この情報は古くなっています。マニュアルや[2024年版] DatabricksにおけるAWS PrivateLinkのバックエンド接続の設定(実践編)を参照ください。
本書は、DatabricksにおけるAWS PrivateLinkの有効化に記載されているバックエンド接続の設定手順をまとめたものとなっています。
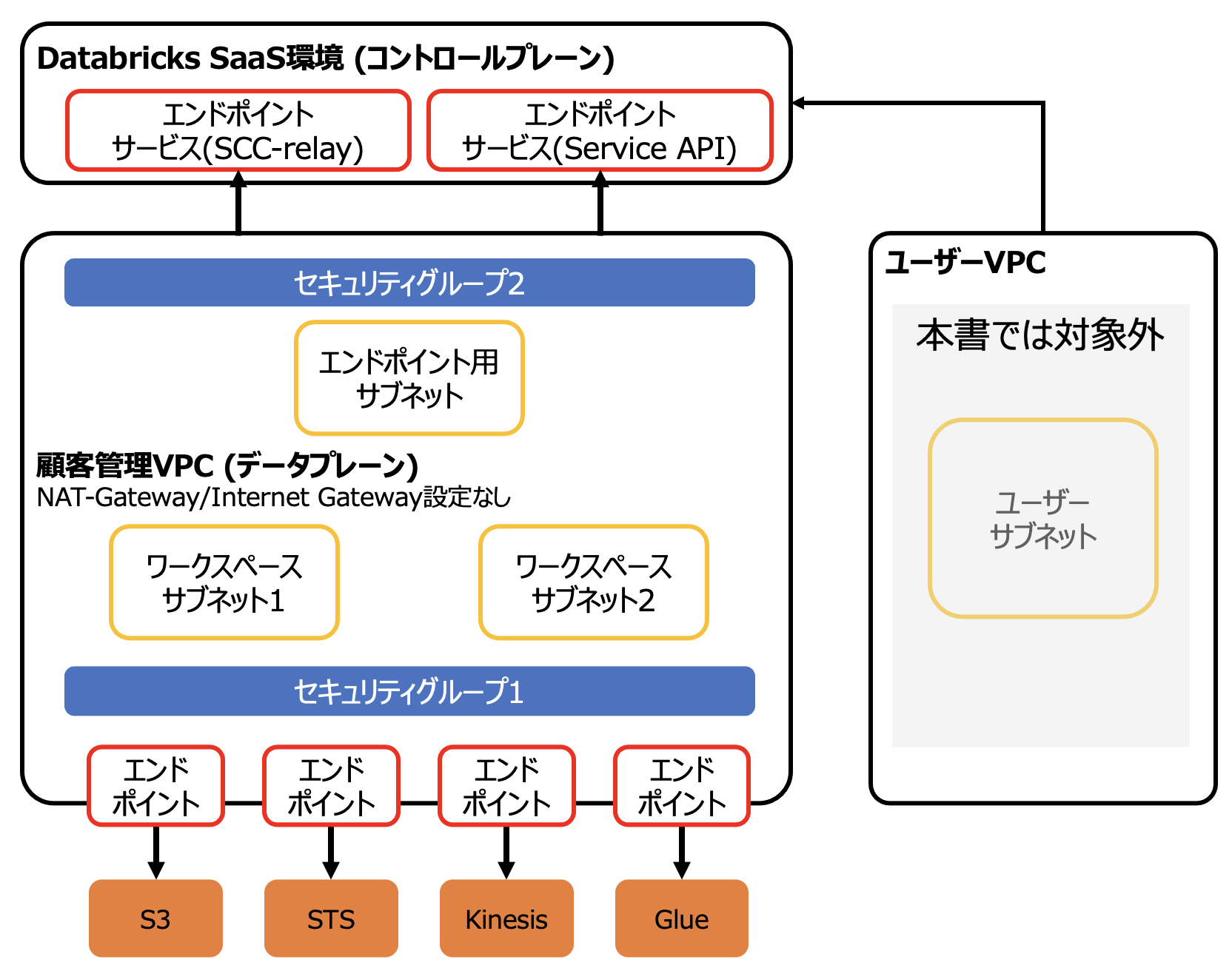
全体構成
本書でDatabricksをセットアップするVPCはインターネットに接続されていないクローズドネットワーク環境であり、外部との通信は全てエンドポイント経由で構成する環境を想定しております。本書で示しているものはあくまで一例です。お客様の要件に応じて構成を変更してください。
AWS PrivateLinkを用いることで、公衆ネットワークを経由することなしに、AWS VPCやオンプレミスのネットワークからAWSサービスへのプライベート接続を実現することができます。E2バージョンプラットフォーム上のDatabricksワークスペースでは、以下の2つのタイプのPrivateLink接続をサポートしています。
- フロントエンド(ユーザーからワークスペースへの接続): フロントエンドPrivateLink接続によって、ユーザーはVPCインタフェースエンドポイント経由でDatabricksのwebアプリケーション、REST API、Databricks Connect APIに接続することができます。
- バックエンド(データプレーンからコントロールプレーンへの接続): 顧客管理VPCのDatabricksランタイムクラスター(データプレーン)は、DatabricksクラウドアカウントにあるDatabricksワークスペースのコアサービス(コントロールプレーン)に接続します。クラスターは2つの目的でコントロールプレーンに接続します:REST APIとセキュアクラスター接続のリレーです。このタイプのPrivateLinkでは、二つの異なるサービスを使用するため、二つの異なるVPCインタフェースエンドポイントが必要となります。
本書では以下の構成を想定しています。ユーザー側からDatabricksの接続でもPrivateLinkを使用するフロントエンド接続に関しては、DatabricksにおけるAWS PrivateLinkの有効化、およびDatabricksにおけるAWS PrivateLinkのフロントエンド接続の設定(実践編) をご覧ください。
参考資料
- Databricksアカウントのセットアップとワークスペースのデプロイメント - Qiita
- Databricksにおける顧客管理VPC - Qiita
- DatabricksにおけるAWS PrivateLinkの有効化 - Qiita
- Databricksワークスペース(E2)作成時のトラブルシューティング - Qiita
- Use AWS Glue Data Catalog as the metastore for Databricks Runtime | Databricks on AWS
全体の流れ
- 事前準備
- クロスアカウントIAMロールの作成
- クレデンシャル設定情報の登録
- S3バケットの設定
- 顧客管理VPCの作成
- PrivateLinkの設定
- PrivateLinkの有効化 Databricksがお客様のE2、AWSアカウントを有効化し、ワークスペースエンドポイントサービス、リレーエンドポイントサービスにアクセスできるようにする。(プレビュー期間はマニュアルの操作)
- VPCエンドポイントの作成 お客様がワークスペース、リレーエンドポイントサービスに対して、ユーザー・ワークスペース間、DP・CP間のためのVPCエンドポイントを作成する。
- VPCエンドポイントの登録 お客様がE2 Account APIを用いて、VPCエンドポイントをDatabricksに登録する。
- プライベートアクセス設定オブジェクトの作成 お客様が(ワークスペースに対するプライベート/パブリックアクセスを決定した後で)E2 Account APIを用いて「プライベートアクセス設定」オブジェクトを作成する。
- ネットワークオブジェクトの作成 お客様がE2 Account APIを用いて、DPからCP間の接続のためのVPCエンドポイントを参照するネットワークオブジェクトを作成する。
- ワークスペースの配備 お客様がE2 Account APIを用いて「プライベートアクセス設定」とネットワークオブジェクトをリンクさせたワークスペースを配備する。
事前準備
事前準備における、クロスアカウントIAMロールの作成、クレデンシャル設定情報の登録、S3バケットの設定に関しては、Databricksアカウントのセットアップとワークスペースのデプロイメントを参考に設定を行ってください。AWS上でのDatabricksの環境構築を行う際には、Databricks担当者のサポートを受けることをお勧めします。こちらからお問い合わせください。
ステップバイステップの手順はこちらをご覧ください。
顧客管理VPCの作成
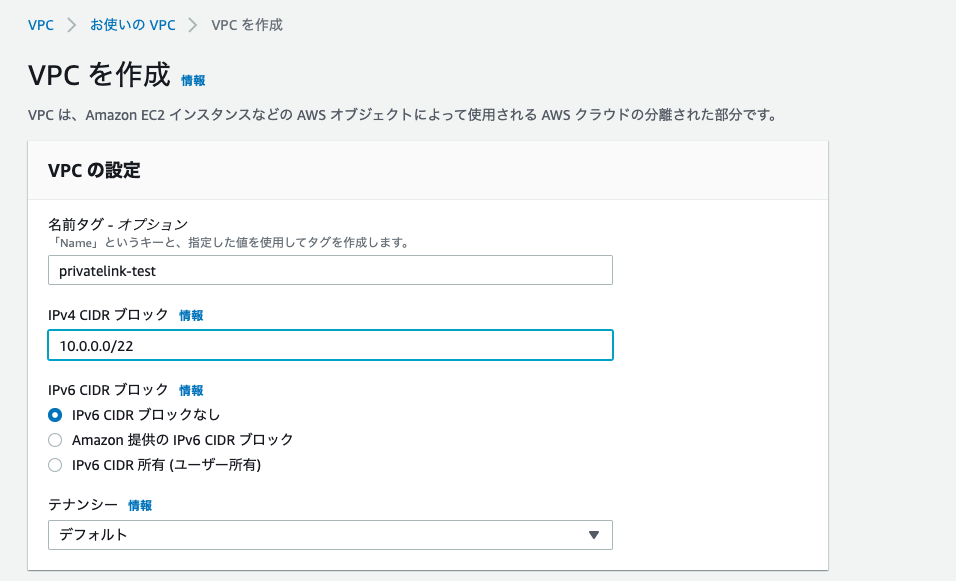
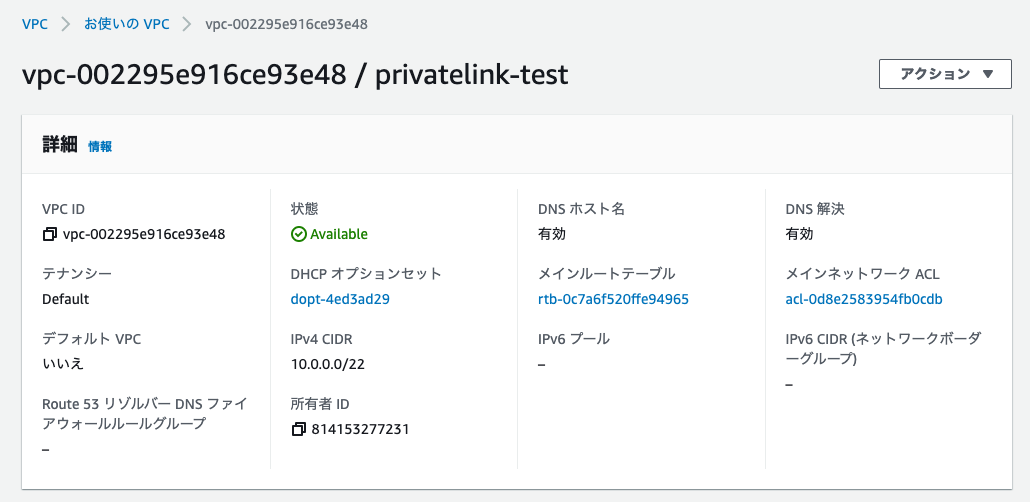
VPCの作成
