著者: 伊藤 雅博, 株式会社日立製作所
はじめに
AWSでストリーム処理を実現するサービスには複数の選択肢があります。本投稿では、AWSが提供する主要なストリーム処理サービスの特徴を紹介します。
なお、本投稿の内容は2020年中頃の調査結果をベースに、いくつか更新を加えたものです。AWSのサービス仕様は随時更新されるため、最新の仕様とは異なる場合があります。最新の情報はAWSの公式ドキュメントをご参照ください。
投稿一覧:
- AWSでストリームデータを扱うためのメッセージングサービス
- AWSのストリーム処理向けメッセージングサービスKDS(Kinesis)・MSK(Kafka)・SQSの特徴
- AWSのKinesis Data Analytics、EMR Spark Streaming、Lambdaによるストリーム処理の特徴 (本投稿)
AWSにおけるストリーム処理の基本構成
AWSでストリーム処理システムを構成する際の、一般的なサービスの組み合わせを以下の図に示します。
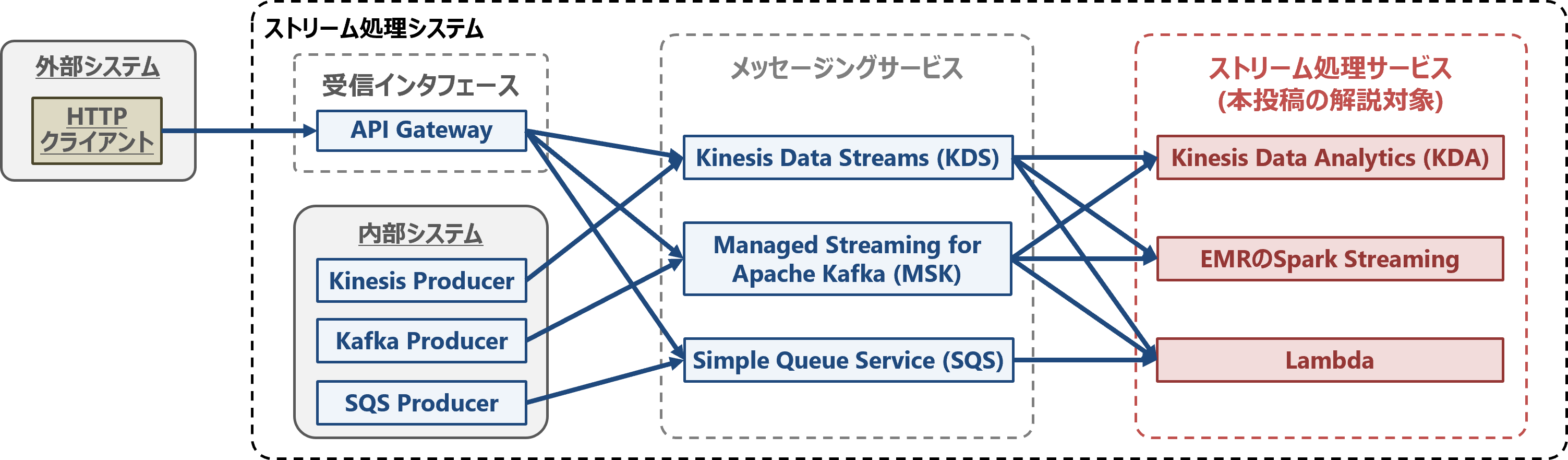
AWSでストリーム処理を実現する際は、ストリームデータをKDSやMSK、SQSといったメッセージングサービスでキューイングしてから、ストリーム処理を行うことが一般的です。
メッセージングサービスの特徴については、以前の投稿「AWSでストリームデータを扱うためのメッセージングサービス」および「AWSのストリーム処理向けメッセージングサービスKDS(Kinesis)・MSK(Kafka)・SQSの特徴」をご参照ください。
