こちらの続きと言えるでしょう。
Delta Lakeも触り始めて約三年経ちます。しかし、当時は「一体全体Delta Lakeって何??」となってました。
サンプルなどを動かしたり、ブログ記事を翻訳していく中でようやく「こういうものか」となってきた次第です。
なお、弊社エンジニアによる網羅的な記事もあります。こちらを読んでいただいた方が良いと思いますが、自分の復習も兼ねてまとめてみます。
その他のDatabricksコアコンポーネントの記事はこちらです。
Delta Lakeとは
Delta Lakeのサイトです。
こちらには以下の説明があります。
Delta LakeはSpark、PrestoDB、Flink、Trino、Hive、そして、Scala、Java、Rust、Ruby、PythonのAPIを含む計算エンジンを伴うレイクハウスアーキテクチャの構築を可能とするオープンソースのストレージフレームワークです。
これでDelta Lakeが理解できたとしたらスゴいと思います。以下の図でイメージが掴めてくるかもしれません。

左がストリーミングやバッチで取り込まれるデータソース、右側が分析や機械学習のようなユースケースとなっています。その間に鎮座しているのがDelta Lakeです。
そしてその下には、お使いの既存のデータレイクとあります。これらのキーワードに着目するとDelta Lakeが何なのかが見えてくると思います。
レイクハウスアーキテクチャとは
Databricksが提唱しているアーキテクチャであり、レイクハウスというキーワードもDatabricksが作り出したものです。
名前の由来は従来からあるデータプラットフォームである、データレイクとデータウェアハウスとを組み合わせたものです。
データウェアハウスとは
長い歴史を持つデータプラットフォームであり、構造化データの取り扱いに長けています。一方で、画像、音声、テキストのような非構造化データの取り扱いや(一部はサポートされていますが)機械学習は不得手です。このため、約10年前からデータレイクが活用されるようになりました。

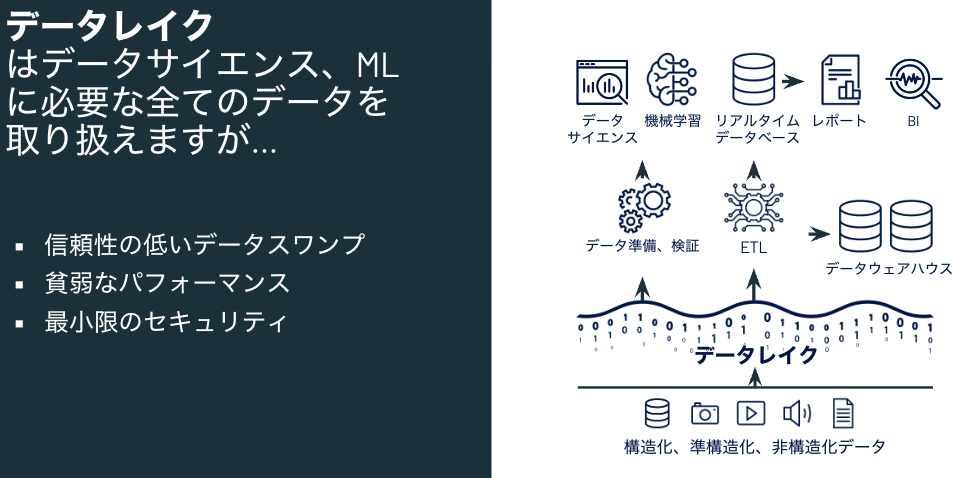
データレイクとは
クラウドのオブジェクトストレージ(AWSのS3、AzureのADLS、Google CloudのGCSなど)を活用することで、構造化データ、非構造化データを問わずにデータを蓄積、活用できるデータプラットフォームとして活用が進んできました。オブジェクトストレージの耐障害性、コストパフォーマンスなどのメリットがありますが、一方で、ガバナンスが効かない、パフォーマンスが出ないなどの課題を抱えていました。
レイクハウスとは
上述のデータウェアハウスとデータレイクの課題をお互いを補完し合うことで解決するのがレイクハウスです。

具体的には以下のように補完します。
- データウェアハウスではプロプライエタリなデータフォーマットを用いておりベンダーロックインされてしまう → データレイク上のオープンフォーマットを使用する
- データウェアハウスでは構造化データが取り扱えない(あるいは困難) → データレイクに任意のフォーマットを格納可能
- データレイクでファイルスキャンが発生するとパフォーマンスが出ない → データレイク上でデータウェアハウスのインデックスのようなパフォーマンス改善の仕組みを活用可能
