関連記事
設計
基本方針
基盤を設計する上で次のキーワードを意識した。
- Immutable infrastructure
- 一度構築したサーバは設定の変更を行わない
- Infrastructure as Code
- インフラの構成をコードで管理 (Terraformを採用)
- Serverless architecture
- 無駄にサーバを増やさない
アプリケーションレイヤに関して言えば、Twelve Factor Appが参考になる。コンテナ技術とも親和性が高い。
ECSとBeanstalk Multi-container Dockerの違い
以前に記事を書いたので、詳しくは下記参照。
Beanstalk Multi-container Dockerは、ECSを抽象化してRDSやログ管理の機能を合わせて提供してくれる。ボタンを何度か押すだけでRubyやNode.jsのアプリケーションが起動してしまう。
一見楽に見えるが、ブラックボックスな部分もありトラブルシュートでハマりやすいので、素直にECSを使った方が良いと思う。
ECSクラスタの作り方
ECSクラスタにEC2を登録する方法は2パターンある。
- クラスタ作成時にEC2を作成する (デフォルト)
- クラスタ作成時にEC2を作成せず、手動登録する
1は裏でCloudFormationが働き、クラスタへのEC2の登録からオートスケーリング周りの設定まで自動で行ってくれる。
2は空のクラスタを作成し、ECSコンテナインスタンスを手動登録する必要がある。
インフラをコード管理する上でも、ここでは2の手法をお勧めしたい。実はクラスタ作成後のオートスケール周りで設定の違いが出てくる。
下図は1の手法でクラスタを作成した場合のコンテナインスタンスの設定ページ。Scale ECS Instancesという項目が用意されている。インスタンス数を増減する場合はこのボタンから変更すれば良い。
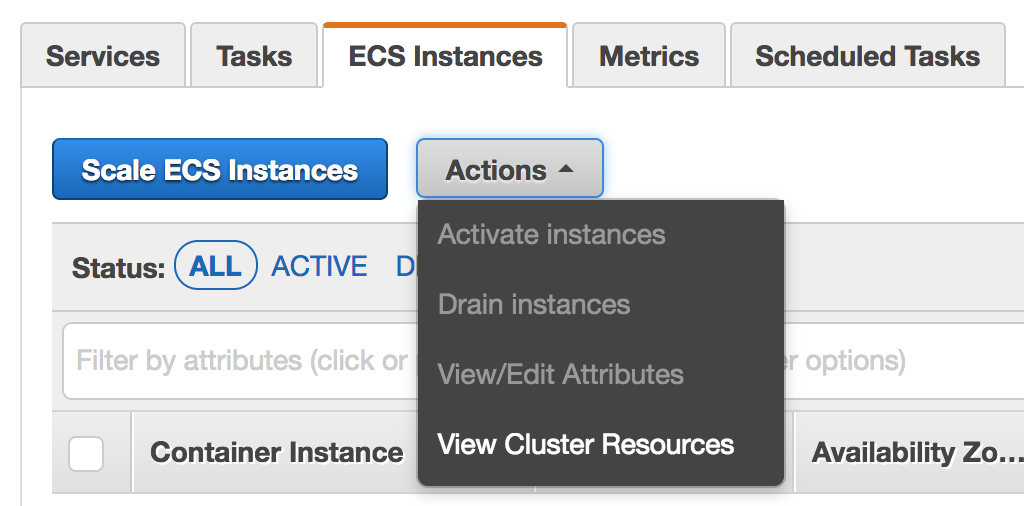
※後述するが、インスタンスを減らす場合はこのボタンを押す前にインスタンスの保護設定が必要。でないと稼働中のアプリケーションが落ちてしまうことがある。
続いてこちらが手動登録時のUI。Scale ECS Instancesボタンが無い。インスタンスの増減はEC2(Auto Scaling Groups)から設定が必要となる。
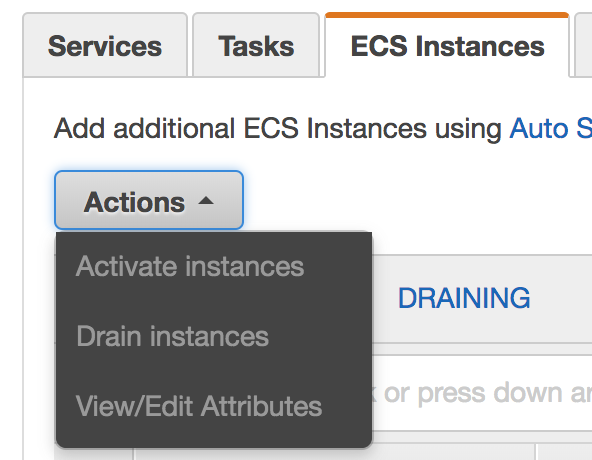
以前、1のパターンで作成したクラスタには次のような問題が起きた。
- クラスタが所属するサブネットを
Auto Scaling Groupsから変更後、Scale ECS Instancesからインスタンスを増やしても追加インスタンスは変更後のサブネットに所属しない。更にインスタンスを増やした時点でサブネットの設定が元に戻ってしまう。- 原因としてはCloudFormation側のテンプレートもサブネットの変更が必要だった
-
Auto Scaling Groupsでもインスタンス数を増減できるが、インスタンス数はScale ECS Instancesと同期していない-
Auto Scaling Groupsからインスタンス数の変更しない方が無難
-
2のパターンでコンテナインスタンスを登録するには、EC2作成時のイメージとしてAWS Marketplaceで公開されているAmazon ECS-Optimized Amazon Linux AMIを使うのが簡単である。
