Understanding the Delta Lake Transaction Log - Databricks Blogの翻訳です。
Delata Lakeを理解するためには、重要な機能であるACIDトランザクション、スケーラブルなメタデータ管理、タイムトラベルなどに共通する要素となるトランザクションログが鍵となります。本記事では、Delta Lakeのとランザクションログが何者なのか、ファイルレベルでどのように動作するのか、そして、同時読み込み、書き込みにおいてどのようなエレガントなソリューションを提供するのかを探ります。
Delta Lakeのトランザクションログとは?
Delta Lakeのトランザクションログ(DeltaLogとも呼ばれます)は、Delta Tableが作成された以降に為されたすべてのトランザクションの記録です。
トランザクションログは何のために?
Single Source of Truth(ただ一つの真実)
特定のテーブルに対して同時に読み書きが行えるように、Delta LakeはApache Spark™の上に構築されています。ユーザーに対して常に適切なビューを表示するために、Delta Lakeのとランザクションログはsingle source of truth - ユーザーがテーブルに対して行ったすべての変更を追跡する集中管理リポジトリを提供します。
ユーザーが初めてDelta Lakeテーブルを見込むか、以前読み込んでから変更されたテーブルにクエリーを発行した際、**Sparkはテーブルに新たなトランザクションが発生していないかトランザクションログを確認し、ユーザーのテーブルに新たな変更を反映します。**これによって、ユーザーのテーブルのバージョンは最新のクエリー時点のマスターレコードと常に同期され、競合が起きるようなテーブルの変更をユーザーが行えないようにします。
Delta Lakeにおける原子性の実装
ACIDトランザクションの4つの属性の一つ、原子性はデータレイク上で(INSERTやUPDATEのような)オペレーションが完全に完了するか、しないかのどちらかであることを保証します。この属性なしには、ハードウェアの故障やソフトウェアのバグによってデータがテーブルに部分的に書き込まれた状態になってしまい、データの破損を引き起こすことになります。
**Delta Lakeのトランザクションログは原子性を保証するメカニズムです。**事実上、トランザクションログに記録されないということは、起きなかったということです。完全時に実行されたトランザクションのみを記録し、記録を単一の真実とすることで、Delta Lakeのトランザクションログによって、ペタバイトスケールであっても、ユーザーはデータを判断でき、根本的な信頼性に関して心の平安を得ることができるのです。
トランザクションログはどのように動作するのか?
トランザクションの原子的コミットへのブレークダウン
テーブルを変更するためにユーザーがオペレーション(INSERT、UPDATE、DELETE)を行うときは常に、Delta Lakeはオペレーションを以下のアクションから構成される別々のステップにブレークダウンします。
