初めてDatabricks SQLを使い始める方向けに資料をまとめました。
Databricks SQLとは
Databricks SQLは、クイックなアドホッククエリーを実行し、異なる視点からクエリーの結果を探索するために複数のビジュアライゼーションを作成し、ダッシュボードを構築し、共有したいと考えているSQLユーザーに対してシンプルな体験を提供します。
もし、あなたのメインタスクでSQLクエリーやBIツールを使っているのであれば、Databrikcs SQLはお使いのデータレイクに格納されているデータを用いて、アドホックなクエリーを実行し、ダッシュボードを構築するための直感的な環境を提供します。

Databricks SQLの主な機能
- SQLウェアハウス: Databricks SQLで使用する計算資源です。Databricksクラスターと同様にお客様のクラウドアカウントに構築するデータプレーンで動作するクラシックSQLウェアハウスと、Databricks管理のクラウドアカウントで動作するサーバレスSQLウェアハウスを利用することができます。
- クエリー: お客様のデータレイクに格納されているデータに対して問い合わせを行うSQLです。
- ビジュアライゼーション: クエリーの結果を可視化したものです。さまざまなビジュアライゼーションのタイプを提供しています。
- ダッシュボード: ビジュアライゼーションを組み合わせてダッシュボードを構築します。
- アラート: クエリーから返却された値が閾値を超えた際にメールなどで通知を行います。
アナリストによるDatabricks SQLの一般的な使い方は以下のようなものとなります。通常ステップ2からステップ5は試行錯誤を伴う繰り返しの作業となります。
- データをアップロードする。(管理者が準備するケースもあります)
- クエリーを実行するなどしてデータを理解する。
