こちらでは、無料で利用できるDatabricks Community Editionを用いて、分類の一手法であるXGBoostを使って、特徴量からアヤメ(iris)を種類を特定(分類)するとともに、Databricksの画面や機能に慣れていただきます。
こちらの続編となります。前回は一年前でした。
一年経つと、GUIも結構変わっているので新たなGUI含めてウォークスルーしていきます。
今回使うノートブックはこちらです。
こちらをベースにしています。
全体の流れは以下のようになります。
- Databricks Community Editionへのサインアップ
- 計算資源の作成
- ノートブックの作成
- XGBoostによるアヤメの分類
ここで行う分類とは、アヤメの特徴量からアヤメのクラス(種類)を推定するという処理を指しています。
- 特徴量: アヤメのがく(sepal)や花びら(petal)の幅や長さ
- クラス: Setosa、Versicolour、Virginica
Databricksとは
Databricksは、Apache Spark™、Delta Lake、MLflowの開発者グループによって2013年に創業されたデータ&AIカンパニーです。Databricksのデータインテリジェンスプラットフォームは、組織全体でのデータとAIの活用を促進させ、データレイクハウスを基盤とするプラットフォームが、あらゆるデータとガバナンス要件をサポートするオープンな統合環境を提供します。
Databricks Community Editionとは
Databricksではその機能を無償でお試しいただけるよう、2通りの方法を用意しております。
- 2週間の無償トライアル: Databricksのすべての機能を2週間無償でお試しいただけます。
- Community Edition: 利用できる機能が限定されますが、期限なし・無償でご利用いただけます。
本記事では、Community EditionでのDatabricksの基本的な機能を体験いただきます。
Databricks Community Editionへのサインアップ
-
https://databricks.com/jp/try-databricks にアクセスします。必要な情報を入力します。続行をクリックします。

-
Community Editionのトライアルを開始をクリックします。

- クイズが出るので人間であることを証明しましょう。

- 認証のためのメールが送信されます。

-
Welcome to Databricks! Please verify your email address. というメールが届くので、Get started by visitingのリンクをクリックします。

- パスワードを設定します。

- これでDatabricks Community Editionにログインできました。

Databricks Community Editionの画面構成
Databricksでは、ノートブック上にロジックを記述してそれを実行することで様々な処理を行います。この観点ではJuypter notebookと非常に近いUIを持っていると言えます。しかし、様々な点で強化・拡張がなされているのがDatabricksです。
画面の左側のサイドメニューにマウスカーソルを移動するとメニューが展開されます。基本的な機能にはこちらからアクセスすることになります。

各項目については、以下の参考資料をご覧ください。ここでは、クラスターを作成するためにメニューからクラスターをクリックします。
GUIが英語になっている場合は、こちらを参考に日本語に変更してください。
- 画面右上のユーザーアイコンをクリックし、Settingsを選択。