- Add file - データファイルの追加
- Remove file - データファイルの削除
- Update metadata - テーブルのメタデータの更新(テーブル名、スキーマ、パーティショニングの変更)
- Set transaction - 構造化ストリーミングジョブにおいて、特定のIDが与えられコミットされたマイプロバッチの記録
- Change protocol - Delta Lakeトランザクションログを最新のソフトウェアプロトコルに切り替えることで新機能を有効化
- Commit info - どのオペレーションが実行されたのか、いつからいつまでの期間実行されたのかというコミットに関わる情報を格納
これらのアクションは順にトランザクションログに記録され、原始的な単位がコミットと呼ばれます。
例えば、ユーザーがテイブルに新たな列を追加し、いくつかのデータを追加するトランザクションを作成するとします。Delta Lakeはこのトランザクションをコンポーネントに分割し、トランザクションが完了した際には、以下のコミットとしてトランザクションログに追加します。
- Update metadata - 新たな列をスキーマに追加
- Add file - 新たなファイルの追加
ファイルレベルでのDelta Lakeのトランザクションログ
**Delta Lakeテーブルを作成する際、テーブルのトランザクションログは_delta_logサブディレクトリに自動的に作成されます。テーブルに変更を加えた際には、それらの変更は、順番に原子的なコミットとしてトランザクションログに記録されます。**それぞれのコミットは、000000.jsonから始まるJSONファイルとして書き出されます。次の変更は000001.json、さらに次の変更は000002.jsonと言うように、追加の変更は数字を増やしながらさらなるJSONファイルを作成します。
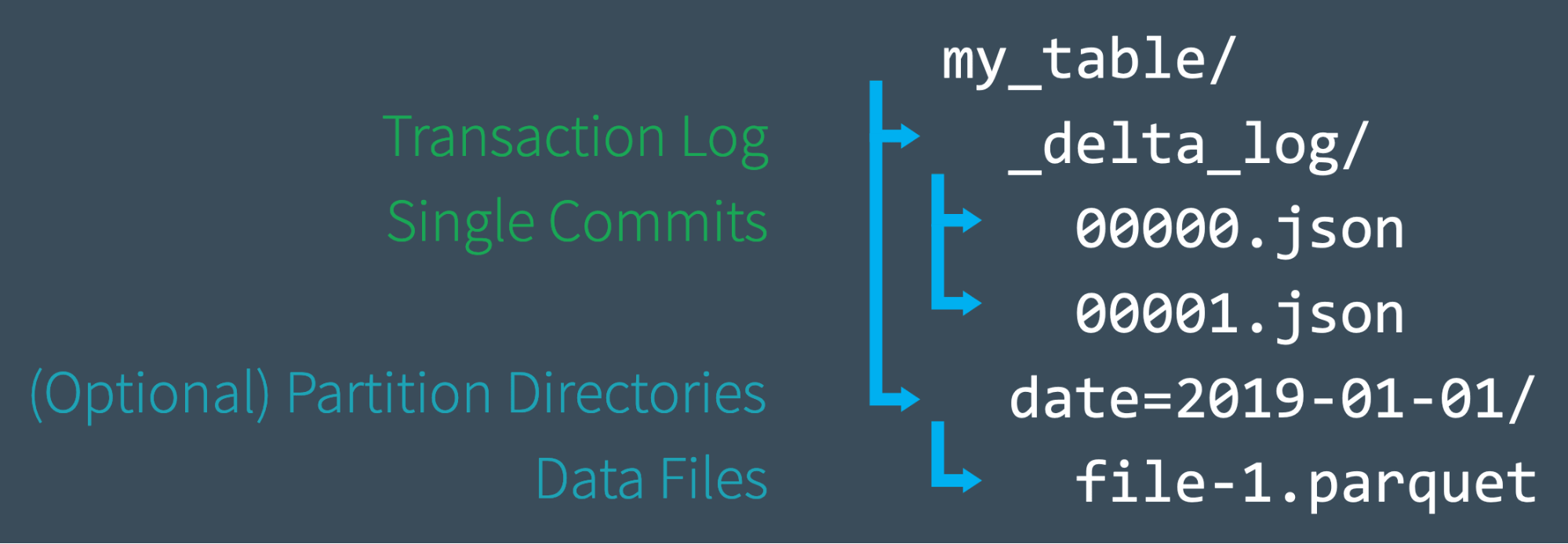
例えば、我々は1.parquet、2.parquetデータファイルからテーブルにレコードを追加するとします。このトランザクションは自動的にトランザクションログに記録され、コミット000000.jsonとしてディスクに書き込まれます。今度は気が変わって、これらのファイルを削除し、代わりに新たなファイル(3.parquet)を追加します。これらのアクションは、以下のようにトランザクションに次のコミット000001.jsonとして記録されます。

もはや1.parquet、2.parquetはDelta Lakeテーブルに含まれていませんが、追加、削除はテーブルに対して行われたオペレーションであるので、最終的には取り消されたとしても、これらはトランザクションログに記録されたままとなります。Delta Lakeはこのように原子的コミットを維持します。これによって、テーブルに対するイベントの監査、特定の時点のテーブルを参照できる"タイムトラベル"が可能となります。
また、我々がテーブルからデータファイルを削除したとしても、**Sparkは積極的にディスクからファイルを削除しません。**ユーザーはVACUUMを使用することで、不要なファイルを削除することができます。
