著者: 伊藤 雅博, 株式会社日立製作所
はじめに
本稿ではApache Kafkaを構成するコンポーネントの1つである、Kafka Connectの概要とユースケースを紹介します。Kafka Connectのより詳細なアーキテクチャや具体的な構築手順については、次回以降の記事で紹介します。
記事一覧:
- Kafka Connectの概要とユースケース(本稿)
- Kafka Connectのアーキテクチャとチューニングポイント
- Kafka Connectを分散モードで動かしてみた
Kafka Connectの位置づけ
Apache Kafkaは以下のようなコンポーネントで構成されています。メッセージキューを構成するKafka Brokerを中心に、メッセージを格納・参照するクライアントとなるコンポーネント群があります。
本稿ではKafkaのコンポーネントの1つであるKafka Connectについて解説します。
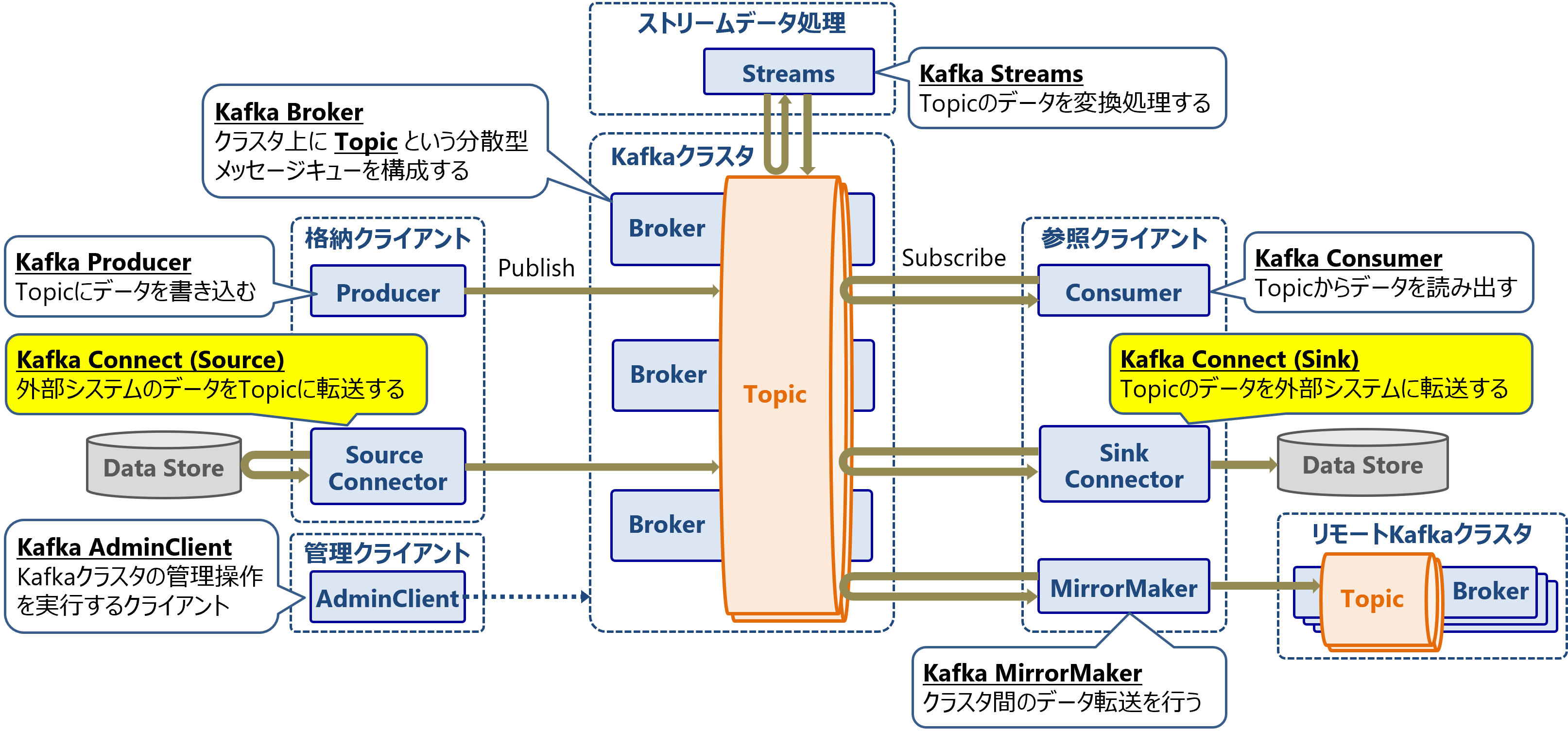
なお、Apache Kafkaの概要については以下をご参照ください。
Kafka Connectの概要
Kafka Connectとは、 Kafkaと外部のシステムとの間でデータを連携するためのフレームワークです。外部のシステムとは、例えばソフトウェアやデバイス、データベース、クラウドサービスなどです。Kafka Connectを活用することで、Kafkaを介して様々なシステム間でデータを転送できます。
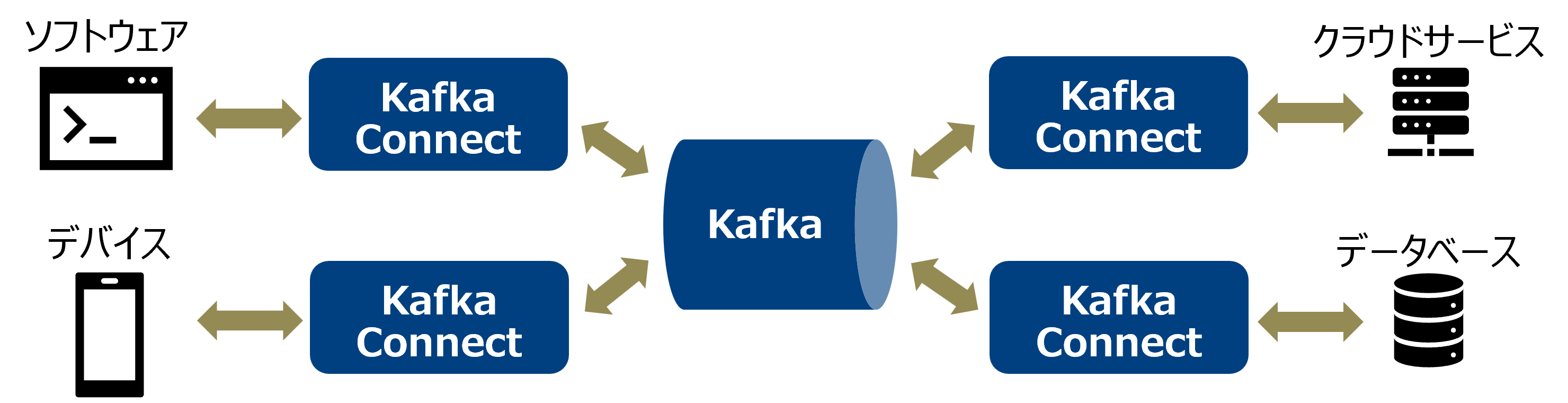
Kafka Connectにおけるデータ転送は「コネクタ」が実行します。コネクタには、外部システムのデータをTopicに転送するSourceコネクタと、Topicのデータを外部システムに転送するSinkコネクタの2種類が存在します。コネクタは常駐プロセスとして動作し、データを継続的に転送し続けます。