ALBを使う
ECSでロードバランサを利用する場合、CLB(Classic Load Balancer)かALB(Application Load Balancer)を選択できるが、特別な理由がない限りALBを利用するべきである。
ALBはURLベースのルーティングやHTTP/2のサポート、パフォーマンスの向上など様々なメリットが挙げられるが、ECSを使う上での最大のメリットは動的ポートマッピングがサポートされたことである。
動的ポートマッピングを使うことで、1ホストに対し複数のタスク(例えば複数のNginx)を稼働させることが可能となり、ECSクラスタのリソースを有効活用することが可能となる。
※1: ALBの監視方式はHTTP/HTTPSのため、TCPポートが必要となるミドルウェアは現状ALBを利用できない。
※2: 2017年9月、TCPによる高スループットを実現したNetwork Load Balancerが追加された。詳しくはクラスメソッドの記事辺りを参考に。HTTP/HTTPSはALB、TCPはNLBを利用することで、今後CLBを利用する機会は無くなってくるものと考えられる。
アプリケーションの設定は環境変数で管理
Twelve Factor Appでも述べられてるが、アプリケーションの設定は環境変数で管理している。
ECSのタスク定義パラメータとして環境変数を定義し、パスワードやシークレットキーなど、秘匿化が必要な値に関してはKMSで暗号化。CIによってECSにデプロイが走るタイミングで復号化を行っている。
ジョブスケジューリング
アプリケーションをコンテナで運用する際、スケジュールで定期実行したい処理はどのように実現するべきか。
いくつか方法はあるが、1つの手段としてLambdaのスケジュールイベントからタスクを叩く方法がある(Run task)。この方法でも問題はないが、最近(2017年6月)になってECSにScheduled Taskという機能が追加されており、Lambdaに置き換えて利用可能となった。Cron形式もサポートしているので非常に使いやすい。
Service Discoveryの運用
Service Discoveryを使うことで、サービス間の名前解決が容易になった。サービス登録時に一意の名前を付けておくことで、自動でRoute 53にコンテナを指すレコードが登録される(更にサービスのスケールに合わせてレコードを自動管理してくれる)。サービス呼び出し元は事前に付けた名前でエンドポイントを叩くことでコンテナにアクセスすることができるという仕組み。
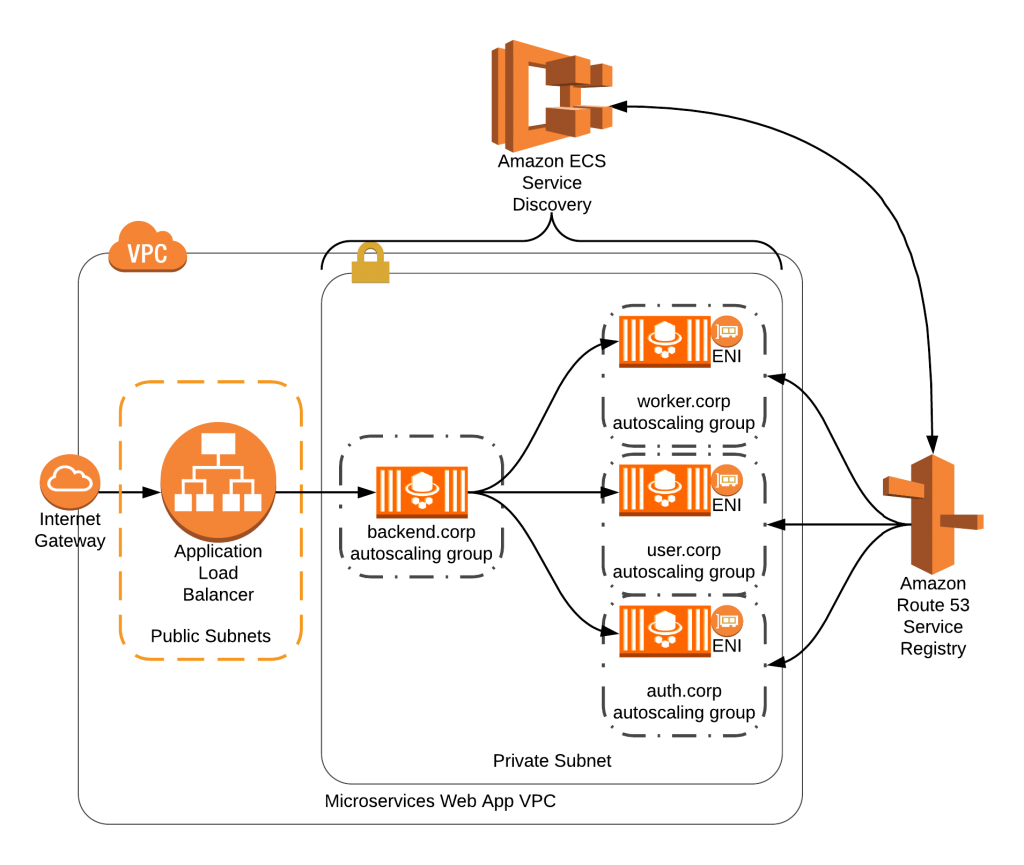
名前解決には二通りパターンがある点に注意したい。
Aレコードによる名前解決
タスクのネットワークモードがawsvpcの場合に利用可能。サービス名がfoo.localであれば、サービス呼び出し元ではfoo.localに対しリクエストを送ることで、Route 53経由でAレコードの名前解決が行われ、コンテナにアクセスすることができる。
コンテナごとにENIが割り振られるため、ECSの起動タイプとしてEC2を利用する場合はインスタンスが持てるENIの上限に注意が必要となる。
$ curl -I foo.local
HTTP/1.1 200 OK
...
