pythonスクレイピング リダイレクトされる?
解決したいこと
スクレイピングするにあたって
取得したいURLが変わってしまう為、どうしたら良いのか
解決方法を教えて下さい。
発生している問題・エラー
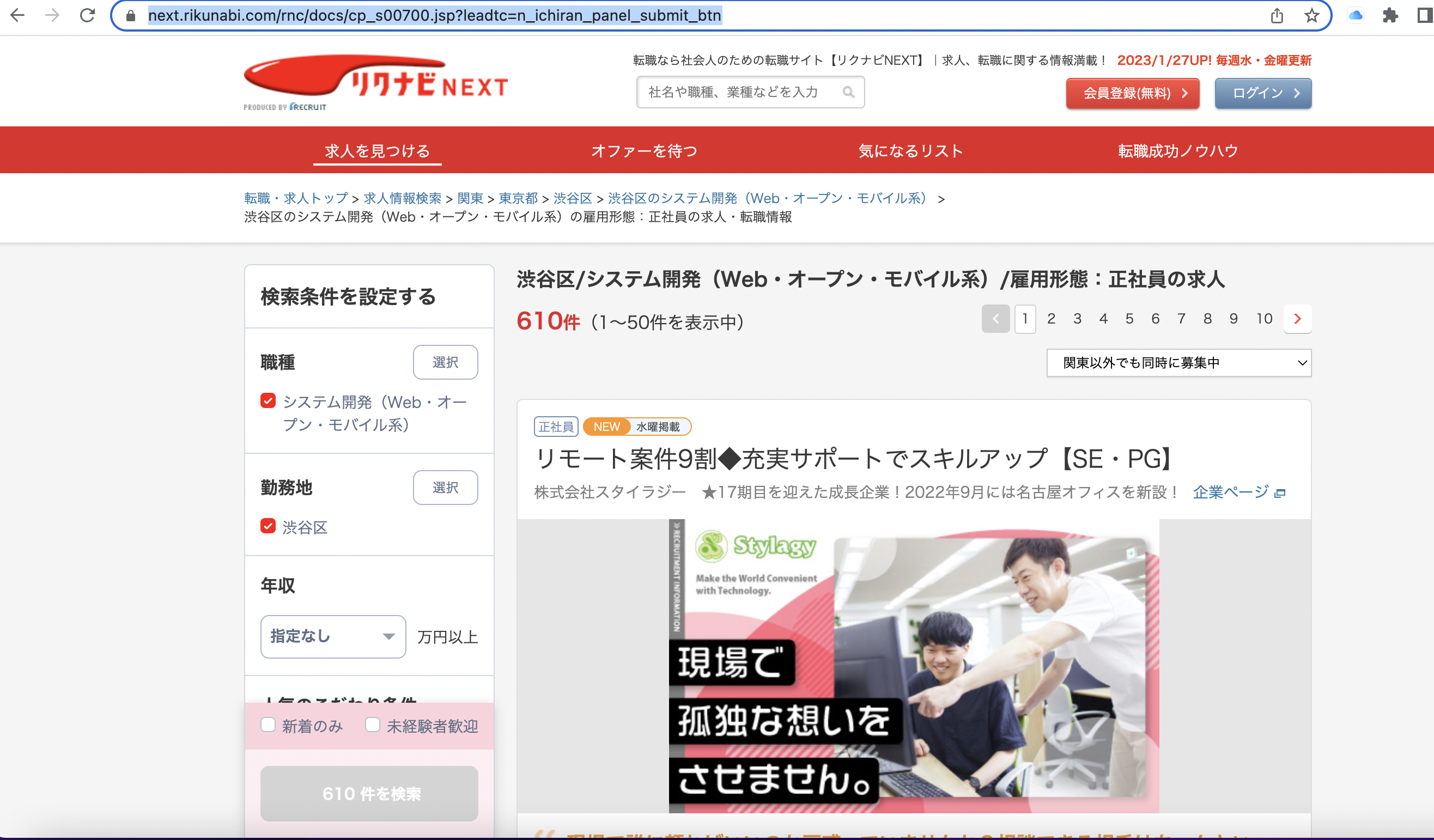
上記の条件で取得したい。
「職種」システム開発・・・モバイル系
「勤務地」渋谷
「雇用状態」正社員
URLは以下になる
https://next.rikunabi.com/rnc/docs/cp_s00700.jsp?leadtc=n_ichiran_panel_submit_btn
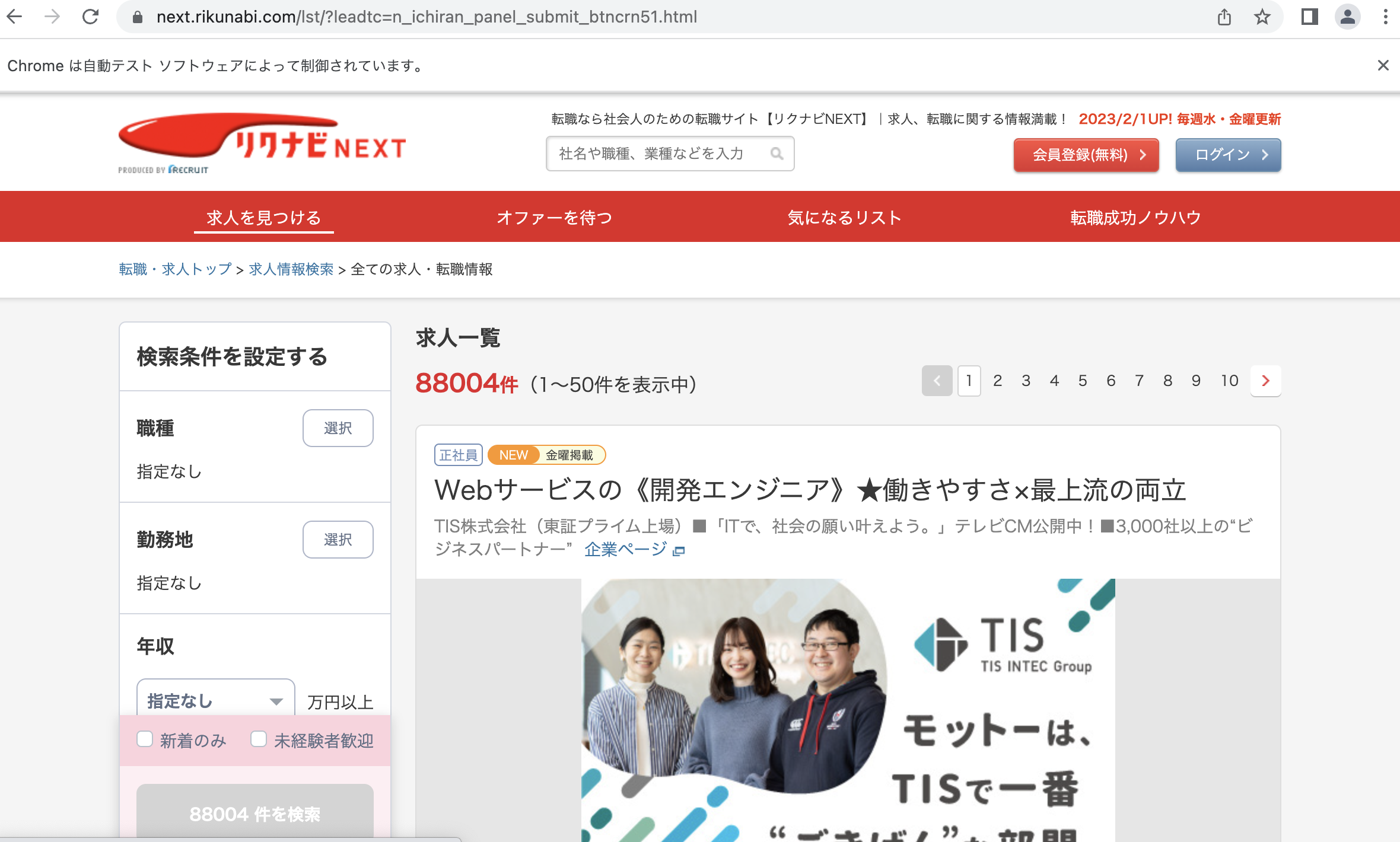
しかし、スクレイピングを実施すると
URLが変更してしまう(条件が全て無効になってる)
該当するソースコード
def rikunabi_next():
#ここでurlを取得
get_url = request.form.get('url_name')
get_page = request.form.get('page')
browser = webdriver.Chrome(ChromeDriverManager().install())
url = get_url
browser.get(url)
response = requests.get(url, allow_redirects=False)
soup = BeautifulSoup(response.text, 'html.parser')
page_count = 1
p = get_page
p = int(p)
urls = []
while True:
#ブロックで取得
res = requests.get(url)
soup = BeautifulSoup(res.content, 'html.parser',from_encoding='utf-8')
boxs = soup.find_all('ul', attrs={'class': 'rnn-group rnn-group--xm rnn-jobOfferList'})
for box in boxs:
links = box.find_all('a', attrs={'class': 'rnn-linkText rnn-linkText--black'})
for link in links:
link = link.get('href')
urls.append(link)
page_count += 50
time.sleep(3)
url = get_url + 'crn' + str(page_count) + '.html'