-
User配下のPreferencesをクリック。
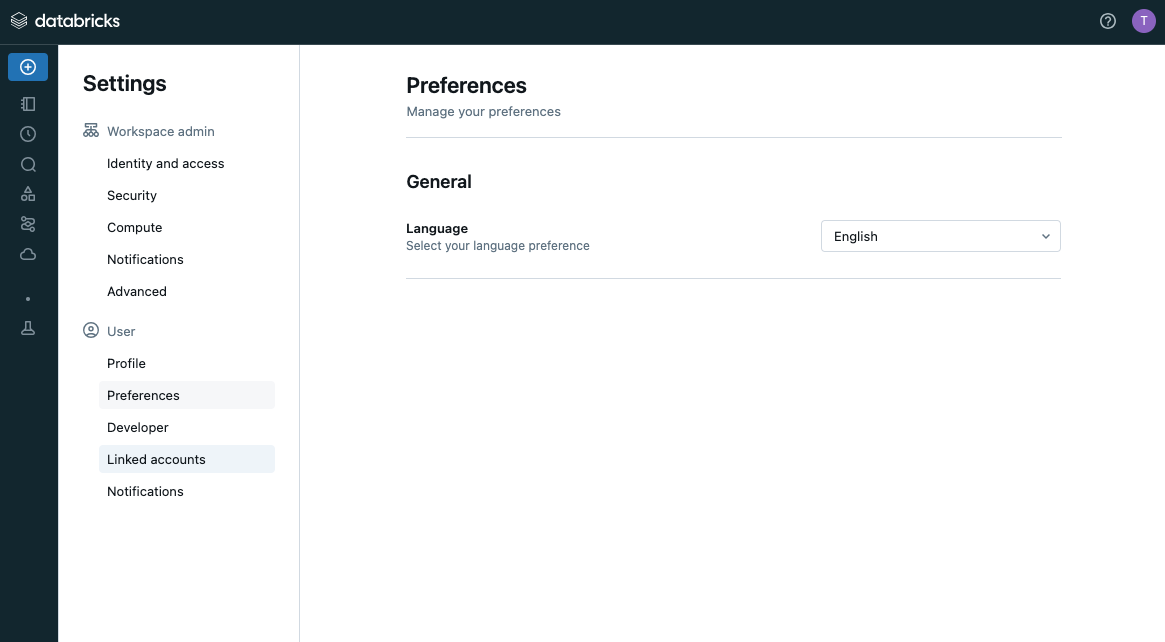
-
Languageから日本語を選択。


- ホームページに戻るには画面左上のdatabricksロゴをクリックします。
クラスターの作成
クラスター(コンピュート)とは、機械学習モデルのトレーニングやデータの加工を行う際に必要となる計算資源です。Databricksでは大量のデータを高速に処理できるように複数の仮想マシンをまとめてクラスターとして構成します。Databricksクラスターを用いることで、従来であれば手間のかかる環境構築(仮想マシンの設定、ソフトウェアのインストールなど)をGUIからの操作で手軽に行えるようになります。
-
クラスターの一覧が表示されます。この時点ではクラスターは存在していないため一覧は空の状態です。左上にあるコンピューティングを作成ボタンをクリックします。

-
この画面で作成するクラスターの設定を行います。ここでは、クラスター名とDatabricks Runtimeのバージョンを指定します。
- クラスター名: 人が見てわかりやすい名前を指定してください。
-
Databricks Runtimeのバージョン: Databricks Runtimeとはクラスターに自動でインストールされるソフトウェアのパッケージです。Pythonの実行環境やPythonライブラリなどが含まれています。ここでは、
Runtime 15.3 MLを選択します。