- データレイクではトランザクション保証がされない → データレイク上でデータウェアハウスのようなトランザクション保証を実現
言い換えれば、データレイクとデータウェアハウスの良いところ取りをしているのがレイクハウスです。レイクハウスではデータをデータレイクに格納しますが、その際の上述の課題をデータウェアハウスで培われた技術で解決しています。
以下に、データウェアハウス、データレイク、データレイクハウスの違いをまとめます。
| データウェアハウス | データレイク | データレイクハウス | |
|---|---|---|---|
| データフォーマット | クローズド、プロプライエタリなフォーマット | オープンフォーマット | オープンフォーマット |
| データタイプ | 構造化データ、一部の準構造化データ | 全てのタイプ:構造化データ、準構造化データ、テキストデータ、非構造化(生)データ | 全てのタイプ:構造化データ、準構造化データ、テキストデータ、非構造化(生)データ |
| データアクセス | SQLのみ、ファイルへの直接アクセスは未サポート | SQL、R、Pythonなど他の言語による直接のファイルアクセスのためのオープンAPI | SQL、R、Pythonなど他の言語による直接のファイルアクセスのためのオープンAPI |
| 信頼性 | ACIDトランザクションによる高品質、高信頼性のデータ | 低品質、データスワンプ | ACIDトランザクションによる高品質、高信頼性のデータ |
| ガバナンス、セキュリティ | テーブルの行/列レベルでのきめ細かいセキュリティ、ガバナンス | ファイルレベルのセキュリティ、貧弱なガバナンス | テーブルの行/列レベルでのきめ細かいセキュリティ、ガバナンス |
| パフォーマンス | 高 | 低 | 高 |
| スケーラビリティ | スケーリングによるコストは指数関数的に増加 | データタイプに関係なく、低コストで大規模データを保持できるようにスケーリング | データタイプに関係なく、低コストで大規模データを保持できるようにスケーリング |
| ユースケースサポート | BI、SQLアプリケーション、意思決定に限定 | 機械学習に限定 | BI、SQL、機械学習に対応できるアーキテクチャ |
そして、このレイクハウスを実現するために欠かせないソフトウェアがDelta Lakeとなります。

Bronze、Silver、Goldとは
聞き慣れない方もいらっしゃるかと思いますが、これらはメダリオンアーキテクチャの構成要素となります。こちらで触れたようにデータソースからユースケースを繋いでいるのがデータパイプラインとなります。生データそのままでは分析や機械学習で活用することは困難であり、何かしらのデータ加工が必要となります。この加工処理を行うのがデータパイプラインです。そして、このデータパイプラインは多段になることが多いので、それらを整理するために用いる考え方がメダリオンアーキテクチャとなります。これは整理学であり、特定の機能を指すものではありません。
- ブロンズ(bronze): 生データの保持、履歴管理用途のテーブル
- シルバー(silver): クレンジング、他のテーブルと結合した状態のテーブル
- ゴールド(gold): 分析で用いる集計テーブル、機械学習で用いる特徴量テーブル
