概要
ECS運用において、Dockerコンテナはデプロイの度に破棄・生成が繰り返されるため、アプリケーションが生成する各種ログはコンテナ内に保管しておくことができない。
すべてのログはイベントストリームとして扱い、外部ストレージに送る必要がある。
本ページではECSを運用していく中で発生したログの取り扱いに関する遍歴をまとめていく。
※このページは、ECS運用のノウハウからログの取り扱いに関する項目を抜き出して再編集したものです。
Phase 1: CloudWatch Logsの導入
コンテナ運用を考慮したアプリケーション設計では、The Twelve Factor Appが参考となる。
この中のLogsセクションではログの取り扱いで以下の記述がある。
A twelve-factor* app never concerns itself with routing or storage of its output stream.
It should not attempt to write to or manage logfiles. Instead, each running process writes its event stream, unbuffered, to stdout.
During local development, the developer will view this stream in the foreground of their terminal to observe the app’s behavior.
全てのログはファイルへ書き込むのではなく、標準出力(STDOUT)に書き出す必要がある。
ECS運用当初はノウハウもなく右も左も分からない状況だったため、ログの永続化についてはあまり深く考えずAWSが標準で提供するCloudWatch Logs(awslogsドライバ)を利用することにした。
CloudWatchにログを転送してしまえば、後はElasticsearchと連携し、ログの可視化まで比較的容易だったからである。

しかし、実際に運用を始めてみるといくつかの問題が起きた。
- アプリケーションが生成する例外(スタックトレース)が行単位でストリームに流れるため、ログを追いづらい
- ElasticsearchでMultiline codec pluginプラグインの利用を検討したが、Elasticsearch Service自体がプラグインのインストールをサポートしていなかったので断念
- EC2上にElasticsearchを構築することも考えたが、バックエンドサービスへの依存が高く、将来的にログドライバを変更する際の障壁と考え、導入を見送った
- 特定のキーワード・頻度に一致したエラーを検知することが難しい
- CloudWatchのアラームだけでは条件一致の判定が出来ない
Phase 2: ログクラスタの構築 (2017年2月〜)
前述の運用は数ヶ月で廃止し、代案として導入したのがFluentd経由でログをElasticsearchに流す方法である。
アプリケーションが将来的にスケールすることを考慮し、ログ用のクラスタを別途構築している。
この変更でFluentdがログ集約基盤となり、不正なログの検知や将来的なバックエンドサービスの切り替えが容易な構成となった。
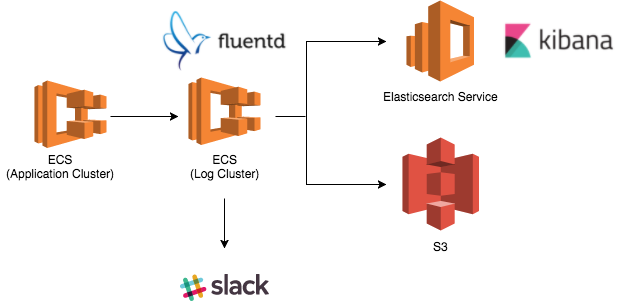
Fluentdの役割
アプリケーション例外はSentryで追跡しており、Sentryが検知できないエラー(ミドルウェアが標準出力や標準エラーに送信するログ)やLoggerが生成するメッセージをFluentdに送信。Fluentdはログをリアルタイムに監視し、一定期間内に閾値を超えた回数発生したメッセージをSlackに通知。すべてのログはS3とElasticsearchに並列で書き込みを行っている。
ログの欠損問題
しばらく運用させていると、一部のログがElasticsearch・S3に書き込まれていないことに気付いた。
ログクラスタにはロードバランサとしてCLBを利用していたが、どうもCLBがアイドルタイムアウト直後の数リクエストでログが消失している。
試しにCLBを外してアプリケーションからログクラスタにアクセスすると問題は起きなかった。

