シリーズ目次
- ボックスカルバートの形状予測AI ~データ整理編~
- ボックスカルバートの形状予測AI ~学習用設計データの作成編~
- ボックスカルバートの形状予測AI ~ニュートラルネットワークの構築編~
- ボックスカルバートの形状予測AI ~いざ予測 編~
- Tensorflow.Keras で学習したモデルをtensorflow.jsで使う
説明
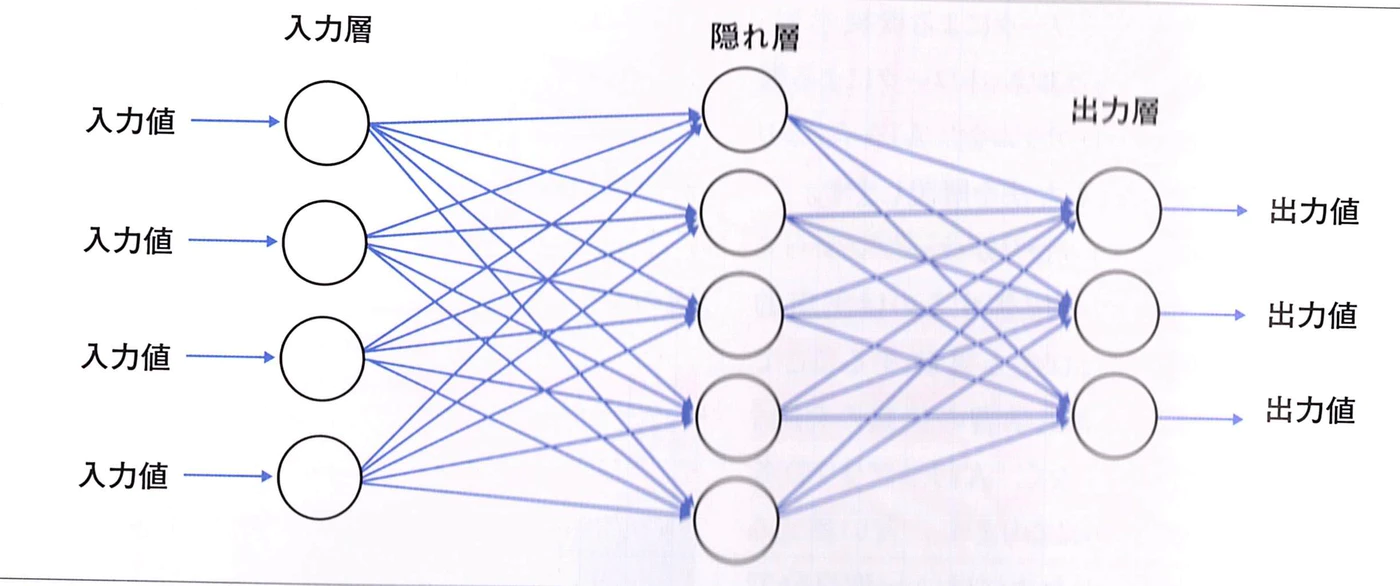
土木構造物のボックスカルバートの過去の事例を学習させ、部材厚を予測するAI を作る
ニュートラルネットワーク(AI)とは
- 入力値 × 中間層の重み係数 = 中間層の出力値
- 出力層の入力値 × 出力層の重み係数 = 出力値
重み係数とは層と層をつなぐ線のことで 0.0045 や 1.232 などの 任意の数値です
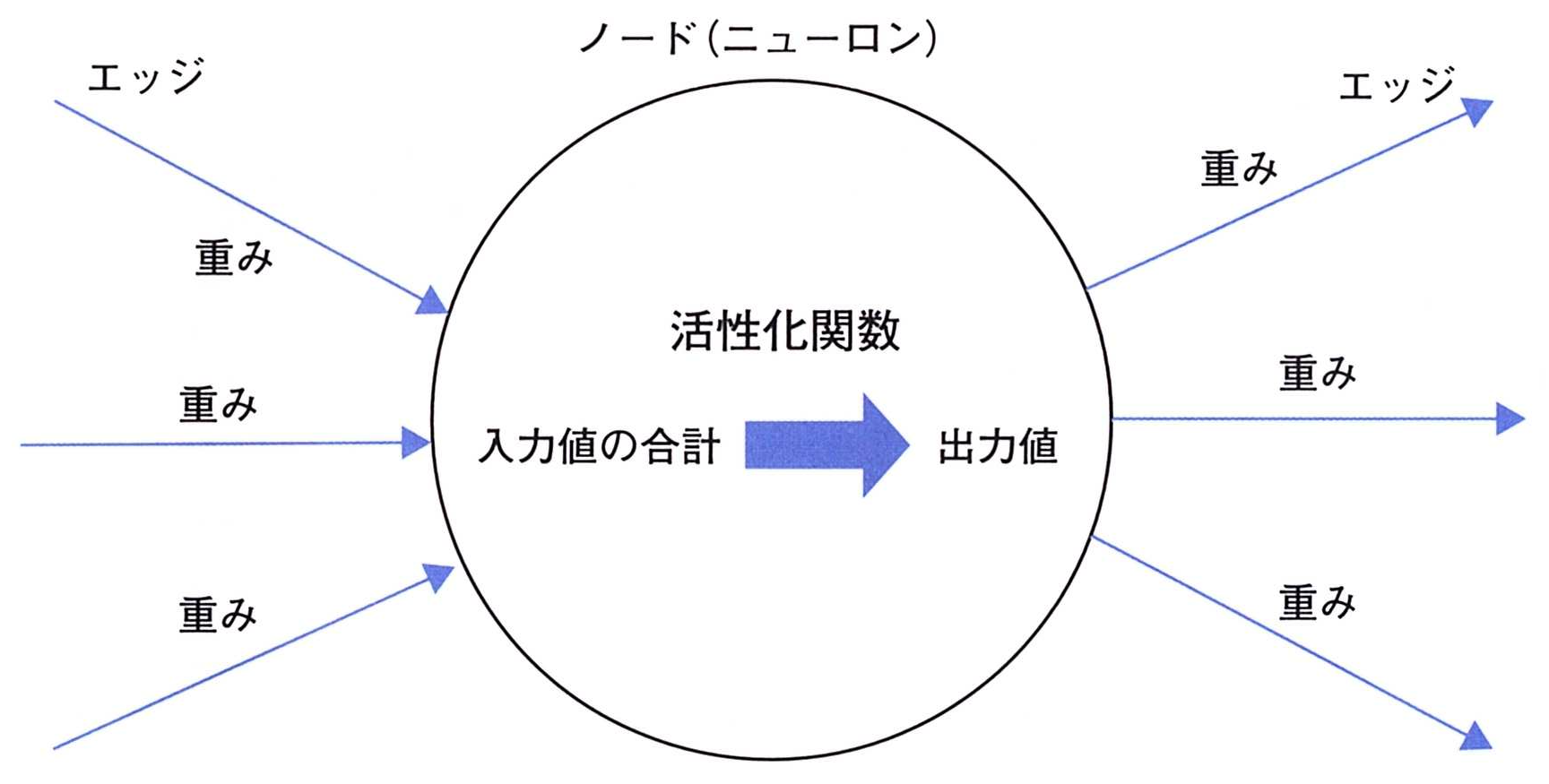
中間層の出力値 → 出力層の入力値 とするときに活性化関数を通します。
ソースコードは、google colacoratory で、↓ここにあります。
必要なモジュールを読み込む
import tensorflow as tf