尚、awsvpcモードでは動的ポートマッピングは利用できない。
SRVレコードによる名前解決
タスクのネットワークモードがbridge、あるいはhostの場合に有効(つまりFargateでは利用不可)。コンテナ間でネットワークが共有されるため、動的ポートマッピングが利用可能。ただしRoute 53にはSRVレコードが登録されるため、サービス呼び出し元は(ライブラリにも依存するが)、SRVレコードの名前解決を行った上でホスト名・ポート番号を取得し、その上でリクエストを送る必要がある。
# SRVレコードを取得し、ホスト名とポート番号を取得
$ host -t srv foo.local
foo.local has SRV record 1 1 33753 xxx.foo.local.
# リクエストの送信
$ curl -I xxx.foo.local:33753
HTTP/1.1 200 OK
...
運用
ECSで設定可能なパラメータ (起動タイプ: EC2)
ECSコンテナインスタンスにはコンテナエージェントが常駐しており、パラメータを変更することでECSの動作を調整できる。設定ファイルの場所は /etc/ecs/ecs.config。
変更する可能性が高いパラメータは下表の通り。他にも様々なパラメータが存在する。
| パラメータ名 | 説明 | デフォルト値 | 補足 |
|---|---|---|---|
| ECS_LOGLEVEL | ECSが出力するログのレベル | info | 障害調査時はdebug |
| ECS_AVAILABLE_LOGGING_DRIVERS | 有効なログドライバの一覧 | ["json-file","awslogs"] | 利用するログドライバに応じて追加が必要。Fluendを利用している場合は fluentd など |
| ECS_ENGINE_TASK_CLEANUP_WAIT_DURATION | タスクが停止してからコンテナが削除されるまでの待機時間 | 3h | |
| ECS_IMAGE_CLEANUP_INTERVAL | イメージ自動クリーンアップの間隔 | 30m | イメージサイズによってはディスクを圧迫するので、Dockerボリュームサイズから適正値を算出 |
| ECS_IMAGE_MINIMUM_CLEANUP_AGE | イメージ取得から自動クリーンアップが始まるまでの間隔 | 1h | |
| ECS_LOG_MAX_ROLL_COUNT | ECSログ (/var/log/ecs) の保管期間 | 24 | デフォルトは1日でログが消えるので調整を推奨 |
パラメータ変更後はエージェントの再起動が必要。
# Amazon Linux 2の場合
$ sudo systemctl stop ecs
$ sudo systemctl start ecs
# Amazon Linux 1の場合
$ sudo stop ecs
$ sudo start ecs
クラスタのスケールアウトを考慮し、ecs.configはUserDataに定義しておくと良い。
以下はfluentdを有効にしたUserDataの記述例。
# !/bin/bash
echo ECS_CLUSTER=sandbox >> /etc/ecs/ecs.config
echo ECS_AVAILABLE_LOGGING_DRIVERS=["fluentd\"] >> /etc/ecs/ecs.config
CPUリソースの制限 (起動タイプ: EC2)
現状ECSにおいてCPUリソースの制限を設定することはできない(docker runの--cpu-quotaオプションがサポートされていない)。
タスク定義パラメータcpuは、docker runの--cpu-sharesにマッピングされるもので、CPUの優先度を決定するオプションである。従って、あるコンテナがCPUを食いつぶしてしまうと、他のコンテナにも影響が出てしまう。
