著者: 伊藤 雅博, 株式会社日立製作所
はじめに
本稿ではKafka Connectの処理の流れと内部アーキテクチャ、チューニングポイントを紹介します。なお、具体的な構築手順やコマンド、設定ファイルの記載内容については次回の投稿で説明します。
記事一覧:
- Kafka Connectの概要とユースケース
- Kafka Connectのアーキテクチャとチューニングポイント(本稿)
- Kafka Connectを分散モードで動かしてみた
Kafka Connectの動作の流れ
Kafka Connectの動作モードについて
Kafka Connectにはスタンドアロンモードと分散モードの2種類の動作モードがあります。
| 観点 | スタンドアロンモード | 分散モード |
|---|---|---|
| 動作環境 | 1台のサーバで動作 | 複数台のサーバで動作可能 |
| 処理性能 | 低い | 高い(スケールアウトで並列分散処理) |
| 障害耐性 | なし | あり(自動フォールトトレランス) |
| 推奨用途 | ローカル環境での開発・テスト | 本番環境 |
以下では分散モードにおける処理の流れを説明します。
コネクタの配置
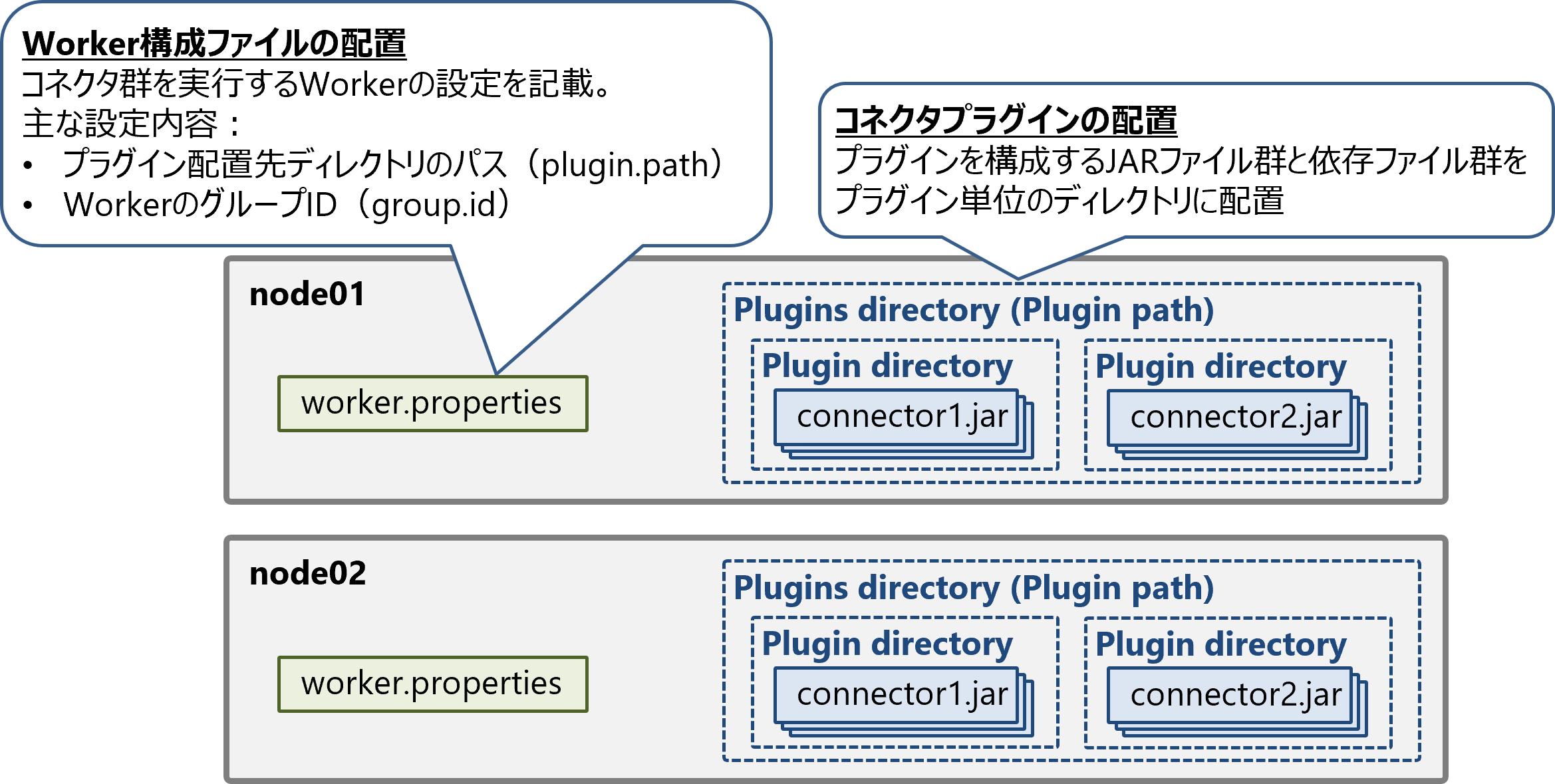
Kafka Connectクラスタを構成するサーバconnect01、connect02があるとします。事前準備として、各サーバに同一のWorker構成ファイルとコネクタプラグインを配置します。
Worker構成ファイルは、コネクタ群を実行するWorkerの設定ファイルです。プラグインを配置したディレクトリのパスplugin.path、WorkerのグループIDgroup.idなどを記載します。設定ファイルの詳細な内容については次回の投稿をご参照ください。
コネクタプラグインについては、プラグインを構成するJARファイル群と依存関係にあるファイルを、プラグイン単位のディレクトリに配置します。
Workerの起動
各サーバでKafka ConnectのWorkerインスタンスを起動します。
Workerを起動すると同じグループIDgroup.idを持つWorker間で、自動的にWorkerグループ(クラスタ)が構成されます。これはKafkaのConsumer Group機能を利用しており、Worker間はKafka Broker経由で通信して協調します。
今回はgroup.idがmyclusterのWorkerクラスタを起動します。