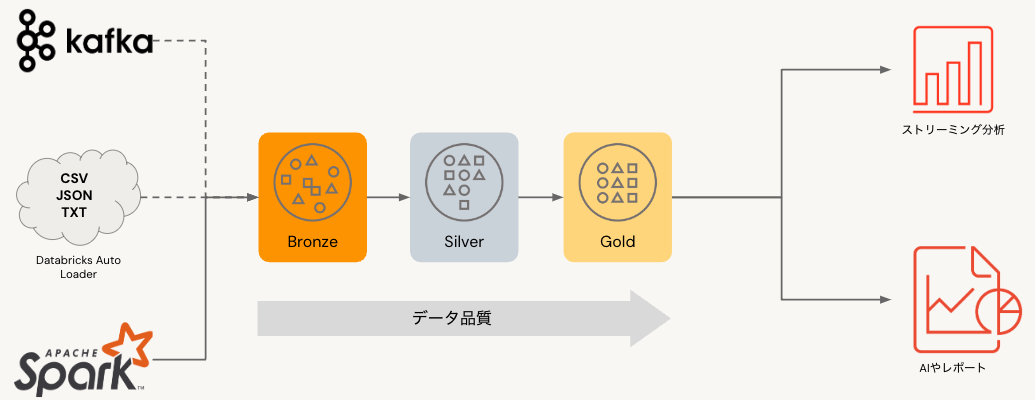
Delta Lakeを用いることで、このようなメダリオンアーキテクチャの実現が容易になります。
データレイクとDelta Lakeの関係は
こちらでお使いの既存のデータレイクとして触れたように、レイクハウスにおけるデータの置き場所はデータレイクです。その際に生じるデータレイクの課題をDelta Lake(が提供するデータウェアハウス由来の機能)で解決しているのがレイクハウスとなります。
Delta Lakeのデータファイル自体はデータレイクに格納されます。後ほどのサンプルで説明しますが、Delta Lakeはファイルとしてだけではなく、SQLで操作可能なテーブルとしても取り扱うことが可能です(最初がこれが分からなかったです)。この際にはDelta Lakeをメタストア(HiveメタストアやUnity Catalogメタストア)に登録する必要があります。
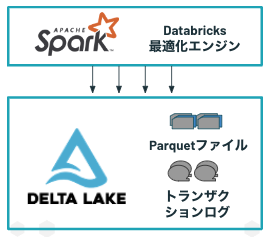
Delta Lakeの提供機能
Deltaエンジンなどの関連機能は存在しますが、Delta Lake自体はデータフォーマットと考えていただくのが良いかと思います。以下のような機能を提供しています。フォーマットという意味ではベースはApache Parquetです。これにトランザクションログの機能が追加されたものがDelta Lakeです。データの読み書きにおいては、Apache Sparkとの親和性が高いです。
-
ACIDトランザクション
- データの更新処理はすべてトランザクションログに記録されます。トランザクションログによって、データレイクに対する操作を完全に成功するか、後でリトライするために完全にロールバックされるかすることが可能となります。

- データの更新処理はすべてトランザクションログに記録されます。トランザクションログによって、データレイクに対する操作を完全に成功するか、後でリトライするために完全にロールバックされるかすることが可能となります。
-
インデックス Delta Lakeの実態はオブジェクトストレージ上のファイルなので、最も性能が出ないファイルのフルスキャンは一番避けるべき事象です。Delta Lakeではこれを実現するための様々な機能を提供しています。
- パーティショニング:典型的なクエリーに対するファイルレイアウト
- データスキッピング:統計情報に基づくファイルの刈り込み
- Z-Ordering:複数カラムに基づくレイアウトの最適化
-
タイムトラベル、監査ログ Delta Lakeに対する更新処理はすべてトランザクションログに記録されます。これによって任意のタイミングのデータ断面にアクセス(タイムトラベル)することができます。
- 実験、レポートの再現:特定のタイミング、バージョンのデータを参照
- アクシデントからのロールバック:1日前のデータにロールバック

-
スキーマエンフォースメント
- Delta Lakeテーブルのスキーマを強制することが可能です。これによってデータのスキーマが勝手に変更され、データ品質が低下することを避けることができます。なお、ビジネス要件の変更に応じて明示的にスキーマを進化させることもできます。
- バッチとストリーミングの統合
-
DMLオペレーション
- Delta LakeにはANSI SQLを用いて読み書きを行うことができます。