尚、Docker 1.13からは直感的にCPUリソースを制限ができる--cpusオプションが追加されている。是非ECSにも取り入れて欲しい。
ユーティリティ (起動タイプ: EC2)
実際に利用しているツールを紹介。
-
awslabs/ecs-logs-collector
ECSに関する各種ログを集約して出力 -
ExpediaDotCom/c3vis
ECSクラスタのリソース使用状況をビジュアライズ化

ルートボリューム・Dockerボリュームのディスク拡張 (起動タイプ: EC2)
ECSコンテナインスタンスは自動で2つのボリュームを作成する。1つはOS領域(/dev/xvda 8GB)、もう1つがDocker領域(/dev/xvdcz 22GB)である。
クラスタ作成時にDocker領域のサイズを変更することはできるが、OS領域は項目が見当たらず変更が出来ないように見える。
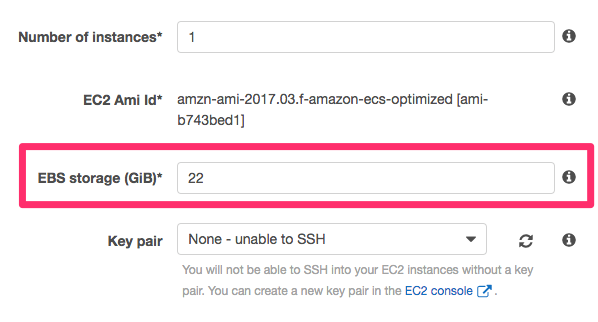
どこから設定するかというと、一度空のクラスタを作成し、EC2マネージメントコンソールからインスタンスを作成する必要がある。
また、既存ECSコンテナインスタンスのOS領域を拡張したい場合は、EC2マネージメントコンソールのEBS項目から変更可能。スケールアウトを考慮し、Auto scallingのLaunch Configurationも忘れずに更新しておく必要がある。
補足となるが、Docker領域はOS上にマウントされていないため、ECSコンテナインスタンス上からdf等のコマンドで領域を確認することはできない。
デプロイ
ECSのデプロイツールは色々ある。
- aws/amazon-ecs-cli
- openfresh/ecs-formation
- silinternational/ecs-deploy
- eagletmt/hako
- naomichi-y/ecs_deployer
- metaps/genova
※下2つは私が開発したツールです。genova は ecs_deployer をベースとしたデプロイ管理マネージャとなってます。
デプロイ方式
- コマンド実行形式のデプロイ
- GitHubのPushを検知した自動デプロイ
- Slackを利用したインタラクティブデプロイ
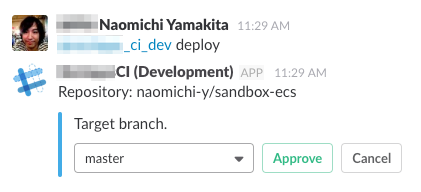
デプロイフロー
ECSへのデプロイフローは次の通り。
- リポジトリ・タスクの取得
- イメージのビルド
- タグにGitHubのコミットID、デプロイ日時を追加
- ECRへのプッシュ
- タスクの更新
- 不要なイメージの削除
- ECRは1リポジトリ辺り最大1,000のイメージを保管できる
- サービスの更新
- タスクの入れ替えを監視
- コンテナの異常終了も検知
- Slackにデプロイ完了通知を送信
デプロイパフォーマンスの改善
ALBを利用している場合、デプロイ時のコンテナの入れ替えに時間がかかることがある。
これはELBが登録解除プロセスを実行する前に300秒待機して、リクエストの完了を待つために起きている。アプリケーションの特性によってはこの時間を短くすることで、デプロイのパフォーマンスを改善することができる。

この設定の変更により、6〜7分かかっていたデプロイが2分程度に改善された。
ログの分類
ECSのログを分類してみた。
| ログの種別 | ログの場所 | 備考 | |
|---|---|---|---|
| サービス | AWS ECSコンソール | サービス一覧ページのEventタブ | APIで取得可能 (※1) |
| タスク | AWS ECSコンソール | クラスタページのTasksタブから"Desired task status"が"Stopped"のタスクを選択。タスク名のリンクから停止した理由を確認できる | APIで取得可能 |
| Docker daemon | ECSコンテナインスタンス | /var/log/docker | (※2) |