from tensorflow.keras.layers import Activation, Dense, Dropout
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.applications.mobilenet import MobileNet
import csv
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
データを読み込む
csv ファイルのダウンロード
データ boxculvert_data.csv は 以下のリンクからダウンロードし、下記の読み込み処理で参照できるところに置いてください
以後のソースは、下図の通り Google ドライブ の boxAI フォルダ内にデータがあるものとしています
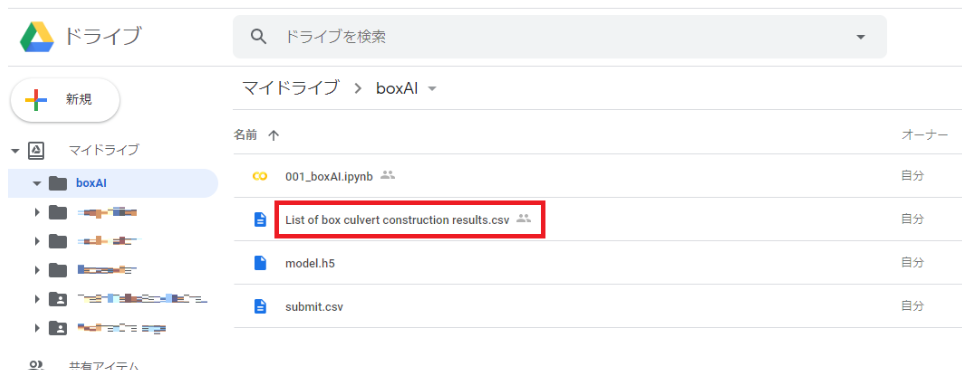
Google Drive をマウントする
今回は Google Drive にデータを保存しておいて読み込ませたが各々の環境に応じて読み込ませる方法を変えてください
from google.colab import drive
drive.mount('/content/drive')
データを読み込む
csv ファイルを 読み込みます.