チェックポイントファイルによる迅速な状態の再計算
トランザクションログに対して合計10のコミットを行うと、Delta Lakeは同じ_delta_logサブディレクトリにParquetフォーマットでチェックポイントファイルを保存します。Delta Lakeは10コミットごとに自動でチェックポイントファイルを生成します。
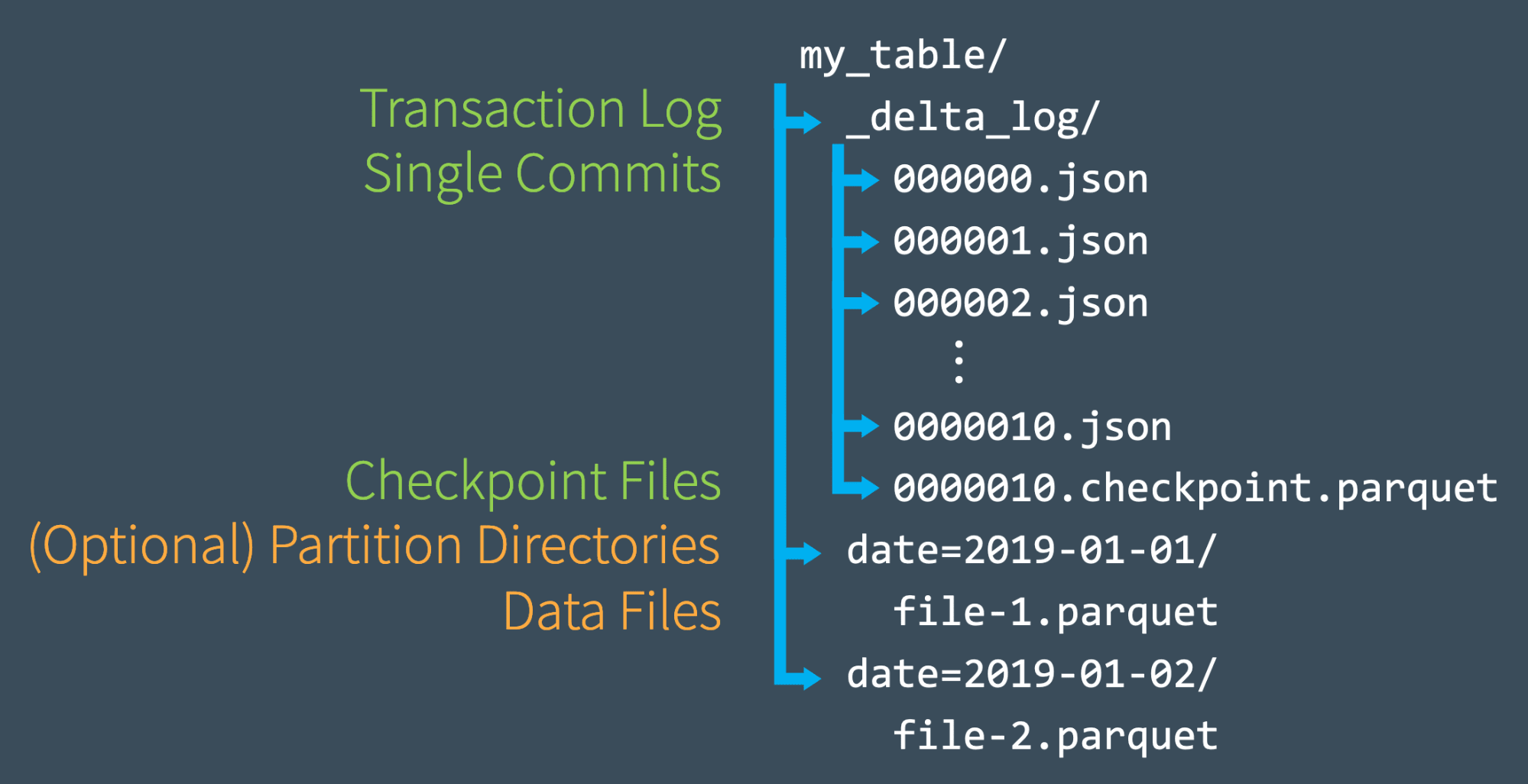
**これらのチェックポイントファイルにはある時点のテーブルの全体的な状態が、Sparkが容易かつ高速に読み込めるようにParquetフォーマットで保存されます。**言い換えると、小さく非効率的なJSONファイルを再処理することなしに、Spark readerがチェックポイントファイルを読み込むことで、テーブルの状態を再現できる"ショートカット"を提供していると言えます。
スピードを改善するために、SparkはlistFromオペレーションを実行し、トランザクションログの全てのファイルを参照し、迅速に最新のチェックポイントファイルまでスキップし、最新のチェックポイント以降のJSONのコミットのみを処理することができます。
これがどのように動作するのかをデモするために、以下の図に示すように000007.jsonまでコミットをしたものと考えましょう。最新バージョンのテーブルを自動でメモリにキャッシュすることで、Sparkはこのコミットまで順調に進みます。しかし、他の書き込み処理(例えば非常にやる気のあるあなたのチームメイト)が同時にテーブルにデータを追加し、0000012.jsonまでコミットを追加するものとします。
これらの新たなトランザクションを取り込みテーブルの状態を更新するために、SparkはlistFrom version 7オペレーションを実行し、テーブルに対する新たな変更を確認します。

Sparkは全ての中間JSONファイルを処理するのではなく、コミット#10自転の全ての状態を含む最新のチェックポイントファイルまでスキップします。このため、Sparkは現在のテーブルの状態を取得するには、0000011.jsonと0000012.jsonを処理するだけで済みます。そして、Sparkはバージョン12のテーブルをメモリにキャッシュします。このワークフローに従うことで、Delta LakeによってSparkは常に効率的にテーブルの状態を最新に保つことができます。
複数の同時読み書きへの対応
ハイレベルでどのようにDelta Lakeのトランザクションログが動作するのかを理解したので、同時実行性に関して話しましょう。ここまでの例では、ユーザーが順にトランザクションをコミットする、あるいは、少なくとも競合が発生しないシナリオをカバーしてきました。しかし、Delta Lakeが同時書き込み、読み取りを取り扱う際には何が起きるのでしょうか?
答えはシンプルです。Delta LakeはApache Sparkは共に動作するため、複数のユーザーがテーブルを同時に更新できるだけではなく、予期されたものです。これらのシチュエーションに対応するために、Delta Lakeは楽観的同時実行制御(optimistic concurrency control)を行います。