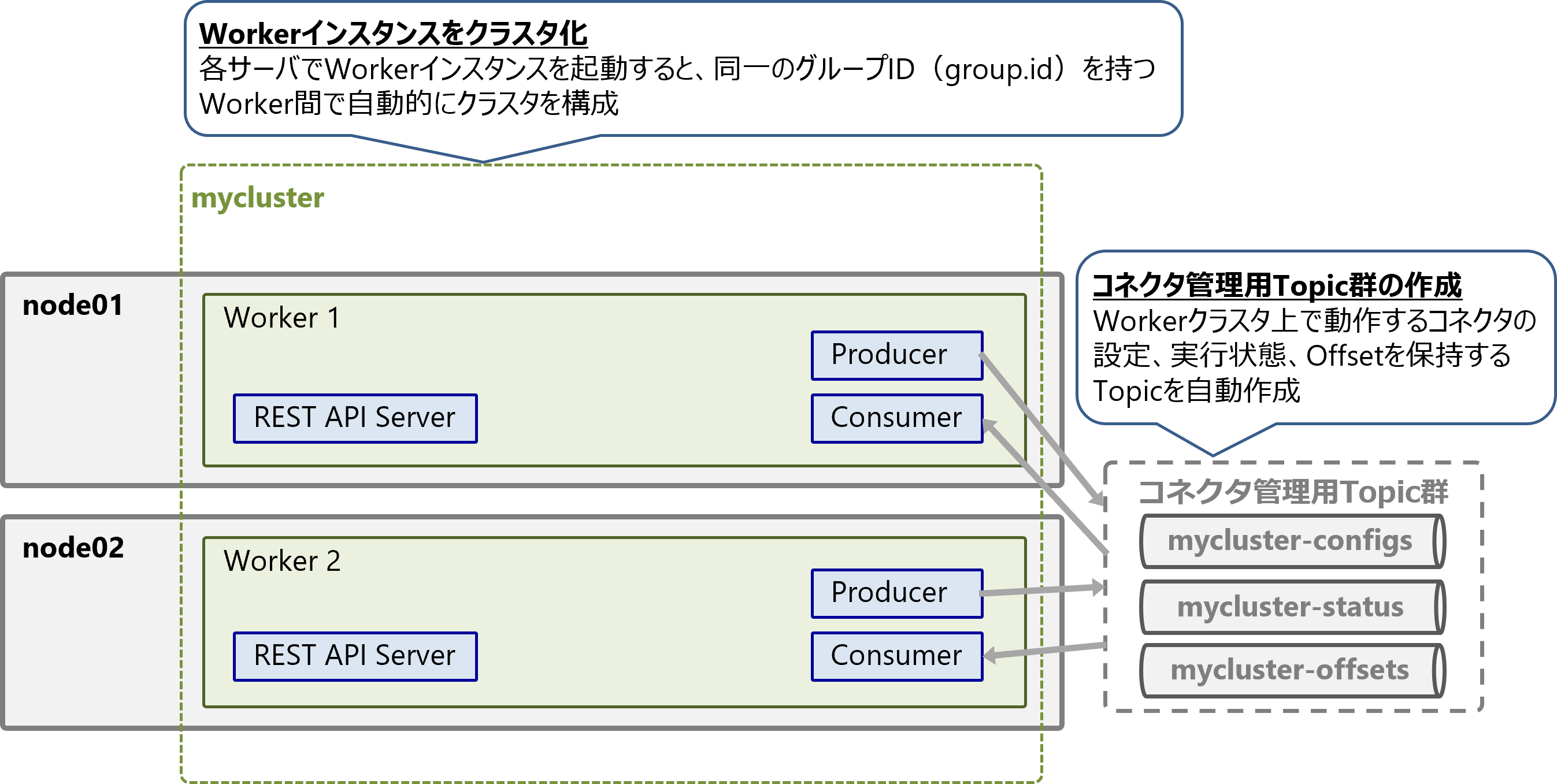
Workerクラスタを起動すると、以下の3種類のコネクタ管理用Topicが作成されます。
-
mycluster-configs: コネクタの設定を保存 -
mycluster-status: コネクタの実行状態を保存 -
mycluster-offsets: Partitioned StreamのOffsetを保存(Sourceコネクタのみ利用)
管理用Topicはコネクタのメタデータの保存、ConnectorとTask間のデータ共有、スケールアウト時と障害発生時の復旧などに利用します。
コネクタの起動
コネクタを起動するには、いずれかのWorkerのREST APIに対してコネクタ作成リクエストを送信します。コネクタ設定はリクエストのJSONペイロードで渡します。
Workerクラスタ上には複数のコネクタを起動できます。以下の図はWorkerクラスタ上に2個のコネクタを起動した例です。
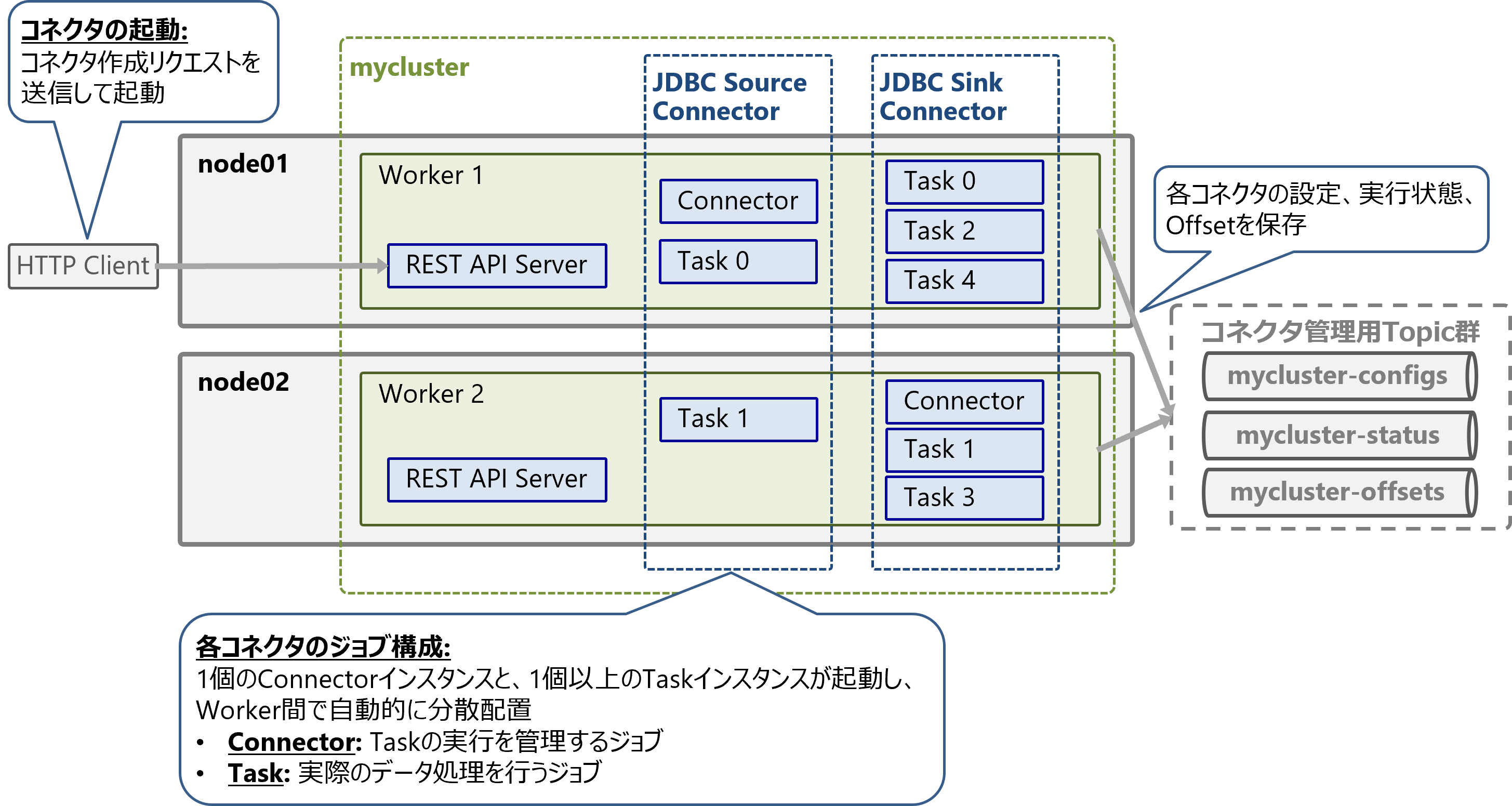
1個のコネクタを起動すると、1個のConnectorインスタンスと、1個以上のTaskインスタンスが起動し、Worker間で自動的に分散配置されます。ConnectorはTaskの実行を管理するジョブで、Taskは実際のデータ処理を行うジョブです。
Taskの最大数はコネクタ設定のtasks.maxで指定しますが、実際に起動されるTask数はコネクタの実装に依存します。例えば、JDBC Source Connectorは入力元テーブル数と同数のTaskを起動します(1テーブル=1Task)。
一方、同じような用途で使用されるDebezium Source ConnectorのTask数は1個で固定であり、テーブルごとにコネクタを起動する必要があります(1テーブル=1コネクタ)。
スケールアウトとフォールトトレランス
WorkerクラスタへのWorkerの参加および離脱時には、Worker間でConnectorとTaskの移動(リバランス)が発生します。
スケールアウト時の動作
Workerインスタンスを追加することで、Kafka Connectクラスタをスケールアウトして処理性能を向上できます。
新しいサーバ上でWorkerインスタンスを起動すると、同一のgroup.idを持つWorkerは自動的にWorkerクラスタへ参加します。起動中のコネクタのConnectorとTaskの一部は、自動的に新しいWorkerに移動(リバランス)します。新しいWorker上のConnectorとTaskは、Connector管理用Topicの情報から設定、実行状態、Offsetが復元されます。