datafolder = "/content/drive/MyDrive/boxAI"
with open(f'{datafolder}/boxculvert_data.csv') as f:
read_csv = [row for row in csv.reader(f)]
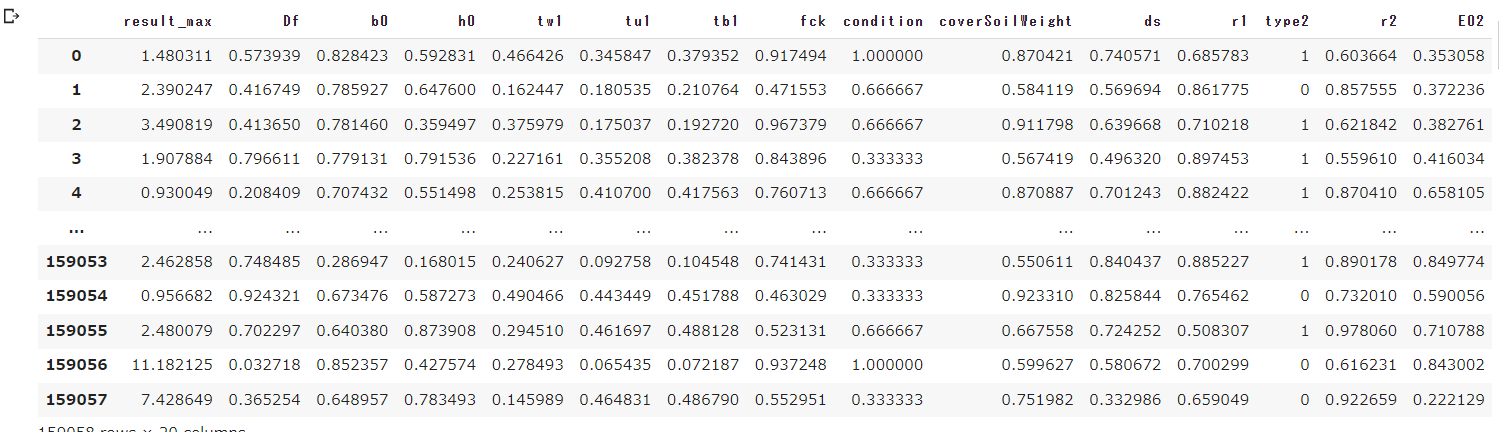
pd.DataFrame(data=read_csv)
データの正規化
csv データには、砂質土(sand), 粘性土(cray) を表す文字列 や、とても大きな数値があります。
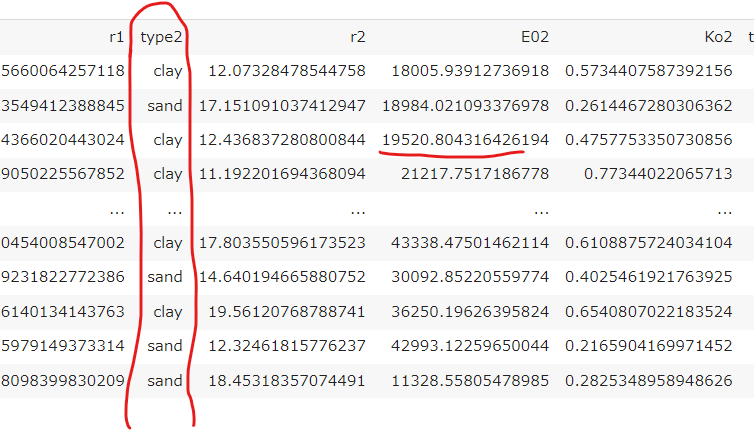
これらを学習にそのまま使うことはできません
そこで、全データを 0~1 の間の数値に変換します。
各列の最大値は以下の通りです。
max_value = [
3, # result_max
10000, # Df
20000, # b0
20000, # h0
5000, # tw1
5000, # tu1
5000, # tb1
80, # fck
3, # condition
20, # coverSoilWeight
100, # ds
20, # r1
1, # type2
20, # r2
51000, # E02
0.8, # Ko2
1, # type3
20, # r3
51000, # E03
0.8 # Ko3
]
この最大値を用いて 正規化します。
header = read_csv[0][1:]
data_norm = []
for r in range(1, len(read_csv)):
line = read_csv[r]
line_norm = []
