こちらのマニュアルを翻訳しているときに以下の一文が目に入りました。
Delta Lakeを用いてデータを格納することで、データが処理されるとすぐに皆様のコアのETLワークロードをサポートし、後段のデータサイエンティスト、アナリスト、機械学習エンジニアは同一のプロダクションデータを活用できるようになります。
自分でもよく話している内容ではありますが、これって具体的にどういうことなんだろうか?と今更ながらと自分の中でモヤモヤした訳です。
と言うことで、仮想的なシナリオに沿って上の話を再現してみました。
ある企業におけるCOVID-19分析
データからわかる-新型コロナウイルス感染症情報-にあるようなダッシュボードを作ってみたいというシナリオからスタートします。
登場人物
- 偉い人: そのままです。
- DE君: データエンジニア
- BA君: ビジネスアナリスト
- DS君: データサイエンティスト
ある日のオフィス
- 偉い人: やあ、BA君。
- BA君: はい。
- 偉い人: コロナなかなか落ち着かないね。
- BA君: そうですね。
- 偉い人: ニュースで感染者数はわかるけど、これまでどのようなトレンドだったのかを知りたいのだけど、ダッシュボードをチャチャっと作ってくれない?
- BA君: えっ。データからわかる-新型コロナウイルス感染症情報-を見ればいいじゃないですか?
- 偉い人: いやいや、これだと足りない観点があるから独自に作ってほしいんだ。
- BA君: はあ。
- 偉い人: じゃ、頼んだよ!
- BA君: 参ったな。データをどうにかしないと。DE君に相談しよう。
(データエンジニア)DE君の取り組み
- BA君からの相談を受けたDE君は作業に取り掛かります。
- ダッシュボードを作るにはまずデータが必要です。
- オープンデータ|厚生労働省で公開されているデータを使用します。
いわゆるETL(Extract-Transform-Load)処理を行なっていきます。最初はデータの抽出(Extract)からです。
データの抽出(Extract)
Databricksノートブックを使ってETLロジックを記述していきます。
import pandas as pd
# pandasを使ってURLから直接データを取得します
pdf = pd.read_csv("https://covid19.mhlw.go.jp/public/opendata/newly_confirmed_cases_daily.csv")
# データを表示します
display(pdf)
注意
上のコマンドは外部サイトにアクセスしますので、アクセス頻度に関しては注意してください。
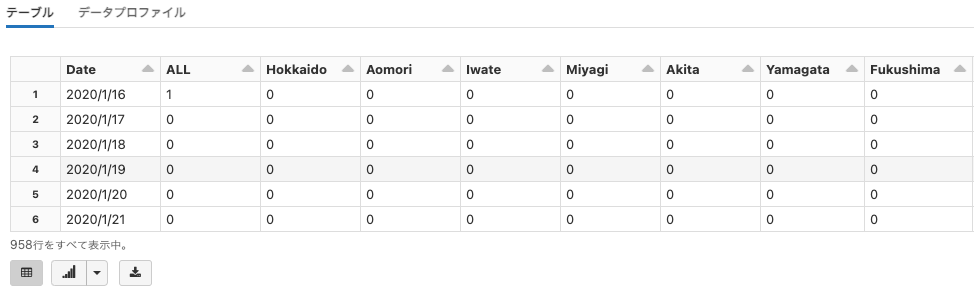
データの変換(Transform)
データ構造の変換
このデータは、そのままでも都道府県ごとの日々の感染者数の推移を確認することはできます。しかし、このデータは各列が都道府県名となっている横持ちのデータフレーム(Wide dataframe) となっています。特定の県のデータを取り出すためには、列名を指定しなくてはならず、where句を使うSQLとの相性は良いとはいえません。
そこで、ここではいろいろな切り口で分析をしやすくなるように、縦持ちのデータフレーム(Long dataframe) に変換します。
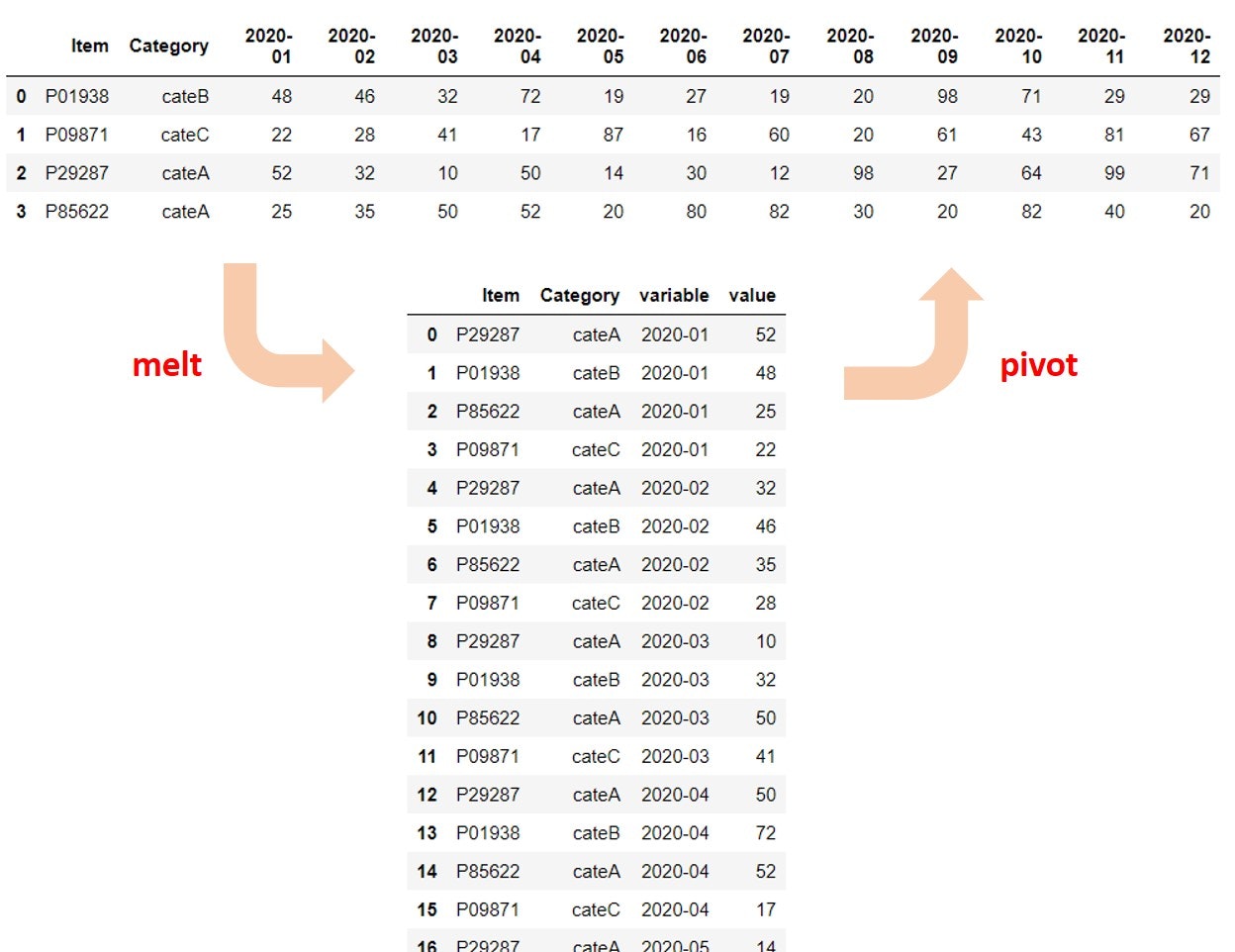
上の図は以下の記事から引用させていただきました。
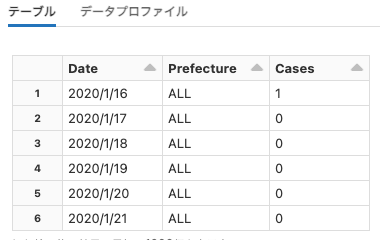
# 縦長に変換
# id_vars: Dateをidとして、変換後のデータフレームにそのまま残します
# var_name: variable変数の列名をPrefectureにします
# value_name: value_name変数はCaseとします
long_pdf = pdf.melt(id_vars=["Date"], var_name="Prefecture", value_name="Cases")
display(long_pdf)
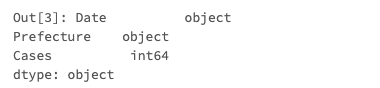
データ型の確認
次にデータ型を確認します。
pandasのデータ型dtype一覧とastypeによる変換(キャスト) | note.nkmk.me
long_pdf.dtypes
フレームワークの選択、データ型の変換、フィルタリング
ここでは、データエンジニアの立場に立って以下の検討を行うものとします。
- pandasでは豊富なメソッドが提供されていますが、大量データの取り扱いには不得手です。このため、ここからは大量データを容易に取り扱うことができるSparkデータフレームで操作を行なっていきます。
-
objectはオブジェクト型であることを示しています。日付を示すDateがオブジェクト型だと後程の処理で都合が悪くなるのでタイムスタンプ型に変換します。 -
PrefectureがALLは全国の感染者数を示しています。全都道府県のデータの合計を取れば全国分は計算できるので除外します。 - 全期間のデータは不要なので2022年以降のデータに限定します。
このように、データエンジニアリングの過程では、後段での処理で求められる要件を踏まえてデータを加工していきます。これと並行して、性能要件も考慮してどのようなアプローチを取ったらいいのかも検討していきます。
# pandasデータフレームをSparkデータフレームに変換します
sdf = spark.createDataFrame(long_pdf)
from pyspark.sql.functions import *
# PythonのSpark API(pyspark)を用いて、データ型の変換を行います
# 変換後に元のDate列は削除します
# Prefecture ALLを除外します
# 2022年以降のデータに限定します
df = (sdf
