著者: 伊藤 雅博, 株式会社日立製作所
はじめに
AWSでストリーム処理を実現する際は、データをキューイングするメッセージングサービスと、キューイングしたデータをストリーム処理するサービスを組み合わせることが一般的です。本投稿では、AWSが提供する各メッセージングサービスのうち、ストリームデータを扱う際によく活用されている下記サービスの特徴を紹介します。
- Amazon Kinesis Data Streams (KDS)
- Amazon Managed Streaming for Apache Kafka (MSK)
- Amazon Simple Queue Service (SQS)
なお、本投稿の内容は2020年中頃の調査結果をベースに、いくつか更新を加えたものです。AWSのサービス仕様は随時更新されるため、最新の仕様とは異なる場合があります。最新の情報はAWSの公式ドキュメントをご参照ください。
投稿一覧:
- AWSでストリームデータを扱うためのメッセージングサービス
- AWSのストリーム処理向けメッセージングサービスKDS(Kinesis)・MSK(Kafka)・SQSの特徴 (本投稿)
- AWSのKinesis Data Analytics、EMR Spark Streaming、Lambdaによるストリーム処理の特徴
AWSにおけるストリーム処理の基本構成
ストリーム処理システムを構成するAWSサービスの組み合わせを以下の図に示します。
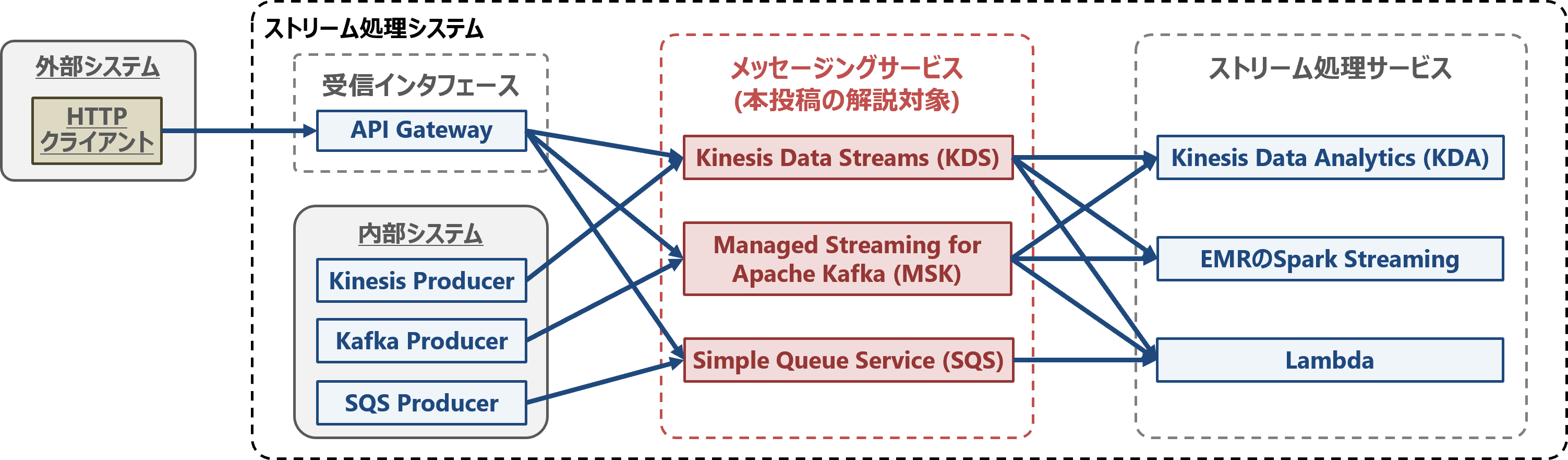
ストリーム処理システムでは一般的に、メッセージングサービスでストリームデータをキューイングしてから、ストリーム処理を行います。詳細は前回の投稿「AWSでストリームデータを扱うためのメッセージングサービス」をご参照ください。
KDS、MSK、SQSの特徴とアーキテクチャ
AWSでストリームデータを扱う際によく活用されているKDS、MSK、SQSの特徴とアーキテクチャを紹介します。
Amazon Kinesis Data Streams (KDS)