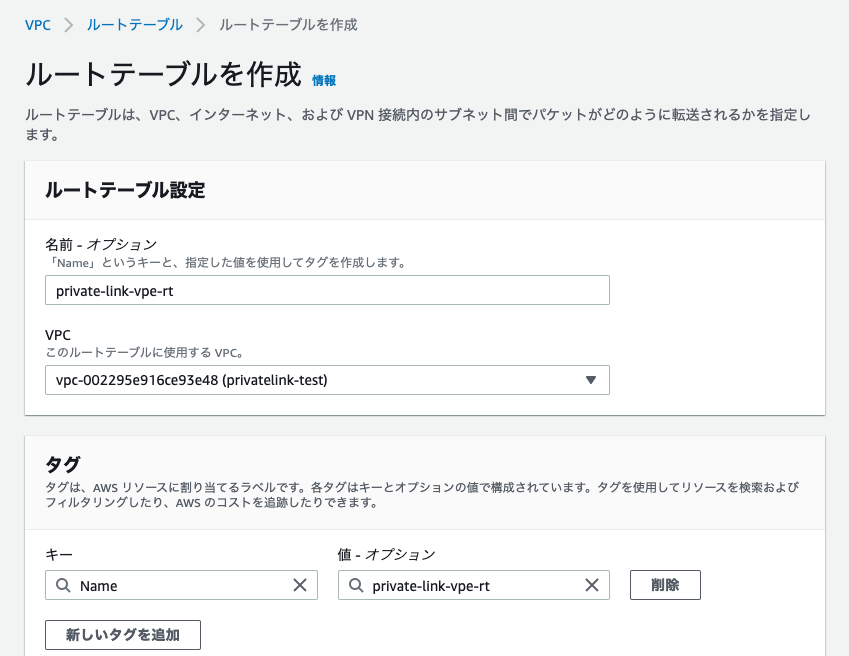
以下の設定でVPCを作成します。名前、CIDRは適宜変更してください。
- 名前タグ - オプション: privatelink-test
- IPv4 CIDR ブロック: 10.0.0.0/22
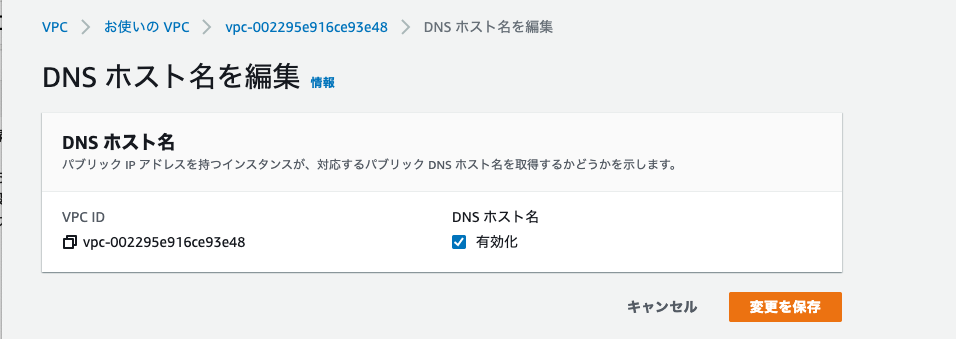
アクションから「DNS ホスト名を編集」を選択し、DNS ホスト名の有効化にチェックをつけて、変更を保存をクリックしてください。
DNSホスト名とDNS解決が有効になっていることを確認します。
サブネットの作成
PrivateLink構成では以下のサブネットが必要となります。名称、CIDRは適宜変更してください。CIDRはワークスペース内で起動するクラスターの数に基づき決定する必要があります。ワークスペース用サブネット1とワークスペース用サブネット2は別のアベイラビリティゾーンに作成する必要があります。
| サブネット | CIDR | 名前 |
|---|---|---|
| ワークスペース用サブネット1 | 10.0.1.0/24 | databricks-ws-1 |
| ワークスペース用サブネット2 | 10.0.2.0/24 | databricks-ws-2 |
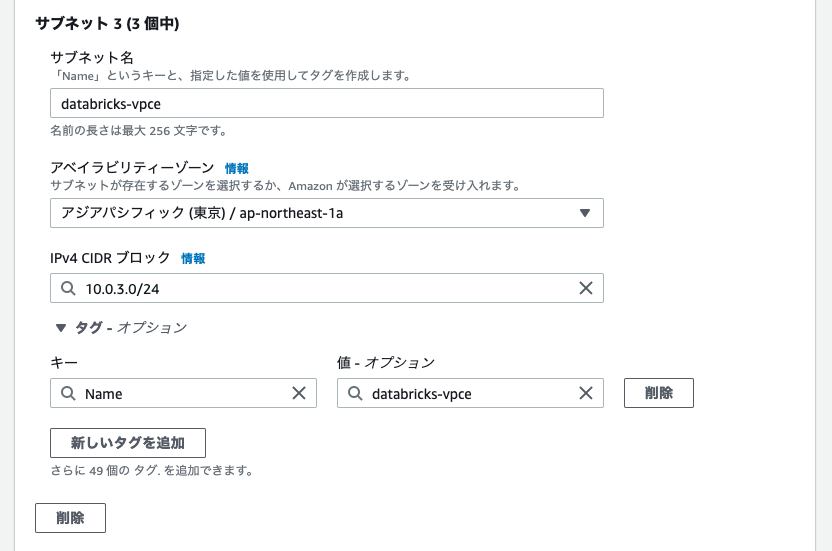
| VPCエンドポイント用サブネット | 10.0.3.0/24 | databricks-vpce |
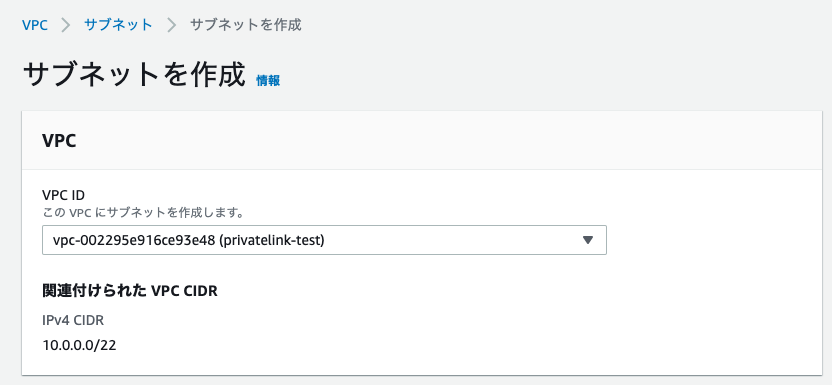
databricks-ws-1
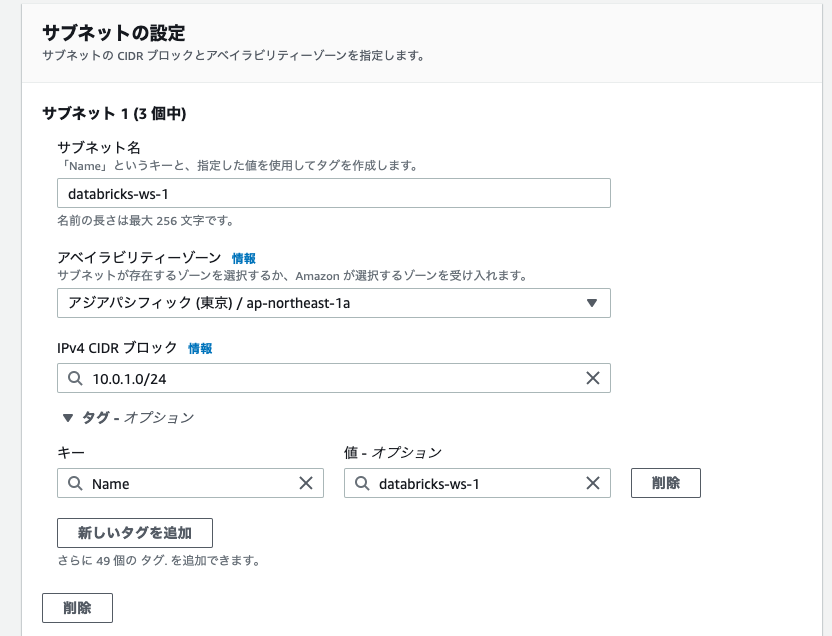
databricks-ws-2
databricks-vpce
ルートテーブル
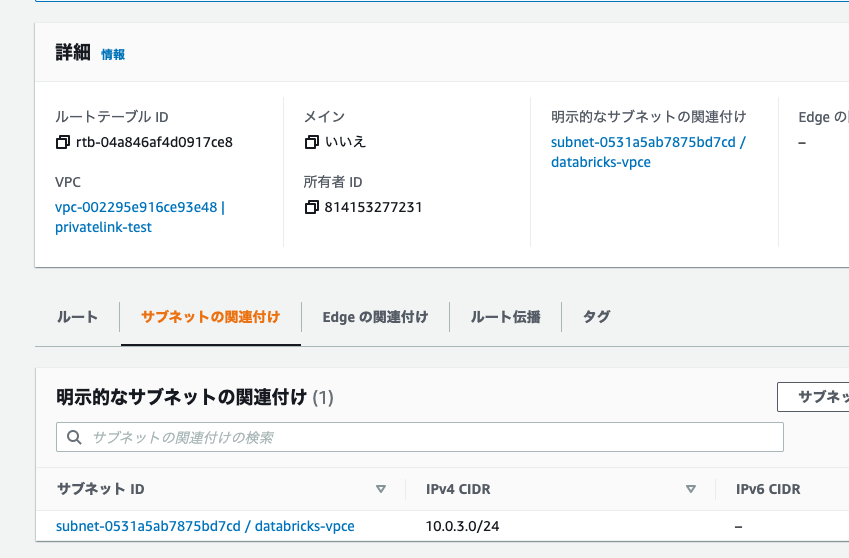
PrivateLink構成では、メインルートテーブルに加えて、VPCエンドポイント用サブネットdatabricks-vpceにアタッチするルートテーブルが必要となります。
| 送信先 | ターゲット |
|---|---|
| 10.0.0.0/22(VPCのCIDR) | local |
private-link-vpe-rt
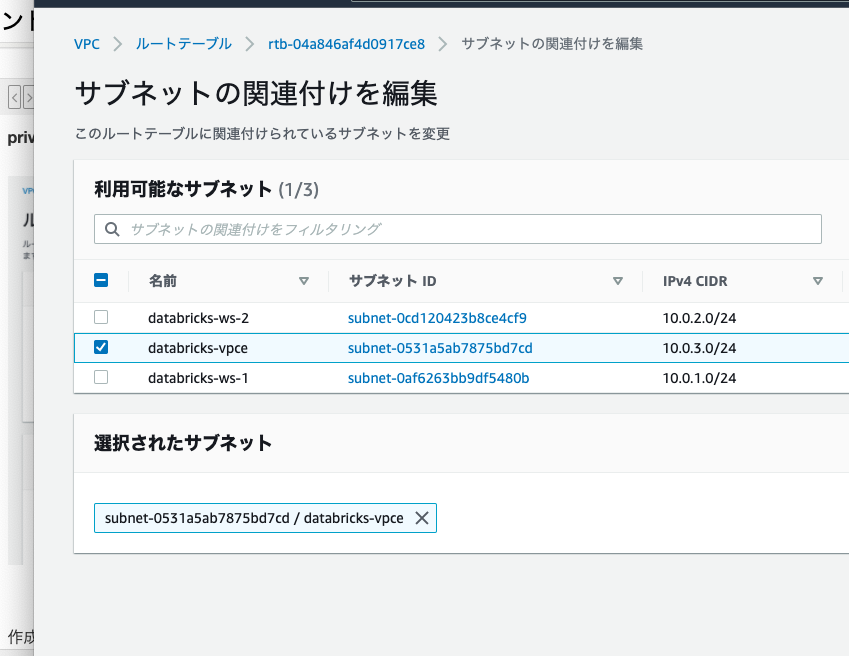
作成したルートテーブルをサブネットdatabricks-vpceに関連づけます。ルートテーブルの「サブネットの関連付け」で「サブネットの関連付けを編集」をクリックします。
databricks-vpceにチェックをつけ、「関連付けを保存」をクリックします。
ネットワークACL
サブネットの作成で作成したサブネットのネットワークACLがデフォルトのすべての通信を許可する様に設定されていることを確認します。
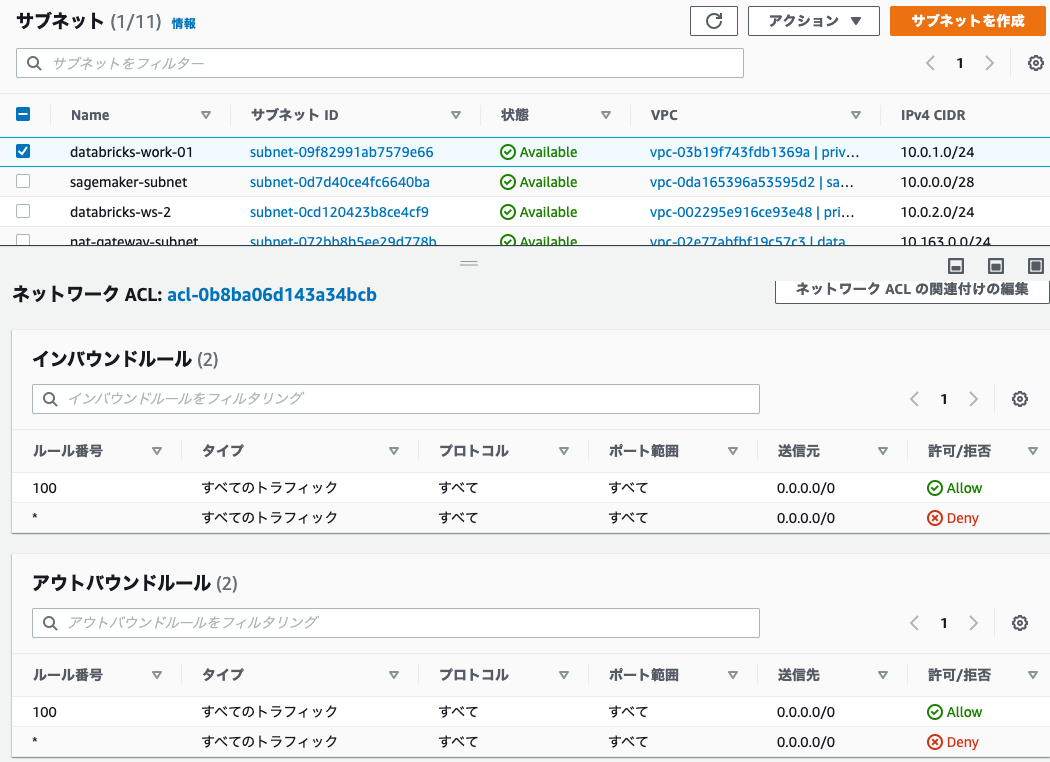
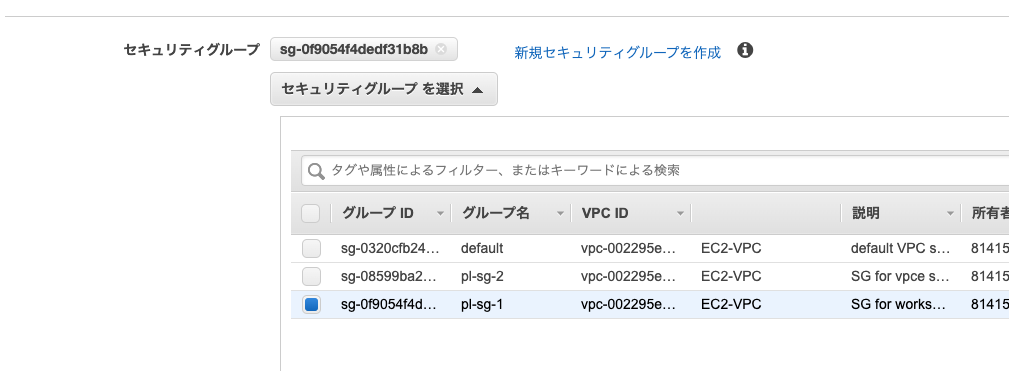
セキュリティグループ
PrivateLink構成では以下の2つのセキュリティグループが必要となります。
| セキュリティグループ | 名前 | 説明 | VPC |
|---|---|---|---|
| ワークスペース用サブネット向けセキュリティグループ | pl-sg-1 | SG for workspace subnet | privatelink-test |
| VPCエンドポイント用サブネット向けセキュリティグループ | pl-sg-2 | SG for vpce subnet | privatelink-test |
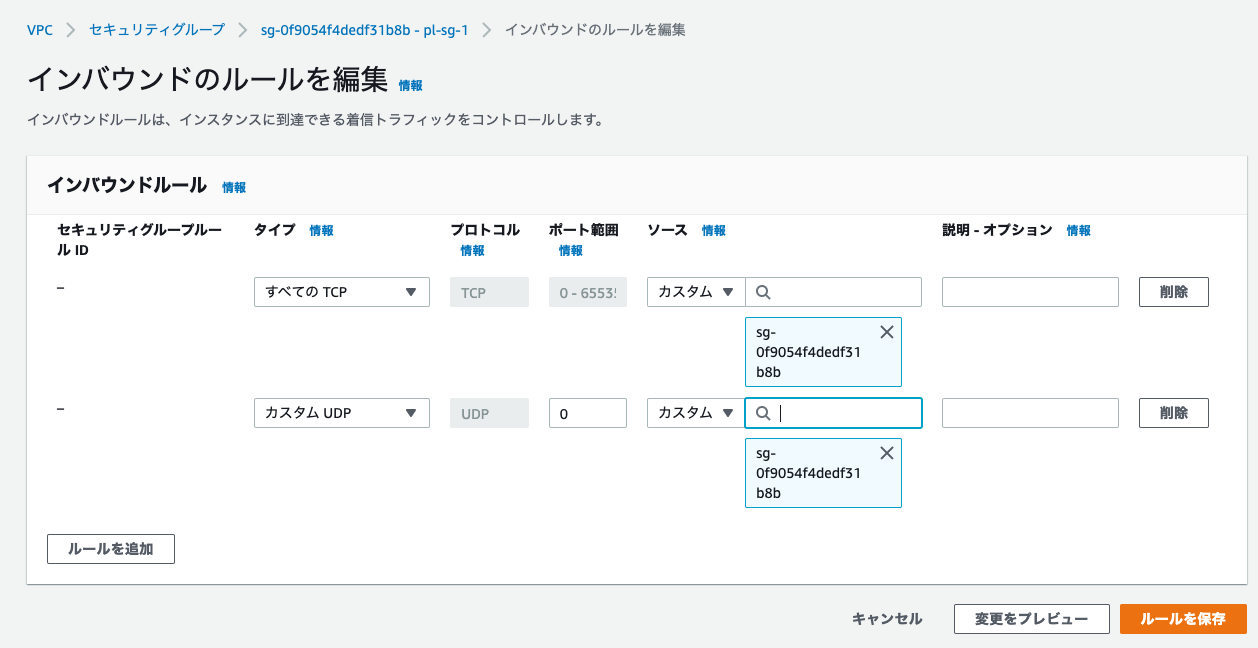
pl-sg-1のインバウンドルール
自分自身(セキュリティグループ)を指定するには、一度ルールが空の状態でセキュリティグループを作成後に、以下の設定を追加します。
| タイプ | ソース |
|---|---|
| すべてのTCP | pl-sg-1 |
| すべてのUDP | pl-sg-1 |
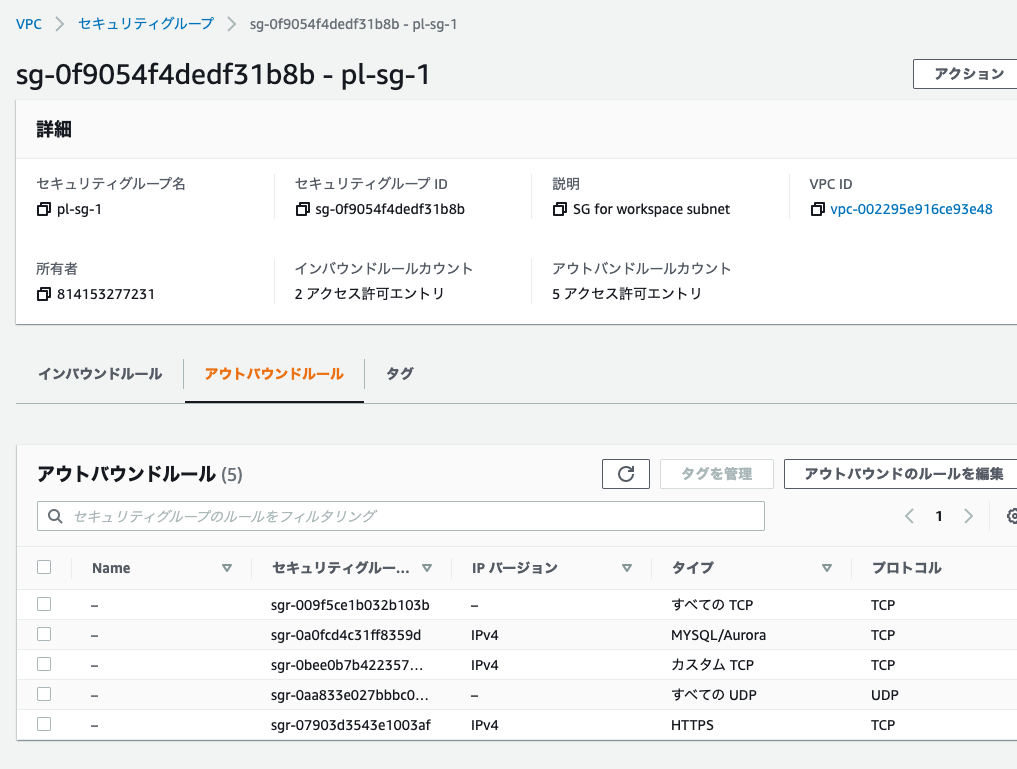
pl-sg-1のアウトバウンドルール
| タイプ | ポート | 送信先 |
|---|---|---|
| すべてのTCP | pl-sg-1 | |
| すべてのUDP | pl-sg-1 | |
| カスタムTCP | 443 | 0.0.0.0/0 |
| カスタムTCP | 3306 | 0.0.0.0/0 |
| カスタムTCP | 6666 | 0.0.0.0/0 |
自分自身を追加するには、一度セキュリティグループを作成した後にソース、送信先で選択します。
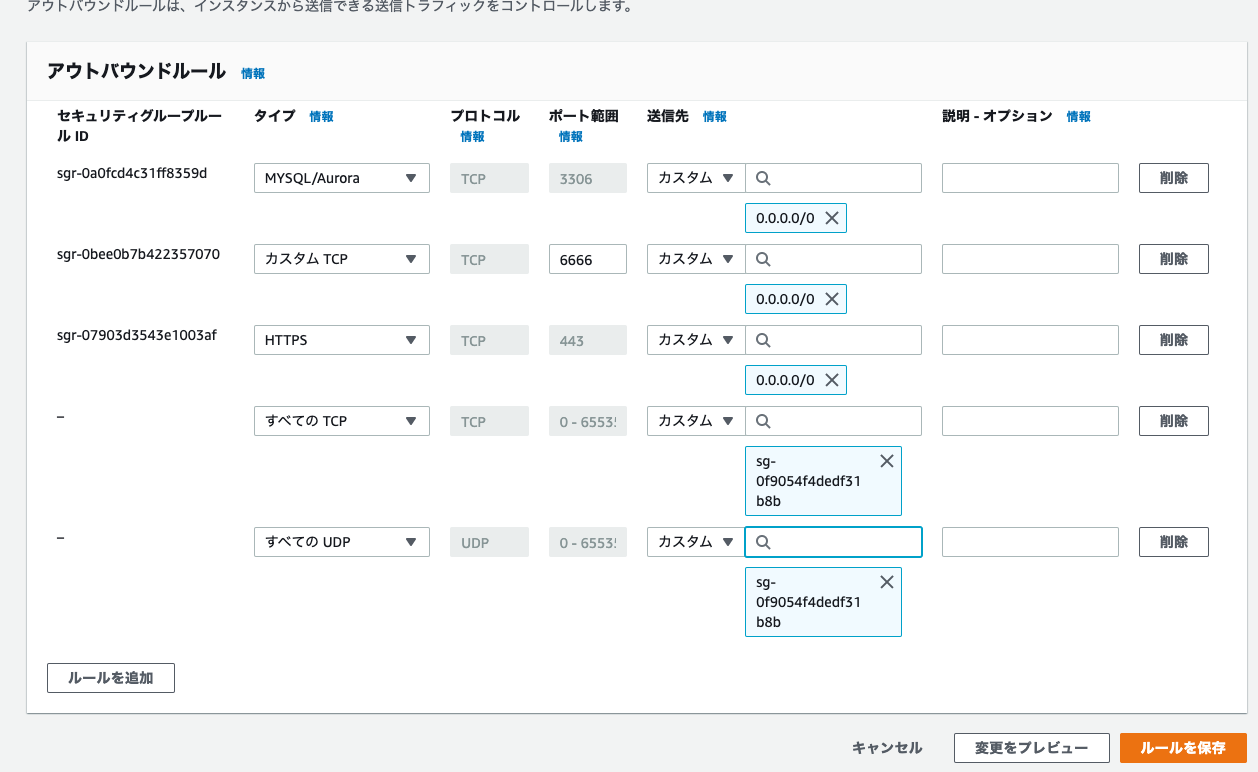
設定後は以下の様になります。
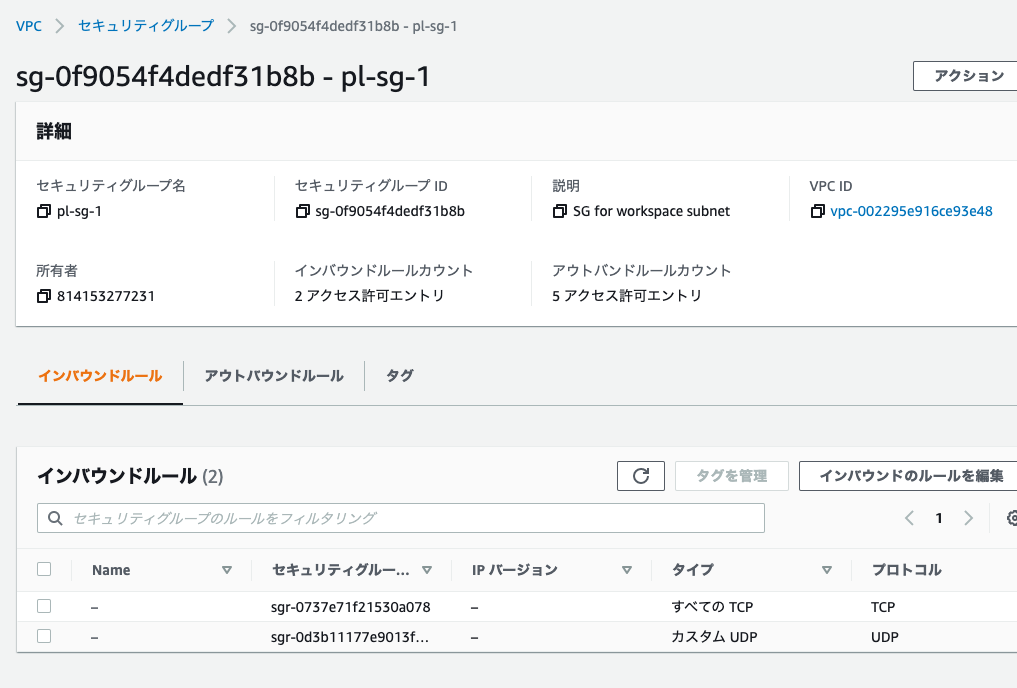
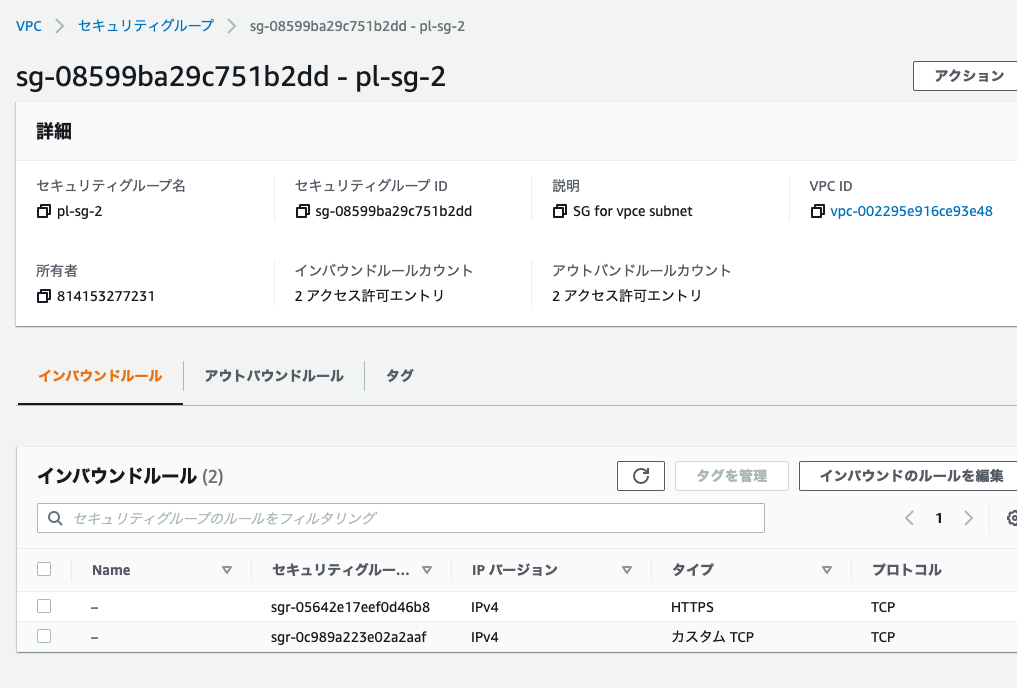
pl-sg-2のインバウンドルール
| タイプ | ポート | ソース |
|---|---|---|
| カスタムTCP | 443 | 10.0.0.0/22(VPCのCIDR) |
