Selenium WEB API
解決したいこと
エンジニア歴半年のクソ雑魚エンジニアです、。
友人が転職したくて、求人サイトを毎日のように見てると言っていたので、最近Python(selenium)を勉強していたので、抽出してやろうと思い、いろんなサイトでデータ採取をしていました。
そこで、スプレッドシート共有して、スプレッドシートに書き出していました。
しかし、その友人が毎回私にLINEして採取してもらうのは申し訳ないから、その機能をWEBサイトでできないの?って聞いてきて、、頭が真っ白です。
WEB_API化?をすればいけるのか、cloud9で書いて、デプロイすれば良いのか
何をどうしたら、なんて検索して、勉強すれば良いのか、何もかもわからず。。
PHPでWEBサイトを作成して、デプロイしたことあるが、seleniumの場合はちょっと違う気がして
解決方法を教えて下さい。
発生している問題・エラー
エラーはない
該当するソースコード
import pandas
import datetime
import requests
import time
from bs4 import BeautifulSoup
import csv
import pandas as pd
from gspread_dataframe import set_with_dataframe
import gspread
from oauth2client.service_account import ServiceAccountCredentials
from webdriver_manager.chrome import ChromeDriverManager
from selenium import webdriver
from time import sleep
browser = webdriver.Chrome(ChromeDriverManager().install())
url = 'https://doda.jp/DodaFront/View/JobSearchList.action?ss=1&ci=131016%2C131024%2C131032%2C131041%2C131059%2C131067%2C131075%2C131083%2C131091%2C131105%2C131113%2C131121%2C131130%2C131148%2C131156%2C131164%2C131172%2C131181%2C131199%2C131202%2C131211%2C131229%2C131237&pic=1&ds=0&oc=03L&so=50&tp=1'
browser.get(url)
res = requests.get(url)
#parser = 分割的な意味
soup = BeautifulSoup(res.text, 'html.parser',from_encoding='utf-8')
page_count = 1
p = soup.find('span', attrs={'class': 'number'})
p = p.text
p = p.replace(',','')
p = int(p)
p = -(-p // 50)
links = []
urls = []
while True:
res = requests.get(url)
soup = BeautifulSoup(res.content, 'html.parser',from_encoding='utf-8')
title = soup.find_all('span', attrs={'class': 'company width688'})
boxs = soup.find_all('div', attrs={'class': 'upper clrFix'})
#会社名取得
for link in title:
link = link.text
link = link.replace('NEW','')
link = link.replace('締切間近','')
links.append(link)
#リンク取得
for box in boxs:
uls = box.find_all('a', attrs={'class': '_JobListToDetail'})
for ur in uls:
ur = ur.get('href')
urls.append(ur)
page_count += 1
time.sleep(3)