browser.get(url)
if page_count > p:
break
#except TimeoutException:
print('pageの読み込みを終了しました')
lists = []
periods = []
for list in urls:
key_word = list
url = 'https://next.rikunabi.com' + key_word
browser.get(url)
res = requests.get(url)
soup = BeautifulSoup(res.content, 'html.parser',from_encoding='utf-8')
#会社名取得
list = soup.find('p', attrs={'class': 'rn3-companyOfferSide__menuMainCompanyName'})
period = soup.find('p',attrs={'class': 'rn3-companyOfferHeader__period'})
for z in list:
z = z.replace("[<p class=rn3-companyOfferSide__menuMainCompanyName>",'')
lists.append(z)
for x in period:
period = x.text
periods.append(period)
time.sleep(3)
phone_numbers = []
titles = []
adress = []
for title in lists:
titles.append(title)
key_word = title
#取得した会社名+電話番号でGoogleで調べる
url = 'https://www.google.com/search?q=' + key_word +'電話番号'
browser.get(url)
#電話番号取得
if browser.find_elements_by_class_name('X0KC1c'):
phone_number = browser.find_elements_by_class_name('X0KC1c')
#所在地取得
adres = browser.find_elements_by_css_selector('span[class="LrzXr"]')
for d in adres:
adres = d.text
adress.append(adres)
for c in phone_number:
phone_number = c.text
phone_numbers.append(phone_number)