KDSの代表的な関連コンポーネント
KDSの代表的な関連コンポーネントを以下の図に示します。KDSはクライアントライブラリを使用して、様々な言語のアプリケーションから利用可能です。また、AWSの様々なサービスとの連携が可能です。なお、KDSに対応するサービスは随時追加されているため、最新の対応状況はAWSの公式ドキュメントを確認してください。
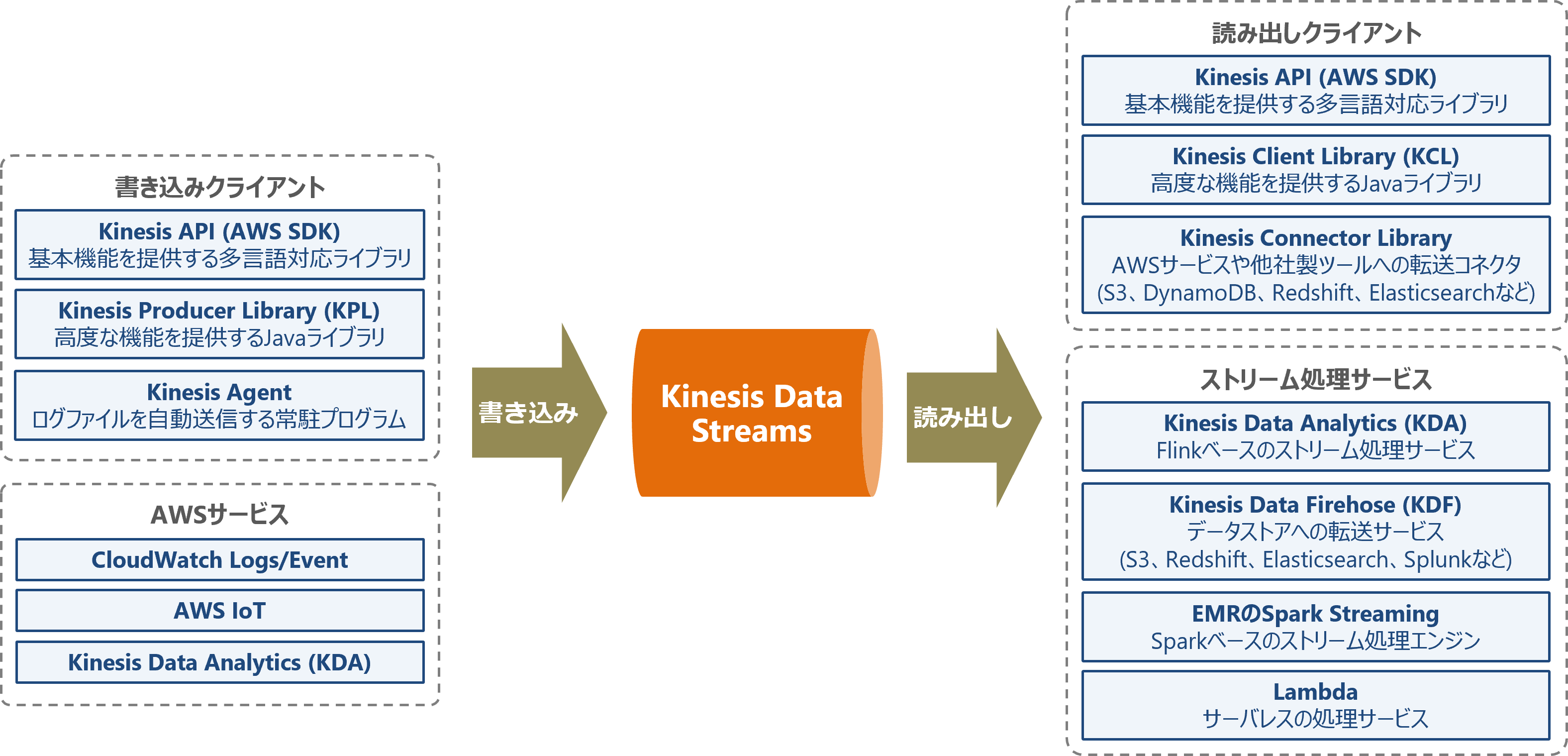
KDSのアーキテクチャ
KDSのアーキテクチャを以下の図に示します。KDSはPublish/Subscribe方式の分散型メッセージキューです。KDSでは1個の仮想的なキューをStreamと呼び、各Streamは複数個のShardで構成します。Streamへの書き込み/読み出しを、複数のShardに分散することで性能をスケールアウトします。
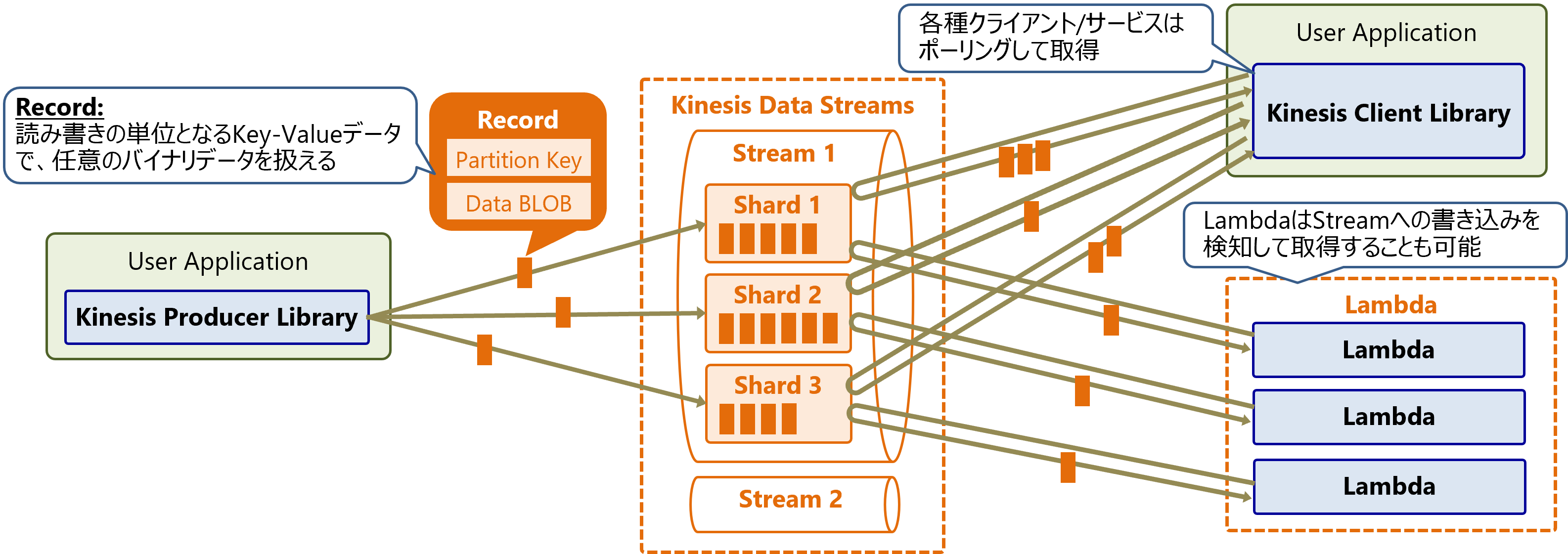
KDSに書き込むデータはKey-Value形式のRecordであり、Valueには任意のバイナリデータ(Data BLOB)を格納できます。
KDSからRecordを読み出す際は、読み出し側のアプリケーションがShardをポーリングしてRecordを取得します。取得はPull方式であり、KDS側からPush配信は出来ません。ただしAWS Lambdaを使用する場合は、Streamへの書き込みをトリガーにLambda関数を起動し、Recordを取得・処理するイベント駆動型のアプリケーションを構築できます。
また、Recordは読み出しても削除されないため、1個のStreamの同じデータを複数のアプリケーションから並列に読み出し可能です。
KDSの処理の流れ
KDSの処理の流れを以下の図に示します。ここでは、書き込みにKinesis Producer Library (KPL)、読み出しにKinesis Client Library (KCL)を利用する場合の例を示しています。KPL/KCLは任意のユーザアプリケーションに組み込んで利用できます。