| ecs-init upstart ジョブ | ECSコンテナインスタンス | /var/log/ecs/ecs-init.log | (※2) |
| ECSコンテナエージェント | ECSコンテナインスタンス | /var/log/ecs/ecs-agent.log | (※2) |
| IAMロール | ECSコンテナインスタンス | /var/log/ecs/audit.log | タスクに認証情報のIAM使用時のみ |
| アプリケーション | コンテナ | /var/lib/docker/containers | ログドライバで変更可能 |
- ※1: イベントが発生したタイミングでログを取得することは出来ないため、Lambda等から定期的にイベントを取得する必要がある。
- ※2: ECSコンテナインスタンス上の各種ログは、CloudWatch Logs Agentを使うことでCloudWatch Logsに転送することが可能(現状の運用ではログをFluentdサーバに集約させているので、ECSコンテナインスタンスにはFluentdクライアントを構築している)。
サーバレス化
ECSから少し話が逸れるが、インフラの運用・保守コストを下げるため、Lambda(Node.js)による監視の自動化を進めている。各種バックアップからシステムの異常検知・通知までをすべてコード化することで、サービスのスケールアウトに耐えうる構成が容易に構築できるようになる。
ECS+Lambdaを使ったコンテナ運用に切り替えてから、EC2の構築が必要となるのは踏み台くらいだった。
インスタンスのドレイニング (起動タイプ: EC2)
クラスタから特定のインスタンスを外したい場合は、インスタンスのドレイニングが必要となる。ドレイニング状態となったインスタンスには新しいタスクが配置されなくなり、別のインスタンスにタスクが配置される。
ドレイニングを行わずインスタンスを削除した場合、インスタンス上のコンテナが削除され、アプリケーションへの接続が遮断される点に注意したい。
インスタンスのドレイニングはクラスタページのECS Instancesタブから設定できる。
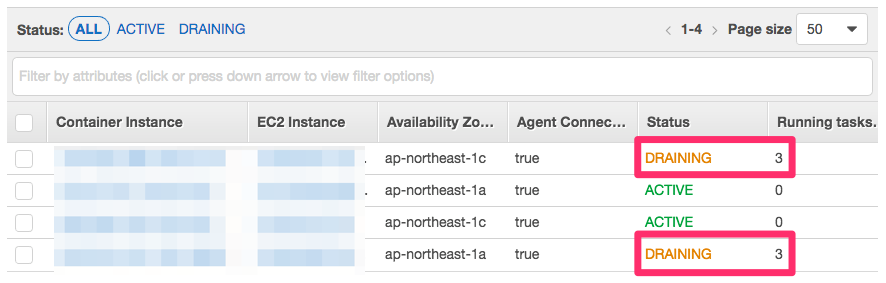
ドレイニングが終わると、対象インスタンス上のタスク数は 0 となる。
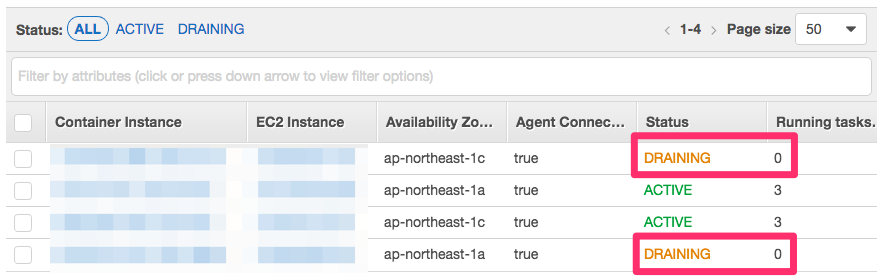
尚、インスタンスをドレイニングするに辺り、クラスタ上で利用できるリソースは減るため、タスクに割り当てるCPUやメモリの設定値、タスク数などを事前に確認しておいたほうが良い。インスタンスの削除については クラスタにアタッチされているインスタンスを削除する (起動タイプ: EC2) を参照。
ドレイニングの自動化についてはAWSの記事が参考となる。
インスタンスのスケールアウト (起動タイプ: EC2)
クラスタの作成方法によって作業手順が変わる。クラスタ作成時に Create an empty cluster にチェックを付けた場合は空のクラスタのみ作成されるが、チェックを外した場合はCloudFormationにより、クラスタと同時にEC2インスタンスやセキュリティグループなどが紐づく。

- 空のクラスタを作成した場合
- EC2コンソールの
Auto Scaling Groupsからクラスタに紐づく設定を開き、GeneralタブからEditを選択
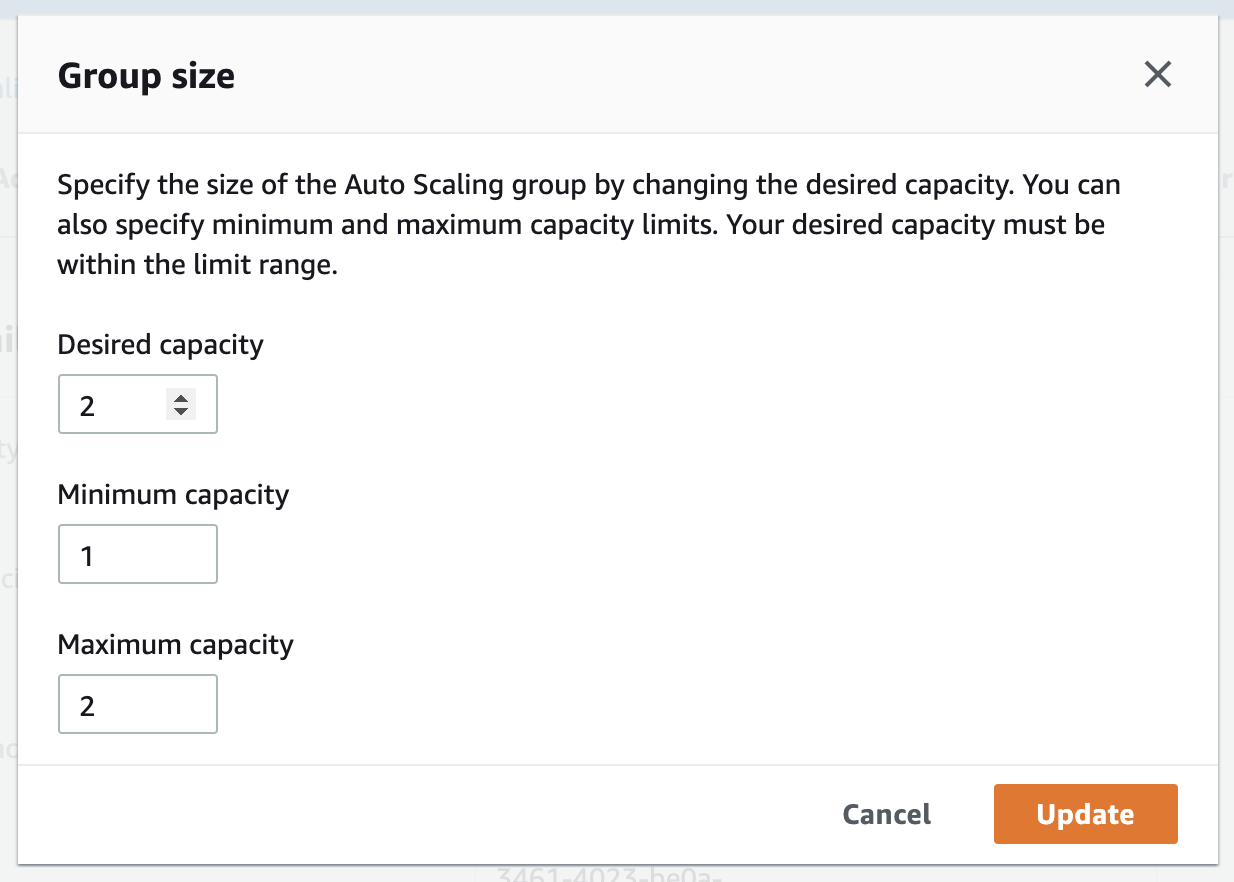
-
Desired capacityにスケールするインスタンス数、Maximum capacityに並列でスケールするインスタンス数 (最大値はDesired capacity) を指定してUpdateを実行
- EC2コンソールの
- クラスタと同時にインスタンスを作成した場合
- ECSコンソールの
ECS InstancesタブにScale ECS Instancesというボタンがある
- ECSコンソールの