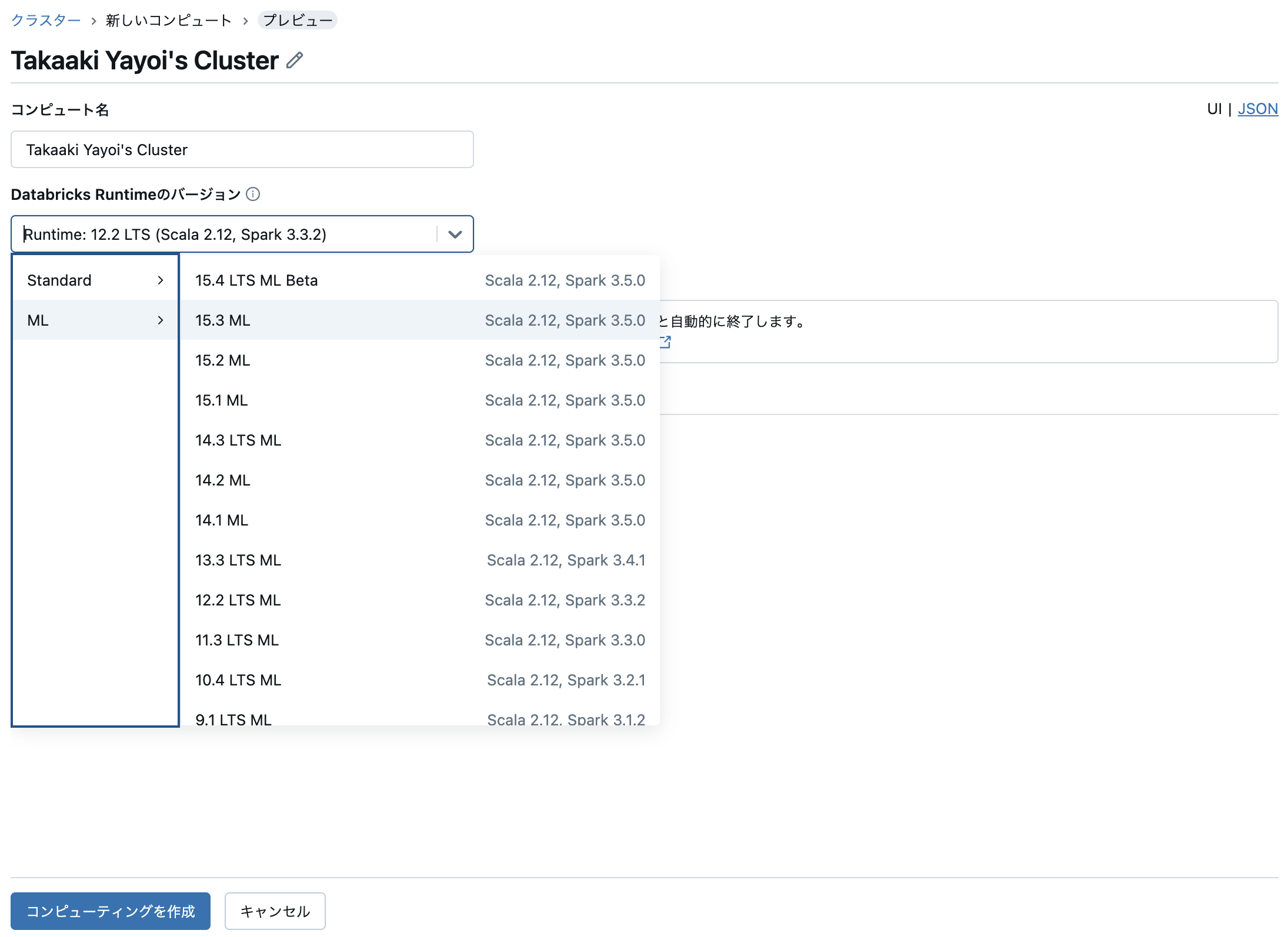
-
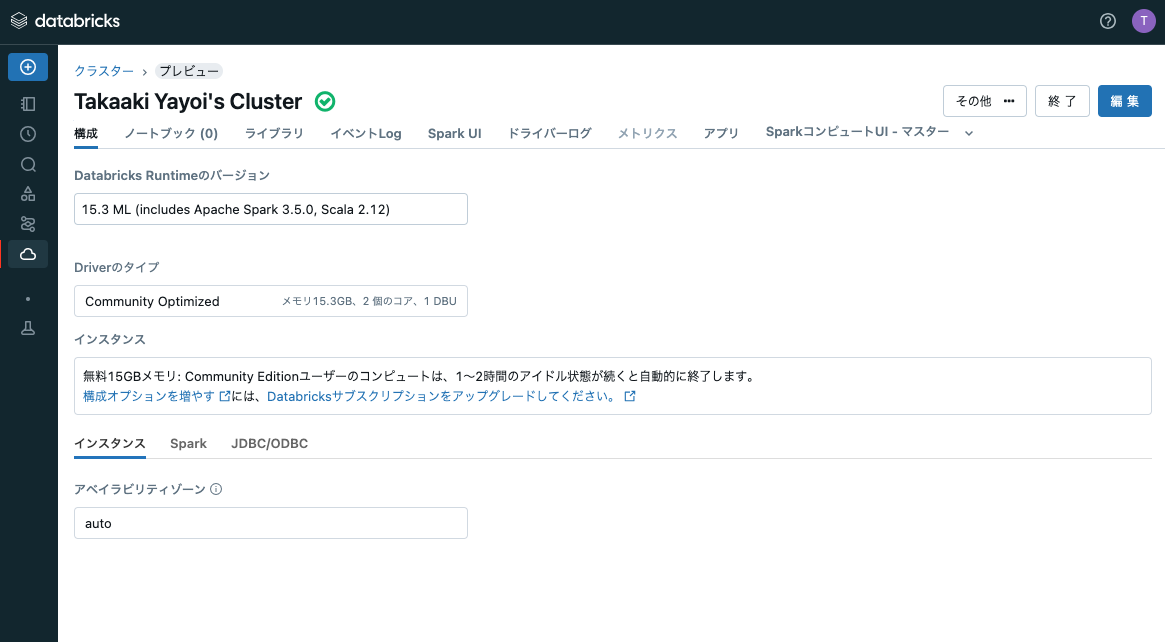
画面下のコンピューティングを作成をクリックするとクラスターが作成されます。クラスターが作成され、起動するまでに数分要しますのでお待ちください。作成が完了するとクラスター名の右側に緑のチェックマーク入りのアイコンが表示されます。
ノートブックの作成
次に、ロジックを記述するノートブックを作成します。
- サイドメニューのワークスペースをクリックします。ワークスペースは名前の通り、皆様の作業場でありノートブックを格納する場所となります。
- ホームフォルダは自分のメールアドレスの名称となっています。ここにフォルダを作成したり、ノートブックを格納することになります。

