シリーズ目次
- 機械学習の理論を理解せずに tensorflow で オセロ AI を作ってみた ~導入編~
- 機械学習の理論を理解せずに tensorflow で オセロ AI を作ってみた ~実装編~
- 機械学習の理論を理解せずに tensorflow で オセロ AI を作ってみた ~いざ対戦編~
- 機械学習の理論を理解しようとしてから オセロ AI を作ってみた 〜再始動‼〜
- 機械学習の理論を理解しようとしてから オセロ AI を作ってみた 〜何これ Alpha Zero 編〜
- 機械学習の理論を理解しようと エクセルでニュートラルネットワークを作ってみた 〜画像認識 mnist 編〜
この分野では門外漢の私が、「機械学習の理論」をまったく勉強せずに
オセロのAI を作ってみようと思います。
参考にしたサイトはこちら
・ 超シンプルにTensorFlowでDQN (Deep Q Network) を実装してみる 〜導入編〜
概要
構想をざっくり説明しますと
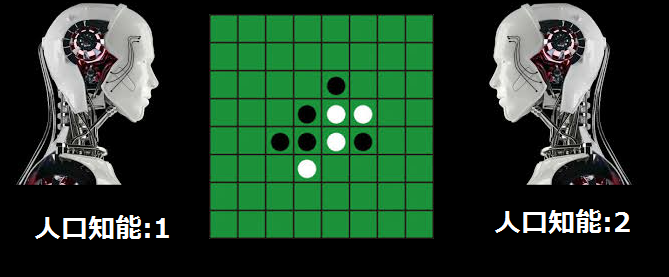
2体の人工知能がひたすらオセロの対決を行い、
後手のAIを保存し私(人間)と戦う。というわけです。
環境条件
私の環境は下記の通りです。
OS
・ubuntu
開発環境
・python 3.5
この環境でも動くと思う
Google Cloud Platform で Ubuntu python 開発環境を構築する
まずは動かしてみよう
はじめにソースコードをダウンロードします。
ソースはここにおいておきます。
$ git clone https://github.com/sasaco/tf-dqn-reversi.git
学習
環境が整ったら、ソースコードのディレクトリに移動して、train.pyを叩くと学習が始まります。
$ cd tf-dqn-reversi
$ python train.py
下記のようなログが出ていれば、正しく学習が行われています。
player:1 | pos:32 | LOSS: 0.0000 | Q_MAX: 0.0041
player:2 | pos:15 | LOSS: 0.0000 | Q_MAX: 0.0009
…
layer:2 is only pos:56
player:2 | pos:56 | LOSS: 0.0000 | Q_MAX: 0.8607
EPOCH: 999/999 | WIN: player2
winner is player2
※LOSS がほとんど 0 なんですけど問題ないのでしょうか.
LOSS が何であるかすら 理解していません ( ̄^ ̄)
どなたか詳しい方、ご教示をお願いいたします。
m(_ _)m
実装は、実装編をご覧ください。
テスト
学習が終わるのに数時間掛かります。
では学習したモデルでテストしてみましょう。
$ python FightWithAI.py
------------- GAME START ---------------
*** userターン○ ***
0 1 2 3 4 5 6 7
8 9 10 11 12 13 14 15
16 17 18 19 20 21 22 23
24 25 26 ○ ● 29 30 31
32 33 34 ● ○ 37 38 39
40 41 42 43 44 45 46 47
48 49 50 51 52 53 54 55
56 57 58 59 60 61 62 63
番号を入力してください
[43, 34, 29, 20]
>>>
上記のようにゲームが開始されればば成功です。
きちんと動作しましたでしょうか?
対戦結果は~いざ対戦編~に書きます。
次回は、実装編についてお届けします。