AWSにおけるストリーム処理サービス
AWSにおける代表的なストリーム処理サービスには以下があります。
- Amazon Kinesis Data Analytics (KDA)
- Amazon EMR の Spark Streaming
- AWS Lambda
これらサービスの特徴を以下の表に示します。

各サービスの仕様は随時更新されるため、最新の情報はAWSの公式ドキュメントをご参照ください。また、AWSではサービスクォータの引き上げを申請することで、一部の制限値については引き上げが可能です。
各ストリーム処理サービスのアーキテクチャ
各サービスのアーキテクチャを紹介します。
Amazon Kinesis Data Analytics (KDA)
KDAは、KDSまたはMSKからRecordを取得して変換処理するマネージドサービスです。オープンソースの並列分散処理フレームワークであるApache Flinkをベースにしたサービスであり、SQLまたはJavaによるデータ変換処理が可能です。
一般的には、Recordが表形式で扱えるデータ構造(CSV/TSV/JSONなど)の場合は変換処理をSQLで記述し、それ以外の場合Javaで変換処理用のFlinkアプリケーションを作成します。KDAでは複数Recordにまたがる高度な処理も可能です。例えば、直近3分間のRecordの平均値を計算するウィンドウ集計などが可能です。
変換処理したデータはそのまま他のAWSサービス(DynamDB、Elasticsearch、S3、KDS、KDFなど)に配信することが可能です。
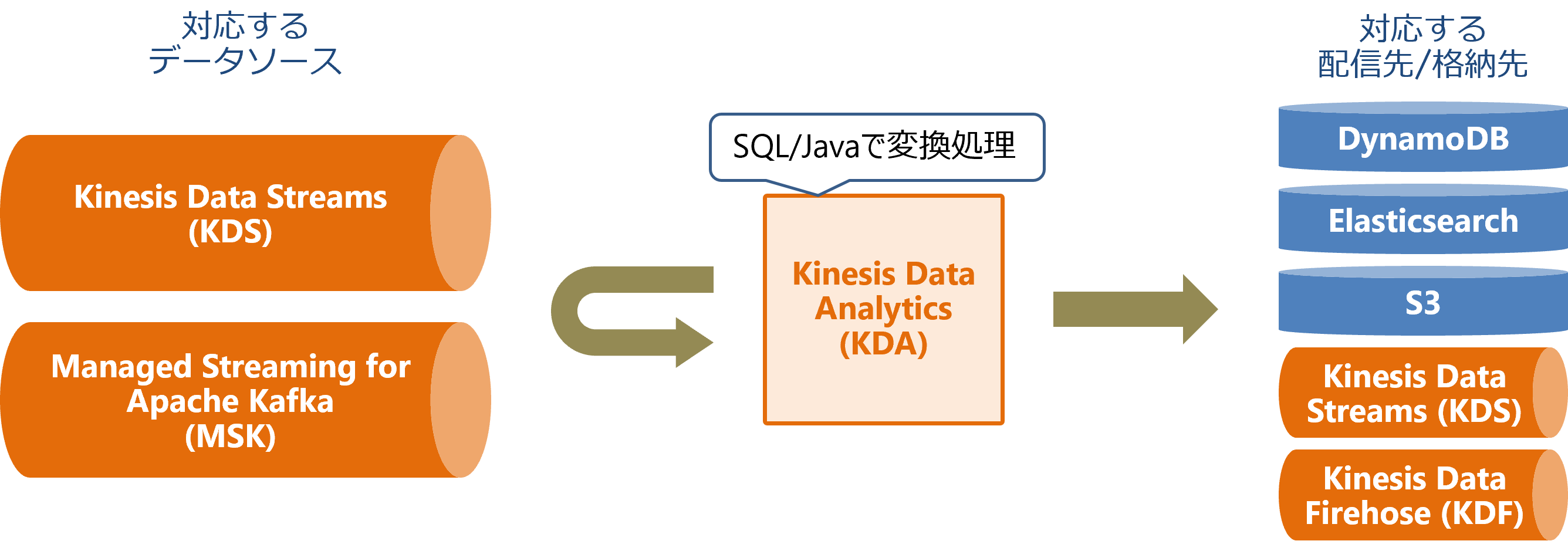
性能チューニングについては、処理の並列数を指定するだけなので気軽に利用することができます。
Amazon EMR と Spark Streaming
Amazon EMRとは
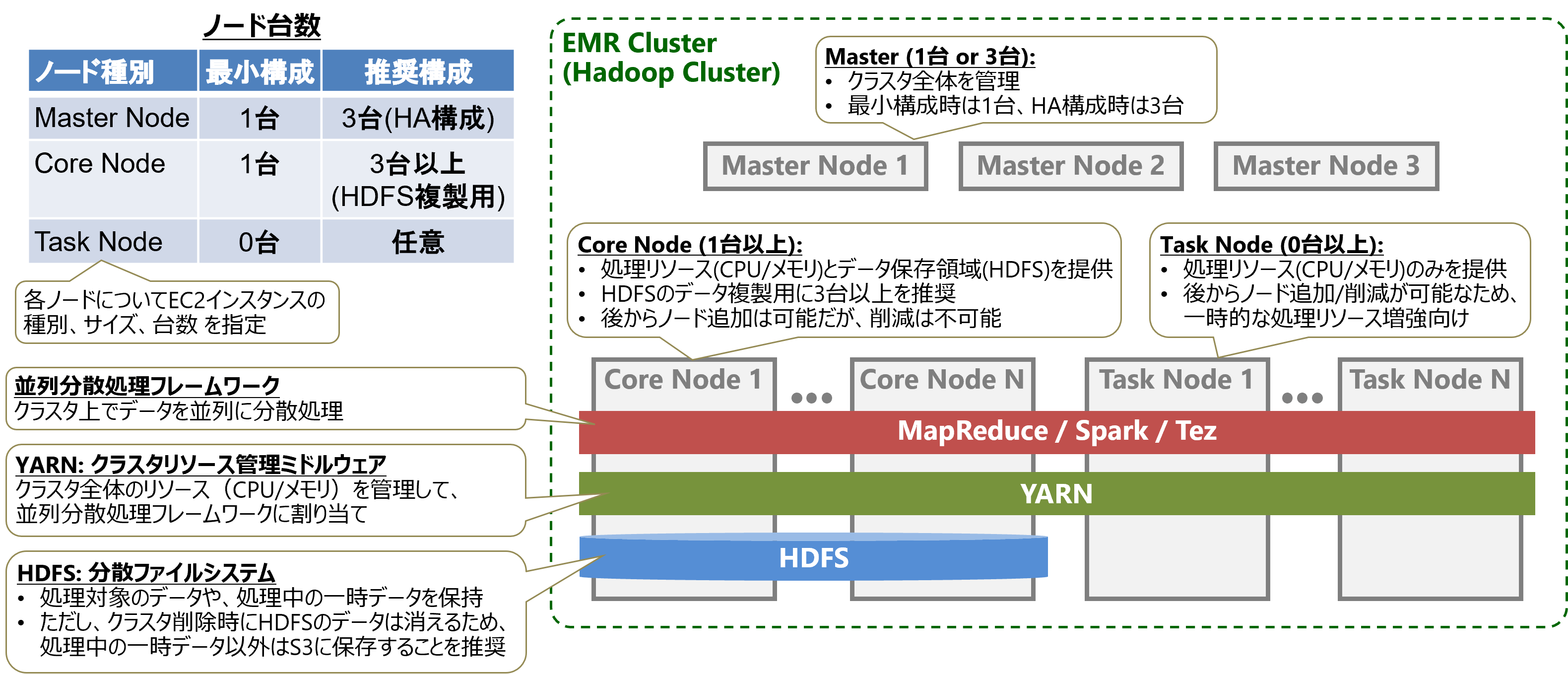
EMRは大量のデータを処理・分析するためのマネージドサービスです。オープンソースのApache HadoopやApache Sparkを中心とした、20以上のOSSコンポーネント群をベースにしています。
EMRでは、複数のAmazon EC2インスタンスでEMRクラスタ(Hadoopクラスタ)を構成します。このEMRクラスタ上で、Sparkなどの並列分散処理フレームワークを実行することで、大量のデータを高速に処理できます。EMRはクラスタの拡張(インスタンス追加)により性能をスケールアウトできます。
EMRクラスタの構成を以下の図に示します。
Spark Streamingとは
Sparkはインメモリで処理を行う並列分散処理フレームワークであり、基本的にはバッチ処理に使用します。Spark Streamingは、このSparkでストリーム処理を行うためのコンポーネントであり、KDSまたはKafka(MSK)と接続するためのプラグインが提供されています。
