Adaptive query execution | Databricks on AWS [2021/9/14時点]の翻訳です。
Adaptive query execution (AQE)は、クエリー実行時に行われるクエリーの再最適化処理です。
実行時における再最適化のモチベーションは、Databricksにおいてはシャッフルやブロードキャストエクスチェンジの最後(AQEではクエリーステージと呼びます)に、最新かつ最も精度の高い統計情報が存在するということです。結果として、Databricksはより良い物理的な戦略を選択し、最適なシャッフル後のパーティションサイズ、パーティション数を選択する、あるいは、skew joinの取り扱いのようにヒントを必要としていた最適化を実行することができます。
統計情報の収集が有効化されていない場合や統計情報が古くなっている場合には、これは非常に有用となります。また、例えば、複雑なクエリーの途中やデータの偏りの発生後に、静的に導出された統計情報が不正確である場合にも役立ちます。
機能
Databricksランタイム 7.3 LTSでは、AQEはデフォルトで有効化されています。主に4つの機能が存在します。
- sort merge joinを動的にbroadcast hash joinに変更します。
- シャッフルの交換後のパーティションを動的に結合します(小さなパーティションを合理性のあるサイズのパーティションに結合します)。非常に小さいタスクは、最悪のI/Oスループットを持ち、スケジューリングのオーバーヘッドとタスクセットアップのオーバーヘッドに影響を受ける傾向があります。小さなタスクの結合は、リソースを節約しクラスターのスループットを改善します。