楽観的同時実行制御とは?
楽観的同時実行制御は、互いに競合することなしに、異なるユーザーがテーブルに対するトランザクション処理(変更)を完了できるという仮定に基づいて、同時トランザクションを取り扱う方法です。ペタバイトのデータを取り扱う際は異なるユーザーがデータの異なる箇所に対して作業を行う可能性が高いため、この処理は非常に高速であり、同時トランザクションを競合させることなく処理を完了することができます。
例えば、あなたと私が一緒にジグソーパズルに取り組んでいるとします。例えば、それぞれが異なる箇所、あなたが角で私が縁で作業している限りは、巨大なパズルを同時に作業できない理由はなく、二倍の速さで完成させることができます。同時に同じピースを必要とするときにだけ競合が発生します。これが楽観的同時実行制御です。
もちろん、楽観的同時実行制御であっても、ときにはユーザーが同じときにデータの同じパーツを変更しようとするケースがあります。幸い、Delta Lakeには、これを取り扱うためのプロトコルがあります。
楽観的に競合を解決する
ACIDトランザクションを提供するために、Delta Lakeにはコミットをどのような順序に並び替えるべきか(データベースにおけるシリアライズ可能性)を決定し、同時に二つ以上のコミットが起こった場合にどうすべきかを決定するためのプロトコルがあります。Delta Lakeは相互排他のルールを実装し、楽観的に競合を解決しようとすることで、これらのケースを取り扱います。このプロトコルによって、Delta LakeはアイソレーションのACID原理に基づいて処理を行います。すなわち、複数の同時書き込みを、それらの書き込みが独立かつ順番に行われたものとして扱うことになります。
一般的には、プロセスは以下のように進みます:
- 開始時点のテーブルバージョンを記録
- 読み取り/書き込みを記録
- コミットの試行
- 一方が勝った場合には、読み取ったものが変化したかどうかをチェック
- 繰り返す
実際にこれがどのように動作するのかを見るために、Delta Lakeが思いがけなく発生した競合をどのように取り扱うのかを以下の図で見てみましょう。二人のユーザーが同じテーブルから読み取りを行い、それぞれがデータを追加しようとするケースを考えてみます。

- Delta Lakeは変更が為される前に読み込まれる開始時点のテーブルバージョン(バージョン0)を記録します。
- ユーザー1とユーザー2は同時にデータを追加しようとします。ここでは、一つのコミットのみが次に起こりえ、
000001.jsonとして記録されるため競合が発生します。 - Delta Lakeはこの競合を"相互排他"の考え方で取り扱います。すなわち、一人のユーザーのみがコミット
000001.jsonを成功させることができると言うことです。ユーザー1のコミットが受け入れられ、ユーザー2のコミットは却下されます。 - ユーザー2にエラーを表示するのではなく、Delta Lakeはこの競合を楽観的に取り扱うことを好みます。テーブルに対して新たなコミットがなされていないかを確認し、これらの変更を静かに反映させ、(データを処理することなしに)シンプルにユーザー2のコミットを新たに更新されたテーブルに対して再度適用し、