.withColumn("date_timestamp", to_timestamp(col("Date"), "yyyy/M/d"))
.drop("Date")
.filter("Prefecture != 'ALL' AND date_timestamp >= '2022-1-1'")
)
display(df)
データの拡張
これで変換処理は概ね完了しましたが、都道府県がどの地方に属しているのかが分かった方が分析の幅が広がるので、地方名などでデータを拡張します。
以下のサイトのデータをお借りして、補強するデータを準備します。
以下のCSVファイルを準備します。
pref_no,Prefecture,Area
1,Hokkaido,北海道地方
2,Aomori,東北地方
3,Iwate,東北地方
4,Miyagi,東北地方
5,Akita,東北地方
6,Yamagata,東北地方
7,Fukushima,東北地方
8,Ibaraki,関東地方
9,Tochigi,関東地方
10,Gunma,関東地方
11,Saitama,関東地方
12,Chiba,関東地方
13,Tokyo,関東地方
14,Kanagawa,関東地方
15,Niigata,中部地方
16,Toyama,中部地方
17,Ishikawa,中部地方
18,Fukui,中部地方
19,Yamanashi,中部地方
20,Nagano,中部地方
21,Gifu,中部地方
22,Shizuoka,中部地方
23,Aichi,中部地方
24,Mie,関西地方
25,Shiga,関西地方
26,Kyoto,関西地方
27,Osaka,関西地方
28,Hyogo,関西地方
29,Nara,関西地方
30,Wakayama,関西地方
31,Tottori,中国地方
32,Shimane,中国地方
33,Okayama,中国地方
34,Hiroshima,中国地方
35,Yamaguchi,中国地方
36,Tokushima,四国地方
37,Kagawa,四国地方
38,Ehime,四国地方
39,Kochi,四国地方
40,Fukuoka,九州地方
41,Saga,九州地方
42,Nagasaki,九州地方
43,Kumamoto,九州地方
44,Oita,九州地方
45,Miyazaki,九州地方
46,Kagoshima,九州地方
47,Okinawa,沖縄地方
上のCSVをDBFSにアップロードします。
# 拡張用のデータを読み込みます
augment_df = spark.read.csv("dbfs:/FileStore/shared_uploads/takaaki.yayoi@databricks.com/pref_augment.csv", header=True)
display(augment_df)
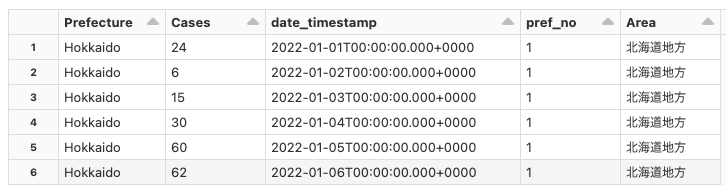
元のデータと拡張用のデータを結合(join)します。
# 結合キーはPrefecture、内部結合(inner join)します
final_df = df.join(augment_df, on="Prefecture", how="inner")
display(final_df)
データのロード(Load)
これでデータの準備が整いました。ETL(Extract-Transform-Load)で言うところのTransformまでが終わった形になります。最後にBIなどでこのデータを活用できるようにデータベースにロードします。
import re
from pyspark.sql.types import *
# ログインIDからUsernameを取得
username_raw = dbutils.notebook.entry_point.getDbutils().notebook().getContext().tags().apply('user')
# Username の英数字以外を除去し、全て小文字化。Username をファイルパスやデータベース名の一部で使用可能にするため。
username = re.sub('[^A-Za-z0-9]+', '', username_raw).lower()
# データベース名
db_name = f"japan_covid_{username}"
# Hiveメタストアのデータベースの準備:データベースの作成
spark.sql(f"DROP DATABASE IF EXISTS {db_name} CASCADE")
spark.sql(f"CREATE DATABASE IF NOT EXISTS {db_name}")
# Hiveメタストアのデータベースの選択
spark.sql(f"USE {db_name}")
print("database name: " + db_name)

# データベースに登録
final_df.write.format("delta").mode("overwrite").saveAsTable("covid_cases")
データベースに登録すると、SQLで簡単にアクセスできるようになります。
%sql
SELECT * FROM japan_covid_takaakiyayoidatabrickscom.covid_cases
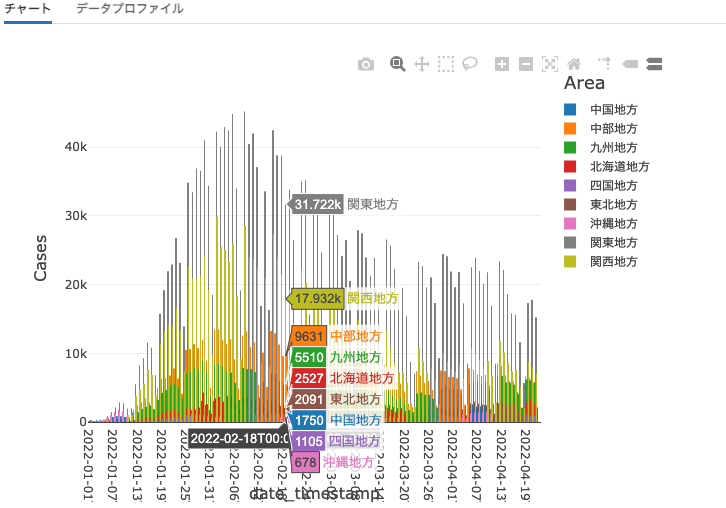
注意
上のコマンドでは可視化の設定を行なっています。Databricksノートブックでは取り扱っているデータを簡単に可視化することができます。
これでDE君はBA君の必要としているデータを準備できました。
- DE君: ふう、これでBA君の要望に応えられるかな。
- BA君: ありがとう!これでダッシュボードを作れるよ!