- 偏りのあるタスクを概ね均等なサイズのタスクに分割することで、sort merge joinとshuffle hash joinにおける偏りを動的に取り扱います。
- 空のリレーションを動的に検知し、伝播します。
アプリケーション
AQEは以下の条件を満たす全てのクエリーに適用されます。
- 非ストリーミング
- 少なくとも一つの交換(通常はjoin、集計、ウィンドウ関数)、あるいはサブクエリー、これらの両方を含む
必ずしもAQEが適用されるクエリーの全てが再最適化されるわけではありません。再最適化によって、静的にコンパイルされたクエリープランと異なるクエリープランが生成される場合もあれば、されない場合もあります。AQEによって、クエリープランが変更されたかどうかを知るためには、以下のセクションのクエリープランを参照ください。
クエリープラン
このセクションでは、異なる方法でどのようにクエリープランを検証できるのかを議論します。
Spark UI
AdaptiveSparkPlanノード
AQEが適用されたクエリーには1つ以上のAdaptiveSparkPlanノードが含まれ、通常はメインクエリーあるいはサブクエリーのルートノードとなります。クエリー実行前、実行中には対応するAdaptiveSparkPlanノードのisFinalPlanフラグはfalseと表示されます。クエリーの実行が完了すると、isFinalPlanフラグはtrueに変化します。
