こんにちは、square1001 です。
現在は東京大学の学部 1 年生をしています。私は中学 1 年の頃からプログラミングをやっていて、特にアルゴリズムが大好きです。AtCoder をはじめとする 競技プログラミング にも取り組んでいて、中高生のときは 情報オリンピック にも参加していました。
本記事では、アルゴリズムや競技プログラミングに興味がある方、あるいはプログラミングをやっているけどアルゴリズムをよく知らない方に
- アルゴリズムはどんなもので
- アルゴリズムを使うとどんな問題が解けて
- アルゴリズムが地球のように広く、多様で、奥深く、そして楽しいこと
を知ってもらおうと思っています。
アルゴリズムの世界へようこそ
時代は 2020 年代に突入し、急速に IT 化 や DX が進んでいく中で、問題を効率的に解くアルゴリズム技術の重要性が、ますます高まっています。そして、アルゴリズムは、世の中の色々な場面で使われるようになっています。まずは例を 3 つ挙げてみます。
- 例 1:電車の乗換案内。どのように電車を乗り継げば最も速く目的地に着けるかは、どのようにして求めているのだろうか?
- 例 2:検索エンジン。検索する文字列を入力したとき、どのように一番上に表示するウェブページを探索しているのか?
- 例 3:オセロや将棋などの AI1。コンピューターはどのような計算をして、最善手を考えているのだろうか?
ここで本記事では、プログラミングをやったことがあるけどアルゴリズムをまだ知らない人や初心者に向けて、アルゴリズムがどんな世界なのかを体感させたいと思っています。その中で、多様なアルゴリズムの世界を感じてもらうため、アルゴリズムの世界を 7 つのカテゴリーに分け2、全部で 25 個の問題を紹介します。一方で、本記事はアルゴリズムの世界を感じてもらうことを最大の目的としているため、「アルゴリズムやその実装を紹介する」という一般的な方法ではなく、アルゴリズムの各分野はどんな感じで、どんな問題が解けるかを紹介していく構成にしています。
この記事は「アルゴリズムの世界地図」というタイトルのように、7 つのカテゴリーは世界地図の大陸のように考えてほしいです。そして、大陸に位置する「都市」のようなアルゴリズムの問題を見ていくことで、「グラフアルゴリズム」や「データ構造」など、大陸ごとに違った多様な世界が見えてきます。
ここで紹介する 25 個の問題は、アルゴリズムの勉強をすれば目にする方も多いであろう、よく知られた問題です。この中には、一見解きにくそうに見える問題もたくさんあります。最初はアルゴリズムを理解することを意識せずに、初めて見る世界を旅行するような感じで楽しんで読んでください。
では、アルゴリズムの世界の旅行を始めましょう。
(画像は https://unsplash.com/photos/MKKT-lXCppE より)

目次
| 章 | タイトル | 備考 |
|---|---|---|
| 0 | アルゴリズムとは? | 前提知識「アルゴリズム」「計算量」の説明です |
| 1 | World 1. 二分探索 | 二分探索の世界と、3 つの問題を紹介します |
| 2 | World 2. 動的計画法 | 動的計画法の世界と、5 つの問題を紹介します |
| 3 | World 3. グラフアルゴリズム | グラフアルゴリズムの世界と、5 つの問題を紹介します |
| 4 | World 4. ソート | ソートについて説明します |
| 5 | World 5. データ構造 | データ構造の世界と、5 つの問題を紹介します |
| 6 | World 6. 数理最適化 | 数理最適化の世界と、4 つの問題を紹介します |
| 7 | World 7. 数学的アルゴリズム | 数学的アルゴリズムの世界と、3 つの問題を紹介します |
| 8 | おわりに |
0. アルゴリズムとは?
まず、アルゴリズムとは何かを説明します。(0 節の説明はスライド「50 分で学ぶアルゴリズム」 の説明を参考にして書きました)
さて、次の問題を考えてみましょう。
問題: 1 + 2 + 3 + … + 100 の値を計算してください。
単純な方法として、式の通りに 1 つずつ足していく方法が考えられます。すると、以下の図のように答えが計算されることになります。

これで答え 5050 が正しく求まりました。これはれっきとした アルゴリズム であり、この問題を 99 回の足し算 で解いています。しかし、計算回数が多く、計算に時間がかかるのではないかと思った方もいると思います。
ここで、方法を変えて、「1 + 100」「2 + 99」「3 + 98」…「50 + 51」の合計を求めることで、1 + 2 + 3 + … + 100 の値を計算してみましょう。
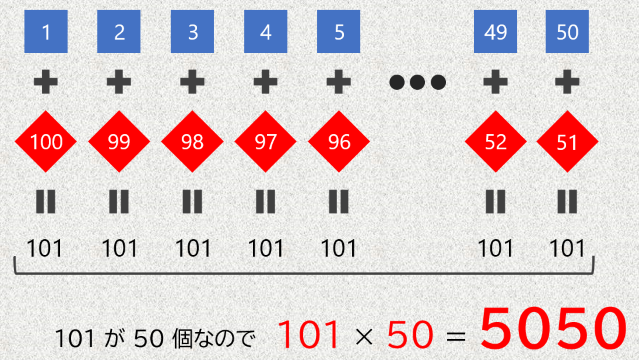
50 個の足し算の結果がすべて 101 なので、答えは 101 × 50 = 5050 と求まりました。「1 + 100 = 101 を求める」→「100 ÷ 2 = 50 を求める」→「101 × 50 = 5050 を求める」という 3 回の計算 で解いており、先ほどよりも 効率が良い解き方(アルゴリズム) であるといえます。
0-1. プログラミングの問題として解く
「3 回の計算も 99 回の計算も、コンピューターにとっては五十歩百歩ではないか」と思う方もいるかもしれません。では、1 + 2 + 3 + … + N を求めるプログラムを、上に挙げた 2 つの方法で書いてみます。
1 番目の方法(1 つずつ順に足していく)
N = int(input())
sum = 1
for i in range(2, N + 1):
sum += i
print(sum)
2 番目の方法(合計が $N + 1$ になるようなペアを $\lfloor N/2 \rfloor$ 個作る3)
N = int(input())
print((N + 1) * (N / 2))
いざ、N = 1000000 を入力してみると、プログラムの実行時間は、次のようになりました。
- 1 番目の方法:0.1446101 秒
- 2 番目の方法:0.0000539 秒
N = 100 の場合よりも差が広がり、実行速度に何千倍も差がついてしまいました。なぜなら、前者は N に比例した計算回数がかかっているのに対し、後者は定数回の計算回数しかかかっていないからです。
アルゴリズムとは問題を解く手順のことです。 この 2 つのアルゴリズムの比較にみるように、アルゴリズムを変えるだけで大幅に効率がよくなることもあり、N が大きくなるほど、効率的なアルゴリズムの重要性が高まるのです。
0-2. 計算量について
1 + 2 + 3 + … + N を計算する例に見たように、アルゴリズムの工夫で、大幅に効率がよくなることがあります。先ほど紹介した 2 つのアルゴリズムでは、
- 1 番目のアルゴリズム:N-1 回の計算
- 2 番目のアルゴリズム:3 回の計算
となっています。複雑なプログラムになると具体的な計算回数を見積もるのが難しくなるので、ランダウの O 記法を使って「計算回数をざっくりと」見積もる方法がよく使われます。例えば
- 1 番目のアルゴリズム:計算量 $O(N)$(N に比例する計算量、という意味)
- 2 番目のアルゴリズム:計算量 $O(1)$(1 に比例する計算量、という意味)
このように、ランダウの O 記法では、計算回数を余分な項や定数倍を除いた「最も単純な形」で表し、それに比例する計算回数であることを表します4。すると、
- 計算量 $O(N^3)$ のアルゴリズムより $O(N^2)$ のアルゴリズムの方が速い5
- 計算量 $O(N^2)$ のアルゴリズムより $O(N)$ のアルゴリズムの方が速い5
- 計算量 $O(N)$ のアルゴリズムより $O(\log N)$ のアルゴリズムの方が速い5
- 計算量 $O(\log N)$ のアルゴリズムより $O(1)$ のアルゴリズムの方が速い5
といったように、アルゴリズムの効率が一目でわかります。
コンピューターの計算速度にも限界があります。標準的な家庭用 PC の場合、(測り方やプログラムの実装にもよりますが)1 秒間に数億回の計算 ができます。計算量を見積もることで、どの程度の N までなら計算できそうかが大ざっぱに分かります。
計算量についてもっと詳しく知りたい方は、@drken さんの記事がおすすめです。
World 1. 二分探索
さて、最初に「二分探索6」の大陸に入っていきましょう。
まずは、試験の合格発表の場面を想像してみてください。大学受験とかで、合格したり不合格したりした時を思い出してみてもいいかもしれません。あなたの受験番号が 1186 だと思って探してみましょう。

どのような方法で探しましたか?
方法 1. 最初から順に見ていく
受験番号を 1001, 1004, 1005, 1009, 1016, 1027, 1028 ... と最初から順々に見ていったら、自分の受験番号を見つけるまでに時間がかかってしまいます。(最大 50 回の比較が必要です)
方法 2. 工夫して探す
列の一番上の受験番号 1001, 1064, 1112, 1184, 1235 を見ると、自分の受験番号 1186 が 4 列目にあることが分かります。なので、4 列目を 1184, 1186, 1189, 1200, ... と見ていって、自分の受験番号が見つかります。おそらく多くの読者が考えた方法だと思います。(最大 15 回の比較が必要です)
方法 3. もっと速い「二分探索」
実は、もっと効率的な方法があります。これは、探したい値を真ん中の値と比較すると、これより小さかった場合は左半分に、これより大きかった場合は右半分に範囲が限定されます。これを繰り返して、範囲を全体の 1/2, 1/4, 1/8, 1/16, ... と絞っていくことで、自分の受験番号を見つける、というものです。
最初は、真ん中(25 番目)の受験番号 1148 と比較することになります。
- 自分の受験番号が 1148 より小さい → 1 番目 ~ 24 番目の受験番号に絞られる
- 自分の受験番号が 1148 に等しい → 見つかった!
- 自分の受験番号が 1148 より大きい → 26 番目 ~ 50 番目の受験番号に絞られる
そうすると、元々 50 個の受験番号を「見る」必要があったのが、一発で半分の 25 個に減らせました。この小さくなった範囲に対して同じことをやると、最悪のケースでも 50 個 → 25 個 → 12 個 → 6 個 → 3 個 → 1 個と、最大 6 回の比較で受験番号を見つけることができます。この方法を 二分探索 といい、とても効率的です。
この方法で、受験番号 1186 を探してみましょう。
- 1~50 番目の中で真ん中の値 1148 より大きい → 26~50 番目に絞られる
- 26~50 番目の中で真ん中の値 1219 より小さい → 26~37 番目に絞られる
- 26~37 番目の中で真ん中の値 1184 より大きい → 32~37 番目に絞られる
- 32~37 番目の中で真ん中の値 1200 より小さい → 32~33 番目に絞られる
- 32~33 番目の中で真ん中の値 1186 に等しい → 見つかった!