注意
今回は一度限りの処理を行いましたが、当然データは日々更新されます。入力データの更新に合わせて、上の処理を行うようにジョブ化して定期実行することを検討することになります。Databricksではジョブもサポートしています。
(ビジネスアナリスト)BA君の取り組み
-
BA君: さすがDE君、あっという間にETLを終わらせてくれた。今度は自分の番だな。まずは、Databricks SQLにアクセスしてと。
-
(以降はBA君のセリフ) よしよし。DE君が準備してくれた
covid_casesテーブルがあるな。
-
これに対するSQLクエリーを書こう。ちょっと年月でも集計したいからロジックを追加してと。
SQLSELECT *, date(date_timestamp) AS Date, month(date_timestamp) AS Month, year(date_timestamp) AS Year, concat( year(date_timestamp), "-", RIGHT(concat("0", month(date_timestamp)), 2) ) AS YearMonth FROM japan_covid_takaakiyayoidatabrickscom.covid_cases ORDER BY pref_no ASC; -
よし、結果も問題ないな。
-
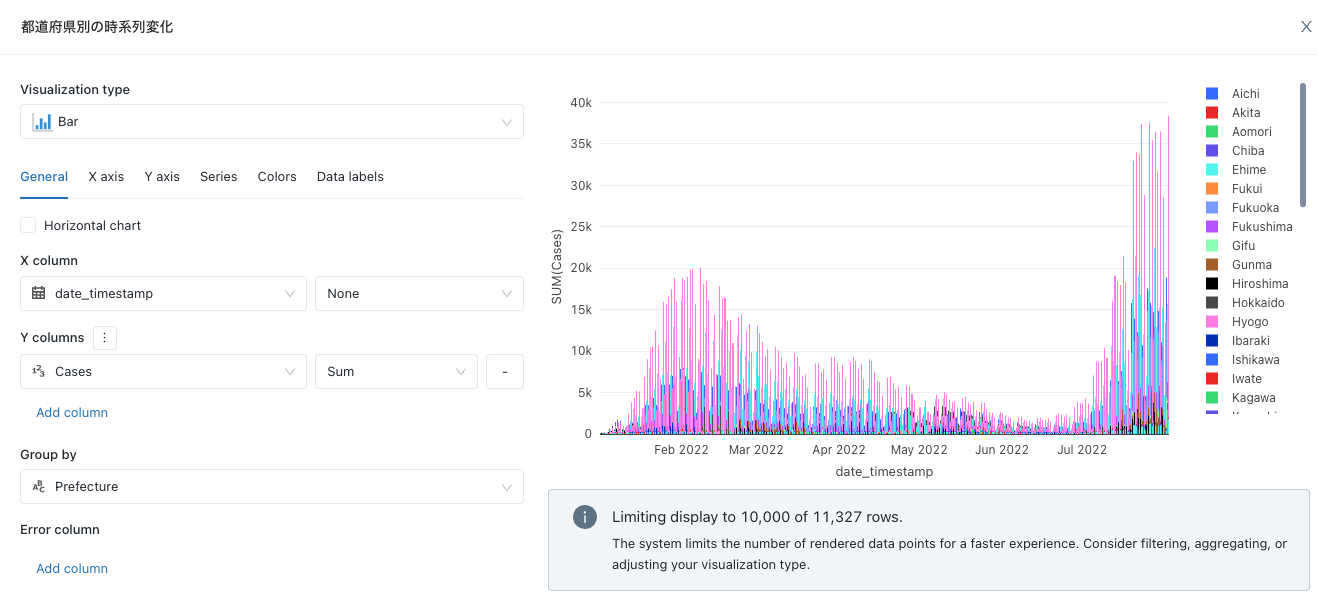
時系列変化から見ていこうか。都道府県別に集計して棒グラフにしてと。
-
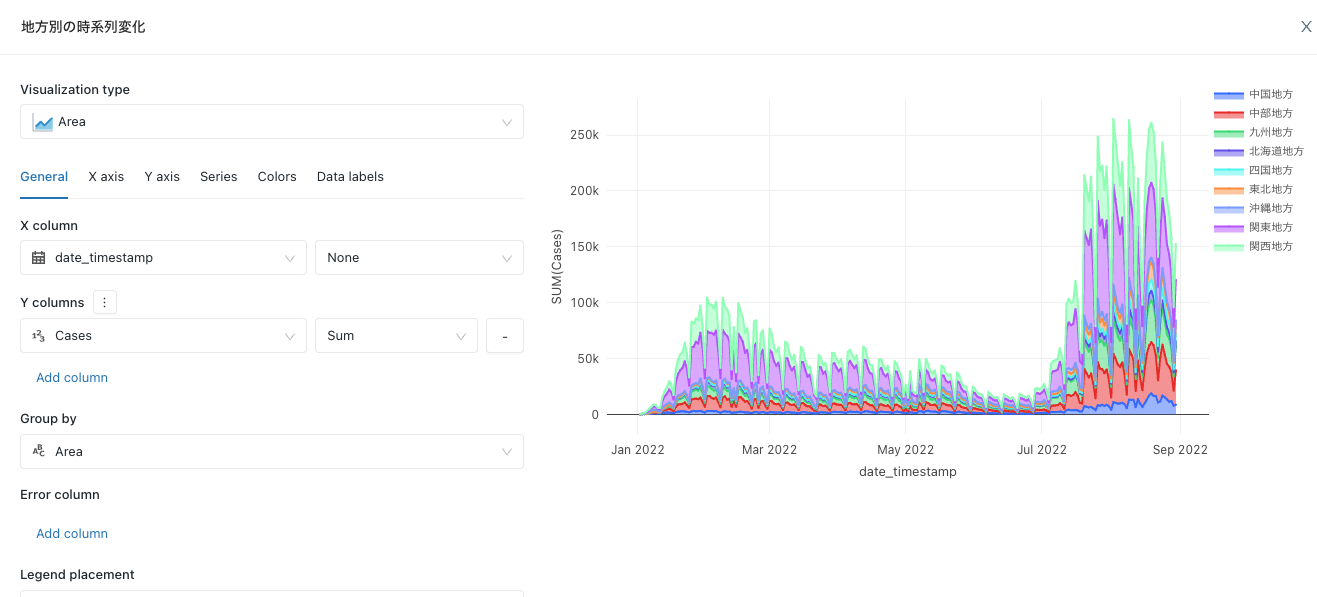
うーん、都道府県レベルだと細かすぎるか。地方レベルにしてみよう。
-
こっちの方が傾向がわかりやすいな。
-
次は地図にマッピングしてみよう。
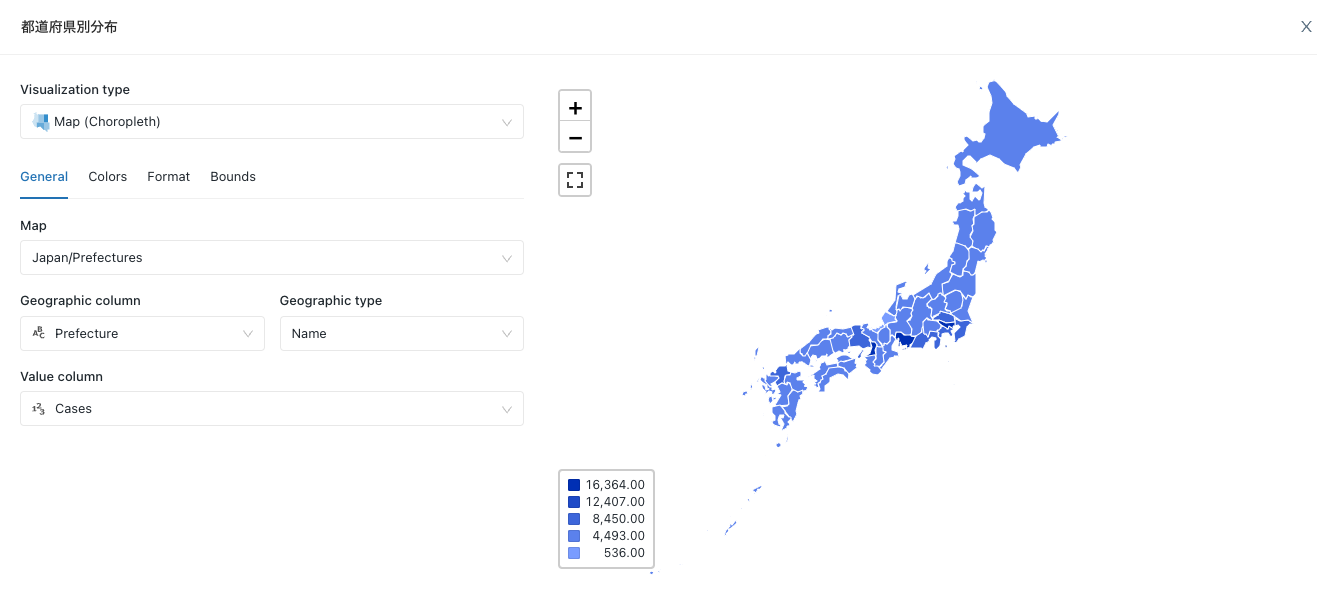
-
まあ、傾向はニュースの通りだな。
-
他にはヒートマップも作ってみよう。
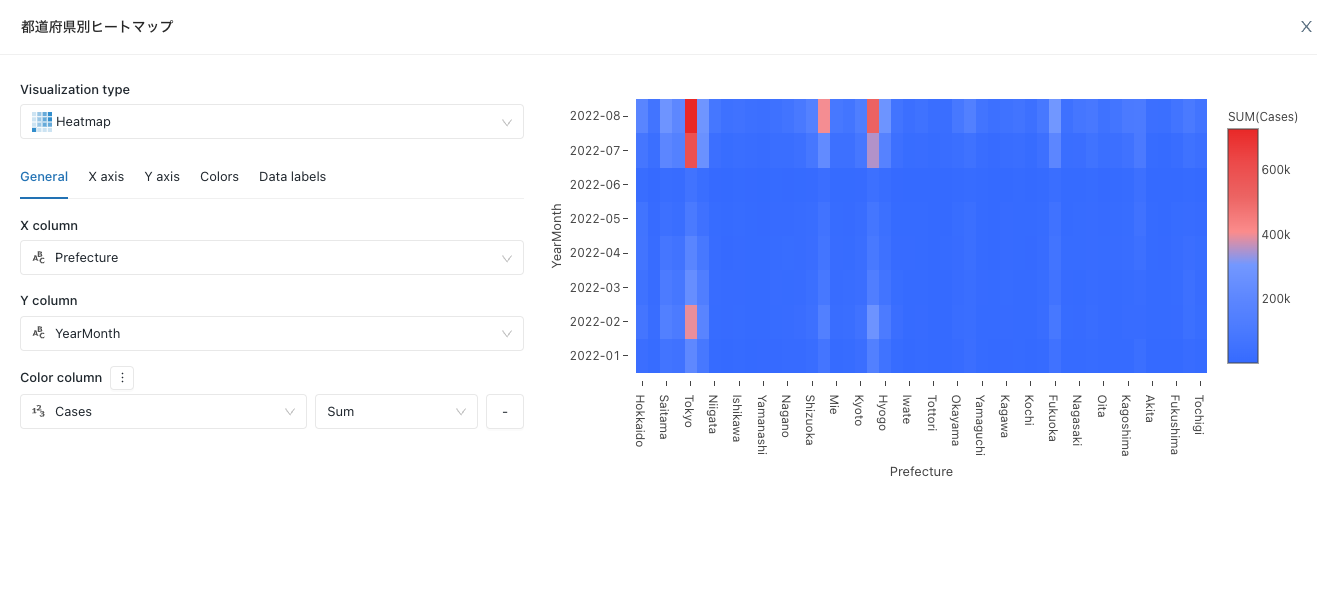
-
これで大体パーツは揃ったかな。これらをダッシュボードにまとめよう。
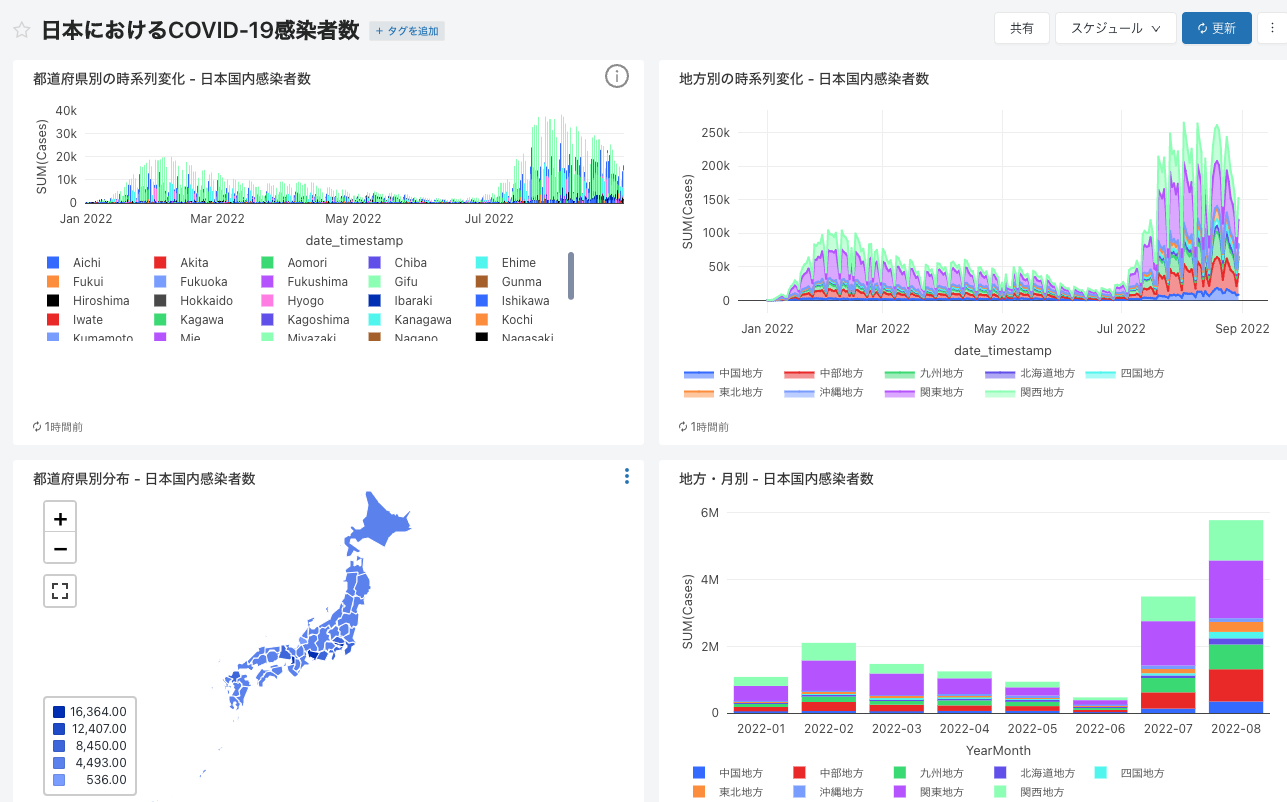
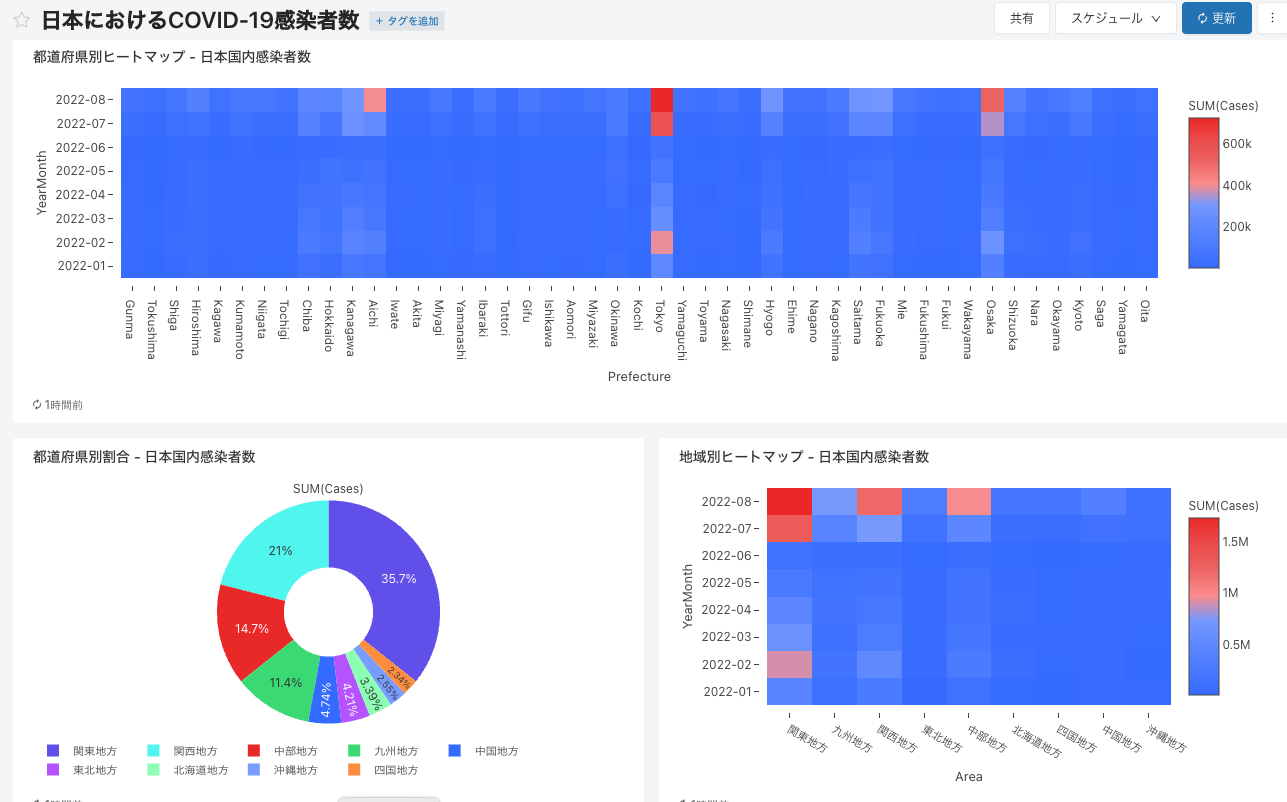
-
よし、これを偉い人に見せにいこう!
このように、ビジネスアナリストはデータ集計を通じて様々な観点からデータを可視化することで洞察を得ることになります。