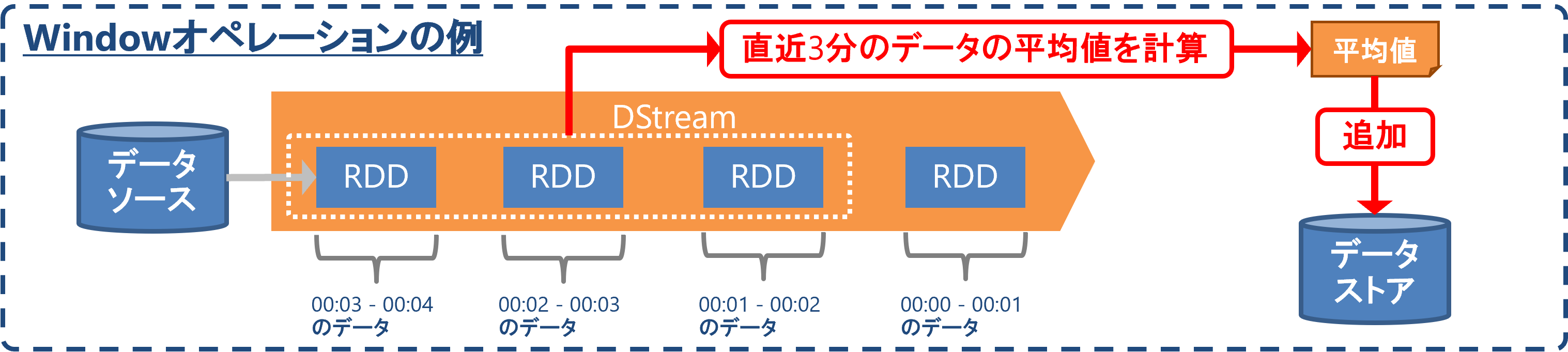
Spark Streamingのストリーム処理はマイクロバッチ方式です。数秒~数分ほどの短い間隔でバッチ処理を繰り返すことで、準リアルタイムなデータ処理を実現します。Spark StreamingもKDSと同様に、複数のRecordにまたがる高度な処理が可能です。
例えばマイクロバッチを1分間隔で実行しており、Windowオペレーションで直近3分間のデータの平均値を計算する場合、直近3回分のマイクロバッチのデータを使用します。マイクロバッチを実行するたびに、この3分間のWindowがスライドしていきます。
KDSとSpark Streamingの組み合わせ
Spark StreamingはKDS用のプラグインを使用することで、KDSからデータを取得してストリーム処理を行います。Spark Streamingの内部では、Kinesis Client Library (KCL)を使用してBlock interval(1秒)間隔でデータを取得しておき、それをBatch interval(例えば5秒)間隔でまとめて処理します。
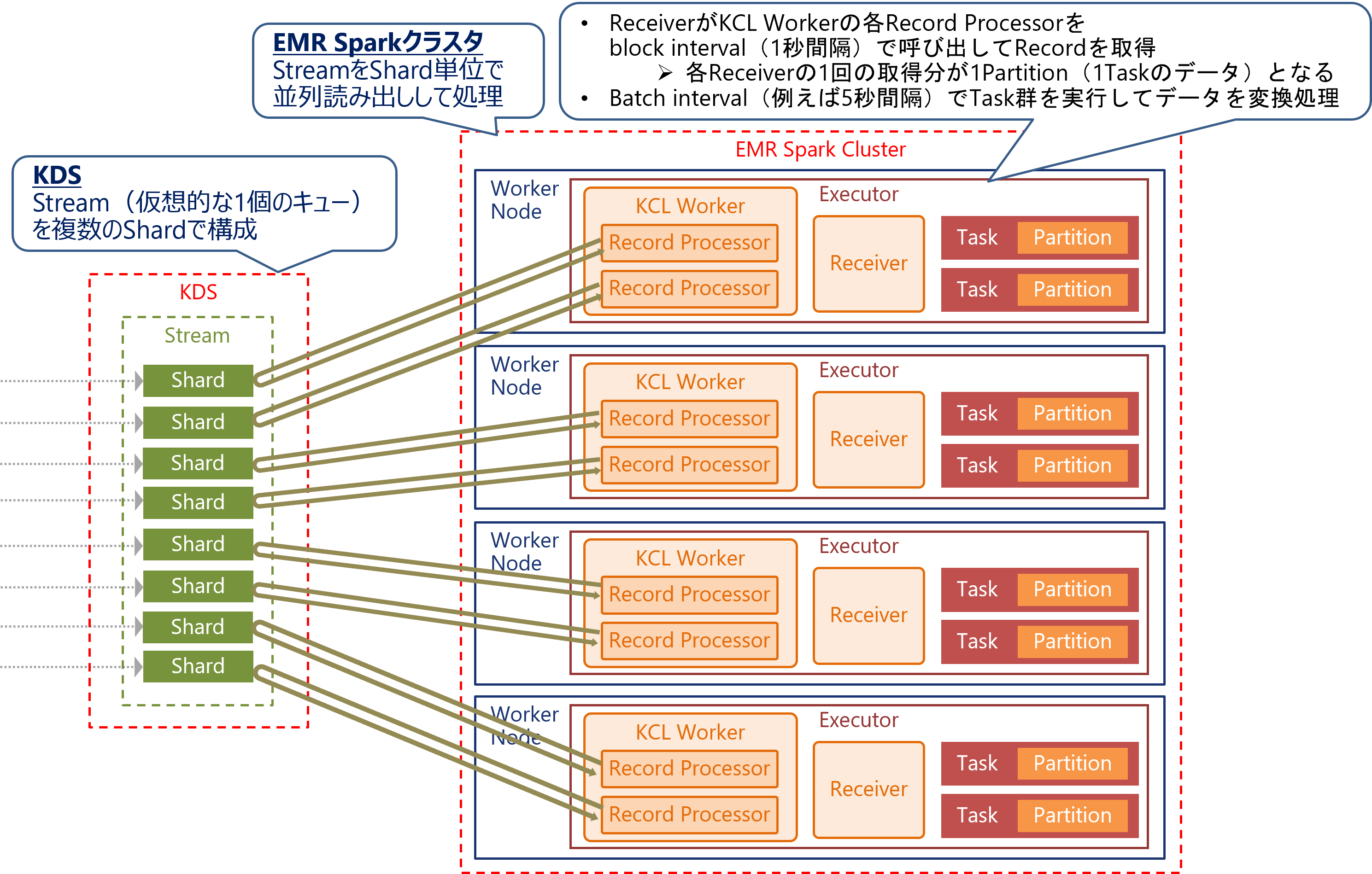
- 参考URL:
MSK と Spark Streaming の組み合わせ
