Delta Lake Tutorial: How to Easily Delete, Update, and Merge Using DML - The Databricks Blogの翻訳です。
これまでの記事トランザクションログを読み解く、スキーマの強制、進化でDelta Lakeのトランザクションログがどのように動作するのか、スキーマ強制と進化の内部処理を説明しました。Delta LakeはDELETE、UPDATE、MERGEを含むDML(Data manipulation language)コマンドをサポートしています。これらのコマンドはチェンジデータキャプチャ(CDC)や監査、ガバナンス、さらには、GDPR/CCPAワークフローなどをシンプルなものにします。この記事では、それぞれのDMLコマンドの使い方、コマンドを実行した際に背後でDelta Lakeが何をしているのかを説明し、それぞれに対するパフォーマンスチューニングのティップスを紹介します。特に以下の点をご説明します:
- Delta LakeのACIDトランザクションログ入門
- DELETE、UPDATE、MERGEを実行する際の基本を理解する
- これらのタスクを実行する際のアクションを理解する
- Delta Lakeにおけるパーティションプルーニングを理解する
- Delta Lakeでストリームがどのように動作するのか
この記事に関する情報は、Diving into Delta Lake Part 3: How do DELETE, UPDATE, and MERGE workの動画でも参照できます。
Delta Lake: 基本的なメカニズム
まず初めに、Delta Lakeがファイルレベルでどのように構成されているのかをクイックに見てみましょう。新たなテーブルを作成した際、Deltaはデータを一連のParquetファイルとして保存し、Delta Lakeトランザクションログを_delta_logフォルダに作成します。ACIDトランザクションログは、テーブル作成以来の全ての変更(トランザクション)のマスターレコードとして動作します。テーブルに変更(例えば、新規データの追加、更新、マージ)を加えると、Delta Lakeはそれぞれの新たなトランザクションを、_delta_logフォルダ内に00...00000.jsonで始まり、カウントアップしていくJSONファイルとして保存します。10トランザクションごとに、Deltaは"チェックポイント"Parquetファイルを同じフォルダに作成します。これにより、読み取り処理がテーブルの状態を迅速に再構築できます。
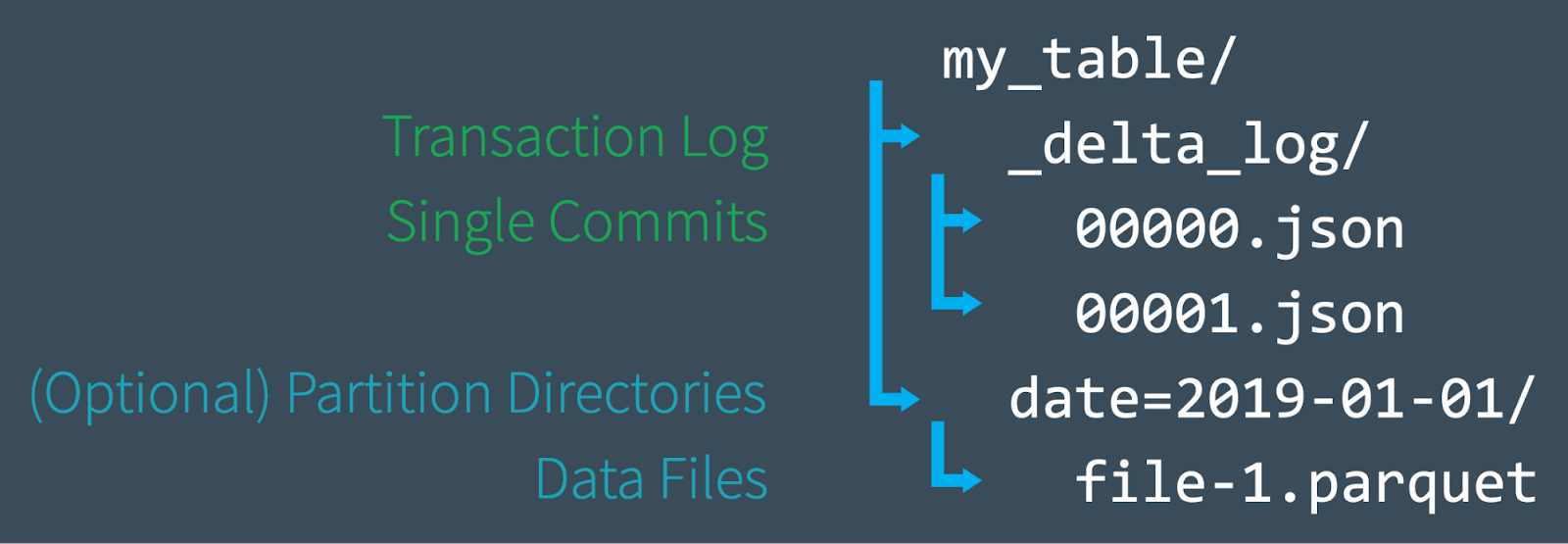
最終的には、Delta Lakeテーブルにクエリーを行った際、読み取りを行うリーダーはトランザクションログを参照し、迅速にどのデータファイルが最新バージョンのテーブルを構成しているのかを特定します。クラウドオブジェクトストレージからファイルの一覧を取得するのではなく、必要なファイルの正確なパスを指定することで、劇的なクエリー性能の改善を実現します。この記事で議論するように、DMLオペレーションによってDelta Lakeはその場でテーブルを変更するのではなく、新たなバージョンのファイルを作成します。そして、それを追跡するためにトランザクションログを使用します。詳細に関しては、以前の記事Delta Lakeにダイビング #1:トランザクションログを読み解くを参照ください。