- ホームフォルダ名(自分のメールアドレス)の右にある作成をクリックしてノートブックを選択します。

- ノートブックの右上の接続からクラスターを選択します。Databricksで処理を実行するには、ノートブックをクラスターにアタッチする必要があります。編集のみを行う際にはクラスターへのアタッチは不要です。

- これで準備が整いました。

ティップス
フルバージョンのDatabricksではフォルダやノートブックなどにアクセス権を設定できるので、ユーザー間でセキュアに資産のやり取りを行うことができます。
ノートブックの実行
すでにノートブックが表示されていますので、Juypter notebookを使うのと同様にPythonの処理を記述、実行することができます。
-
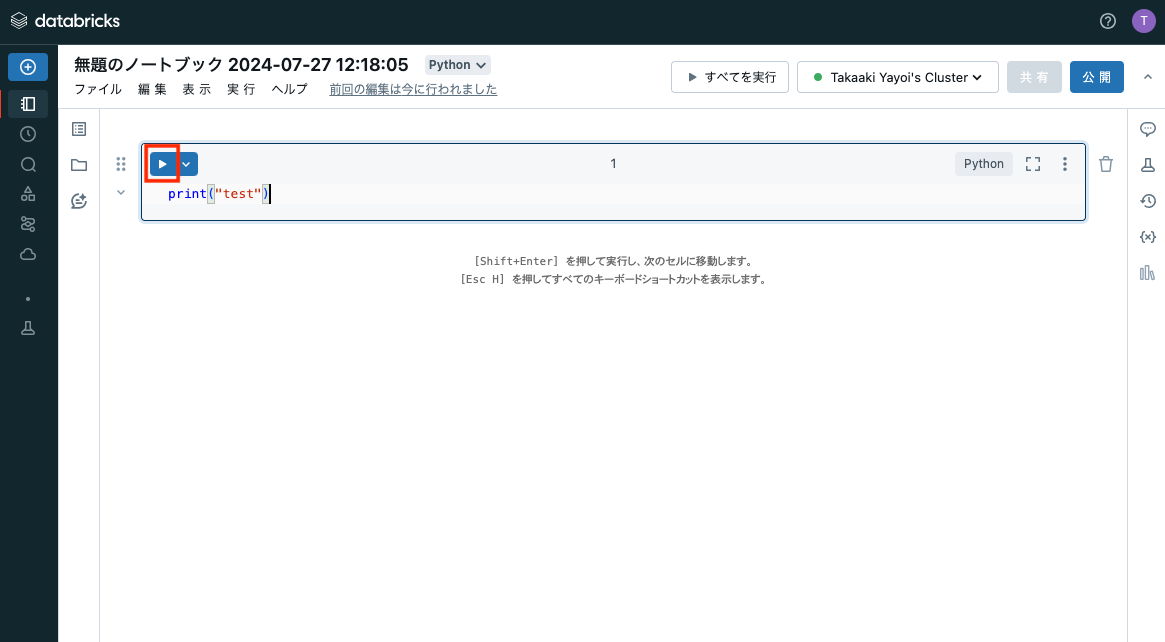
一つ目のセルにカーソルを移動し、以下の内容を記述します。
Pythonprint("test") -
セルを実行するにはいくつかの方法がありますが、ここではセルの左上の再生ボタンをクリックします。
-
以下のように結果が表示されます。