| カスタムTCP | 6666 | 10.0.0.0/22(VPCのCIDR) |
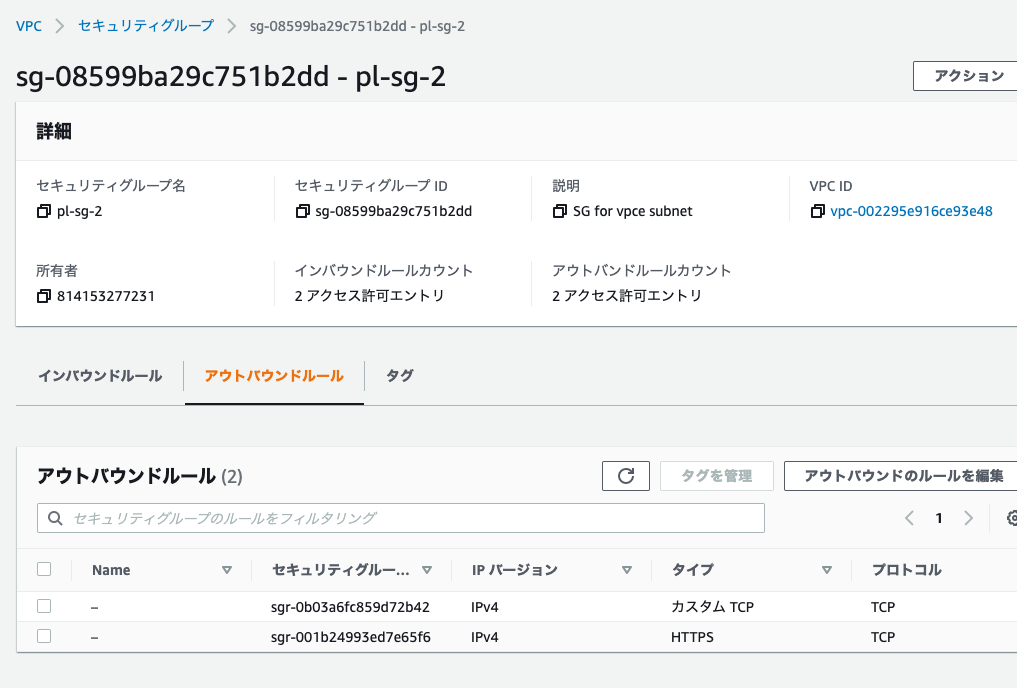
pl-sg-2のアウトバウンドルール
| タイプ | ポート | 送信先 |
|---|---|---|
| カスタムTCP | 443 | 10.0.0.0/22(VPCのCIDR) |
| カスタムTCP | 6666 | 10.0.0.0/22(VPCのCIDR) |
設定後は以下の様になります。
PrivateLinkの設定
PrivateLinkの有効化
Databricks担当者に以下をお伝えください。Databricks側にてPrivateLinkの有効化作業を行います。
- 環境をデプロイするAWSリージョン
- AWSのアカウントID
- 事前準備でアクセスするAccount Consoleで確認できるDatabricksのAccount ID
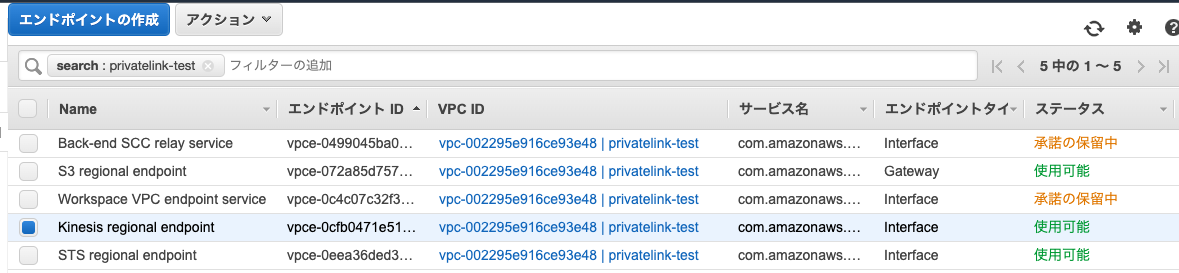
VPCエンドポイントの作成
以下のエンドポイントを作成します。
- VPCエンドポイントサービス(Workspace VPC endpoint service)
- VPCエンドポイントサービス(Back-end SCC relay service)
- S3 VPCゲートウェイエンドポイント
- STS VPCインタフェースエンドポイント
- Kinesis VPCインタフェースエンドポイント
S3、STS、Kinesisのエンドポイントに関しては、顧客管理VPCでリージョナルエンドポイントの設定をしていない場合には、こちらで設定します。設定している場合でも、こちらの設定と合っているか確認してください。
VPCエンドポイントサービス
環境構築を行っているAWSリージョンに対応するVPCエンドポイントサービスをこちらで確認します。東京リージョン(ap-northeast-1)の場合は以下となります。
- Workspace VPC endpoint service:
com.amazonaws.vpce.ap-northeast-1.vpce-svc-02691fd610d24fd64 - Back-end SCC relay service:
com.amazonaws.vpce.ap-northeast-1.vpce-svc-02aa633bda3edbec0
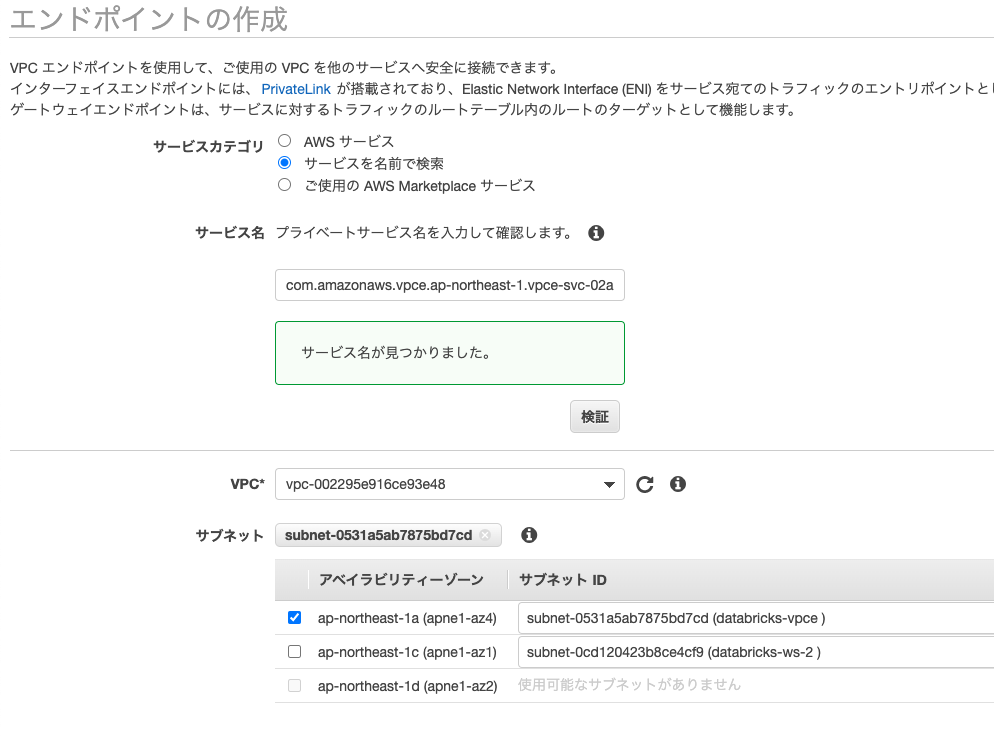
サービスカテゴリでサービスを名前で検索を選択し、上のエンドポイントサービスで検索を行います。
VPCは上で作成したVPCを選択します。サブネットはdatabricks-vpceのみを選択します。
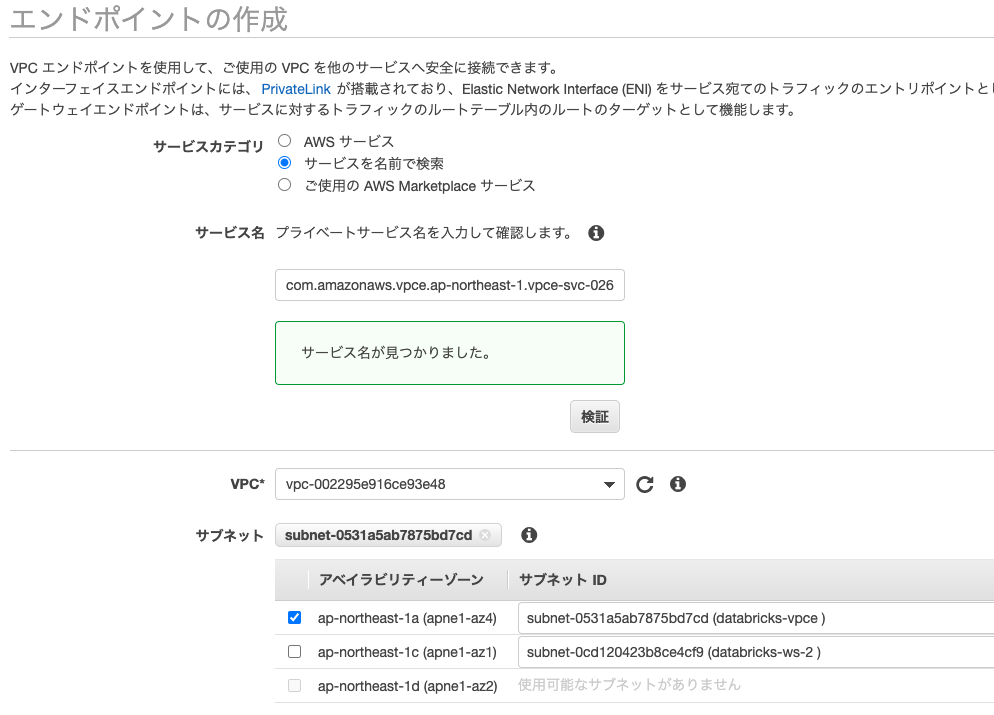
セキュリティグループはpl-sg-2を選択します。
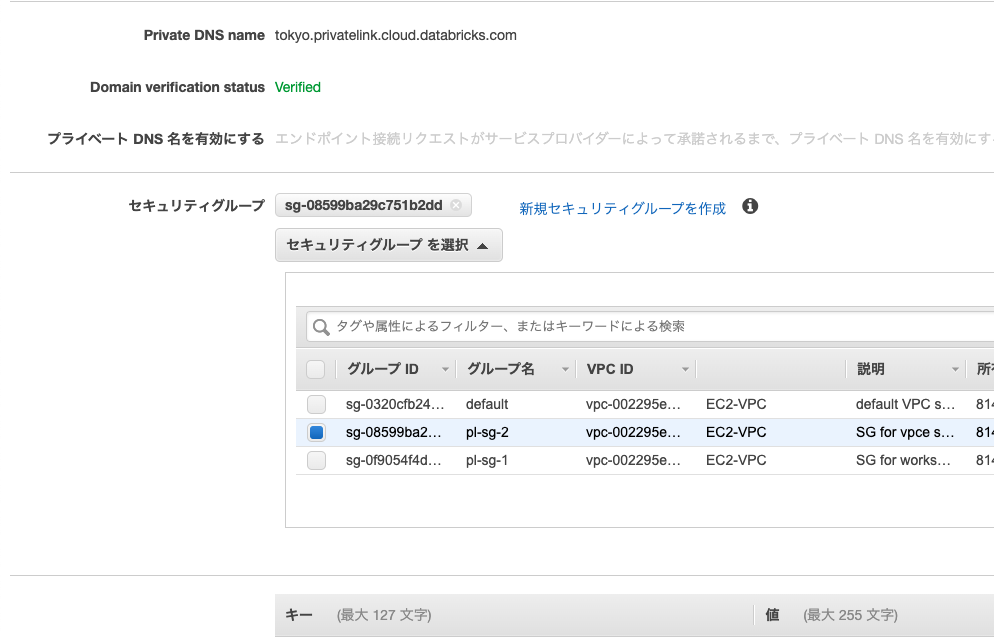
作成するとステータスが「承諾の保留中」となりますが問題ありません。Back-end SCC relay serviceについても同じ設定を行います。
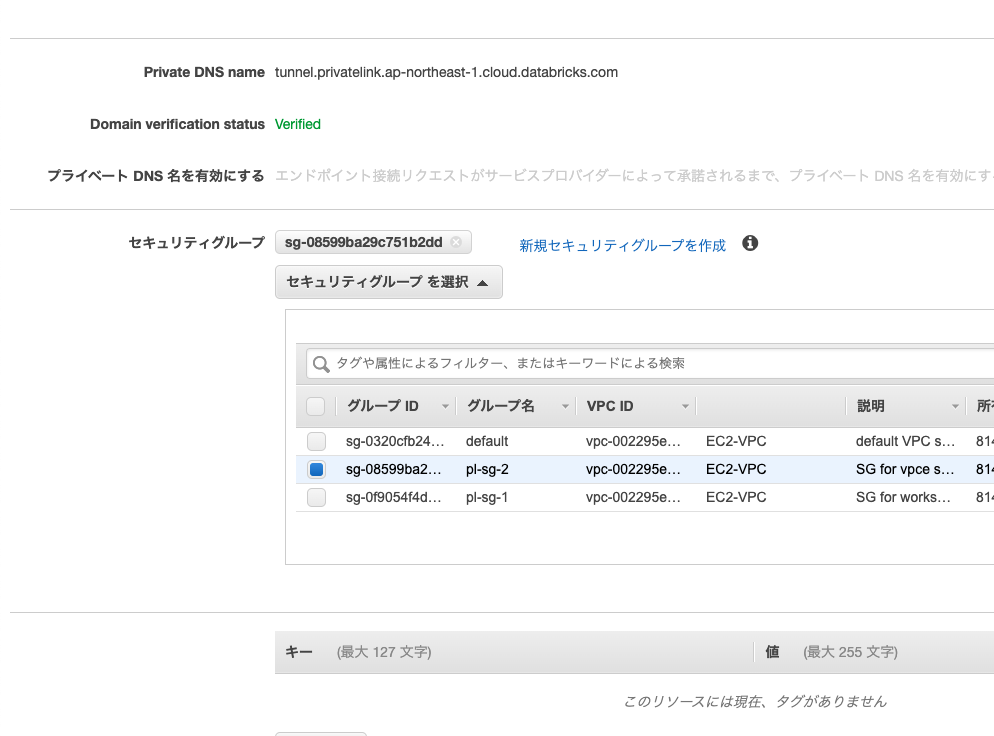
この様な状態になります。次のステップで使用するので、作成した2つのエンドポイントID(Workspace VPC endpoint service/Back-end SCC relay service)をメモしておきます。

S3 VPCゲートウェイエンドポイント
サービスカテゴリでAWS サービスを選択し、S3で検索します。結果からGatewayタイプの「com.amazonaws.ap-northeast-1.s3(東京リージョンの場合)」を選択します。VPCには上で作成したVPCを選択します。
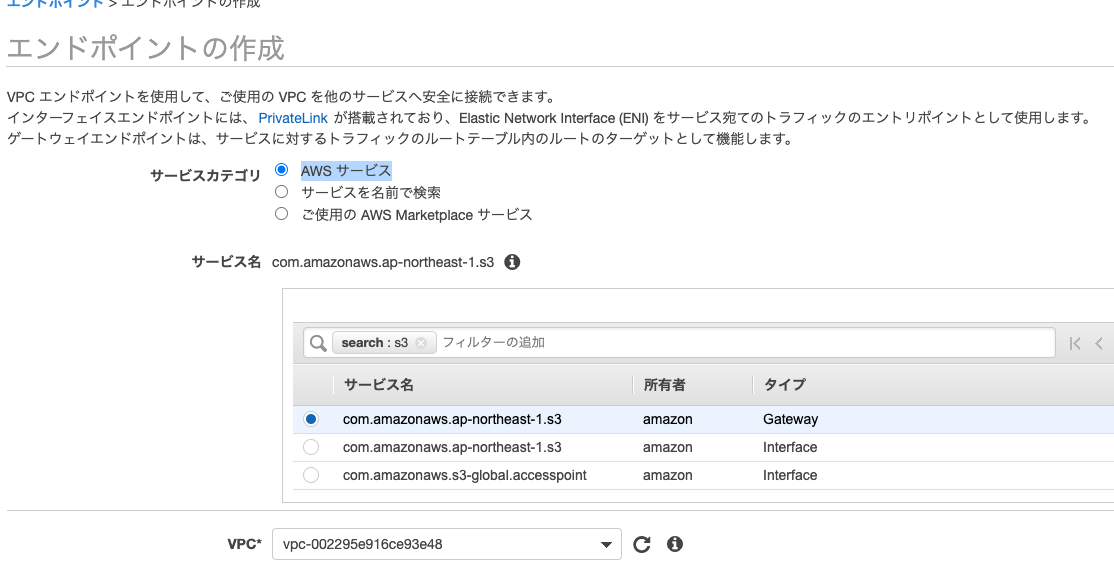
ルートテーブルでは、メインルートテーブルを選択します。これによって、ワークスペース用サブネットにアタッチされます。
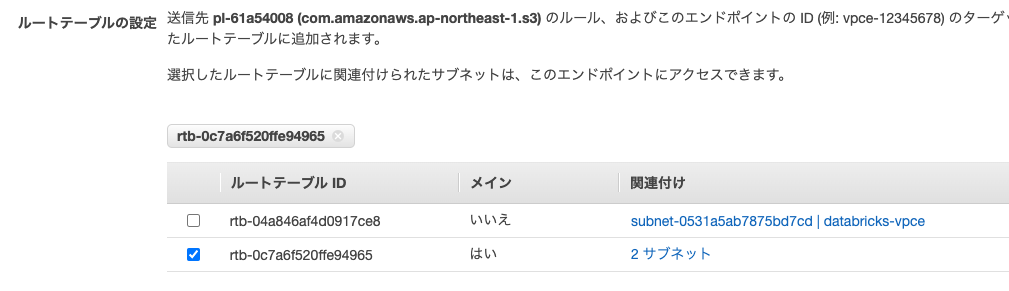
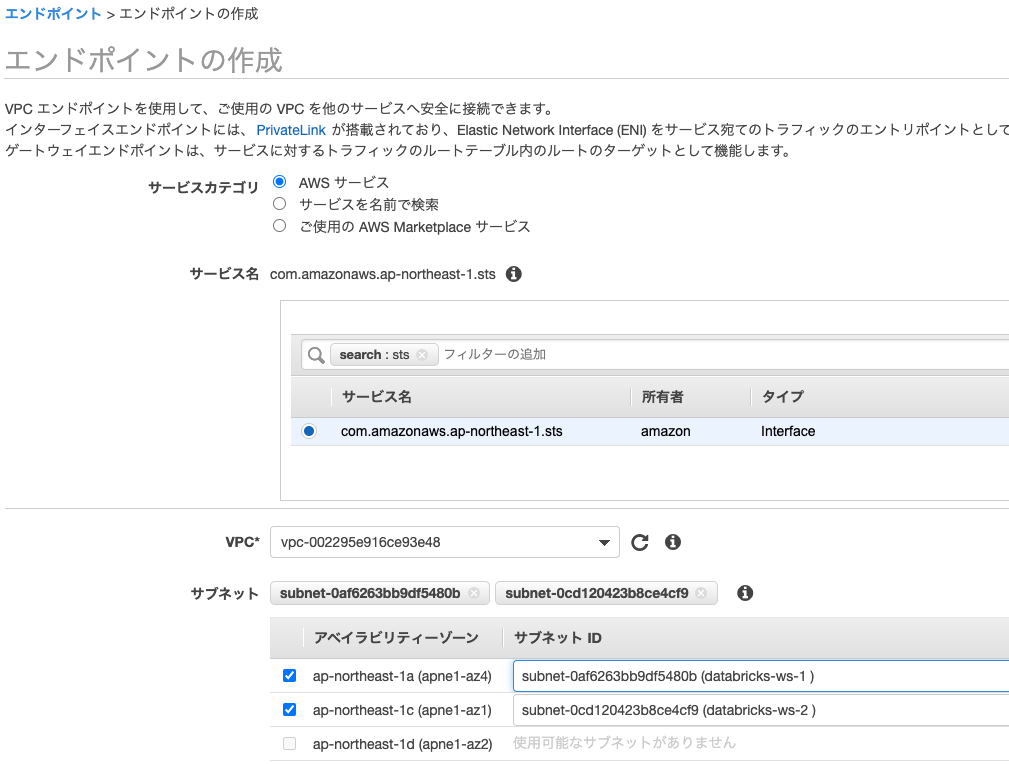
STS VPCインタフェースエンドポイント
サービスカテゴリでAWS サービスを選択し、stsで検索します。結果からInterfaceタイプの「com.amazonaws.ap-northeast-1.sts(東京リージョンの場合)」を選択します。VPCには上で作成したVPCを選択します。サブネットにはdatabricks-ws-1とdatabricks-ws-2を選択します。
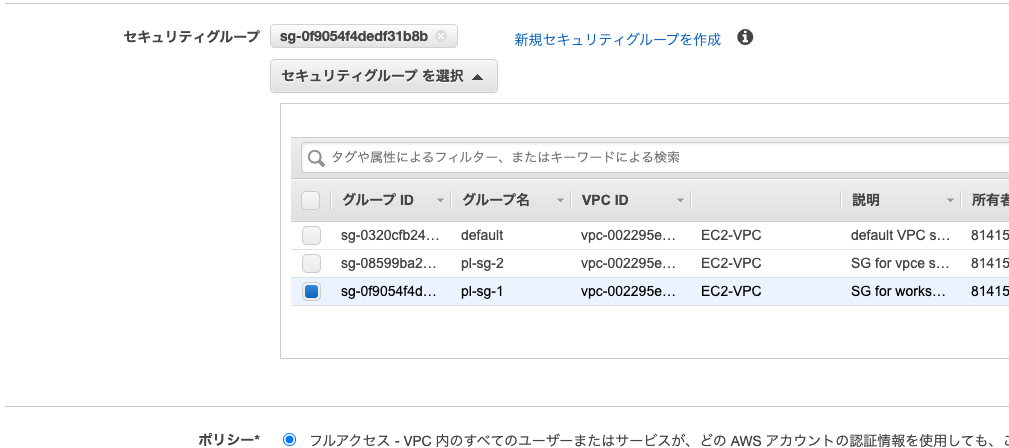
セキュリティグループには、ワークスペース用のpl-sg-1を選択します。
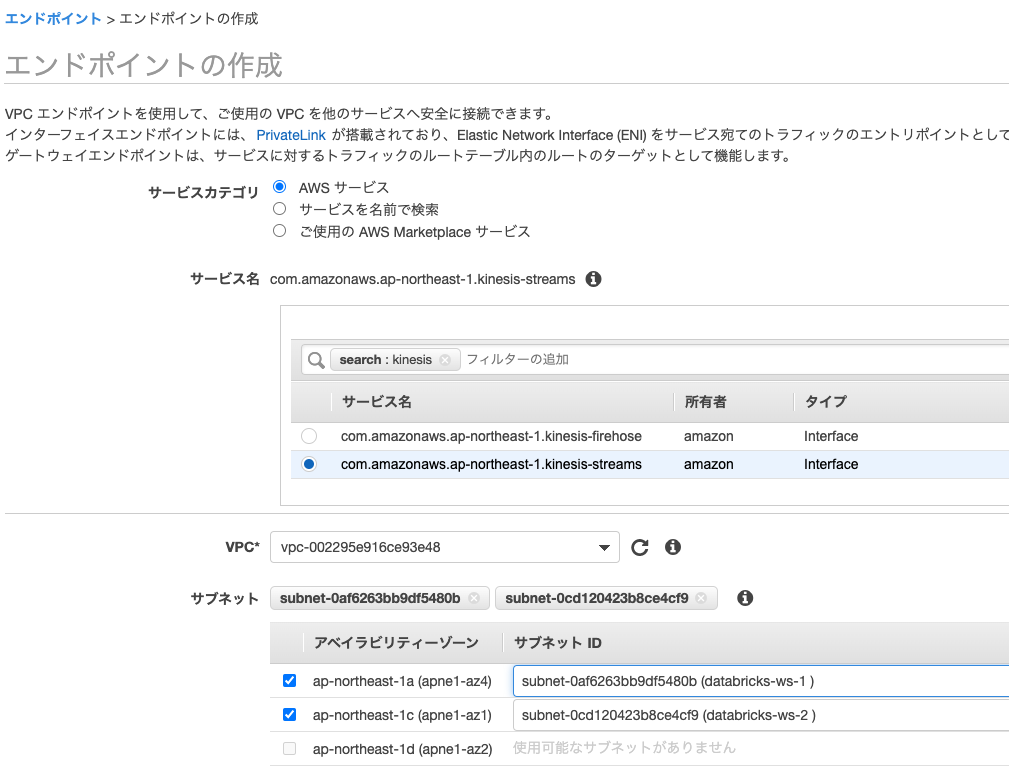
Kinesis VPCインタフェースエンドポイント
サービスカテゴリでAWS サービスを選択し、kinesisで検索します。結果からInterfaceタイプの「com.amazonaws.ap-northeast-1.kinesis-streams(東京リージョンの場合)」を選択します。VPCには上で作成したVPCを選択します。サブネットにはdatabricks-ws-1とdatabricks-ws-2を選択します。