これでファイルシステムレベルでDelta Lakeがどのように動作するのかに関して基本的な理解ができたので、次にDelta LakeでどのようにDMLコマンドを使うのか、内部で何が起きているのかに関してダイブしましょう。以下の例では、Delta Lake 0.7.0とApache Spark 3.0におけるSQLシンタックスを用います。詳細に関しては、Enabling Spark SQL DDL and DML in Delta Lake on Apache Spark 3.0を参照ください。
Delta Lake DML: UPDATE
**述語(predicate)**とも呼ばれるフィルタリング条件にマッチする行を選択的に更新するためにUPDATEを使用できます。以下のコードはUPDATE文における述語の使い方を説明しています。
-- Update events
UPDATE events SET eventType = 'click' WHERE eventType = 'clck'
UPDATE: 内部処理
Delta Lakeはテーブルに対するUPDATEを2つのステップで実行します:
- 述語に合致するデータを含むファイルを検索し選択します。Delta Lakeはこのプロセスを高速化できる場合にはデータスキッピングを活用します。
- マッチしたファイルをメモリに読み込み、適切な行をアップデートし、結果を新たなデータファイルに書き出します。
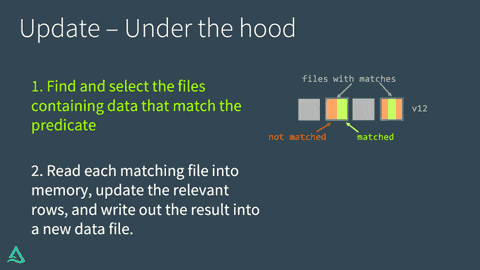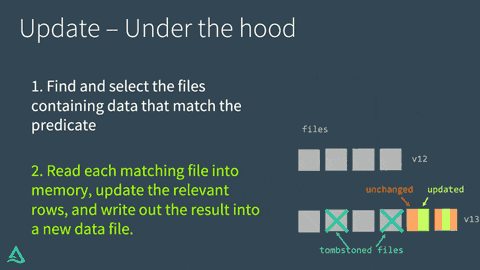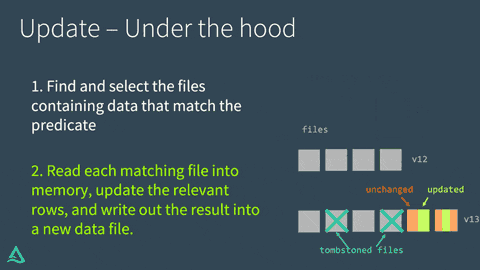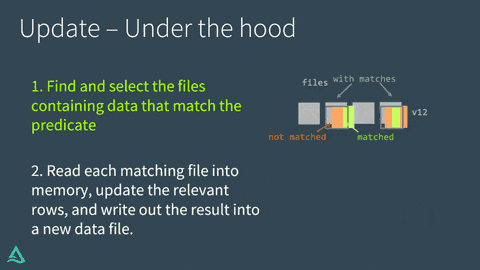
Delta LakeがUPDATEの処理に成功すると、以降は古いデータファイルの代わりに新たなデータファイルが使用されることを示すコミットをトランザクションログに追加します。しかし、古いファイルは削除されません。代わりに、"墓石を建てます"。最新バージョンではなく、古いバージョンのテーブルに適用されたデータファイルとして記録されます。Delta Lakeはこれをデータのバージョン管理やタイムトラベルに活用します。
UPDATE + Delta Lakeのタイムトラベル = 容易なデバッグ
古いデータファイルを保持することで、テーブルの過去の任意のバージョンを参照できるDelta Lakeの「タイムトラベル」を利用できるので、デバッグが容易になります。誤ってテーブルをアップデートしてしまった際に、何が起きたのかを明らかにしたい場合には、二つのバージョンのテーブルを容易に比較することができます。
SELECT * FROM events VERSION AS OF 12
UPDATE: パフォーマンスチューニングのティップス
Delta LakeにおけるUPDATEコマンドのパフォーマンスを改善する主たる方法は、検索空間を狭めるために、述語を追加するということです。検索が限定的であるほど、Delta Lakeがスキャンし、変更するファイルの数が少なくて済みます。