なお、リバランス中も影響を受けないConnector/Taskは処理を中断せず実行を継続します。
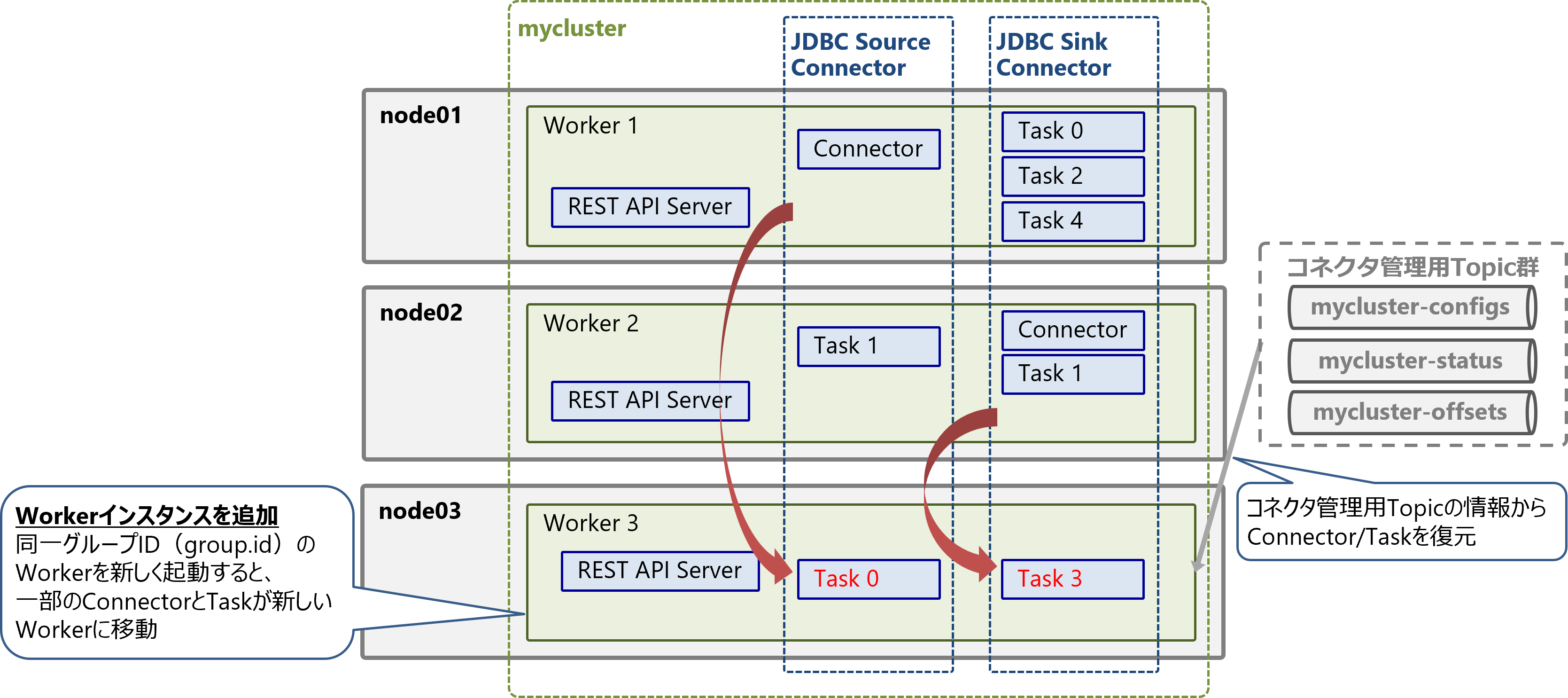
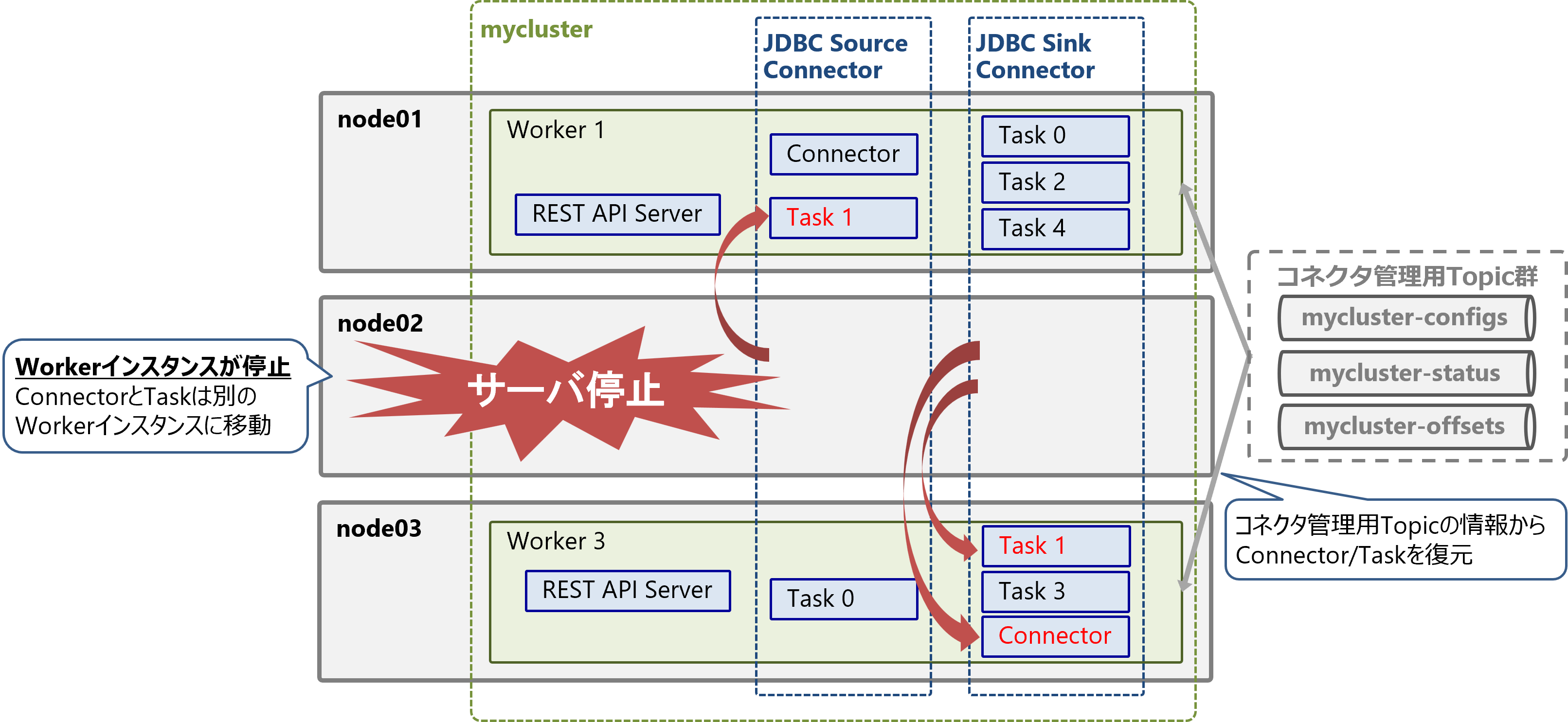
障害発生時/スケールイン時の動作
Workerクラスタはフォールトトレランス機能による障害耐性があります。
サーバ障害などでWorkerインスタンスが停止すると、WorkerクラスタからWorkerが離脱し、ConnectorとTaskは自動的に別のWorkerに移動(リバランス)します。Connector管理用Topicの情報から、移動先のWorker上でConnectorとTaskが復元されます。
これにより、一部のWorkerインスタンスが停止しても、コネクタは稼働を継続する事が可能です。また、リバランス中も影響を受けないConnector/Taskは処理を中断せず実行を継続します。
Workerインスタンスを減らしてスケールインする場合も同様の動作となります。
スケールアウトとスケールインは共に、Worker間でConnector/Taskを再配置(リバランス)するので、本質的には同じ動作です。ただしWorker離脱時のリバランスは即座に実行されるとは限りません。これは以下の仕組みのためです。
増分協調リバランスと遅延実行
Kafka Connectのリバランス方式は、増分協調リバランス (Incremental Cooperative Rebalancing)と呼び、以下の特徴があります。
- リバランス時には、移動するConnector/Task以外は停止や再起動せず、処理を継続する
- リバランスを即座に実行しないことで、リバランスの頻発を抑える
後者について、リバランスは実行前に最大scheduled.rebalance.max.delay.msだけ待機することがあります。この待機時間はデフォルト設定では300000ミリ秒 (5分)となっています。
この設定により、一時的なサーバ過負荷やネットワーク障害によるリバランスの頻発を防ぐことができます。特にWorker上で大量のTask(数百以上)が実行されている場合はリバランスの負荷が大きいため、リバランスの頻度を減らすことで全体的なコネクタのスループット低下を抑える効果があります。