for c in range(1, len(line)):
if c == 13 or c == 17:
value_norm = 1 if line[c] == 'clay' else 0
else:
value = float(line[c])
imax = max_value[c - 1]
if c == 1:
value_norm = (1/value) / imax # 安全率は逆数にして正規化する
else:
value_norm = value / imax
line_norm.append(value_norm)
data_norm.append(line_norm)
df = pd.DataFrame(data=data_norm, columns=header)
df
データから 入力と出力のパラメータに分ける
boxculvert_data.csv には答えとなる tu1, tb1, tw1列 が含まれているため 抽出します。
入力データ
train_datas = df.drop(['tw1','tu1','tb1'], axis='columns')
train_datas.head()

出力データ
train_labels = df.drop(['result_max','Df','b0','h0','fck','condition','coverSoilWeight','ds','r1','type2','r2','E02','Ko2','type3','r3','E03','Ko3'], axis='columns')
train_labels.head()

モデルの作成
今回は 17個の入力値を受け取って 3個の値を出力する「全結合層」を3つ重ねたシンプルなモデルを作成します。

n_in = len(train_datas.columns)
n_out = len(train_labels.columns)
nn= n_in * 5
model = Sequential()
model.add(Dense(nn, activation='sigmoid', input_shape=(n_in,)))
model.add(Dense(nn, activation='relu'))
model.add(Dense(nn, activation='sigmoid'))
model.add(Dense(nn, activation='relu'))
model.add(Dense(nn, activation='sigmoid'))
model.add(Dense(nn, activation='relu'))
model.add(Dense(nn, activation='sigmoid'))
model.add(Dense(n_out))
コンパイル
ニューラルネットワークのモデルをコンパイルを行います。
今回、
- 「損失関数」は回帰なので「mse」,
- 「最適化関数」は 「Adam」,
- 「評価指標」は「mse」
を指定しています。
「MSE」(Mean Squared Error) は, 「平均二乗誤差」とも呼ばれ、実際の値と予測値との誤差の二乗を平均したものになります。
$$
MSE=\frac{1}{n}\sum_{i=1}^{n}(f_i-y_i)^2
$$
「MAE」(Mean Absolute Error) は, 「平均絶対誤差」とも呼ばれ、実際の値と予測値との誤差の絶対値を平均したものになります。
$$
MAE=\frac{1}{n}\sum_{i=1}^{n}|f_i-y_i|