ティップス
上に表示されているように、Shift+Enterキーを押してもセルを実行することができます。
新たにセルを追加するには、追加したいセルの上部あるいは下部にカーソルを移動すると+コードや+テキストが表示されるのでこれをクリックすることでセルの上下に追加することができます。


XGBoostを試してみる
XGboostとは
XGBoost(eXtreme Gradient Boosting / 勾配ブースティング回帰木)とは、アンサンブル学習の一つで、ブースティングと決定木を組み合わせています。
ブースティングとは、弱いモデル(弱学習器と呼びます)を複数作成し、一つ前の学習器の誤りを次の学習器が修正するという操作を繰り返し行うことで性能を向上させる手法です。
勾配ブースティング回帰木では、浅い決定木を複数作成し、それぞれの決定木はデータの一部に対してしか良い予測を行うことができないため、ブースティングを行うことで性能を向上させています。パラメータ設定に敏感という欠点がありますが、正しく設定すればランダムフォレストよりも良い性能となります。
また、XGBoost(勾配ブースティング回帰木)の名前に「回帰木」とありますが、回帰と分類のどちらでも使用可能です。
ノートブックのインポート
上ではノートブックを作成しましたが、インターネットで公開されているノートブックなどを簡単に取り込むこともできます。
-
サイドメニューのワークスペースをクリックします。
-
ホームフォルダ名(自分のメールアドレス)の右にある(3つの点が縦に並んでいる)三点リーダーをクリックします。メニューが表示されるのでインポートを選択します。

-
ダイアログが表示されます。以下を指定してインポートをクリックします。

インポート元:
URLを選択します。
テキストボックス: 以下のURLを貼り付けます。https://sajpstorage.blob.core.windows.net/yayoi/ce-xgboost-python.html -
以下のようにノートブックがインポートされます。