 * ボタンを押すと `Desired number of instances` という項目があるので、スケールアウト後の数を指定して `Scale` を実行
* ボタンを押すと `Desired number of instances` という項目があるので、スケールアウト後の数を指定して `Scale` を実行
数分待つとインスタンスが起動するので、ECSのコンソールを開き、対象クラスタの ECS Instances にインスタンスが追加されていることを確認する。
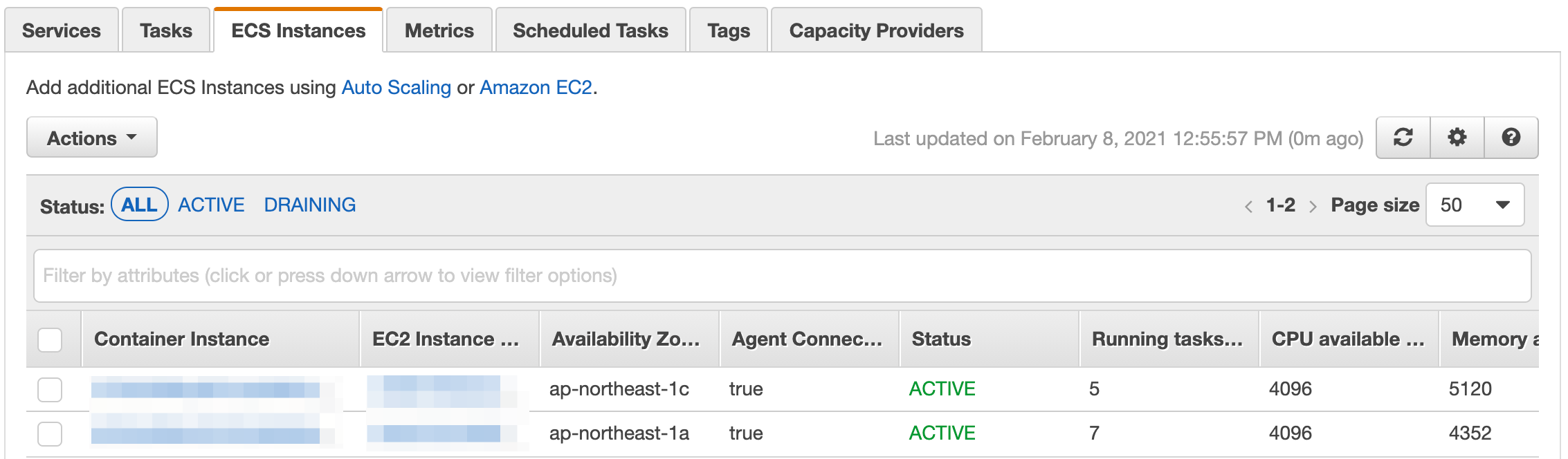
尚、インスタンスを起動しただけではサービスはスケールアウトしないので、別途サービスのタスク数を調整する必要がある。
インスタンスのスケールイン (起動タイプ: EC2)
インスタンスを減らす場合、初めに削除対象インスタンス上で稼働しているサービスやスケジュールタスクを別のインスタンスに退避させる必要がある (詳しくは インスタンスのドレイニング を参照)。
インスタンスのスケールイン自体はコンソールから変更 (後述) となるが、スケールインの対象となるインスタンスは利用者側では決められない (ドレイニングしたインスタンスが削除対象となる訳ではない) ので、予め削除保護しておきたいインスタンスをオートスケーリンググループに登録しておく必要がある。
- EC2コンソールの
Auto Scaling Groupsから対象クラスタを選択。Instance Managementタブを開く - スケールインから保護したいインスタンスを選択して
ActionsからSet scale-in protectionを選択
削除保護が有効になると、対象インスタンスの Protected from が Scale in の表示に切り替わる。
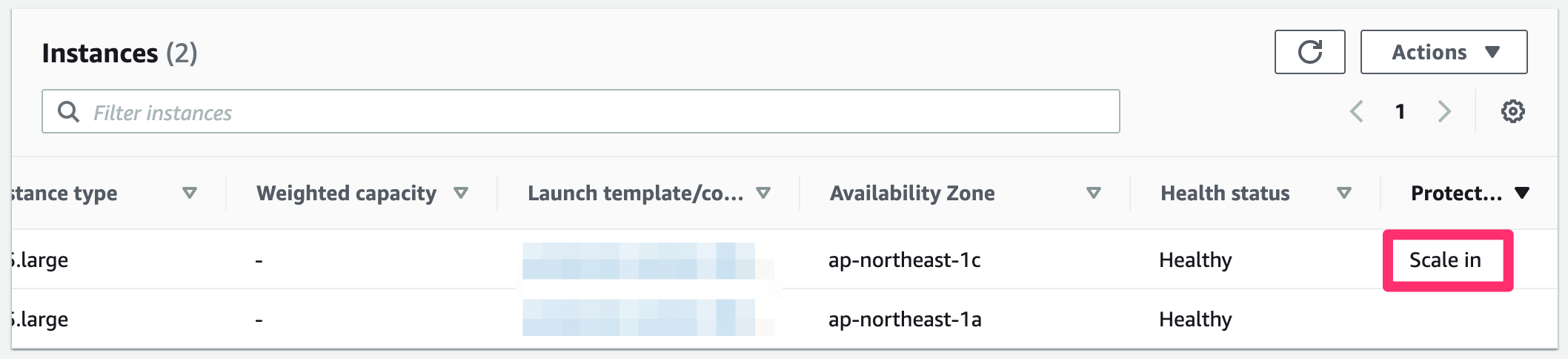
続いてインスタンスのスケールインを行う。
- 空のクラスタを作成した場合
- EC2の
Auto Scaling Groupsから対象クラスタの設定を開き、DetailsからEditを選択。Desired capacityとMaximum capacityにスケールイン後の数を指定してUpdateを押す
- EC2の
- クラスタと同時にインスタンスを作成した場合
- ECSコンソールの
ECS InstancesタブにScale ECS Instancesというボタンがある
* ボタンを押すと `Desired number of instances` という項目があるので、スケールイン後の数を指定して `Scale` を実行
- ECSコンソールの
トラブルシュート
コンテナの起動が失敗し続け、ディスクフルが発生する
ECSはタスクの起動が失敗すると数十秒間隔でリトライを実施する。この時コンテナがDockerボリュームを使用していると、ECSコンテナエージェントによるクリーンアップが間に合わず、ディスクフルが発生することがあった(ECSコンテナインスタンスの/var/lib/docker/volumesにボリュームが残り続けてしまう)。
この問題を回避するには、ECSコンテナインスタンスのOS領域(※1)を拡張するか、コンテナクリーンアップの間隔を調整する必要がある。
コンテナを削除する間隔はECS_ENGINE_TASK_CLEANUP_WAIT_DURATIONパラメータを使うと良い。
※1: DockerボリュームはDocker領域ではなく、OS領域に保存される。OS領域の容量はデフォルトで8GBなので注意が必要。
また、どういう訳か稀に古いボリュームが削除されず残り続けてしまうことがあった。そんな時は次のコマンドでボリュームを削除しておく。
# コンテナから参照されていないボリュームの確認
docker volume ls -f dangling=true
# 未参照ボリュームの削除
docker volume rm $(docker volume ls -q -f dangling=true)