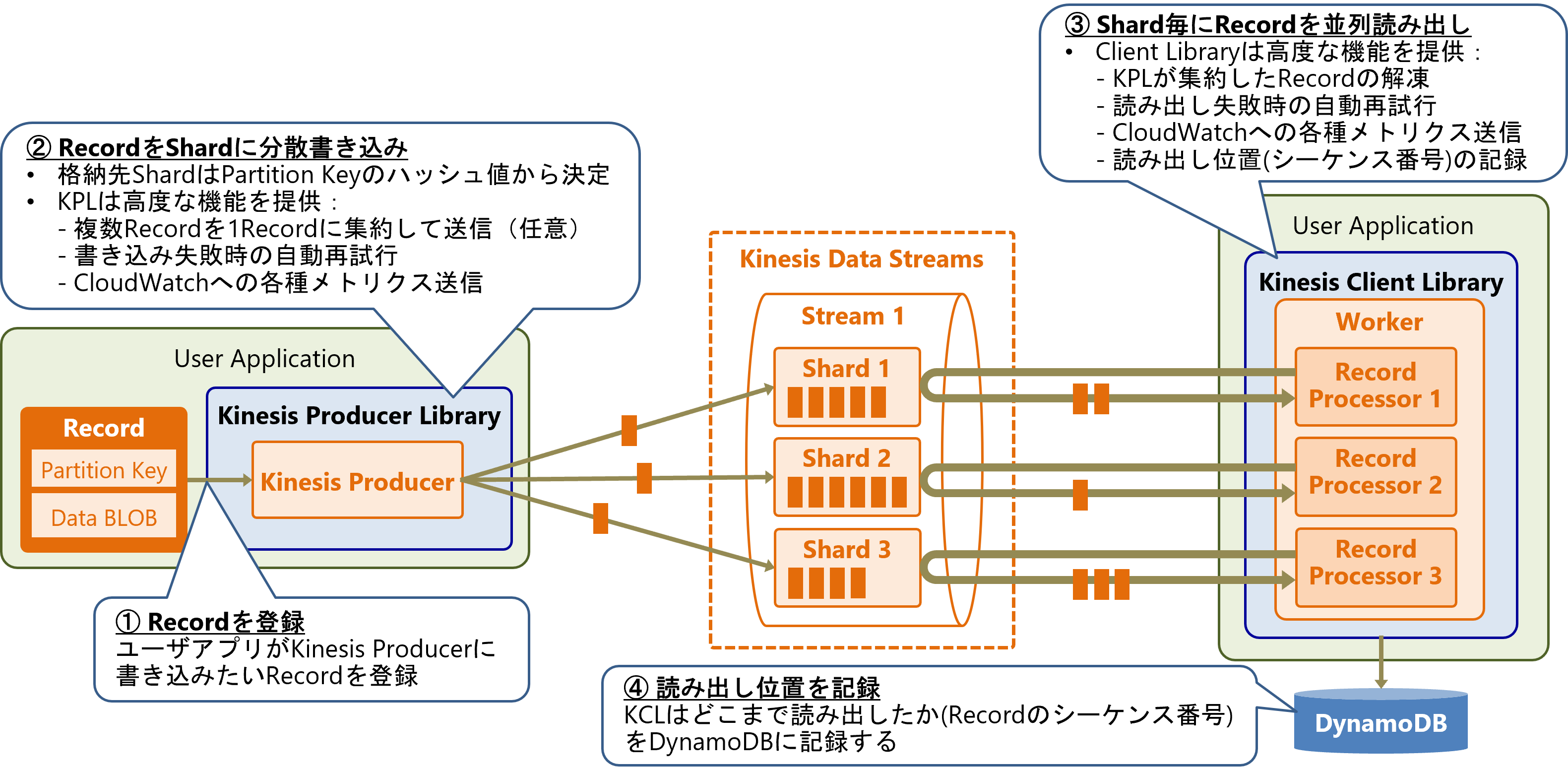
書き込み側のユーザアプリケーションが送信したいRecordをKPLに登録すると、KPLが対象StreamのShardに送信します。Recordの書き込み先Shardは、RecordのPartition Keyのハッシュ値から決定されます。
また、KPLは以下に示すような高度な書き込み機能を提供します。
- 複数Recordを1つのRecordに集約して送信
- 書き込み失敗時の自動再試行(リトライ)
- CloudWatchへの各種メトリクス送信(送信クライアント監視)
KCLを使用した読み出し側アプリケーションでは、Shard単位でRecordを並列に読み出すことができます。各アプリケーションがRecordをどこまで読み出したかは、KDSではなく読み出しアプリケーション側で管理します。具体的には、ShardからRecordをどこまで読み出したかを示すシーケンス番号を、読み出し側のアプリケーションで記憶しておく必要があります。
KCLは以下に示すような高度な読み出し機能を提供します。
- KPLが集約したRecordの解凍
- 読み出し失敗時の自動再試行(リトライ)
- CloudWatchへの各種メトリクス送信(受信クライアント監視)
- 読み出し位置(シーケンス番号)のDynamoDBへの自動記録
KDSの仕様と制限
KDSの主な仕様と制限を以下の図に示します。
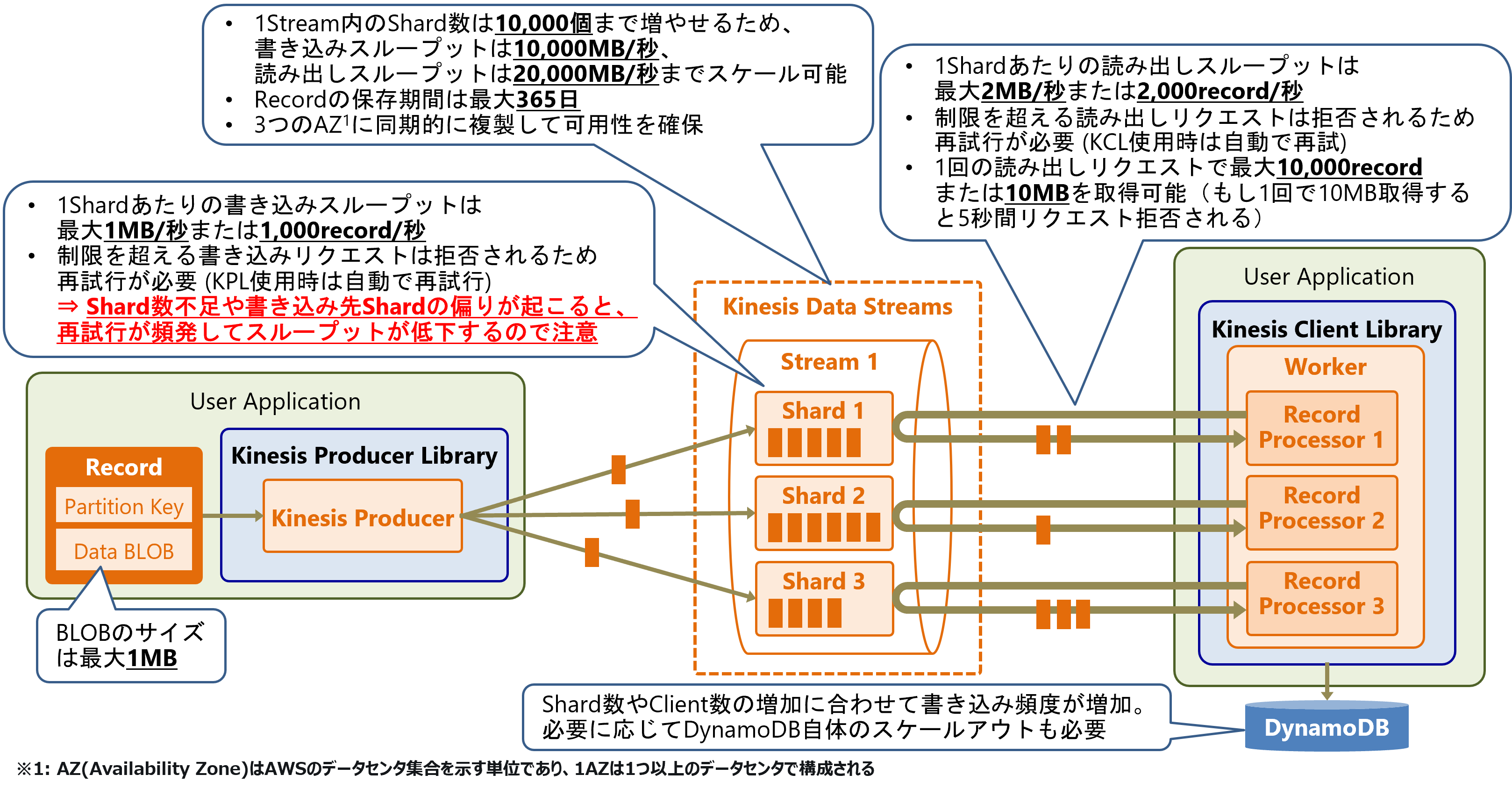
Streamに書き込める 1Recordのデータ(BLOB)サイズは最大1MBです。書き込みの最大スループットはStreamのShard数により制限されます。1Shardあたりの書き込みスループットは最大1MB/秒または1,000record/秒で、1Stream内のShard数は最大10,000個まで増やすことが可能です。つまり、書き込みスループットは最大10,000MB/秒までスケール可能です。なお、スループット制限を超える書き込みリクエストは拒否されるため再試行(リトライ)が必要です。KPL使用時は自動で再試行してくれます。