プランの進化
クエリープランの図は実行が進行すると変化し、実行中の最新のプランが反映されます。すでに実行された(メトリクスが利用できる)ノードは変化しませんが、実行されていないものは再最適化の結果、時間と共に変化します。
以下にクエリープランの図のサンプルを示します。

DataFrame.explain()
AdaptiveSparkPlanノード
AQEが適用されたクエリーには1つ以上のAdaptiveSparkPlanノードが含まれ、通常はメインクエリーあるいはサブクエリーのルートノードとなります。クエリー実行前、実行中には対応するAdaptiveSparkPlanノードのisFinalPlanフラグはfalseと表示されます。クエリーの実行が完了すると、isFinalPlanフラグはtrueに変化します。
現在プラン、初期プラン
それぞれのAdaptiveSparkPlanノードには、初期プラン(AQEの最適化が適用される前のプラン)と、処理の実行状態に基づいて、現在あるいは最終的なプランが存在します。処理が進行すると現在のプランも変化していきます。
ランタイムの統計情報
それぞれのシャッフル、ブロードキャストステージにはデータの統計情報が含まれます。
ステージの実行前、あるいはステージの実行中は、統計情報はコンパイル時の推定値となり、Statistics(sizeInBytes=1024.0 KiB, rowCount=4, isRuntime=false)のように、フラグisRuntimeはfalseとなります。