-
画面右上で上のステップで作成したクラスターを選択します。
ノートブックを実行
データの準備
# ライブラリのインポート
import pandas as pd
import xgboost as xgb
# 分析データのコピー
dbutils.fs.cp('dbfs:/databricks-datasets/Rdatasets/data-001/csv/datasets/iris.csv', 'file:/tmp/iris.csv')
今回使用するデータは以下のような構造となっています。
-
sepal length: 萼(がく)の長さ -
sepal width: 萼(がく)の幅 -
petal length: 花びらの長さ -
petal width: 花びらの幅 -
class: アヤメの種類
# pandasライブラリを使用してirisデータセットを読み込む
raw_input = pd.read_csv("/tmp/iris.csv",
header=0,
names=["item", "sepal length", "sepal width", "petal length", "petal width", "class"])
# 不要な列を削除
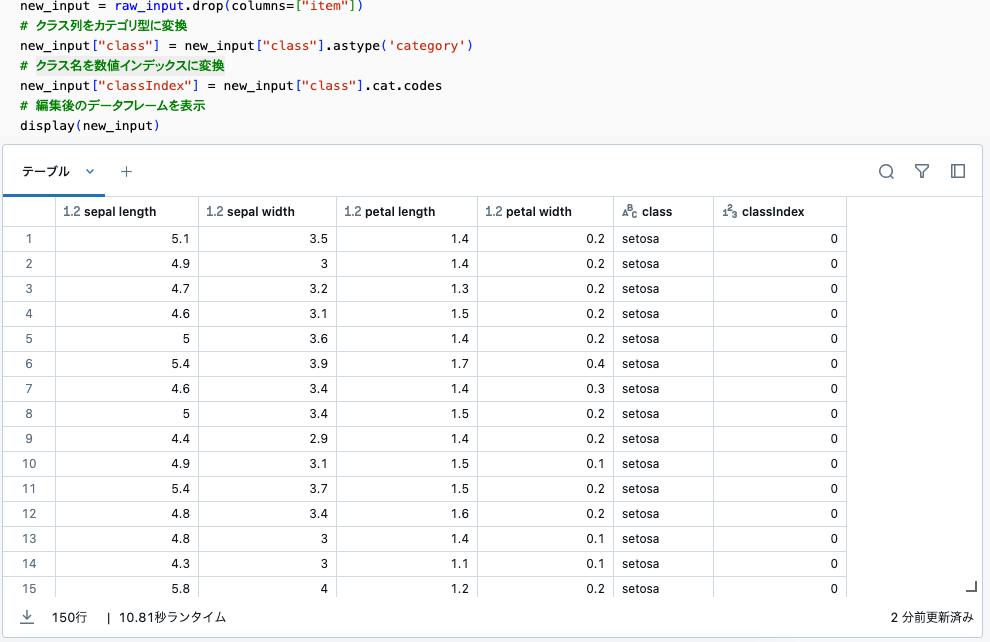
new_input = raw_input.drop(columns=["item"])
# クラス列をカテゴリ型に変換
new_input["class"] = new_input["class"].astype('category')
# クラス名を数値インデックスに変換
new_input["classIndex"] = new_input["class"].cat.codes
# 編集後のデータフレームを表示
display(new_input)
上で使用しているdisplay関数はDatabricks固有のものです。pandasデータフレームやSparkデータフレームを可視化することができます。こちらを参考に色々なグラフを作ってみてください。