Spark StreamingはKafka用のプラグインを使用することで、MSKからデータを取得してストリーム処理を行います。Spark Streamingの内部では、KafkaのPartitionと1:1対応するSparkのTaskを自動生成し、Partition単位で並列にデータを読み出して処理します。
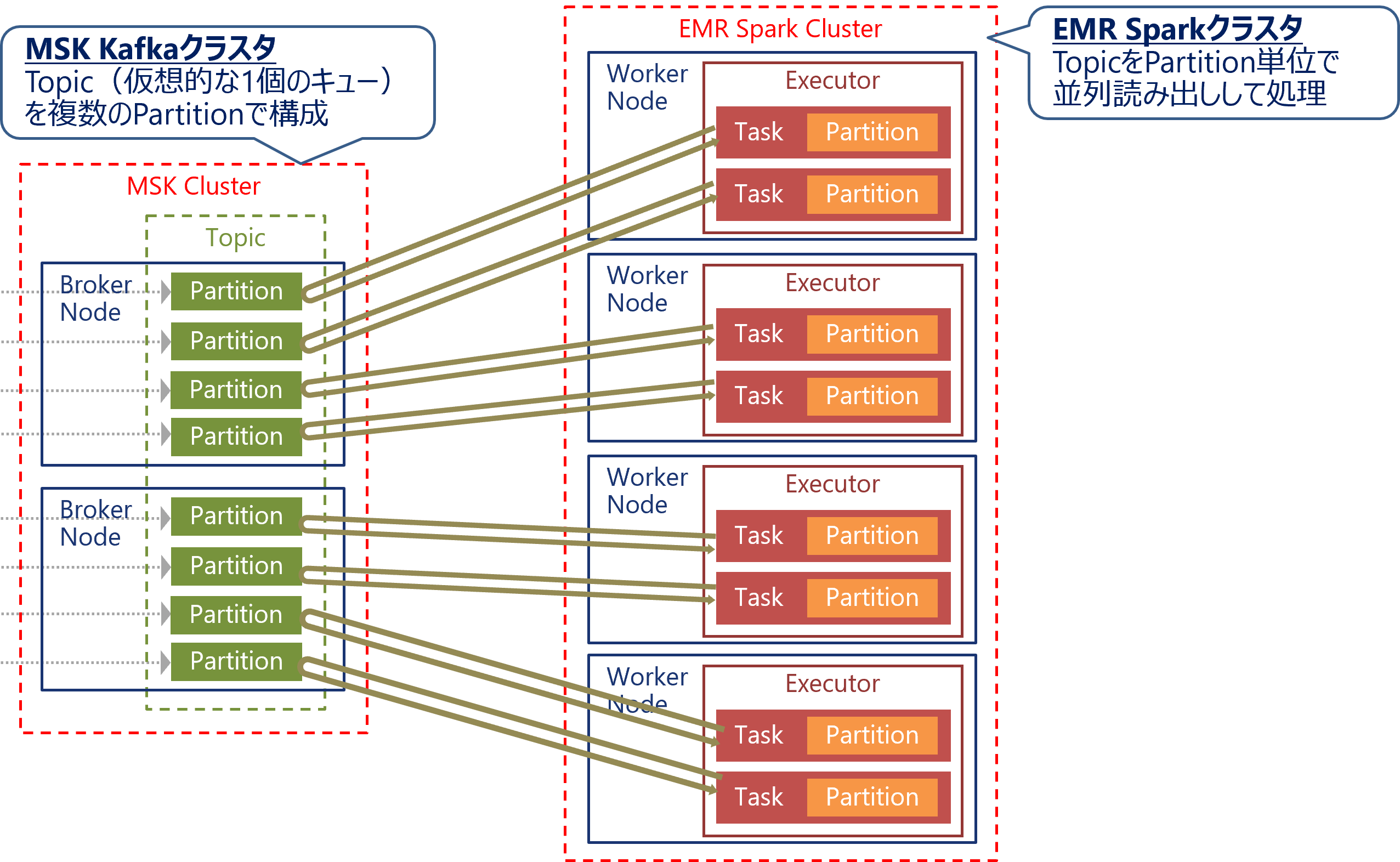
KDSの場合はまずReceiverがデータを取得して一旦蓄積し、それをSparkのタスクがまとめて処理しますが、MSKの場合はSparkのタスクが直接データを取得して処理します。そのためSpark Streamingを使用する場合は、KDSよりもMSKから取得する場合の方がオーバーヘッドなくデータを処理できるといえます。
参考URL: https://spark.apache.org/docs/latest/streaming-kafka-0-10-integration.html
AWS Lambda
Lambdaによるイベント駆動処理
Lambdaは任意の処理コードをサーバレスで実行できるサービスです。Amazon EC2のようにインスタンスを常時起動しておく必要はなく、処理コードの実行時間で課金されます。
メッセージングサービスと組み合わせることで、メッセージキューへの書き込みをトリガーにしてLambda関数を起動することが可能です。データ読み出しのためにメッセージキューをポーリングする必要はありません。これにより、イベント駆動型のアプリケーションを構築できます。ただしKDSやEMRとは異なり、複数のRecordにまたがる高度な処理(ウィンドウ集計など)はできません。