ステージの実行が完了すると、実行時に収集された統計情報は、Statistics(sizeInBytes=658.1 KiB, rowCount=2.81E+4, isRuntime=true)のようになり、フラグisRuntimeはtrueになります。
以下にDataFrame.explainのサンプルを示します。
-
実行前
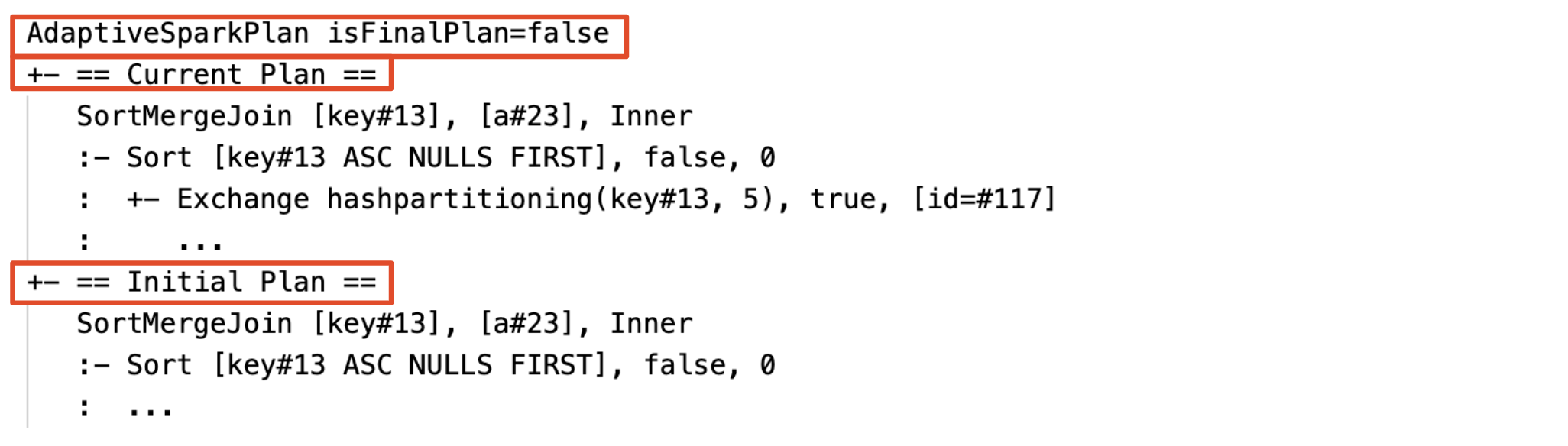
-
実行中
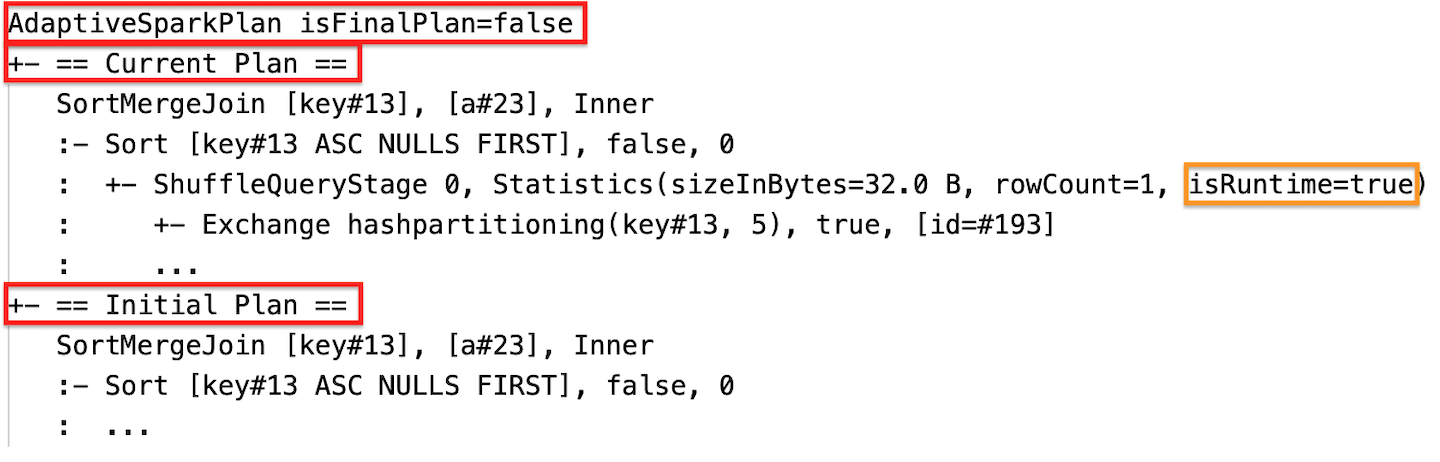
-
実行後

SQL EXPLAIN
AdaptiveSparkPlanノード
AQEが適用されたクエリーには1つ以上のAdaptiveSparkPlanノードが含まれ、通常はメインクエリーあるいはサブクエリーのルートノードとなります。
現在のプランは表示されません
SQL EXPLAINはクエリーを実行しないので、現在のプランは初期プランと同じになり、最終的にAQEによって実行される内容を反映しません。
以下にSQL EXPLAINのサンプルを示します。

効果
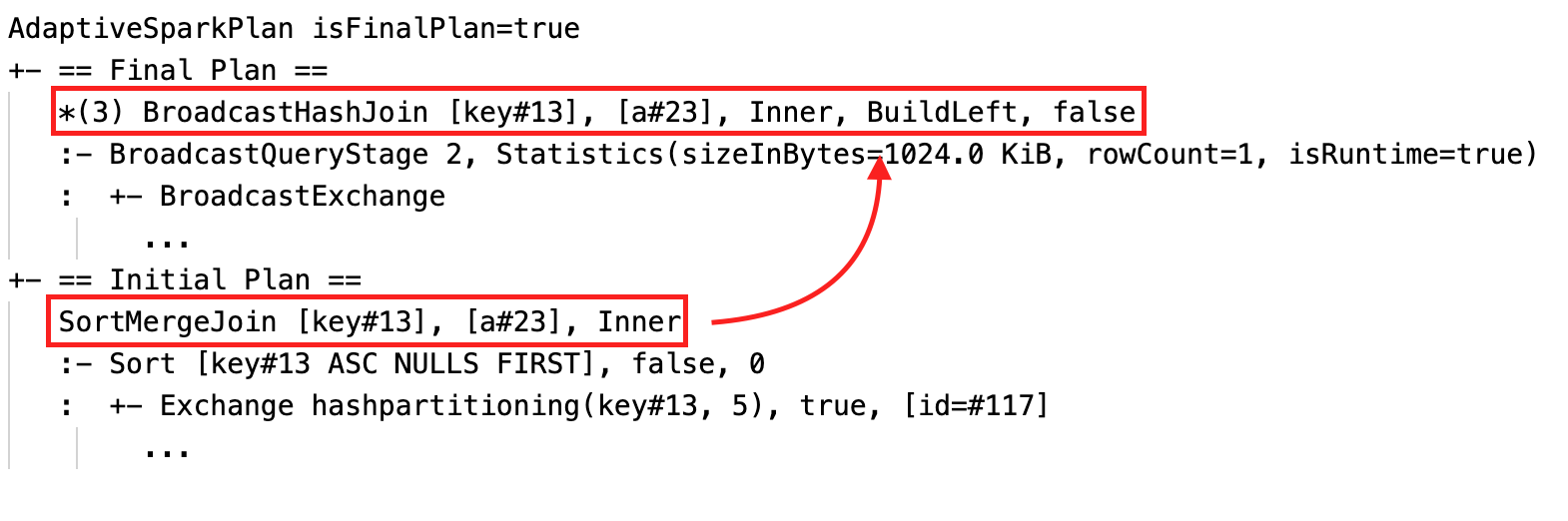
1つ以上のAQEの最適化が実行されるとクエリープランは変更されます。これらのAQEの最適化による効果は、現在プランと最終プラン、初期プランの違い、現在プランと最終プランにおける特定のプランノードに現れます。
- 動的にsort merge joinがbroadcast hash joinに変更:現在・最終プランと初期プランの間で異なる物理joinノードが表示されます。