セキュリティグループには、ワークスペース用のpl-sg-1を選択します。
ここまで設定すると以下の様になります。
VPCエンドポイントの登録
以降はAccount APIを操作します。ローカル環境でコマンドプロンプト、ターミナルなどを開いてください。ここでは、以下のツールを使用します。
- curl
- jq
以下の情報をメモしておいてください。
- DatabricksアカウントID
- アカウントオーナーのメールアドレスおよびパスワード
- 作成した2つのエンドポイントID(Workspace VPC endpoint service/Back-end SCC relay service)
Workspace VPC endpoint serviceの登録
curl -X POST -u <アカウントオーナーのメールアドレス>:<アカウントオーナーのパスワード> \
'https://accounts.cloud.databricks.com/api/2.0/accounts/<DatabricksアカウントID>/vpc-endpoints' \
-d '{
"vpc_endpoint_name": "workspace-rest-api",
"region": "ap-northeast-1",
"aws_vpc_endpoint_id": "<Workspace VPC endpoint serviceのVPCエンドポイントID>"
}' | jq
結果
{
"vpc_endpoint_id": "17f25981-069f-455f-a116-c2de067ba476",
"account_id": "<DatabricksアカウントID>",
"vpc_endpoint_name": "workspace-rest-api",
"aws_vpc_endpoint_id": "vpce-0c4c07c32f30868b3",
"aws_endpoint_service_id": "vpce-svc-02691fd610d24fd64",
"use_case": "WORKSPACE_ACCESS",
"region": "ap-northeast-1",
"aws_account_id": "814153277231",
"state": "pending"
}
上のvpc_endpoint_idをメモしておきます。
Back-end SCC relay serviceの登録
以下を実行してエンドポイントを登録します。
curl -X POST -u <アカウントオーナーのメールアドレス>:<アカウントオーナーのパスワード> \
'https://accounts.cloud.databricks.com/api/2.0/accounts/<DatabricksアカウントID>/vpc-endpoints' \
-d '{
"vpc_endpoint_name": "scc-relay",
"region": "ap-northeast-1",
"aws_vpc_endpoint_id": "<Back-end SCC relay serviceのVPCエンドポイントID>"
}' | jq
結果
{
"vpc_endpoint_id": "2a25fd2a-3dde-4a8f-9dc7-187b1239aac2",
"account_id": "<DatabricksアカウントID>",
"vpc_endpoint_name": "scc-relay",
"aws_vpc_endpoint_id": "vpce-0499045ba03fa9c95",
"aws_endpoint_service_id": "vpce-svc-02aa633bda3edbec0",
"use_case": "DATAPLANE_RELAY_ACCESS",
"region": "ap-northeast-1",
"aws_account_id": "814153277231",
"state": "pending"
}
上のvpc_endpoint_idをメモしておきます。
これですべてのエンドポイントが使用可能になります。
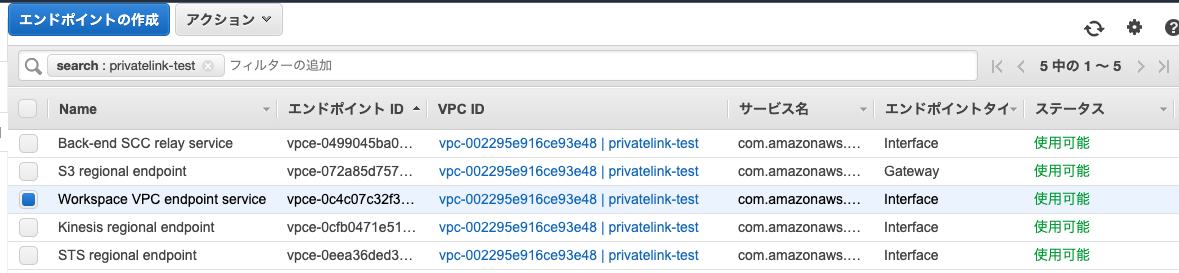
VPCエンドポイントのプライベートDNS名を有効化する
VPCエンドポイントサービス(Workspace VPC endpoint service)、VPCエンドポイントサービス(Back-end SCC relay service)が「使用可能」になったら、これらのプライベートDNS名を有効にします。
エンドポイントを選択し、アクションからプライベートDNS名の変更を選択します。プライベート DNS 名を有効にするのこのエンドポイントで有効にするのチェックを入れて、プライベートDNS名の変更をクリックします。この操作をVPCエンドポイントサービス(Workspace VPC endpoint service)、VPCエンドポイントサービス(Back-end SCC relay service)両方に対して行います。
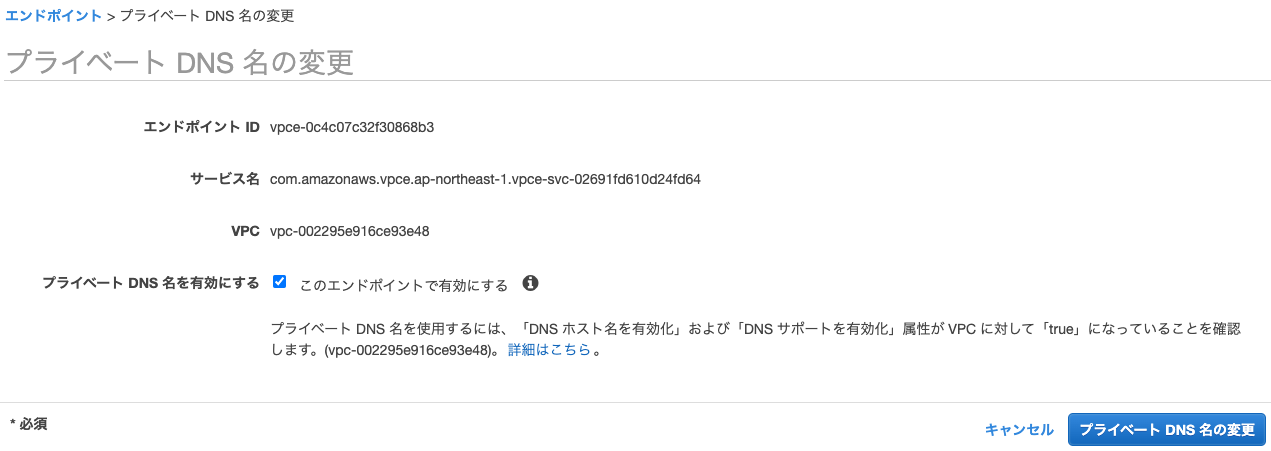
ステータスが「保留中」になりますが、少し待てば「使用可能」になります。
プライベートアクセス設定オブジェクトの作成