一方でTask数が少なく、かつ復旧時間を短縮したい場合は、このリバランス実行の遅延時間を減らすことを推奨します。
なお、リバランスの実行タイミングは様々な要因に影響されるため、この遅延が発生せず即座にリバランスが実施される場合もあります。
増分協調リバランスの詳細な内容を知りたい方は、以下の資料をご参照ください。
参考:
- Apache Kafka Documentation - 8.4 Kafka Connect - Administration
- KIP-415: Incremental Cooperative Rebalancing in Kafka Connect
- Incremental Cooperative Rebalancing in Apache Kafka: Why Stop the World When You Can Change It?
コネクタのアーキテクチャ
Kafka ConnectのJDBC Connectorを題材にして、コネクタのデータモデルと内部構造を説明します。
Sourceコネクタのアーキテクチャ
JDBC Source Connectorを例にSourceコネクタのアーキテクチャを解説します。
Sourceコネクタのデータモデル
Sourceコネクタでは、データソースをPartitioned Streamというデータモデルで表現します。
JDBC Source Connectorの場合、データベースのテーブルをPartitionにマッピングし、テーブルのレコード(各行)をPartitionのメッセージにマッピングし、テーブルのタイムスタンプ列をPartitionのOffsetにマッピングします。
これによりデータベースのテーブルをTopic Partitionのように扱います。
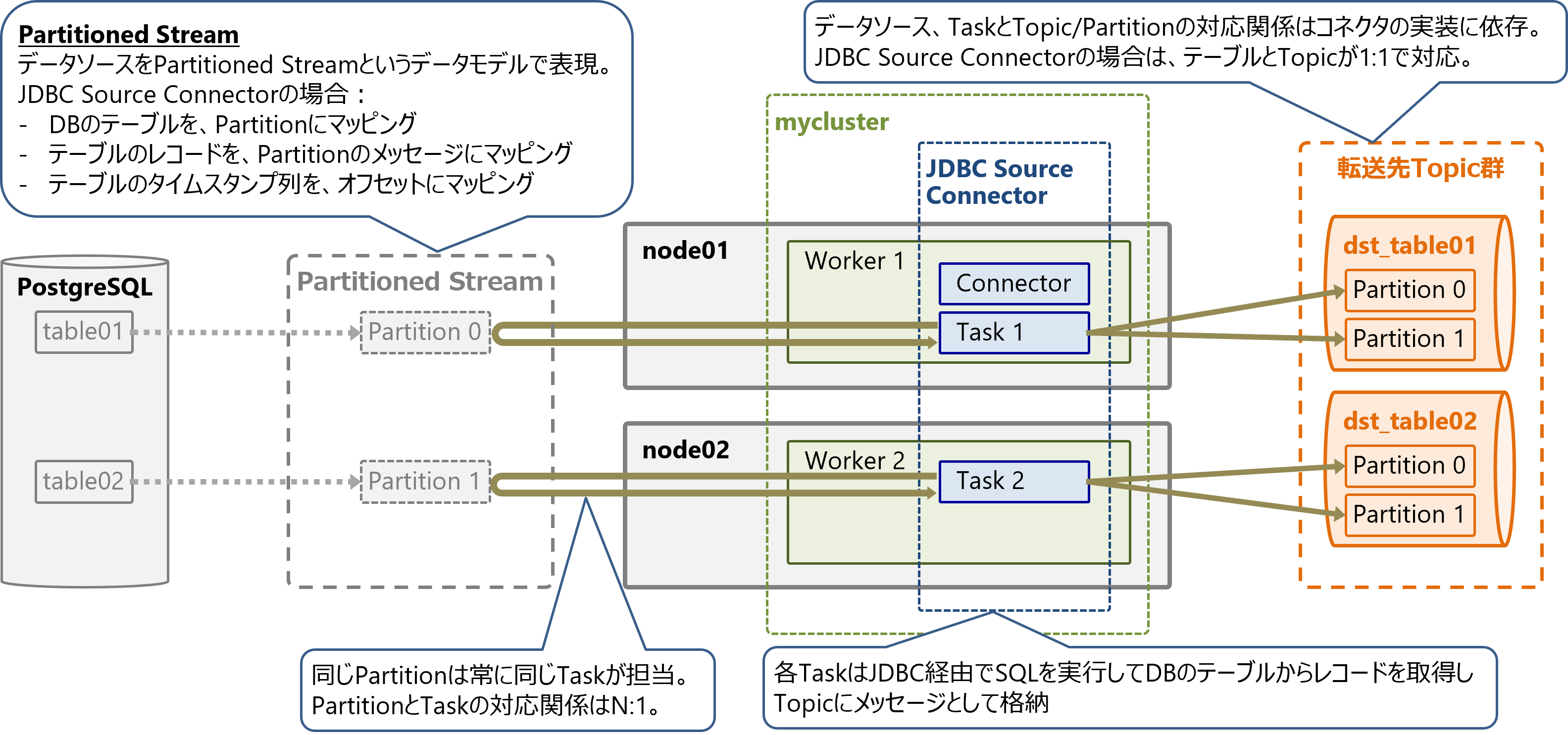
Partitioned StreamのPartitionとTaskの対応関係は固定であり、同じPartitionは常に同じTaskが担当します。PartitionとTaskの対応関係はN:1です。
Partition数がtasks.maxよりも少ない場合は、1つのTaskが1つのPartitionを担当しますが、Partition数がTask数よりも多い場合は、1つのTaskが複数のPartitionを担当します。