といったように、たった 5 回の比較で見つかり、非常に効率的だと分かります7。
二分探索は、いろいろな場面で使われます。二分探索の世界を知ることで解ける問題を、いくつか紹介してみます。
1-1. 小さい順に並べられたリストから数を見つける
最初の問題は、合格発表のシチュエーションを一般化した、小さい順に並べられたリストから数を見つける問題です。
$N$ 個の値が小さい順に並んだ配列 $[A_1, A_2, \dots, A_N]$ に対して、この中から値 $x$ を見つける。
この問題は、最初から順に見ていく「線形探索」というアルゴリズム(方法 1 に対応)を使うと計算量 $O(N)$ かかりますが、二分探索を使うと計算量 $O(\log N)$ で見つけることができます。
以下は、値 x が配列 A のどの位置にあるか(なければ -1 を返す)を返す Python プログラムです。Python を知らない方も、コメントなどを見れば読めると思います。
def binary_search(N, A, x):
l = 0; r = N - 1 # A[l], A[l+1], ..., A[r] が探索範囲
while r - l + 1 >= 1: # 探索範囲の長さ r - l + 1 が 1 以上のあいだループする
m = (l + r) // 2 # (l + r) / 2 を小数点以下切り捨て
if A[m] == x:
return m
if A[m] < x:
l = m + 1
if A[m] > x:
r = m - 1
return -1
1-2. 辞書で単語の意味を調べる
英語の辞書を作成することを想像してみてください。手元に英語の辞書がある方は、"travel" という英単語の意味を調べてみましょう。
<英語の辞書>
A: Used as a function word before singular nouns
AARDVARK: An African mammal
ABACK: Toward the back
ABACUS: A calculating device
:
TRAVEL: To go from one place to another
:
ZYZZYVA: A tropical weevil
ZZZ: Used to suggest the sound of snoring
辞書の最初から順に "a" → "aardvark" → "aback" → "abacus" → "abalone" → … と調べていると時間がかかってしまいます。この代わりに、二分探索を使うことで、単語数 $N$ に対して計算量 $O(\log N)$ で目的の単語を見つけ、その意味を調べることができます8。
裏を返せば、辞書の単語がアルファベット順に書かれている理由は、(二分探索をはじめとする工夫を使って)人間にとって検索しやすいようにしたかったからなのだと思われます。
1-3. √N の値を求める
中学校の頃に、√2, √3, √5 などの値を覚えた方もいるかもしれません。
- √2 = 1.414213562...
- √3 = 1.732050807...
- √5 = 2.236067977...
実は、このような値は二分探索を使って計算することができます9。同じ方法で、³√2 = 1.259921049... などの値も計算できます。二分探索のアルゴリズムは、このような場所にまで応用ができるのです。
World 2. 動的計画法
では、2 番目の「動的計画法」の大陸に入っていきましょう。
コンビニで買い物をする場面を想像してみてください。ある世界では、1 円硬貨・3 円硬貨・5 円硬貨・11 円硬貨の四種類の硬貨が流通しているとしましょう。これを使って 40 円をピッタリ支払う方法は、以下の図のようにたくさんあります。
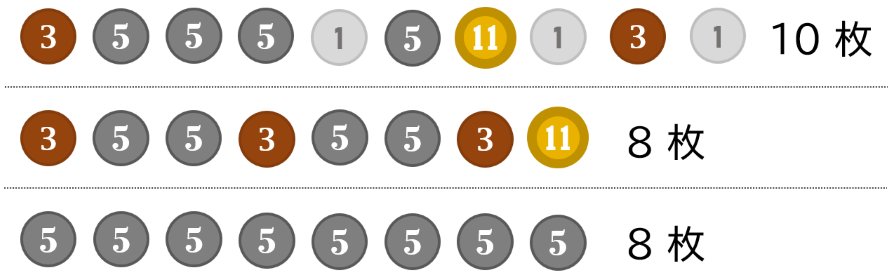
では、最小枚数は何枚になるでしょうか?みなさん、少し手を止めて考えてみてください。
どうやって求めるか?
おそらく「全パターン調べ上げて、最小枚数の方法を求めた」という方が大多数だと思います。もちろん、40 円程度ならこの手法が使えますが、全パターンを調べ上げるのは大変で、考えるときに混乱した方も多いと思います。さらに、
- 支払う金額が「40 円」より多くなった場合、どうしますか?
- 硬貨の枚数が「4 種類」より多くなった場合、どうしますか?
このように、金額や硬貨の枚数が増えると、硬貨の組み合わせの数は著しい速度で増加していきます。例えば、日本で流通している 1・5・10・50・100・500 円硬貨で 1,000,000 円を支払う方法の数はなんと
66,778,393,577,069,937,001 通り
もあるのです。これは、スーパーコンピューターを使っても、全部調べ上げるのは難しいような数です。
「動的計画法」の登場
では、この問題を以下の手順で解いてみることにしましょう。
- 1 円になる硬貨の最小枚数 $c_1$ を求める(1 円硬貨を使って $c_1 = 1$ 枚)
- 2 円になる硬貨の最小枚数 $c_2$ を求める(1, 1 円硬貨を使って $c_2 = 2$ 枚)
- 3 円になる硬貨の最小枚数 $c_3$ を求める(3 円硬貨を使って $c_3 = 1$ 枚)
- 4 円になる硬貨の最小枚数 $c_4$ を求める(1, 3 円硬貨を使って $c_4 = 2$ 枚)
- (中略)
- 40 円になる硬貨の最小枚数 $c_{40}$ を求める
1 枚ずつコインを出していくことを考えると、合計が 40 円になるためには
- 29 円の状態から、11 円硬貨を出して 40 円にする
- 35 円の状態から、5 円硬貨を出して 40 円にする
- 37 円の状態から、3 円硬貨を出して 40 円にする
- 39 円の状態から、1 円硬貨を出して 40 円にする
のいずれかになる必要があります。
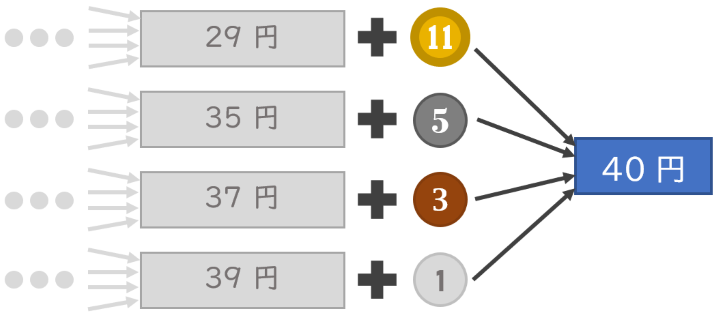
同様にして、合計が $n$ 円になるためには、合計が $n-11, n-5, n-3, n-1$ 円のいずれかの状態から 1 枚のコインを出す必要があります。したがって、最小枚数 $c_n$ は
$$c_n = \min(c_{n-11}+1, c_{n-5}+1, c_{n-3}+1, c_{n-1}+1)$$
という式で求められ、これを $c_1, c_2, \dots, c_{40}$ の順に求めていくことで、この問題の答えである「6 枚」が求まります10。このアルゴリズムは、支払う金額や硬貨の枚数が多くなるにつれ、全パターン調べ上げと比較して圧倒的な効率を持つようになります。
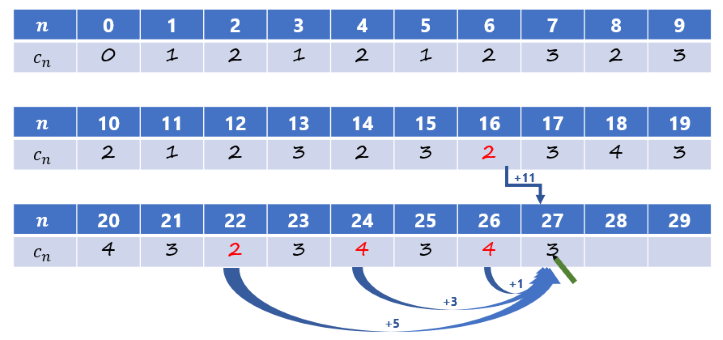
($n = 27$ まで埋めました。残りは自分で考えてみてください)
動的計画法とは?
このように、小さいスケールの問題から順に、これまでの結果を利用して答えを積み上げていくことで、最終的な問題の答えを求める方法は 動的計画法 とよばれます。英語では Dynamic Programming と書くので、DP ともよばれます。
動的計画法 (DP) の世界を知ると、コインを支払う問題に限らず、幅広いジャンルの問題を効率的に解けるようになります。もちろん、競技プログラミングでは実に何百問というレベルで出題されています。ようこそ、動的計画法の世界へ!