以下を実行してプライベートアクセス設定オブジェクトを作成します。public_access_enabledはアクセス経路を決定する重要なパラメーターとなります。こちらを一読ください。以下の様にtrueと設定している場合には、ワークスペースはVPCエンドポイントに加えて、公衆ネットワークからもアクセスできます。完全にロックダウンしたい場合には、PrivateLinkフロントエンド接続も有効化した上で、このパラメーターをfalseに設定します。
curl -X POST -u <アカウントオーナーのメールアドレス>:<アカウントオーナーのパスワード> \
'https://accounts.cloud.databricks.com/api/2.0/accounts/<DatabricksアカウントID>/private-access-settings' \
-d '{
"private_access_settings_name": "private_access_settings2 for ap-northeast-1",
"region": "ap-northeast-1",
"public_access_enabled": true
}' | jq
結果
{
"private_access_settings_id": "1d0c1cd7-2b24-499b-b71c-e7f3936549a8",
"account_id": "<DatabricksアカウントID>",
"private_access_settings_name": "private_access_settings2 for ap-northeast-1",
"region": "ap-northeast-1",
"public_access_enabled": true,
"private_access_level": "ANY"
}
上のprivate_access_settings_idをメモしておきます。
ネットワークオブジェクトの作成
これまでに準備した設定を用いて、PrivateLink用のネットワークオブジェクトを作成します。
curl -X POST -u <アカウントオーナーのメールアドレス>:<アカウントオーナーのパスワード> \
'https://accounts.cloud.databricks.com/api/2.0/accounts/<DatabricksアカウントID>/networks' \
-d '{
"network_name": "databricks-privatelink",
"vpc_id": "<VPC privatelink-testのid>",
"subnet_ids": [
"<サブネットdatabricks-ws-1のid>",
"<サブネットdatabricks-ws-2のid>"
],
"security_group_ids": [
"<セキュリティグループpl-sg-1のid>"
],
"vpc_endpoints": {
"dataplane_relay": [
"<Back-end SCC relay serviceの登録時に取得したvpc_endpoint_id>"
],
"rest_api": [
"<Workspace VPC endpoint serviceの登録時に取得したvpc_endpoint_id>"
]
}
}' | jq
結果
{
"network_id": "5f58cf31-cb33-4d65-ae43-41856cbe8e72",
"account_id": "<DatabricksアカウントID>",
"vpc_id": "<VPC privatelink-testのid>",
"subnet_ids": [
"<サブネットdatabricks-ws-1のid>",
"<サブネットdatabricks-ws-2のid>"
],
"security_group_ids": [
"sg-079cbd8733ab82c30"
],
"vpc_status": "UNATTACHED",
"network_name": "databricks-privatelink",
"creation_time": 1635769375362,
"vpc_endpoints": {
"rest_api": [
"<Workspace VPC endpoint serviceの登録時に取得したvpc_endpoint_id>"
],
"dataplane_relay": [
"<Back-end SCC relay serviceの登録時に取得したvpc_endpoint_id>"
]
}
}
上のnetwork_idをメモしておきます。
ワークスペースの配備
以下を実行して、ワークスペースをデプロイします。
curl -X POST -u <アカウントオーナーのメールアドレス>:<アカウントオーナーのパスワード> \
'https://accounts.cloud.databricks.com/api/2.0/accounts/<DatabricksアカウントID>/workspaces' \
-d '{
"workspace_name": "ワークスペース名",
"deployment_name": "デプロイメント名",
"aws_region": "<デプロイするリージョン>",