JDBC Source Connectorでは、各TaskはJDBC経由でテーブルにSQLを実行してレコードを取得します。テーブル数が増減するとPartition数も増減するため、コネクタはそれを検知してTask数も増減します(ただしtasks.maxを超えない範囲で)。
Taskと転送先Topic/Partitionの対応関係はコネクタの実装に依存します。JDBC Source Connectorの場合は、テーブルとTopicが1:1で対応します。
Sourceコネクタの内部構成
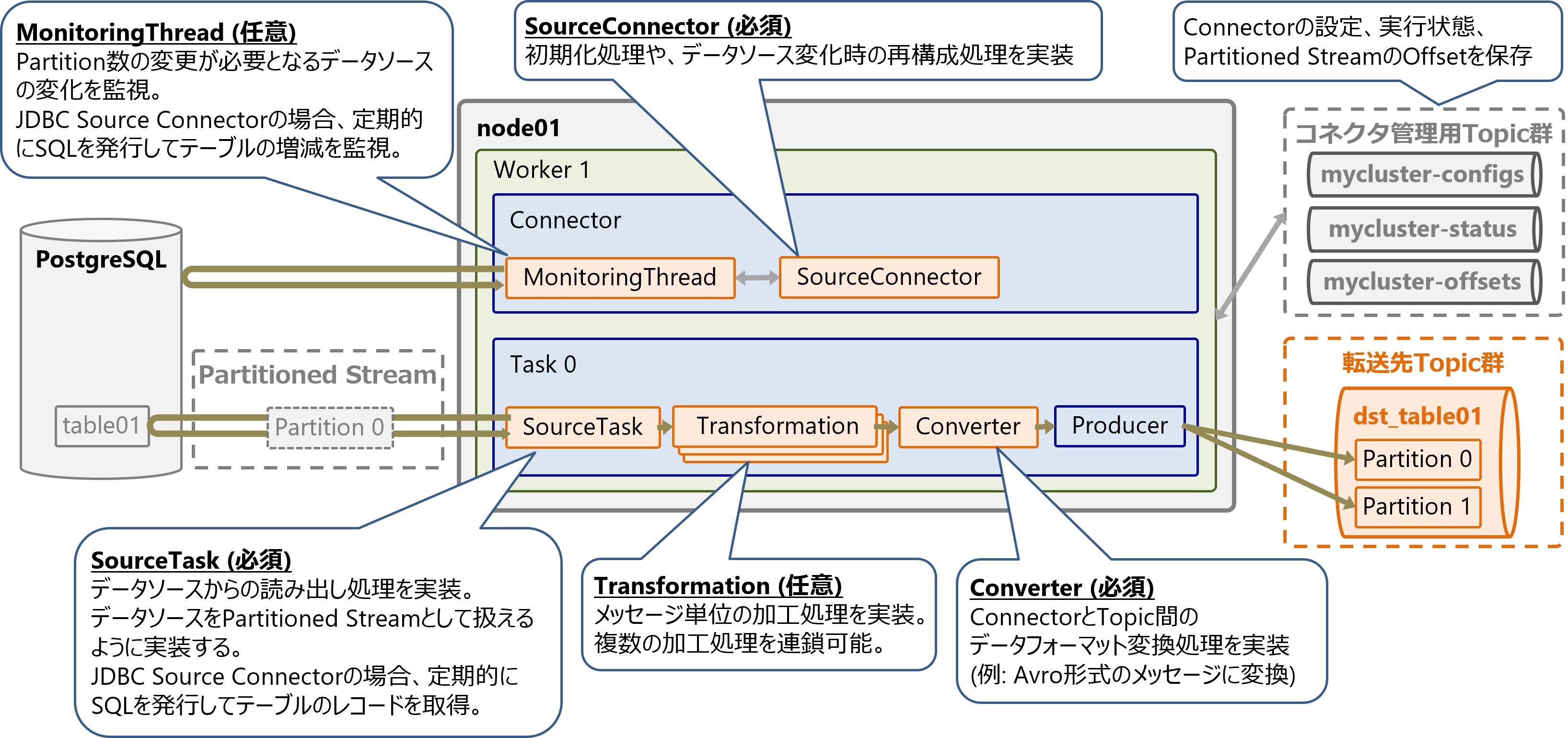
Sourceコネクタは以下の要素で構成されます。各要素の実装内容はコネクタにより異なります。
-
Connector
- SourceConnector (必須)
- 初期化処理や、データソース変化時の再構成処理を実装
- MonitoringThread (任意)
- Partition数の変更が必要となるようなデータソースの変化を監視
- 例: JDBC Source Connectorの場合、定期的にSQLを発行してテーブルの増減を監視して、テーブル数(Partition数)に合わせてTask数を増減させる
- SourceConnector (必須)
-
Task
- SourceTask (必須)
- データソースからの読み出し処理を実装。データソースをPartitioned Streamとして扱えるように実装する
- 例: JDBC Source Connectorの場合、定期的にSQLを発行してテーブルのレコードを読み出し
- Transformation (任意)
- メッセージ単位の加工処理を実装。複数の加工処理を連鎖可能
- Converter (必須)
- ConnectorとTopic間のデータフォーマット変換処理を実装
- 例: Avro形式のメッセージに変換
- SourceTask (必須)
TransformationとConverterは、Workerまたはコネクタの設定で利用(挿入)するクラスを指定できます。
コネクタを自作する場合、 Connectorフレームワークの上記に対応するクラスをJavaで実装します。各クラスは独立しているため、必要な部分だけ実装して他は既存クラスを再利用可能です。
参考となるKafka Connect JDBC Connectorの実装は以下で確認できます。
ConnectorとTaskは管理用Topicでコネクタの設定、実行状態、Partitioned StreamのOffsetを永続化・共有します。
