規模なSparkクラスターによって、より多くのパーティションを一度に実行することができ、全体的なジョブの実行を高速化することができます。
Spark UIのポップアウト
ジョブの上にある"View"リンクをクリックすることで、デバッグできるようにSpark UIがポップアップします。Tip 4では、Spark UIをカバーします。この機能の詳細に関してはこちらの記事を参照ください。
Tip 4: Databricks Spark UIでどのようにデバッグするのかを理解する
Spark UIにはSparkジョブをデバッグする際に利用できる様々な情報が含まれています。数多くの素晴らしいビジュアライゼーションがあります。これらの機能の詳細に関しては、こちらの記事をご覧ください。
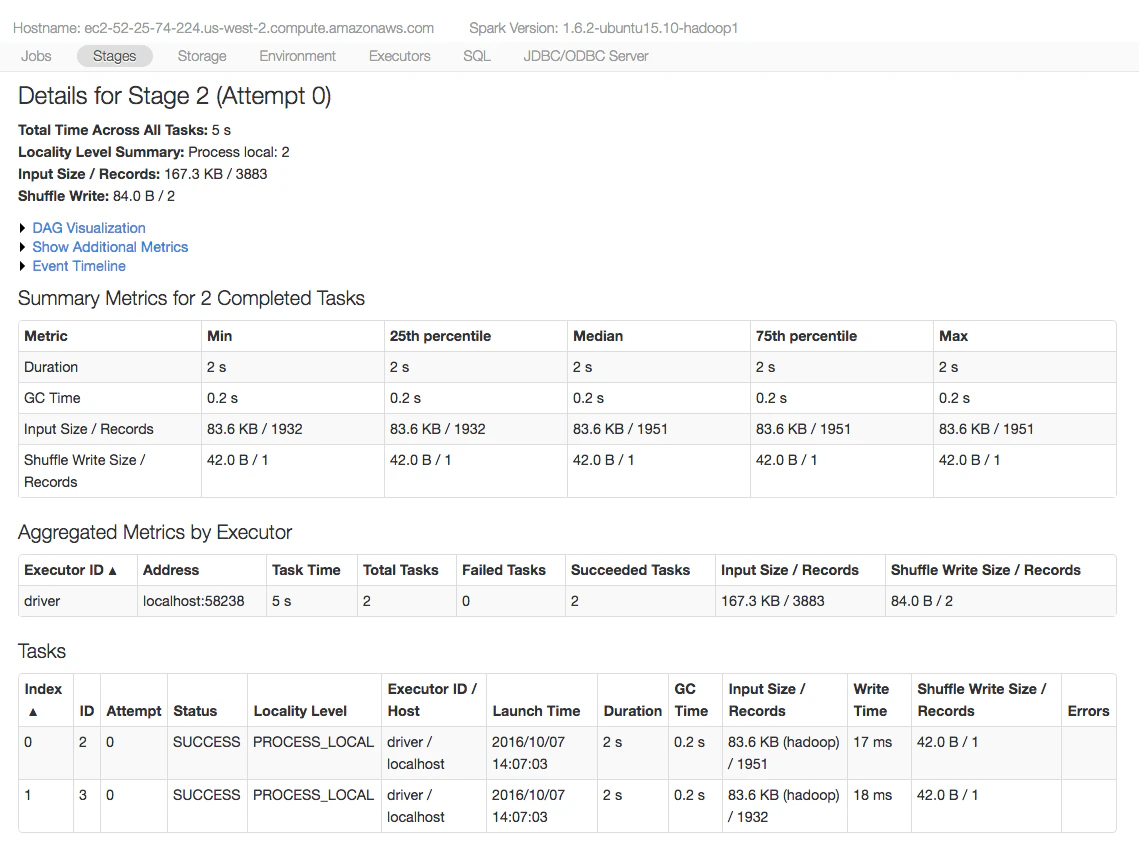
全体的に、私はSpark UIは直感的に使用できると考えています。ジョブが失敗した際、ユーザーはエラーをスローしたノートブックのセルのみを見るというケースを私は見ています。大量のタスクを持つSparkステージがあった場合、単一のタスクが失敗続けるのであれば、ジョブの全ては失敗します。このため、taskページをドリルダウンし、ステータスでそー年、失敗したタスクの"Errors"カラムを確認することをお勧めします。そこには詳細なエラーメッセージがあります。以下にtaskページを示します。なお、こちらのステージは処理に成功しています。
Tip 5: Sparkジョブを徐々に実際の大規模データセットにスケールアップする
本当に大規模なデータセットを取り扱っており、エラーに遭遇した場合には、まず初めにデータセットの一部を用いたデバッグ・テストを行いたくなるかもしれません。コードがスムーズに動くようになった際には、完全なデータセットに戻ってきます。小規模のデータセットを持つことで、エラーの再現がしやすくなり、データパイプラインの様々なステージでデータセットの特性を理解することができます。しかし、注意してください。より大規模なデータセットに対して処理を実行するにつれて、間違いなく、より多くの問題に直面することになります。小規模なデータセットでエラーを再現できるのであれば、完全なデータセットを使っている時よりも容易にエラーを修正できるようになるのがせめてもの救いです。