sec = random.uniform(5,7)
time.sleep(sec)
else:
phone_numbers.append('')
adress.append('')
time.sleep(1)
df = pd.DataFrame()
df['会社名'] = titles
df['掲載期間'] = periods
df['電話番号'] = phone_numbers
df['住所'] = adress
df
SCOPES = ["https://spreadsheets.google.com/feeds",
'https://www.googleapis.com/auth/spreadsheets',
"https://www.googleapis.com/auth/drive.file",
"https://www.googleapis.com/auth/drive"]
SERVICE_ACCOUNT_FILE = '**************'
credentials = ServiceAccountCredentials.from_json_keyfile_name(SERVICE_ACCOUNT_FILE, SCOPES)
gs = gspread.authorize(credentials)
SPREADSHEET_KEY ='*************'
workbook = gs.open_by_key(SPREADSHEET_KEY)
today = datetime.date.today()
#シート作成(新規)
workbook.add_worksheet(title='リクナビNEXT_IT'+str(today), rows=500, cols=10)
#先程作成したシートに出力
set_with_dataframe(workbook.worksheet('リクナビNEXT_IT'+str(today)), df, include_index=True)
browser.quit()
return url
自分で試したこと
get_url = request.form.get('url_name')
url = get_url
browser.get(url)
上記が悪さしているのかな?と思い、スクレイピングの処理を挟まず、returnで1個1個確認しました。
全て
https://next.rikunabi.com/rnc/docs/cp_s00700.jsp?leadtc=n_ichiran_panel_submit_btn
となっており問題はありませんでした。
どのような対策を取ればよろしいでしょうか?
0 likes