KDSの書き込み性能を引き出すには、Shard数の調整やパーティションキーの設計などのチューニングが必要です。最大スループットがShard数に依存するため、Shard数が不足している場合や、パーティションキーの偏りによる書き込み先Shardの偏りが発生すると、リクエストの再試行が頻発してスループットが低下します。
Streamに書き込まれたRecordは一定期間保存され、読み出されても削除されません。Recordの保存期間は最大365日です。保存されたRecordは3つのAZ(Availability Zone)に同期的に複製することで可用性を確保しています。
Streamからの読み出しスループットは、StreamのShard数により制限されます。1Shardあたりの読み出しスループットは最大2MB/秒または2,000record/秒です。1Stream内のShard数は最大10,000個のため、読み出しスループットは最大20,000MB/秒までスケール可能です。
なお、制限を超える読み出しリクエストは拒否されるため再試行が必要です。KCL使用時は自動で再試行してくれます。1回の読み出しリクエストで最大10,000recordまたは10MBを取得可能です。例えば、1回の読み出しリクエストで10MB取得すると、その後5秒間リクエストが拒否されます。
Amazon Managed Streaming for Apache Kafka (MSK)
MSKのアーキテクチャ
MSKのアーキテクチャを以下の図に示します。MSKはクラスタ上にPublish/Subscribe方式の分散型メッセージキューを構成します。
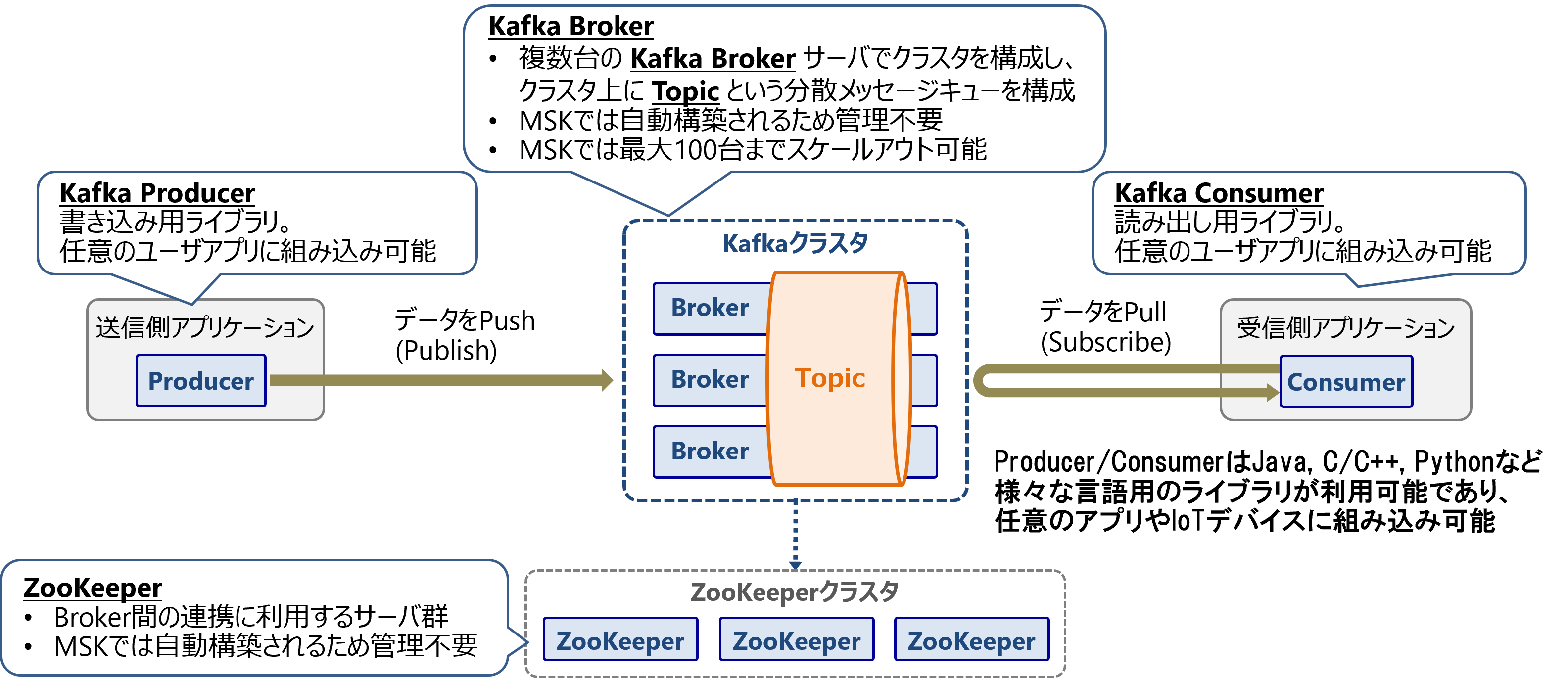
MSKは複数台のKafka Brokerインスタンスでクラスタを構成し、クラスタ上にTopicという分散メッセージキューを構成します。MSKのBrokerは自動で構築され、最大100台までスケールアウト可能です。