2-1. コイン問題
先ほど説明した問題を一般化した問題です。
世の中には $N$ 種類の硬貨が流通しており、それぞれ $A_1, A_2, \dots, A_N$ 円硬貨です。ちょうど $X$ 円を支払うことができるか判定し、できる場合は最小枚数の硬貨の組み合わせをひとつ求めてください。
この問題は、先ほど説明した方法である動的計画法のアルゴリズムを使うと、計算量 $O(NX)$ で解くことができます。
2-2. 部分和問題
次に、「部分和問題」という、シンプルながらもよく研究された問題を紹介します。
$N$ 個の正の整数 $A_1, A_2, \dots, A_N$ からいくつかを選んで、合計を $X$ にする方法が存在するか判定し、できるならば方法をひとつ求めてください。
$2^N$ 通りのパターン全てを調べ上げると、計算に時間がかかってしまいます。この問題も、動的計画法のアルゴリズムを使うと、計算量 $O(NX)$ で解くことができ、効率的です。
2-3. ナップザック問題
次に、「0-1 ナップザック問題」という、動的計画法を学ぶ際には一番最初に出てくることもある問題を紹介します。
$N$ 個の品物があります。$i$ 番目の品物は、重さが $w_i$ で、価値が $v_i$ です。合計の重さが $W$ 以下になるようにいくつかの品物を選んでナップザックに入れるとき、その中に入る品物の価値の合計を最大化してください。
動的計画法の世界を知ると、この問題も計算量 $O(NW)$ で解けるようになります。
0-1 ナップザック問題では、それぞれの品物は 1 つまでしか取れませんが、各品物の個数の制限がない「ナップザック問題」も計算量 $O(NW)$ で解けます。さらには、各品物に対して個数制限 $a_i$ が決められている場合も、動的計画法を工夫すると計算量 $O(NW)$ で解けてしまうのです。
2-4. 編集距離
今度は一転して文字列の問題を紹介します。文章を打っている際に「タイプミス」をすることがあると思いますが、何文字編集することで目的の文字列に修正できるかを求めたいです。具体的には、
- 現在の文字列に 1 文字挿入("abc" → "abxc", "qiita" → "qiitan" などの操作)
- 現在の文字列から 1 文字削除("abxc" → "abc", "qiitan" → "qiita" などの操作)
- 現在の文字列の 1 文字を変更("abc" → "arc", "world" → "would" などの操作)
のどれかの操作を最小何回行うことで、目的の文字列に変えられるか(編集距離)を求めます。
例えば、"distance" → "instant" の編集距離は 4 です。なぜなら、最短ルートは "distance" → "istance" → "instance" → "instante" → "instant" だからです。
動的計画法の世界を知ると、文字列 $S$ を $T$ に変える編集距離を、計算量 $O(|S| \times |T|)$(ただし $|S|, |T|$ は文字列 $S, T$ の長さ)で求められるようになります。
2-5. DNA アラインメント
DNA が A, T, G, C で構成される「ゲノム配列」とよばれる文字列で表されることは、多くの方が知っていることだと思います。しかし、人間のゲノム解析は難しく、世界で初めてできたのは 2001 年のことでした。例えば、人間の DNA に生じた変異や、ゲノム配列を読み取る際のエラーなどによる "違い" を上手くマッチさせる技術が必要だったのです。
読み取ったゲノム配列をできるだけ一致するように「合わせる」ことをシーケンスアラインメントといいます。特に、2 つのゲノム配列のときはペアワイズアラインメントといいます。例えば、"AGTTGAATTT" と "GTCGGACTTT" のペアワイズアラインメントの一例は
AGT-TGAATTT
-GTCGGACTTT
となり、2 つの文字列が異なる箇所が 4 つだけになるようにマッチできます。
実は、動的計画法を使うことで、ゲノム配列 $S$ と $T$ の最適なペアワイズアラインメントを計算量 $O(|S| \times |T|)$ で求めることができます。これは Needleman-Wunsch のアルゴリズム という名前が付いたアルゴリズムです。
このように、動的計画法の世界は、いろいろな分野や場面にまで広がっているのです。
World 3. グラフアルゴリズム
では、3 番目の「グラフアルゴリズム」の大陸に入っていきましょう。
道を歩いている場面を想像してみてください。できるだけ早く目的地に到着したいと思ったとき、地図を見てできるだけ短い経路を探したことがある方もいると思います。あるいは、最近だと、Google マップ などを用いて最短経路を検索している方も多いでしょう。
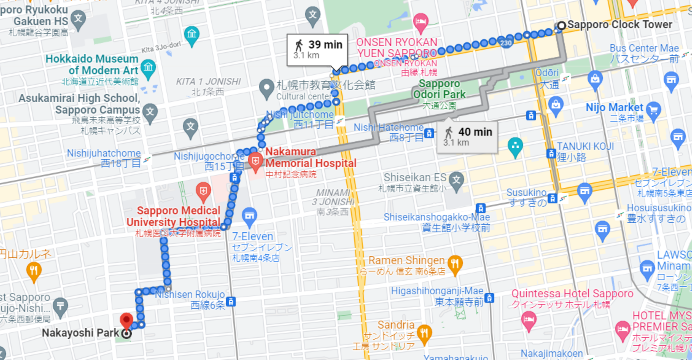
上図は「札幌市時計台」から「なかよし公園」へ行く最短経路です。最近の技術は、地図上の 2 地点間の最短経路を求めることもできるようになっているのです。
ここで、地図の最短経路をどのように求めるのか、などの疑問が生まれます。その前に、地図は複雑であり、最短経路を求めるのをはじめ、地図上の問題を解くのは簡単ではなさそうに見えます。そのため、地図をこのように単純化することが重要になりました11。
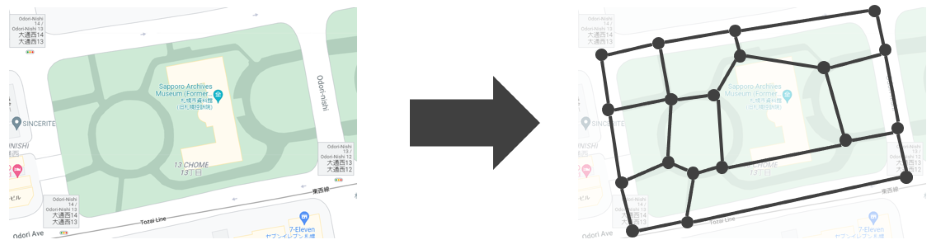
これは、「大通公園」の西側を単純化したものですが、複雑に見える地図がたった 19 個の点と 27 個の線で表現されました。このように単純化すると、先ほどの何も加工を加えていない地図よりも、最短経路が求めやすそうな形に見えてきます。コンピューターにとっては、人間よりもっと分かりやすい形になっています。似たような例として、鉄道の路線図 などがあります。
グラフとは?
このように点と線で単純化した、「モノのつながり方を表すもの」を グラフ といいます。(棒グラフや折れ線グラフといったグラフとは全く別物であることに注意してください)
グラフの言葉では、先ほどの点は 頂点 (vertex)、先ほどの線は 辺 (edge) といいます。つまり、先ほどのグラフは 19 頂点 27 辺の無向グラフ です。(無向グラフとは、辺に向きが付いていないグラフのことです。逆に、有向グラフは、各辺が矢印のように向きが付いたグラフです。)
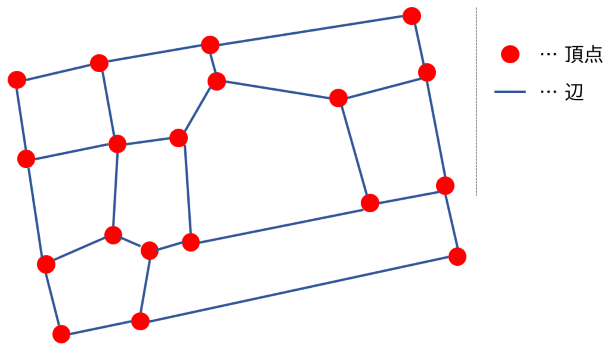
頂点はモノを表し、辺はモノの間のつながりを表すものとして考えると、分かりやすいでしょう。鉄道の路線図の例では、頂点は駅、辺は鉄道路線に対応すると考えるとよいでしょう。
グラフを使って表せる物事
グラフが使えるのは地図だけではありません。世の中のいろいろなものが、グラフで表すことができます。まずは、具体例を 3 つ紹介したいと思います。
例 1. 友達関係の表現
友達関係は、グラフを用いて表すことができます。それぞれの人を頂点として、人と人が友達であるときに辺でつながれているグラフで表せます。友達関係が必ず双方向の場合は無向グラフで表すことができますが、「自分が相手を友達だと思っているのに、相手が自分を友達だと思っていない」可能性もあるため、有向グラフを使うことになります。