Sinkコネクタのアーキテクチャ
JDBC Sink Connectorを例にSinkコネクタのアーキテクチャを解説します。
Sinkコネクタのデータモデル
Sinkコネクタの各TaskはConsumerを持ち、Consumer Groupを構成します。Consumer Groupの性質上、PartitionとTask (Consumer)の対応関係はN:1で固定であり、同じPartitionは常に同じTaskが担当します。また、Topicの最大Partition数より多いTaskは生成されても使用されません。
そのため、並列処理性能を向上させたい場合はTask数tasks.maxを増やすだけでなく、TopicのPartition数も増やす必要があります。
各TaskはPartitionからメッセージを読み出して、データシンクとなるデータベースにJDBC経由でSQLを実行し、テーブルにレコードを挿入します。Topic、Taskとデータシンクの対応関係はコネクタの実装に依存しますが、JDBC Source Connectorの場合は、Topicとテーブルが1:1で対応します。
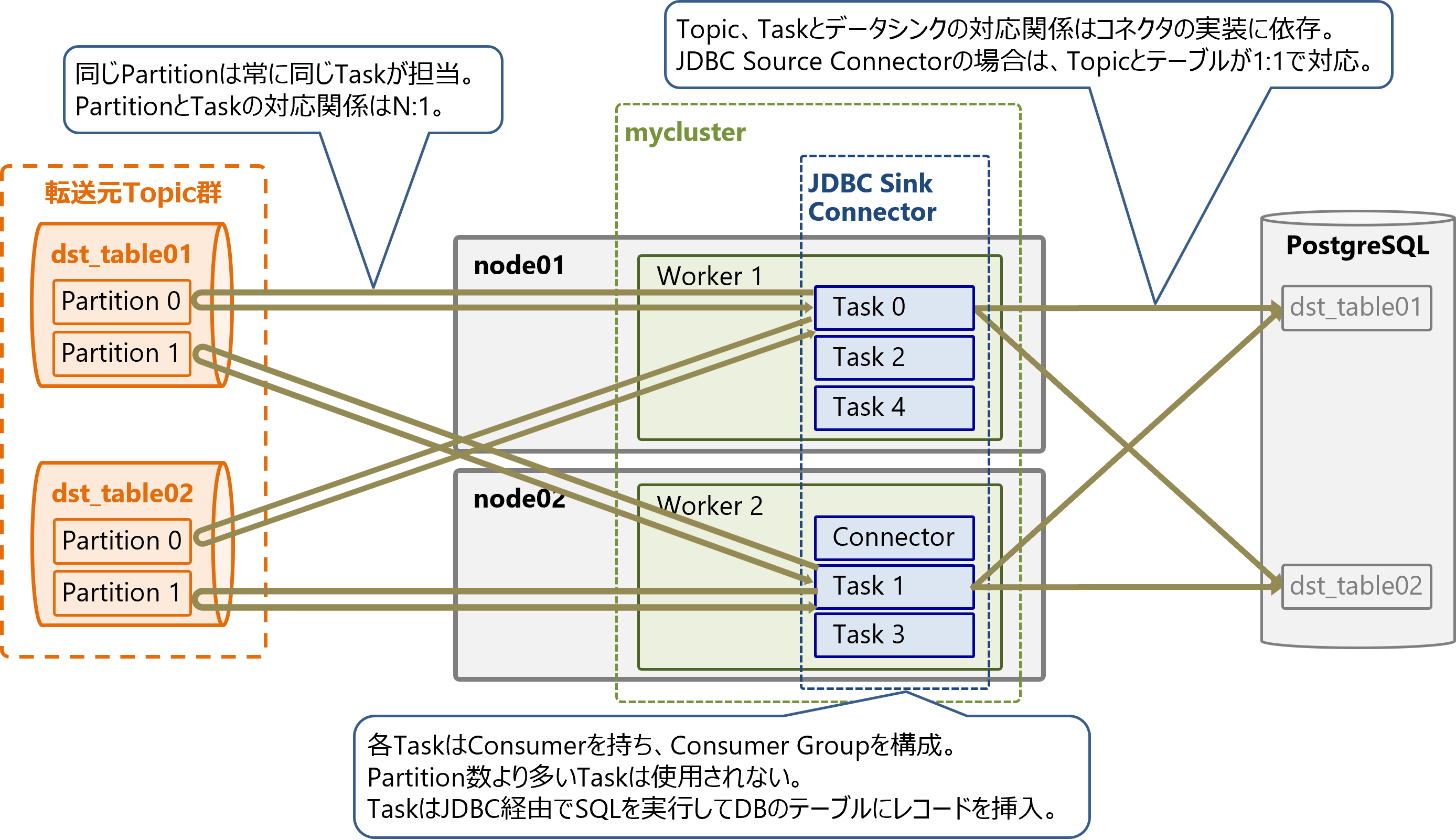
Sinkコネクタの内部構造
Sinkコネクタは以下の要素で構成されます。各要素の実装内容はコネクタにより異なります。
-
Connector
- SinkConnector (必須)
- 初期化処理などを実装
- SinkConnector (必須)
-
Task
- Converter (必須)
- ConnectorとTopic間のデータフォーマット変換処理を実装
- 例: Avro形式のメッセージをデコード
- Transformation (任意)
- メッセージ単位の加工処理を実装。複数の加工処理を連鎖可能
- SinkTask (必須)
- 転送先への書き込み処理を実装
- 例: JDBC SInk Connectorの場合、データベースにJDBCで接続してレコードを書き込み
- Converter (必須)
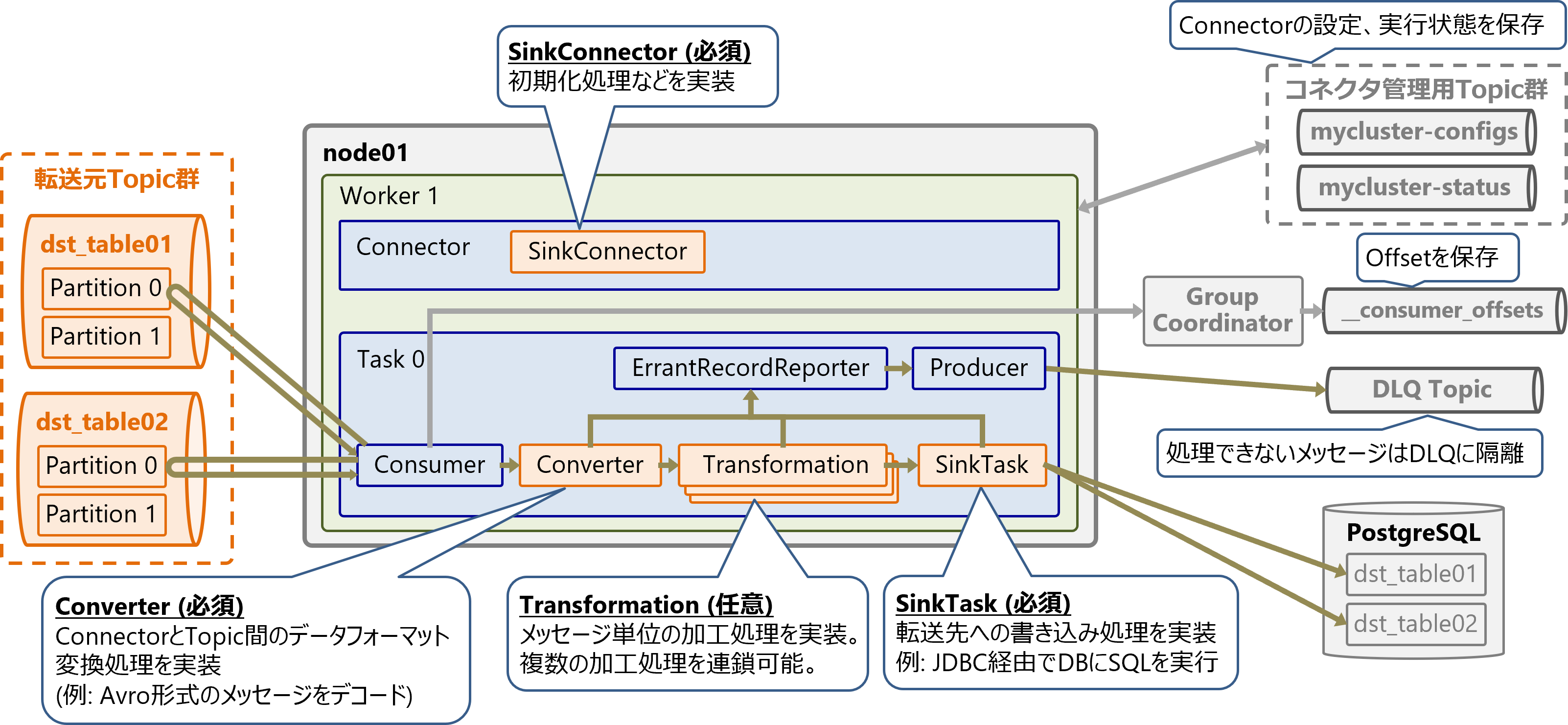
Sinkコネクタを自作する場合はSourceコネクタと同様、上記に対応するクラスをJavaで実装します。SinkコネクタのConnectorとTaskも、管理用Topicでコネクタの設定、実行状態を永続化・共有します。
デッドレターキュー(DLQ)
