ノートブックギャラリーで公開されているAnalysis of the San Fransisco fire calls with Sparkをウォークスルーする内容となっています。
翻訳版ノートブックはこちらとなります。
このノートブックは書籍Learning Spark 2nd Editionの第3章のエンドツーエンドのサンプルを示すものであり、San Francisco Fire Department Calls データセットに対する一般的な分析パターンとオペレーションのために、どのようにデータフレームとSpark SQLを用いるのかを説明します。また、分析のためにどのようにETLやデータの検証、データのクエリーを行うのかをデモします。さらに、インメモリのSparkデータフレームをどのようにParquetファイルとして保存するのか、SparkがサポートするParquetデータソースとしてどのように読み込むのかを説明します。
データの確認
%fs ls /databricks-datasets/learning-spark-v2/sf-fire/sf-fire-calls.csv

from pyspark.sql.types import *
from pyspark.sql.functions import *
sf_fire_file = "/databricks-datasets/learning-spark-v2/sf-fire/sf-fire-calls.csv"
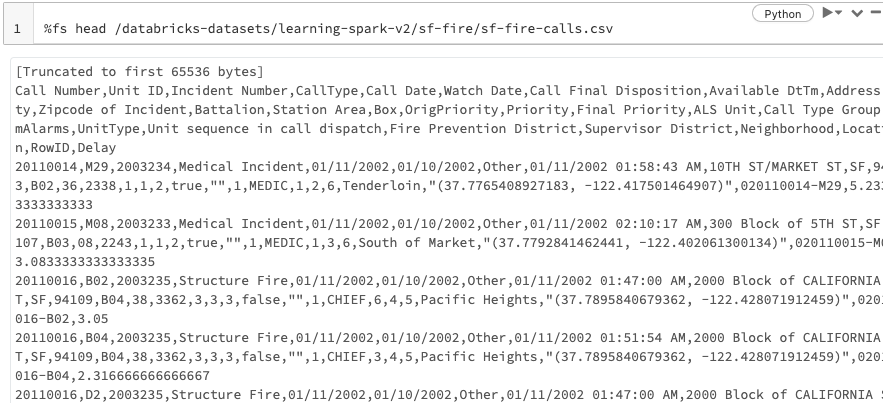
%fs head /databricks-datasets/learning-spark-v2/sf-fire/sf-fire-calls.csv
スキーマの定義
ファイルには400万レコードが含まれているのでスキーマを定義します。大規模ファイルにおけるスキーマ推定には大きなコストが必要となります。
fire_schema = StructType([StructField('CallNumber', IntegerType(), True),
StructField('UnitID', StringType(), True),
StructField('IncidentNumber', IntegerType(), True),
StructField('CallType', StringType(), True),
StructField('CallDate', StringType(), True),
StructField('WatchDate', StringType(), True),
StructField('CallFinalDisposition', StringType(), True),
StructField('AvailableDtTm', StringType(), True),
StructField('Address', StringType(), True),
StructField('City', StringType(), True),
StructField('Zipcode', IntegerType(), True),
StructField('Battalion', StringType(), True),
StructField('StationArea', StringType(), True),
StructField('Box', StringType(), True),
StructField('OriginalPriority', StringType(), True),
StructField('Priority', StringType(), True),
StructField('FinalPriority', IntegerType(), True),