DatabricksのマネージドバージョンであるDelta Lakeには、改善されたデータスキッピング、ブルームフィルターの利用、マルチカラムソートの改善版とも言えるZ-Order Optimize(多次元クラスタリング)など、さらなるパフォーマンス改善の機能が含まれています。Z-orderingは、効率を最大化するために、類似のカラム値が戦略的に隣り合わせに配置されるように、それぞれのデータファイルのレイアウトを再構成します。詳細はこちらを参照ください。
Delta Lake DML: DELETE
述語(フィルタリング条件)に合致する行を選択的に削除する際にDELETEコマンドを使用できます。
DELETE FROM events WHERE date < '2017-01-01'
間違ったDELETE操作を取り消したい場合には、以下のPythonコードにあるように、タイムトラベルを使用してテーブルを元の状態に戻すことができます。
# Read correct version of table into memory
dt = spark.read.format("delta") \
.option("versionAsOf", 4) \
.load(deltaPath)
# Overwrite current table with DataFrame in memory
dt.write.format("delta") \
.mode("overwrite") \
.save(deltaPath)
DELETE: 内部処理
DELETEはUPDATEと同様に動作します。Delta Lakeは2回データをスキャンします:最初のスキャンは、フィルタリング条件に合致する行を含むデータファイルを特定するためのものです。2番目のスキャンでは、マッチするデータファイルをメモリに読み込みます。その時点で、新たなクリーンなデータをディスクに書き込む前にDelta Lakeが該当の行を削除します。
Delta LakeがDELETE処理を成功した後に、古いデータファイルは削除されません。ディスクに留まり続けますが、Delta Lakeトランザクションログには「墓石(アクティブなテーブルとして見做されません)」として記録されます。以前のバージョンのテーブルにタイムトラベルで戻せるようにするために、古いファイルは即時削除されないことに注意してください。特定期間を経過した古いファイルを削除する際には、VACUUMコマンドを使用します。
DELETE + VACUUM: 古いデータファイルのクリーンアップ
VACUUMコマンドを実行すると、以下のデータファイル全てを恒久的に削除します。
- アクティブテーブルではないデータファイル
- 保持期間(デフォルトは7日)より古いデータファイル
Delta Lakeは自動で古いファイルのVACUUMを行いません。以下に示すように、ご自身でコマンドを実行する必要があります。デフォルトの7日の保持期間を変更したい場合には、パラメータとして指定します。
from delta.tables import *
# vacuum files not required by versions older than the default
# retention period, which is 168 hours (7 days) by default
dt.vacuum()
deltaTable.vacuum(48) # vacuum files older than 48 hours
注意
0時間の保持期間を指定したVACUUMの実行は、最新バージョンのテーブルで使用されていない全てのファイルを削除します。データ損失が起こる可能性があるので、このコマンドを実行する際には、テーブルに書き込み中の処理がないことを確認してください。