$$
どちらも、 0 に近いほど予測精度が高いことを示します。まったく同じデータセットに対して計算した場合のみ、相対的な大小が比較できます。
model.compile(loss='mse', optimizer=Adam(lr=0.001), metrics=['mae'])
学習
訓練データと訓練ラベルの配列をモデルに渡して学習を実行します。
EarlyStopping の準備
「EarlyStopping」は、任意のエポック数間に改善がないと学習を停止するコールバックです。
「コールバック」はfit() に引数を指定することで、1エポック毎に何らかの処理を実行する機能になります
callback
EarlyStopping(monitor='val_loss', patience=0)
説明: EarlyStopping の生成
引数: monitor (str 型) 監視する値
patience (int 型)ここで指定したエポック数に改善がないと学習を停止
今回は 20 試行のあいだに誤差の改善がみられない場合は、学習を終了するようにします
early_stop = EarlyStopping(monitor='val_loss', patience=20)
学習の実行
学習の実行には、 callbacks に EarlyStopping を追加します。
学習中に出力される情報
| 情報 | 説明 |
|---|---|
| loss | 訓練データの誤差, 0 に近いほどよい |
| mean_absolute_error | 訓練データの平均絶対誤差, 0 に近いほどよい |
| val_loss | 検証データの誤差, 0 に近いほどよい |
| val_mean_absolute_error | 検証データの誤差, 0 に近いほどよい |