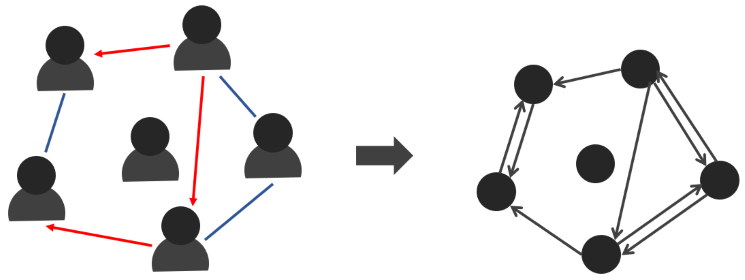
上のグラフは、6 頂点 9 辺の有向グラフです。
ちなみに、現実の世界では、「友達の友達の友達…」といった関係を 6 ステップ程度をたどれば、世界中の人とつながることができるという「6 次の隔たり」という性質が知られています。これは、世界中の人の友達関係を表したグラフ上の 2 頂点を選んだときに、この最短経路が 6 程度である、ということになります。
例 2. 道路のネットワーク
先ほどの例では、札幌市の一部の道路網を 19 頂点 27 辺のグラフで表していました。このように、道路網はグラフとして表すことができます12。
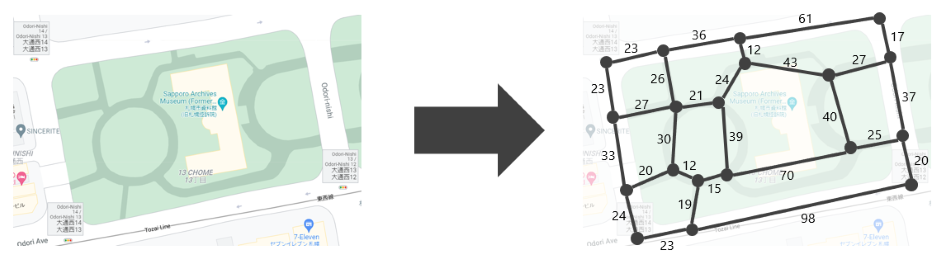
道路によって長さが異なることを反映するため、グラフの辺に長さ(または重み)の属性をつけた 重み付きグラフ として表現します。
例 3. パイプライン
パイプラインは、石油や天然ガスなどを輸送するために使われる管のことです。日本ではあまり多くありませんが、資源大国などでは、油田などから都市に向けて輸送する大規模なパイプラインが設置されています。
パイプラインは管のネットワークでできているので、輸送できるスピードにも限界があります。つまり、それぞれの管に対して「流量制限」が付いていると考えることもできます。パイプラインのネットワークはグラフで表すことができ、各辺には「容量」の値が定めたものとして表現できます。
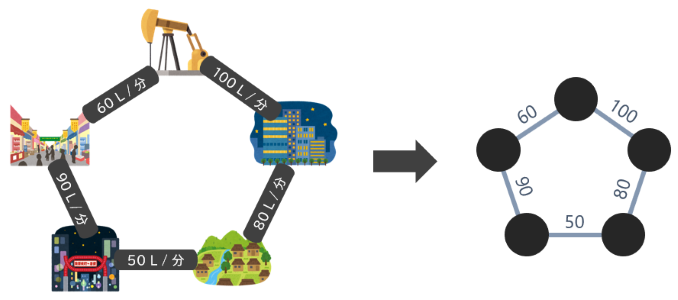
これに対して、例えば「1 分間に輸送できる限界の量を求める」といった問題が考えられます。例えば、上図では、油田から村まで最大 130L / 分 のペースで石油が輸送できます。
グラフアルゴリズム
このように、現実世界の多くのものがグラフで表せます。グラフに関して「最短経路を求める」など色々な問題が考えられ、このようなグラフの問題を解くアルゴリズムを「グラフアルゴリズム」といいます。グラフの問題は、競技プログラミングでもよく出題されています。また、グラフアルゴリズムの最先端研究には、日本でも 河原林健一教授 をはじめとする多くの研究者が取り組んでおり、実社会にも応用されています。
グラフアルゴリズムの世界は広く、たくさんの問題に対してたくさんのアルゴリズムがあります。本記事では 5 つの問題を紹介します。グラフアルゴリズムの世界に親しんでもらえればと思います。
3-1. 最短経路問題
最短経路問題は、名前通り「グラフの 2 頂点間の最短経路」を求める問題です。地図上の最短経路を求めるのと同じように、
- 重みなしグラフの場合 … 通る辺の個数を最小にする
- 重み付きグラフの場合 … 通る辺の重みの合計を最小にする
ような 2 地点間の経路を見つけます。例えば、先ほどの大通公園の例だと、赤い地点から青い地点までの最短経路の長さは、重みなしグラフとみた場合 5、重み付きグラフとみた場合 192 となります(下図参照)。
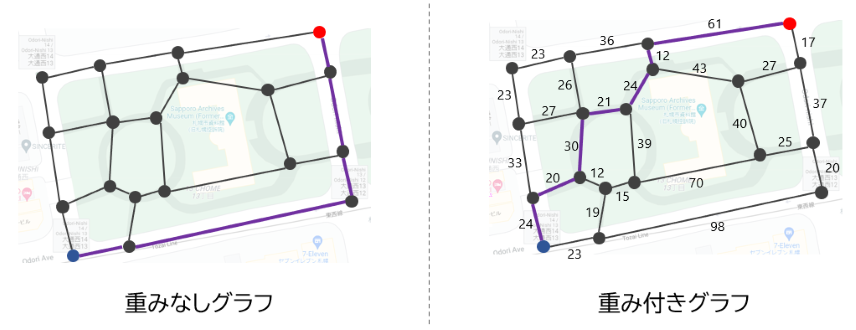
実は、グラフアルゴリズムの世界を知ると、グラフの頂点数を $|V|$、辺数を $|E|$ とすると、重みなしグラフの最短経路は計算量 $O(|E|)$、重み付きグラフの最短経路は計算量 $O(|E| \log |V|)$ で求められるようになるのです。
3-2. 最小全域木問題
先ほどの道路網のように、道路がたくさんあると目的地までより近い距離で移動できるので、住民にとっては便利です。しかし、道路を敷くのにもコストがかかります。ここで、建設業者の人が、次のように考えたとします。
19 頂点すべてが道路でつながれば、あとはどうでもいい。この中で建設コストが最小になるように道路を敷設しよう。
仮に、道路の長さがそのまま建設コストになると、建設業者の人の道路の敷き方は下図のようになり、コストは 417 となります。このような部分的なグラフを「最小全域木」といいます。
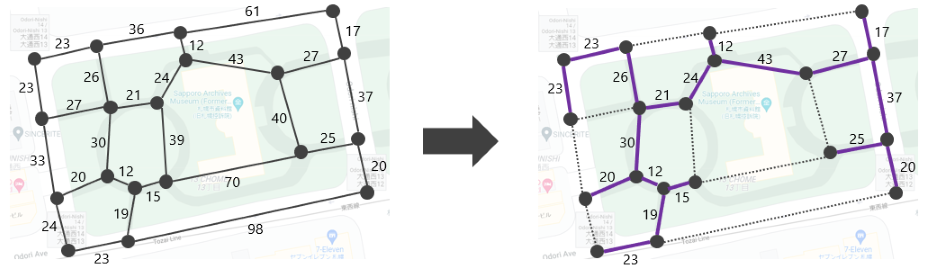
グラフアルゴリズムの世界を知ると、グラフの最小全域木も求められるようになります。計算量は $O(|E| \log |V|)$ です。
3-3. マッチング問題
友達関係を表した 無向グラフ を考えます。小学校や中学校にいた時に、2 人ペアを組んで何かをする場面がたくさんあったと思いますし、中にはペアを組むのに失敗した経験がある方もいると思います。
ここでは、友達同士で 2 人ペアをできるだけ多く組む問題を考えます。2 人ペアを作る行為を結婚の世界では「マッチング」というように、この問題は「最大マッチング問題」とよばれます。
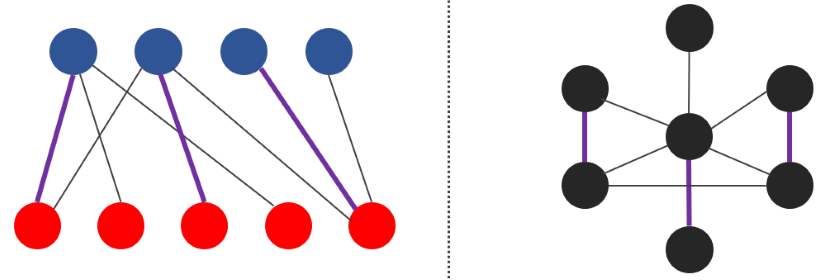
マッチング問題は、左のグラフのように「どの辺も "赤-青" になるようにグラフを 2 色で塗り分けられる」ような 二部グラフ と、そうでないグラフで、解き方の性質が大きく異なってきます。特に、二部グラフの最大マッチング問題は 二部マッチング とよばれます。
でも、どちらも $|V|, |E|$ がある程度であれば解けます。二部マッチング問題は計算量 $O(|E| \sqrt{|V|})$ で解けます。一般のマッチング問題は計算量 $O(|V|^3)$ のアルゴリズムがよく知られていますが、計算量 $O(|E| \sqrt{|V|})$ の非常に複雑なアルゴリズムもあります。
3-4. 最大流問題
先ほどのパイプラインの例を思い出してください。各辺に「容量」が定められたグラフに対して、2 頂点 $s, t$ を指定して、頂点 $s$ から頂点 $t$ に向けてどのくらい石油を輸送できるかを考えます。これは、最大の流量を求める問題なので、「最大流問題」とよばれます。
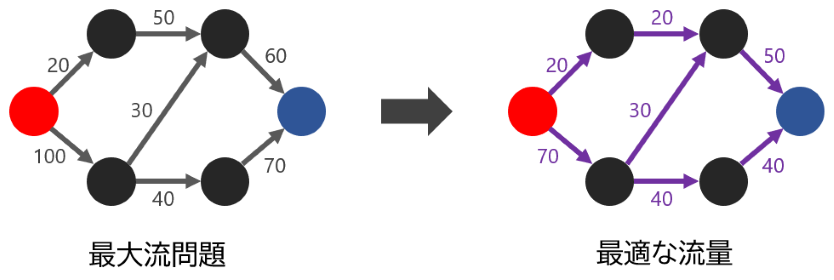
例えば、上の例では、右図のような流し方をしたとき、左の頂点から右の頂点まで 90 の流量を流せます。一見解くのが難しそうに見えるかもしれませんが、実はグラフアルゴリズムの力を使うと解けてしまいます。
最大流問題は、グラフアルゴリズムの中でも最も研究されている問題のひとつであり、2020 年になっても計算量が改善し続けられています。よく知られたアルゴリズムを使うと、$O(|V|^2 |E|)$ などの計算量で解くことができます。
3-5. 最小カット問題
最小カット問題は、2 頂点間のつながりを「切断する」ために、辺を最小でどのくらい消す必要があるかを求める問題です。
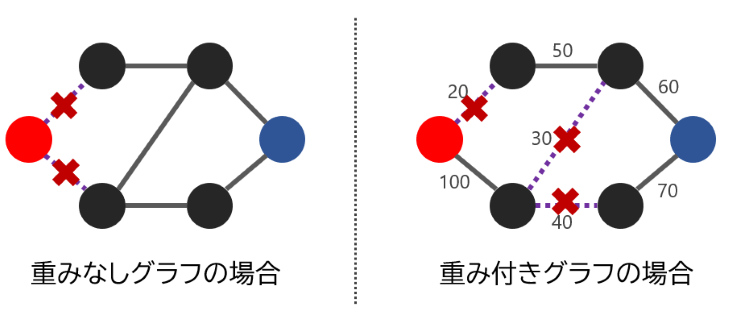
信じられないかもしれませんが、実は「最大流の大きさ = 最小カットの重みの合計」という性質があります(最大流・最小カット定理として知られます)。なので、最大流の結果を利用して、最小カットを同じ計算量で求めることができるのです。
このように、グラフアルゴリズムの世界には、効率的に解けるたくさんの問題があります。
World 4. ソート
では、4 番目の「ソート」に入っていきます。ソートは、他のカテゴリーとは異なり、独立したトピックになっています。なので、他のカテゴリーを「大陸」とするならば、このカテゴリーは「島」だと思って旅行を楽しんでください。
ソートとは?