- BA君: これでどうでしょう?
- 偉い人: おおー、素晴らしい!私が見たかった観点も盛り込まれているよ。さすがだね!
- BA君: ありがとうございます。
- 偉い人: ....
- BA君: どうしました?
- 偉い人: こうやって傾向が分かるとさ、今後どうなっていくか気にならない?
- BA君: えっ!まあ、確かに。
- 偉い人: ちょっとさ、DS君やDE君と相談して予測結果を出してくれない?
- BA君: ええーー!!
データエンジニアリング再び
上長から「予測をできないか」と言われたビジネスアナリストから相談を受けて、「それならDS君にAutoMLを実施してもらおう!」となりました。
ここでは、デモのため予測に用いるデータを東京都に限定します。この際もデータをコピーするのではなくビューを作成します。これによってビュー経由でも最新のデータを参照することができます。
%sql
CREATE VIEW japan_covid_takaakiyayoidatabrickscom.covid_cases_for_forecast
AS SELECT * FROM japan_covid_takaakiyayoidatabrickscom.covid_cases WHERE Prefecture="Tokyo"
(データサイエンティスト)DS君の取り組み
-
DS君: BA君も追加の要求が出てきて災難だったな。ここは、自分がDatabricks AutoMLを使ってチャチャっと予測をしてしまおう。
-
(以降はDS君のセリフ) 今回解く問題は予測なので予測を選択してと。
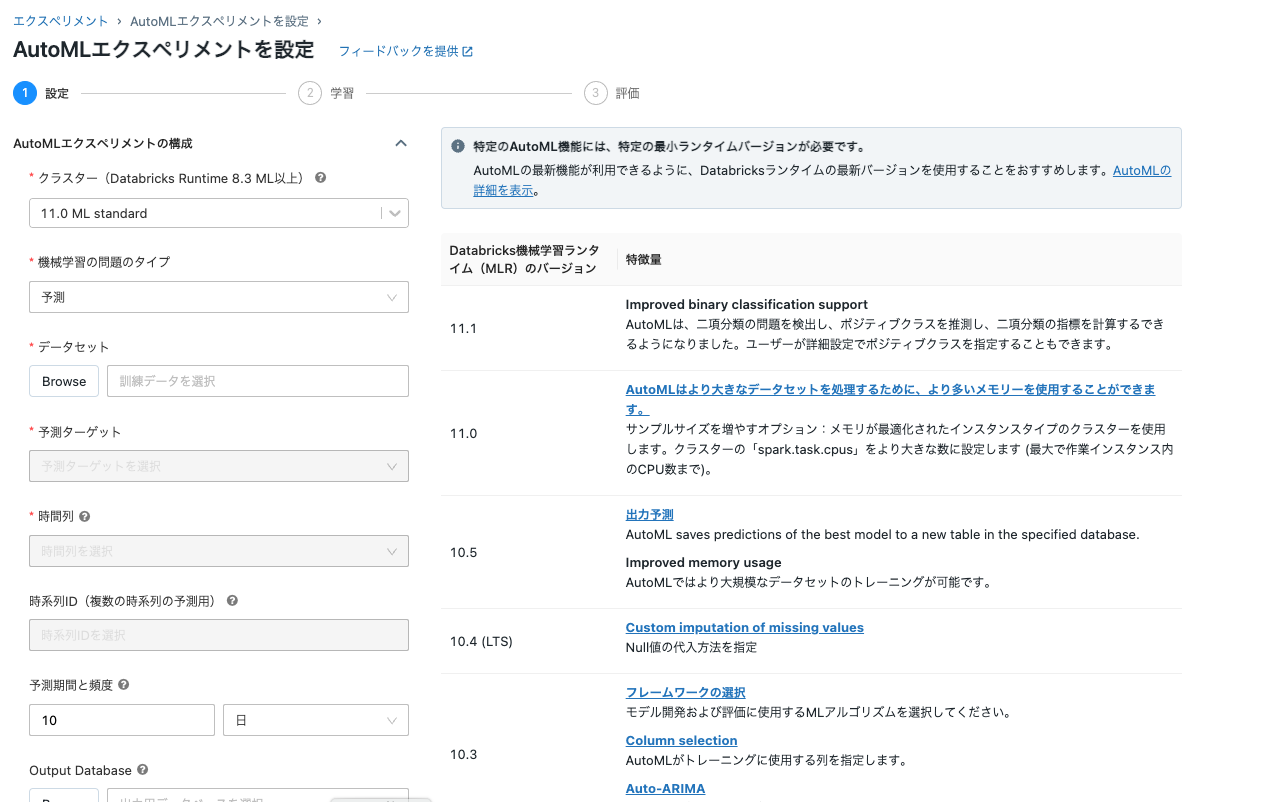
-
今回は東京都の予測だけで良いそうなので、DE君が作ってくれたビュー
covid_cases_for_forecastを使おう。
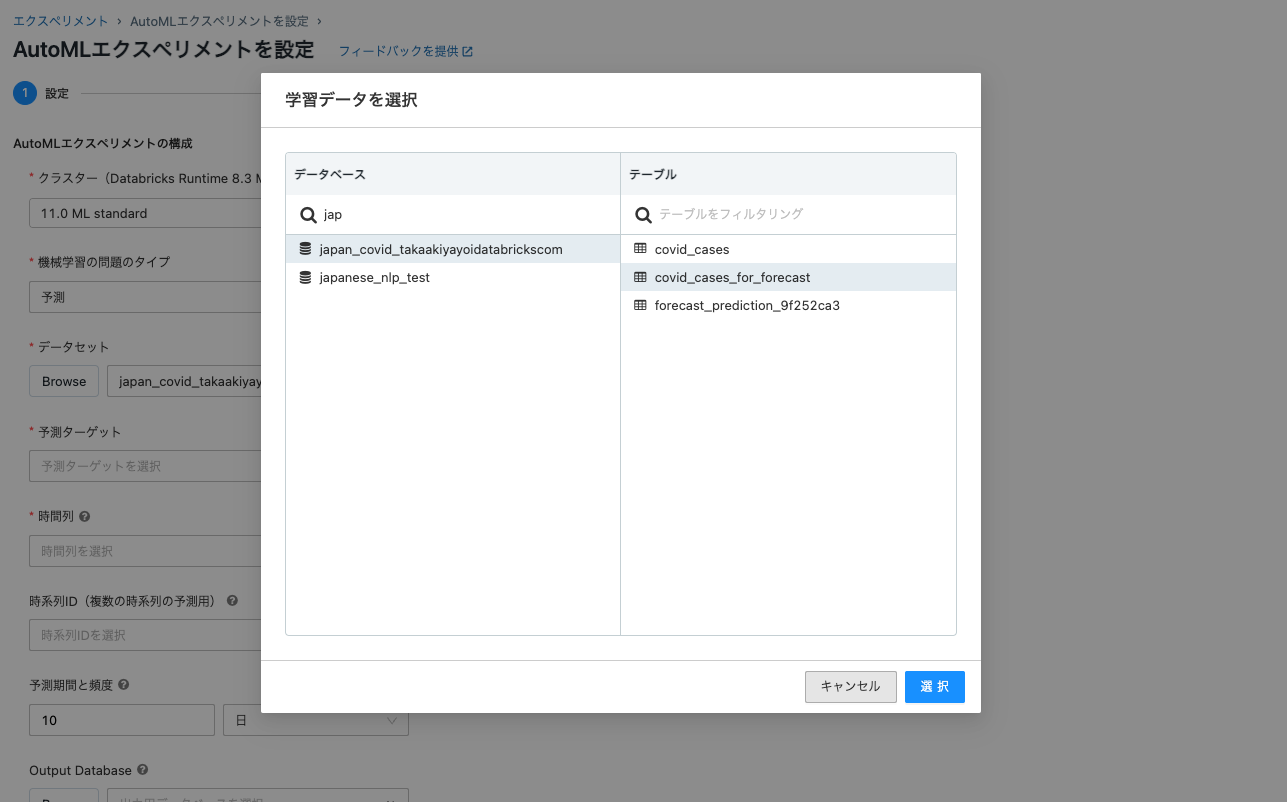
-
その他のパラメータを指定して、AutoMLを開始っと。
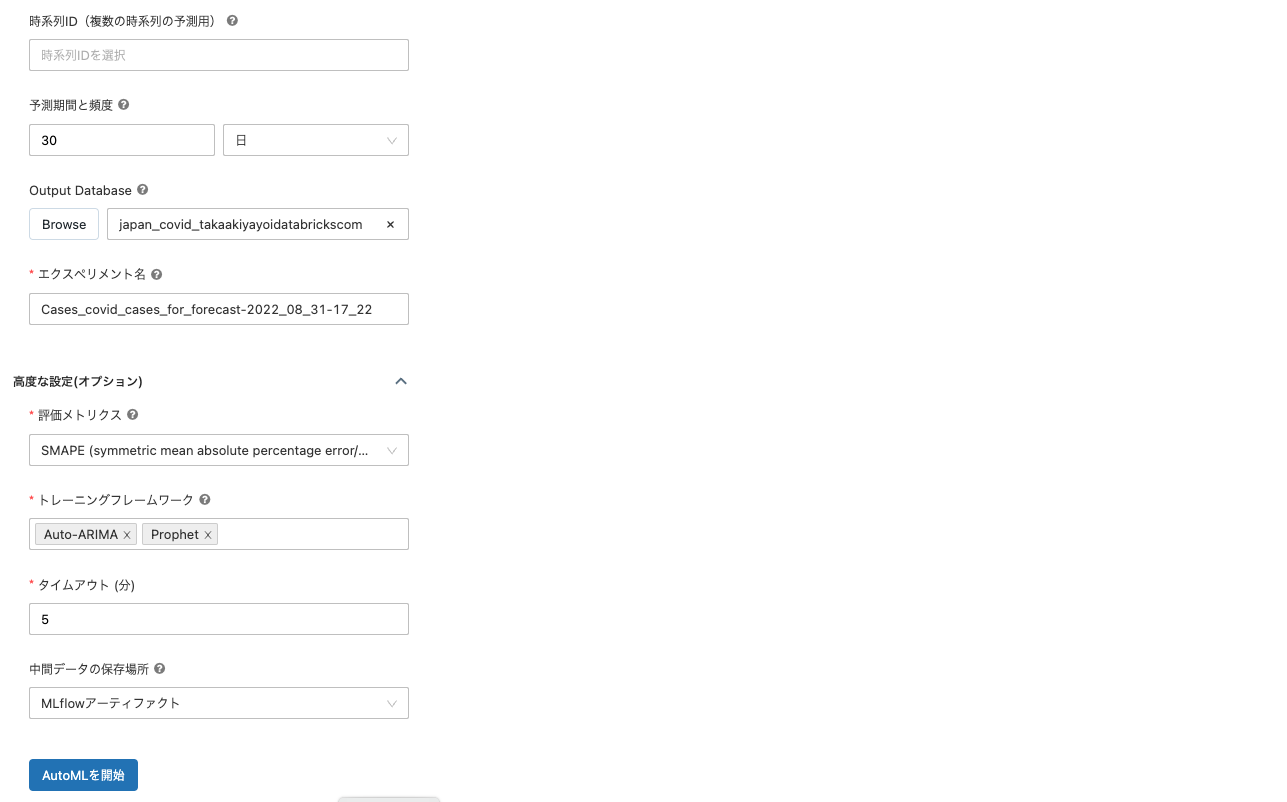
注意
ここではデモのため、トレーニング時間を短く設定しています。実際にご利用する際には、精度を高めるためにデフォルト値など十分に長い時間を設けてください。
- これでトレーニング、ハイパーパラメータチューニング、モデルのロギングなど全ての処理が自動で行われるから便利な世の中になったものだ。