- オープンフォーマット
- 大規模メタデータ管理
サンプル
こちらのチュートリアルを実行していきます。Databricksで実行していきます。
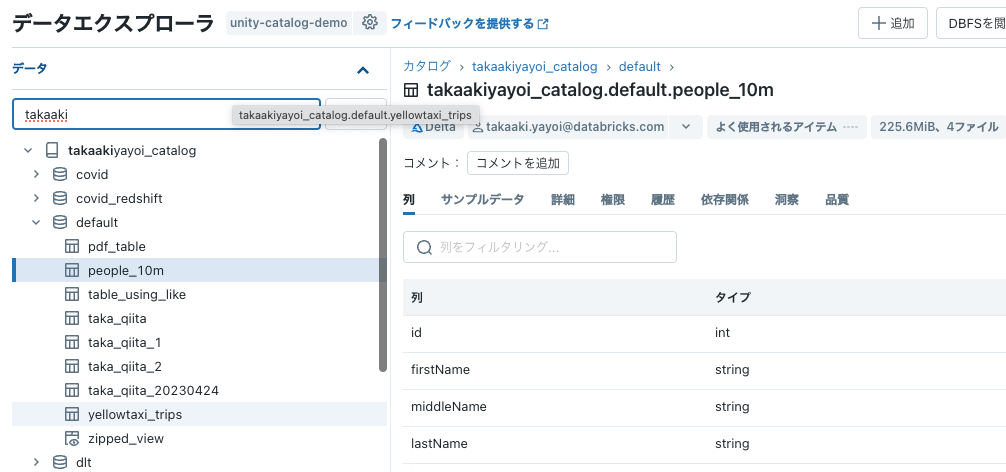
テーブルの作成
spark.read.loadでDelta Lakeのデータを読み込み、write.saveAsTableでテーブルに保存します。これによって、テーブルに対してSQLでアクセスできるようになります。
# ソースからデータのロード
df = spark.read.load("/databricks-datasets/learning-spark-v2/people/people-10m.delta")
# テーブルへのデータの書き込み
# カタログやデータベースを適宜選択してください
table_name = "takaakiyayoi_catalog.default.people_10m"
df.write.saveAsTable(table_name)
テーブルが作成されます。
テーブルのメタデータを確認します。%sqlマジックコマンドを使って直接SQLを実行します。
%sql
DESCRIBE DETAIL takaakiyayoi_catalog.default.people_10m;
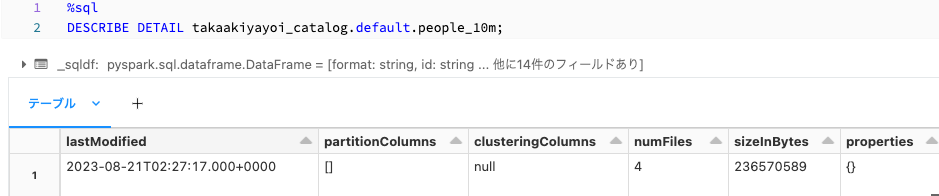
更新日時やファイルパスなどを確認できます。
UPSERT
UPSERTとはUpdateとInsertの組み合わせです。ターゲットテーブルに対してあるテーブルとの突き合わせを行い、一致する場合にはUpdate、一致しない場合にはInsertを行います。以下の例ではカラムidで一致するかどうかを判定しています。
%sql
CREATE OR REPLACE TEMP VIEW people_updates (
id, firstName, middleName, lastName, gender, birthDate, ssn, salary
) AS VALUES
(9999998, 'Billy', 'Tommie', 'Luppitt', 'M', '1992-09-17T04:00:00.000+0000', '953-38-9452', 55250),
(9999999, 'Elias', 'Cyril', 'Leadbetter', 'M', '1984-05-22T04:00:00.000+0000', '906-51-2137', 48500),
(10000000, 'Joshua', 'Chas', 'Broggio', 'M', '1968-07-22T04:00:00.000+0000', '988-61-6247', 90000),
(20000001, 'John', '', 'Doe', 'M', '1978-01-14T04:00:00.000+000', '345-67-8901', 55500),
(20000002, 'Mary', '', 'Smith', 'F', '1982-10-29T01:00:00.000+000', '456-78-9012', 98250),
(20000003, 'Jane', '', 'Doe', 'F', '1981-06-25T04:00:00.000+000', '567-89-0123', 89900);