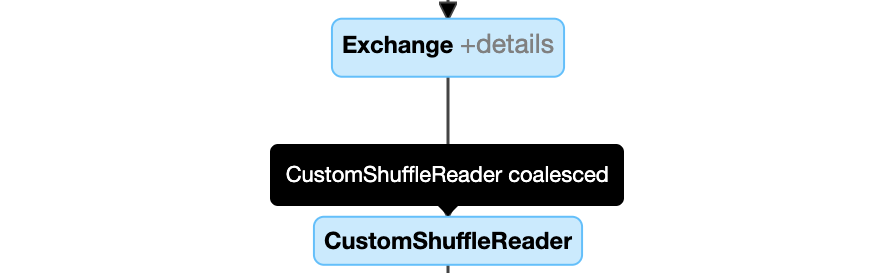
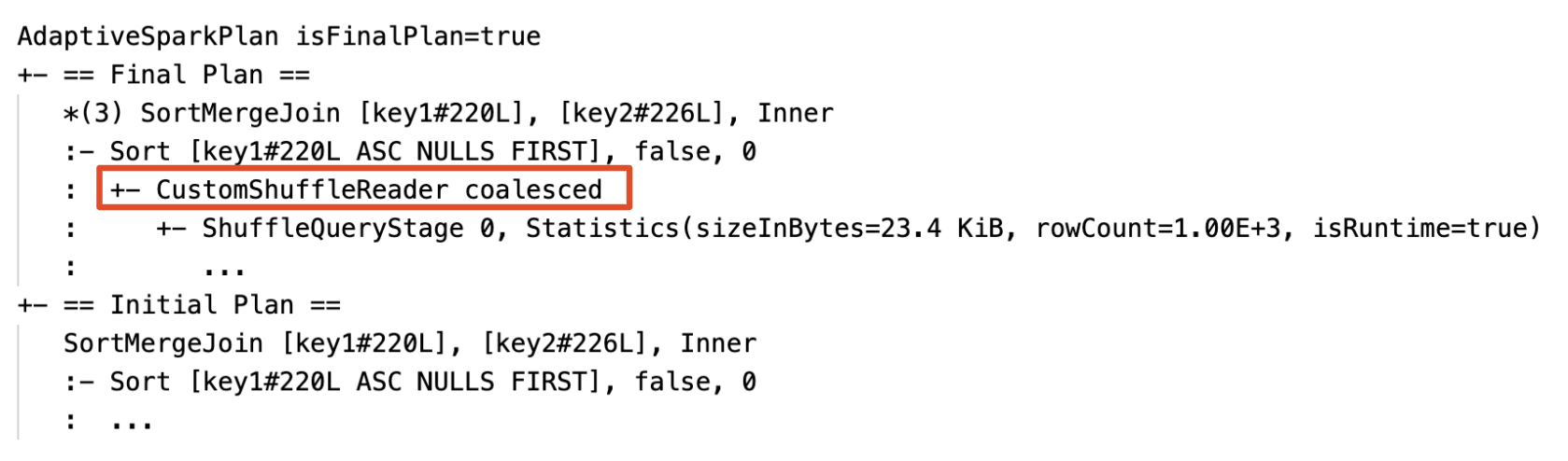
- 動的なパーティションの結合:ノード
CustomShuffleReaderにプロパティCoalescedが表示されます。
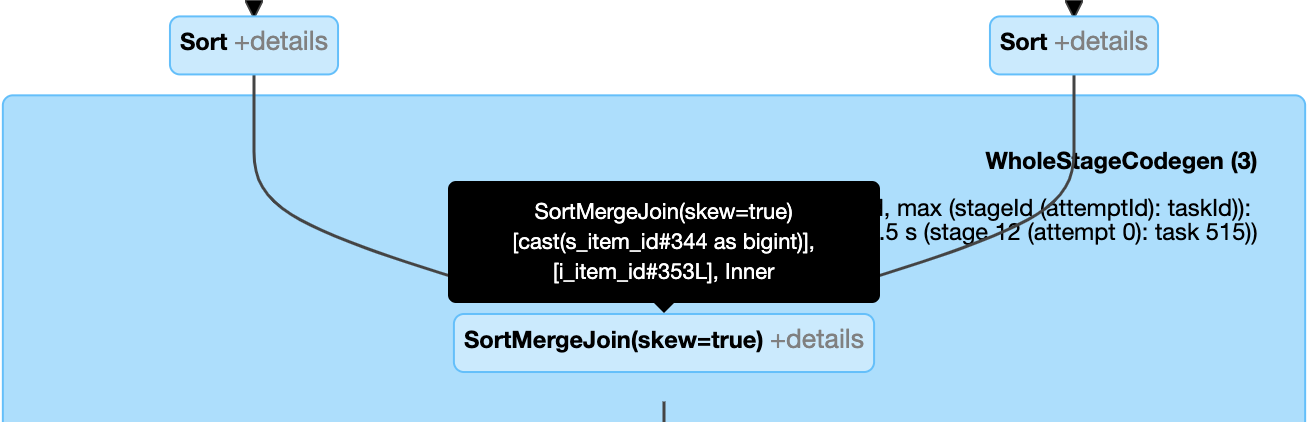
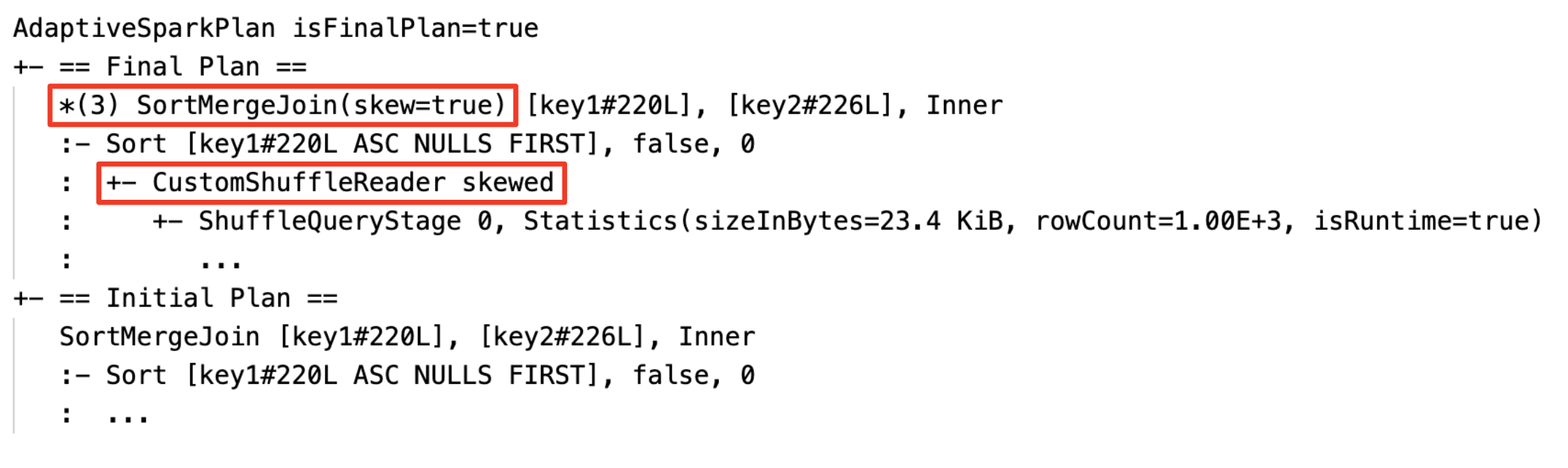
- 動的なskew joinの取り扱い:ノード
SortMergeJoinのフィールドisSkewがtrueと表示されます。
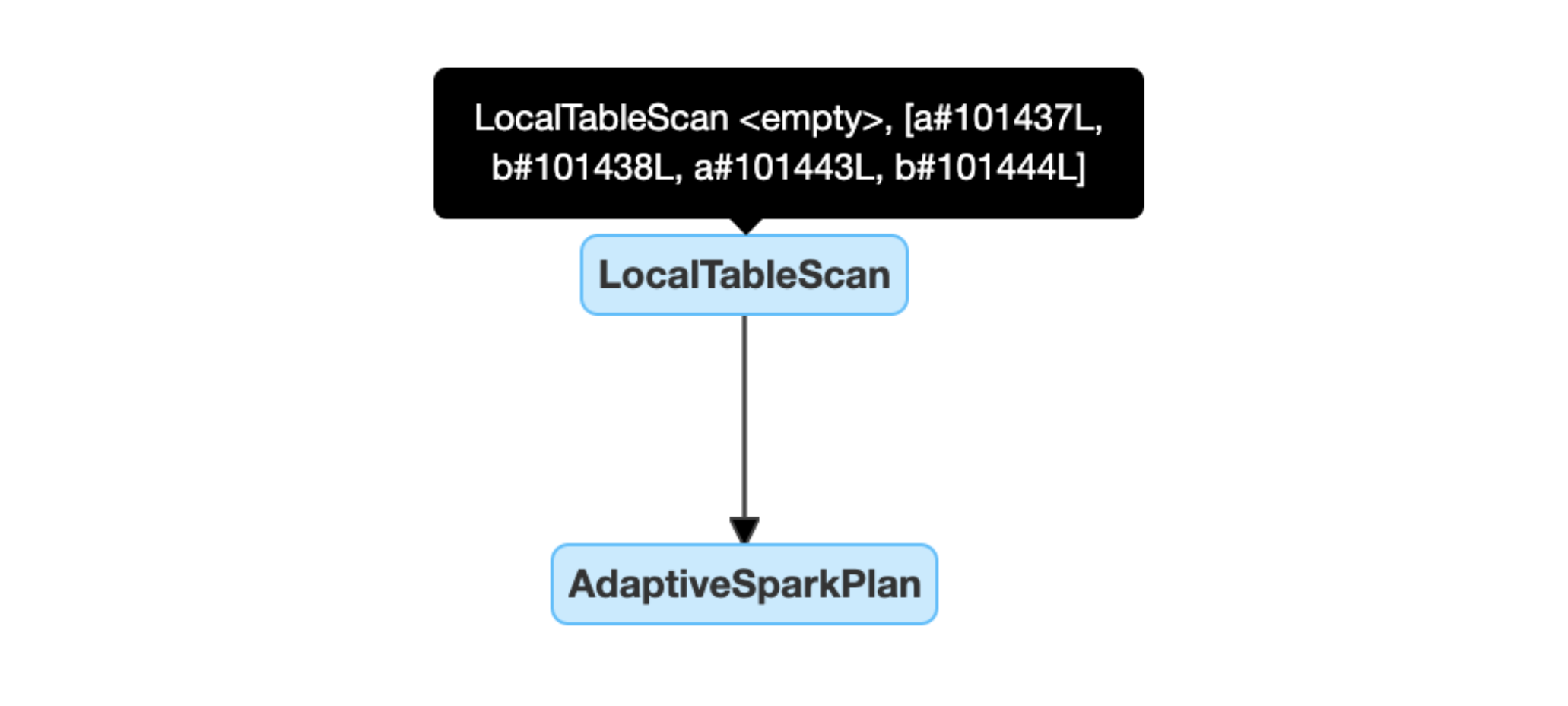
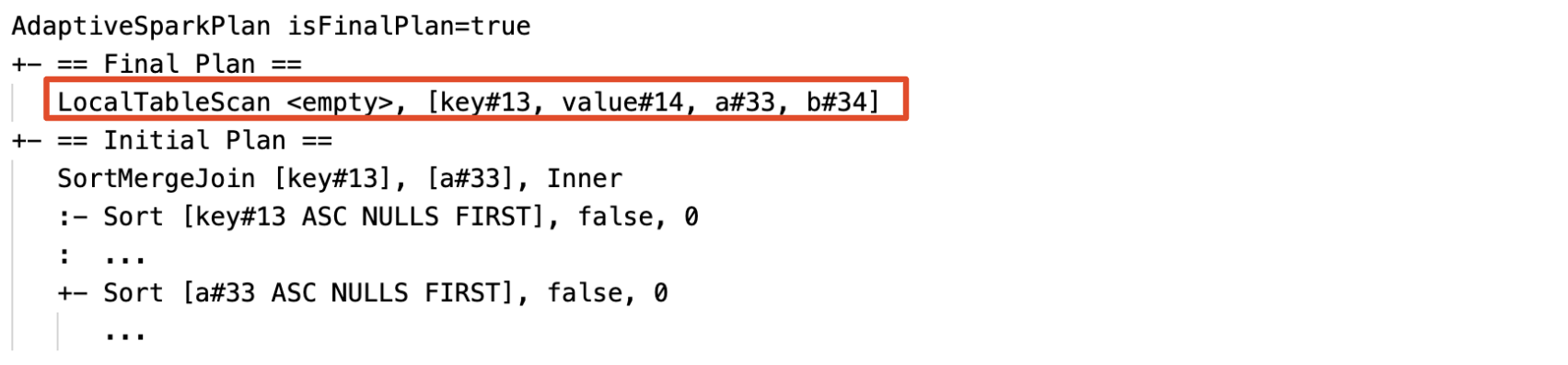
- 空のリレーションの動的な検知および伝播:プランの一部(あるいは全体)が
relationフィールドemptyであるLocalTableScanノードに置き換えられます。
設定
Adaptive query executionの有効化、無効化
| プロパティ |
|---|
|
spark.sql.adaptive.enabled 型: Booleanadaptive query executionの有効・無効 デフォルト値: true
|
動的にsort merge joinをbroadcast hash joinに変更
| プロパティ |
|---|
|