Topicへのデータ書き込みにはKafka Producerというライブラリを使用し、データ読み出しにはKafka Consumerというライブラリを使用します。Producer/ConsumerはJava, C/C++, Pythonなど様々な言語用のライブラリが存在し、任意のユーザアプリケーションやIoTデバイスに組み込み可能です。
ZooKeeperはBroker間の連携に利用します。MSKでは自動構築されるため管理は不要です。
MSKの処理の流れ
MSKの処理の流れを以下の図に示します。
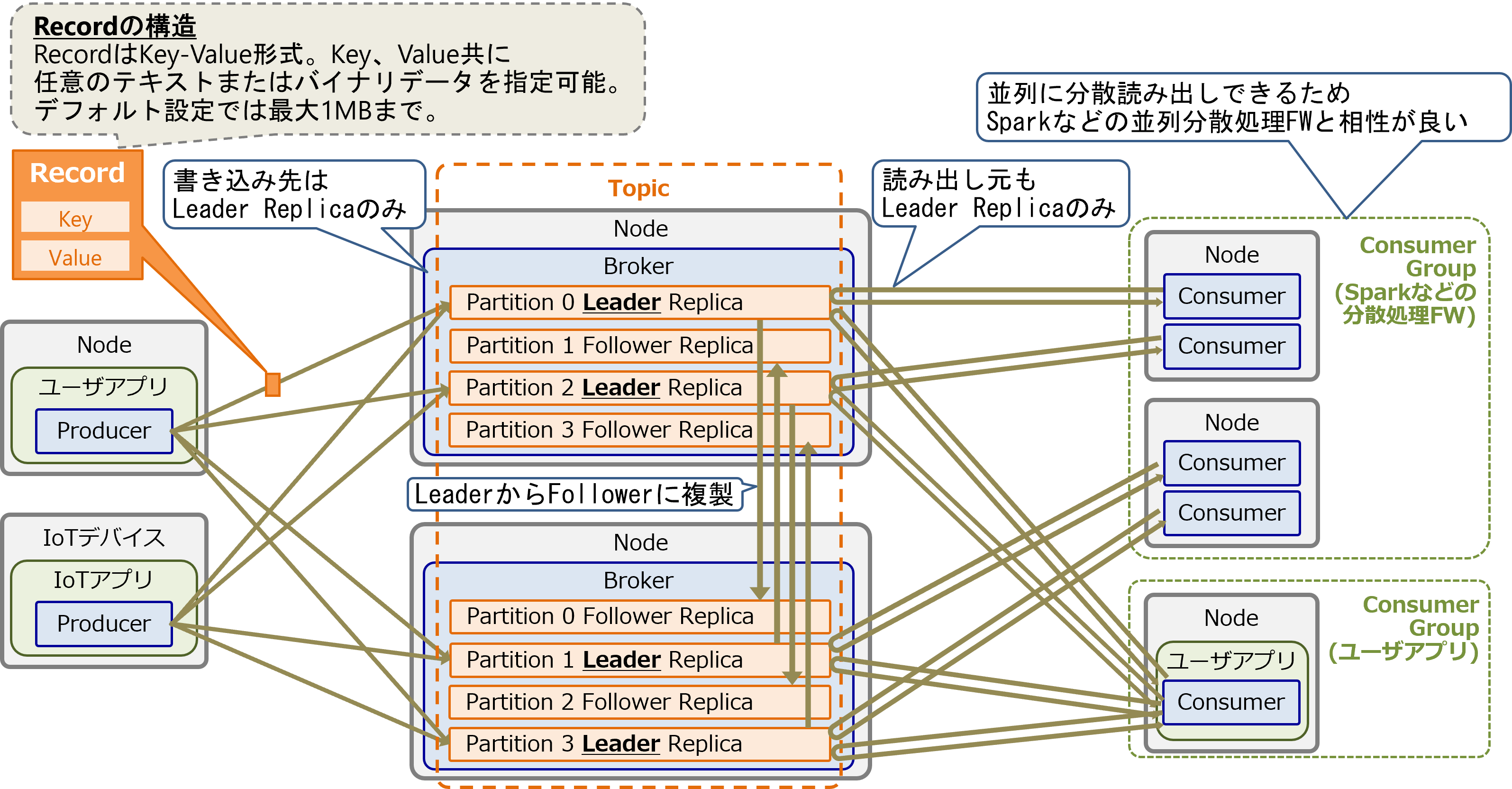
Topicは1個以上のPartitionで構成し、各Partitionは1個のLeaderレプリカと、0個以上のFollowerレプリカで構成します。LeaderとFollowerは別々のBrokerインスタンスに配置します。データの書き込み/読み出しは、PartitionのLeaderレプリカに対してのみ行います。
Topicに書き込むデータはKey-Value形式のRecordであり、任意のテキストまたはバイナリデータを指定可能です。デフォルト設定ではRecordの最大サイズは1MBです。
書き込み側のアプリケーションは、Producerライブラリを使用して各Partitionに分散書き込みします。書き込みをBroker間で分散処理することでスケールアウトします。
PartitionのLeaderレプリカに書き込まれたRecordは、別のBrokerにあるFollowerレプリカに複製します。Brokerに障害が発生してLeaderレプリカが使用できなくなった際は、Followerレプリカのうち1つがLeaderレプリカに昇格します。これにより、一部Brokerインスタンスの故障による稼働停止とデータロストを抑制します。
読み出し側のアプリケーションは、Consumerライブラリを使用して各Partitionから並列にRecordを読み出します。読み出しはKDSと同様にアプリケーション側からポーリングして行います。そのためMSK側からPush配信は出来ません。