- 目的を踏まえて解析(抽出、集計、並び替えなど)の切り口を考える。
- 切り口に応じたクエリーを記述して実行する。
- クエリー実行結果をどのように可視化するのかを考えて可視化を行う。(ビジュアライゼーションの作成)
- 可視化を組み合わせてダッシュボードを作成する。
- ダッシュボードを公開する。
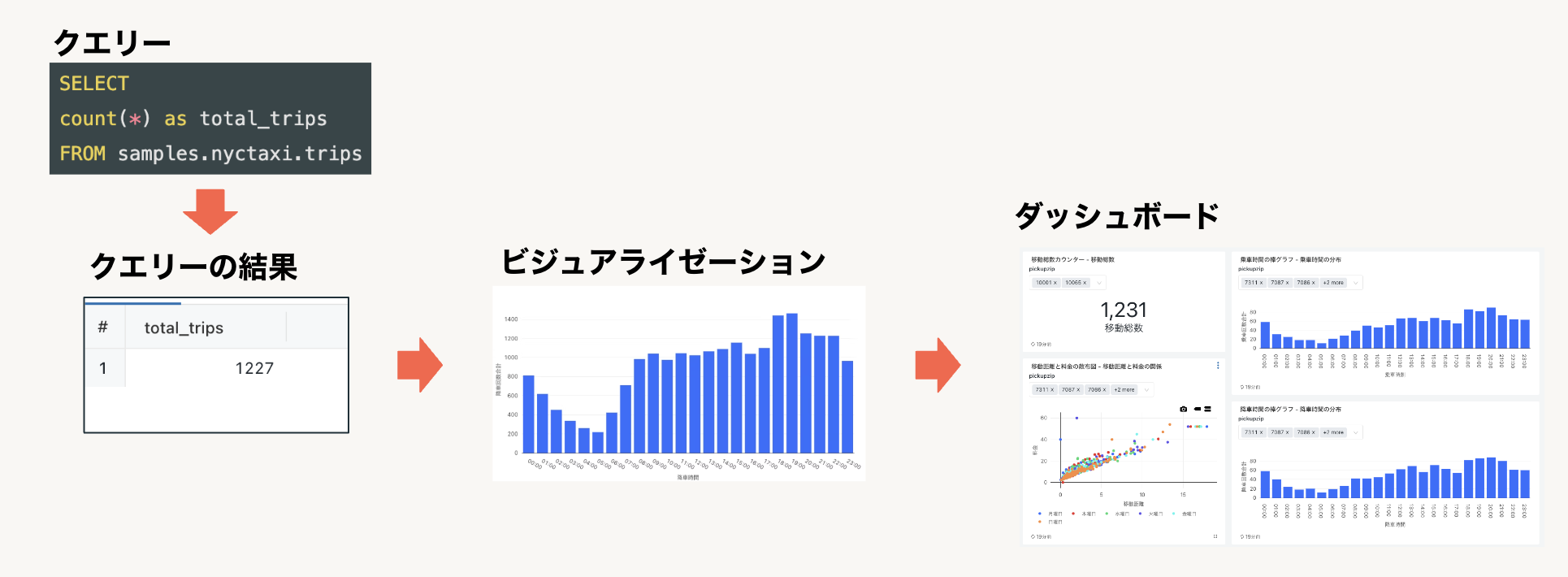
Databricks SQLの使い方
以下では、管理者とアナリストがどのようにDatabricks SQLを使用するのかを、サンプルのシナリオに沿って説明します。権限さえあれば、アナリストが管理者のタスクを行うことも可能です。
まず最初に言語設定を行なってから、Databricks SQLにアクセスします。
-
Databricksにログインし、サイドメニューからSettings > User Settingsを開きます。
-
Language Settingsタブをクリックします。
-
Change Your Languageから言語を選択します。
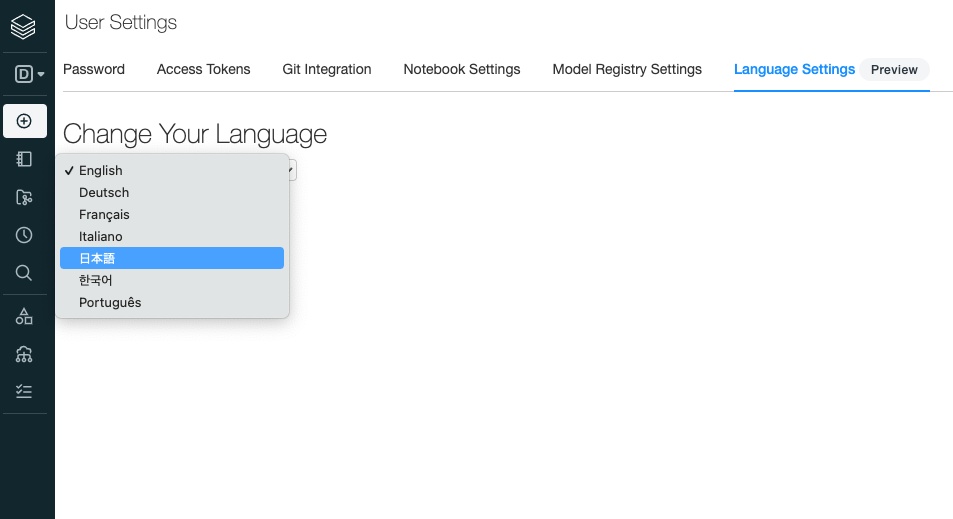
以下の言語がサポートされています。
- 英語
- ドイツ語
- フランス語
- イタリア語
- 日本語
- 韓国語
- ポルトガル語
-
言語を選択すると画面がリフレッシュされ、GUIが選択した言語で表示されます。
-
サイドメニューのペルソナスイッチャーでSQLを選択し、Databricks SQLにアクセスします。

管理者がDatabricks SQLを使う
ここでは、管理者が以下のタスクを行うものとします。アナリストの方はアナリストがDatabricks SQLを使うまでスキップしてください。
テーブルの作成
以下の作業を行うことでテーブルを作成します。
-
Databricks SQLにアクセスするとランディングページが表示されます。