ソートとは、データの集まりを決められた順序で並び替える操作です。例えば、
- [425, 157, 239, 523] を小さい順にソートすると [157, 239, 425, 523]
- [2, 7, 1, 8, 2, 8, 1] を大きい順にソートすると [8, 8, 7, 2, 2, 1, 1]
- ["qiita", "world", "map"] をアルファベット順にソートすると ["map", "qiita", "world"]
データの集まりをソートする場面は多くあります。それどころか、実生活でもソートをしなければならない場面があります。具体的には、以下のような例が挙げられます。
- 学校で、生徒が背の順に並ぶとき。
- テストの答案が先生から返されたが、出席番号順に並べる必要があるとき。
このように、ソートは重要な役割を担っています。
ここでは、$N$ 個の値 $A_1, A_2, \dots, A_N$ を小さい順に並べ替える問題を考えます。どのようなアルゴリズムでソートが行われるのでしょうか。プリントなどを番号順に整列するとき、どのように考えているのかを思い出しながら、読んでいってください。
挿入ソートのアルゴリズム
最も直感的なソートアルゴリズムの 1 つである「挿入ソート」を説明します。これは、配列を先頭から順にソートしていくというやり方で、以下の性質を用いています。
(性質)$[A_1, A_2, \dots, A_i]$ が小さい順に並べられているとします。このとき、$A_{i+1}$ を適切な位置に挿入することで、$[A_1, A_2, \dots, A_i, A_{i+1}]$ をソートできます。
(この「適切な位置」は、$A_k \leqq A_{i+1} \leqq A_{k+1}$ となるような $A_k$ と $A_{k+1}$ の間になります)
分かりづらいかもしれないので、具体例をいくつか挙げます。
- [2, 4, 8, 11] と 5 を合わせた配列は、5 を 4, 8 の間に挿入することで、ソートされた配列 [2, 4, 5, 8, 11] が得られる
- [4, 7, 9] と 11 を合わせた配列は、11 を 9 の右に挿入することで、ソートされた配列 [4, 7, 9, 11] が得られる
といった感じです。これを $i = 1, 2, \dots, N-1$ の順に繰り返すと、
- $[A_1]$ だけがソートされた状態で $A_2$ を挿入し、$[A_1, A_2]$ がソートされる
- $[A_1, A_2]$ がソートされた状態で $A_3$ を挿入し、$[A_1, A_2, A_3]$ がソートされる
- (中略)
- $[A_1, A_2, \dots, A_{N-1}]$ がソートされた状態で $A_N$ を挿入し、$[A_1, A_2, \dots, A_{N-1}, A_N]$ がソートされる
というステップで、配列 $A = [A_1, A_2, \dots, A_N]$ 全体がソートされるのです。以下に、配列 $A = [8, 6, 9, 1, 2]$ がソートされる様子を GIF 画像で示します。
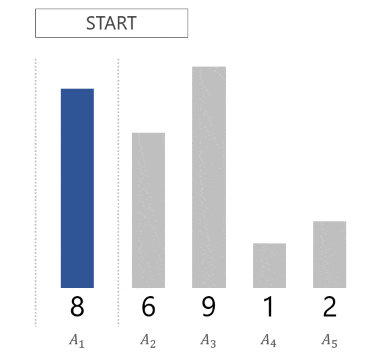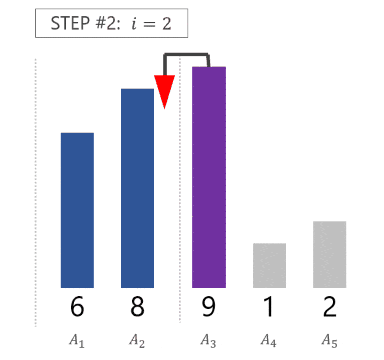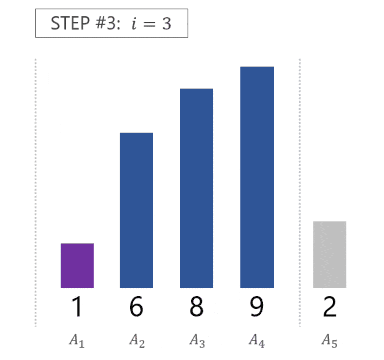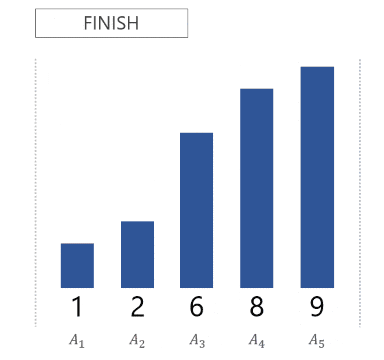
各ステップでは、「どこに挿入するか求める」「実際に挿入する」の 2 つの処理を行う必要があります。単純にやるとそれぞれ計算量 $O(i)$ がかかります13。したがって、ソートにかかる全体の計算量は
$$1 + 2 + \cdots + (N-1) = \frac{1}{2}N^2 - \frac{1}{2}N= O(N^2)$$
となります。
ソートアルゴリズムの世界
このように、挿入ソートを使うと、計算量 $O(N^2)$ で配列をソートできます。
しかし、実はさらに速いソートアルゴリズムがあり、なんと計算量 $O(N \log N)$ で配列をソートできます。マージソート や クイックソート14 が有名です。それ以外にも、個数にして数十種類ものソートアルゴリズムが知られています。
一方、さらに高速なソートができる場合もあります。例えば、配列の値がすべて $1$ 以上 $N^2$ 以下の場合、計算量 $O(N)$ でソートするアルゴリズムがあります。このように、ソートアルゴリズムの世界はとても奥が深いです。
World 5. データ構造
では、5 番目の「データ構造」の大陸に入っていきましょう。
遊園地のアトラクションの列に並んでいる場面を想像してみてください。みなさんも知っている 東京ディズニーランド や ユニバーサル・スタジオ・ジャパン などのテーマパークは、行列ができることで有名で、過去には 700 分待ち の行列ができた記録もあるそうです。

この行列を管理するプログラムを作ってみましょう。例えば、行列に並んでいる人の名前を管理することを考えます。すると、単純にいえば、次のような処理を行うことになります。
- 列の末尾に、名前 $X$ の人が並ぶ。
- 順番が回ってきたので、先頭の人が列から抜ける。
- 列の先頭の人の名前を答える。
このように、データに対して行われる処理や質問のことを クエリ (Query) といいます。このクエリを行うプログラムは、どのように実装することになるのでしょうか?
方法 1. 配列で実装する
まずは、もっとも直感的な方法として、行列に並んでいる人の名前を先頭から順に記録したら配列 S を使うことを考えます。例えば、行列に何もない状態から始めたとき、次のようなクエリが来ることを考えます。
- 列の末尾に Alice が並ぶ → 配列
S = ["Alice"]になる - 列の末尾に Bob が並ぶ → 配列
S = ["Alice", "Bob"]になる - 列の末尾に Chris が並ぶ → 配列
S = ["Alice", "Bob", "Chris"]になる - 列の先頭の人が抜ける → 配列
S = ["Bob", "Chris"]になる
といった感じになります。さて、それぞれのクエリを細かく見ていきましょう。
列の先頭の人の名前を答える
配列 S の先頭 S[0] を答えればよいです。もちろん、計算量は $O(1)$ です。
列の末尾に人が並ぶ
配列 S の末尾に名前 $X$ を追加すればよいです。C++ では std::vector の push_back、Python ではリスト型の append を使うなど、普通に配列を使って計算量 $O(1)$ でできます。
列の先頭の人が抜ける
列の先頭の人が抜けるとき、配列 S の先頭の要素を削除することになります。すると、配列の 2 番目以降の値は、すべて 1 個左にずれることになります。
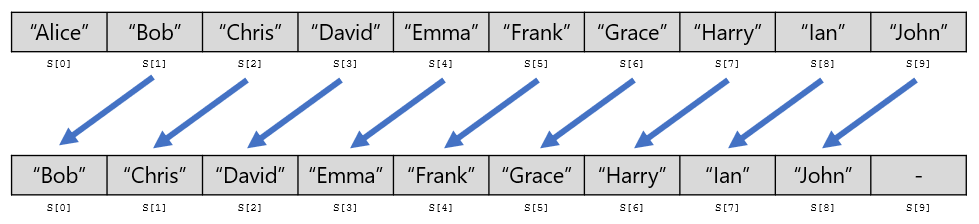
上図の例だと、S[1], S[2], S[3], S[4], S[5], S[6], S[7], S[8], S[9] をすべて 1 個左にずらす必要があります。配列の長さを $n$ とすると、計算量 $O(n)$ かかってしまい、非効率的です。
まとめると、「先頭の人の名前を答える」「末尾に人が並ぶ」のクエリは $O(1)$ で処理できますが、「先頭の人が抜ける」のクエリに $O(n)$ かかってしまいます。
方法 2. 「賢いやり方」を使う
方法 1 を使うと、「先頭の人が抜ける」クエリに $O(n)$ かかってしまい、非効率的でした。これを回避するために、新しいやり方を考えてみましょう。
列から抜けた人を配列から消さずに、"---" で記録したらどうでしょうか。すると、先ほどのように配列の 2 番目以降の値をすべて 1 個左にずらすようなことは、やらなくてもよくなります。
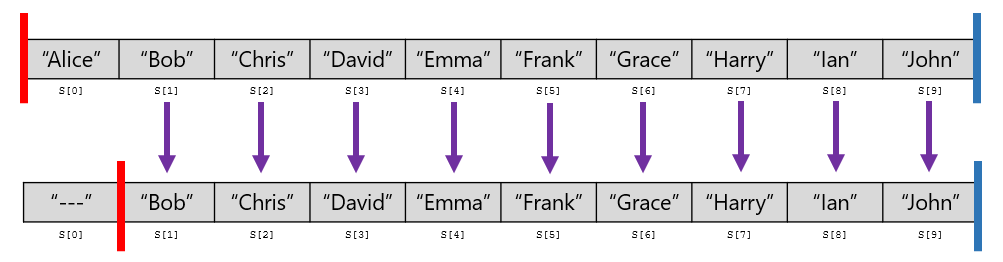
しかし、どこまで "---" が続いているか分からないと、先頭の人が誰なのかをすぐに見つけることができません。これに対応するため、新たに値 $l, r$ を記録し、S[l], S[l+1], ..., S[r] に名前があることを示すようにします。
例えば、S = ["Peter", "Quincy", "Rose"] $(l = 0, r = 3)$ から始めたとき、次のようなクエリが来ることを考えます。
- 列の先頭の人が抜ける →
S = ["---", "Quincy", "Rose"]$(l = 1, r = 3)$ になる - 列の末尾に Sarah が並ぶ →
S = ["---", "Quincy", "Rose", "Sarah"]$(l = 1, r = 4)$ になる - 列の先頭の人が抜ける →
S = ["---", "---", "Rose", "Sarah"]$(l = 2, r = 4)$ になる
といった感じになります。さて、それぞれのクエリを細かく見てみましょう。
列の先頭の人の名前を答える
l は列の先頭が配列 S 中のどの位置かを示すので、S[l] を答えればよいです。もちろん、計算量は $O(1)$ です。
列の末尾に人が並ぶ
S[r] に $X$ を代入するか、配列 S の末尾に $X$ を追加すればよいです。その後、$r$ を 1 増やします。計算量は $O(1)$ です。
列の先頭の人が抜ける
S[l] に "---" を代入して、$l$ を 1 増やせばよいです。計算量は $O(1)$ です。
まとめると
このような工夫をすることで、「先頭の人の名前を答える」「末尾に人が並ぶ」「先頭の人が抜ける」のクエリをすべて $O(1)$ で処理できるようになりました。
これと似た工夫は、レストランでも見たことがある方も多いと思います。
このように、データ構造は実世界でも、管理の手間をより少なく、より高速にするために、使われていることもあるのです。
データ構造とは?