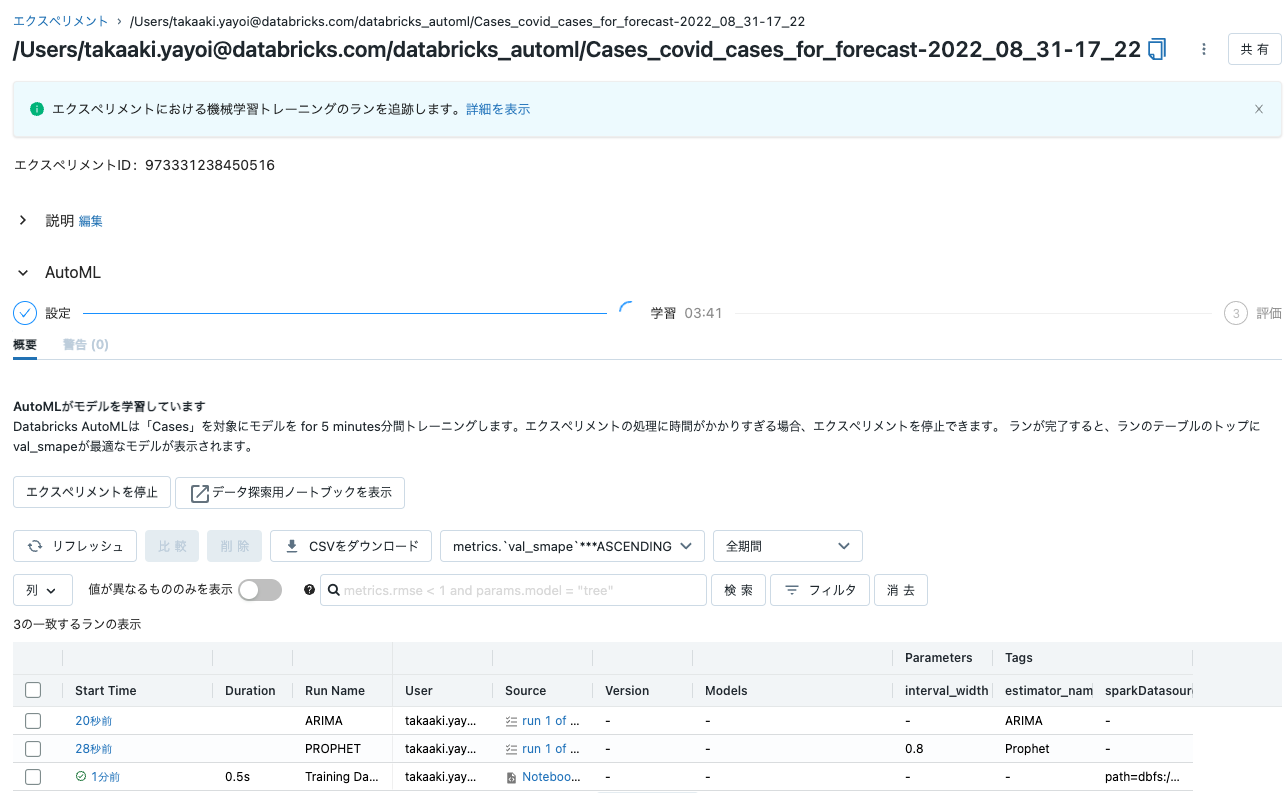
- よし、AutoMLの処理が完了した。
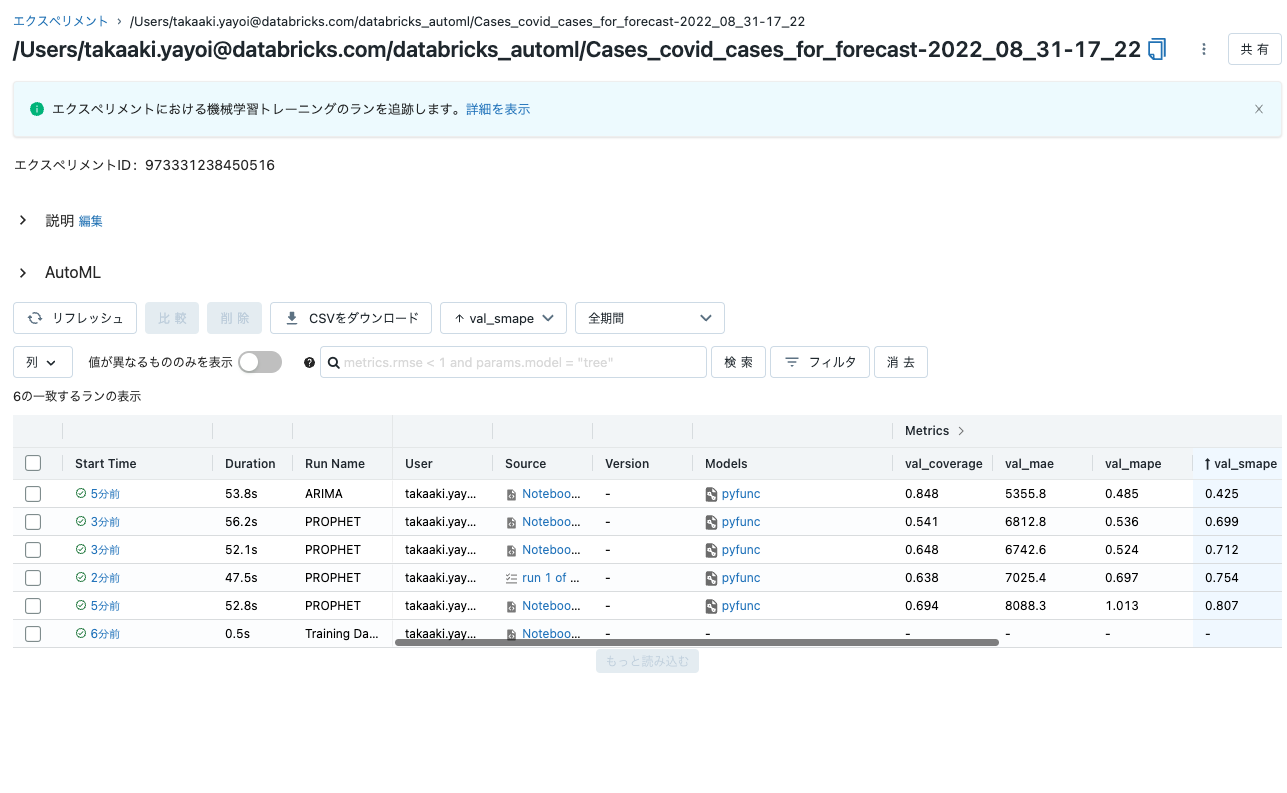
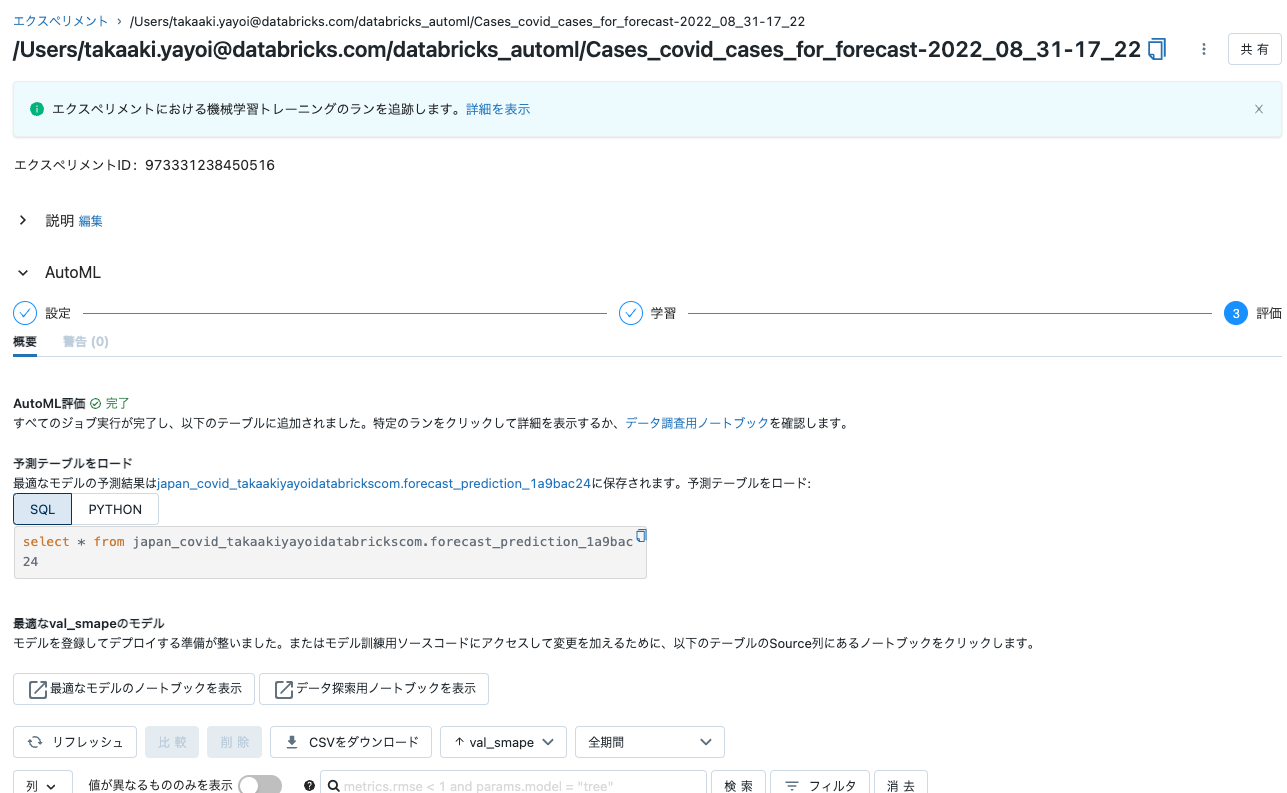
-
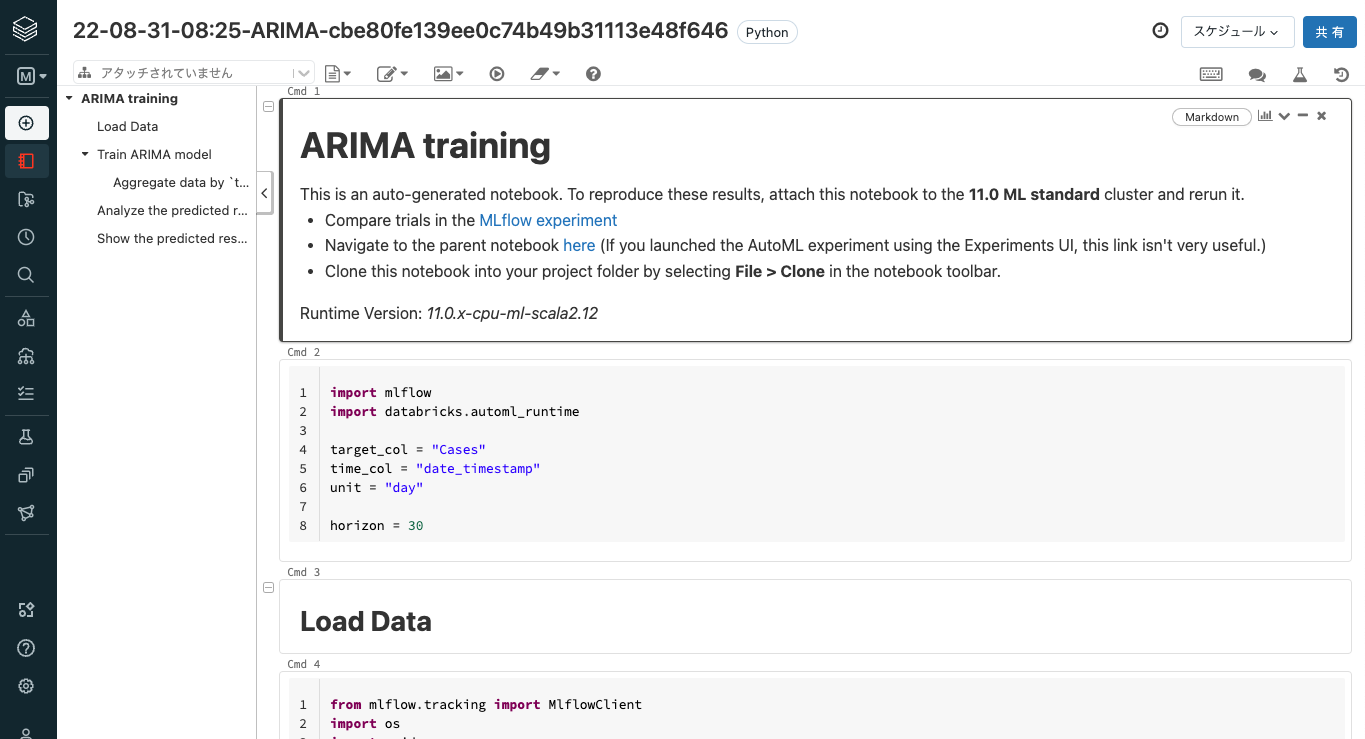
最適なモデルのノートブックを表示をクリックすれば、一番パフォーマンスが良かったモデルがどのように作られたのかも確認できるんだよな。これがガラスボックスアプローチのAutoMLの良いところだ。途中の処理が把握できるし、仮にカスタマイズが必要になってもPythonコードを書き換えるだけで良いんだから。
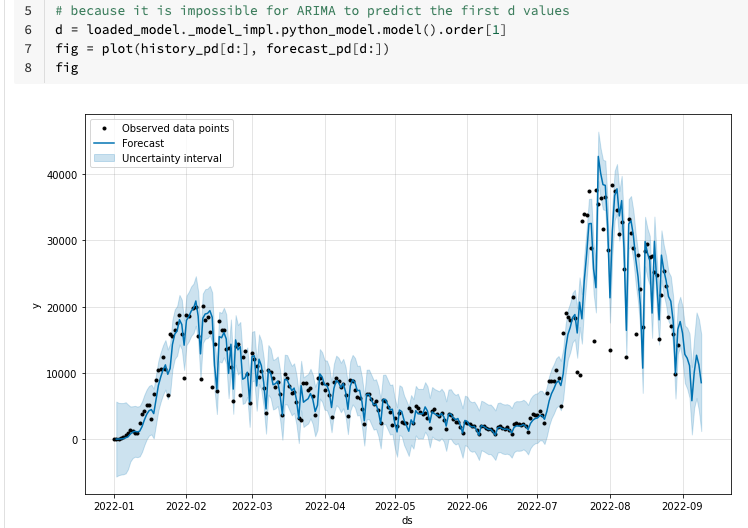
- この結果を見ると減少傾向が続きそうだな。BA君と一緒に偉い人に報告に行こう。予測結果もデータベースに格納されているから、ダッシュボードにしてほしいと言われても大丈夫だし。
注意
今回はAutoMLを活用しましたが、もちろんノートブック上で独自のロジックを記述して分析や機械学習モデルの構築を行うことも可能です。
まとめ
このように、データや機械学習に対する様々な要件に対して、ビジネスアナリスト・データエンジニア・データサイエンティストが一つのプラットフォーム、一つのデータを活用して色々な取り組みを行えるのがDatabricksのレイクハウスです。
ETL処理、BIダッシュボードの構築、機械学習モデルの活用すべてのケースにおいて、さまざまなペルソナが一貫性を持って物事を進めることができると感じていただけたら幸いです。
こちらのシナリオでは、データエンジニアリング、ビジネスアナリティクス(BI)、データサイエンスという一連のプロセスを説明しましたが、このプロセス自体一回きりということではありません。データは日々生成されるので、このプロセスもそれに合わせて繰り返すのが普通です。レイクハウスなら、このプロセス全体を完全に自動化することすら可能なのです。
- Databricksレイクハウスとは何か?
- Databricksのメダリオンレイクハウスアーキテクチャとは?
- 信頼できる唯一の情報源(single source of truth)の構築は何を意味するのか?
- レイクハウスはどのようにしてディスカバリーとコラボレーションを改善するのか?
上でウォークスルーしたノートブックはこちらです。