"credentials_id": "<事前準備で取得したcredentials_id>",
"storage_configuration_id": "<事前準備で取得したstorage_configuration_id>",
"network_id": "<上で取得したnetwork_id>",
"private_access_settings_id": "<上で取得したprivate_access_settings_id>"
}' | jq
結果
{
"workspace_id": 3180937440650220,
"workspace_name": "privatelink-test",
"aws_region": "ap-northeast-1",
"creation_time": 1635769961845,
"deployment_name": "tydatabricks-privatelink-test",
"workspace_status": "PROVISIONING",
"account_id": "<DatabricksアカウントID>",
"credentials_id": "<事前準備で取得したcredentials_id>",
"storage_configuration_id": "<事前準備で取得したstorage_configuration_id>",
"workspace_status_message": "Workspace resources are being set up.",
"network_id": "<上で取得したnetwork_id>",
"pricing_tier": "ENTERPRISE",
"private_access_settings_id": "<上で取得したprivate_access_settings_id>"
}
メタストアの設定
アウトバウンド接続をサポートしないように、ワークスペースVPCをロックダウンした場合、AWSがRDSに対するJDBCトラフィックのPrivateLinkをサポートしていないため、ワークスペースからDatabricks管理のメタストア(RDSベースのHiveメタストア)にはアクセスできなくなります。一つの選択肢としては、リージョンごとにDatabricksが提供するメタストアのFQDNあるいはIPを、イグレスファイアウォール、インターネットゲートウェイに対するパブリックルートテーブル、NATゲートウェイをホスティングするパブリックサブネットに対するネットワークACLのいずれかに対して設定するというものです。この場合、Databricksが提供するメタストアへのトラフィックは、パブリックネットワークを経由することになります。しかし、Databricks管理のメタストアにパブリックネットワーク経由でアクセスしたくない場合には、以下のいずれかの選択肢となります。
- お使いのVPCに外部メタストアをデプロイします。詳細はExternal Apache Hive metastoreを参照ください。
- メタストアとしてAWS Glueを使用できます。GlueはPrivateLinkをサポートしています。Use AWS Glue Data Catalog as the metastore for Databricks Runtimeを参照ください。
以下では、メタストアとしてAWS Glueを使用する際の手順を説明します。なお、DatabricksをデプロイしているAWSアカウントとGlueが動作するAWSアカウントは同一であると想定しています。
Glueカタログエンドポイントの作成
外部メタストア、あるいはGlueに接続するためのエンドポイントを作成します。
サービスカテゴリでAWS サービスを選択し、glueで検索します。結果からInterfaceタイプの「com.amazonaws.ap-northeast-1.glue(東京リージョンの場合)」を選択します。VPCには上で作成したVPCを選択します。サブネットにはdatabricks-ws-1とdatabricks-ws-2を選択します。
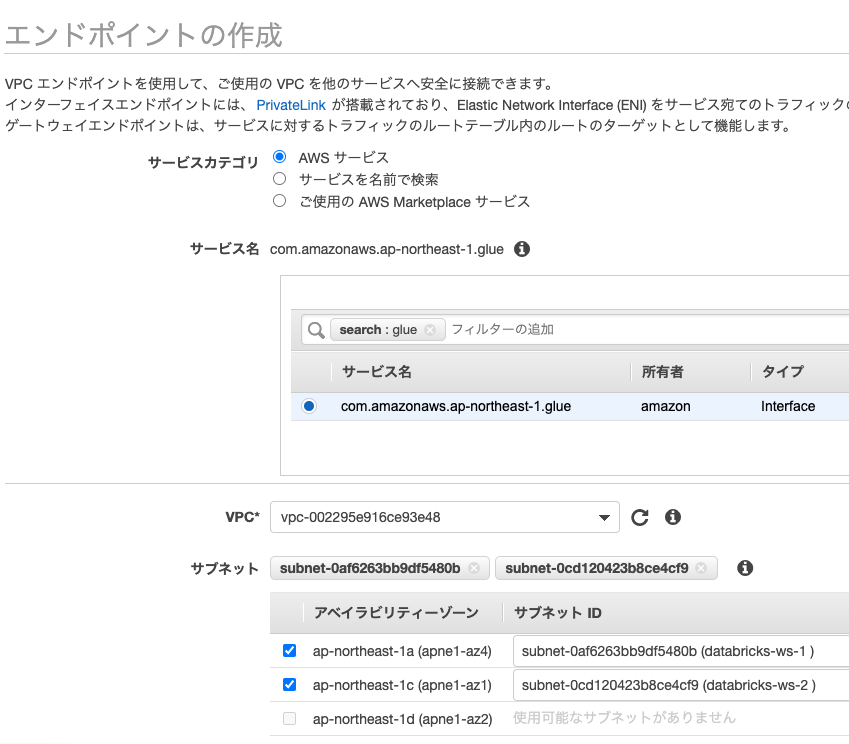
セキュリティグループには、ワークスペース用のpl-sg-1を選択します。
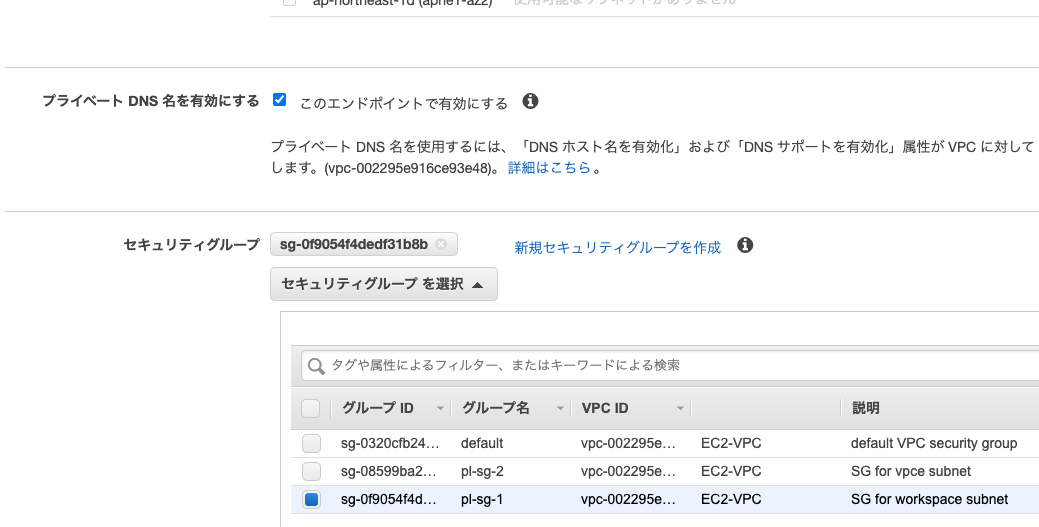
Glueカタログにアクセスするためのインスタンスプロファイルの作成
-
AWSコンソールでIAMサービスにアクセスします。
-
サイドバーからロールを選択します。
-
ロールを作成をクリックします。
-
信頼されたエンティティの種類を選択ではAWSサービス、ユースケースの選択ではEC2を選択します。次のステップ:アクセス権限をクリックします。
-
次のステップ:タグ、次のステップ:確認をクリックします。
-
ロール名を入力して、ロールの作成をクリックします。
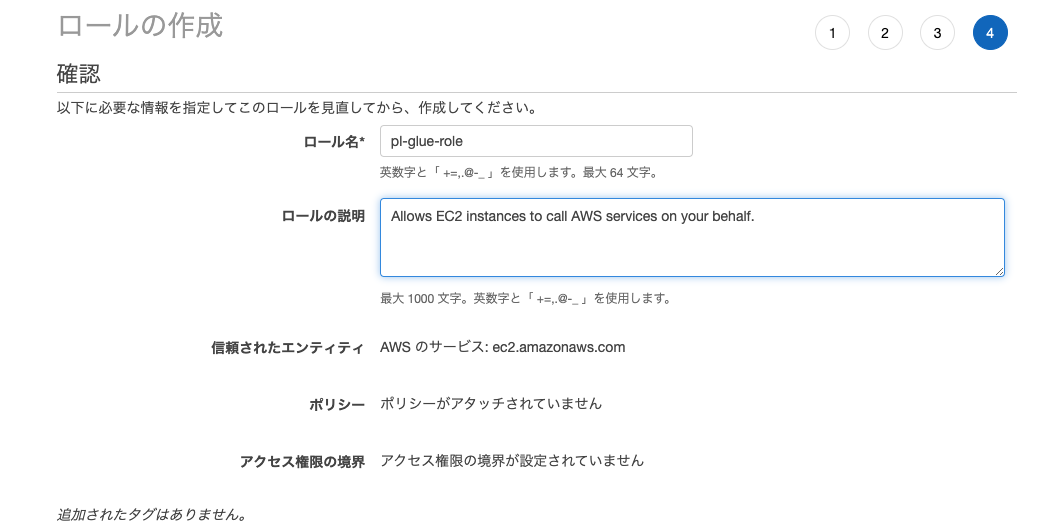
-
ロールの一覧で先ほど作成したロールを検索してクリックします。インラインポリシーの追加をクリックします。
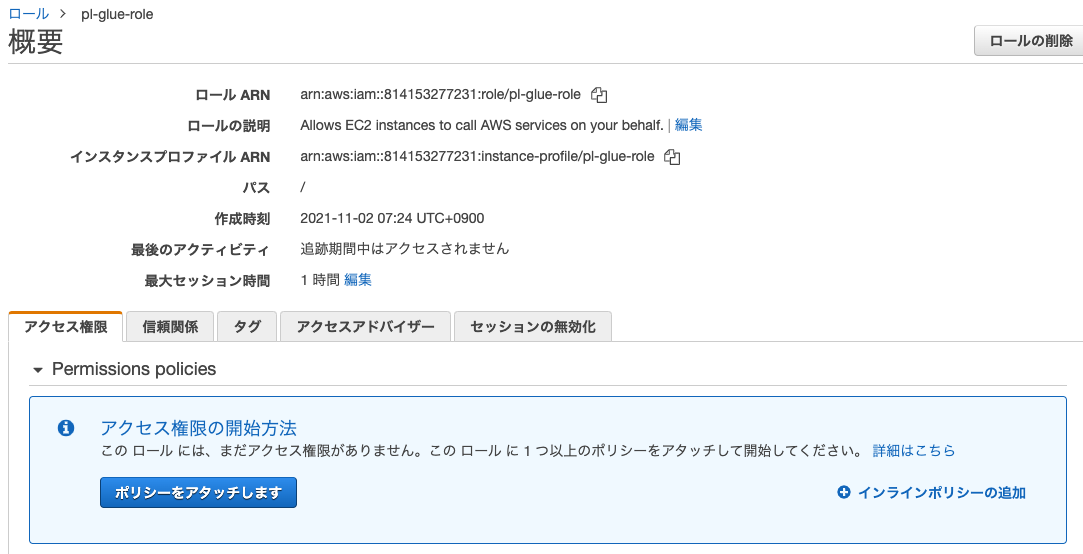
-
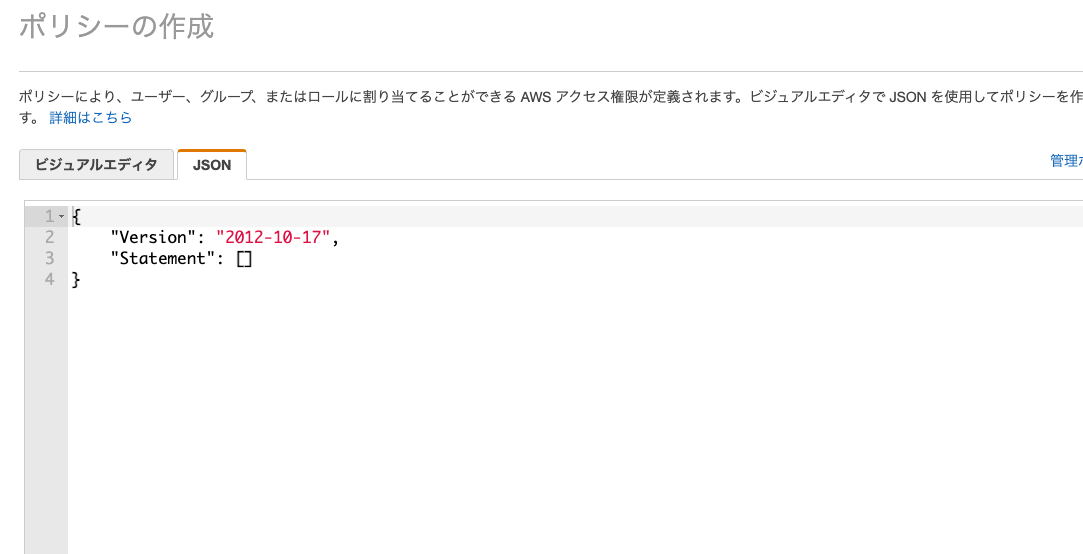
JSONタブをクリックします。
-