SinkコネクタはTopicから読み出したメッセージを順番通りに処理してデータシンクへ転送します。
もし何らかの理由で処理・転送できないメッセージがあった場合は、何度か再試行したのちに、コネクタは以下のいずれかの動作を行います。
- コネクタを停止する
- 処理できなかったメッセージをデッドレターキュー (Dead Letter Queue: DLQ) 用のTopicに隔離して、そのメッセージの処理をスキップする
デッドレターキューを使用することで、処理できなかったメッセージを記録しておくことができます。
配信のセマンティクス
SinkコネクタのTaskはKafka Consumerと同様に、Topicからメッセージをどこまで読み出したかを示すOffsetを、Group Coordinator経由で専用のTopic__consumer_offsetsに保存します。
しかしこの方法ではOffset保存前にTaskがクラッシュすると、Task復旧時にOffsetが巻き戻り、同じメッセージが再度読み出されて処理されます。そのため、同じメッセージが重複してデータシンクに書き込まれます。
同じメッセージが最低でも1回以上処理されるため、これをAt-least-onceの配信と呼びます。
メッセージの重複を排除するには、データシンク側で同じメッセージが来たら上書きされるように処理する(冪等性を担保する)方法が一般的です。
一部のコネクタは、データシンクにメッセージとOffsetを同時にまとめて書き込めます。Task復旧時にこのOffsetを参照することで、処理済メッセージとOffsetのずれを防ぎ、同じメッセージを確実に1回だけ処理するExactly-onceの配信を実現します。
例えばHDFS 3 Sink Connectorでは、HDFSへ書き込むファイル名にOffsetを付与することで、同時に書き込みます。
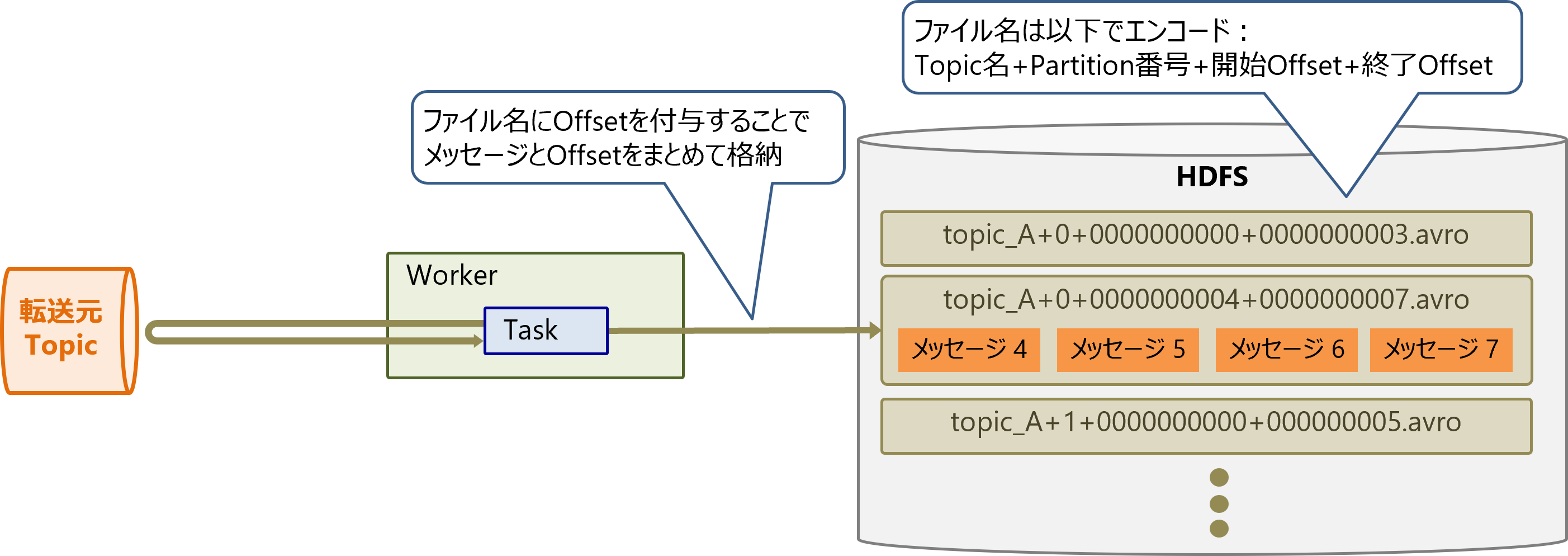
もしRDBMSに書き込む場合は、メッセージとOffsetを同一トランザクションでアトミックに記録できます。
ただし、JDBC Sink ConnectorはAt-least-onceの配信のみをサポートしており、Exactly-onceの配信を実現する機能はありません。
Kafka Connectのチューニングポイント
Task数とPartition数の設定
Kafka ConnectはWorker数を増やして負荷を分散し、Task数を増やして処理を並列化できます。
- Worker数の指定: 同じ