StructField('ALSUnit', BooleanType(), True),
StructField('CallTypeGroup', StringType(), True),
StructField('NumAlarms', IntegerType(), True),
StructField('UnitType', StringType(), True),
StructField('UnitSequenceInCallDispatch', IntegerType(), True),
StructField('FirePreventionDistrict', StringType(), True),
StructField('SupervisorDistrict', StringType(), True),
StructField('Neighborhood', StringType(), True),
StructField('Location', StringType(), True),
StructField('RowID', StringType(), True),
StructField('Delay', FloatType(), True)])
データの読み込み
fire_df = spark.read.csv(sf_fire_file, header=True, schema=fire_schema)
データに対して複数のオペレーションを実行するので、データフレームをキャッシュします。
fire_df.cache()
fire_df.count()
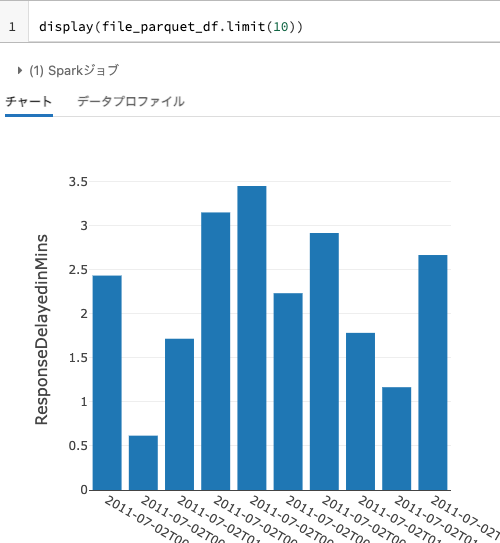
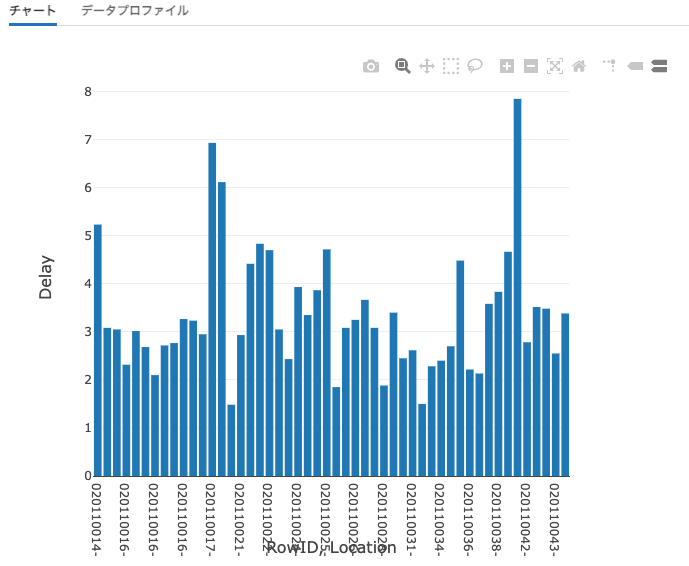
データフレームの最初の50レコードを表示します。以下ではグラフが設定されているので、呼び出しごとの遅延時間が棒グラフで表示されます。
display(fire_df.limit(50))
フィルタリング
Call Typeの"Medical Incident"を除外します。
データフレームに対するfilter()とwhere()メソッドは同じものであることに注意してください。引数のタイプに関してはドキュメントをチェックしてください。
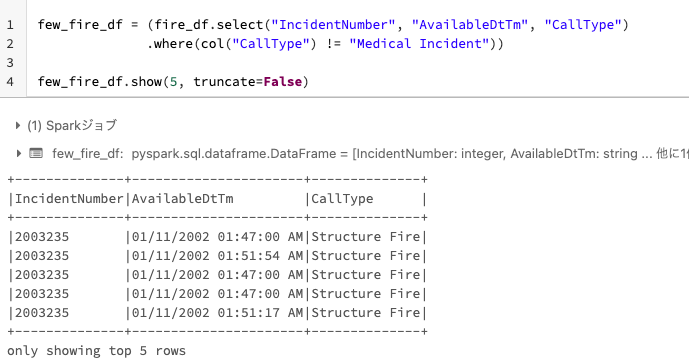
few_fire_df = (fire_df.select("IncidentNumber", "AvailableDtTm", "CallType")
.where(col("CallType") != "Medical Incident"))
few_fire_df.show(5, truncate=False)
Q-1) 消防署に対して何種類の呼び出しの電話がありましたか?
念のために、カラムに含まれる"null"文字列はカウントしないようにしましょう。
fire_df.select("CallType").where(col("CallType").isNotNull()).distinct().count()

Q-2) 消防署に対してどのようなタイプの呼び出しがありましたか?
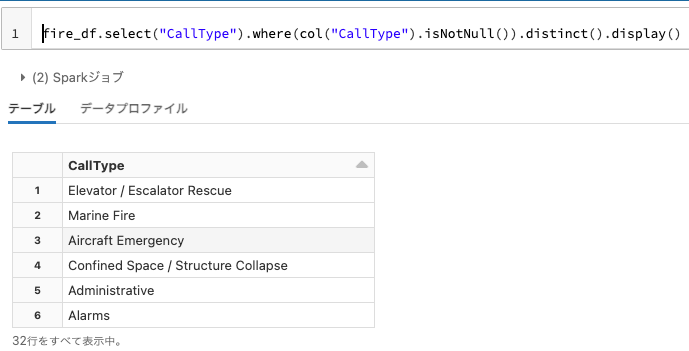
これらがSF Fire Departmentに対する全ての呼び出しタイプとなります。
fire_df.select("CallType").where(col("CallType").isNotNull()).distinct().show(10, False)

display()メソッドを使用することもできます。
fire_df.select("CallType").where(col("CallType").isNotNull()).distinct().display()
Q-3) 遅延時間が5分以上の全ての応答を見つけ出してください