Kafka Connectは、このコネクタを実装するためのJavaライブラリと、実装したコネクタを実行・管理するための基盤を提供します。
例えばSinkコネクタを実装する場合は、KafkaのTopicからメッセージを読み出して、任意の変換処理を行い、外部のデータベースに格納するような処理を、Kafka Connectのライブラリを使用して実装します。
なお、そのまま利用可能な実装済みのサードパーティ製コネクタが100種類以上存在するため、基本的にコネクタを自作する必要はありません。主要なサードパーティ製コネクタについては後ほど説明します。
Kafka Connectの動作モードと実行基盤
Kafka Connectにはスタンドアロンモードと分散モードの2種類の動作モードがあります。
| 観点 | スタンドアロンモード | 分散モード |
|---|---|---|
| 動作環境 | 1台のサーバで動作 | 複数台のサーバで動作可能 |
| 処理性能 | 低い | 高い(スケールアウトで並列分散処理) |
| 障害耐性 | なし | あり(自動フォールトトレランス) |
| 実行管理 | CLIで実施 | REST APIで実行管理 |
| 推奨用途 | ローカル環境での開発・テスト | 本番環境 |
1台のサーバで実行する場合でも、本番環境では分散モードの構成が推奨となります。
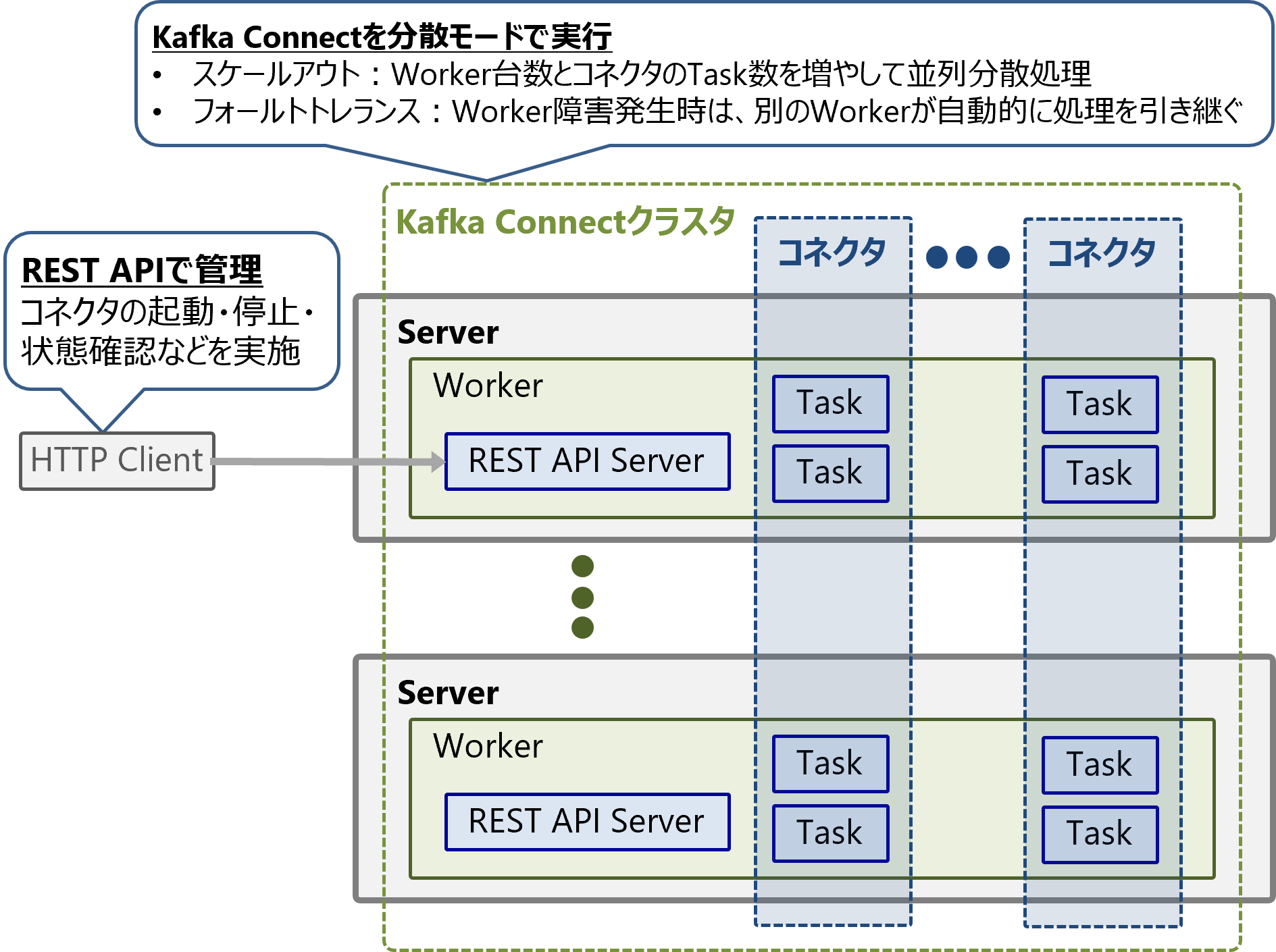
分散モードでは、複数台のサーバ上のWorkerインスタンスでグループ(クラスタ)を組み、その上でコネクタを実行・管理します。
分散モードで実行するコネクタは、複数のTaskによる並列分散処理が可能です。また、処理中にサーバ障害が発生しても、自動的に別のサーバにあるWorkerが処理(Task)を引継ぎ、稼働を継続します。
コネクタの起動、停止、状態確認などはREST API経由で実行します。