古いコンテナが削除されない
ecs.configにECS_ENGINE_TASK_CLEANUP_WAIT_DURATIONを指定を指定しているにも関わらず、古いコンテナが削除されない場合がある。
$ docker ps -a
xxx xxx.dkr.ecr.ap-northeast-1.amazonaws.com/xxx "bundle exec rails..."11 days ago Dead xxx
削除されていないコンテナのステータスを見るとDeadとなっていた。
サポートに問い合わせたところ、DeadステータスのコンテナはECS_ENGINE_TASK_CLEANUP_WAIT_DURATIONを過ぎてもクリーンアップされない仕様らしい。
従って現段階(2019年1月現在)でDeadコンテナを削除するにはホスト側でCronを回すしかない。
$ docker rm $(docker ps --all -q -f status=dead)
または
$ docker rm -f $(docker ps --all -q -f status=dead)
改善して欲しい。。
ECSがELBに紐付くタイミング
DockerfileのCMDでスクリプトを実行するケースは多々あると思うが、コンテナはCMDが実行された直後にELBに紐付いてしまうので注意が必要となる。
bundle exec rake assets:precompile
このようなコマンドをスクリプトで実行する場合、アセットがコンパイル中であろうがお構いなしにELBに紐付いてしまう。
時間のかかる処理は素直にDockerfile内で実行した方が良い。
ecs-agent.logに"WARN messages when no Tasks are scheduled"という警告が出力される
ECSコンテナインスタンスの/var/log/ecs-agent.logにWARN messages when no Tasks are scheduledという警告が頻出していた。Issueにも症例が報告されている。
この問題は既知の不具合のようで、ECSのAMIにamzn-ami-2017.03.d-amazon-ecs-optimized - ami-e4657283を使うことで解決した(AMI amzn-ami-2016.09.f-amazon-ecs-optimized - ami-c393d6a4で問題が起こることを確認済み)。
コンテナ起動時にディスク容量不足のエラーが出てコンテナごと落ちる
CannotPullContainerError: failed to register layer: devmapper: Thin Pool has 2862 free data blocks which is less than minimum required 4449 free data blocks. Create more free space in thin pool or use dm.min_free_space option to change behavior
docker info でDockerの情報を確認する。
$ docker info
Containers: 5
Running: 5
Paused: 0
Stopped: 0
Images: 6
Server Version: 17.12.0-ce
Storage Driver: devicemapper
Pool Name: docker-docker--pool
Pool Blocksize: 524.3kB
Base Device Size: 10.74GB
Backing Filesystem: ext4
Udev Sync Supported: true
Data Space Used: 21.84GB
Data Space Total: 23.33GB
Data Space Available: 1.491GB
...