000002.jsonのコミットを成功します。
**大抵のケースでは、この調整はサイレント、シームレスに行われ成功します。**しかし、Delta Lakeが楽観的に問題を解決できない場合(例えば、ユーザー2が削除したファイルをユーザー1が削除する)に残された選択肢はエラーを発生させることです。
最後に付け加えることとして、Delta Lakeテーブルに対するトランザクションはディスクに直接書き込まれるため、この処理はACIDの頑健性を満足します。すなわち、システム障害が起きてもデータは永続化されます。
その他のユースケース
タイムトラベル
全てのテーブルはDelta Lakeのトランザクションログに記録されたコミットの累積の結果であり、それ以上でもそれ以下でもありません。トランザクションログは、テーブルの初期状態から現在の状態に至るまでに何が起きたのかを示す、ステップバイステップの操作ガイドと言えます。
このため、初期状態からは任意の時点以前のコミットを処理することで、任意の時点のテーブルの状態を再現することができます。これが強力な"タイムトラベル"機能、データバージョニングであり、あらゆる状況におけるライフセーバーになります。詳細に関しては、ブログ記事Introducing Delta Time Travel for Large Scale Data Lakesや、Delta Lakeのドキュメントをご覧ください。
データリネージュとデバッグ
テーブルになされた全ての変更記録を提供するので、Delta Lakeのトランザクションログは、ガバナンス、コンプライアンスの観点で重要なリネージュ(系統情報)をユーザーに提供します。また、パイプラインにおける不可逆な変更の原因となったアクションまで追跡することが可能になります。ユーザーは過去の変更のメタデータを参照するためにDESCRIBE HISTORYを実行できます。
Delta Lakeのトランザクションログのまとめ
この記事では、Delta Lakeのトランザクションログがどのように動作するのかを深掘りしました。
- トランザクションログとは何か、どのように構成されているのか、どのようにコミットがディスク上のファイルとして書き込まれるのか
- Delta Lakeが原子性を実装するために、トランザクションログがどのようにして単一の真実として寄与するのか
- Delta Lakeがそれぞれのテーブルの状態をどのように計算するのか、最新のチェックポイントにたどり着くためにどのようにトランザクションログを使用するのか
- 楽観的同時実行制御を用いて、テーブル変更の際の複数の同時読み取り/書き込みを実現
- どのようにDelta Lakeが相互排他を用いてコミットを適切にシリアライズするのか、競合の際どのように静かにリトライするのか
関連記事
- Delta Lakeにダイビング #1:トランザクションログを読み解く
- Delta Lakeにダイビング #2:スキーマの強制、進化
- Delta Lakeにダイビング #3:DMLの内部処理(Update、Delete、Merge)