以下の内容を貼り付けます。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "GrantCatalogAccessToGlue", "Effect": "Allow", "Action": [ "glue:BatchCreatePartition", "glue:BatchDeletePartition", "glue:BatchGetPartition", "glue:CreateDatabase", "glue:CreateTable", "glue:CreateUserDefinedFunction", "glue:DeleteDatabase", "glue:DeletePartition", "glue:DeleteTable", "glue:DeleteUserDefinedFunction", "glue:GetDatabase", "glue:GetDatabases", "glue:GetPartition", "glue:GetPartitions", "glue:GetTable", "glue:GetTables", "glue:GetUserDefinedFunction", "glue:GetUserDefinedFunctions", "glue:UpdateDatabase", "glue:UpdatePartition", "glue:UpdateTable", "glue:UpdateUserDefinedFunction" ], "Resource": [ "*" ] } ] } -
ポリシーの確認、ポリシーの名前を入力してポリシーの作成をクリックします。
Databricksデプロイメントに使用したIAMロールの設定
-
Account Consoleから当該ワークスペースをクリックすることで表示される画面のCredentialsのRole ARNで確認できます。
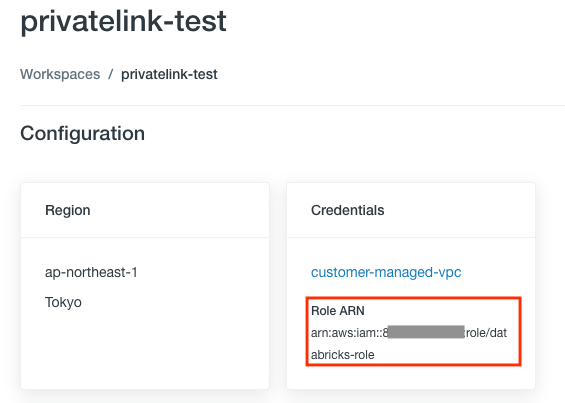
上の例では
databricks-roleとなります。IAMロール一覧で、こちらのロールを検索しクリックします。 -
アクセス権限タブで表示されるポリシー名をクリックし、ポリシーの編集をクリックします。
-
Glueにアクセスするためのインスタンスプロファイルの作成で作成したインスタンスプロファイルを、SparkクラスターのEC2インスタンスに引き渡すことを許可する様にポリシーを変更します。以下の
<aws-account-id-databricks>をDatabricksをデプロイする際にお使いのAWSアカウントID、<iam-role-for-glue-access>をGlueにアクセスするためのインスタンスプロファイルの作成で作成したロールで置き換えてください。その後で変更を保存してください。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1403287045000",
"Effect": "Allow",
"Action": [
"ec2:AssociateDhcpOptions",
"ec2:AssociateIamInstanceProfile",
"ec2:AssociateRouteTable",
"ec2:AttachInternetGateway",
"ec2:AttachVolume",
"ec2:AuthorizeSecurityGroupEgress",
"ec2:AuthorizeSecurityGroupIngress",
"ec2:CancelSpotInstanceRequests",
"ec2:CreateDhcpOptions",
"ec2:CreateInternetGateway",
"ec2:CreatePlacementGroup",
"ec2:CreateRoute",
"ec2:CreateSecurityGroup",
"ec2:CreateSubnet",
"ec2:CreateTags",
"ec2:CreateVolume",
"ec2:CreateVpc",
"ec2:CreateVpcPeeringConnection",
"ec2:DeleteInternetGateway",
"ec2:DeletePlacementGroup",
"ec2:DeleteRoute",
"ec2:DeleteRouteTable",
"ec2:DeleteSecurityGroup",
"ec2:DeleteSubnet",
"ec2:DeleteTags",
"ec2:DeleteVolume",
"ec2:DeleteVpc",
"ec2:DescribeAvailabilityZones",
"ec2:DescribeIamInstanceProfileAssociations",
"ec2:DescribeInstanceStatus",
"ec2:DescribeInstances",
"ec2:DescribePlacementGroups",
"ec2:DescribePrefixLists",
"ec2:DescribeReservedInstancesOfferings",
"ec2:DescribeRouteTables",
"ec2:DescribeSecurityGroups",
"ec2:DescribeSpotInstanceRequests",