-
サイドメニューで作成 > クエリーを選択します。

-
右上のドロップダウン(以下の図の赤枠)で稼働中のSQLウェアハウスを選択します。存在しない場合にはSQLウェアハウスを作成します。
画面の左側にあるスキーマブラウザにデータベース・テーブルの一覧が表示され、右上のSQLエディタにSQLクエリーを記述して実行します。右下にはクエリーの結果が表示されます。

-
以下のクエリーをSQLエディタに貼り付けます。
SQLCREATE TABLE default.db_handson_people10m OPTIONS (PATH 'dbfs:/databricks-datasets/learning-spark-v2/people/people-10m.delta') -
すべてを実行をクリックします。

-
クエリーが成功すると
...was successfully executed.というメッセージが右下に表示されます。

-
スキーマを更新するには、スキーマブラウザの下にある
 ボタンをクリックします。
ボタンをクリックします。 -
データベースの右にあるテキストボックスに
peoと入力します。スキーマブラウザは新たに作成したテーブルを表示します。

-
上で作成したクエリーを保存しておきたい場合には、
New queryの箇所をクリックしてクエリーの名前を入力し、保存ボタンを押します。

テーブルのアクセス権の設定
こちらでは、データエクスプローラのUIを用いてアクセス権を設定します。上述したSQLエディタからも設定することが可能です。
- サイドバーの
 データをクリックします。
データをクリックします。 - 右上のドロップダウンリストで、Starter WarehouseのようなSQLウェアハウスを選択します。
defaultデータベースが選択されます。データベースのコメントとオーナーが表示されます。

-
権限タブをクリックします。

- 付与ボタンをクリックします。
- テキストボックスをフォーカスし、
All Usersを選択します。 -
USAGEチェックボックスをチェックします。

-
付与ボタンをクリックします。

-
defaultデータベースの後のテキストボックスにpeoと入力します。データエクスプローラにdb_handson_people10mテーブルが表示されますので選択します。

-
権限タブをクリックします。

- 付与ボタンをクリックします。
- テキストボックスをフォーカスし、
All Usersを選択します。

-
SELECTとREAD_METADATAチェックボックスをチェックします。

-
付与ボタンをクリックします。

SQLウェアハウスの作成およびアクセス権の設定
上でテーブルを作成する際にSQLウェアハウスにアナリストがアクセスできるようにします。
注意
複数人でSQLウェアハウスをシェアする場合には、十分なスペックであるかを確認してください。
- サイドメニューからSQLウェアハウスにアクセスします。

- 作成済みのSQLウェアハウスを共有するのであれば、ウェアハウス名をクリックします。新規に作成する際には右上のSQLウェアハウスを作成ボタンをクリックしてSQLウェアハウスを作成します。ここでは作成済みのSQLウェアハウスに権限を付与します。右上の権限ボタンをクリックします。

- テキストボックスをフォーカスし
All Usersを選択します。

-
使用可能が選択されていることを確認して追加をクリックします。

- これでアナリストがSQLウェアハウスを利用(ウェアハウスの起動、SQLの実行)できるようになりました。

以上で管理者の作業は終了です。
アナリストがDatabricks SQLを使う
ここでは、アナリストが以下のタスクを行うものとします。
テーブルにクエリーを実行
初回にDatabricks SQLにアクセスすると以下のような画面が表示されます。

チュートリアルを試しても構いませんが、ここでは上のステップで管理者が準備してくれたテーブルを操作していきます。
ここでは、人々の情報を格納したテーブルから、Maryという名前の女性を生まれた年でグルーピングし、グループごとの数をカウントし結果を可視化します。
テーブルのカラムは、id、firstName、middleName、lastName、gender、birthDate、ssn、salaryとなります。
-
管理者がアクセス権を付与したSQLウェアハウスが表示されています。SQLウェアハウス起動していない場合には開始ボタンをクリックしてSQLウェアハウスを起動します。
-
状態が開始中から実行中になるまで待ちます。