ログクラスタのECSコンテナインスタンスを調査したところ、/var/log/dockerに次のようなログが残されていた。
time="2017-04-24T11:23:55.152541218Z" level=error msg="Failed to log msg \"...\" for logger fluentd: write tcp *.*.*.*:36756->*.*.*.*:24224: write: broken pipe"
3) time="2017-04-24T11:23:57.172518425Z" level=error msg="Failed to log msg \"...\" for logger fluentd: fluent#send: can't send logs, client is reconnecting"
同様の問題をIssueで見つけたが、ECSログドライバはKeepAliveの仕組みが無いため、アイドルタイムアウトの期間中にログの送信が無いとELBがコネクションを切断する仕様らしい。AWSサポートからも同様の回答を得られた。
Phase 3: Weighted Routing (2017年5月〜)
CLBの代替策として、ログクラスタにはロードバランサを使わず、Route53のWeighted Routingでリクエストを分散することにした。
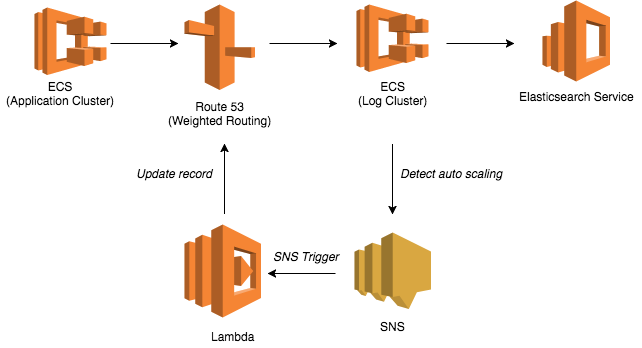
仕組みとしては、ECS(EC2)の全プライベートIPをRoute 53のドメインに紐づけておくイメージである。
ただし、この方式ではログクラスタのスケールイン・アウトに合わせてRoute 53のレコードを更新する必要がある。
ここではオートスケールの更新をSNS経由でLambdaに検知させ、適宜レコードを更新する仕組みを取った。
Phase 4: Service Discoveryの道入 (2018年10月〜)
2018年9月にはService Discoveryが東京リージョンにローンチされた。
ECSコンテナ間の通信をプライベートDNS(Route 53)で解決できる仕組みのため、インターナルなECSクラスタにELBを利用している場合はコスト削減にも繋がる。
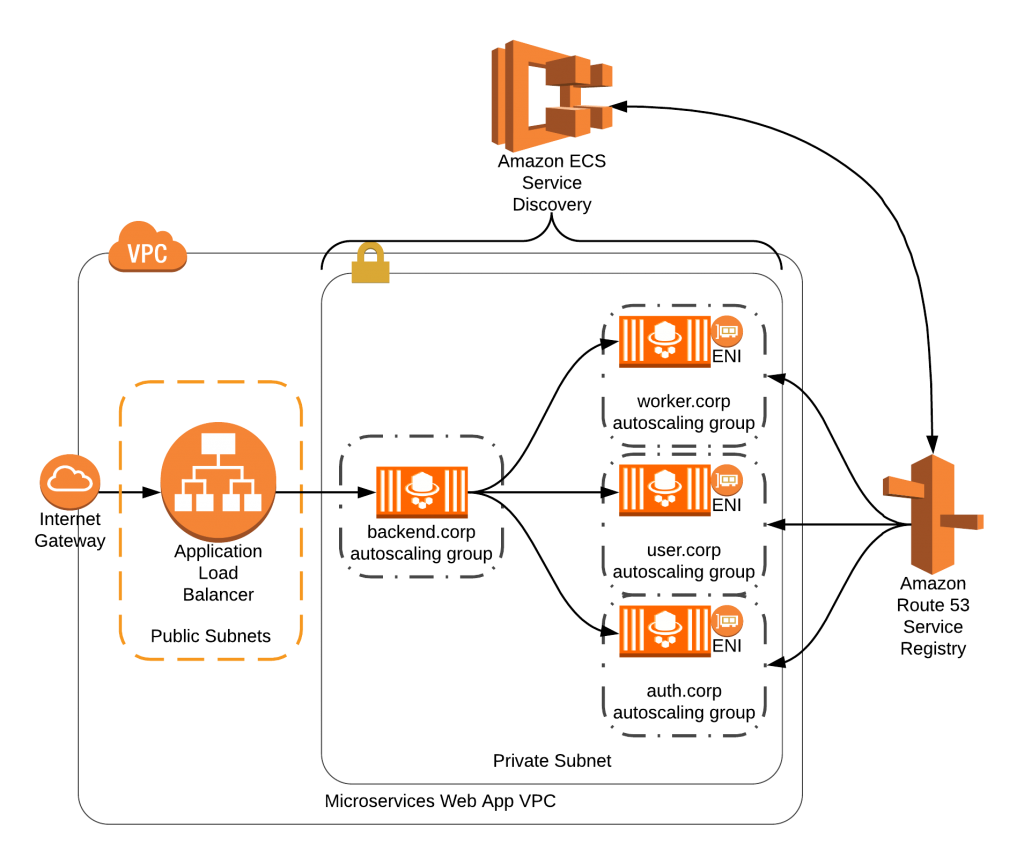
Service Discoveryを利用する場合、コンテナ自体のヘルスチェックをタスク定義に追加する必要がある。
Fluentdが起動しているかの確認は、次のようなコードとなる。
CMD-SHELL,nc -zv localhost 24224 > /dev/null 2>&1 || exit 1
更にコンテナごとにENIが割り振られるため、タスクのネットワークモードをawsvpcに変更する。
例えば稼働タスク数を2にすると、Route 53上でも2つのAレコードが生成されることを確認できた。稼働数に合わせてAレコードが自動で増減する。

ECS(Type: EC2)のPrivate IPsは3IP表示される(一番左はECSコンテナ自体のIP)。

尚、インスタンスタイプごとにENIの上限が決まっており、例えばt2.mediumであれば3つまで(コンテナに割り当てられるのは2つ)となる。
t2.medium 1台の構成で3つ以上のタスクを指定すると、以下のようなエラーが発生することを確認できた。
service log was unable to place a task because no container instance met all of its requirements.
The closest matching container-instance XXX encountered error "RESOURCE:ENI".
For more information, see the Troubleshooting section.
※1: Service Discoveryの導入方法はクラスメソッドの記事が分かりやすい
※2: インフラの構築にはTerraformを使っていたので、プライベートゾーンはaws_route53_zoneで作れば良いと思いきや、ECSコンソール上でDNSが見つからないと言われた。どうやらaws_service_discovery_private_dns_namespaceで作成する必要があった
※3: 試しで作ったゾーンを削除しようとしたところ、サービスディスカバリに紐付いてるから削除できないとエラーが出た (クラスタからはサービスを削除済み)。ゾーンの削除はdelete-namespace APIを使う必要があるみたい