MERGE INTO takaakiyayoi_catalog.default.people_10m
USING people_updates
ON people_10m.id = people_updates.id
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *;
3行がUpdateされ、3行がInsertされました。

この他にUPDATE、DELETE、INSERTも可能です。通常のデータベースと同じようにテーブルを操作することができます。
読み取り
PythonやSQLなどの言語からアクセスできます。
people_df = spark.read.table("takaakiyayoi_catalog.default.people_10m")
display(people_df)
%sql
SELECT * FROM takaakiyayoi_catalog.default.people_10m;
履歴の参照
上述したように、Delta Lakeのテーブルに対する更新処理はすべて記録されます。DESCRIBE HISTORYで履歴を確認できます。
%sql
DESCRIBE HISTORY takaakiyayoi_catalog.default.people_10m;
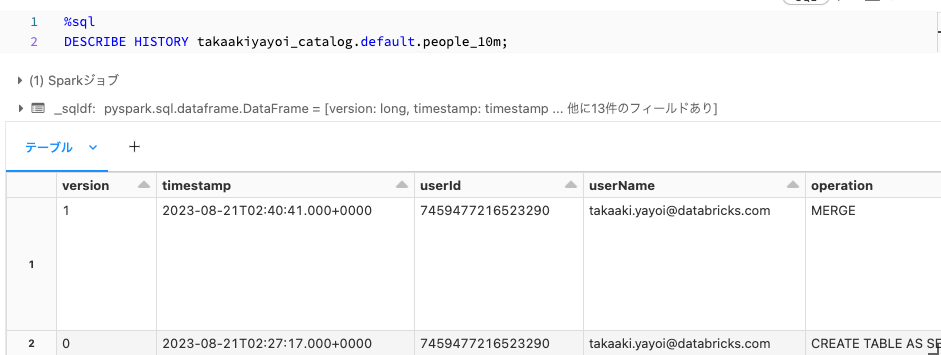
タイムトラベル
Delta Lakeでは任意の断面のデータにアクセスすることができます。これがタイムトラベルです。以下の例ではバージョン番号0を指定しています。
SELECT * FROM takaakiyayoi_catalog.default.people_10m VERSION AS OF 0;
まとめ
Delta Lakeを使い始めた当初は「ファイルなのかテーブルなのか?」と思っていましたが、結局のところその両方でした。今では大規模データのハンドリングにおいては欠かせないものとなっており、通常はテーブルを操作している感覚と大差ないので、Delta Lakeの存在を気にしなくなっていると言っても過言ではありません。しかし、Delta Lakeは奥深い(個人的にはDatabricks関連コンポーネントで一番奥深いと思ってます)ものであり、日々機能も改善されていっています。興味のある方は以下の記事もご覧ください。なお、DatabricksのデフォルトのデータフォーマットはDelta Lakeとなっていますので、フォーマットを指定することなしにご活用いただけます!
- Delta Lakeクイックスタートガイド
- Delta Lakeのチュートリアル
- Delta Lakeのベストプラクティス
- DatabricksにおけるすべてのDelta的なものは何か?
- はじめてのDelta Lakeへのデータ取り込み
- Delta Lakeテーブルのバッチ読み込み・書き込み
- Deltaテーブルのdelete、update、merge
- Delta Lakeにダイビング:トランザクションログを読み解く
- Delta Lakeにダイビング:スキーマの強制、進化
- Delta Lakeにダイビング:DMLの内部処理(Update、Delete、Merge)
- Delta Lakeのチェンジデータフィード