先ほどのアトラクションの列を管理する 2 種類のデータ構造のように、いろいろなデータに対してクエリ処理をするために、適切な形でデータを管理し、クエリ処理の機能を実装したものを データ構造 といいます。
同じクエリを処理する場合でも、データ構造を工夫することで性能がよくなる場合があります。先ほどの例では、方法 1 のデータ構造を使うと「先頭の人が抜ける」クエリに計算量 $O(n)$ かかっていましたが、方法 2 のデータ構造を使うと $O(1)$ になります。
データ構造は、クエリ処理以外の場面でも、問題を解くアルゴリズムに組み込むことで高速化を図れる場合があります。例えば、World 3「グラフアルゴリズム」で紹介した最短経路問題を $O(|E| \log |V|)$ で解くアルゴリズムには、後述の「優先度付きキュー」というデータ構造が使われています。
今回のようなアトラクションの列のクエリ処理だけではなく、様々なクエリ処理がデータ構造の工夫により高速化できます。次は、データ構造の世界のなかでも重要な、5 つのクエリ処理の問題を紹介します。
5-1. キュー (Queue)
数列 $Q$ に対して、以下の 3 種類のクエリを処理したいです。
-
push(x): $Q$ の末尾に値 $x$ を追加する -
pop(): $Q$ の先頭の値を削除する -
top(): 現時点での $Q$ の先頭の値を求める
先ほど紹介したアトラクションの列を管理するデータ構造を使うと、すべてのクエリを 1 回あたり計算量 $O(1)$ で処理できます。このデータ構造のことを キュー (Queue) といいます。
5-2. デック (Deque)
先ほどのキューでは、操作は「末尾に $x$ を追加」「先頭を削除」の 2 種類でした。これに加えて、「先頭に $x$ を追加」「末尾を削除」を追加した 4 種類の操作にも対応できるデータ構造を考えてみましょう。
-
push_back(x): $Q$ の末尾に値 $x$ を追加する -
push_front(x): $Q$ の先頭に値 $x$ を追加する -
pop_back(): $Q$ の末尾の値を削除する -
pop_front(): $Q$ の先頭の値を削除する -
index(p): $Q$ の先頭から $p$ 番目の値を求める
実は、デック (Deque) というデータ構造を使うと、すべてのクエリを 1 回あたり計算量 $O(1)$ で処理できます。普通の配列に両側から追加/削除が行われるイメージですが、これもデータ構造の世界を知れば対応できるようになるのです。
5-3. 優先度付きキュー
今度は、スタックとキューとはまた別のデータ構造を考えます。最大値を取り出すデータ構造です。値の集まり15 $V$ に対して、以下の 3 種類のクエリを処理したいです。これは 優先度付きキュー とよばれています。
-
push(x): $V$ に値 $x$ を追加する -
pop(): $V$ の最大値を 1 つ削除する -
top(): $V$ の最大値を求める
普通にやると、$V$ に入っている値の個数を $n$ として、1 クエリあたり計算量 $O(n)$ かかりそうだと思うでしょう。しかし、データ構造の世界を知れば、より高速化できるのです。データ構造を使うと、1 クエリあたり計算量 $O(\log n)$ で処理できます。
5-4. 区間最小値クエリ RMQ
今度は、前とは少し違う雰囲気のクエリ処理を考えます。
長さ $N$ の配列 $A = [A_1, A_2, \dots, A_N]$ が与えられます。これに対して、以下のクエリがたくさん来るので、高速に処理したいです。
-
rangemin(l, r): $A_l, A_{l+1}, \cdots, A_r$ の最小値を求める。
これは、区間最小値クエリ (Range Minimum Query, RMQ) という問題です。最小値を求めるのには、計算量 $O(N)$ かかると考えるのが普通でしょう。しかし、高度なデータ構造を使うと、データ構造の初期化に計算量 $O(N)$ かけるだけで16 1 クエリあたり計算量 $O(1)$ で RMQ のクエリを処理できてしまいます。
信じられないかもしれませんが、データ構造の世界を知れば、どのようにして実現できるのかが分かります。
5-5. 木の最短経路
最後に、グラフの最短経路問題に関連したものを紹介します。
グラフの最短経路問題は、計算量 $O(|E| \log |V|)$ で解くことができます。しかし、グラフが「木」とよばれるものである場合、最短経路の長さ(=最短距離)をより高速に求めることができます。
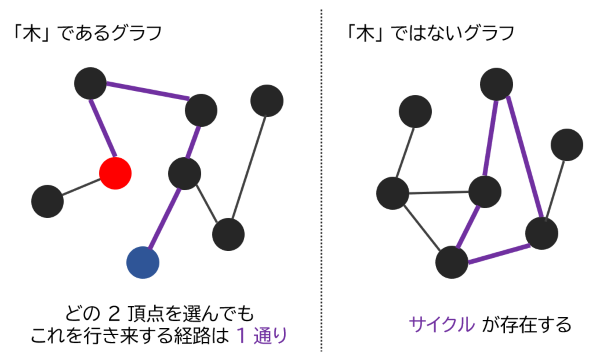
木とは、$n$ 頂点 $n-1$ 辺の、全体がひとつながり(連結)になっているグラフです。このグラフは、最小の辺の本数を使ってグラフ全体を連結にしているので、以下のような性質があります。
- グラフにサイクル(いくつかの辺をたどって元の頂点に戻る経路)が存在しない。
- どの 2 頂点を選んでも、これを同じ辺を通らずに行き来する経路が 1 通りに定まる。
実は、高度なデータ構造を使えば、木上の 2 点間の最短距離を「初期化17に計算量 $O(N)$、1 クエリあたり計算量 $O(1)$」で求めることさえできてしまいます。つまり、木に対して 2 点間の最短距離を求める質問が大量に来たとしても、すぐに答えることができるということです。
さらには、木の辺がつなぎ変えられるなど動的に変化する場合でも、かなり高速にクエリ処理をするデータ構造まで存在します。データ構造の世界を知らない人にとって信じられないような計算量で、クエリ処理ができるようになることもあるのです。
World 6. 数理最適化
それでは、6 番目の「数理最適化」の大陸に入っていきましょう。
大学の食堂には、たくさんの食品が売られています。各食品ごとに 「赤」「緑」「黄」のスコア が付けられていることもあります。栄養バランスを考えるために、赤を 8 点、緑を 3 点、黄を 17 点稼ぐのが目安、といった感じです。
あるとき、食堂には寿司・味噌汁・パスタ・サラダ・ご飯の 5 種類の食品が売られていたとします。また、この食堂では、各食品は何グラムでも自由に取ることができます。以下のように、100 グラムあたりの「赤」「緑」「黄」のスコアと、100 グラムあたりの値段が定められていたとしましょう。

ある学生は、赤を 1.5 点以上、緑を 0.5 点以上、黄を 3.0 点以上稼ぎたくて、その目標を達成するならば、できるだけ最小の金額で食事を済ませたいと思っていたとしましょう。
数理モデルに落とし込む
現実の現象を簡略化し、いろいろなものの関係や条件を数学的なものとして表したものを 数理モデル といいます。食堂の問題も、数理モデルとして表せます。
寿司・味噌汁・パスタ・サラダ・ご飯を実際に買う量を、それぞれ 100 グラム単位で $x_1, x_2, x_3, x_4, x_5$ とします。すると、満たさなければならない条件式は以下のようになります。
- 赤が $1.5$ 以上: $1.0x_1 + 0.3x_2 + 0.6x_3 + 0.0x_4 + 0.0x_5 \geqq 1.5$
- 緑が $0.5$ 以上: $0.1x_1 + 0.2x_2 + 0.0x_3 + 0.4x_4 + 0.0x_5 \geqq 0.5$
- 黄が $3.0$ 以上: $1.2x_1 + 0.6x_2 + 1.7x_3 + 0.1x_4 + 2.0x_5 \geqq 3.0$
- 買う食品の量を $0$ グラム未満にはできないので、$x_1, x_2, x_3, x_4, x_5 \geqq 0$
この 8 つの条件が、買う食品の量 $(x_1, x_2, x_3, x_4, x_5)$ に関して満たすべきすべての条件となります。
また、合計価格は $220x_1 + 90x_2 + 160x_3 + 130x_4 + 100x_5$ 円となります。これで、数理モデルとして表すことができました。
最適解はいくつ?
食堂の問題の最適解は、先ほど述べた 8 つの条件を満たす $(x_1, x_2, x_3, x_4, x_5)$ のなかで $220x_1 + 90x_2 + 160x_3 + 130x_4 + 100x_5$ が最小となるものになります。この最適解を実際に求めると
$$(x_1, x_2, x_3, x_4, x_5) = \left(\frac{75}{181}, \frac{415}{181}, \frac{120}{181}, 0, 0\right)$$
となり、合計値段は $\frac{73050}{181} = 403.59...$ 円となります。
数理最適化とは?