"ec2:DescribeSpotPriceHistory",
"ec2:DescribeSubnets",
"ec2:DescribeVolumes",
"ec2:DescribeVpcs",
"ec2:DetachInternetGateway",
"ec2:DisassociateIamInstanceProfile",
"ec2:ModifyVpcAttribute",
"ec2:ReplaceIamInstanceProfileAssociation",
"ec2:RequestSpotInstances",
"ec2:RevokeSecurityGroupEgress",
"ec2:RevokeSecurityGroupIngress",
"ec2:RunInstances",
"ec2:TerminateInstances"
],
"Resource": [
"*"
]
},
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::<aws-account-id-databricks>:role/<iam-role-for-glue-access>"
}
]
}
DatabricksワークスペースでGlueカタログインスタンスプロファイルを設定
- Adminコンソールに移動します。
- Instance Profilesタブに移動します。
- Add Instance Profileボタンをクリックするとダイアログが表示されます。
- Glueにアクセスするためのインスタンスプロファイルの作成で作成したインスタンスプロファイルARNを貼り付けます。
- Addをクリックします。
Glueカタログのインスタンスプロファイルを設定してクラスターを起動
- Databricksクラスターを作成します。
- クラスター作成ページのInstancesタブをクリックします。
-
Instance Profilesで、先ほど作成したインスタンスプロファイルを選択します。
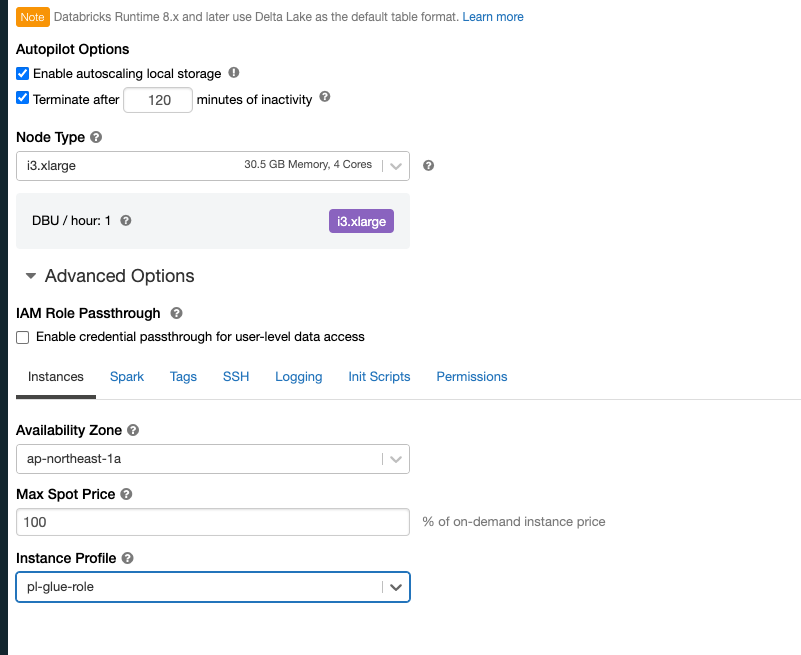
-
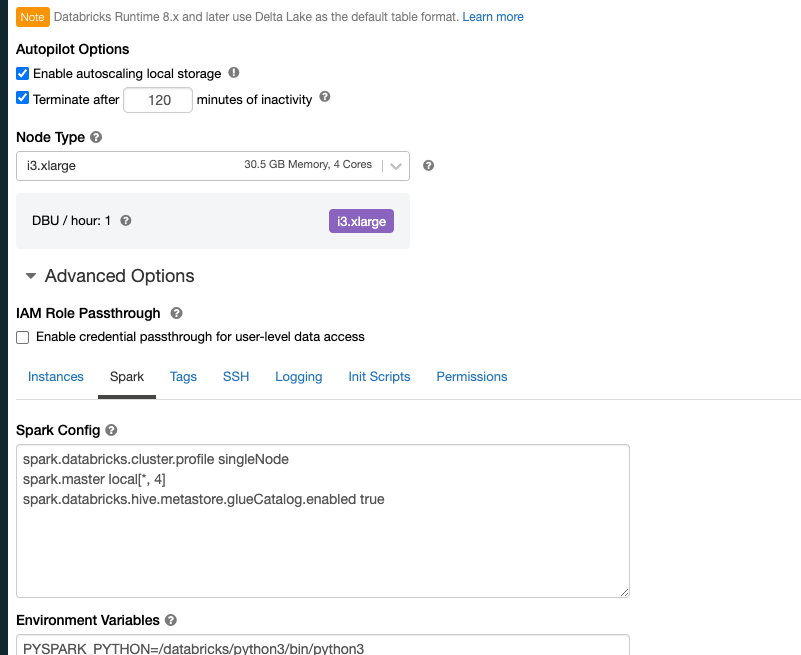
SparkタブのSpark Configで
spark.databricks.hive.metastore.glueCatalog.enabled trueを追加します。
- クラスターを起動します。
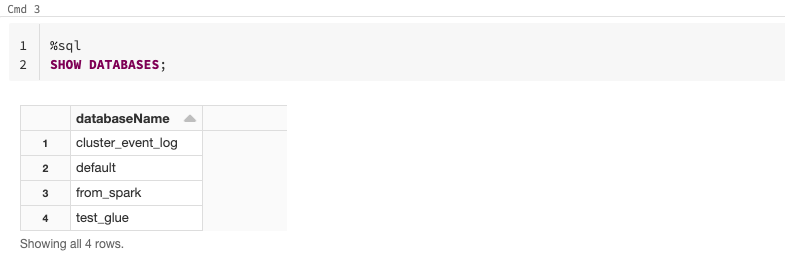
- ノートブックで以下のコマンドを実行し、メタストアが稼働していることを確認します。
Databricks SQLの設定
上記外部メタストアにアクセスするように、Databricks SQLの設定を行います。詳細はData access configurationをご覧ください。
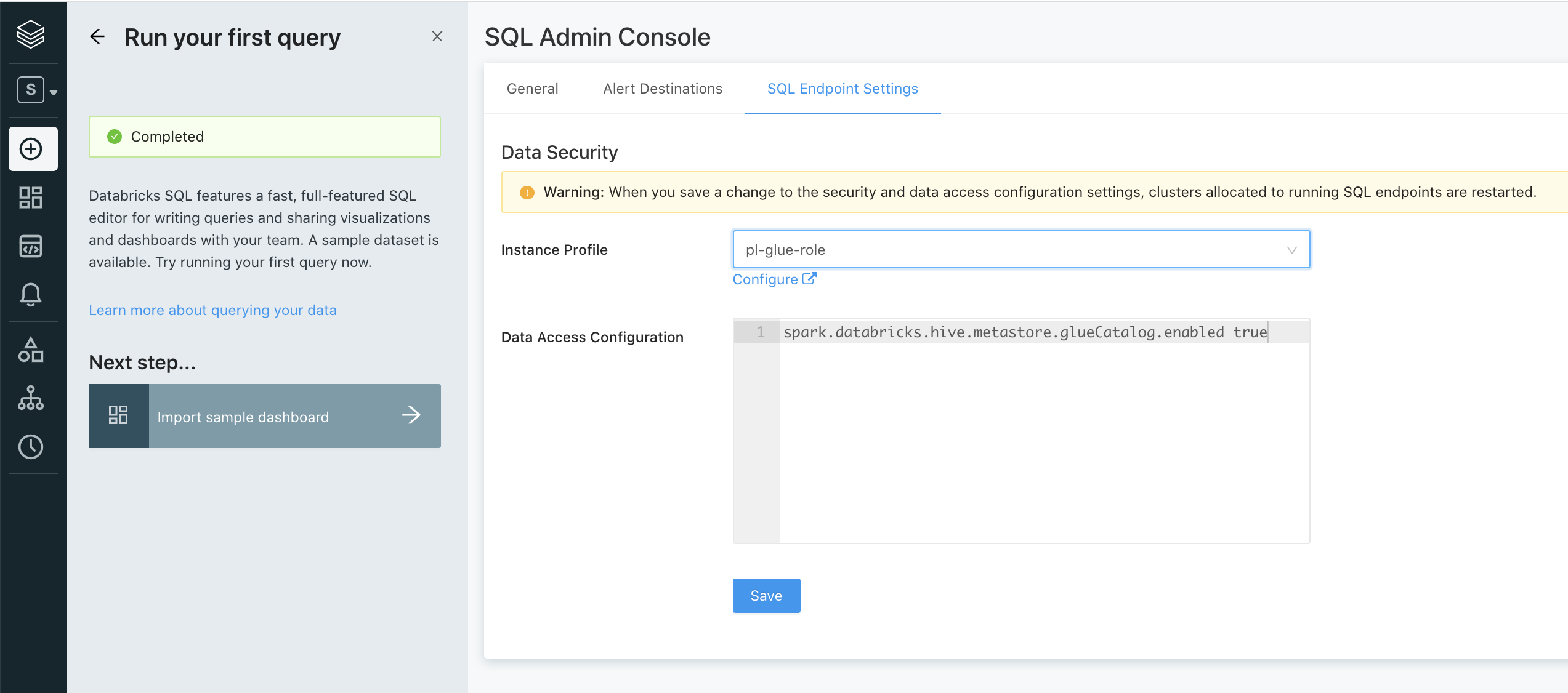
- ペルソナがSQLの状態のサイドメニューから、Settings > SQL Admin Consoleにアクセスします。
- SQL Endpoint Settingsで以下の設定を行います。
- Instance ProfileでGlueにアクセスするためのインスタンスプロファイルの作成で作成したインスタンスプロファイルを選択します。
-
Data Access Configurationに
spark.databricks.hive.metastore.glueCatalog.enabled trueを入力します。
- Saveをクリックします。
- SQLエンドポイントを起動し、Glueに対するクエリーが成功することを確認します。
外部リポジトリに対するアクセスの検討
pypi(python)やCRAN(R)などの公開ライブラリリポジトリにアクセスしたいと考えるかもしれません。これらにアクセスするには、完全なアウトバウンドロックダウンモードでのデプロイモードを再考するか、自身のアーキテクチャで必要なリポジトリにアクセスできるようにイグレスファイアウォールを使用してください。ご自身のデプロイメントの全体アーキテクチャは、ご自身の要件に依存します。質問がある場合には、Databricks担当にお問い合わせください。
注意
外部にアクセスさせないロックダウン構成では、MLflowのモデルサービングは動作しません。
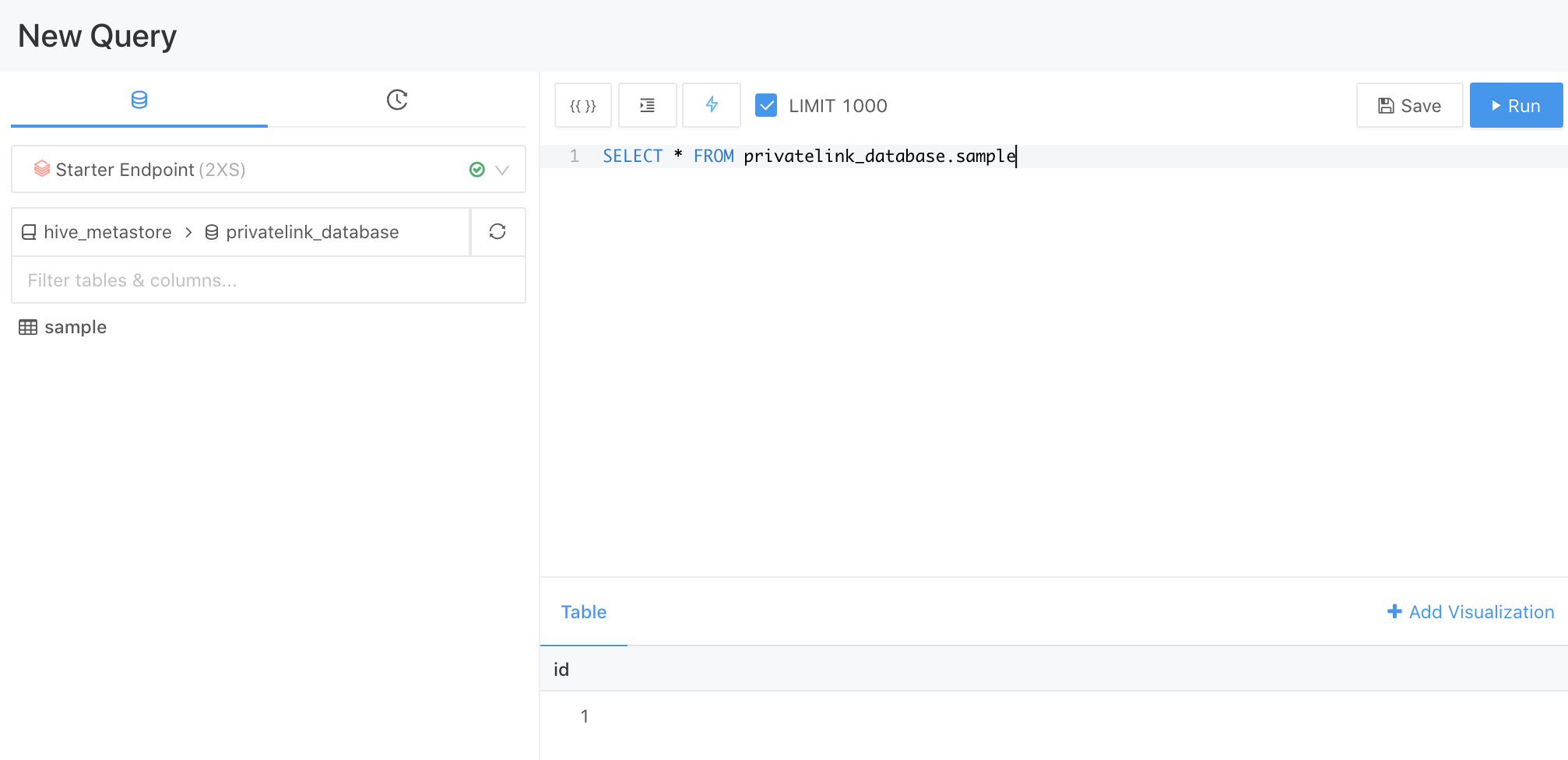
動作確認
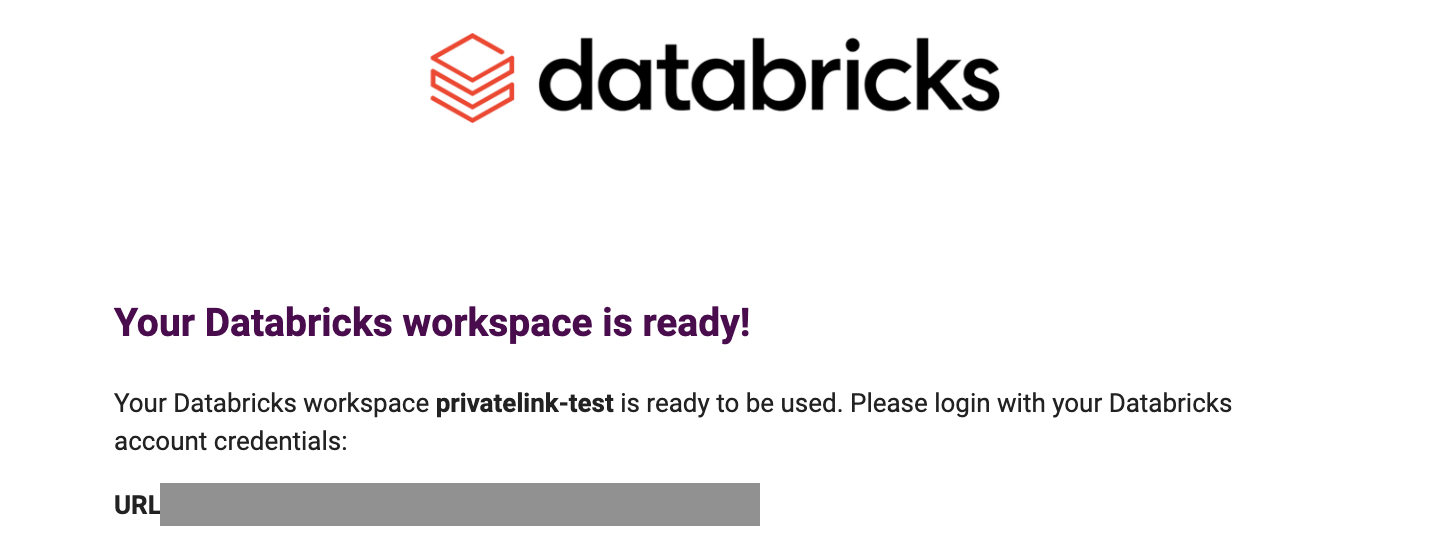
デプロイメントに成功するとアカウントオーナーにワークスペースのURLが記載されたメールが届きます。あるいは、Account Consoleにワークスペースのリンクが表示されます。
-
ワークスペースにアクセスし、アカウントオーナーでログインします。
-
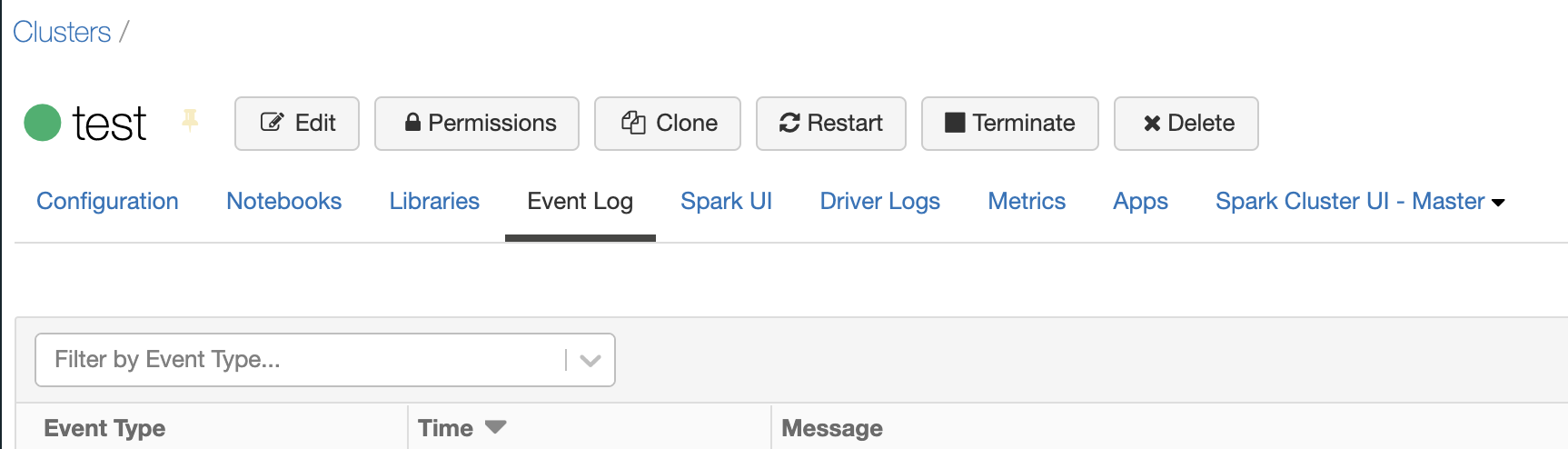
サイドメニューComputeにアクセスし、最小構成のクラスターを作成して起動します。
-
クラスターが起動すれば、設定は成功です。
-
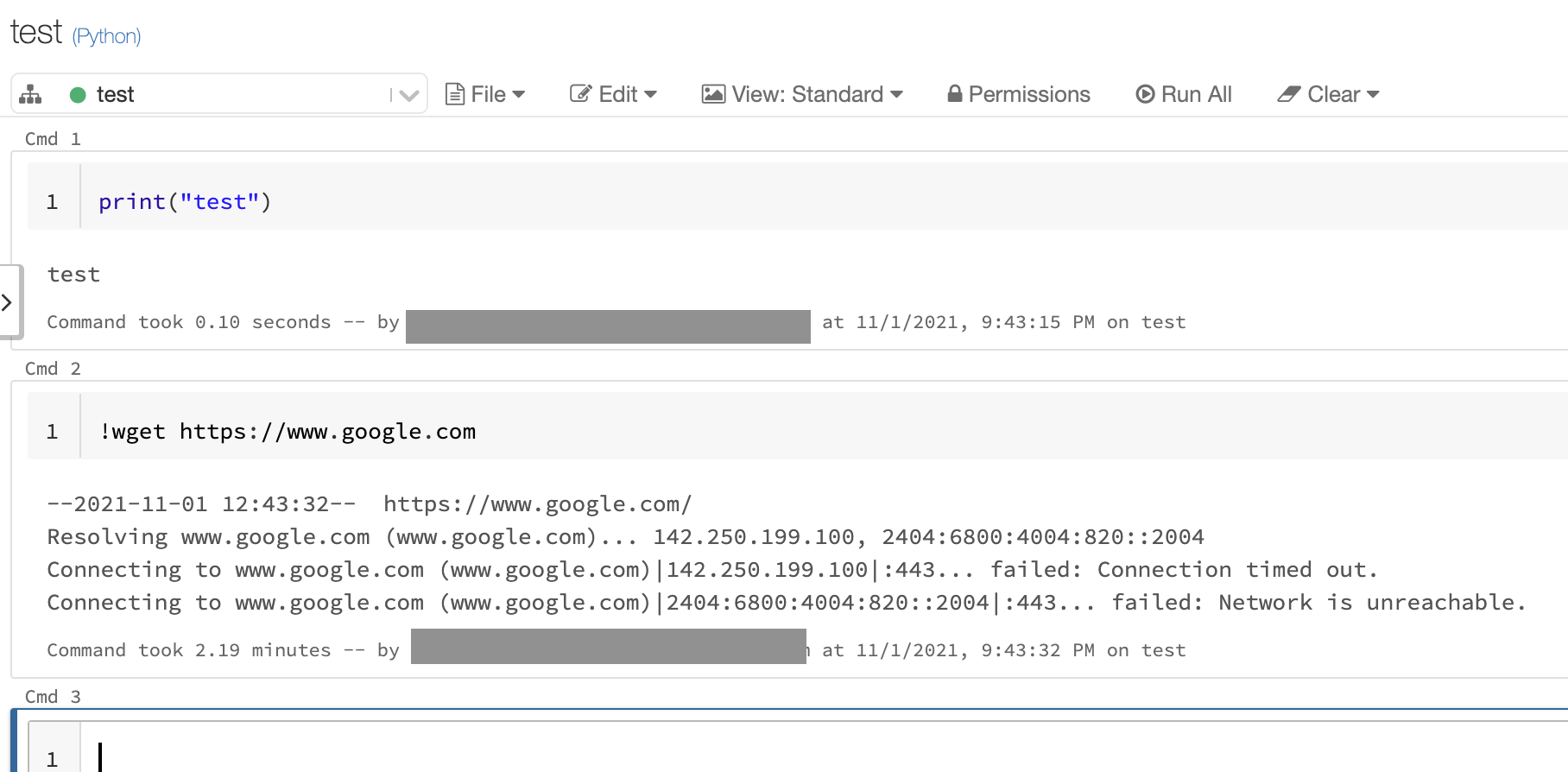
以下の様な処理を実行して、外部に接続できないことを確認することもできます。