Tip 6: Databricksジョブを利用して、Sparkジョブのエラー、遅延を再現する
あらゆるバグと同じように、信頼性を持ってバグを再現できることが、バグを修正する労力の半分を占めているとも言えます。このため、Databricksジョブの機能を用いて、遅いSparkジョブあるいはエラーを再現することをお勧めします。これによって、バグや遅延の発生条件を捕捉し、バグの不確実性を理解することができます。また、検証するために、個々のセルの実行時間、個々のセルのアウトプット、エラ〜メッセージなど全てのアウトプットを捕捉することもできます。また、ジョブ機能にはhistory UIがあるので、クラスターがシャットダウンされた後であっても、あらゆるログファイル、Spark UIを参照することができます。また、異なるバージョンのSpark、インスタンスタイプ、クラスターサイズ、コードの書き方などがどのようにSparkジョブに影響を与えているのかを、制御された環境下で実験を行うことができます。
Tip 7: データセットのパーティショニングを検証する
Sparkはデータに対して適切なデフォルト値を選択しますが、Sparkジョブがアウトオブメモリーを起こしたり、処理が遅い場合には、不適切なパーティショニングが原因になっているかもしれません。私の場合、異なるパーティションサイズがジョブにどのような影響を与えるのかを確認するところから着手します。
データセットが大規模の場合には、ジョブがより高い並列性を発揮できるように、より大きな数に再パーティションすることができます。このことを示すい良いインジケーターは、Spark UIにおいてタスクの数は多くないが、それぞれのタスクが完了するまでに長い時間がかかっているというものです。

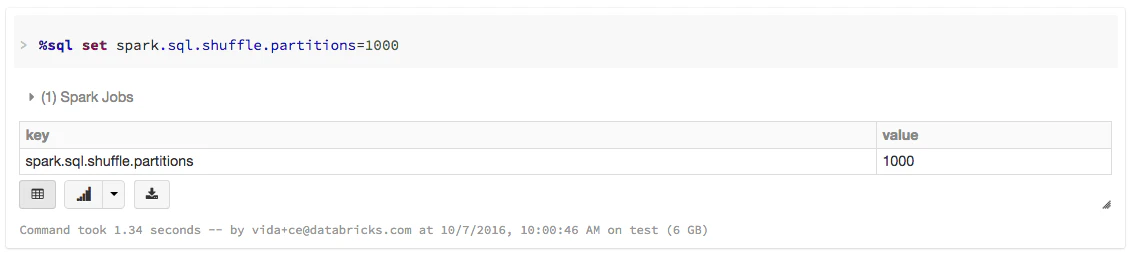
Spark SQLを使っている場合には、spark.sql.shuffle.partitionsを設定することで、シャッフルステップにおけるパーティション数を設定することができます。
次のステップ
この記事は、DatabricksでApache Sparkコードをどのようにデバッグし、最適化するのかを説明するブログシリーズの最初の記事です。今後の記事も楽しみにしていてください。