読み出し側はアプリケーション単位でConsumerグループを構成し、グループ内のConsumer間で1TopicのPartitionを分担して読み出すことができます。この並列読み出し機能があるため、Sparkなどの並列分散処理フレームワークとも相性が良いです。また、RecordはTopicから読み出されても消えないため、複数のアプリケーション(Consumerグループ)で同じTopicの同じRecordを同時に読み出しすことも可能です。
Kafkaの詳細な仕組みついては Apache Kafkaの概要とアーキテクチャ をご参照ください。
Amazon Simple Queue Service (SQS)
SQSの標準キューとFIFOキューの特徴
SQSには高性能な標準キューと、メッセージ順番保証ありのFIFOキューがあります。それぞれの特徴を以下の表に示します。
| 項目 | 標準キュー | FIFOキュー |
|---|---|---|
| 読み書きスループット | 無制限(自動スケール) | 300件/秒(申請により引き上げ可能) |
| メッセージ順序の保証 | なし | あり |
| メッセージ配信のセマンティクス | まれに同じメッセージの重複配信あり | 同じメッセージの重複配信なし |
メッセージの順序を厳密に保ちたい場合や、重複不可の場合には、FIFOキューの使用を推奨します。それ以外の場合は標準キューの使用を推奨します。
SQSのアーキテクチャと処理の流れ
SQSの仕様と処理の流れを以下の図に示します。これはSQSのクライアントライブラリであるProducer/Consumerを使用した場合の例となります。
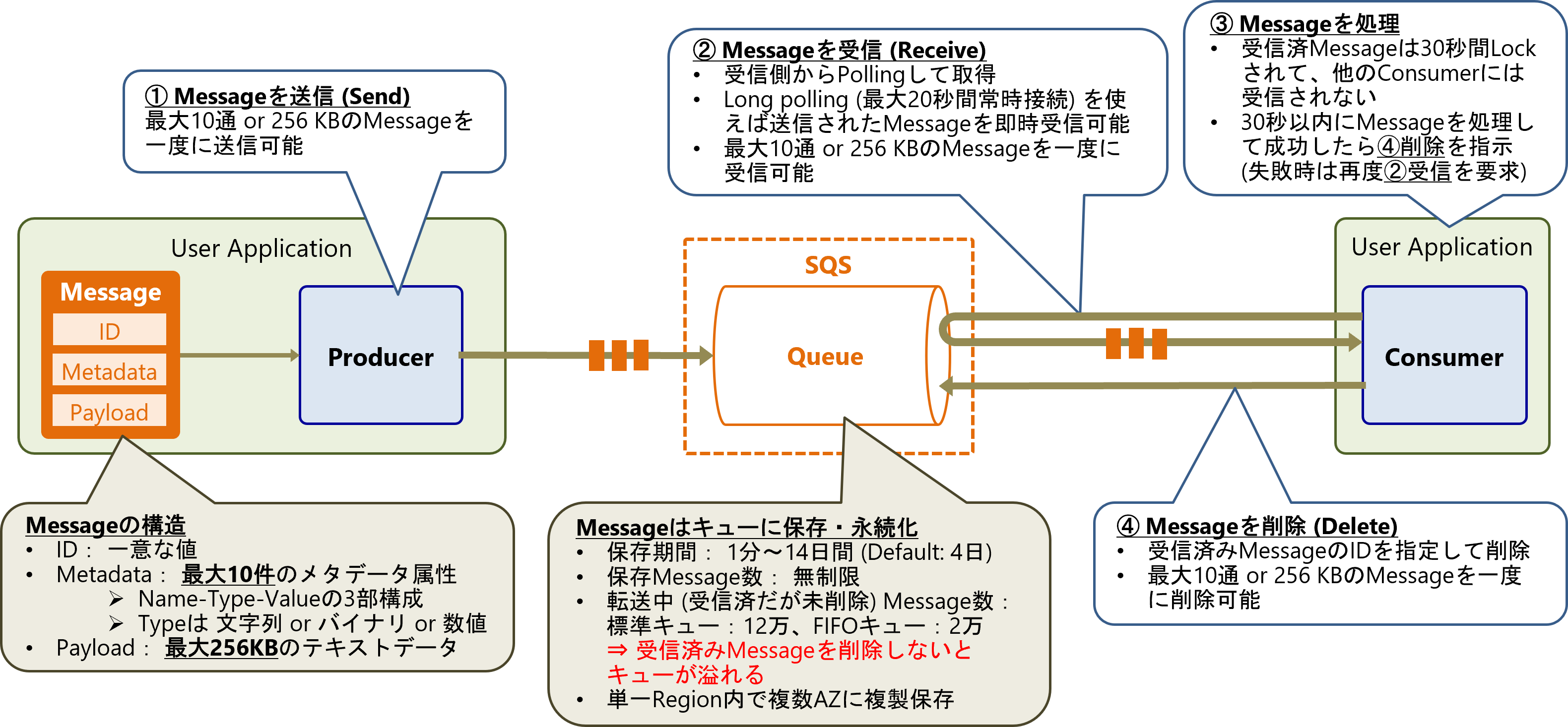
SQSに書き込むメッセージは、一意なID、最大10件のメタデータ属性、最大256KBのテキストデータのペイロードから構成されます。