Lambdaのチューニング
Lambdaのチューニング項目はメモリ量のみであり、CPUパワーとネットワーク帯域、ディスクのI/O性能は、割当メモリ量に比例して割り当てられます。割当メモリの量は、128 MB ~ 10,240 MB の範囲 (1 MB 単位) で選択できます。
例えば256 MB のメモリを指定した場合、CPUパワーは 128 MBのメモリを指定した場合の約 2 倍となります。1,769 MBメモリを指定すると、1vCPUに相当(Amazon EC2インスタンスの1vCPUクレジット)するCPU パワーが割り当てられます。これ以上メモリ割当量を増やすと2個目以降のvCPUが割り当てられ、シングルスレッド処理だと性能が向上しないため注意が必要です。
参考URL: https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/resource-model.html
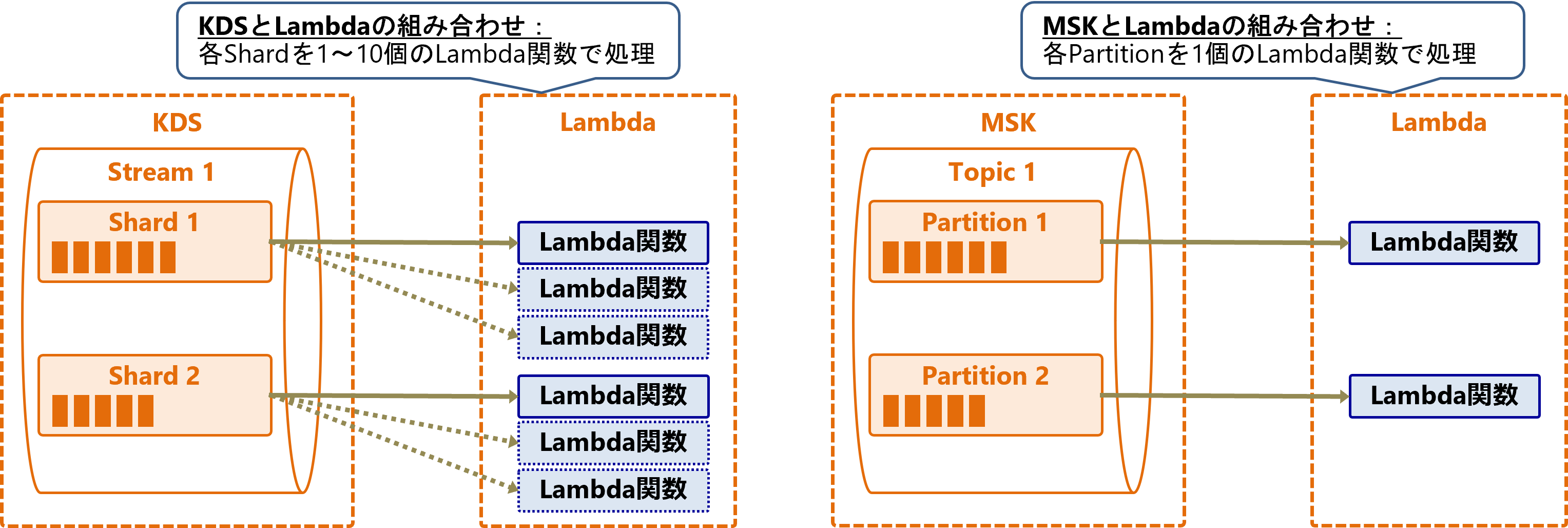
KDS/MSKとLambdaの組み合わせ
KDSのStreamまたはMSKのTopicへの書き込みをトリガーにLambda関数を起動して、データを変換処理することが可能です。これによりイベント駆動型の処理を実現します。このトリガーはStream/Topicへの書き込み時だけでなく、実行間隔を指定した定期実行も可能です。この場合、複数Recordをまとめてバッチ処理できます。