from sklearn.model_selection import train_test_split
# new_inputデータフレームを訓練データとテストデータに分割
# トレーニングには訓練データのみを使用し、精度検証にテストデータを使用します
training_df, test_df = train_test_split(new_input)
Pandasデータフレームを用いたXGBoostモデルのトレーニング
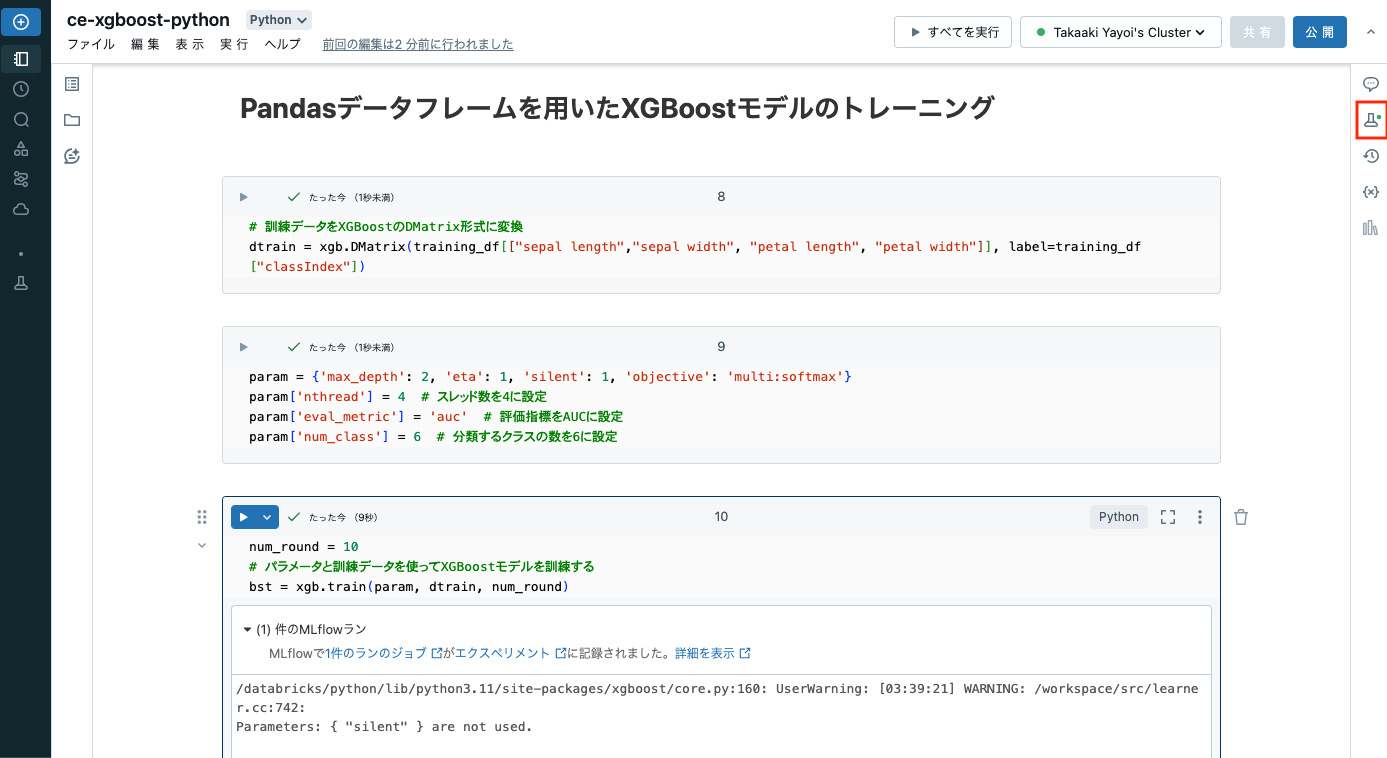
# 訓練データをXGBoostのDMatrix形式に変換
dtrain = xgb.DMatrix(training_df[["sepal length","sepal width", "petal length", "petal width"]], label=training_df["classIndex"])
param = {'max_depth': 2, 'eta': 1, 'silent': 1, 'objective': 'multi:softmax'}
param['nthread'] = 4 # スレッド数を4に設定
param['eval_metric'] = 'auc' # 評価指標をAUCに設定
param['num_class'] = 6 # 分類するクラスの数を6に設定
num_round = 10
# パラメータと訓練データを使ってXGBoostモデルを訓練する
bst = xgb.train(param, dtrain, num_round)
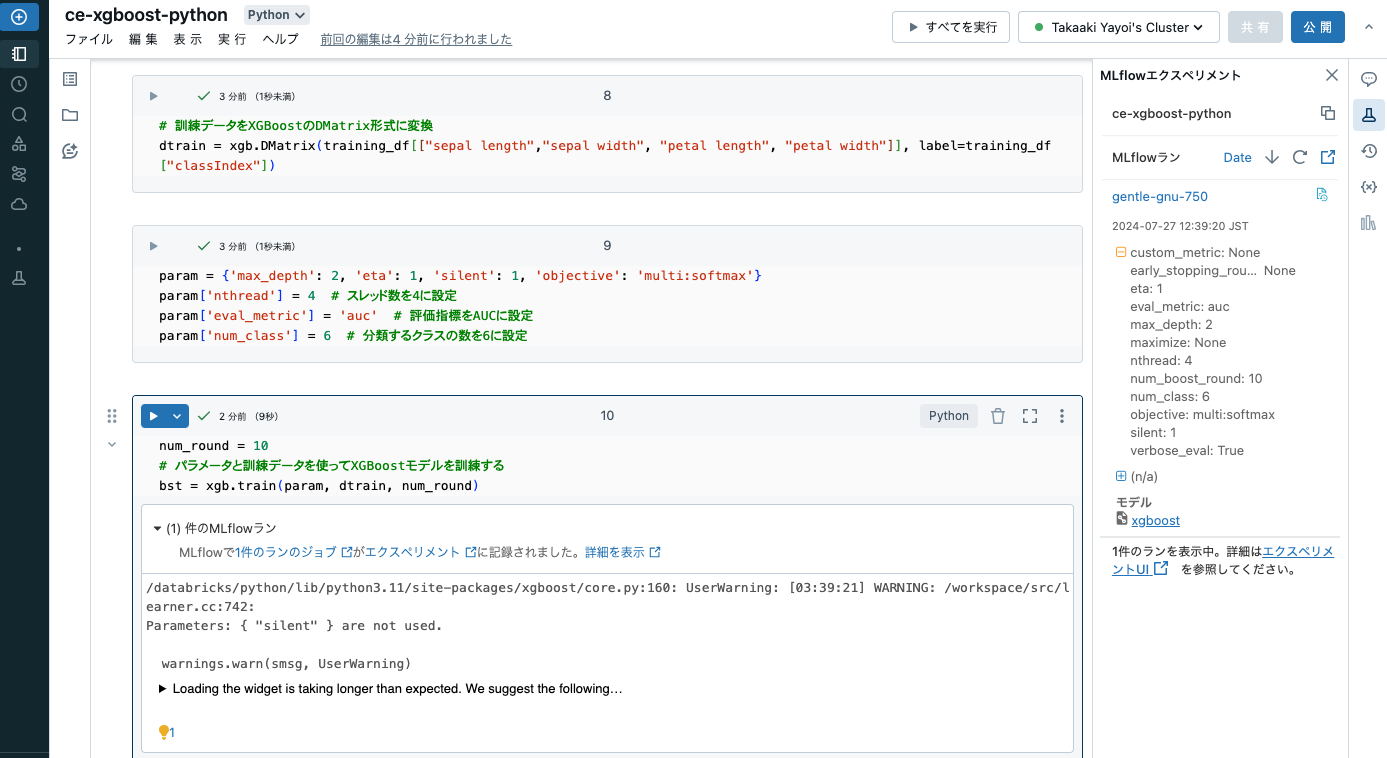
上のセルを実行すると、MLflowで1件のランのジョブがエクスペリメントに記録されました。というメッセージが表示されます。Databricksで機械学習モデルをトレーニングすると、インテグレーションされているMLflowが自動でモデルを記録してくれます。右上のフラスコマークに注目すると、グリーンのドットが表示されています。クリックしてみましょう。
記録されているモデルを確認することができます。どのような情報が記録されているのかを確認してみましょう。