書き込み側のアプリケーションは、SQSのProducerライブラリを使用してキューにメッセージを送信します(Sendリクエスト)。このとき最大10通または256KBのメッセージを一度に送信可能です。メッセージはキューに保存され、単一リージョン内の複数AZに複製されます。保存期間は1分~14日間 (デフォルト: 4日)で設定可能で、保存出来るメッセージ数は無制限です。
読み出し側アプリケーションは、SQSのConsumerライブラリを使用して、キューをポーリングすることでメッセージを取得します(Receiveリクエスト)。キューにメッセージがないときは最大20秒間のロングポーリングを行うことで、新たに来たメッセージを即時受信できます。最大10通または256 KBのメッセージを一度に受信可能です。
Consumerがキューから受信したメッセージは30秒間ロックされて、他のConsumerは受信できません。読み出し側アプリケーションは30秒以内にメッセージを処理する必要があります。メッセージの処理に成功したら、SQSに対して受信済みメッセージのIDを指定して削除を指示します(Deleteリクエスト)。最大10通または256 KBのメッセージを一度に削除可能です。転送中 (読み出し側が受信済だが未削除) のメッセージ数には制限(標準キュー:12万、FIFOキュー:2万)があり、受信済みメッセージを削除しないとキューが溢れるため注意が必要です。
このようにSQSでは、あるクライアントが読み出したメッセージはロックして削除する必要があります。そのため、KDSやMSKのように複数のアプリケーションから同じメッセージを読み出すことはできません。
KDS、MSK、SQSでストリームデータを扱う際の特徴
KDS、MSK、SQSの特徴を以下の表に示します。
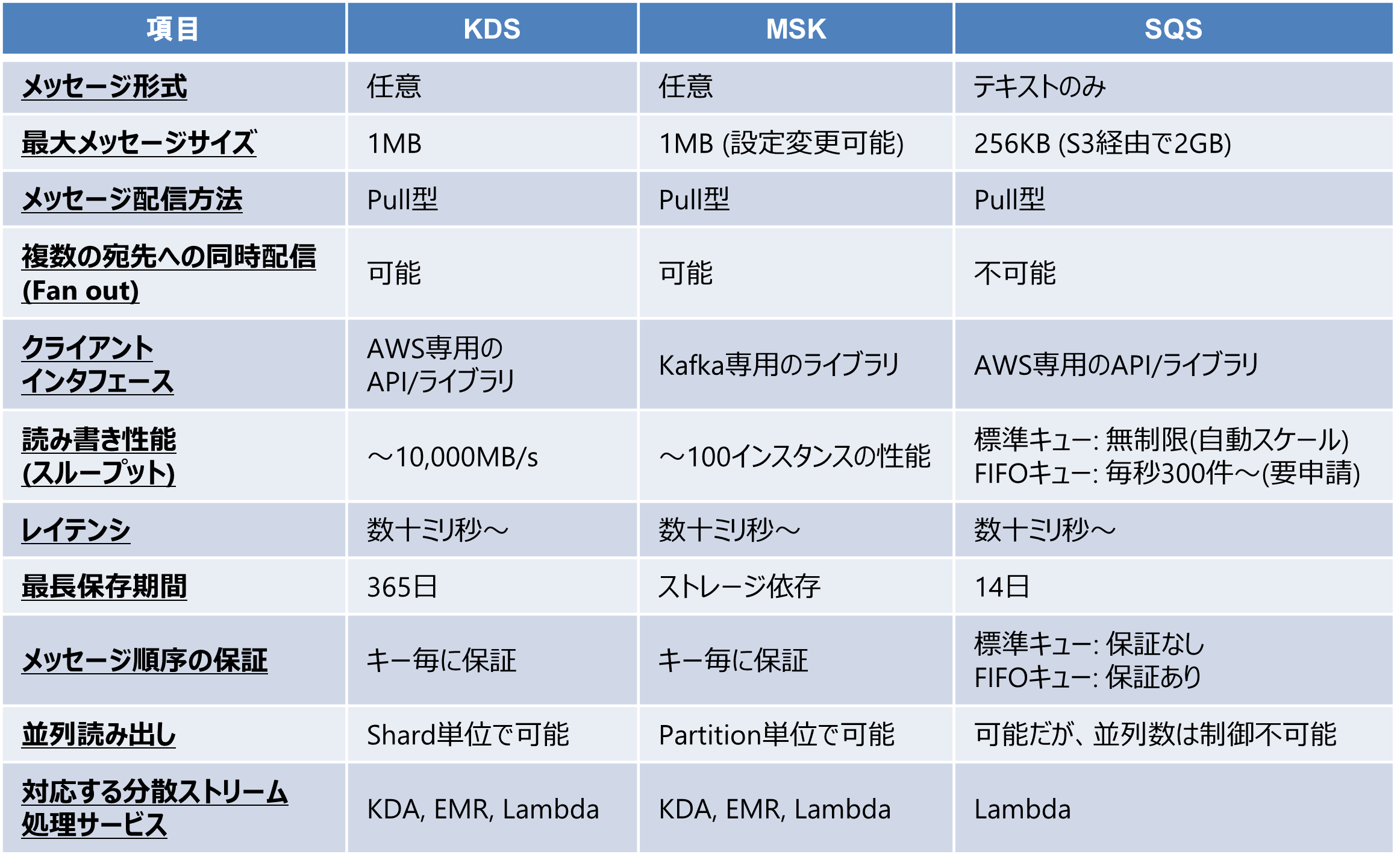
これらのサービスでストリームデータを扱う際のメリットと注意点を以下に示します。
Amazon Kinesis Data Streams (KDS)
- メリット:
- AWSサービスとの親和性が高い
- Shardという並列数の概念があるため、分散ストリーム処理サービス(KDA、EMR、Lambda)と相性がよい