- カラム名
DelayをReponseDelayedinMinsに変更します。 - 新たなデータフレームを返却します。
- 出火地点への反応時間が5分以上遅延した全ての電話を探し出します。
new_fire_df = fire_df.withColumnRenamed("Delay", "ResponseDelayedinMins")
new_fire_df.select("ResponseDelayedinMins").where(col("ResponseDelayedinMins") > 5).show(5, False)

ETL(Extract/Transform/Load)
いくつかのETL処理をやってみましょう:
- 後で時間に基づくクエリーを行えるように、文字列の日付をSparkのTimestampデータ型に変換します。
- 変換された結果が返却されます。
- 新たなデータフレームをキャッシュします。
fire_ts_df = (new_fire_df
.withColumn("IncidentDate", to_timestamp(col("CallDate"), "MM/dd/yyyy")).drop("CallDate")
.withColumn("OnWatchDate", to_timestamp(col("WatchDate"), "MM/dd/yyyy")).drop("WatchDate")
.withColumn("AvailableDtTS", to_timestamp(col("AvailableDtTm"), "MM/dd/yyyy hh:mm:ss a")).drop("AvailableDtTm"))
fire_ts_df.cache()
fire_ts_df.columns
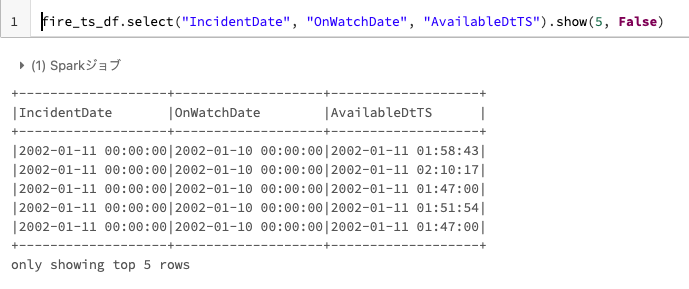
変換されたカラムがSpark Timestamp型であることを確認します。
fire_ts_df.select("IncidentDate", "OnWatchDate", "AvailableDtTS").show(5, False)
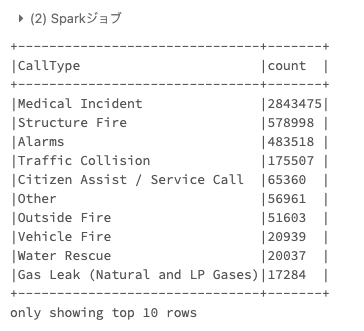
Q-4) 最も多い呼び出しタイプは何ですか?
降順で並び替えをしましょう。
(fire_ts_df
.select("CallType").where(col("CallType").isNotNull())
.groupBy("CallType")
.count()
.orderBy("count", ascending=False)
.show(n=10, truncate=False))
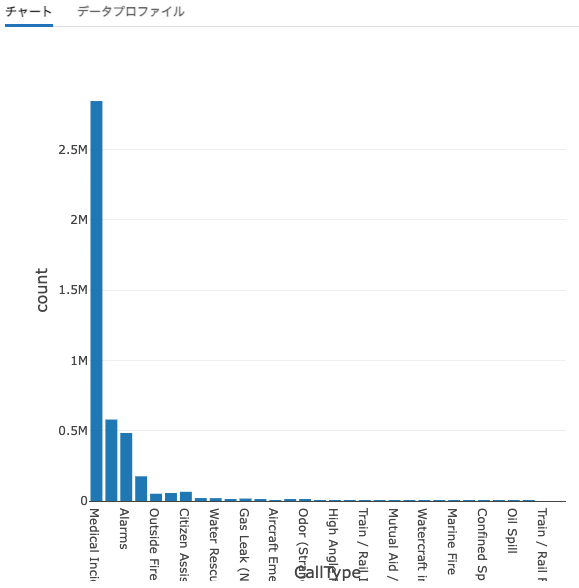
Q-4a) 呼び出しの大部分を占めているzipコードはなんですか?
サンフランシスコ消防署への通報においてどのzipコードが多いのか、どの場所でどのタイプが多いのかを調査してみましょう。
-
CallTypeでフィルタリングします。 -
CallTypeとZip codeでグルーピングします。 - カウントを行い、降順で表示します。
最も共通する電話はMedical Incidentに関連するものであり、多いzipコードは94102と94103です。
display(fire_ts_df
.select("CallType", "ZipCode")
.where(col("CallType").isNotNull())
.groupBy("CallType", "Zipcode")
.count()
.orderBy("count", ascending=False))
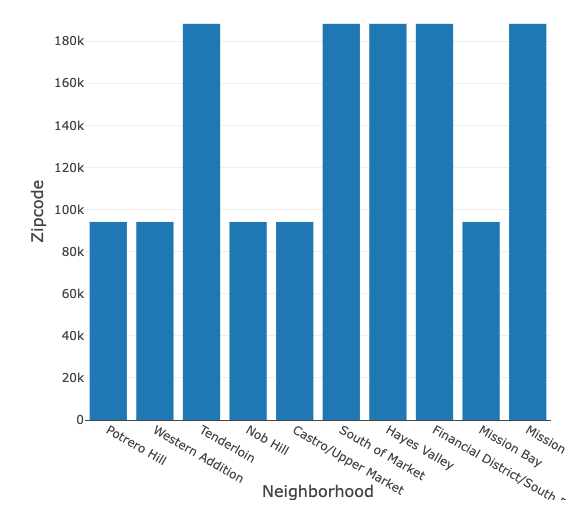
Q-4b) Zipコード94102と94103はサンフランシスコのどの地域ですか?