group.idを指定したWorkerを複数起動 - コネクタのタスク数の指定: コネクタ設定値
tasks.maxを変更
ただしtasks.maxはあくまでTaskの最大数であり、実際に生成されるTask数はコネクタの実装に依存します。さらに、Taskが生成されたとしても入力元のPartition数より多いTaskは使用されません。これはConsumer Groupの仕組みを利用しているためです。
入力元Partition数は以下のように決まります。
- Sourceコネクタの場合: データソースをマッピングしたPartitioned StreamのPartition数
- 例: JDBC Sourceコネクタの場合は、入力テーブル数
- Sinkコネクタの場合: 入力元TopicのPartition数
- 例: JDBC Sinkコネクタの場合は、事前にPartition数を指定してTopicを作成可能だが、メッセージの順序を保ちたい場合は1Partitionにする必要あり
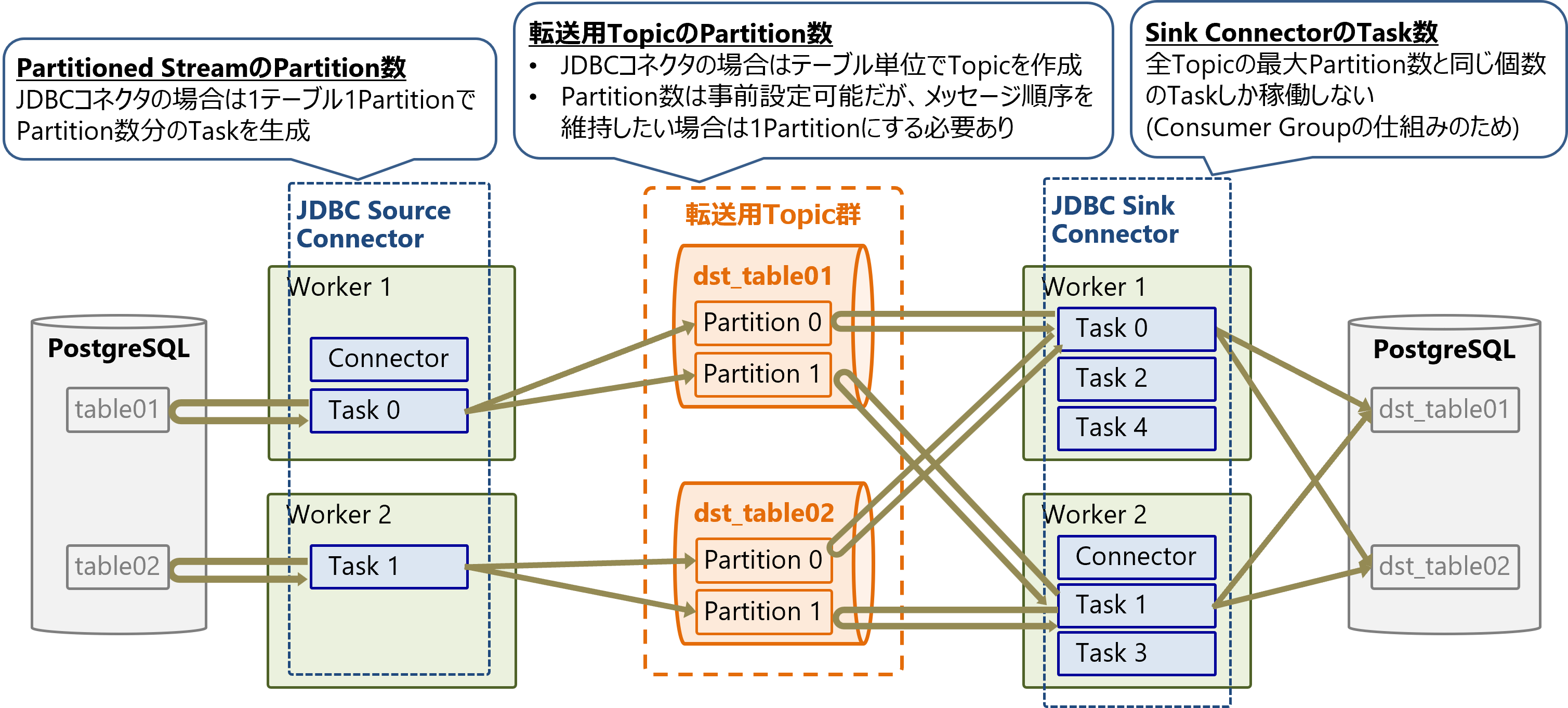
Task数と入力Partition数を合わせることで、処理の並列度を最大化できます。そのためTask数を正しくチューニングするためには、個別のコネクタがPartition数をどのように決めるのかを把握しておく必要があります。
また、各Workerのサーバには、Task数と同数以上のvCPUがあるとよいです。
リバランスの設定
Workerインスタンスを追加してスケールアウトする際は、Connector/Taskの移動(リバランス)はすぐに実行されます。
一方で、障害発生/スケールインでWorkerインスタンスが停止した際は、リバランスの実行前にscheduled.rebalance.max.delay.msだけ待機します。この待機時間はデフォルト設定では300000ミリ秒 (5分)となっています。
この設定によりWorkerの一時的な障害やアップグレード時に不要なリバランスが発生するのを防げますが、すぐにリバランスさせたい場合は、この待機時間を減らす必要があります。
おわりに
本稿ではKafka Connectのコネクタ全般で共通の概念・アーキテクチャを説明しました。性能チューニングではTask数とPartition数の調整が必要ですが、これらは個別のコネクタの実装に依存します。
次回は実際にKafka ConnectのJDBCコネクタを動かして、今回説明した動作を再現してみます。