spark.databricks.adaptive.autoBroadcastJoinThreshold 型: Byte String実行時にbroadcast joinに切り替えを行う閾値 デフォルト値: 30MB |
パーティションの動的な結合
| プロパティ |
|---|
|
spark.sql.adaptive.coalescePartitions.enabled 型: Booleanパーティション結合の有効・無効 デフォルト値: true |
|
spark.sql.adaptive.advisoryPartitionSizeInBytes 型: Byte String結合後のターゲットサイズ。結合後のパーティションサイズはこの値に近いものになりますが、ターゲットサイズは超えません。 デフォルト値: 64MB
|
|
spark.sql.adaptive.coalescePartitions.minPartitionSize 型: Byte String結合後の最小サイズ。結合後のパーティションサイズはこの値よりは小さくなりません。 デフォルト値: 1MB
|
|
spark.sql.adaptive.coalescePartitions.minPartitionNum 型: Integer結合後の最小パーティション数。この設定は明示的に spark.sql.adaptive.coalescePartitions.minPartitionSizeを上書きすることになるので設定はお勧めしません。デフォルト値: クラスターのコア数 x 2
|
動的なskew joinの取り扱い
| プロパティ |
|---|
|
spark.sql.adaptive.skewJoin.enabled 型: Booleanskew joinの取り扱いの有効・無効 デフォルト値: true |
|
spark.sql.adaptive.skewJoin.skewedPartitionFactor 型: Integerパーティションに偏りがあるかどうかを決定するために用いられる、パーティションサイズの中央値に掛ける倍数 デフォルト値: 5
|
|
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes 型: Byte Stringパーティションに偏りがあるかどうかを決定するために用いられる閾値 デフォルト値: 256MB
|
以下の両方がtrueとなった場合に、パーティションに偏りがあると判定します。
(partition size > skewedPartitionFactor * median partition size)(partition size > skewedPartitionThresholdInBytes)
空のリレーションの動的な検知および伝播
| プロパティ |
|---|
|
spark.databricks.adaptive.emptyRelationPropagation.enabled 型: Boolean空のリレーションの動的な検知および伝播の有効・無効 デフォルト値: true |
FAQ
パーティション結合を有効化しているのに、どうしてAQEはシャッフルパーティション数を変更しないのか?