これらの2つのZipコードに関連づけられる地域を見つけ出しましょう。おそらく、通報率が高い地域は隣接しているケースがあるのでしょう。
display(fire_ts_df.select("Neighborhood", "Zipcode").where((col("Zipcode") == 94102) | (col("Zipcode") == 94103)).distinct())
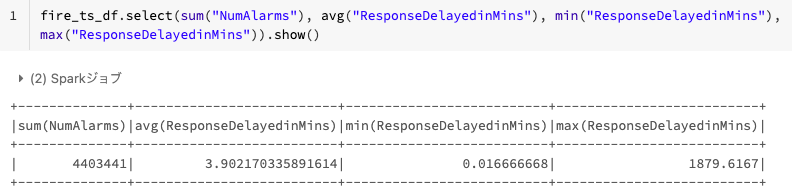
Q-5) 全ての呼び出しの合計、呼び出しに対する反応時間の平均値、最小値、最大値は何ですか?
いくつかのカラムに対して合計、平均値、最小値、最大値を計算するためにビルトインのSpark SQL関数を使いましょう。
- 通報の合計数
- 通報地点に消防隊員が到着するまでの反応時間の平均値、最小値、最大値
fire_ts_df.select(sum("NumAlarms"), avg("ResponseDelayedinMins"), min("ResponseDelayedinMins"), max("ResponseDelayedinMins")).show()
Q-6a) CSVファイルには何年分のデータが含まれていますか?
Timestamp型のIncidentDateから年を取り出すためにSpark SQL関数year()を使うことができます。
全体的には2000-2018のデータが含まれていることがわかります。
fire_ts_df.select(year('IncidentDate')).distinct().orderBy(year('IncidentDate')).show()

Q-6b) 2018年のどの週が最も通報が多かったですか?
注意: Week 1は新年の週で、Week 25は7/4の週となります。花火の季節を考えると、この週の通報が多いのは納得できます。
fire_ts_df.filter(year('IncidentDate') == 2018).groupBy(weekofyear('IncidentDate')).count().orderBy('count', ascending=False).show()

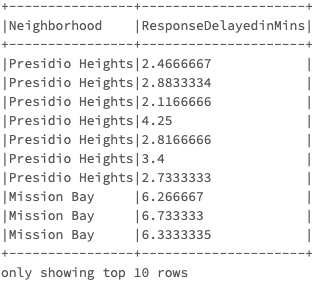
Q-7) 2018年で最も反応が悪かったサンフランシスコの地域はどこですか?
Presidio Heightsに住んでいると消防隊員は3分以内に到着し、Mission Bayに住んでいるのであれば6分以上かかるようです。
fire_ts_df.select("Neighborhood", "ResponseDelayedinMins").filter(year("IncidentDate") == 2018).show(10, False)
Q-8a) どのようにしてデータフレームをParquetファイルに保存し、読み戻すことができますか?
fire_ts_df.write.format("parquet").mode("overwrite").save(work_path)
Q-8b) データを保存し、読み戻せるようにするためにどのようにSQLテーブルを使用できますか?
fire_ts_df.write.format("parquet").mode("overwrite").saveAsTable("FireServiceCalls")
%sql
CACHE TABLE FireServiceCalls
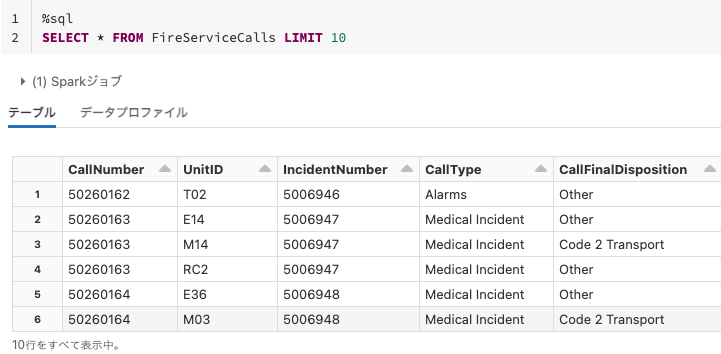
%sql
SELECT * FROM FireServiceCalls LIMIT 10
Q-8c) どのようにParquetファイルを読み込むことができますか?
Parquetメタデータの一部にスキーマが格納されているので、スキーマを指定する必要がないことに注意してください。
file_parquet_df = spark.read.format("parquet").load(work_path)
display(file_parquet_df.limit(10))