Kafka Connectのユースケース
変更データキャプチャ(CDC)
Kafka Coonectの活用例として、データベース間でデータを同期する変更データキャプチャ(Change Data Capture, CDC)があります。CDCでは、あるデータベースにおけるデータ更新(挿入・更新・削除)を、別のデータベースにほぼリアルタイムで反映します。
CDCは以下のようなケースで利用されます。
RDBMSからデータレイク・データウェアハウスへのオフロード
基幹系システムで稼働しているRDBMSのデータを分析したいとします。しかし分析クエリは大量のデータを読み出すため、基幹系システムに大きな負荷がかかります。
そのため一般的には、基幹系システムのRDBMSのデータを、情報系システムのデータレイクやデータウェアハウスにコピーしてから分析します。このデータコピーにCDCを活用します。
CDCではデータ更新がほぼリアルタイムで反映されるため、常に最新の情報をもとにしたデータ分析が可能となります。

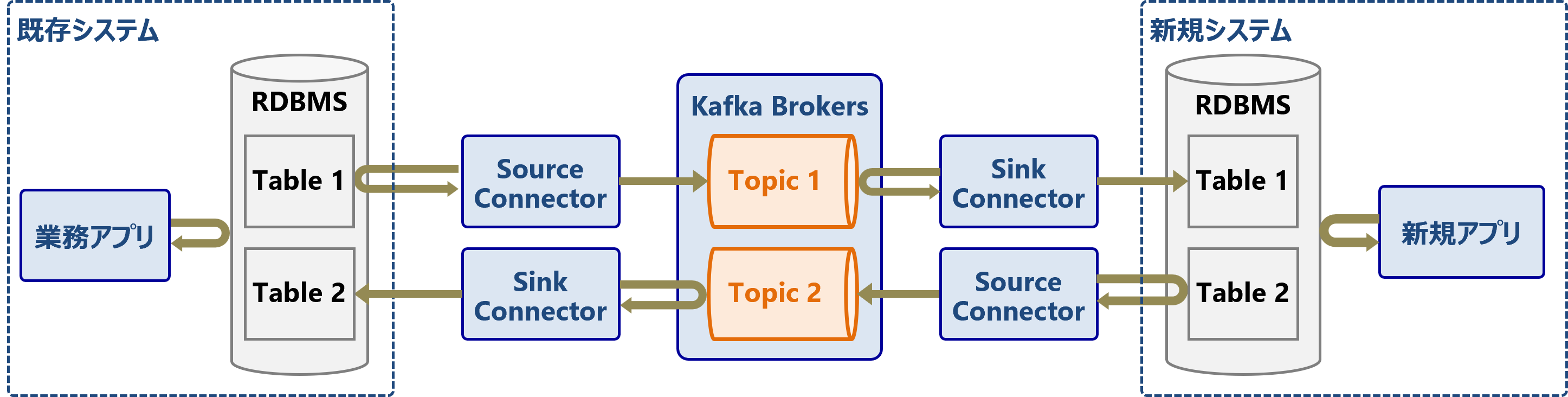
既存システムと新規システム間のデータ連携
例えば、オンプレミス上にある既存システムを残しながら、新規のシステムはクラウド上に構築したいとします。または、メインフレームで稼働するレガシーなシステムを残しながら、追加機能はKubernetesなどのコンテナ基盤上にデプロイしたいとします。
この既存システムと新規システムのDB間をCDCで同期することで、既存システムを残しながらシステムを拡張することができます。
主要なコネクタの入手先
そのまま利用可能な実装済みのコネクタを紹介します。
Apache Kafkaのコミュニティが提供するコネクタは、サンプルのFile connectorのみです。その他のコネクタはサードパーティー製となります。導入時は各コネクタのオープンソースライセンスもご確認ください。