VACUUMコマンドの詳細、Scala、SQLのサンプルに関しては、VACUUMコマンドのドキュメントを参照ください。
DELETE: パフォーマンスチューニングのティップス
UPDATEコマンドと同様に、Delta LakeにおけるDELETEオペレーションの性能を改善する主たる方法は、検索空間を狭めるために述語を追加するというものです。DatabricksのマネージドバージョンであるDelta Lakeには、改善されたデータスキッピング、ブルームフィルターの利用、マルチカラムソートの改善版とも言えるZ-Order Optimize(多次元クラスタリング)など、さらなるパフォーマンス改善の機能が含まれています。詳細はこちらを参照ください。
Delta Lake DML: MERGE
Delta LakeのMERGEコマンドを用いることで、UPDATEとINSERTの組み合わせである"upsert"を実行できます。upsertを理解するには、既存のテーブル(ターゲットテーブル)と新規レコードと更新レコードを含むソーステーブルを想像します。upsertは以下のように動作します:
- ソーステーブルのレコードがターゲットテーブルの既存レコードに合致する場合には、Delta Lakeはレコードをupdateします。
- レコードが合致しない場合には、Delta Lakeは新規レコードをinsertします。
MERGE INTO events
USING updates
ON events.eventId = updates.eventId
WHEN MATCHED THEN UPDATE
SET events.data = updates.data
WHEN NOT MATCHED THEN
INSERT (date, eventId, data) VALUES (date, eventId, data)
Delta LakeのMERGEコマンドは、Parquetのような他の従来型のデータフォーマットにおいては、複雑かつ重荷となり得るワークフローを劇的に簡素化します。merge/upsertが有用な一般的なシナリオには、チェンジデータキャプチャ、GDPR/CCPAコンプライアンス、セッショニゼーション、レコードの重複排除が含まれます。upsertの詳細に関しては、ブログ記事Efficient Upserts into Data Lakes with Databricks Delta、Simple, Reliable Upserts and Deletes on Delta Lake Tables using Python API、Schema Evolution in Merge Operations and Operational Metrics in Delta Lakeを参照ください。
whenMatched句による条件の使用を含むプログラム処理などMERGEに関するより詳細な情報に関しては、ドキュメントを参照ください。
MERGE: 内部処理
Delta LakeにおけるMERGEは二つのステップで実行されます:
- 合致する全てのファイルを選択するために、ターゲットテーブルとソーステーブルの間でinner joinを実行します。
- ターゲットテーブルとソーステーブルで選択されたファイルの間でouter joinを実行し、update/delete/insertされたデータを書き出します。