url = 'https://doda.jp/DodaFront/View/JobSearchList.action?pic=1&ds=0&oc=03L&so=50&ci=131016%2C131024%2C131032%2C131041%2C131059%2C131067%2C131075%2C131083%2C131091%2C131105%2C131113%2C131121%2C131130%2C131148%2C131156%2C131164%2C131172%2C131181%2C131199%2C131202%2C131211%2C131229%2C131237&pf=0&tp=1&page='+ str(page_count)
browser.get(url)
if page_count > 10:
break
#except TimeoutException:
print('pageの読み込みを終了しました')
periods = []
for v in urls:
url = v
browser.get(url)
res = requests.get(url)
soup = BeautifulSoup(res.content, 'html.parser',from_encoding='utf-8')
period = soup.find('p', attrs={'class': 'meta_text'})
#掲載期間取得
for x in period:
period = x.text
periods.append(period)
time.sleep(3)
phone_numbers = []
titles = []
adress = []
for title in links:
titles.append(title)
key_word = title
#取得した会社名+電話番号でGoogleで調べる
url = 'https://www.google.com/search?q=' + key_word +'電話番号'
browser.get(url)
#電話番号取得
if browser.find_elements_by_class_name('X0KC1c'):
phone_number = browser.find_elements_by_class_name('X0KC1c')
#所在地取得
adres = browser.find_elements_by_css_selector('span[class="LrzXr"]')
for d in adres:
adres = d.text
adress.append(adres)
#電話番号取得
for c in phone_number:
phone_number = c.text
phone_numbers.append(phone_number)
time.sleep(3)
else:
phone_numbers.append('')
adress.append('')
time.sleep(1)
df = pd.DataFrame()
df['会社名'] = titles
df['掲載期間'] = periods
df['電話番号'] = phone_numbers
df['住所'] = adress
df
SCOPES = ["https://spreadsheets.google.com/feeds",
'https://www.googleapis.com/auth/spreadsheets',
"https://www.googleapis.com/auth/drive.file",
"https://www.googleapis.com/auth/drive"]
SERVICE_ACCOUNT_FILE = '**********'
credentials = ServiceAccountCredentials.from_json_keyfile_name(SERVICE_ACCOUNT_FILE, SCOPES)
gs = gspread.authorize(credentials)
SPREADSHEET_KEY ='*********'
workbook = gs.open_by_key(SPREADSHEET_KEY)
today = datetime.date.today()
#シート作成(新規)
workbook.add_worksheet(title='dodaIT'+str(today), rows=100, cols=10)
#先程作成したシートに出力
set_with_dataframe(workbook.worksheet('dodaIT'+str(today)), df, include_index=True)
実際のデータ
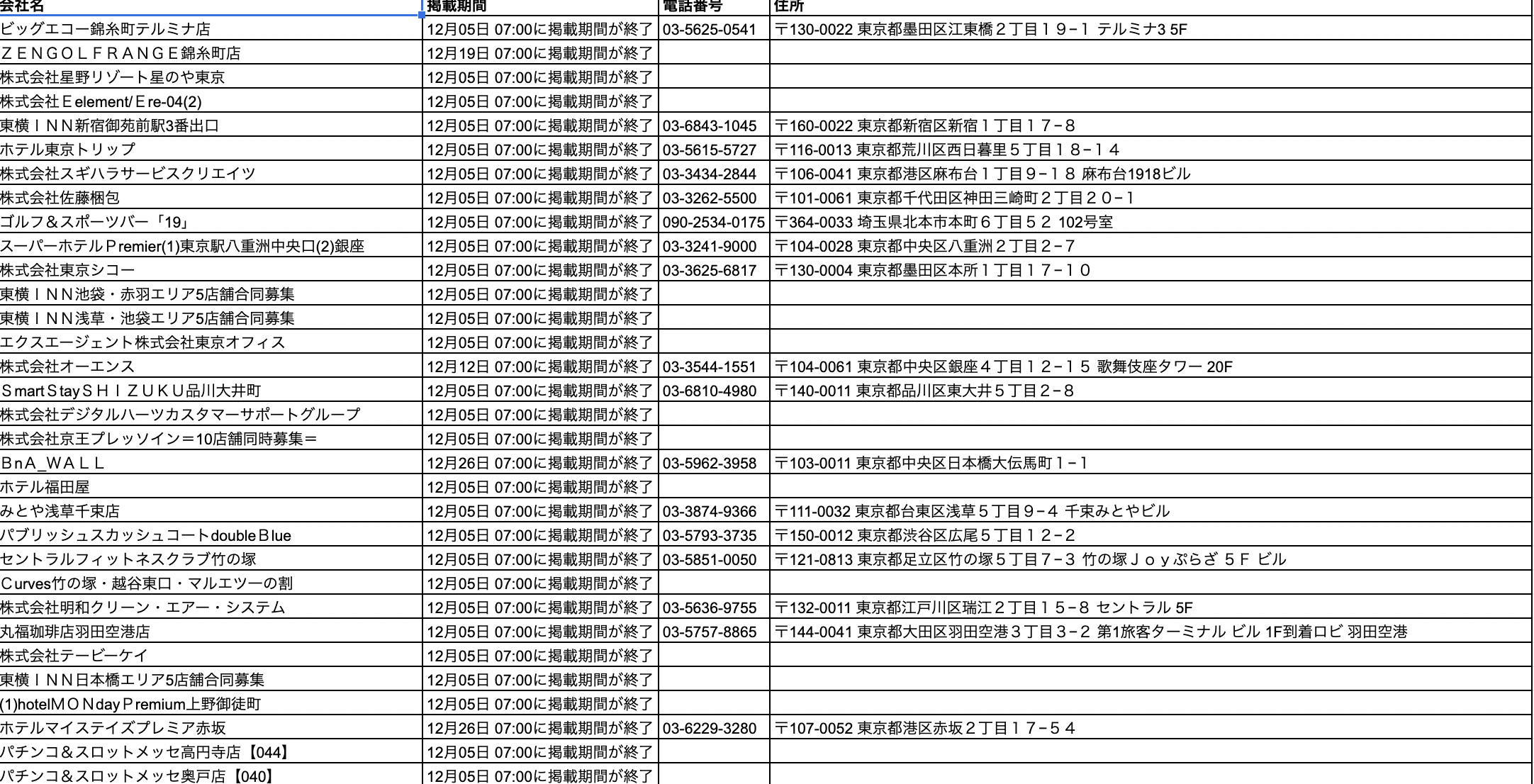
自分で試したこと
https://www.true-fly.com/entry/2022/08/01/080000
とか,APIって検索して色々なサイト見ましたが、どれもしっくりこなくて、、
恥ずかしいばかりです。。。
ご教授よろしくお願い致します
0 likes