- 並列数をユーザが制御可能なので、最初から最大性能を出しやすい
- 注意点:
- 性能を引き出すにはチューニングが必要(特にShard数の調整とパーティションキーの設計)
- 読み書きスループットがShard数に依存するため、Shard数が不足している場合や、パーティションキーの偏りによる書き込み先Shardの偏りが発生すると、リクエストの再試行が頻発してスループットが低下するので注意
- 性能を引き出すにはチューニングが必要(特にShard数の調整とパーティションキーの設計)
Amazon Managed Streaming for Apache Kafka (MSK)
KDSとほぼ同じ特徴を持ちますが、以下の違いがあります。
- メリット:
- OSSのKafkaベースなのでベンダーロックインを回避しやすい
- Partition単位のスループット制限がないので、KDSよりは若干チューニングしやすい
- 注意点:
- マネージドサービスであるがインスタンス台数などを意識する必要がある
Amazon Simple Queue Service (SQS)
- メリット:
- チューニング不要で簡単に使える
- 注意点:
- テキストデータ、かつ256KB以下のデータしか扱えない
- 同じデータを複数の宛先に配信できない(読み出したデータは即時削除する必要があるため)
- 対応するストリーム処理サービスはLambdaのみ。性能(Lambda同時実行数)は自動スケールで制御不可
おわりに
AWSが提供する各メッセージングサービスのうち、ストリームデータを扱う際によく活用されるKDS、MSK、SQSの特徴とアーキテクチャを紹介しました。MSKとKDSはストリーム処理との組み合わせに適していますが、性能を引き出すには若干のチューニングが必要です。SQSについてはチューニング不要で簡単に利用できるのが特徴です。
次回の投稿では、今回紹介したメッセージングサービスとKinesis Data Analytics、EMRのSpark Streaming、Lambdaを組み合わせたストリーム処理の特徴を紹介します。