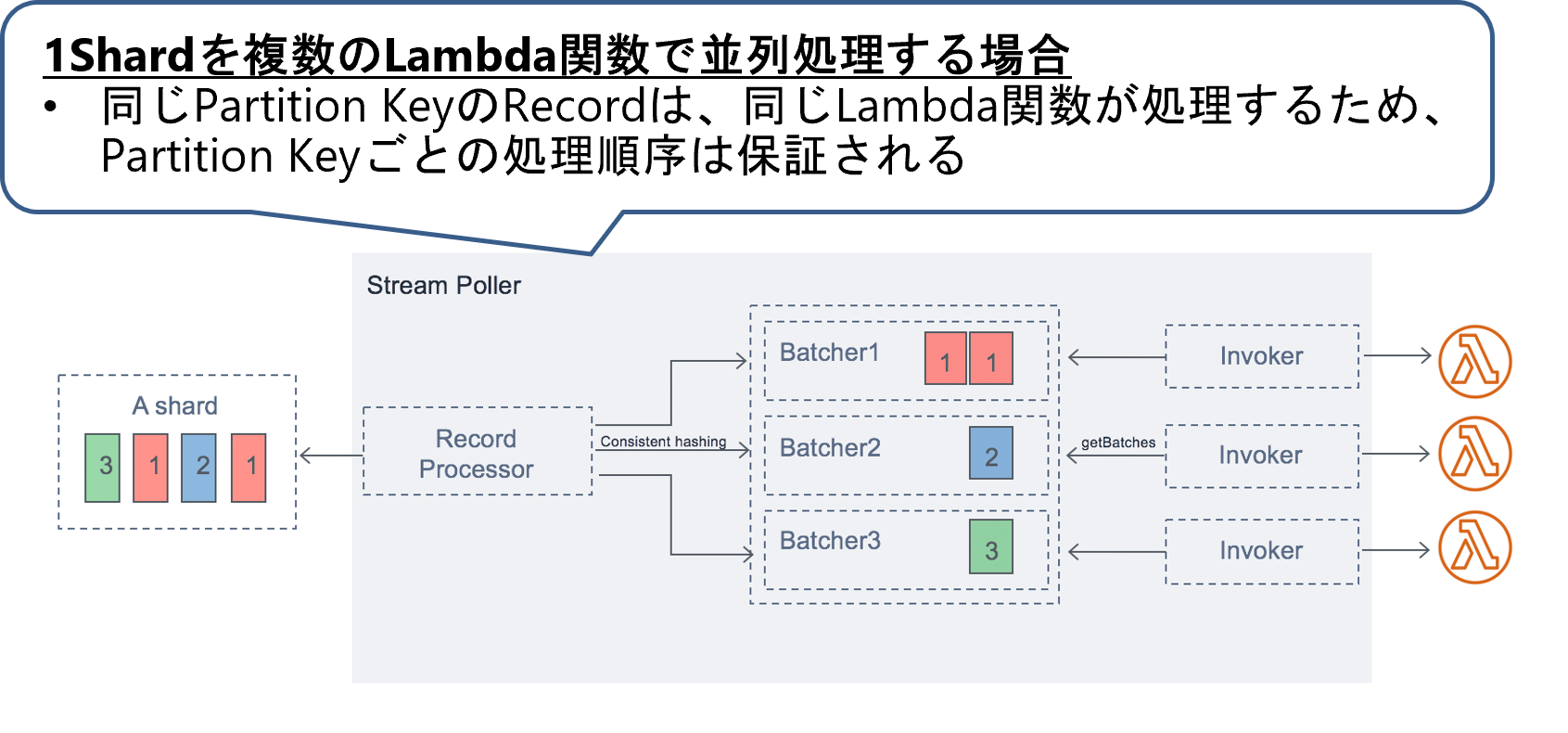
初期設定では、1Shardまたは1Partitionを1個のLambda関数で並列処理します。**KDSの場合のみ、**1Shardを最大10個のLambda関数で並列処理することも可能です(Parallelization Factorを指定)。
1Shardを複数のLambda関数で並列処理する場合でも、同じPartition KeyのRecordは同じLambda関数が処理するため、Partition Keyごとの処理順序は保証されます。
SQSとLambdaの組み合わせ
SQSへの書き込みをトリガーにLambda関数を起動して、データを変換処理することが可能です。このトリガーは標準キューとFIFOキューを共にサポートしています。また、Lambda関数が正常に処理できたメッセージは、キューから自動的に削除してくれます。
標準キューの場合、Lambda関数の並列起動数は自動的にスケールします。Lambda関数の起動数は5個から開始し、1分あたり最大60個増加し、最大1,000個までスケールできます。

ストリーム処理におけるKDA、EMR、Lambdaの特徴
ストリーム処理におけるKDA、EMR、Lambdaのメリットと注意点を以下に示します。