学習開始
# 学習
history = model.fit(train_datas, train_labels, epochs=100, validation_split=0.2, callbacks=[early_stop])
# モデルを保存する
model.save(model_path)
コマンドを実行すると下のように学習が始まりますので待ちます。
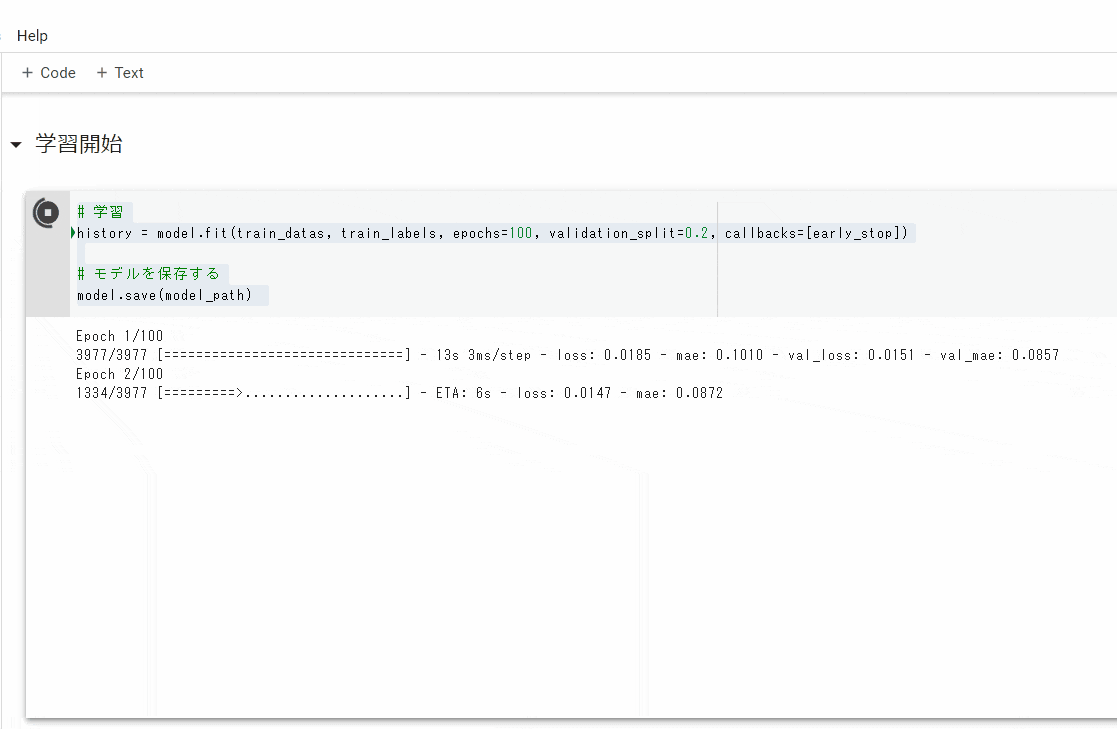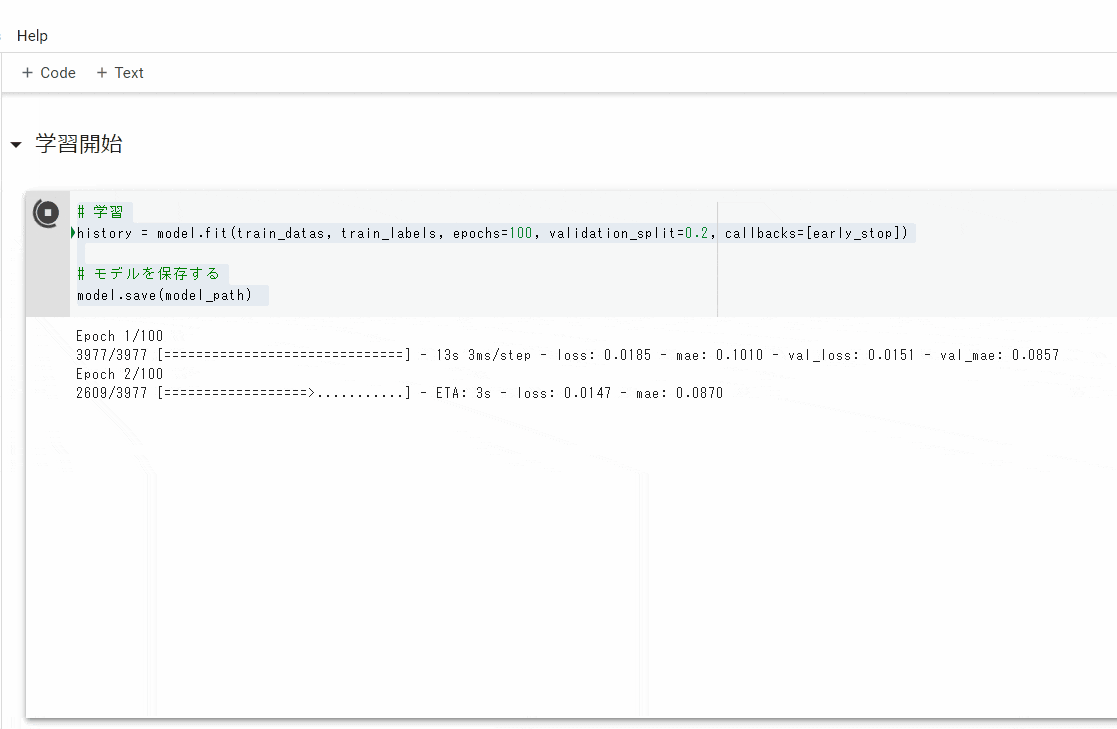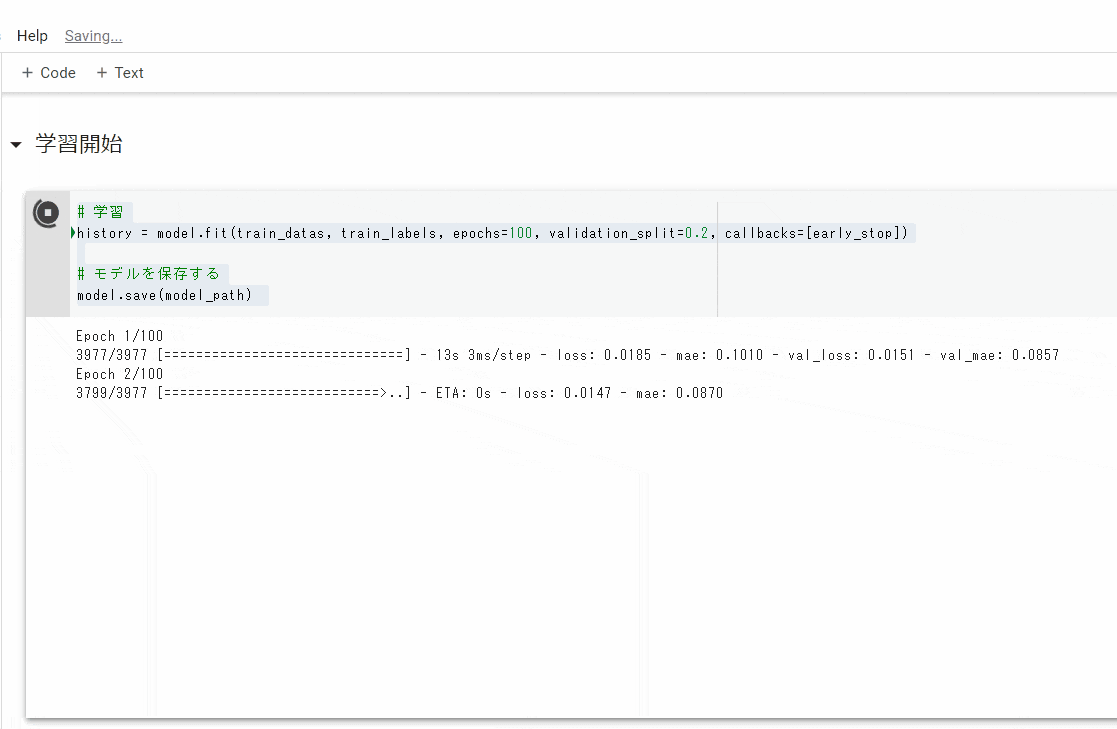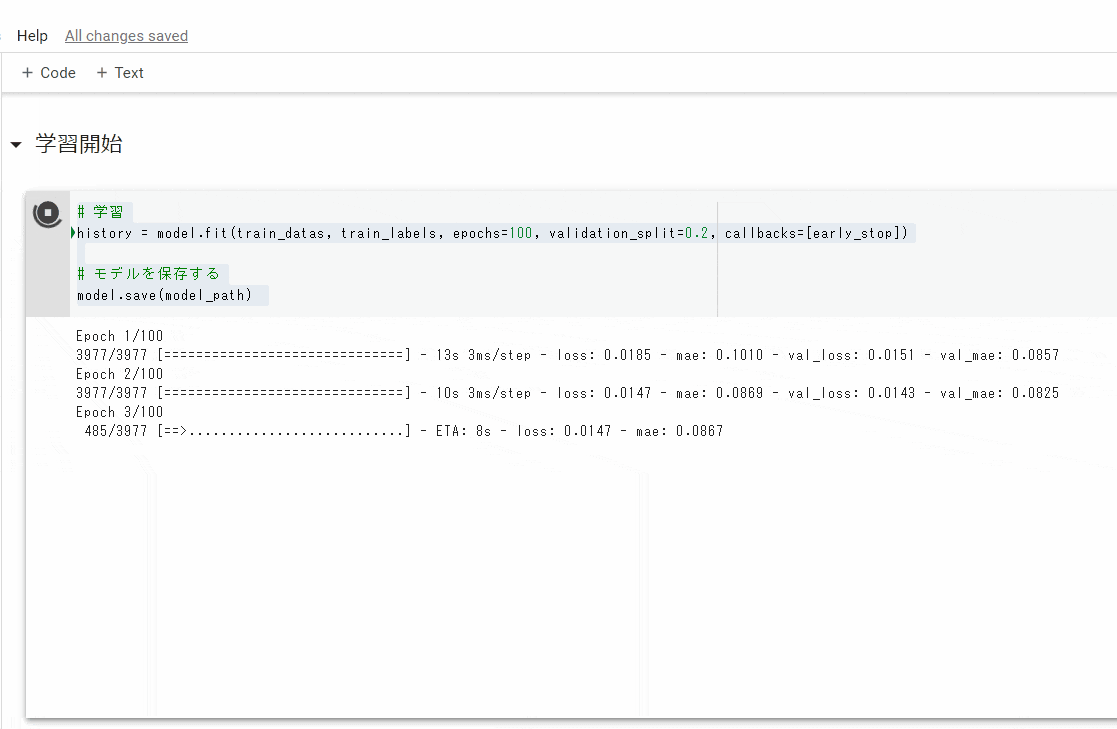
グラフの表示
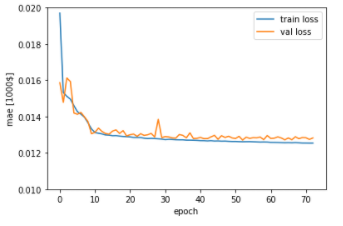
fit() の戻り値の「history」には、以下のような情報が含まれています。
「loss」と「val_loss」はコンパイル時の「損失関数」、それ以外は「評価指標」で指定したものになります。
この情報を「matplotlib」でグラフに表示します。
plt.plot(history.history['loss'], label='train loss')
plt.plot(history.history['val_loss'], label='val loss')
plt.xlabel('epoch')
plt.ylabel('mae [1000$]')
plt.legend(loc='best')
plt.ylim([0.01, 0.02])
plt.show()
次回
で AI に予測をさせてみます