コンテナの監視どうやんだみたいなECSの話があって、ちょっと試してみたんですが、実験台として提供いただいた環境がどうもFargate(のタスクスケジュール)だったわけで、まあどっちもやったことないからしらべるとこからやってみっか、ということでやってみた備忘録です。
コンテナの監視できるやつ軽く検索してみたりなど。色々あるんですね。
https://dev.classmethod.jp/cloud/zabbix-docker-monitoring/
https://thinkit.co.jp/article/9318
DatadogでECSはそのIntegration設定すると色々取れるっぽいと。
https://docs.datadoghq.com/integrations/amazon_ecs/
ECSはデーモンサービスとしてdd-agentを動かすことで色々取れるみたいなことで(k8sでいうとdaemonsetでホスト毎にPod一個動かすみたいな感じぽい)、以下のような(たぶんホストの)イベントが取れるのは結構いいかもと。(FagateのIntegrationだとデーモンサービス動かせないようでレプリカサービスしかだめそうでイベント取れなさそうでした)
Drain
Error
Fail
Out of memory
Pending
Reboot
Terminate
ECSはコンテナごとのリソース取れるぜという例かいてる記事も。
https://dev.classmethod.jp/cloud/aws/ecs-task-metric-by-datadog/
Fargateでタスクスケジュールだとちょっと取れるメトリクス違うようでした。
CloudWatchだとちょっと細かいの見れないみたいでした。(そもそもタスクスケジュールだとリソースが見れないのか出てなかった)
https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/cloudwatch-metrics.html
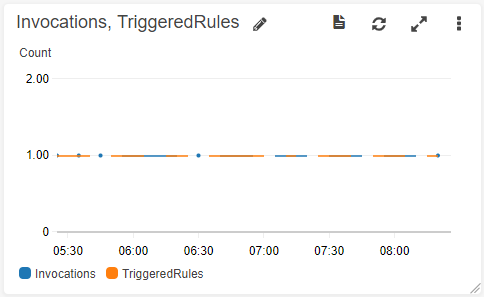
こんなんしかとれてなかった↑
コンテナの詳細状況をイベント監視するようなのはLambda連携な自作が要る話になるっぽい(めんどくさい
https://aws.amazon.com/jp/blogs/news/monitor-cluster-state-with-amazon-ecs-event-stream/
https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/ecs-agent-introspection.html
Fagateはホスト(EC2インスタンス)の存在が隠蔽されててログインできないので、Datadogエージェントの入れ方は、サイドカーコンテナとして既存のタスク定義にコンテナを追加する、というもの。コンソールからもjsonで定義もできそうでした。
https://www.datadoghq.com/blog/monitor-aws-fargate/
https://qiita.com/atsumjp/items/3a6efb982d40bb299057
dockerLabelsつけるにはタスク定義からなんとかしないとダメかもと言ってる似た記事が。↓
https://qiita.com/taishin/items/f1916af4582fafd93be3
で、サイドカーコンテナでdd-agent入れたスケジュールタスクだけだとコンテナランタイムにリストが出てくるだけなので、AWSインテグレーションしてみました。
https://docs.datadoghq.com/ja/integrations/aws/
クロスアカウントスイッチロール的な設定するとFargateのIntegrationボタンも出てたのでインストールをポチりました。
そうすると冒頭の画像のようなメトリクス取れるようになりまして(なんか表示されてるやつが全部とれるわけでもなかったですが)、ダッシュボードとかモニタの設定などができるようになりました。サンプルダッシュボードも色々追加されてたけどECSダッシュボードで値がでなかったりもしてたのでエクスプローラーからグラフ探してダッシュボード作りました↓。
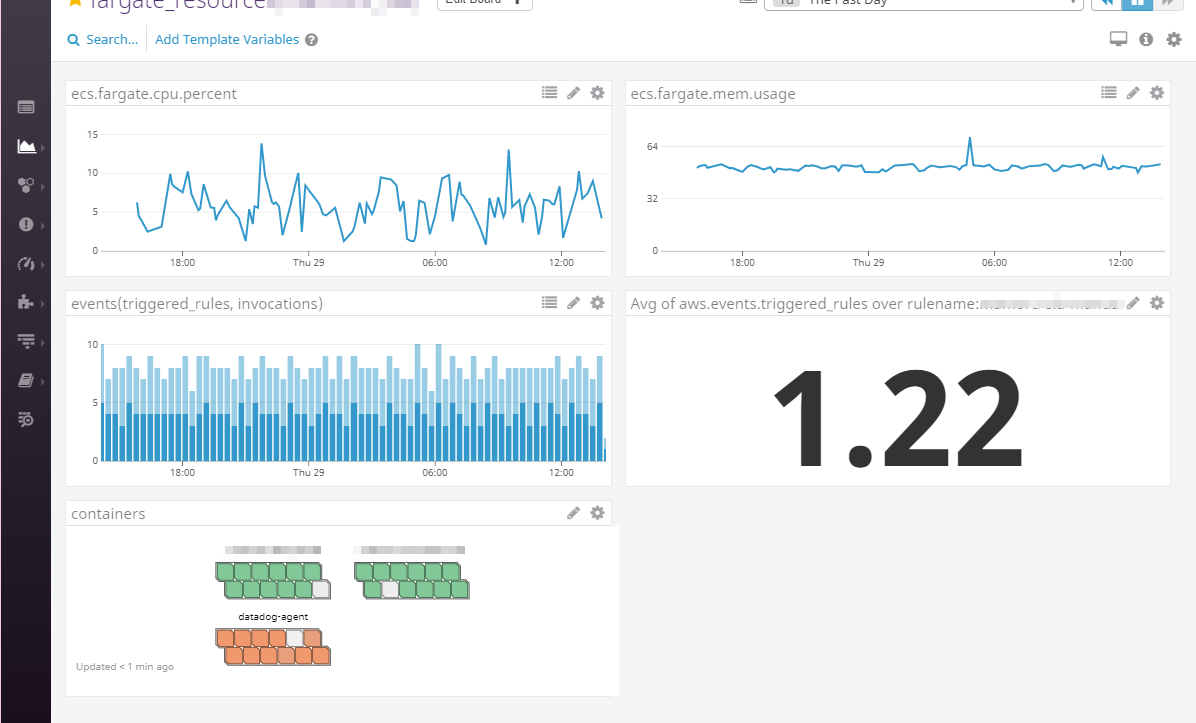
プロセスモニタリングはFagateタイプだとボリュームをroでマウントができないようで無理なように思われました。