Amazon Kinesis Data Analytics (KDA)
- メリット:
- JavaとSQLによるデータ変換処理が可能
- 複数Recordにまたがる高度な処理(ウィンドウ集計など)が可能
- 注意点:
- Flinkアプリケーション開発方法の学習が必要
Amazon EMR の Spark Streaming
- メリット:
- Java、Scala、PythonおよびSQLによるデータ変換処理が可能
- 複数Recordにまたがる高度な処理(ウィンドウ集計など)が可能
- MSKとの組み合わせでは若干オーバーヘッドが少ない
- 注意点:
- Sparkアプリケーション開発方法の学習が必要
- インスタンス台数などを意識する必要があり、実行時のチューニングはKDAより若干複雑
AWS Lambda
- メリット:
- 処理コードをデプロイするだけで簡単に利用可能
- チューニング項目はメモリ量だけなので単純
- サーバレスで常時稼働する必要がないため、コストを抑えやすい
- 注意点:
- 複数Recordにまたがる高度な処理(ウィンドウ集計など)はできない
おわりに
本投稿では、AWSが提供するストリーム処理サービスの特徴を紹介しました。ユースケースに合わせて適切なメッセージングサービスとストリーム処理サービスを組み合わせることで、効率的なストリーム処理が可能になります。
本投稿がAWSでストリーム処理システムを構築する際の参考になれば幸いです。