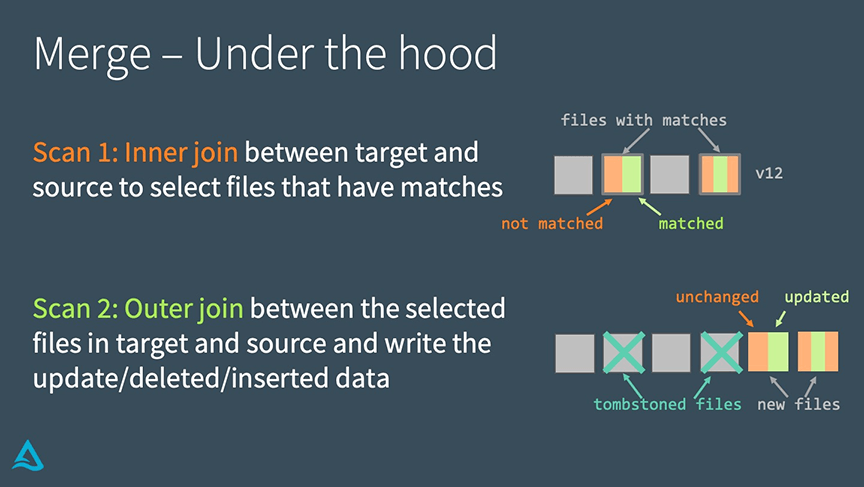
UPDATEやDELETEの内部処理と異なるのは、Delta LakeはMERGEを実行するのにjoinを用いる点です。これによって、性能改善方法を探す際にユニークな戦略を取ることができます。
MERGE: パフォーマンスチューニングのティップス
MERGEコマンドの性能を改善するには、mergeを構成する2つのjoinのどちらが性能のリミットとなっているのかを特定する必要があります。
inner joinがボトルネックである場合(例:Delta Lakeが再度書き込む必要のあるファイルの検索が長時間要する)、以下の戦略をトライしてください。
- 検索空間を狭めるために述語を追加する。
- シャッフルパーティションを調整します。
- ブロードキャストジョインの閾値を調整します。
- テーブル内の小さいファイルが大量にある場合コンパクトにします。しかし、Delta Lakeは再度書き込むファイル全体をコピーする必要があるため、大きすぎるファイルへのコンパクションは行わないでください。
DatabricksマネージドのDelta Lakeにおいては、更新の局所性を高めるためにZ-orderによる最適化を実行してください。
一方で、outer joinがボトルネックの場合(例:実際のファイルの再書き込みが長時間要する)、以下の戦略をトライしてください。
- シャッフルパーティションを調整します
- パーティショニングされたテーブルに対して大量の小さいファイルが生成される場合があります。
- (Databricks Delta Lakeの最適化された)書き込みの前に自動再パーティショニングを有効化してファイルを削減します。
- ブロードキャスト閾値を調整します。full outer joinを行う際には、Sparkはブロードキャストジョインを行いません。しかし、right outer joinを行う際には、Sparkはブロードキャストジョインを行います。必要に応じてブロードキャストの閾値を調整できます。
- ソーステーブル/データフレームをキャッシュします。
- ソーステーブルのキャッシュによって2番目のスキャンをスピードアップしますが、キャッシュの一貫性問題を引き起こす可能性があるので、ターゲットテーブルをキャッシュしないよう注意してください。
まとめ
Delta Lakeは、一般的なビッグデータオペレーションを劇的に簡素化するUPDATE、DELETE、MERGE INTOのDMLコマンドをサポートしています。本記事では、Delta Lakeでこれらのコマンドをどのように使用するのか、それぞれの内部処理、パフォーマンスチューニングのティップスを紹介しました。
関連記事
- Delta Lakeにダイビング #1:トランザクションログを読み解く
- Delta Lakeにダイビング #2:スキーマの強制、進化
- Delta Lakeにダイビング #3:DMLの内部処理(Update、Delete、Merge)
その他のリソース
- Delta Lakeクイックスタートガイド - Qiita
- Databricks documentation on UPDATE, MERGE, and DELETE
- Simple, Reliable Upserts and Deletes on Delta Lake Tables using Python APIs