このように、数理モデルで表される問題の最適解を求める問題、そしてこれを解くアルゴリズムのことを、数理最適化 といいます。これは、近年注目を集めているアルゴリズム分野でもあります。
数理最適化の問題は、大きく 2 つに分けられます。
- 連続最適化: 先ほどの食堂の問題のように、実数をはじめとする連続的な値を調節することで、決められた条件のもとで、何かを最大化/最小化する問題。
- 組合せ最適化: 整数のような離散的な値や、「選ぶ・選ばない」などの組み合わせをうまく決めることで、決められた条件のもとで、何かを最大化/最小化する問題。
なお、World 2「動的計画法」と World 3「グラフアルゴリズム」で紹介した問題の多くが「組合せ最適化」の問題になっています。例えば、3-2. の「最小全域木問題」は、全体がひとつながりになるという制約のもとで辺の「選ぶ・選ばない」を決め、選ぶ辺の長さの合計を最小化する問題です。
数理最適化の世界へようこそ。競技プログラミングでも、たくさんの最適化問題が出題されていますが、ここでは、競技プログラミングではあまり使われないものの、アルゴリズムを学ぶ人なら知っておくべき 4 つの問題(連続最適化・組合せ最適化からそれぞれ 2 問)を紹介します。
6-1. 近似曲線を求める
アンケート調査や実験などで、たくさんのデータをとった後に、このデータがどのような傾向になるか調べることがあります。例えば、以下は「数学のテストの点数」と「テスト勉強にかけた時間」のアンケート調査18の結果を表したグラフです。
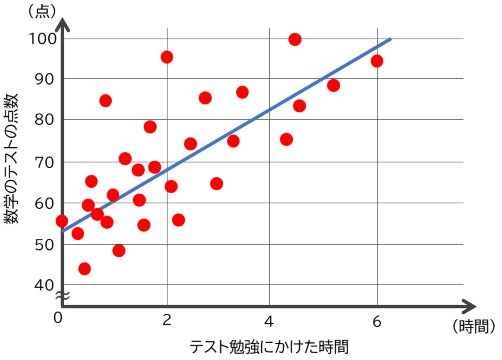
このように、結果に最もフィットする直線を求めることを「線形回帰」といいます。$n$ 個のデータ $(x_1, y_1), (x_2, y_2), \dots, (x_n, y_n)$ に最もフィットする直線 $y = ax + b$ は、データとの誤差の 2 乗の合計、つまり
$$(y_1 - (ax_1 + b))^2 + (y_2 - (ax_2 + b))^2 + \cdots + (y_n - (ax_n + b))^2$$
を最小化する $a, b$、とするのが一般的です。これは、2 次関数の性質を使うと、計算で求めることができます。
一方、数理最適化の力を使えば、最も近い多項式にフィットさせることだってできます。$n$ 個のデータに最もフィットする $m$ 次以下の多項式 $f(x) = p_m x^m + \cdots + p_2 x^2 + p_1 x + p_0$、すなわち $(y_1 - f(x_1))^2 + \cdots + (y_n - f(x_n))^2$ を最小にする $(p_m, \dots, p_1, p_0)$ は、計算量 $O(m^2 \cdot n)$ で求められます。
6-2. 割り当て問題
割り当て問題は、有名な組合せ最適化問題です。
$N$ 人の労働者が、$N$ 個の仕事をひとつずつ分担することを考えます。しかし、人によって仕事の適正が異なるため、$i$ 人目の労働者が $j$ 番目の仕事をやるのに $A_{i, j}$ 時間かかる、といったような $N^2$ 個の値が定められています。仕事の合計時間を最小化する、最適な役割分担を求めるのが、割り当て問題 です。
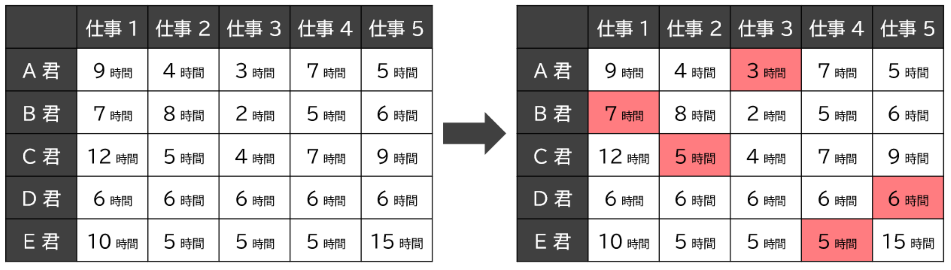
仕事の割り当て方は $N! = 1 \times 2 \times \cdots \times N$ 通りあり、データが大きくなれば全探索が現実的な選択肢ではなくなります。しかし、組合せ最適化のアルゴリズムを使えば、実にこの問題を計算量 $O(N^3)$ で解けてしまいます。
6-3. 線形計画問題
線形計画問題 (Linear Programming, LP) は、条件がすべて 1 次式の等式または不等式で表され、1 次式の値を最大化する、連続最適化の問題です。先ほどの食堂の問題は、実数 $(x_1, x_2, x_3, x_4, x_5)$ に対して
- $1.0x_1 + 0.3x_2 + 0.6x_3 + 0.0x_4 + 0.0x_5 \geqq 1.5$
- $0.1x_1 + 0.2x_2 + 0.0x_3 + 0.4x_4 + 0.0x_5 \geqq 0.5$
- $1.2x_1 + 0.6x_2 + 1.7x_3 + 0.1x_4 + 2.0x_5 \geqq 3.0$
- $x_1, x_2, x_3, x_4, x_5 \geqq 0$
という 8 つの条件を満たしたうえで $220x_1 + 90x_2 + 160x_3 + 130x_4 + 100x_5$ を最大化する、線形計画問題になっています。
線形計画問題には、変数の数 $n$、条件の数 $m$ の多項式時間19で解けるアルゴリズムが知られているほか、実用上はかなり高速に解けることが知られています。線形計画問題は様々な問題に応用できるため、数理最適化のなかでも最も重要な問題なのです。
6-4. クラスタリング
クラスタリングは、データの集まりを特徴に応じて分類することです。
例えば、犬と猫のペットを飼っている人がいたとして、その犬の写真と猫の写真を分類する問題を考えます。

そのまま画像として分類するのは難しいですが、画像の「特徴量」(例えば、茶色のピクセルの割合など)を調べることで、違いの特徴がつかめる場合があります。写真を集めてみたら、白いピクセルの割合と茶色いピクセルの割合をプロットしてみると、以下のようになったとしましょう。
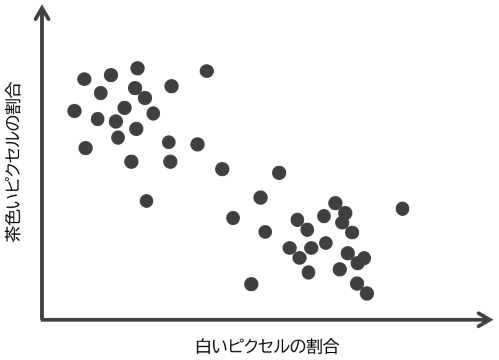
なんとなく、左上と右下の 2 つのクラスタに分かれているような気がしますね。データを 2 つのクラスタに自動で分けるためには、どのような最適化問題を解けばいいのでしょうか?
データ $i$ が座標 $(x_i, y_i)$ にあったとします。各点を赤と青に塗り分けて、「赤いまとまり」「青いまとまり」になっているようにしたいです。このため、例えば、同じ色の点の距離の 2 乗の合計20を最小化する塗り分け方がよく使われ、そうするとうまく 2 つのグループに分かれます。
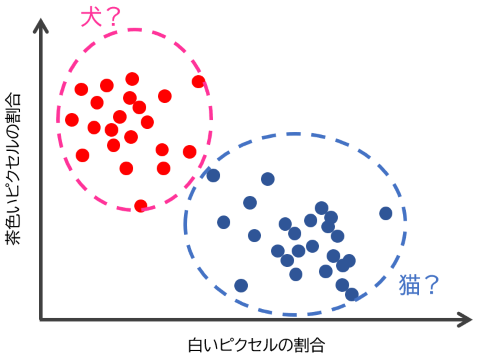
このクラスタリングの問題で、効率的に最適解を求める方法は知られていませんが、k-means++ などのアルゴリズムを使うと、高速に十分よいクラスタリングを得ることができます。
この手法は、機械学習(特に教師なし学習)にも応用することができます。このように、数理最適化は情報科学の幅広い分野に応用されるどころか、工学・経済・マネジメントをはじめとするあらゆる分野に応用されます。
World 7. 数学的アルゴリズム
最後に、7 番目の「数学的アルゴリズム」の大陸に入っていきましょう。
アルゴリズムは、これまでのような最適化やクエリ処理などの問題だけでなく、整数のような数学的な問題を解くこともできます。数学的な問題を解く際に、アルゴリズムの工夫ができることもあります。一例として、次の問題を考えてください。
1111111111111111111(1 が 19 個)は素数か、それとも合成数か?
N が素数であるのは、 2 以上 N-1 以下の整数で割り切れない数のことです。したがって、「N は 2 で割り切れるか?」「N は 3 で割り切れるか?」「N は 4 で割り切れるか?」…「N は N-1 で割り切れるか?」と試していくと、計算量 $O(N)$ で素数判定できます。
下のプログラムは、2 以上の整数 n を素数判定する Python のプログラムです。(Python を知らない方も、コメントなどを見れば読めると思います)
def is_prime(n):
# i = 2, 3, 4, ..., n-1 でループ
for i in range(2, n):
# 「n % i」は n を i で割った余り
if n % i == 0:
return False
return True
しかし、このプログラムで 11111..11(1 が 19 個)を素数判定しようとしても、現実的な時間で実行が終わりません。
ひと工夫で高速化
実は、2 以上 √N 以下の整数で割り切れるかどうかしか試す必要はありません。
もし N が合成数であって、2 以上 √N 以下の整数で割り切れないならば、√N より大きいどれかの整数 $x$ で割り切れることになります。すると $N \div x$ は N で割り切れ、しかも √N 以下になります。これは √N 以下では割り切れないことに矛盾し、おかしいです。だから、合成数は必ず √N 以下のどれかの数で割り切れるのです。
したがって、11111..11(1 が 19 個)を素数判定するためには、2 以上 105409255321 以下の整数で割り切れるかどうか判定するだけで十分、ということになります。この工夫で、素数判定の計算量が $O(\sqrt{N})$ に高速化されます。
この工夫で、10 秒ほどプログラムを実行すれば、「11111...11(1 が 19 個)は素数である」と判定できるようになりました。
数学的アルゴリズムの力強さ
しかし、数学的アルゴリズムの世界は、$O(\sqrt{N})$ よりもさらに高速な素数判定を可能にし、1000 桁くらいの数ならすぐに素数判定ができます。時間をかければ、数万桁の数も素数判定できます。
さらには、メルセンヌ数 とよばれる $2^k-1$ の形で表せる数はより高速に素数判定できることが知られており、現在知られている素数のなかで最大のものは $2^{82589933}-1$ という 2500 万桁ほどの数です。
このように、普通では考えられないような速度で計算できることがあるのは、数学的アルゴリズムの世界の魅力でもあります。数学的アルゴリズムは、競技プログラミングでもよく出題されるトピックです。ここでは、3 つの数学的な問題を紹介します。
7-1. 素数判定
整数 N を素数かどうか求める問題を「素数判定」といいます。先ほど説明したように、2 から √N まで割り切れるかどうか試すことで、計算量 $O(\sqrt{N})$ で素数判定ができます。
実はこれよりもさらに高速に素数判定ができ、計算量 $O((\log N)^2)$ のアルゴリズム22も存在します。なので、1000 桁程度の数なら、短い時間で素数判定ができます。
7-2. 素因数分解
2 以上の整数 N は、すべて素数の掛け算で表すことができます。例えば、111111 = 3 × 7 × 11 × 13 × 37、といった感じです。素数判定と同様、2 から √N まで割れるか試すことで、計算量 $O(\sqrt{N})$ で素因数分解ができます。
一方、素数判定とは違って、数百桁程度の大きな数の素因数分解をすることは困難です。なぜなら、素数判定ほど高速なアルゴリズムが存在しないからです。現在知られている最速のアルゴリズムである 一般数体ふるい法 を使うと、計算量