代表的なコネクタ:
-
File connector
- Kafka本体に付属するサンプルのコネクタ
- ファイルの各行を読み取りメッセージとしてTopicに転送するSourceConnectorと、Topicの各メッセージをファイルに書き込むSinkConnectorで構成
- サーバ上のローカルファイルを読み書きするため、スタンドアロンモードでのみ使用可能
-
- 変更データキャプチャ(CDC)によるデータベース間のデータ同期を行うコネクタ
- 主要なRDBMS、KVS、データウェアハウスとの接続に対応
-
- JDBC互換のデータベースとの間でデータ転送を行うコネクタ
- CDCが目的であれば、より差分更新機能が強力なDebeziumを推奨
-
- Apache Camelは、複数のシステムを連携・統合するためのオープンソースのJavaフレームワーク
- Camel Kafkaコネクタを使用すると、CamelコンポーネントをKafka Connectコネクタとして使用可能
- これにより、Camelで連携可能な様々なシステムとKafkaを接続可能
コネクタの提供サイト:
-
Confluent Hub
- 主にConfluent Platform向けのコネクタを公開しているサイト
-
Self-Hostedのものは基本的にApache Kafkaでも利用可能だが、オープンソースライセンスをご確認ください
他にも各パブリッククラウドベンダーや、Kafka関連の製品・サービスを提供している企業がコネクタを公開しています。
コネクタを自作したい場合は、以下の公式ドキュメントと次回の記事をご参照ください。
おわりに
本稿ではKafka Connectの概要とユースケース、代表的なコネクタを紹介しました。次回はKafka Connectのより詳細な内部構造と動作の流れ、およびチューニングのポイントを紹介します。