AQEは初期のパーティション数を変更しません。最初にシャッフルパーティション数に十分大きな値を設定し、クエリーのそれぞれのステージのアウトプットデータのサイズに基づきAQEに小規模なパーティションを結合させることをお勧めします。
ジョブでspilling(溢れ)が発生する場合には、以下を試してみてください。
- シャッフルパーティション数の設定
spark.sql.shuffle.partitionsを増やす。 -
spark.databricks.adaptive.autoOptimizeShuffle.enabledをtrueに設定して、自動最適化シャッフルを有効にする。
どうしてAQEは小さなjoinテーブルをブロードキャストしないのか?
ブロードキャストされると期待されるリレーションのサイズが閾値以下となってもブロードキャストされない場合があります。
- joinのタイプを確認してください。
LEFT OUTER JOINの左側のリレーションのような特定のjoinタイプではブロードキャストはサポートされていません。 - リレーションに多くの空のパーティションが含まれる場合、タスクの大部分はsort merge joinですぐに完了するか、あるいは、skew joinのハンドリングで最適化される可能性があります。空でないパーティションの割合が
spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoinより低い場合、AQEはそのようなsort merge joinからbroadcast hash joinへの変更を避けます。
AQEが有効化されている場合でもbroadcast join戦略ヒントを使う必要がありますか?
はい。AQEはjoinの両側に対するシャッフルを実行するまで(実際のリレーションのサイズを取得できるまで)broadcast joinに切り替えないため、静的に計画されたbroadcast joinは多くの場合でAQEによって動的に計画された計画よりも高い性能を発揮します。このため、あなたが自身のクエリーをよく理解している場合には、broadcastヒントは依然として良い選択肢となります。AQEは静的な最適気化が行うのと同じように、クエリーのヒントを考慮しますが、依然としてヒントによる影響を受けない動的な最適化は適用します。
skew joinのヒントとAQEのskew joinの最適化の違いは何ですか?どちらを使うべきですか?
AQEのskew joinは完全に自動的なものであり、通常、ヒントよりも高い性能を出すので、skew joinのヒントよりもAQEのskew joinハンドリングを使用することをお勧めします。
なぜ、AQEはjoinの順序を自動で調整しないのですか?
動的なjoin順序の並び替えは、Databricksランタイム7.3 LTS時点ではAQEに含まれていません。
なぜ、AQEはデータの偏りを検知しないのですか?
AQEがパーティションに偏りがあると判定するには、サイズ上の条件が2つあります。
- パーティションサイズが
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes(デフォルトは256MB)より大きい。 - パーティションサイズが全てのパーティションのサイズの中央値 x skewパーティションファクター(デフォルトは5)よりも大きい。
さらに、skewハンドリングのサポートは、例えばLEFT OUTER JOINの左側のみが最適化されうるなど、特定のjoinのタイプのみに限定されます。
レガシー
"Adaptive Execution"という用語はSpark 1.6から存在していますが、新たなSpark 3.0におけるAQEは根本的に異なります。機能面では、Spark 1.6では「動的パーティション結合」のみを行っています。技術的なアーキテクチャの面では、新たなAQEは実行時の統計情報に基づくクエリーの再計画と動的計画のフレームワークであり、本文で述べたような様々な最適化をサポートsており、より潜在的な最適化に拡張されます。