$$O \left(\exp\left(\left(\sqrt[3]{\frac{64}{9}}+o(1)\right)(\log_e N)^{1/3}(\log_e \log_e N)^{2/3}\right)\right)$$
で解けることが知られていますが、スーパーコンピューターを 3 年間使っても 230 桁程度が限界 です。
このように、素数を判定したり生成したりするのは簡単なのに対して、素因数分解は難しいという性質があります。この「非対称性」を利用して、現在主流の暗号である RSA 暗号 に応用され、私たちの情報セキュリティーが守られているのです。
7-3. 多倍長整数演算
多倍長整数演算とは、C++ や Java の int 型などでは表せないような大きな数を計算することです。大きな数の計算には、桁数に応じて時間がかかります。みなさんも、2 桁 × 1 桁の掛け算よりも 3 桁 × 3 桁の掛け算の方が大変そうなイメージを持っていると思いますが、コンピューターでも同じようなことになります。
一般に、みなさんが小学校で習った筆算を使うと
- $n$ 桁 + $n$ 桁の足し算: 計算量 $O(n)$
- $n$ 桁 - $n$ 桁の引き算: 計算量 $O(n)$
- $n$ 桁 × $n$ 桁の掛け算: 計算量 $O(n^2)$
- $n$ 桁 ÷ $(n/2)$ 桁の割り算: 計算量 $O(n^2)$
で計算できます。
しかし、実はさらに高速な方法もあり、高度なアルゴリズムを使えば掛け算を計算量 $O(n \log n)$23、割り算も計算量 $O(n \log n)$ で計算することができます。
これを応用して、√2 = 1.4142... や円周率 π = 3.1415... を、たった数秒で小数点以下 100 万桁まで計算することもできます。
このように、数学的アルゴリズムは、数学的な問題を普通では考えられないような速度で解くことがあります。そのようなアルゴリズムは、現実社会でも暗号などに応用されています。
8. おわりに
アルゴリズムの世界はいかがでしたでしょうか。筆者としては、この記事で
- アルゴリズムがどんなもので
- アルゴリズムを使うとどんな問題が解けて
- アルゴリズムが地球のように広く、多様で、奥深く、そして楽しいこと
を体感できたならば、うれしいと思っています。実際に探検した 7 つの世界2を振り返って見ると、以下の写真集のようなイメージで振り返れるように、多様な問題が解けることが見てとれるでしょう。
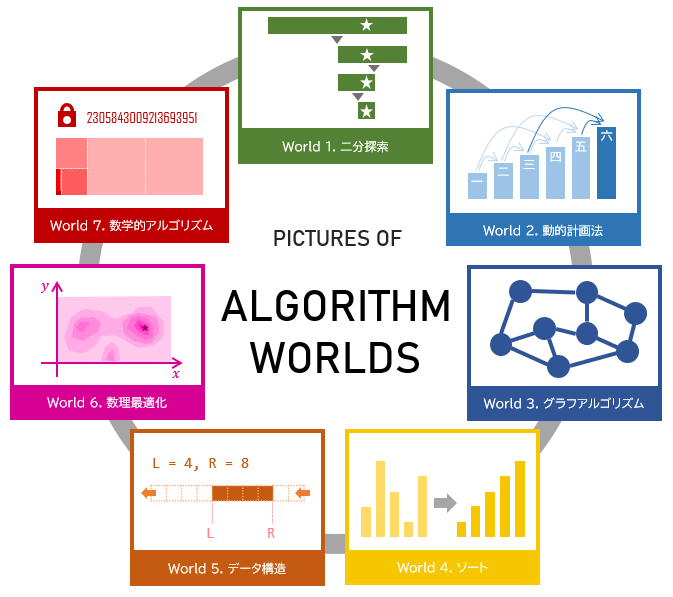
しかし、この記事では、実際に 7 つの世界と 25 の都市を旅行したわけではなく、アルゴリズムの世界旅行のカタログを見ただけだと思ってください。
アルゴリズムを学ぶことは、実際にアルゴリズムの世界の地面に降り立って、いろいろなアルゴリズムの中身を知ったり、いろいろな問題で使いこなしたりすることです。旅行のカタログを見るだけでなく、実際にその地に立ったときに、新たに感じられることはたくさんあるはずです。
だから、この記事が、アルゴリズムの世界への飛行機の切符となってくれればと思っています。
9. 実際にアルゴリズムをやってみたいと思った方へ
この記事の最後に、実際にアルゴリズムや競技プログラミングをやってみようと思った方に、次のステップを踏むためのいくつかの参考資料を書いておきます。
まず、アルゴリズムを入門したい方にとって代表的な 4 つの書籍です。
- 問題解決力を鍛える!アルゴリズムとデータ構造(大槻兼資) 2020 年 10 月に出版された、アルゴリズムのベストセラー本です。
- 『アルゴリズム×数学』がしっかり身に付く本(米田優峻) 2021 年 12 月に出版された、アルゴリズムと数学が同時に学べる本です。
- プログラミングコンテスト攻略のためのアルゴリズムとデータ構造(渡部有隆) 会津大学の先生が書いた、高度なアルゴリズムまで学べる本です。
- プログラミングコンテストチャレンジブック(秋葉拓哉・岩田陽一・北川宜稔) 競技プログラミングをやっている人なら誰もが知っている、競プロ攻略本です。難易度は比較的高めです。
また、競技プログラミングを始めようと思った方におすすめの記事や教材です。
- レッドコーダーが教える、競プロ・AtCoder上達のガイドライン【初級編:競プロを始めよう】(@e869120 さんより) 競技プログラミングや AtCoder がどんなものか、そして戦うためにはどうすればよいのかが書かれた、有名な記事です。
- AtCoder に登録したら次にやること ~ これだけ解けば十分闘える!過去問精選 10 問 ~(@drken さんより) AtCoder を始めたい人が最初に読むべき記事です。
- アルゴ式 2021 年に開設された、アルゴリズムや情報科学を学べる最近話題のウェブサイトです。
- 競プロ典型 90 問 アルゴリズムを使った 90 問の厳選された問題です。競プロ練習に最適な教材のひとつです。
-
筆者も 2021 年 11 月にオセロ AI を作っていましたが、Nyanyan さん に勝利することができませんでした。 ↩
-
7 個の世界がアルゴリズム分野のすべてというわけではありません。本記事で紹介していない代表的なアルゴリズムとして、「探索アルゴリズム」や「文字列アルゴリズム」、「確率的アルゴリズム」などがあります。 ↩ ↩2
-
$\lfloor N/2 \rfloor$ は「N ÷ 2 を整数に切り捨てた値」という意味です。N が奇数の場合は、「1+7, 2+6, 3+5, 4」(N = 7 の例)のように 1 個余りますが、4 = 8 × (1/2) と表せるように、この場合も 1 + 2 + … + N = (N + 1) * (N / 2) という式で計算できます。 ↩
-
厳密な定義では、アルゴリズムの計算回数が $T(N)$ であるとき、どんな $N$ に対しても $f(N) \leqq c \times T(N)$ が成り立つような定数 $c \gt 0$ が存在するとき「計算量 $O(f(N))$ である」といいます。 ↩
-
実際には、計算時間の定数倍の部分で差がつき、計算量オーダー(ランダウの O 記法の中身)が遅いプログラムの方が実行速度が速い場合もあります。例えば、$N \lt 100$ の範囲では、計算回数 $N^3$ のプログラムの方が $100N^2$ のプログラムより速いです。一方、$N$ が十分大きくなれば、計算量オーダーが速いプログラムが実行時間も速くなります。 ↩ ↩2 ↩3 ↩4
-
「にぶんたんさく」と読みます。 ↩
-
でも、人間の視覚的には、方法 2 の方が見つけるのが簡単だと思います。なぜなら、視界を移動するのに時間がかかるからです。プログラミングの配列だと基本的には方法 3 の方が速いですが、連続するメモリ上のアクセスの方が速いなど、実際のアーキテクチャの特徴を生かした工夫もできるかもしれません。 ↩
-
文字列の比較の計算量が $O(1)$ であると仮定しています。例えば、SCRABBLE 辞書 に載っている単語は 8 文字以下に限定されているので、定数回の計算で比較できるという仮定も現実的です。 ↩
-
具体的には、$x^2 = N$ となる $x$ を二分探索で求めると、$x$ の値がどんどん $\sqrt{N}$ に近づいていきます。$d$ 桁の精度で求めるためには、$O(d)$ 回のステップが必要です。一方で、二分探索より効率的に $\sqrt{N}$ を求めるアルゴリズムもあり、例えば ニュートン法 を使うと $O(\log d)$ 回のステップで求まります。 ↩
-
具体的なコインの組み合わせは「1, 1, 5, 11, 11, 11 円」、「1, 3, 3, 11, 11, 11 円」そして「3, 5, 5, 5, 11, 11 円」の 3 通りがあります。これも DP 復元 というテクニックを使って求められます。 ↩
-
1736 年に、スイスの数学者 オイラー が ケーニヒスベルクの橋の問題 を解く際に、ケーニヒスベルクの地図をグラフで単純化したときが、グラフ理論の始まりとされています。 ↩
-
図中のグラフの辺の重みの単位はすべてメートル (m) です。 ↩
-
挿入する場所を求めるのは、World 1 で説明した「二分探索」を使うと $O(\log i)$ でできます。しかしこの場合でも、実際に挿入するためには $A_{k+1}, A_{k+2}, \dots, A_i$ の場所を 1 つ右にずらす必要があるので、計算量 $O(i)$ かかります。 ↩
-
クイックソートは乱数を使ったアルゴリズムであり、平均計算量が $O(N \log N)$ です。一方で、どのステップでも最悪な乱数の値を引いてしまった場合、$N^2$ に比例する計算時間がかかる場合があります。 ↩
-
集合ではないので、$V$ には同じ値が複数あってもよいです。 ↩
-
もしデータ構造の初期化に無限に計算量をかけてよいならば、あらかじめ計算量 $O(N^3)$ かけて可能な $(l, r)$ の組み合わせすべてに対する答えを計算しておけば、1 クエリ当たり $O(1)$ が実現できます。初期化にかける時間が長いほど、1 クエリにかける時間を短くできる、トレードオフの関係が知られています。しかし、ここで重要なのは、高度なデータ構造を使えば、データ構造の初期化に $O(N)$ しかかけなくても 1 クエリあたり $O(1)$ が実現できるということです。 ↩
-
5-4. RMQ を参照。 ↩
-
これは架空のデータであり、実際にこのようなアンケート調査を行ったわけではありません。 ↩
-
$n, m$ の多項式で表される計算量、という意味です。例えば、$L$ を精度の桁数として、計算量 $O((n + m)^{1.5} \cdot m \cdot L)$ のアルゴリズムが知られています。 ↩
-
つまり、色が同じ 2 つのデータ $i, j$ $(1 \leqq i \lt j \leqq n)$ に対する、$(x_i - x_j)^2 + (y_i - y_j)^2$ の合計、ということです。 ↩
-
$\sqrt{11111...11} = 1054092553.389...$ だからです。 ↩
-
Miller-Rabin 素数判定法とよばれるアルゴリズムです。確率的アルゴリズムですが、どんな $N$ に対しても「運が悪くない限り」正しく判定されます。「運がどのくらい悪ければ諦めるか」も自分で設定できます。計算量は、四則演算が計算量 $O(1)$ でできると仮定した場合のものですが、$N$ の桁数が多く、7-3 で述べる「多倍長整数演算」を必要とする場合、計算量 $O((\log N)^3 \log(\log N))$ かかります。 ↩
-
コンピューターのビット数(64 bit など)を $b$ として、メモリサイズが $2^b$ 程度以下であることを仮定した場合の計算量です。この仮定は実質すべてのコンピューターで成り立ちます。 ↩