予測
特徴量からアヤメの種類を予測します。
# テストデータフレームから特徴量を選択してDMatrixを作成
dtest = xgb.DMatrix(test_df[["sepal length","sepal width", "petal length", "petal width"]])
# 訓練済みモデルを使って予測を実行
ypred = bst.predict(dtest)
ypred
array([0., 1., 0., 0., 1., 1., 1., 2., 1., 2., 0., 0., 1., 2., 2., 2., 0.,
1., 2., 2., 0., 0., 1., 2., 1., 2., 1., 1., 0., 0., 0., 0., 0., 1.,
0., 1., 2., 1.], dtype=float32)
# nparrayをpandasデータフレームに変換
df_pred = pd.DataFrame(ypred, columns = ["prediction"], index=test_df.index)
# 予測結果とテストデータを結合
# classIndexとpredictionが一致している場合、正しく予測(分類)できたことを意味します
df_result = pd.concat([test_df, df_pred], axis=1)
display(df_result)

予測したアヤメの種類が実際のデータと一致しているのかどうかを確認します。precision_scoreで正解率を計算します。
# sklearnからprecision_scoreをインポート
from sklearn.metrics import precision_score
# 予測結果の精度を計算
pre_score = precision_score(test_df["classIndex"], ypred, average='micro')
# 精度スコアを表示
display("xgb_pre_score: {}".format(pre_score))
'xgb_pre_score: 0.8947368421052632'
お疲れ様でした!Databricksに興味を持たれた方はこちらもご覧ください。
- はじめてのDatabricks
- Databricksドキュメント | Databricks on AWS
- Databricks ブログ
- Databricks記事のまとめページ(その1) #Databricks - Qiita
- Databricks記事のまとめページ(その2) #Databricks - Qiita