-
上述の通り、すでに管理者が
db_handson_people10mというテーブルを作成しています。ここでは、このテーブルにクエリーを実行し、Maryという名前のすべての人の誕生日と誕生年を表示します。 -
サイドバーで
 作成をクリックしクエリーを選択すると、SQLエディタが表示されます。
作成をクリックしクエリーを選択すると、SQLエディタが表示されます。 -
上で起動したSQLウェアハウスを選択します。

-
Maryという名前の女性の数をクエリーする以下のSELECT文をSQLエディタに貼り付けます。SQLSELECT year(birthDate) as birthYear, count(*) AS total FROM default.db_handson_people10m WHERE firstName = 'Mary' AND gender = 'F' GROUP BY birthYear ORDER BY birthYear
-
すべてを実行ボタンをクリックします。通知の許可を求めるプロンプトが表示された際には許可します。
-
クエリーの結果が右下に表示されます。

デフォルトでは最大1000行が返却されます。より多くの行を取得したい場合には、チェックボックスの選択を解除し、クエリーにLIMIT句を指定します。

-
クエリーを保存するにはNew Queryの箇所をクリックし、名前を入力して保存をクリックします。

ビジュアライゼーションを作成
- 結果を表示しているTableの右にある + をクリックし、Visualizationを選択します。

ビジュアライゼーションエディタが表示されます。
- ビジュアライゼーションの名前を誕生年ごとのMaryさんの人数に変更します。左上の
Scatter 1をクリックすると名前を変更することができます。 - Visualization TypeドロップダウンでBarを選択します。
- X ColumnドロップダウンでbirthYearを選択します。
- Y Columnドロップダウンでtotalを選択します。
- X Axisタブをクリックします。
- Nameフィールドに
誕生年と入力します。 - Y Axisタブをクリックします。
- Nameフィールドに
誕生年ごとのMaryさんの人数と入力します。 -
保存をクリックします。
保存したグラフがSQLエディタに表示されます。

- 最後にクエリーの保存ボタンをクリックします。
ここまでのステップでクエリー、ビジュアライゼーションを作成しました。最後のダッシュボード作成のステップではこれらを参照してダッシュボードを構築します。
ダッシュボードの作成
- サイドバーの作成をクリックしダッシュボードを選択します。
- ダッシュボード名として
Peopleと入力します。わかりやすい別の名前をつけても構いません。 - 保存をクリックします。
- ダッシュボードが表示されますが、この時点では何も表示されません。

- 追加ドロップダウンをクリックし、可視化を選択します。
- クエリーを選択する画面が表示されるので、上のステップで作成したクエリーを選択します。

- クエリーに属しているビジュアライゼーションを選択します。Select existing visualizationが選択されている状態で、下のドロップダウンから追加したいビジュアライゼーションを選択します。

-
ダッシュボードに追加をクリックします。これでダッシュボードにビジュアライゼーションが追加されます。

- 他のビジュアライゼーションを追加する場合には、上の作業を繰り返します。
- 追加したビジュアライゼーションはドラッグ&ドロップでサイズや位置を調整できます。

- レイアウトに満足したら右上の編集完了をクリックします。これで初めてのダッシュボードの完成です!

次のステップ
アナリスト向け
- Databricks SQLのコンセプト
- Databricks SQL : ユーザー向けクイックスタート
- Databricks SQLクイックスタート:サンプルダッシュボードギャラリーからダッシュボードをインポートしてDatabricks SQLを学ぶ
- Databricks SQLのダッシュボード
- Databricks SQLにおけるテーブルの作成
- ADLSにあるデータを使ってDatabricks SQLでダッシュボードを作成する
管理者向け
- Databricks SQL : 管理者向けクイックスタート
- Databricks SQL管理者クイックスタート:Databricks SQLのオンボーディングタスク
- Databricks SQLウェアハウスとは?
- Databricks SQLのセキュリティモデルとデータアクセスの概要