ECSはデフォルトで22GBのDockerイメージ格納領域を作るが、Data Space Available の値を見ると 1.49GB しかない。
次のコマンドを実行して容量を増やす。
# 実行中でないコンテナを削除
$ docker rm $(docker ps -aq)
# 未使用のイメージを削除
$ docker rmi $(docker images -q)
# 確認
$ docker info
Containers: 5
Running: 5
Paused: 0
Stopped: 0
Images: 3
Server Version: 17.12.0-ce
Storage Driver: devicemapper
Pool Name: docker-docker--pool
Pool Blocksize: 524.3kB
Base Device Size: 10.74GB
Backing Filesystem: ext4
Udev Sync Supported: true
Data Space Used: 20.54GB
Data Space Total: 23.33GB
Data Space Available: 2.79GB
1.49GB→2.79GB と少し増えた。
続けてコンテナ内で使用されていないデータブロックを削除してみる。
$ sudo sh -c "docker ps -q | xargs docker inspect --format='{{ .State.Pid }}' | xargs -IZ fstrim /proc/Z/root/"
$ docker info
Containers: 5
Running: 5
Paused: 0
Stopped: 0
Images: 3
Server Version: 17.12.0-ce
Storage Driver: devicemapper
Pool Name: docker-docker--pool
Pool Blocksize: 524.3kB
Base Device Size: 10.74GB
Backing Filesystem: ext4
Udev Sync Supported: true
Data Space Used: 10.43GB
Data Space Total: 23.33GB
Data Space Available: 12.9GB
2.79GB→12.9GB まで増えた。
根本解決としては、Dockerに割り当てるストレージ容量を増やすか、古いイメージの削除間隔を短くすれば良さそう。
Scheduled task (CloudWarch Events)が多重実行される
Scheduled taskの実行タスク数を1にしてるのに、タスクが複数回実行される場合がある。これ仕様です。マニュアルに書いてます。
1 つのイベントに応じてルールが複数回トリガーされました。CloudWatch イベント で、ルールのトリガーまたはターゲットへのイベントの提供で何が保証されますか。
まれに、単一のイベントまたはスケジュールされた期間に対して同じルールを複数回トリガーしたり、特定のトリガーされたルールに対して同じターゲットを複数回起動したりする場合があります。
現時点(2019年5月)ではアプリケーション側で排他制御するしかなさそうです。マニュアルそこまで読まないし絶対ハマると思う。
ちなみにサポートからの回答では、冗長性や可用性を担保する関係で、LambdaやSQSもまれに複数回実行される可能性があるとのことです。ご注意ください。
ecs-agentが落ちる (起動タイプ: EC2)
それまで安定稼働していたサービスが突然落ちることがありました。よくよく調べてみるとクラスタにアタッチしているインスタンスが落ちて、コンテナエージェントの状態が false に変わっていました。

ホストインスタンスに接続してDockerの状態を見ようとするも、起動が失敗している様子。
[root@development-web developer]# docker ps
Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
[root@development-web developer]# docker -v
Docker version 19.03.6-ce, build 369ce74
状況によっては Out of memory のエラーが出ることもありました。
$ docker -v
fatal error: runtime: out of memory
この問題は弊社プロダクトで同時期に一斉に起こり悩まされたのですが、原因はDockerのバージョンを19に上げると起きることが再現できました。movyプロジェクトで報告されているメモリが多く消費される問題に起因してるようです。
- dockerd: high memory usage
弊社ではホストインスタンスを立ち上げる際に
- Terraform経由で常に最新かつ安定版のAMIを取得していた
- cloud-init経由でパッケージの最新版へ更新を行っていた (
repo_upgrade: all)
この2つを行っていたがために、Dockerが最新版に更新されサービスの動作が不安定に陥っていました。
参考までにAMIとDockerの組み合わせで動作が安定した環境は下表の通りです。

尚、検証したOSは Amazon Linux 1 ですが、Amazon Linux 2 であれば ami-032b1a02e6610214e が最新の安定したAMIとなります (2020年7月現在)。
この問題が解消されるまでの間は、AMIを固定にし、cloud-initを利用している場合は repo_upgrade の設定を none (Amazon Linux 2の場合は security でも問題なし) に設定しておいたほうが良さそうです。
コンテナでOOMが発生、あるいはEC2の自動停止が発生する (起動タイプ: EC2)
前述の問題に類似する問題ですが、コンテナが正常に起動せず、以下のようなエラーが発生することがありました。
OutOfMemoryError: Container killed due to memory usageservice *** was unable to place a task because no container instance met all of its requirements. The closest matching container-instance *** has insufficient memory available. For more information, see the Troubleshooting section.Host EC2 (instance i-***) terminated.
原因はコンテナ実行時のメモリ使用率がタスクに割り当てられている上限値を超えている可能性があります。
あるプロジェクトではRailsコンテナのメモリ平均使用率が170MB、タスク定義におけるハード制限が386MB指定されていましたが、コンテナの動作が不安定になることがりました。
その後、コンテナ起動直後からプロセスの状態を確認してみると、ENTRYPOINTで asset:precompile が実行されていることが確認でき、瞬間的に400MB以上のメモリが使用され、コンテナが落ちていることが分かりました。
この問題に関しては一次対策としてソフト制限を256MB、ハード制限を768MB割り当てることで解消しています。
恒久対応として、アセットプリコンパイルはビルド時に行う形が良さそうです。