https://docs.datadoghq.com/graphing/infrastructure/process/?tab=docker
モニタですが、Fagateでcron的に5分に一回動く感じのコンテナだったので、じゃー5分間トータル一回もトリガ動いてなかったらメールすっかという感じに。単純で小規模なスケジュールタスクのリソースのアラートを出す意味はあんまりなさそう(タスクに設定したリソースの閾値超えは気にする必要があるのかな)。。クラスタにオートでなくリソース追加する指標にしないといけないようだったらアレですが(ECSのインスタンスつかう場合など)。
{
"name": "[test]fagate rule been trrigerd below 1 total in 5minutes",
"type": "query alert",
"query": "sum(last_5m):sum:aws.events.triggered_rules{rulename:<rule-name>}.as_count() < 1",
"message": "<タスクの名前>のトリガが5分間で1を下回りました @通知先",
"tags": [],
"options": {
"notify_audit": false,
"locked": false,
"timeout_h": 0,
"silenced": {},
"include_tags": false,
"no_data_timeframe": null,
"require_full_window": true,
"new_host_delay": 300,
"notify_no_data": false,
"renotify_interval": 0,
"escalation_message": "",
"synthetics_check_id": null,
"thresholds": {
"critical": 1
}
}
}
お値段
https://www.datadoghq.com/pricing/
ECSとFagateで検索したら運用が結構違うっぽいのかなというのが多かったですかね。
そのた参考↓
http://tech.connehito.com/entry/2018/09/05/164805
https://dev.classmethod.jp/cloud/aws/amazon-ecs-entrance-1/
https://qiita.com/naomichi-y/items/d933867127f27524686a
https://qiita.com/CkReal/items/87bb8cc8b23cde715a47
https://qiita.com/tarumzu/items/2d7ed918f230fea957e8
ログを連携さすとまた別途有料だったりなど↓
https://docs.datadoghq.com/ja/guides/logs/
https://developers.cyberagent.co.jp/blog/archives/12565/
Linuxにdocker上がってるだけならdd-agentをホストにパッケージまたはコンテナ入れる方法でよくてコンテナでエージェント入れる方法だと[DockerIntegration設定]がデフォルト有効な感じ。(k8sだとdaemonsetで撒く感じ。)で、パッケージで入れるタイプならAnsibleのロールも公式のがgalaxyにあるのでそれを入れてvarsで設定する感じでした。
https://github.com/DataDog/ansible-datadog#configuring-a-check
構成管理上可能な方法かつどうしたいかでどちらにするかというところでしょうか。
Dockerの取れるメトリックなどは以下のようでした。
https://docs.datadoghq.com/integrations/docker_daemon/
アラート設定するのであればイベント監視がメインかなーと思いました。
2020/2追記です↓
aws.events.triggered_rulesだと動いたことしか確認できなくて動いたけど失敗したケースを捕捉するのには、aws.events.failed_invocationsもとるのがよさそうです。
FagateじゃなくてEC2インスタンスの場合のECSで、EC2インスタンスのIAMロールに、AmazonECS_FullAccessポリシーをアタッチしてfailed_invocationsが解決したという出来事があったので追記でした。